{kind=link}
{kind=link}
{kind=link}
主成分分析排序和模糊线性判别分析的生菜近红外光谱分类
[武斌1  , 沈嘉棋
, 沈嘉棋2 , 汪鑫2 , 武小红3 , 侯晓蕾2 ]
, 沈嘉棋|
|


作者简介: 武 斌, 1978年生, 滁州职业技术学院信息工程学院副教授 e-mail: wubind2003@163.com
贮存时间是影响生菜品质的一项重要因素, 传统的贮存时间鉴别方法主要依靠人工经验, 但是这种方法的准确率和可信度并不高。 研究的目标是建立一种基于模糊识别的模型进行生菜光谱分析以实现生菜贮存时间的鉴别, 并与其他鉴别方法作比较。 为此, 在当地超市购买60份新鲜生菜样品, 存放于冰箱中待用。 首先, 通过Antaris Ⅱ近红外光谱检测仪采集生菜样品的近红外光谱数据, 每隔12小时检测一次, 每个样本检测重复三次, 并取三次平均值作为实验数据。 其次, 利用多元散射校正(MSC)减少近红外光谱中的冗余信息。 为了进一步去除近红外光谱中的无用信息以及简化随后的数据分类过程, 分别运用主成分分析(PCA)和排序主成分分析 (PCA Sort)。 其中, PCA Sort通过改进对主成分的排序方法能提高分类准确率, 同时便于模糊线性鉴别分析(FLDA)进一步提取特征。 PCA和PCA Sort的计算仅运用了前15个主成分(能充分反映光谱的主要信息)。 最后, 利用模糊线性鉴别分析算法(FLDA)和K近邻算法(KNN)进一步分类所得的低维数据。 基于PCA和KNN算法的模型鉴别准确率达到43%, 而基于PCA, FLDA和KNN算法的模型鉴别准确率可达83%。 上述结果说明基于PCA, FLDA和KNN算法的模型鉴别准确率已经得到较大程度提高。 当用PCA Sort替代了模型中的PCA算法后, 结合FLDA和KNN算法则鉴别准确率达到98.33%。 实验结果表明PCA Sort结合FLDA和KNN所建立的模型是有效的生菜贮存时间鉴别模型。
The storage time of lettuce is an important factor affecting the quality. The traditional way of detecting lettuce storage time mostly depends on artificial experience, so it lacks accuracy and reliability. This study aims to provide a fuzzy recognition model for spectral analysis of lettuce to identify the storage time of lettuce compared with other discriminant methods. For this objective, sixty samples of fresh lettuce bought in the local supermarket were prepared and stored in a refrigerator for later detection. These samples were detected by near-infrared spectroscopy (NIR). Firstly, the Antaris II NIR spectrometer (the wave number range: 10 000~4 000 cm-1) was utilized to collect the near-infrared spectral data of lettuce samples every 12 hours, and every sample detection was repeated three times, taking the average value as experiment data. Secondly,NIR spectra were preprocessed with multiple scatter correction (MSC) for decreasing reductant information. PCA and PCA Sort were used to further clear the useless data of NIR spectra and simplify the following classification of data. PCA Sort was based on PCA with sorting principal components and could improve the classification accuracy and help the FLDA extract features effectively. In this step, only the first fifteen components of PCA and PCA Sort were used to compress NIR spectra. Finally, fuzzy linear discriminant analysis (FLDA) algorithm and k-nearest neighbor (KNN) were performed to classify the previous low-dimensional data. The classification accuracy of the model based on PCA coupled with KNN was 43%, and that based on PCA as well as FLDA and KNN was 83%. The classification results in experiments showed that the discriminant of the model based on PCA, FLDA and KNN was significantly improved. Replacing PCA in the model with PCA Sort, the recognition accuracy of this new model based on the algorithm PCA Sortcoupled with FLDA and KNN was better and achieved 98.33%, which was higher than other classification algorithms. The classification results in experiments showed that PCA Sort plus FLDA and KNN could build an efficient discrimination model for the identification of the storage time of lettuce.
目前, 冰箱可以用来保鲜生菜, 但随着贮藏时间的延长, 生菜中亚硝酸盐含量在不断增加而损害人体健康。 更重要的是, 长期贮存会导致其中的水和大多数营养物质的含量下降[1]。 例如, 董伟等人选取华南4种高叶酸含量作物作为实验材料, 实验表明, 因长期贮存平均叶酸损失达到23%。 因此, 确定食物的贮存时间具有重要意义[2]。 本工作以生菜为例, 探讨一种有效的蔬菜新鲜度检测方法。
传统的人工筛选是评估食物新鲜度最常见的方法。 有经验的人可通过观察食物的外部特征(比如颜色、 形状和味道)快速做出判断。 然而, 受一些内部和外部因素的影响, 人工筛选是主观的, 缺乏准确性。 因此, 研究人员通过多种方法进行实验以检测食品的质量和贮存时间。 高婷婷等[3]结合时间-温度指标(time-temperature indicators, TTIS), 借助一些常用的建模方法, 如测定反应速率常数(k)和活化能(Ea)以及Ea匹配来监测新鲜食品质量。 为了快速准确地评价罗非鱼鱼片的新鲜度, Han 等[4]利用电子舌结合线性和非线性多元算法检测鱼的新鲜度。
近红外光谱技术具有快速、 无损、 操作简单、 精度高、 成本低等优点。 目前, 环境分析、 食品工程[5, 6]、 食品新鲜度检测[7]等不同领域的许多研究人员都应用了近红外反射光谱(near infrared reflectance spectroscopy, NIRS)技术。
模糊线性判别分析(fuzzy linear discriminant analysis, FLDA)是一种有监督的特征提取和降维方法, 该算法也被广泛应用于分类及其他领域。 例如Guidea等[8]借助FLDA算法对矿泉水中的矿物成分进行分析分类, 有效区分了来自罗马尼亚和德国的矿泉水, 正确分类率达到88%。 Shen等[9]应用FLDA对白菜的中红外光谱进行特征提取, 并使用K-最近邻法(K-nearest neighbor, KNN)进行样本分类, 实现了无损检测白菜是否有λ -三氯氟氰菊酯农药残留。
K-最近邻法(KNN)是一种有监督的分类方法[10]。 Chen等[11]为快速无损地检测猪肉的储存时间, 分别使用线性判别分析(linear discriminant analysis, LDA)、 K-最近邻(KNN)、 反向传播人工神经网络(back propagation artificial neural network, BP-ANN)等算法建立了猪肉储存时间判别模型, 结果表明BP-ANN模型在训练集和预测集中的判别率分别为99.26%和96.21%。
在主成分分析算法(principal component analysis, PCA)的基础上, 采用新排序原则对特征向量进行重组的principal component analysis sort (PCA Sort)算法, 并建立生菜贮藏时间的判别模型。 首先, 利用Antatis Ⅱ 型近红外光谱仪采集生菜的近红外光谱数据, 并利用多元散射校正(multiple scatter correction, MSC)消除光散射的影响, 对预处理后的数据分别采用PCA, PCA+FLDA和PCA Sort+FLDA等方法进行分析。 最后利用KNN进行分类, 确定各组生菜的贮存时间, 计算并比较这三种方法的鉴别结果。
从镇江一家超市购买生菜。 为了减小误差, 实验材料应符合一定的标准。 所有的生菜样品(60个样品)保证是在同一时间(新鲜和成熟)采摘的, 大小、 颜色、 重量和叶子的完整性没有太大的差异。 用水清洗和晾干后, 生菜样品被放入有标签的塑料袋中, 并放入4 ℃保鲜柜中备用。
采用美国Thermo Antaris Ⅱ 型近红外光谱仪获取生菜的近红外反射光谱。 在整个实验过程中, 由于近红外光谱对外界环境敏感, 实验室保持温度在20~25 ℃, 空气相对湿度在50%~60%。
所有计算均在Windows 10的MATLABR2020a(Math Works, Natick, MA, USA)运行。
光谱仪需要提前开机预热1 h。 采用反射积分球模式采集样品的近红外光谱, 对每个样品扫描32次, 得到漫反射光谱的平均值。 光谱扫描的波数范围为10 000~4 000 cm-1, 扫描间隔为3.856 cm-1。 实验开始后, 每隔12 h取出生菜样品进行近红外光谱检测, 共检测三次, 取其平均值, 每个样品采集的近红外光谱为1557维数据。
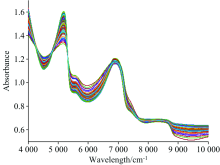
在生菜原始近红外光谱中, 受环境影响, 易发生噪声、 样本异质性、 基线漂移和偏移[12]。 多元散射校正(MSC)可有效消除不同散射水平引起的光谱差异。 故采用MSC对初始近红外光谱进行预处理。 图1为MSC预处理后的光谱图。
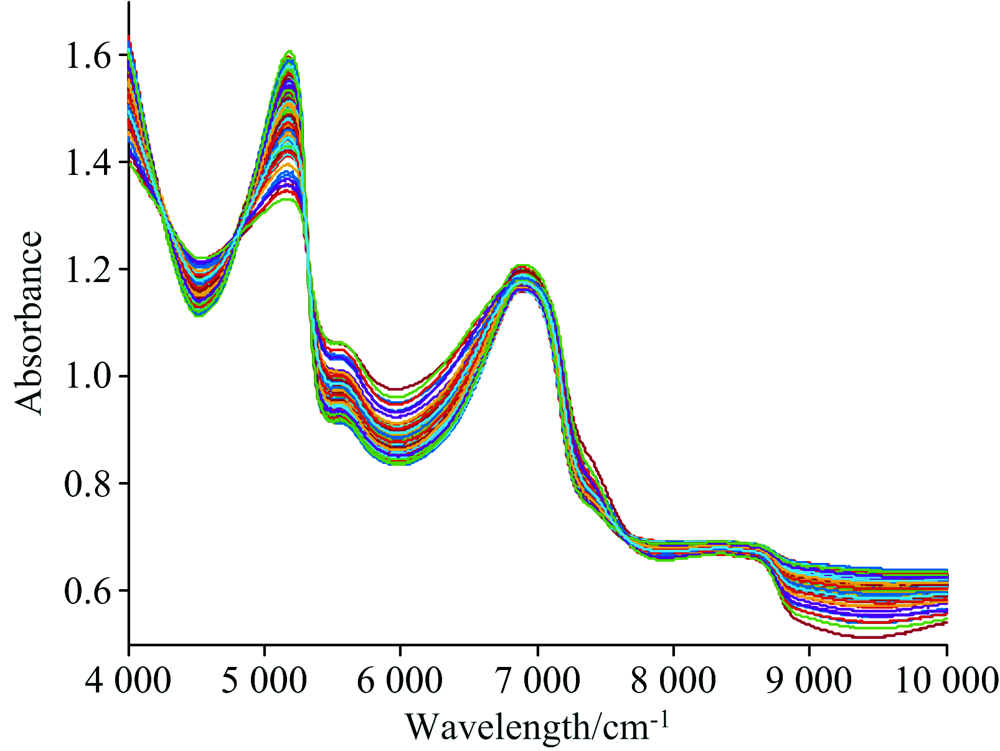 | 图1 MSC处理后的生菜样本近红外光谱Fig.1 NIR spectral data of lettuce samples treated by MSC |
采集的生菜样品近红外光谱有1557维, 属于高维数据, 同时光谱中含有大量无用信息和噪声数据, 增加了分析、 建模和计算的难度, 故需对近红外光谱进行降维以提取生菜近红外光谱的主要特征信息。 主成分分析(PCA)可对生菜近红外光谱数据进行降维, 同时较好地保留主要特征信息。 然而, PCA在降维过程中会丢失一些鉴别信息而导致分类准确率降低。 为提高分类的准确率, 对PCA算法进行了改进, 按照一定的规则改变其特征向量的顺序。 具体算法如下:
(1)设训练样本组成的矩阵为A, A∈ Rn× d(n为训练样本数, d为训练样本维数)。
(2) 用训练样本矩阵A组成协方差矩阵S
式(1)中, xk为第k个训练样本,
(3) 根据式Sv=λ v, 对矩阵S进行特征分解, 得到一组特征向量v1, v2, ..., vn, λ 和v分别是特征值和对应的特征向量。
(4) 计算类内散射矩阵Sw与类间散射矩阵Sb
式(2)中, c为样本总类别数; ni为第i类样本个数, i=1, 2, ..., c;
(5) 根据式(4)计算特征向量$v_{1}, v_{2}, \cdots, v_{n}$的J(vk)值, 并按J(vk)从大到小的规则将$v_{1}, v_{2}, \cdots, v_{n}\left(n=\sum_{i=1}^{c} n_{i}\right)$进行排序,得到一组新的特征向量$w=\left[w_{1}, w_{2}, \cdots, w_{n}\right]^{\mathrm{T}}$,其中$w_1$为式(4)最大值时对应的特征向量。
(6) 将第k个训练样本xk和测试样本yk根据式(5)和式(6)投影到特征向量w上, 其中zk是训练样本xk在特征向量w上的投影, tk是测试样本yk在特征向量w上的投影。
模糊线性判别分析(FLDA)用式(5)中训练样本zk的每类均值作为聚类中心, 计算出类内离散度矩阵Sfw和模糊类间离散度矩阵Sfb。 计算矩阵[Sfw]-1Sfb的特征值和特征向量及投影空间, 并将训练样本和测试样本投影到得到的特征向量上。 FLDA具体算法描述见文献[13], m为FLDA中的权重指数。
分别使用PCA和PCA Sort对生菜近红外光谱降维。 计算结果表明, 前15个主成分充分反映了生菜近红外光谱的大部分信息。 分别使用PCA和PCA Sort算法得到它们的前6~15个特征向量, 并用FLDA和KNN进一步处理, 得到各自的准确率如表1所示。 由表1可知PCA Sort的准确率要高于PCA, 当取m=2, K=3时, PCA Sort的准确率达到98.33%, 高于PCA算法(83.33%)。
| 表1 PCA和PCA Sort的前6~15个特征向量及其准确率 Table 1 The first 6~15 eigenvectors and accuracies of PCA and PCA Sort |
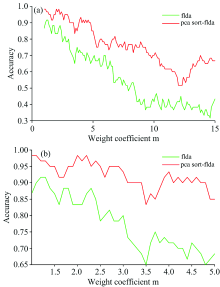
为确定恰当的权重系数m, 首先计算出m在1~15范围内取值时的准确率, 当m增加时, 总体准确率下降。 结果如图2(a)所示, 发现权重系数较小时, PCA+FLDA+KNN和PCA Sort+FLDA+KNN的分类结果相对准确。 因此, 将计算范围缩小到m为1~5, 寻找更为精确的m。 缩小范围[如图2(b)所示], 当权重系数取m=2时, 分类的准确率最高。
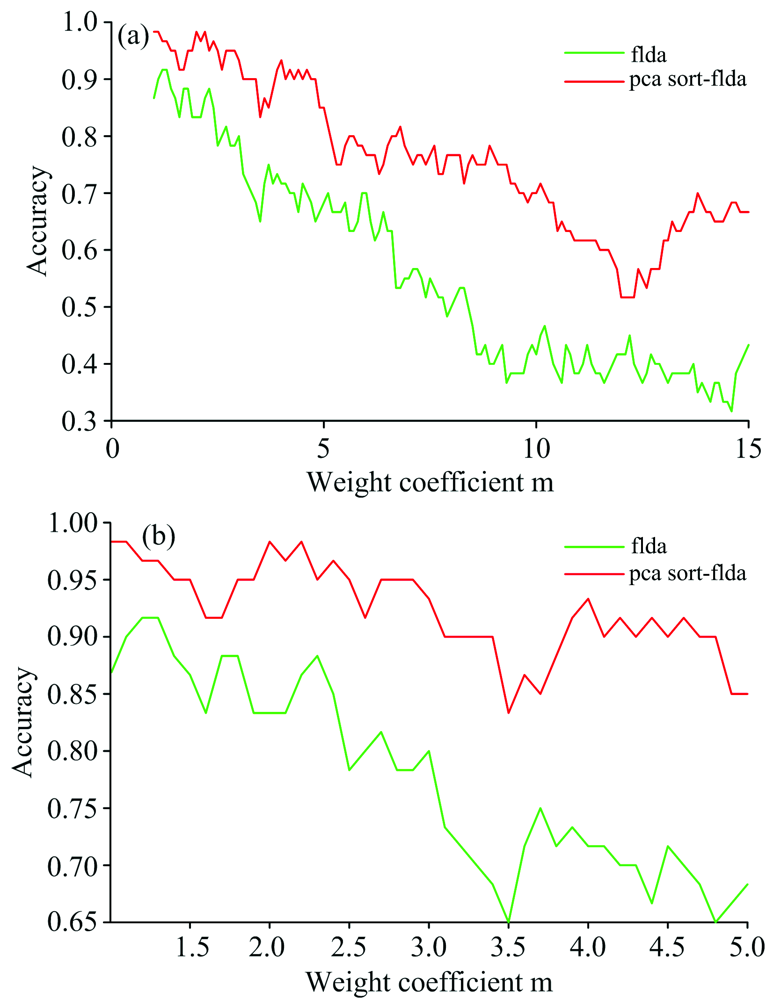 | 图2 改变权重系数时准确率的变化 (a): 权重系数m为1~15; (b): 权重系数m为1~5Fig.2 The accuracy changing with the weight coefficient (m) (a): m in the range of 1~15; (b): m in the range of 1~5 |
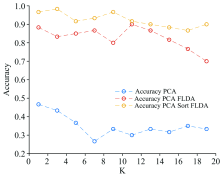
KNN参数K的取值也是影响分类结果的一个因素。 计算K取1~20内的奇数时对应的各项准确率, 结果如图3所示, 由此可知, K=3时PCASort+FLDA+KNN的分类准确率最高, 此时PCA+KNN及PCA+FLDA+KNN两种方法的分类准确率也近似最优结果, 故K取3。
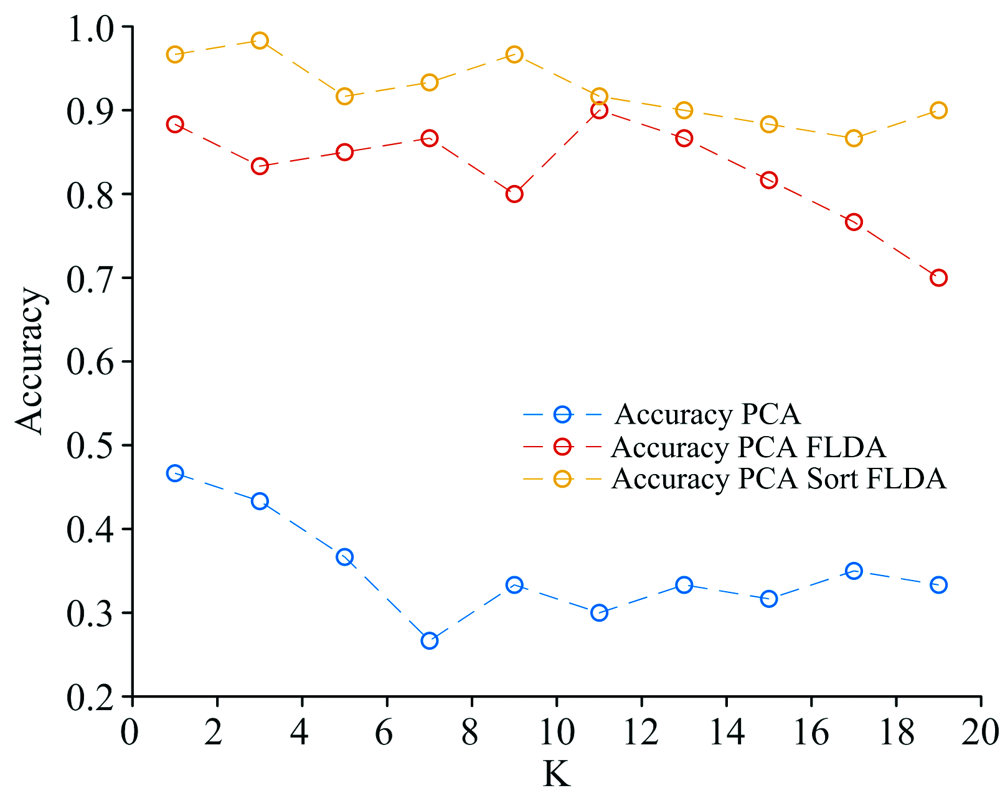 | 图3 K改变时分类准确率的变化Fig.3 The accuracy changing with the number of cluster center (K) |
三种方法的最高准确率如表2所示。 分析表2可以看出, 采用FLDA算法并结合PCA和KNN, 准确率近似为PCA和KNN算法的两倍, 达到83%。 而用PCA Sort代替PCA, 准确率则进一步提高, 达到98%。 因此, 使用PCA Sort, 并用FLDA进行特征提取, 再用KNN进行分类, 具有更好的优越性。
| 表2 三种方法的最高准确率 Table 2 The highest accuracy of three methods |
提出一种新的特征提取方法, 即PCA Sort+FLDA, 以降低数据的维数, 提取生菜近红外光谱的特征信息, 基于该方法及近红外光谱技术, 建立了一种比传统人工筛选方法具有更多优势的分类模型。 通过比较PCA+KNN, PCA+FLDA+KNN和PCA Sort+FLDA+KNN三种方法的分类准确率, 发现当使用PCA Sort得到新的特征向量空间, 并用FLDA进行特征提取, 可以提高KNN分类的准确率(达到最高的98%)。 综上所述, 近红外光谱结合PCA Sort, FLDA和KNN可大幅提高生菜贮藏时间的识别准确率, 也为其他食品贮藏时间的测定提供了可行的参考方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|