
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
大豆水分含量的高光谱无损检测及可视化研究
[金诚谦1, 2  , 郭榛
, 郭榛1 , 张静1 , 马成业1 , 唐小涵1 , 赵男1 , 印祥1 ]
, 郭榛|
|


作者简介: 金诚谦, 1973年生, 山东理工大学农业工程与食品科学学院教授, 农业农村部南京农业机械化研究所研究员e-mail: 412114402@qq.com
采用近红外高光谱成像技术对大豆水分含量进行快速无损检测, 实现大豆水分含量可视化。 采集了96个不同品种大豆样本在900~2 500 nm的高光谱图像, 采用直接干燥法测量每个大豆样品的水分含量。 利用系统自带的HSI Analyzer软件提取图像感兴趣区域(ROI)的平均光谱信息, 代表样品的光谱信息。 利用SPXY算法划分样品校正集和预测集, 并保留938~2 215 nm波段范围内的光谱数据。 采用移动平滑(moving average)、 S-G平滑、 基线校正(baseline)、 归一化(normalize)、 标准正态变量变换(standard normal variate, SNV)、 多元散射校正(multiple scattering correction, MSC)、 去趋势(detrending)共7种光谱预处理方法, 发现Normalize方法处理后的PLSR模型效果较好。 为了去除光谱冗余信息, 简化预测模型, 采用连续投影算法(SPA)、 竞争性自适应加权算法(CARS)、 无信息消除变量法(UVE)提取特征波长, 其中SPA, CARS和UVE三种算法优选出14, 16和29个波长, 分别占总波长的6.5%, 7.4%和13.4%。 分别对938~2 215 nm波段光谱和特征波长建立预测模型, 并将效果较优的模型与Normalize方法结合。 建立的14种预测模型效果相比较, 发现SPA算法筛选的特征波长建模预测效果较好, 并优选出Normalize-SPA-PCR模型, 模型的
NIR Hyperspectral imaging technology was used to detect soybean moisture content rapidly and non-destructively and realized the visualization of soybean moisture content. A total of 96 soybean samples of hyperspectral images in the region of 900~2 500 nm were acquired, and the moisture content of each soybean sample was measured by the direct drying method. The average spectral information of the region of interest(ROI)of the image was extracted by HSI Analyzer software, representing the sample's spectral information. The SPXY algorithm was used to divide the sample calibration set and prediction set, and the spectral data in the band range of 938 to 2 215 nm were retained. The spectral's pretreatment was analyzed, such as Moving Average, Smoothing S-G, Baseline, Normalize, Standard Normal Variate(SNV), Multiple Scattering Correction(MSC)and Detrending, and the PLSR model established after Normalize pretreatment had the best effect. The characteristic wavelengths were selected by successive projections algorithm(SPA), competitive adaptive reweighted sampling(CARS)and uninformative variable elimination(UVE). 14,16 and 29 characteristic wavelengths were selected by SPA, CARS and UVE, accounting for 6.5%, 7.4% and 13.4% of the total wavelengths. The prediction models were established for the spectra and characteristic wavelengths of 938~2 215 nm, and the model with better effect was combined with the Normalize method. Compared with the 14 prediction models established, it was found that the modeling and prediction effect of characteristic wavelengths selected by the SPA algorithm was good, and the Normalize-SPA-PCR model was optimized. The values of
大豆是我国重要的粮食作物和经济作物, 其品质检测一直是研究的焦点。 大豆籽粒种皮薄, 发芽孔大, 吸湿返潮后, 体积膨胀, 极易生霉, 含水量直接影响大豆的贮藏期。 因此入库时要严格控制水分, 长期贮藏水分不能超过12%。此外, 在育种过程中, 水分含量影响大豆种子活力, 控制和检测大豆水分含量是保证种子质量的重要环节[1]。 常用的水分检测方法有105 ℃恒重法、 真空干燥法、 定温定时烘干法和化学法等, 这些方法检测精度和准确度较高, 但其操作过程繁琐且费时, 破坏样品, 浪费优质种质资源, 不适用于大规模无损检测。
高光谱成像技术结合了光谱技术和成像技术的优点, 可以对多个目标同时进行无损检测, 实现物质成分含量可视化, 有着连续波段多、 光谱分辨率高、 “ 图谱合一” 的优点, 满足了快速无损检测的需求。 近年来广泛应用于茶叶病害侵染和水分含量等品质检测[2, 3, 4]、 鱼类和肉类品质指标的检测[5, 6]、 小麦籽粒蛋白质含量检测[7]等。 Nicola等[8]使用高光谱成像技术检测单粒咖啡豆水分和脂质含量, 并使水分和脂质含量分布可视化。 Xu等[9]采集单粒黄瓜种子在400~1 000和1 050~2 500 nm范围内的高光谱图像, 分别基于两个波段预测单粒黄瓜种子水分含量并进行可视化分析, 发现在1 000~2 500 nm范围内对水分含量预测效果较好。 Jennyfer等[10]在900~1 700 nm波段实现单粒花生仁的水分含量检测及可视化研究, 但只采用了加权回归系数法提取特征波长。 Wang等[11]采集单个玉米籽粒胚和胚乳两侧的高光谱图像, 建立的CARS-SPA-LS_SVM模型Rpre值为0.931 1, 表明高光谱成像技术可以快速无损检测玉米籽粒中的水分含量。 朱洁等[12]预测单粒小麦水分含量, 并将单粒小麦水分含量可视化。 相关研究表明, 高光谱成像技术可以实现作物种子水分含量检测及可视化, 目前未见高光谱成像技术检测大豆水分含量的相关报道。
本工作以96个品种的大豆为研究对象, 利用高光谱成像技术结合化学计量学方法建立并寻找最优预测模型, 在900~2 500 nm 范围检测大豆水分含量并进行可视化研究, 为大豆收获、 贮藏加工过程中水分含量检测提供新的方法。
试验所用的大豆来自黑龙江龙科种业公司、 辽宁东亚种业公司和临沂河东区试验农场等, 包括黑农84、 绥农88、 沈农8、 东豆1133、 中黄37、 徐豆20等96个不同品种。 每个品种取100g样品分别放置在培养皿中, 在实验室静置72h后采集高光谱图像, 随后按照GB 5009.3— 2016《食品安全国家标准食品中水分的测定》中的直接干燥法测量每个品种大豆样品的水分含量。 每个品种测量三次, 取平均值作为该品种大豆的水分含量。
光谱采集仪器为近红外高光谱成像系统(中国台湾五铃光学, HSI-eSWIR-900~2 500 nm), 101-0E型电热鼓风干燥箱。
近红外高光谱成像系统由900~2 500 nm线扫式近红外光谱仪(芬兰Specim, N25E-SWIR)、 900~2 500 nm CCD相机镜头(品牌: 芬兰Specim, OLES30)、 900~2 500 nm双分支卤素灯光源(中国台湾五铃光学, IRCP0078-1COMB)、 暗箱、 计算机等构成。
为了减小暗电流以及光源强度不均匀对高光谱图像的影响, 需要对高光谱图像进行黑白校正[13]。 将与样品等高且反射率为0.99的白板(芬兰Specim公司)置于样品采集区域, 采集的图像作为白板标定图像, 记为Iw; 盖上CCD相机镜头盖, 采集的图像作为黑板标定图像, 记为Id。 大豆高光谱图像黑白校正公式如式(1)所示
式(1)中, RT为校正后的样品图像, I为原始样品图像。
样本扫描时, 曝光时间为2.9 ms, 位移平台移动速度为15.34 mm· s-1, 焦距为30.7 mm, 相机分辨率为384× 288, 光源入射角度为45° 。
采用高光谱成像系统自带的HSI Analyzer光谱分析软件提取高光谱图像感兴趣区域(region of interest, ROI), 选取半径为200像素的圆形区域为ROI, 提取ROI平均光谱作为样本光谱信息。
采用SPXY(sample set partitioning based on joint X-Y distance)算法将样本按照3:1的比例划分为校正集和预测集[14]。 样本水分含量如表1所示, 校正集样品水分含量范围涵盖了预测集范围, 说明样本集划分合理。
| 表1 大豆样品水分含量 Table 1 Moisture content of soybean samples |
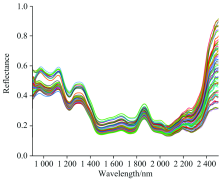
图1是大豆样品光谱反射率曲线, 1 210 nm附近明显的反射率波谷是有机物中C— H键的二级倍频振动带; 1 450 nm处反射率波谷与O— H键倍频振动有关, 1 940 nm表现O— H键的合频特性, 都是水分含量的特征谱带。 原始光谱包含背景信息和噪声, 在938 nm之前和2 215 nm之后的光谱数据无法提供有效的样本信息[15]。 故保留938~2 215 nm共216个光谱带作为建模数据, 带间距为5.6 nm。
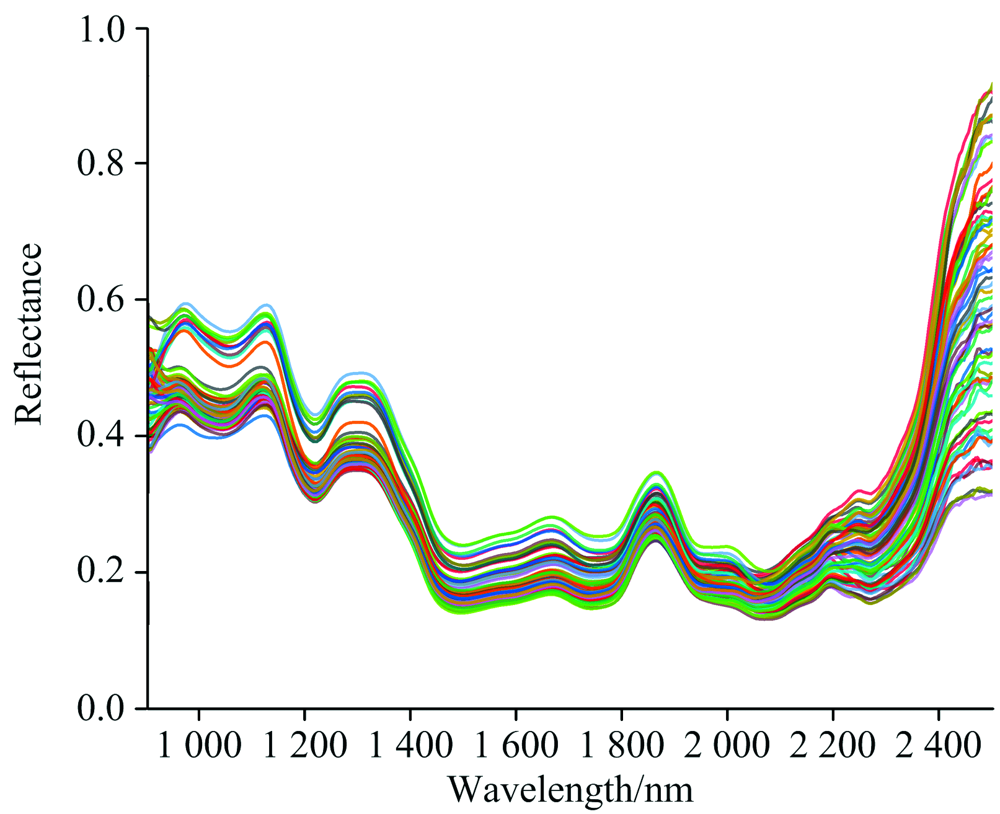 | 图1 光谱反射曲线Fig.1 Reflectance curves of spectrum |
为了减小无关信息和噪声对光谱数据的影响, 结合化学计量学方法对保留的光谱数据进行预处理。 PLSR模型综合考虑自变量和因变量之间影响关系, 能够在自变量存在严重的多重共线性条件下进行回归建模, 因此选择PLSR模型比较不同预处理方法效果[16]。 采用留一交互验证法计算交互验证集均方根误差RMSECV并做为模型评价指标。 由表2可知, 未经光谱预处理和7种预处理的PLSR大豆水分含量预测模型中, 未经光谱预处理预测模型的RMSECV值为0.373, Normalize方法处理后, 模型的RMSECV值较小, 为0.353, 且与未预处理相比
| 表2 不同预处理方法PLSR模型 Table 2 PLSR model based on different pretreatment methods |
保留的216个光谱带中仍然包含大量冗余信息, 为了提高建模速度和模型鲁棒性, 需要对光谱数据进行压缩, 提取特征波长[17]。 应用连续投影算法[18](successive projections algorithm, SPA)、 竞争性自适应加权算法[19](competitive adaptive reweighted sampling, CARS)、 无信息消除变量法(uniformative variable elimination, UVE)分别提取特征波长。
2.3.1 连续投影算法(SPA)
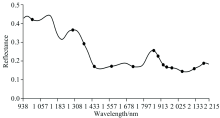
SPA筛选出14个特征波长, 占总波长的6.5%, 这14个波长分别为1 001, 1 296, 1 377, 1 452, 1 575, 1 726, 1 867, 1 896, 1 930, 1 952, 1 986, 2 052, 2 127和2 185 nm。 图2为SPA筛选出的14个波长。
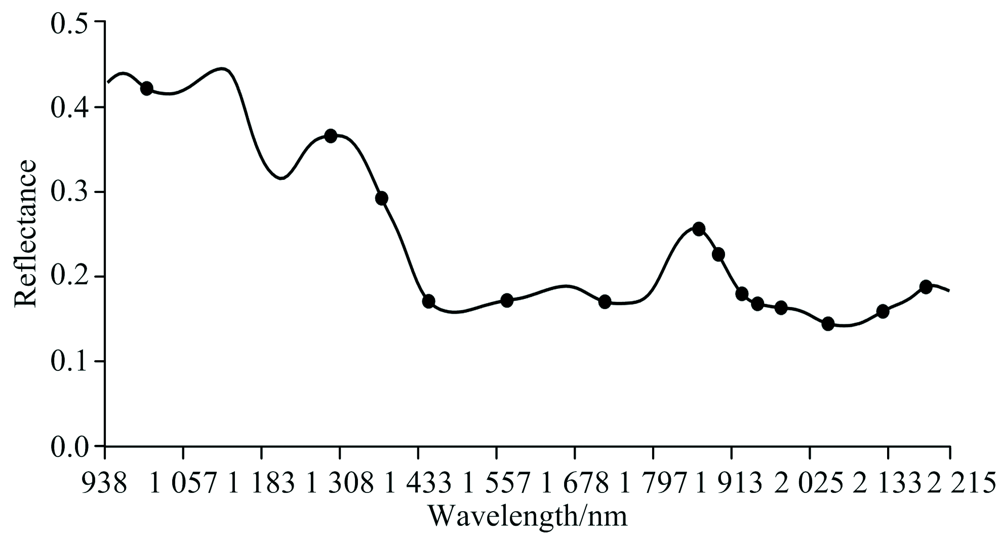 | 图2 SPA筛选特征波长Fig.2 Selected characteristic wavelengths by SPA |
2.3.2 竞争性自适应加权算法(CARS)
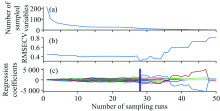
图3(a)显示随着采样次数增加, CARS筛选得到的变量数逐渐减少, 且变量数变化的趋势为迅速减小到趋于平缓; 图3(b)显示筛选过程中交互验证错误率的变化趋势: 交互验证错误率平稳下降到最低点后曲折上升, 并在采样次数为28次时, 交互验证的RMSECV值最小, 模型的稳定性最好; 图3(c)为各变量在采样过程中回归系数的变化路径。 经CARS筛选得到16个特征波长, 分别为: 1 308, 1 358, 1 390, 1 483, 1 672, 1 678, 1 962, 1 779, 1 832, 1 861, 1 941, 2 019, 2 025, 2 122, 2 133和2 138 nm, 占总波长的7.4%。
 | 图3 CARS筛选过程 (a): 变量个数随样本个数的变化趋势; (b): 均方根误差; (c): 各变量回归系数随采样次数的变化(蓝色线表示RMSECV最低的位置)Fig.3 Selection process of CARS variables (a): Variation trend of the number of variables with the number of samples; (b): RMSECV; (c): The change process of regression coefficient of each variable with sampling times (The blue line represents the position with the lowest RMSECV) |
2.3.3 无信息消除变量法(UVE)
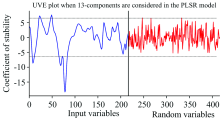
UVE筛选特征波长, 当潜在变量设为13时, PLSR模型的RMSECV值最小, 为0.327。 图4中, 竖虚线左右分别有216个波长变量, 左侧为216个输入变量稳定性C分布曲线, 右侧为UVE产生的216个随机变量稳定性C分布曲线; 两条水平虚线为变量选择阈值的上下限, 虚线外对应变量为筛选出的29个特征波长: 976, 982, 988, 994, 1 001, 1 096, 1 076, 1 082, 1 089, 1 227, 1 233, 1 239, 1 246, 1 346, 1 352, 1 358, 1 365, 1 371, 1 377, 1 396, 1 402, 1 408, 1 415, 1 421, 1 427, 1 433, 1 439, 1 446和1 452 nm, 占总波长的13.4%。
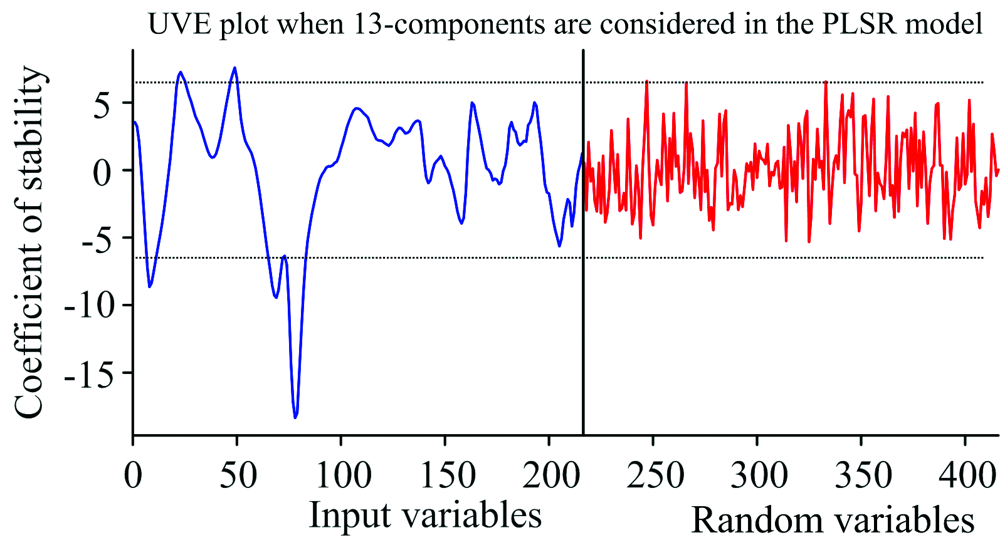 | 图4 UVE-PLSR模型的稳定性分布曲线Fig.4 Stability distribution curve of UVE-PLSR modle |
对938~2 215 nm波段光谱建立PLSR, PCP和SVMR模型。 将预测集均方根误差RMSEP值作为评价模型预测效果的指标, RMSEP值越低说明预测效果越好。 其中, PCR模型RMSEP和RMSECV值较低, 说明基于938~2 215 nm波段光谱建立的PCR模型预测效果和稳定性较好。
为了提高建模速度和模型鲁棒性。 分别对SPA, CARS和UVE三种算法筛选出来的14, 16和29个特征波长建立PLSR, PCR和SVMR模型。 如表3所示, SPA算法筛选出的特征波长建立的PLSR, PCR和SVMR模型较938~2 215 nm波段光谱建立的三种模型, RMSEP值均有所降低, 而CARS和UVE算法对模型预测效果提升并不明显甚至会降低预测效果, 但也有效降低了光谱维度。 基于特征波长建立的模型中, SPA-PLSR和SPA-PCR模型RMSEP值较低, 均为0.262, 说明SPA算法筛选的特征波长建模预测效果较好, 这可能是由于SPA算法能有效降低光谱共线性。
| 表3 基于不同预处理方法及特征波长筛选方法建立的模型效果 Table 3 Performance of models based on different pretreatment methods and characteristic wavelengths selecting methods |
将Normalize方法与SPA-PLSR和SPA-PCR模型结合, 发现模型的RMSEP值降低, 经预处理后模型的预测效果进一步提升。 两种模型相比较, RMSEP值相同, 但Normalize-SPA-PCR模型的RMSECV值较低, 说明Normalize-SPA-PCR模型比Normalize-SPA-PLSR模型更稳定。 将Normalize-SPA-PCR模型更适合用于大豆水分含量可视化预测。
在大豆收获和加工储藏过程中无法用肉眼直接判断水分含量, 而利用预测模型可以计算出高光谱图像上的每一个像素点的水分含量预测值, 得到灰度图像, 然后对灰度图像进行伪彩色变换, 得到大豆水分含量可视化图。
图5是Normalize-SPA-PCR模型预测得到的大豆水分含量可视化图, 颜色梯度条由下向上代表大豆水分含量由低变高, 范围为0~12%。 图5为从预测集挑选的4个品种大豆水分含量可视化图, 4个大豆品种按照平均水分含量高低进行排列, 其中, (a)为华豆2号的水分含量可视化图, 水分含量为10.40%; (b)为垦豆40的水分含量可视化图, 水分含量为9.39%; (c)为皖豆701的水分含量可视化图, 水分含量为7.13%; (d)为皖豆34的水分含量可视化图, 水分含量为6.46%。 由图5可知, 不同品种大豆对应的水分含量可视化图颜色不同, 4幅图像颜色差异十分明显; 同一图像内不同大豆的颜色也有差异, 但颜色差异较小。 对预测集24个品种的大豆高光谱图像进行可视化处理, 结果表明大豆水分含量不同对应图像颜色不同, 水分含量变化对应图像颜色变化较为明显, 通过图像颜色变化可以判断大豆水分含量范围。
 | 图5 大豆水分含量可视化图 (a): 华豆2号; (b): 垦豆40; (c): 皖豆701; (d): 皖豆34Fig.5 Visualization of soybean moisture content (a): Huadou 2; (b): Kendou 40; (c): Wandou 701; (d): Wandou 34 |
实验表明高光谱成像技术可以有效实现大豆水分含量可视化检测, 与传统的水分测量方法相比, 有着无损、 快捷、 准确的优点, 并且可以得到大豆水分含量可视化图, 为大豆的收获、 储藏和加工提供了技术支持。
(1)使用7种预处理方法对938~2 215 nm波段光谱数据建立PLSR模型, 发现经Normalize处理后模型的
(2)采用SPA, CARS和UVE三种方法提取特征波长特征波长个数分别为14, 16和29个, 占光谱数据的6.5%, 7.4%和13.4%, 有效的降低了光谱维度。
(3)将预处理方法和特征波长提取方法与建模方法相结合, 比较14种模型效果, 优选出Normalize-SPA-PCR模型, 并用于大豆水分含量可视化预测。 Normalize-SPA-PCR模型的
(4)对预测集24个高光谱图像进行可视化处理, 不同水分含量大豆的可视化图像颜色不同, 水分含量变化对应的颜色变化也较为明显, 通过图像颜色变化判断大豆水分含量范围。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|