

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱和集成学习的黑枸杞快速分级方法
[卢伟1  , 蔡苗苗
, 蔡苗苗1 , 张强2 , 李珊3 ]
, 蔡苗苗|
|


作者简介: 卢 伟, 1978年生, 南京农业大学副教授 e-mail: njaurobot@njau.edu.cn
黑枸杞具有较高的营养和医学价值, 不同等级的黑枸杞质量不同, 价格也具有显著差异, 但由于缺乏有效的检测分级手段, 造成黑枸杞市场鱼龙混杂、 以次充好, 影响黑枸杞市场质量监管。 为实现黑枸杞快速、 无损、 高精度分级检测, 提出基于高光谱和集成学习的黑枸杞快速无损分级方法。 首先, 选取诺木洪1级(NMH-grade1)、 诺木洪2级(NMH-grade2)、 诺木洪3级(NMH-grade3)、 诺木洪4级(NMH-grade4)黑枸杞各200颗, 在两种放置模式下(果柄朝上、 去柄后整体横放), 通过GaiaSorter-Dual宽波段高光谱分选仪得到光谱范围为391.6~2 528.1 nm的光谱图像立方体。 掩模处理后结合细胞计数算法实现单颗黑枸杞ROI高光谱信息的自动提取。 考虑噪声的影响, 截取500~2 400 nm范围内的黑枸杞光谱信息。 经过FD(first derivative), FFT(fast Fourier transform)、 HT(hilbert transform), SG(savitzky golay), Normalize, SNV(standard normal variate)预处理后, 再通过PCA(principal components analysis), SPA(successie projection algorithm), CARS(competitive adaptive reweighted sampling)提取特征波长的光谱信息。 然后分别建立LIBSVM, LDA(latent dirichlet allocation), KNN(k-nearest neighbor), RF(random forest), NB(naive Bayes)检测模型, 其中, 果肉-Normalize-SPA-LDA、 果肉-FD-CARS-RF和果肉-SNV-CARS-LIBSVM组合方式最优, 准确率分别为0.941 7, 0.941 7和0.937 5。 在预处理方法中, FD, HT, Normalize和SNV效果较好; 在降维方法中, SPA和CARS的模型效果较好; 在LIBSVM, LDA, KNN, RF和NB所建立的模型中, 测试集精度不低于0.9的个数分别为2, 7, 0, 4和1, 因此LDA, RF和LIBSVM三个分类器效果最好。 为进一步提高黑枸杞的分级精度, 以LDA, RF, LIBSVM三个最优分类器为元模型, 通过Stacking集成学习建立黑枸杞快速无损分级模型, 使用果肉-FD-SPA-Stacking组合, 精度可从0.941 7提升到0.983 3, 此时共提取17个特征波长, 分别为: 591.6, 609.1, 721.6, 989.1, 1 083.3, 1 111.3, 1 296.1, 1 564.9, 1 844.9, 1 934.5, 1 996.1, 2 046.5, 2 130.5, 2 292.9, 2 315.3, 2 320.9和2 348.9 nm, 其中721.6, 1 083.3, 1 111.3, 2 130.5, 2 292.9, 2 315.3, 2 320.9和2 348.9 nm附近有C—H的倍频峰和吸收峰, 721.6, 989.1, 1 934.5, 1 996.1和2 292.9 nm附近有O—H的倍频峰和吸收峰, 2 130.5和2 292.9 nm附近有C—O的吸收峰。 研究结果表明基于高光谱结合集成学习进行黑枸杞快速无损分级是可行的。
Black goji berry has high nutrition and medical value. Different grades of black goji berry have different quality, and prices are also significantly different. However, due to the lack of effective detection and grading methods, the black goji berry market is chaotic, and the bad become mixed with the good, which affects the black goji berry market's quality supervision. To achieve fast, non-destructive and high-precision classification of black goji berry, this paper proposes a fast non-destructive classification method of black goji berry based on hyperspectral and ensemble learning. First of all, for Nomhong 1st grade (NMH-grade1), Nomhong 2nd grade (NMH-grade2), Nomhong 3rd grade (NMH-grade3), Nomhong 4th grade (NMH-grade4), select 200 for each grade. Then, in two placement modes (carpopodium up and overall horizontal after removing the carpopodium), the spectral image cube with a spectral range of 391.6~2 528.1 nm is acquired using a GaiaSorter-Dual wide-band hyperspectral sorter. Through the mask processing, automatically extract single black goji berry ROI hyperspectral information with cell counting algorithm. The spectral information of black goji berry in the range of 500~2 400 nm is extracted. After FD(First Derivative), FFT(Fast Fourier Transform), HT(Hilbert Transform), SG(Savitzky Golay), Normalize, SNV(Standard Normal Variate) preprocessing, the spectral information of the characteristic wavelength is extracted by PCA(Principal Components Analysis), SPA(Successive Projection Algorithm), CARS(Competitive Adaptive Reweighted Sampling). Then build LIBSVM, LDA(Latent Dirichlet Allocation), KNN(k-Nearest Neighbor), RF(Random Forest), NB(Naive Bayes) detection models. The combination of sarcocarp-Normalize-SPA-LDA, sarcocarp-FD-CARS-RF and sarcocarp-SNV-CARS-LIBSVM is the best, with accuracy rates of 0.941 7, 0.941 7 and 0.937 5, respectively. At the same time, it can be found that in the pretreatment, FD, HT, Normalize, and SNV have better effects. In the dimensionality reduction method, the models of SPA and CARS have better effects. And in the models established by LIBSVM, LDA, KNN, RF, and NB, the number of test set accuracy rates of not less than 0.9 are 2, 7, 0, 4, and 1, respectively, so the three classifiers LDA, RF, and LIBSVM work best. To further improve the classification accuracy of black goji berry, LDA, RF and LIBSVM are used as meta-models to build a fast and non-destructive classification model of black goji berry Stacking ensemble learning. When the sarcocarp-FD-SPA-Stacking is combined, the accuracy can be improved from 0.941 7 to 0.983 3. A total of 17 characteristic wavelengths is extracted, respectively (in nm): 591.6, 609.1, 721.6, 989.1, 1 083.3, 1 111.3, 1 296.1, 1 564.9, 1 844.9, 1 934.5, 1 996.1, 2 046.5, 2 130.5, 2 292.9, 2 315.3, 2 320.9, 2 348.9. Among them, there are C-H frequency doubling peaks and absorption peaks near 721.6, 1 083.3, 1 111.3, 2 130.5, 2 292.9, 2 315.3, 2 320.9, 2 348.9, O—H frequency doubling peaks and absorption peaks near 721.6, 989.1, 1 934.5, 1 996.1, 2 292.9, and C—O absorption peaks near 2 130.5 and 2 292.9. Research has shown that fast and non-destructive classification of black goji berry based on hyperspectral combined with ensemble learning is feasible.
黑枸杞(Lycium ruthenicum Murr.)主要分布在我国内蒙古西部、 宁夏、 青海和西藏等地区, 具有较高的营养和医学价值[1]。 黑枸杞因其花青素含量较高, 具有抗氧化、 抗肿瘤、 降低血栓等功能, 其医学价值远高于普通的红枸杞。 近几年来黑枸杞的价格逐渐上升, 市场不断扩大, 前景广阔。 而不同等级的黑枸杞质量不同, 其商业价值也不同, 因此实现黑枸杞分级具有重要意义。 目前分级方法仍以人工检测和化学方法为主, 人工检测根据经验分级, 检测精度较低, 而化学方法速度较为缓慢, 且具有破坏性, 因此目前黑枸杞市场鱼龙混杂。 现在急需一种快速、 无损、 高精度黑枸杞检测方法。
近红外技术将光谱测量与化学计量学有机结合, 在农业种子质量检测等领域取得了广泛的应用[2]。 但是该方法因无法获取图片信息, 检测精度较低。 而高光谱成像技术将光谱和图像结合, 可以同时反映样品的外部纹理特征、 内部结构以及化学成分, 受到许多食品工业研究者的青睐。 王磊[3]等利用近红外高光谱图像实现了宁夏枸杞产地的鉴别。 于慧春[4]等采用高光谱图像技术对枸杞多糖和总糖含量进行检测, 并探寻其最适宜的光谱波段。 然而目前对于黑枸杞的研究较少。
为提高检测速度和精度, 多元散射校正(multiplicative scatter correction, MSC)[5]、 标准正态变量校正(standard normal variate, SNV)[5]等预处理方法被用来去噪; 主成分分析(principal components analysis, PCA)[3]、 竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)[5], 连续投影算法(successie projection algorithm, SPA)[5]等方法被用来数据降维。 再通过支持向量机(support vector machine, SVM)[5]、 线性判别分析(latent dirichlet allocation, LDA)[3]、 K最近邻(k-nearest neighbor, KNN)[5]、 随机森林(random forest, RF)[6]、 朴素贝叶斯(naive Bayes, NB)[7]、 BP(back propagation)等神经网络等弱分类器建立食品质量检测模型。 而基于不同的预处理方法, 降维方法和弱分类器建立的模型差异较大, 需要进一步研究。 为提高弱分类器的检测精度, 深度学习[8]和集成学习[9]因其较强的特征学习能力而逐渐被引入食品质量的无损检测领域。 但是, 深度学习对计算机软硬件配置要求较高且资源消耗较大, 计算速度很大程度上受限于计算机的性能。 集成学习则通过将多个弱分类器融合成一个强分类器, 来增强模型的学习和泛化能力[9], 且在提高模型预测精度的同时, 对资源消耗和计算机软硬件的要求并未明显提高。 因此本工作拟采用高光谱技术, 并基于Stacking集成学习[9]实现黑枸杞品质的快速无损检测分级。
实验的黑枸杞均为2019年产自青海诺木洪地区, 按照果实大小分为4个等级, 从大到小分别为诺木洪1级(NMH-grade1)、 诺木洪2级(NMH-grade2)、 诺木洪3级(NMH-grade3)、 诺木洪4级(NMH-grade4)。 从每个等级中挑选大小颜色均匀、 无明显缺陷、 带有果柄的黑枸杞200颗, 分别采集黑枸杞在两种放置模式下(果柄朝上、 去柄后整体横放)的高光谱图像。
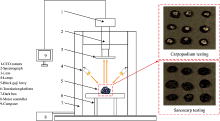
GaiaSorter-Dual宽波段高光谱分选仪如图1所示。 仪器主要由均匀光源、 宽波段光谱相机、 大行程电控移动平台(传送带)、 计算机及控制软件等部分构成。 均匀光源由4个400 W溴钨灯和4个800 W溴钨灯组成。 Image-λ“ G” 系列高光谱相机将分光元件与面阵列相结合, 能够同时、 快速获取光谱和影像信息。 借助移动平台对样品实现线扫描。 系统整体采用上下分体设计, 使样品以传送带传输的方式实现同步宽波段检测, 最终实现连续性测量。 采集的光谱范围为391.6~2 528.1 nm, 在391.6~1 044.1 nm区间内分辨率为2.5 nm, 在1 044.1~2 528.1 nm区间内分辨率为5.6 nm。
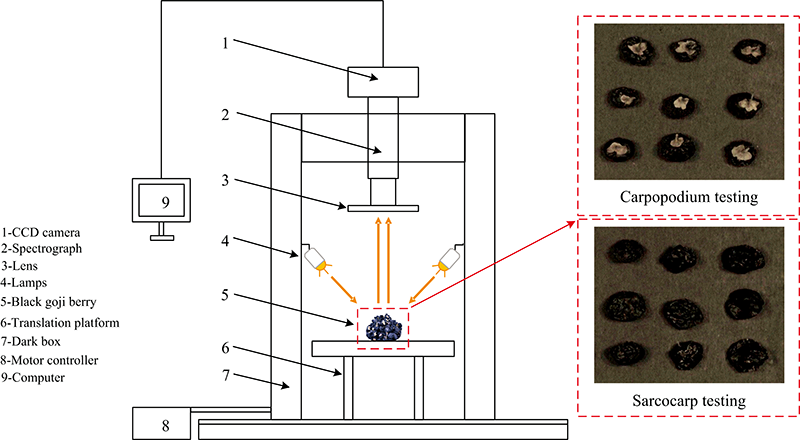 | 图1 高光谱成像系统Fig.1 Hyperspectral imaging system |
实验开始前, 将仪器进行30 min的预热以确保实验的精准性。 经过多次调整, 将相机高度设置为5 cm, 曝光设置为6 ms, 传送带速度设置为0.36 cm·s-1。 同时, 对采集到的高光谱图像进行黑白校正以减少因暗电流或者光照不均匀等因素造成的影响[3], 校正公式为
其中, I为原始高光谱图像; D为黑帧(反射率接近0); W为白帧(反射率接近1); R为经过黑白校正后最终得到的光谱图像。 校正工具为系统自带的SpecVIEW软件。
通过高光谱成像系统, 可得1 681×1 024×527的光谱图像立方体。 其中共1 681×1 024个像素, 每个像素点有527个光谱信息。 为实现单颗黑枸杞果柄和果肉ROI区域高光谱信息的自动提取, 利用MATLAB编写ROI提取算法如下(流程见图2)。
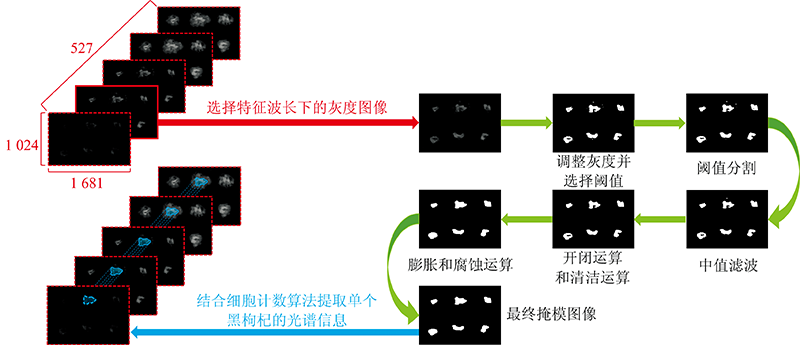 | 图2 单颗黑枸杞ROI的自动提取Fig.2 Automatic ROI extraction in hyperspectral images |
Step 1 ROI掩模
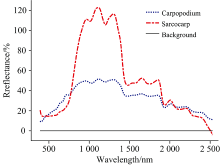
首先, 通过手动比较20颗随机挑选的黑枸杞的果柄、 果肉和背景区域的平均反射信息(如图3所示), 选取果柄与果肉反射光差值最大的波长作为提取果柄的特征波长(1 094.5 nm), 再选取果肉与背景反射光差值最大的波长作为提取果肉的特征波长(1 111.3 nm), 分别在两个特征波长下的灰度图中通过阈值分割和中值滤波、 开闭运算、 清洁运算、 膨胀和腐蚀等运算, 获取果柄和果肉的ROI掩模图像。
 | 图3 果柄、 果肉和背景平均反射信息Fig.3 Average reflection informations of carpopodium, sarcocarp and background |
Step 2 ROI光谱信息的自动提取
通过细胞计数算法, 将掩模图像中每颗黑枸杞果柄和果肉的位置提取出来, 结合光谱图像立方体, 提取对应位置下的光谱信息。 最后利用每颗黑枸杞果柄和果肉的平均光谱信息建立模型。
1.5.1 花青素的提取
采集完样本的高光谱信息后, 再采用pH示差法测定黑枸杞内花青素的含量H, 具体方法见文献[10]。 设置测定波长为525 nm, 温度为40 ℃。 在pH 1.0和pH 4.5的缓冲液稀释处测定吸光度, 其平衡时间分别设定为30和20 min。 最后采用Fuleki T公式计算花青素含量H。
为减小仪器、 测量环境等因素对模型结果造成的影响, 首先进行smooth平滑去噪, 再分别采用一阶导数(first derivative, FD)、 快速傅里叶算法(fast Fourier transform, FFT)低通去噪[5]、 希尔伯特变换法(Hilbert transform, HT)[5]、 多项式平滑算法(savitzky golay, SG)、 正规化(normalize)、 标准正态变量校正(standard normal variate, SNV)六种方法进行预处理。 其中经参数优选, FFT算法中低通滤波器的截止频率设置为0.125, SG算法中阶数和窗口点数分别设置为3和9, Normalize算法中采用0-1正规化。
为降低计算消耗和提高运算速度, 主成分分析(principal components analysis, PCA)、 连续投影算法(successie projection algorithm, SPA)、 竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)三种常用的降维算法被用来提取特征波长[5]。 PCA旨在利用降维的思想, 把多变量转化为少数几个综合指标。 SPA是一种变量选择技术, 旨在消除变量共线性问题。 CARS将指数衰减函数和自适应重加权采样技术相结合建立PLS(partial least squares)模型, 去掉权重较小的波长点, 利用交互验证选出RMSECV(root mean square error of cross-validation)最低的子集, 将其作为最优波长组合。
选用的分类器为LIBSVM[11]、 线性判别分析(latent dirichlet allocation, LDA)[3]、 K最近邻(k-nearest neighbor, KNN)[5]、 随机森林(random forest, RF)[6]和朴素贝叶斯(naive Bayes, NB)[7]。 LIBSVM为台湾大学林智仁教授的算法, 其利用交叉验证选择最优参数, 可实现多分类。 通过比较, LIBSVM中交叉验证次数设为5, KNN中相邻数目设为10, RF中决策树数目设为500。 在使用分类器时, 均将70%的样本作为训练集, 其余30%的样本为测试集。
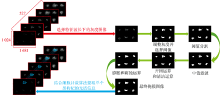
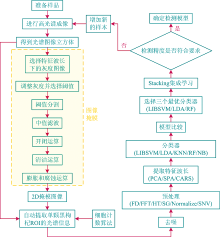
首先将采集到的高光谱图像进行ROI掩模处理, 结合细胞计数算法获取单颗黑枸杞果柄和果肉的平均光谱信息。 然后通过FD, FFT, HT, SG, Normalize和SNV进行预处理, 再用PCA, SPA, CARS进行特征波长的提取。 最后利用LIBSVM, LDA, KNN, RF和NB分类器建立黑枸杞分级模型。 为进一步提高模型精度, 通过Stacking集成学习将多个弱分类器融合成一个强分类器以提高黑枸杞分级模型的泛化能力[9], 其具体过程如图4, 总算法流程如图5。
 | 图4 Stacking集成学习过程 (a): 元模型的训练和预测模型; (b): 总流程图Fig.4 Stacking ensemble learning process (a): Training and prediction models for metamodels; (b): General flowchart |
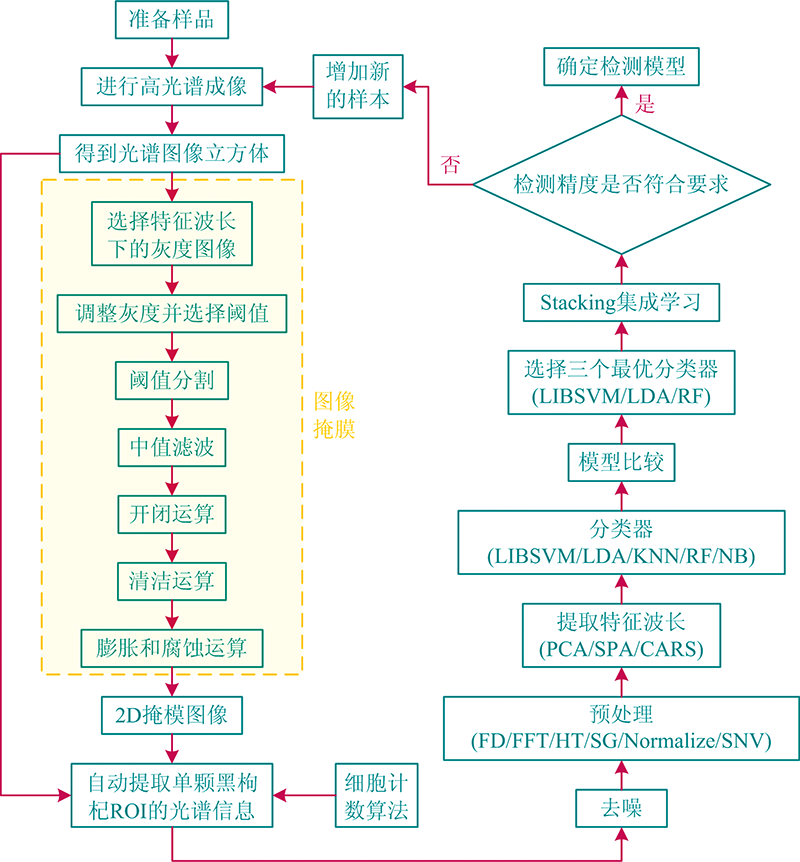 | 图5 黑枸杞快速无损分级模型的流程图Fig.5 Flow chart of fast and non-destructive grading model of black goji berry |
Stacking集成学习采用两层训练结构。 第一层利用不同的分类器构建不同的元模型, 将所有元模型的预测结果进行整合, 然后将其作为第二层的输入数据, 最后对第二层进行训练。
(1)第一层: 基于交叉验证思想的元模型的建立
首先选出建模效果最好的三个分类器构建三个元模型。 每个元模型中, 基于5折交叉验证的思想, 对训练集和测试集预测。
黑枸杞原始数据集M划分为原始训练集S和原始测试集C。 原始训练集S中, 每类黑枸杞有140颗, 共560颗; 原始测试集C中, 每类黑枸杞有60颗, 共240颗。 基于交叉验证的思想, 将黑枸杞原始训练集S平均划分为5份, 记s1-s5。 其中, 每份有112个数据, 每份每类黑枸杞有28个数据。 首先用s2-s5训练第一个基分类器并且预测s1和C, 得到s1的预测值x1和C的第一次预测值y1; 然后用s1, s3-s5训练, 得到s2的预测值x2和C的第二次预测值y2。 以此类推, 最终得到s1-s5的预测值x1-x5以及C的5次预测值y1-y5。 将x1-x5合并得到原始训练集S的预测值X1, 将y1-y5取均值得到原始测试集C的预测值Y1。 对剩下两个基分类器进行同样的操作得到S的预测结果X2, X3和C的预测结果Y2, Y3。
(2)第二层: 利用新的训练集和新的测试集建立黑枸杞分级模型
将第一层得到的结果合并: X={X1, X2, X3}, Y={Y1, Y2, Y3}。 其中, X为新的训练集, Y为新的测试集, 选择建模效果最好的基分类器进行第二层模型的训练。
pH示差法测定后的四个等级的黑枸杞花青素含量如表1所示。 由表1可知, 诺木洪的分级与花青素含量呈正相关, 其中诺木洪1级花青素含量达到30.57 mg·L-1, 诺木洪4级花青素含量达到20.37 mg·L-1, 二者花青素含量差别显著。
| 表1 黑枸杞花青素含量 Table 1 Anthocyanin content of four grades of black goji berry |
测量波长范围为391.6~2 528.1 nm, 共527个波长, 考虑噪声的影响, 截取500~2 400 nm作为有用光谱信息, 如图6(a)和(b)所示。
 | 图6 预处理前后黑枸杞的光谱曲线 (a): 果柄原始光谱曲线; (b): 果肉原始光谱曲线; (c): FD处理后果柄光谱曲线; (d): FD处理后果肉光谱曲线; (e): FD处理后不同等级黑枸杞果柄的平均光谱曲线; (f): FD处理后不同等级黑枸杞果肉的平均光谱曲线Fig.6 Spectral curves of black goji berries before and after pretreatment (a): Raw spectra of carpopodium; (b): Raw spectra of sarcocarp; (c): Spectra of carpopodium after FD treatment; (d): Spectra of sarcocarp after FD treatment; (e): Average spectra of different grades of black goji berrycarpopodium after FD treatment; (f): Average spectra of different grades of black goji berrysarcocarp after FD treatment |
对截取后的原始光谱进行平滑滤波, 然后分别通过FD, FFT, HT, SG, Normalize和SNV方法进行预处理。 其中, 经过FD处理后的光谱曲线及其平均值如图6(c), (d), (e)和(f)所示。 FD的主要思想是对原始光谱求导, 进而放大不同样本间的差异。 从图6(c)和(d)可观察出不同黑枸杞之间的光谱差异主要在580~640, 700~1 500和1 840~2 100 nm波段。
在PCA中, 提取前30个成分特征值的贡献率, 再选出贡献率大于1%的主成分作为新坐标系, 并将原始数据在新坐标系下解析, 得到降维后数据。
在SPA中, 设置SPA可选择波长数量范围为5~35, 步长为1。
在CARS中, 对原始光谱采用CARS降维, 设定蒙特卡罗采样次数为50, 采用5折交叉验证法建立PLS模型。 当某个采样次数所建立的PLSR模型达到最小RMSECV时, 取在该采样次数下的波长作为特征波长。
将果柄和果肉的光谱信息经6种预处理方法和3种特征提取方法去噪和降维后, 分别建立LIBSVM, LDA, KNN, RF和NB模型, 训练集和测试集精度如表2所示。 模型判断标准以测试集精度为主: 精度越高, 模型效果越好。
| 表2 基于PCA的建模结果 Table 2 PCA-based modeling results |
由表2可见, 采用果肉-Normalize-SPA-LDA、 果肉-FD-CARS-RF和果肉-SNV-CARS-LIBSVM建立的分级模型最优, 准确率分别为0.941 7, 0.941 7和0.937 5。
果柄光谱信息建立的模型中, 有2个测试集精度大于等于0.9, 而果肉则有12个, 表明果肉的光谱信息更有利于分级。 在预处理方法中, FD, HT, Normalize和SNV效果较好, 测试集精度不低于0.9的模型个数分别为6, 2, 4和2, 其中FD效果最好。 在降维方法中, SPA和CARS的模型效果较好, 测试集精度大于等于0.9的模型分别有6个和7个, 而PCA由于提取特征波长数量较少, 难以反应完整的黑枸杞信息, 建模效果欠佳。
在LIBSVM, LDA, KNN, RF和NB所建立的模型中, 准确率不低于0.9的个数分别为2, 7, 0, 4和1, 因此优选出LDA, RF和LIBSVM三个分类器用于Stacking集成学习。
选取LDA, RF和LIBSVM三个分类器作为第一层分类器, 建模效果最好的分类器(LDA)作为第二层分类器, 结果如表3所示。
| 表3 Stacking集成学习的建模结果 Table 3 Modeling results of Stacking ensemble learning |
可见, 果肉-FD-SPA-Stacking的建模效果最佳, 可将测试集准确率从原来的0.941 7上升到0.983 3。 该模型提取的特征波长有17个, 分别为(单位nm): 591.6, 609.1, 721.6, 989.1, 1 083.3, 1 111.3, 1 296.1, 1 564.9, 1 844.9, 1 934.5, 1 996.1, 2 046.5, 2 130.5, 2 292.9, 2 315.3, 2 320.9和2 348.9。 花青素是类黄酮化合物, 以C6-C3-C6的C骨架为基本结构, 含有C—H, O—H, C—O等化学键[12]。 黑枸杞除了含有花青素, 还有蛋白质、 水分、 糖类、 脂肪等成分[1]。 在提取的特征波长中, 721.6 nm附近有C—H五倍频峰、 H2O四倍频峰以及O—H四倍频峰; 989.1 nm附近有H2O三倍频峰; 1 083.3 nm附近有C—H第三组组合频峰; 1 111.3 nm附近有C—H三级倍频峰; 1 934.5 nm附近有水分O—H一级倍频峰; 1 996.1 nm附近有O—H一倍频峰; 2 130.5 nm附近有蛋白的C—H和C—O组合吸收峰; 2 292.9 nm附近有糖类的O—H和C—O组合吸收峰; 2 315.3和2 320.9 nm附近有油分的C—H键伸缩一级倍频峰; 2 348.9 nm附近有纤维素C—H键伸缩振动一级倍频峰。 因此, 基于高光谱结合集成学习算法建立的黑枸杞无损检测模型可以较好地反应黑枸杞内部的生化参数。
采用高光谱技术结合Stacking集成学习实现黑枸杞快速无损分级。 首先, 采集黑枸杞在两种放置模式下(果柄朝上、 去柄后整体横放)的高光谱图像, 通过掩模处理自动提取单颗黑枸杞果柄和果肉的图谱信息。 经FD, FFT, HT, SG, Normalize和SNV进行预处理后, 通过PCA, SPA和CARS获取特征波长下的光谱信息, 再比较LIBSVM, LDA, KNN, RF和NB的分类效果, 优选LDA, RF和LIBSVM三个分类器。 结果表明, 与果柄相比, 黑枸杞果肉信息的建模精度更高, 其中, 果肉-Normalize-SPA-LDA、 果肉-FD-CARS-RF和果肉-SNV-CARS-LIBSVM建立的模型最优, 精度分别为0.941 7, 0.941 7和0.937 5。 为进一步提高分类精度, 建立LDA, RF和LIBSVM元模型, 构建基于Stacking集成学习的黑枸杞快速无损分级模型, 在果肉-FD-SPA-Stacking组合方式时, 精度可从0.941 7提升到0.983 3。 研究表明, 采用高光谱结合Stacking集成学习, 可进一步提升黑枸杞的分级精度, 实现黑枸杞质量的快速、 无损、 高精度分级。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|