


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
改进BP神经网络算法对煤矿水源的分类研究
[闫鹏程1, 2  , 尚松行
, 尚松行2, * , 张超银2 , 张孝飞2 ]
, 尚松行, 张超银|
|


作者简介: 闫鹏程, 1988年生, 安徽理工大学电气与信息工程学院讲师 e-mail: pcyan1988@126.com
煤矿安全对煤炭工业的健康持续发展至关重要, 而煤矿水灾又是煤矿事故的重大隐患, 因此煤矿水源数据的处理对于预防矿井突水事故具有重要意义。 实验在激光器的辅助下利用激光诱导荧光技术获取7种水源的数据信息, 设定激光发射功率为100 mW, 向被测水体发射波长405 nm激光, 获取实验水样210组的荧光光谱数据, 为了剔除光谱在采集过程受到的荧光背景、 检测器噪声以及功率波动等影响, 利用SG平滑、 多元散射矫正(MSC)预处理对数据进行降噪以及提高光谱特异性, 由于初始数据运算量过大并对数据压缩、 消除冗余和数据噪音, 利用主成分分析(PCA)分别对7种水样进行建模降维处理, 从而得到小数据并且保持原有信息的数据特征。 为了识别煤矿水源的突水类型, 对于降维后的数据利用粒子群算法(PSO)优化BP神经网络, PSO算法通过对新粒子的适应度值和个体极值、 群体极值适应度值的比较更新个体极值和群体极值的位置, 将最优初始权值和阈值赋予BP神经网络, 从而对待测水样的种类进行预测分析。 普通的PSO优化BP神经网络, 容易出现早熟收敛, 故在改进的PSO算法中引入变异因子来提高模型寻找更优解的可能性。 实验证明: SG, MSC以及Original三种预处理方式中, SG算法表现良好, 提高了模型的相关性。 在SG预处理的前提下, BP的决定系数 R2为0.984 5, 平均相对误差MRE 7.39%, 均方根误差为7.25%; PSO-BP的决定系数 R2为0.999 8, 平均相对误差MRE 0.17%, 均方根误差 0.08%; IPSO-BP的决定系数 R2达到0.999 9, 平均相对误差MRE和均方根误差RMSE皆为0.01%。 结果表明: 经SG预处理过后的光谱数据, 比MSC预处理效果更精确, 改进的粒子群优化算法更适用于该实验的矿井水源分类。
Coal mine safety is very important to the healthy and sustainable development of the coal industry, and the coal mine flood is a major hidden danger of coal mine accidents. Therefore, coal mine water source data processing is of great significance to prevent mine water inrush accidents. In this experiment, the laser-induced fluorescence technology was used to obtain the data information of 7 water sources. The laser power was set at 100 mW, 405 nm laser was emitted to the measured water, and 210 groups of fluorescence spectrum data of experimental water samples were obtained. n order to eliminate the influence of fluorescence background, detector noise and power fluctuation, SG smoothing and multiplicative scatter correction (MSC) preprocessing is used to reduce the noise and improve the spectral specificity of the data. Due to a large amount of initial data operation, data compression, redundancy elimination and data noise elimination, principal components analysis (PCA) is used to analyze the seven water samples Row modeling and dimensionality reduction are used to obtain small data and keep the original data characteristics. In order to identify the water inrush type of coal mine water source, particle swarm optimization (PSO) is used to optimize BP neural network for dimension reduced data. PSO algorithm updates the position of individual extremum and population extremum by comparing the fitness value of new particle with that of individual extremum and population extremum, PSO algorithm updates the position of individual extremum and population extremum by comparing the fitness value of new particle with that of individual extremum and population extremum, and endows the optimal initial weight and threshold value to BP neural network, so as to predict and analyze the types of water samples to be measured. The common PSO optimized BP neural network is prone to premature convergence, so mutation factor is introduced into the improved PSO algorithm to improve the possibility of finding a better solution. Experimental results show that the SG algorithm performs well among SG, MSC, and original preprocessing methods and improves the correlation of models. On the premise of SG pretreatment, the determination coefficient R2 of BP is 0.984 5, the mean relative error MRE is 7.39%, and the root mean square error is 7.25%; the determination coefficient R2 of PSO-BP is 0.999 8, the mean relative error MRE is 0.17%, the root mean square error is 0.08%; the determination coefficient R2 of IPSO-BP is 0.999 9, the MRE and RMSE are 0.01%. The results show that the spectral data preprocessed by SG is more accurate than that by MSC, and the improved particle swarm optimization algorithm is more suitable for mine water source classification in this experiment.
煤矿在生产建设中会遇到各种安全问题[1, 2], 根据国家煤矿安全监察局事故查询系统公布的煤矿安全数据, 仅2020年上半年全国煤矿企业共发生事故48起, 死亡74人。 减少矿井事故的发生对人民的生命安全和国家的生产建设具有极其重要的意义[3]。 矿井事故主要有瓦斯事故、 顶板事故、 机电事故、 放炮事故、 水灾事故、 火灾事故、 运输事故以及其他事故[4, 5, 6], 其中尤以矿井水害事故最为严重。 矿井水害事故一般发生在采煤工作面, 当采煤工作面遇到地下暗河或者富水性强的含水层等, 就会出现水源的大规模涌出, 进入采煤巷道[7, 8], 而一旦发生矿井突水事故, 轻则淹没采煤工作面, 摧毁煤矿开采工具, 重则导致矿井损毁, 造成人员财产的重大损失。
传统对于煤矿水源种类的判别主要是利用水化学的方法[9, 10, 11], 利用水源中各种离子浓度的不同对水源进行分类, 比如代表离子法就是利用水源中7种元素的离子浓度, 通过对比已分类的含水层水质来辨识水源类型[12, 13, 14]。 但是由于水化学方法实验的特殊性, 操作复杂且数据不稳定, 因而提出一种利用激光诱导荧光的方法获取水源的荧光光谱, 再通过IPSO算法(改进的粒子群优化算法)优化BP神经网络模型来预测分类煤矿水源类型。
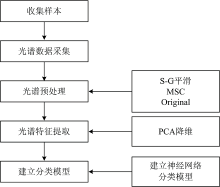
实验以对矿井水源分类为目的, 首先收集样本并获取光谱数据, 对繁杂的数据进行PCA降维等预处理, 提取处理后数据的光谱特征并进行神经网络的建模分类。 具体过程如图1所示。
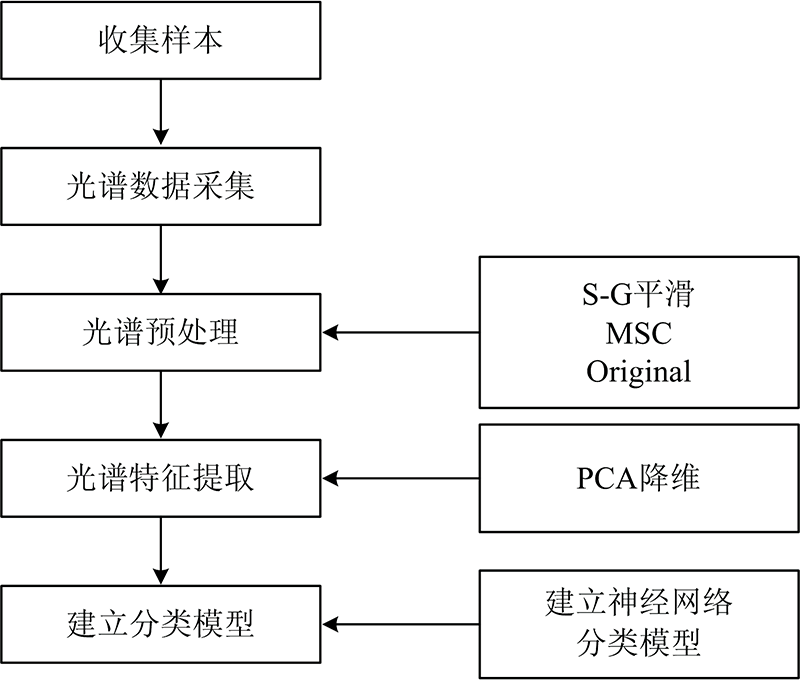 | 图1 矿井水源预测分类模型流程图Fig.1 Flow chart of mine water source prediction and classification model |
由于煤矿水害水源类型多为老空水, 实验选择新庄孜煤矿采集到的岩溶水与老空水以及按两者按不同比例混合作为实验样本, 混合比例分别为10:3, 10:6, 10:10, 6:10, 3:10, 每种样本取30份, 共计210个样本, 皆避光存储。
待测样本经405 nm入射光激发光谱, 设定激光功率100 mW, 积分时间设定为1/1 000 nm, 采用浸入式荧光探头(广州标旗光电FPB-405-V3), 直接将其放入待测水体获取待测光谱信息, 光谱采集与接收是由OceanView软件记录, 整个实验过程均在暗室中进行。
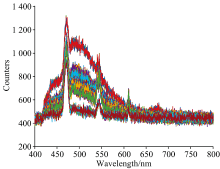
OceanView软件收集的样本原始光谱图如图2所示。 光波长检测范围是400~800 nm, 光谱的变化范围主要集中在光波长为400~700和700~800 nm之间光谱强度趋于稳定。
 | 图2 原始光谱图Fig.2 Original spectrum |
由于原始荧光光谱受到仪器噪声以及功率波动等因素的影响, 采集的干扰信息会影响实验结果的准确度, 因此采用预处理对光谱数据进行定量定性分析。 采用多元散射矫正(MSC)和SG平滑对原始光谱数据进行预处理, 可以有效减少光谱噪声, 提高光谱的分辨能力, 增强模型的分类性能。
(1) SG平滑算法
由于是利用激光激发待测水源的荧光光谱信息, 而光谱的噪声属于白噪声, 可以利用SG平滑算法经过多次测量光谱信息数据求平均值来降低其自身所携带的随机误差、 提高光谱的信噪比, 经过平滑之后可以有效地减少光谱噪声对实验数据的影响。
(2)多元散射矫正MSC
多元散射矫正的目的是消除由于光程变化或者待测物质分布不均匀而对红外光漫反射光谱的影响。 MSC算法主要是通过一组实验样本的光谱信息, 基于统计的方法来修正光谱因为散射所带来的线性变化, 消除样本间的基线平移和漂移现象, 增强光谱特异性。
对实验采集的原始光谱作MSC预处理: 首先选取平均光谱作为标准光谱; 用原始光谱和标准光谱进行一元线性回归, 得出截距bi和系数ki; 然后对每个样本进行校正见式(1)—式(3)。
各预处理图像如图3(a, b, c)所示。
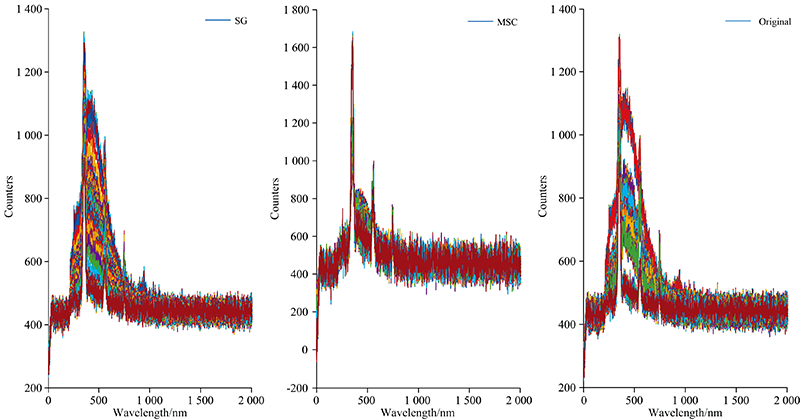 | 图3 原始光谱图及预处理后的图像 (a): SG; (b): MSC; (c): Original预处理Fig.3 Original spectrogram and preprocessed image (a): SG; (b): MSC; (c): Original preprocessed |
对所选取的210个样本进行PCA降维, 主成分数取7, 其主成分贡献率如图4所示。 仅7种主成分的累计贡献率就达到了95%。
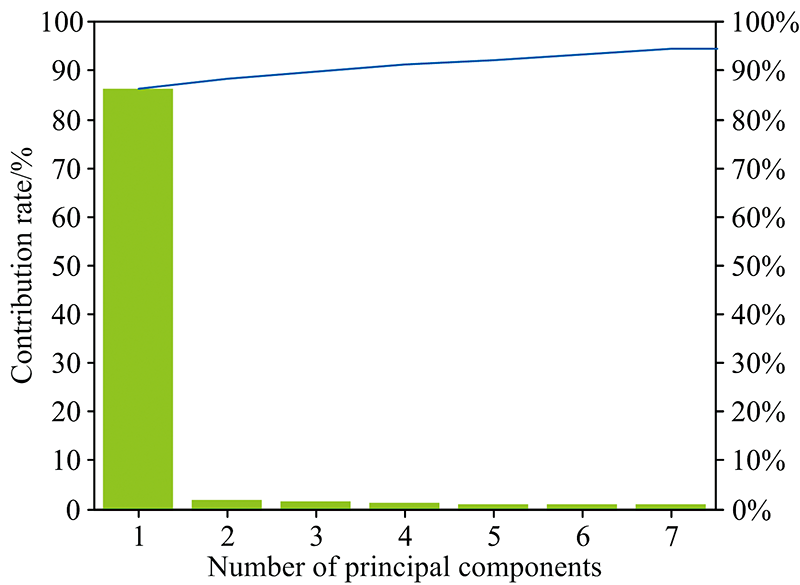 | 图4 主成分累积贡献率Fig.4 Cumulative contribution rate of principal components |
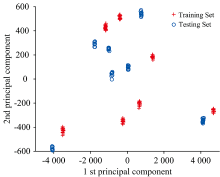
在第一主成分与第二主成分作对比时, 水样的聚类效果明显, 并且模型的决定系数达到0.9, 如图5所示。
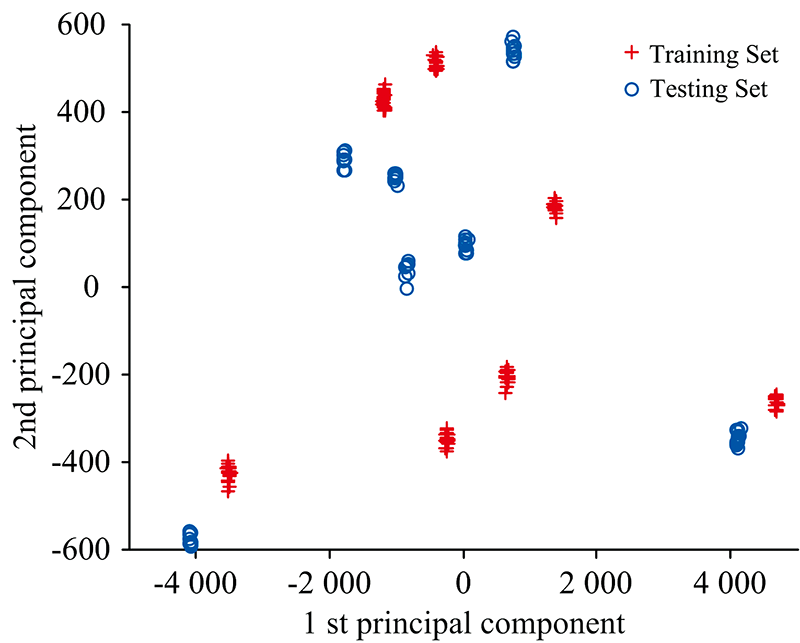 | 图5 得分分布图Fig.5 Score distribution |
1.5.1 BP神经网络参数选取
BP神经网络隐含层节点数m的计算公式如下
式(4)—式(6)中, h为隐含层节点数, m为输出层节点数, n为输入层节点数, a=1, 2, …, 10是隐含层之间的调节常数。
a取值的不同会影响神经网络的训练误差, 在隐含层神经元个数可以随意调整的前提下, 将隐含层神经元个数分别设为5~15, 创建神经网络模型并进行网络训练, 得出不同隐含层节点的训练误差, 如表1所示。 在经过训练后, 隐含层节点数为13时, 训练误差最小, 因此在本次矿井水源分类BP神经网络预测实验中隐含层神经元个数为13。
| 表1 不同隐含层神经元个数的训练误差 Table 1 Training error of neuron number in different hidden layers |
1.5.2 PSO算法优化模型
PSO算法即粒子群优化算法, 是一种源于对鸟类捕食的研究并用于求解优化问题的优化算法。 PSO算法用位置、 速度和适应度值表示该粒子特征, 通过追踪个体极值Pbest和群体极值Gbest来确定最优位置。
假设有一个D维的目标搜索空间, 有n个粒子组成的种群Z=(X1, X2, …, Xn), 种群Z中有某一i个粒子可以表示为一个D维向量Xi=[xi1, xi2, …, xiD]T, 代表某一问题在D维空间的一个潜在的解向量, 根据目标函数确定每个Xi粒子位置对应的适应度值。 第i个粒子的速度为Vi=[Vi1, Vi2, …, ViD]T, 个体极值为Pi=[Pi1, Pi2, …, PiD]T, 种群的群体极值为Pg=[Pg1, Pg2, …, PgD]T。
在迭代过程中, 粒子的速度和位置的更新通过式(7)和式(8)得到
式中w为惯性权重; d=1, 2, …, D; i=1, 2, …, n; k为当前迭代次数; Vid是粒子速度; c1和c2是加速常数; r1和r2是[0, 1]之间的随机数。
1.5.3 建立PSO-BP预测模型
PSO-BP预测模型的基本步骤主要包括:
(1) BP神经网络选择单隐含层网络拓扑结构, 矿井水源种类的影响因素作为网络输入, 水源种类为网络输出, 根据调节常数a确定最优隐含层节点数。
(2) 对PSO算法粒子和速度进行初始化处理, 确定粒子种群n, 粒子速度v以及种群的维度D。
(3) 将降维以及预处理后的数据集划分为训练集和测试集, 导入PSO-BP预测模型。
(4) 运行PSO-BP模型, 根据适应度函数计算粒子适应度值, 通过追踪个体Pbest和群体极值Gbest更新个体位置, 设置收敛精度, 使Gbest不断逼近此精度。
(5) 将在收敛精度范围内的Gbest赋值给BP神经网络作为网络的权值和阈值。
(6) 根据训练组训练的神经网络, 并以此作为标准对测试集进行预测处理并检验结果。
1.5.4 IPSO-BP模型的建立
PSO-BP算法模型的优点是具有快速的收敛性和很强的通用性, 但正是由于这一优点容易存在早熟收敛、 搜索精度偏低、 迭代效率不高等缺点, 为了使算法跳出局部最优, 本实验改进了PSO-BP算法模型, 联想到遗传算法的变异思想, 改进的PSO-BP算法在种群更新和优化选择的基础上引入了自适应变异操作, 在普通PSO-BP算法中粒子每次更新之后添加变异算子, 对某些变量以一定概率进行初始化处理, 使粒子可以跳出先前的最优值位置, 在更大空间内开展搜索, 提高算法寻找到更优值的可能性。
实验中7种比例的水样样本, 分别编号1—7, 每种样本包含30组实验数据, 将每种样本的前20组数据作为训练集进行模型演算, 后10组数据作为测试集, 共计140组训练数据, 70组测试数据。 在经过MSC与SG预处理算法后, 经PCA进行降维, 将降维之后的数据代入各预测模型中并进行预测值和真实值作比较, 如图6所示, 决定系数最小的是采用MSC预处理的PSO-BP预测模型, 最大的是采用SG预处理的IPSO-BP预测模型, 其决定系数无限接近1。
 | 图6 九种不同预处理方法下的各预测模型真实值与预测值对比Fig.6 Comparison between the real value and the predicted value of each prediction model under nine different pretreatment methods |
根据表2的各分类模型的评价指标对比可知, 在BP神经网络中, 三种预处理均表现出大体上进行分类, 但是具体分类出现较大偏差; PSO-BP分类模型中, 三种预处理预测性能较好, MSC预处理在60-70号样本中发生错判, 而SG预处理在对每组样本的最后一个样本分类时会发生较小差值, Original预处理在20—30号样本之中会发生明显错判; IPSO-BP预测模型中, MSC预处理在第69号样本预测分类时发生较大错判; SG预处理分类结果与真实值完全相符, 表现良好; Original预处理方式下, 在20—60的每组的最后一个样本发生错判现象。 因此在三种预处理方式下的BP, PSO-BP以及IPSO-BP预测分类模型中, SG-IPSO-BP分类性能良好。
| 表2 不同预处理方法下的各预测模型评价指标对比 Table 2 Comparison of evaluation indexes of each prediction model under different pretreatment methods |
预测效果最佳的是SG-IPSO-BP算法预测分类模型, 其平均相对误差MRE和均方根误差RMSE皆是0.01%, 预测错误率无限接近于0。 实验中9种预测模型效果最差的是SG-BP模型, 其决定系数为0.984 5, 平均相对误差MRE为7.39%, 与同种预处理方式下的IPSO-BP相差7.38%, 均方根误差RMSE为7.25%, 二者相差7.24%。 BP神经网络模型经过SG, MSC和Original三种预处理, 其中经过Original处理过后效果最好; 在PSO-BP预测模型种经过SG预处理算法预测效果最佳。
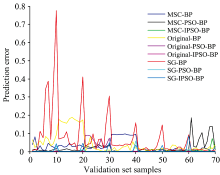
如图7所示为BP, PSO-BP, IPSO-BP分别对经MSC, SG和Original预处理之后数据做出的预测值和真实值的绝对误差图, 误差幅度的剧烈变化主要集中在0—20之间的样本, 也就是编号为1和2的样本预测误差变化幅度较大, 其中SG-BP的误差幅度远远大于其他几种预测分类模型, 该模型的绝对误差最大值为0.775 1, 最小值为0.001; 绝对误差最小的模型为SG-IPSO-BP预测模型, 预测的绝对误差最大值为0.084 7, 最小值是0误差。
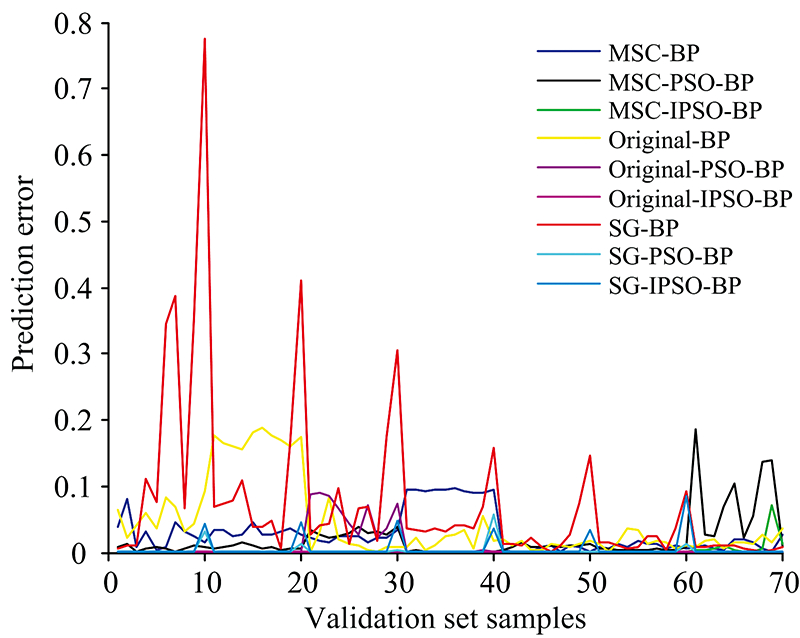 | 图7 各模型预测值与真实值的绝对误差图Fig.7 Absolute error diagram of predicted value and true value of each model |
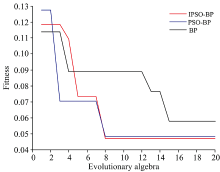
三种分类模型的适应度曲线如图8所示, 最终得到的最优个体适应度值为IPSO-BP的0.047 0要优于PSO-BP以及BP预测分类模型。
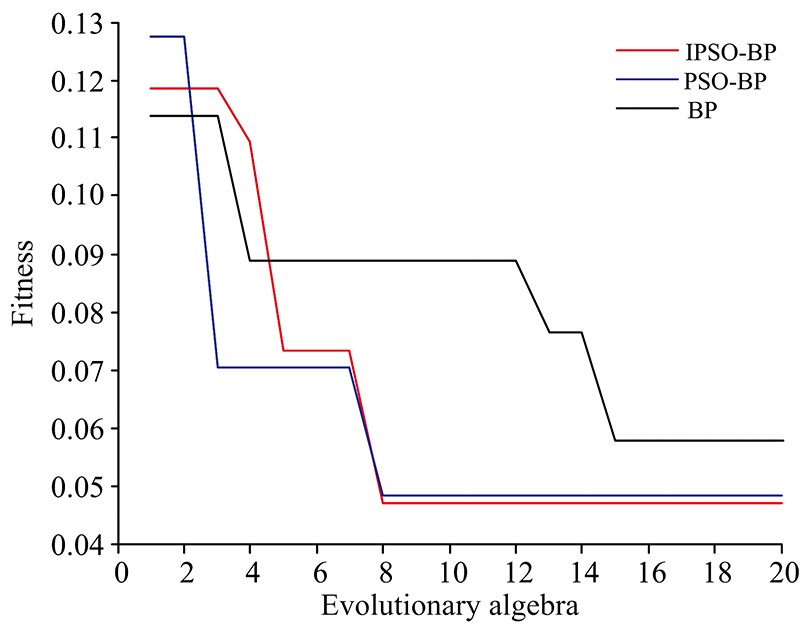 | 图8 适应度曲线Fig.8 Fitness curves |
综上所述, 从预测值和实际值的对比图以及各模型误差结果分析的可以看出SG-BP神经网络的预测分类能力最差, SG-IPSO-BP的预测值与真实值完全相符, 分类性能较好, 对水源种类的预测分类模型中, IPSO-BP要优于PSO-BP与BP神经网络, 而PSO-BP的神经网络预测模型要优于BP神经网络。
对于BP, PSO-BP和IPSO-BP算法预测分类模型在SG, MSC以及Original三种预处理方式中, SG被选为最适宜对7种水样进行预处理的算法, 结合PCA降维, 对比同种预处理方式下的不同分类预测模型发现SG-IPSO-BP分类性能最佳。 在本次实验中, SG预处理可以很好的提高光谱的平滑性, 并降低噪声的干扰; 经过PCA降维, 去除冗余信息, 减少计算量; 在PSO算法模型的基础上提出一种变异因子的改进算法, 增加了模型寻找最优解的可能性, 对水源在激光诱导荧光的实验环境下提供了一种新的分类方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|