



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱的刺五加黑斑病的早期检测研究
[赵森 , 付芸
, 付芸* , 崔江南, 鲁烨, 杜旭东, 李永亮]
, 付芸, 崔江南, 鲁烨, 杜旭东, 李永亮]
|
|


作者简介: 赵 森, 1994年生, 长春理工大学光电工程学院硕士研究生 e-mail: 572161650@qq.com
对感染黑斑病的刺五加叶片进行光谱特性研究, 能为药用植物病害的早期筛选与精准治疗提供重要研究资料。 实验目的, 运用高光谱成像技术实现植物病害的自动监督分类与识别。 实验过程, 首先使用高光谱成像系统在可见光波段(380~960 nm)内采集刺五加黑斑病的叶片样本, 光谱数据经过去除亮暗噪声和平滑预处理后, 再经过主成分分析实现数据降维, 继而运用基于不同核函数的支持向量机法建立分类模型, 最后利用总体分类精度、 Kappa系数等因子评价不同核函数对分类器性能的影响。 根据叶片表面的特征将其分为四类样本: 健康亮部、 健康暗部、 轻度病害和重度病害等。 对比各类样本的光谱可知, 刺五加的健康样本在540 nm波长存在一个明显峰值, 在620~680 nm光谱曲线急剧上升; 而病害样本的光谱反射率呈现缓慢且平稳的上升趋势, 上述特征能够将图像空间上反射强度接近的健康亮部和严重病害完全区分开。 经对比发现前四个主成分(PC1, PC2, PC3, PC4)在分类表达上存在差异, 主要表现为PC1含有的信息多, 能够较好地区分各类样本; PC2则出现健康亮部和严重病害的交叉混淆; PC3是对于PC2的补充, 能基本完整地表达轻微病害; PC4的贡献率仅有0.19%, 依然能够准确地识别严重病害。 不同主成分分量在表达各类样本特征中存在的差异能够作为复杂样本分类的参考依据。 对比四种核函数对支持向量机分类器性能的影响, 结果显示线性核函数的识别过程受光强反射的影响较大, Sigmoid核函数的训练精度易受数据集大小的影响, 在识别健康亮或暗, 以及轻微病害上均存在一定的误差, 多项式核函数与径向基核函数的效果较好, 其中, 多项式核函数的精度更高, 为92.77%。 研究表明, 利用高光谱成像技术能够准确地识别刺五加的健康叶片和患病叶片, 为实现自动诊断药用植物叶片病害提供新方法。
Taking the leaves of Acanthopanax acanthopanax infected with black spot disease as an example, the study of plant disease detection by spectral technology provides a research basis for early screening and precise treatment of medicinal plant diseases. The experiment aimed to realize the supervised classification and identification of plant diseases by hyperspectral imaging technology. The experimental procedure is as follows: First, the leaf samples of Acanthopanax japonicus were collected using the hyperspectral imaging technique. After the spectral data were preprocessed by removing light and dark noise and smoothing, the data dimension was reduced using principal component analysis. Then, a support vector machine (SVM) based on different kernel functions was used to establish a classification model separately. Finally, the overall classification accuracy, Kappa coefficient and other factors were used to evaluate different kernel functions’ influence on the classifier performance. According to the leaf’s surface characteristics, the leaf was divided into four kinds of samples: healthy bright part, healthy dark part, mild disease and severe disease. It can be seen that the healthy sample of Acanthopanax senticosus had a significant peak at 540 nm, and the spectral curve rose sharply at 620~680 nm; while the spectral reflectance of disease samples showed a slow and steady rising trend. The above features could completely distinguish healthy samples with close reflection intensity from serious disease samples on the image. After comparison, it was found that the first four principal components (PC1, PC2, PC3, PC4) have certain differences in the classification results. The main differences were that PC1 contains much information and can better distinguish various samples; PC2 showed a cross-confusion between bright healthy samples and seriously diseased samples; PC3 was a supplement to PC2, which can find mild diseased areas; PC4 contribution rate was only 0.19%, and it could still accurately identify serious diseased areas. The differences of principal component components in showing various sample characteristics can be used to reference complex sample classification. Compared with the classification accuracy of SVM modeling based on different kernel functions, the results showed that the linear kernel function’s recognition process was greatly affected by light intensity reflection. The training accuracy of the Sigmoid kernel function was easily affected by the size of the data set, and there were certain errors in recognition of healthy light or dark and minor diseases. The effect of polynomial kernel function and radial basis kernel function was good, and the accuracy of the polynomial kernel was higher, which was 92.77%. Research showed that the hyperspectral imaging technology could accurately identify the healthy and diseased leaves of Acanthopanax senticosus and provided a new method for the automatic diagnosis of diseases of medicinal plant leaves.
刺五加(Acanthopanax senticosus)具有益气健脾、 补肾安神的功效, 作为药物被广泛地用于中国医药学中已有悠久的历史, 主要分布于东三省、 河北和山西等地。 黑斑病是刺五加常见的一种病害, 它是由半知菌亚门、 链格孢属真菌形成的病菌侵害引起的, 会侵染根茎叶等不同器官。 该病害常借助于气流传播, 尤其是雨季多发的夏天, 严重时, 叶片早落, 影响生长[1], 对于药圃养殖业的危害较大。 传统的诊断方法依赖农学研究人员的判断和农民自身的经验, 判别结果易受主观因素的影响, 缺乏及时性和精准性, 经常会延误治理病害的最佳时机。 因此, 种植业迫切需要一种实时监测且自动判别病害的有效手段。
近年来, 越来越多的学者将高光谱成像应用到识别植物叶片及果实病害的研究中。 结合化学计量法根据高光谱数据建立植物成分的反演模型。 Kong[2]等利用这种方法检测油菜茎部的菌核病, 不仅给出被病害侵染前后的油菜茎中叶绿素的敏感波长, 而且构建出最小二乘支持向量机(LS-SVM)的反演模型, 标定集和预测集的最佳分类准确率均在90%以上。 张静宜[3]等从甜菜尾孢叶斑病的高光谱数据中选取前三个主成分进行主成分分析(principal component analysis, PCA), 虽然在不同程度的病害样本中存在着部分样本重叠的现象, 但是, 健康样本与病害样本的差别显著, 运用支持向量机(support vector machine, SVM)的识别准确率为88.2%。 在分析稻瘟菌感染的大麦叶片时, Zhou[4]等也利用前三个主成分, 根据光谱反射率的差异准确地识别出叶片上的健康与患病部位。 继而, BP神经网络、 模糊聚类和支持向量机等分类方法被用到高光谱的数据处理中。 Wang[5]等使用一阶导数法去噪, 并选取前5个主成分分量作为特征波长, 运用支持向量机和极限学习机的算法分别建立基于特征波长与纹理特征的分类模型, 结果证明基于数据融合的支持向量机模型的性能更稳定, 预测集正确率达到98%。 Zhang[6], Li[7]分别运用卷积神经网络和拓展协同表达(extented collaborative representation, ECR)检测黄瓜叶片的病害, 如, 霜霉病、 白粉病或褐斑病, 识别正确率达到92%以上, 且处理时间更短。 总之, 高光谱成像已经广泛地应用于粮食、 水果和蔬菜等植物病害的监测中, 并且具有广阔的应用前景。 但是, 由于高光谱成像过程受一定外界因素(如光线和环境)的干扰, 迫切需要特异性模型的构建和数据处理的优化[8, 9]。
本工作以刺五加的黑斑病为研究对象, 利用高光谱成像系统采集到健康叶片和患病叶片的数据, 将经过PCA变换后得分最高的前四个主成分作为SVM的输入向量, 构建出刺五加早期黑斑病的分类模型, 再根据混淆矩阵的几个二级指标评价不同核函数对分类器性能的影响。 此外, 对前四种主成分在分类上的差异进行了对比。 旨在为高光谱成像技术在药用植物的病害监测中的应用提供实验基础。
实验中所使用的刺五加样本均采摘于吉林省长春农科院经济植物研究所(位于: 北纬43° 05', 东经125° 27')。 在长春经植所研究人员的协同下, 进行了植物叶片病理检验分析, 证实已感染刺五加的黑斑病。 2019年9月采集自然状态下患病叶片112片及健康叶片52片, 并按照叶片患病区域的面积大小及患病后叶片的木化程度划分病害程度的等级[10]。
 | 图1 健康样本与病害样本的图片Fig.1 Pictures of health samples and disease samples |
由于植物光照, 通风或个体差异, 健康叶片存在两种不同的性状, 一些叶片表面光亮, 叶绿素含量居于上成, 而另外一些叶片处于植株下端, 光照略少且通风差, 表面暗淡无光。 病害叶片也分为两类, 一类是轻度病害, 其表面变黑, 病株叶片正面有零星黑或褐色小点, 并出现明显的木质化; 另一类是重度病害, 患病区域逐渐扩大, 呈圆形或不规则的黑色病斑, 边缘连片, 内侧出现亮斑, 并且叶片背面与正面的斑点相同。 按照上述特征将叶片分为四类进行建模分析。
高光谱成像系统主要由四部分组成, 如图2(a)所示。 系统包括光谱仪(ImSpector N10E, 400~1 000 nm, Spectral Imaging Ltd., 芬兰奥卢)、 14 bits的1 600× 1 200像素的CCD相机(Bobcat ICL-1410., 美国弗洛里达)、 双侧150W卤素灯线性光源(IT3900., Illumination Technologies, 美国)、 一维位移台(IRCP-0076-400., Isuzu Optics Corp., 中国台湾)等等。 整个系统封装于暗箱里以避免环境光的干扰, 采集前需要调整光学成像系统, 以及设置位移台的控制参数。 当镜头焦距调整到35~45 cm时, 得到实际的采集区域为11~13 cm; 通过实验发现, 当相机曝光时间设置为22 ms, 并且位移台的移动速度为5.3 mm· s-1时, 可以满足叶片的真实长宽比的采集要求。 此外, 为了消除空间场的噪声干扰, 需要进行明暗场校正[11]。 叶片一律为正面对准相机采集到的光谱数据送到上位机中进行数据处理, 数据处理流程如图2(b)所示, 具体过程见1.3节。
 | 图2 采集系统(a)与数据处理流程(b)Fig.2 Data collection (a) and data processing flowchart (b) |
高光谱成像系统采集到刺五加黑斑病的样本数据后, 导入计算机进行处理。 由于高光谱数据的波段多, 具有极高的光谱分辨率, 因而能够识别更精细的特征。 但是, 光谱间相关性强, 数据冗余严重, 就使得高光谱图像处理及信息提取技术显得尤为重要。 高光谱数据处理与建模主要使用ENVI5.1(ITT Visual Information Solutions, Boulder, Colorado, 美国)和Matlab(R2014a The Mathworks Inc., 美国)等软件。
1.3.1 主成分分析
主成分分析法是一种有效的数据降维方法, 它将大量的相关变量转换为少数的不相关变量的组合, 即分离原有变量间的相关性, 使用少数变量来表达总体数据集的信息。 由于高光谱的数据量随着波段数的增加呈指数量级的增长, 同时, 相邻波段之间高度相关, 产生大量的冗余信息, 主成分分析法极大地减少了数据量, 从而缩短计算时间。
1.3.2 感兴趣区获取
使用ENVI软件提取样本的感兴趣区域(region of interest, ROI)是关键的一步, 将直接影响分类模型的性能。 通过对所采集的刺五加叶片的观察, 确定使用100× 100像素的窗口获取样本数据, 用平均光谱来表征感兴趣区域的特征光谱, 并进行平滑处理。
1.3.3 支持向量机
支持向量机是一种基于凸二次规划理论的统计学分类方法, 对样本具有良好的泛化能力, 根据待处理数据的特点, 可选择不同类型的核函数并设置参数, 表1给出了四类常用的核函数的原理及其特点[12]。
| 表1 四类核函数的表达式及其特点 Table 1 The expressions and characteristics of four kernel functions |
1.3.4 混淆矩阵
混淆矩阵也称误差矩阵, 是衡量分类模型准确度的一种简单、 直观的方法。 采用其二级指标, 包括总体分类精度、 Kappa系数、 错分误差和漏分误差, 比较不同核函数对分类器性能的影响。
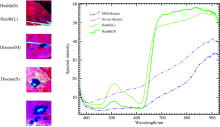
将叶片划分成四类样本: ①健康(亮部), 即Health(L)。 ②健康(暗部), 即health(D)。 健康样本出现亮暗差异的原因有: 实验环境下外界光照不均匀, 叶片存在弯折卷曲; 生长中植株尖端的叶片受光照面积大且通风好, 表面油光; 而植株底部的叶片受光面积小, 通风差叶片暗淡许多。 ③轻度病害, 即Mild Disease(M), 表现出叶片的暗色小点状。 ④重度病害, 即Severe Disease(S), 显现出大斑块, 斑块边缘呈现暗黑色, 中心区域更暗, 与周围的光谱差异明显。 从图像空间上, 很难分辨出健康亮部和严重病害的差异, 容易造成错判。 然而, 在光谱空间上, 可以清晰地分辨两者的差异, 准确地定义健康与患病样本, 见图3。 这恰好体现了高光谱成像技术中“ 图谱合一” 的优越性。
 | 图3 轻度病害、 重度病害、 健康(亮部)和健康(暗部)的光谱曲线Fig.3 Spectra of mild disease, severe diseases, health (L) and health (D) |
图3中四类样本的光谱曲线反映了在各个波段下样本的平均反射强度。 从中看出, 健康样本和病害样本的光谱差异显著, 病害样本的光谱呈现平稳上升的趋势, 没有起伏或阶跃现象, 黑斑病严重的区域, 光谱反射强度增大; 健康样本的光谱曲线变化明显, 在540 nm附近存在峰值形态, 其原因是叶绿素对540 nm波长的光吸收作用弱; 在620~680 nm波长范围内, 光谱反射率曲线急剧上升, 被称为绿色植物特有的“ 红边效应” 特征光谱; 700~900 nm范围内, 健康样本的反射强度趋于平稳, 远远高于病害样本的光谱反射强度; 在910 nm波段附近是水和氧的窄吸收带[13], 光谱曲线呈现下降趋势。
以上分析表明, 高光谱成像技术能够检测到患病前后的叶片中组分含量的变化, 如叶绿素的含量, 以及水和氧等的变化, 说明这些物质含量的改变都能够反映到光谱反射率的变化上。 这表明高光谱成像技术监测植物病害的可行性。
采用主成分分析法对采集到的高光谱数据进行降维, 选取累计贡献率为95.11%的前四个主成分, 使光谱维度的个数从1 040降至4, 截取面积相同的病害区域并绘制出这四个主成分的图像, 如图4所示。 其中, 图4(a)— (d)分别对应前四个主成分(PC1, PC2, PC3和PC4), (e)为合成RGB图。 经过比较分析发现: 主成分PC1的贡献率为92.60%, 此时健康样本和患病样本具有明显差异, 图4(a)中可以看出叶脉的分布, 同时, 严重病害的中心区域有别于其他患病区; 主成分PC2的贡献率为1.56%, 图4(b)中健康(亮部)和严重病变均被标记为蓝色, 而且轻微病害区域也没有表现出来; 主成分PC3的贡献率为0.76%, 不难看出PC3是对于PC2的补充, 将轻微病害区域基本表达完全, 但忽略了严重病害区域的反射强度信息, 并且健康区域无论亮暗均标记为黄绿色; 主成分PC4的贡献率仅有0.19%, 依然将严重病害区识别出来并标记为蓝色。 图4(e)是基于前三个主成分合成的RGB图像, 虽然不同病变程度的部分样本有重叠, 但是, 各类样本的差异十分明显, 能够严格地区分轻微病害(绿色和黄色)和严重病害(红色)。
 | 图4 前四个主成分与RGB图像的对比Fig.4 Comparison of the first four principal components with the RGB image |
以上分析表明, 主成分分析法既能很好的保留样本特征, 又能够极大地压缩数据量, 为后续的建模提供方便。
运用四种不同核函数的支持向量机法对样本进行建模, 分类结果见图5。
 | 图5 SVM采用不同核函数的对比 (a)— (d)依次为降维前线性核、 多项式核、 径向基核、 Sigmoid核的分类结果; (e)— (f)依次为降维后线性核、 多项式核、 径向基核、 Sigmoid核的分类结果Fig.5 The comparison of SVM based on different kernel functions (a)— (d) represent the classification results of linear kernel, polynomial kernel, radial basis kernel and Sigmoid kernel before data dimension reduction; (e)— (f) are after data dimension reduction |
图5可以看出, 基于不同核函数的SVM的分类器差异不大, 这说明主成分降维较好地保留了原始数据的信息; 图5(a)和(e)中红色方框显示在叶脉识别上两者存在细微的差异, 全光谱将其识别为健康亮部, 而降维之后判别为健康暗部, 说明叶肉和叶脉在组分上略有差异, 而降维处理丢失了这部分信息。 图5(e)— (h)是降维后再运用不同核函数的SVM建模的分类结果, 基本没有差异, 仅在样本边界区域(如粉色方框)有细节性差异。 其原因是: 线性核函数参数设置简单, 忽略了细节差异, 虽然区域划分鲜明但存在噪点; 径向基核函数能够清晰地区分轻微病害(黄色)与严重病害(靛色), 各区域界限鲜明; 多项式核函数与径向基核函数的识别效果相近; Sigmoid核函数参数调整复杂, 存在过拟合现象, 会淡化细节。 相比于前三种核函数, 在健康暗区与患病初期的交界处, Sigmoid核函数会出现界限模糊的情况。
随机抽取68个样本, 其中四类样本的数量相同, 从中提取感兴趣区作为测试集, 按照上述方法建模, 基于不同核函数的SVM模型的识别结果见图6(Ⅰ — Ⅳ )。 “ 暗色方块” 表示预测值, “ 红色圆点” 表示标准值; 横坐标表示样本编号, 纵坐标表示类型标签: “ 1” 表示健康亮部, “ 2” 表示健康暗部, “ 3” 表示轻微病害, “ 4” 表示严重病害。
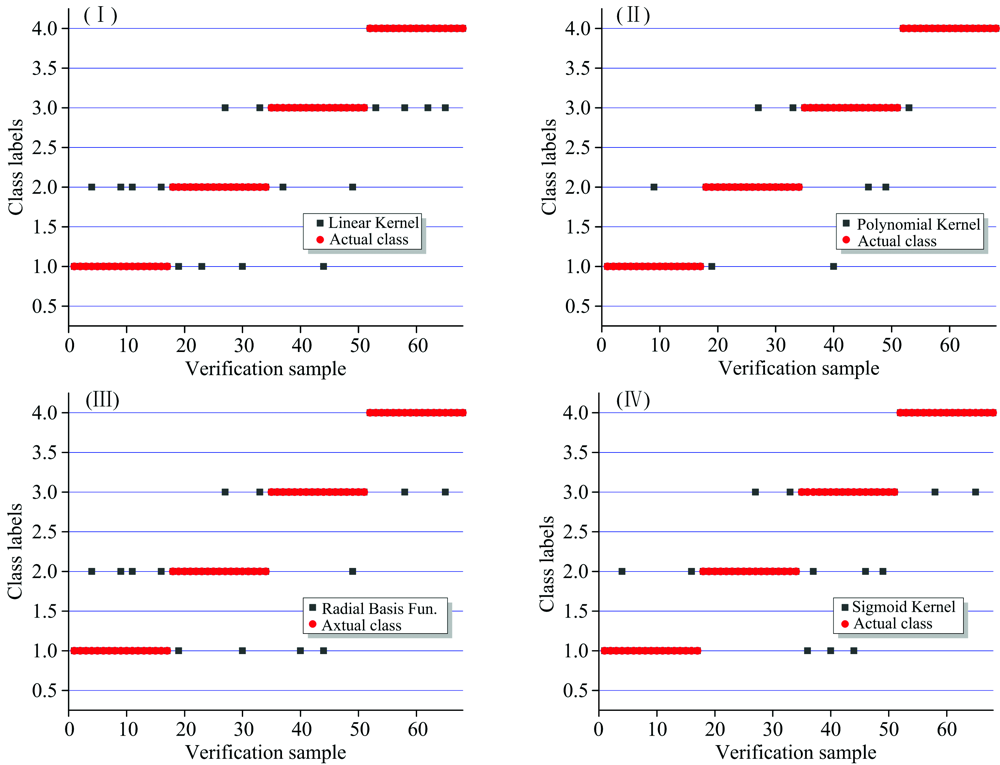 | 图6 对比不同核函数的SVM的识别结果 (Ⅰ ): 线性核函数; (Ⅱ ): 多项式核函数; (Ⅲ ): 径向基核函数; (Ⅳ ): Sigmoid核函数Fig.6 The recognition results of SVM with different kernel functions (Ⅰ ): Linear kernel function; (Ⅱ ): Polynomial kernel function; (Ⅲ ): Radial basis kernel function; (Ⅳ ): Sigmoid kernel function |
从图6中看出, 四种核函数均有较好的识别效果, 但是也有一定的区别。 线性核函数虽然计算速度快, 但是识别过程受光强反射的影响较大; Sigmoid核函数采用神经网络的分类方法, 变量不可控, 训练精度受数据集大小的影响, 在识别健康亮或暗, 以及轻微病害上均存在一定的误差, 需要进一步的实验改进。 目前, 多项式核函数与径向基核函数使用最为广泛, 本文中多项式核函数的识别效果更好, 能够严格地区别健康与病害样本。
用总体分类精度、 Kappa系数、 错分误差和漏分误差等因子评价SVM模型的识别准确度[14], 结果见表2。 从表中看出, 各种核函数的分类精度一般在90%左右, 其中, 多项式核函数的效果最优, 达到92.77%。
| 表2 总体分类精度和Kappa系数 Table 2 Overall classification accuracy and Kappa coefficient |
表3和表4的数据表明, 对相同条件下采集到的刺五加样本, 运用不同核函数的支持向量机算法进行建模时, 健康暗部和严重病害最不易被错分, 只有健康亮部的错分现象明显, 一般出现在两类健康区域的边界处。 其中, 多项式核函数的错分误差和漏分误差最小。
| 表3 错分误差% Table 3 The misclassification error |
| 表4 漏分误差% Table 4 The omission errors |
光谱成像技术已越来越广泛地应用于植物病害分析。 以刺五加的黑斑病叶片作为研究对象, 采集380~960 nm可见光波段的高光谱数据, 运用支持向量机建立病害样本与健康样本的分类模型, 利用总体分类精度、 Kappa系数等因子评价基于不同核函数的SVM建模的分类效果。 结果证明将高光谱成像技术应用于药用植物的病害检测是可行的。
(1) 高维的光谱数据经过PCA处理后, 由于各个主成分所包含的信息不同, 因此, 在分类表达上也有差异。 例如, 本文中PC3清晰地表达了轻微病害的信息, 而PC4能够识别出严重病害样本。 可以利用主成分之间的差异进行某些易混淆组分的划分;
(2) 基于SVM的分类模型能够有效地区分各类样本。 尤其是在区分严重病害时效果最好, 而对健康暗部的识别效果较差, 错分现象多集中在边界处, 后续将就此开展研究;
(3) 采用不同核函数的SVM算法的分类精度不同, 多项式核函数的分类精度最高, 错分误差和漏分误差最低。 这与核函数的参数设置有关, 证明核函数受参数的影响较大。
致谢: 感谢长春理工大学付芸老师的指导; 感谢长春经济植物研究所王娜研究员提供刺五加样本, 以及在病害鉴别上给与的帮助和指导; 感谢五铃光学公司Roger工程师给予高光谱实验设备调试的指导。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|