

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LIF结合LSTM神经网络的矿井水源识别
[闫鹏程1, 2  , 张孝飞
, 张孝飞2, * , 尚松行2 , 张超银2 ]
, 张孝飞, 尚松行|
|


作者简介: 闫鹏程, 1988年生, 安徽理工大学电气与信息工程学院讲师 e-mail: PCYan1988@126.com
矿井水害对煤矿安全生产存在巨大威胁, 所以快速识别矿井突水水源, 对煤矿水灾预警及灾后救援工作开展都有重大意义。 激光诱导荧光(LIF)技术具有快速、 高效、 灵敏度高等特点, 克服了传统水化学方法识别时间长的缺点。 循环神经网络(RNN)在解决长序列训练过程中产生的梯度消失、 梯度爆炸等问题上存在明显不足, 而特殊变体RNN即长短期记忆(LSTM)神经网络很好地弥补了RNN的短板及缺陷。 提出了将LIF技术与LSTM算法相结合, 应用在矿井突水水源快速识别中。 实验样本采自淮南矿区, 以砂岩水和老空水为原始样本, 并将砂岩水和老空水按照不同比例混合配置成5种混合水样, 共7种待测水样进行实验。 首先采用最大最小值归一化(MinMaxScaler)、 平滑滤波(SG)以及标准正态变量变换(SNV)三种预处理方法对原始光谱数据进行预处理, 减少原始光谱数据存在的噪声和干扰信息。 之后为防止数据量过大, 维度过高, 将包括原始光谱数据在内的四组数据再进行LDA降维至3维。 最后分别搭建LSTM识别模型, 从测试集预测准确率、 训练集准确率变化趋势以及训练集损失函数变化趋势三个方面进行比较, 选择最优模型。 其中SG+LDA+LSTM和Original+LDA+LSTM在测试集预测准确率上都能达到100%, MinMaxScaler+LDA+LSTM测试集预测准确率在98.57%, SNV+LDA+LSTM准确率最低, 只有87.14%; 在训练集准确率变化趋势表现上, SG+LDA+LSTM能够保持良好的学习, 很快达到100%, Original+LDA+LSTM和MinMaxScaler+LDA+LSTM也能达到100%的准确率, 但在前几次训练过程中会有准确率下降的情况出现, SNV+LDA+LSTM训练集准确率在训练次数内并未达到100%; SG+LDA+LSTM损失函数变化趋势也具有很好的收敛性和稳定性, Original+LDA+LSTM, MinMaxScaler+LDA+LSTM以及SNV+LDA+LSTM在损失函数变化趋势上表现并不出色。 结果表明, 4组模型中, SG+LDA+LSTM模型是最适合应用于矿井突水识别, 该方法补充了矿井突水水源识别工作的内容, 为矿井突水识别提供了新的思路。
Mine water disasteris a great threat to the safety production of a coal mine, so the rapid identification of mine water inrush source is of great significance to the early warning and post-disaster rescue work. Laser-induced fluorescence (LIF) technology has high speed, high efficiency and high sensitivity, which overcomes the shortcomings of long recognition time in traditional hydrochemical methods. Circulating neural network (RNN) has obvious shortcomings in solving the problems of gradient disappearance and gradient explosion in long sequence training, while the special variant RNN, long and short term memory (LSTM) neural network, makes up for the shortcomings of RNN.In this paper, the combination of LIF technology and LSTM algorithm is applied to rapidly identify mine water inrush source.The experimental samples were collected from Huainan Mining Area. The sandstone water and goaf water were taken as the original samples, and the sandstone water and goaf water were mixed into 5 kinds of mixed water samples. According to different proportions, 7 kinds of water samples experimented. Firstly, MinMaxSxalerr, SG and SNV were used to preprocess the original spectral data to reduce the noise and interference. After that, to prevent the data from being too large and too high a dimension, the dimension of four groups of data, including the original spectral data, was reduced to 3 dimensions by LDA.Finally, the LSTM recognition models are built respectively, and the optimal model is selected by comparing the prediction accuracy of the test set, the changing trend of the accuracy and the loss function of the training set.Thereinto, SG+LDA+LSTM and Original+LDA+LSTM can reach 100% in the test set prediction accuracy, MinMaxScaler+LDA+LSTM test set prediction accuracy is 98.57%, SNV+LDA+LSTM accuracy is the lowest, only 87.14%;In terms of the trend of training set accuracy, SG+LDA+LSTM can keep good learning and reach 100% soon. Original+LDA+LSTM and MinMaxScaler+LDA+LSTM can also reach 100% accuracy. However, at the beginning of the training process, the accuracy will decline, and the SNV+LDA+LSTM training set does not reach 100% within the training times; The trend of SG+LDA+LSTM loss function also has good convergence and stability. Original+LDA+LSTM, MinMaxScalerr+LDA+LSTM and SNV+LDA+LSTM do not perform well in the trend of loss function.The results show that the SG+LDA+LSTM model is the most suitable for mine water inrush identification among the four models. This method supplements the work of mine water inrush source identification and provides a new idea for mine water inrush identification.
煤矿资源对于国家发展和生产起着重要作用, 是重要的不可再生资源和基础能源, 能否合理开发与利用煤矿资源, 直接影响经济社会的安全发展与国民经济可持续发展, 而煤矿的安全生产不仅关乎经济发展, 也关乎到人民的生命财产安全[1]。 矿井水害严重威胁着煤矿的安全生产, 是煤矿生产过程中存在的主要灾害之一[2, 3, 4]。 虽然近些年来矿井采掘技术的不断提高, 灾害处理能力的不断加强, 已经大幅度减少伤亡人员数量, 但随着矿井采掘深度加深, 开采规模日益加大, 导致水文地质环境也在随之变得复杂, 在不确定的工作环境中, 矿井水害的发生概率也会随之提高, 威胁着矿井工作者的生命财产安全[5]。 因此快速识别矿井突水水源类型, 对于水害预防工作和灾后救援工作都有着重大意义[6, 7]。
LIF技术能够完成非扰动、 实时原位测量, 荧光光谱分析具有灵敏度高, 速度快等优点, 近几年在科研中得到了广泛的应用[8]。 例如, 陈至坤等[9]运用LIF的光谱特征提取, 实现了对油类的检测; 张大源等[10]运用LIF技术, 实现了对HCCI发动机甲醛的定量测量; 朱家健等[11]将LIF技术运用到燃烧诊断的研究。 在矿井突水水源识别研究中, LIF技术也在近几年得到了应用, 但仍然有待改进和完善[12]。
循环神经网络(RNN)在解决长序列训练过程中产生的梯度消失、 梯度爆炸等问题上存在明显不足, 而特殊变体RNN即长短期记忆(LSTM)神经网络很好地弥补了RNN的短板及缺陷。 输入门、 输出门和遗忘门结构是LSTM相较于RNN, 添加的三个门结构[13]。 LSTM的关键是细胞状态, 它贯穿整个神经网络, 用来筛选并保留信息, 光谱数据往往含有比较多的复杂冗余的信息, 所以LSTM非常适合用来处理光谱数据。
鉴于此, 提出运用LIF技术得到水样的荧光光谱数据, 通过MinMaxScaler, SNV和SG三种方法对光谱数据进行预处理, 再将包括原始光谱数据在内的四组数据, 通过LDA进行降维处理, 最后结合LSTM神经网络, 搭建四种矿井突水水源识别模型, 进行对比, 选择最优模型。
实验样本采自淮南矿区, 以砂岩水和老空水为原始样本, 并将砂岩水和老空水按照不同比例(7:10, 4:10, 10:10, 10:7, 10:4)混合配制成5种混合水样, 共7种待测水样进行实验, 并且每种水样均采集30个, 共计210个水样待测样本。 按照不同混合比例, 为样本编号1, 2, 3, 4, 5, 6, 7, 将贴好标签的210个水样密封存储在遮光玻璃瓶中。
实验使用的仪器包括北京华源拓达生产的405 nm的单模激光器, 广州标旗光电生产的浸入式荧光探头(FPB-405-V3), 美国海洋公司生产的微型光纤光谱仪(USB2000+)。 实验参数设置: 激光功率为100 mW, 积分时间1 s, 采样间距340~1 020 nm, 光谱分辨率为1 nm。
首先对不同样本的光谱数据进行添加标签处理, 按照样本采取时的编号, 给对应的样本光谱数据添加相应的标签数值(1, 2, 3, 4, 5, 6, 7)。 LSTM神经网络通过训练集与之对应的标签形成的映射关系, 进行训练学习。 调整合适的训练周期以及一次训练抓取的样本数, 使用Adam优化器调整合适的学习率并对模型其他相关参数进行优化。 用Python3.9软件建立模型。
模型优劣的评判是通过测试集预测(Prediction)结果与真实值(Real)比较、 训练样本准确率变化趋势(Accuracy)和迭代损失(Loss)来进行模型的评估和对比。 测试集预测值与真实值相符越多, 则模型识别效果越好; 训练集准确率(Accuracy)是通过测试集经过模型输出的预测值和测试机对应的标签真实值对比, 是准确个数与总样本数的比值; 迭代损失(Loss)属于多分类交叉熵损失, 当迭代损失趋于平稳则反应系统训练良好, 系统性能更具有优势。
如图1所示, 除原始光谱数据外, 实验采用3种方法对原始光谱数据进行预处理, 分别为MinMaxScaler、 SG以及SNV, 总共得到4组光谱数据。 由图1可知在420~650 nm波段, 水样的光谱数据区别比较明显, 而在340~420以及650~1 020 nm波段光谱图像十分相近。
 | 图1 原始光谱曲线及预处理后的光谱曲线Fig.1 Original spectra and spectra pretreated by using different methods |
灰岩水所含有机物比较少, 而老空水成分复杂, 所以水样荧光光谱图像会随着老空水含量增加, 荧光光谱特征逐渐明显。 根据水源类的识别研究机理, 这是由于不同水源中所含的物质成分以及浓度等特征不同, 从而导致在光谱图像中形成了明显的差异。 与原始数据比较, SG和MinMaxScaler预处理后的光谱图像都有较好的处理效果, 组间间距有所增加或保持良好, SNV处理后的数据比较冗杂, 效果不如SG和MinMaxScaler理想。
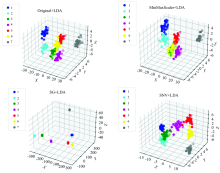
对原始数据及预处理后的荧光光谱数据进行LDA降维处理, 降维至3维特征数, 其降维效果图如图2所示。 由图2可得经SG预处理后的LDA降维聚类效果最为明显; 原始光谱数据及MinMaxScaler预处理后的数据进行LDA降维后效果相差不大; SNV预处理后LDA降维效果没有其他的效果明显。 基于这四种分别搭建LSTM识别模型。
 | 图2 不同预处理下的LDA降维结果图Fig.2 Dimension reduction results of LDA under different pretreatments |
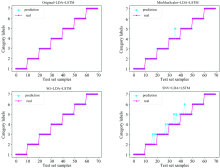
基于四组光谱数据, 经LDA降维处理后分别搭建LSTM水源识别模型。 通过对比测试集的预测情况、 训练集的准确率变化趋势以及迭代损失函数变化趋势三个方面, 多角度考虑, 选择最优模型。 四种模型的测试集的预测情况如图3所示。 其中SNV+LDA处理后的数据所搭建的LSTM模型预测效果最差; MinMaxScaler+LDA处理后的模型预测准确率比较高; SG+LDA以及原始光谱数据经LDA处理后的两组模型, 在测试集的准确率上都有着很好的表现, 准确率能够达到100%。 测试集预测准确率如表1所示。
 | 图3 不同模型下的测试集识别结果Fig.3 Recognition results of test sets in different models |
| 表1 不同模型测试集准确率 Table 1 Accuracies of test set in different models |
训练集训练准确率也是很重要的比较依据。 如图4所示, SNV+LDA之后的光谱数据在经过30次迭代训练之后, 训练集训练准确率依旧很难达到100%, 模型训练效果比较差; 原始光谱数据经过LDA和MinMaxScaler+LDA处理后的光谱数据在数次迭代之后训练集训练准确率会有一个下降过程, 说明该模型在前期训练效果比较差, 如果训练次数不够, 很难达到最佳状态; 而SG+LDA处理后的光谱数据在训练过程中, 训练集训练准确率处于持续上升的趋势, 比较少的训练次数就能很快达到100%的训练准确率。
 | 图4 不同模型的训练过程准确率变化趋势图Fig.4 The changing trends of accuracy in training process of different models |
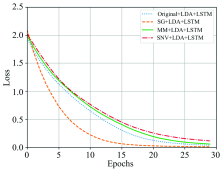
损失函数也是评判模型优劣的重要指标之一。 如图5不同模型训练过程损失函数变化趋势图来看, SG+LDA处理后的光谱数据建立的模型具有更好的收敛性和稳定性; 原始光谱数据经过LDA处理和MinMaxScaler+LDA处理后的光谱数据, 两者建立的模型收敛相对较慢, 性能不如前者; SNV+LDA处理后的数据建立的模型收敛性稳定性最差, 并不具有较好的性能。
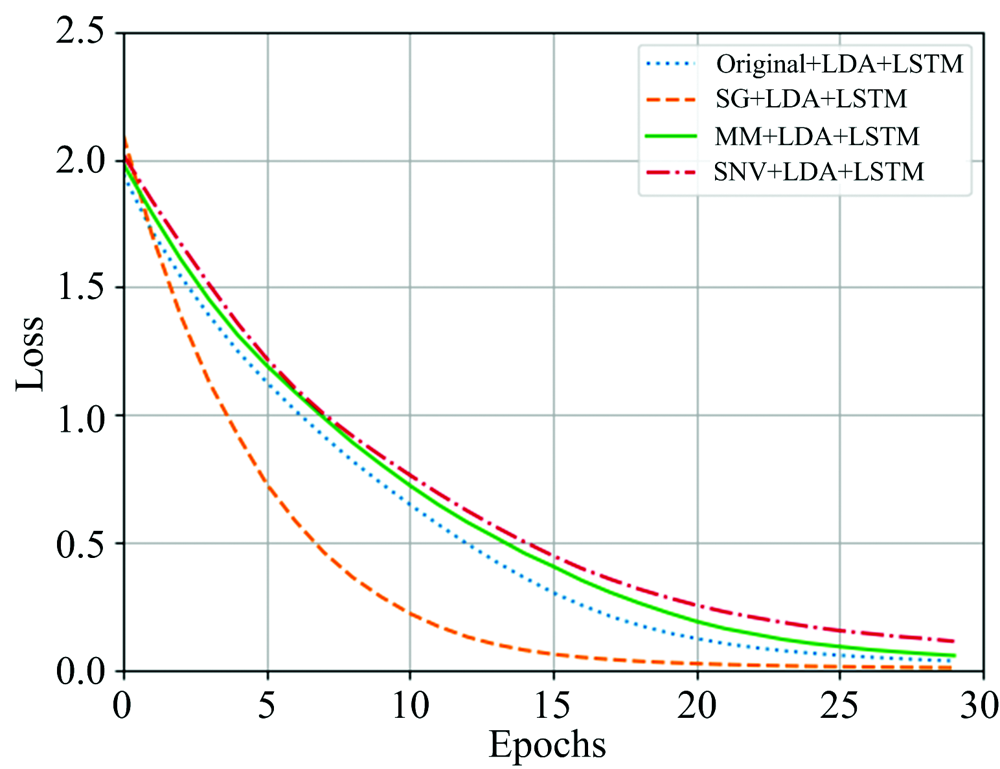 | 图5 不同模型的训练过程损失化数变化趋势图Fig.5 The changing trends of loss function in training process of different models |
综合上述分析, SNV+LDA处理后的光谱数据建立的LSTM识别模型效果最差; 原始光谱数据经过LDA降维处理后建立的LSTM识别模型和MinMaxScaler+LDA处理后的光谱数据建立的LSTM识别模型有不错的识别效果和性能表现; SG+LDA处理后的光谱数据建立的LSTM识别模型在预测准确率、 训练过程准确率以及损失函数变化趋势都有更好的表现。
利用淮南谢桥煤矿的砂岩水和老空水为原始样本, 并将两种水按照不同比例混合成5种水样, 共七种水样样本, 对七种水样的激光诱导荧光光谱进行识别分析。 经过MinMaxScaler, SG以及SNV三种方法预处理, 包括原始光谱数据再进行LDA降维处理, 搭建四种LSTM识别模型。 从测试集预测结果, 训练集训练准确率变化趋势以及训练过程的损失函数变化趋势三个方面进行比较, 选择出最优模型。 结果表明, 采用SG+LDA处理后的光谱数据搭建的LSTM识别模型对水样样本识别效果最好, 这是由于三种预处理方法对于光谱数据的作用不同导致的, 其中MinMaxScaler主要消除光谱数据尺度差异过大的影响, SG用来消除随机噪声并且提高信噪比, 而SNV主要是降低分布不均匀带来的影响; 本工作中SG预处理方法表现最佳。 LSTM识别模型具有比较好的性能实现对水源的识别, 对人工智能在矿井突水水源识别方面提供了新的探索和改进。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|