
{kind=link}
{kind=link}
{kind=link}
{kind=link}
东北寒地水稻茎秆纤维素含量近红外光谱反演
[徐博1  , 许童羽
, 许童羽1, 2, * , 于丰华1, 2 , 张国圣1 , 冯帅1 , 郭忠辉1 , 周长献1 ]
, 许童羽, 于丰华|
|


作者简介: 徐 博, 1989年生, 沈阳农业大学信息与电气工程学院博士研究生 e-mail: xuboboapple@163.com
在水稻抗倒伏育种中, 水稻茎秆纤维素含量作为重要的作物性状表现型数据, 用传统方法获取时受人力成本和时间成本的约束, 采集群体大小有限。 利用高光谱技术能够实现对作物性状信息的快速、 无损检测。 为探究水稻茎秆纤维素含量近红外光谱反演模型, 以田间小区试验的方式, 采集水稻灌浆期至成熟期茎秆基部倒2、 3节作为实验样本, 并在实验室内使用NIRQuest512型号高光谱仪测得茎秆近红外反射光谱数据; 采用标准变量正态变换(SNV)、 连续小波变换(CWT)及两种方法结合(SNV-CWT)对原始近红外光谱进行预处理, 经对比分析, 原始光谱经SNV处理后再通过CWT对应6尺度分解最优, 然后采用联合区间偏最小二乘法(SiPLS)、 迭代保留信息变量法(IRIV)对最优预处理(SNV-CWT)的光谱特征曲线进行光谱特征变量筛选, 分别提取了64个和16个特征变量; 为优化模型并提高其模型精度, 采用IRIV算法对SiPLS所选的特征变量进行二次筛选, 得到6个特征变量, 特征波长为1 200, 1 207, 1 325, 1 470, 1 482和1 492 nm, 最后基于优选出的特征变量分别建立水稻茎秆纤维素含量的支持向量机回归(εSVR)和核极限学习机(KELM)预测模型, 模型参数(惩罚系数 C, 核函数系数 γ和不敏感参数 ε)分别采用灰狼算法(GWO)、 差分进化灰狼算法(DEGWO)和自适应差分进化灰狼算法(SaDEGWO)进行优化选择。 结果表明, 采用SNV-CWT方法光谱预处理后, 经SiPLS-IRIV方法筛选的特征变量构建的SaDEGWO优化的SVR模型精度最高, 模型参数 C, γ, ε分别为302.838 2, 0.087 7, 0.070 8, 测试集的决定性系数(
, XU Tong-yu, YU Feng-huaIn lodging resistance breeding of rice, the cellulose content of rice stem, as an important phenotypic data of crop traits, is constrained by human and time costs, which makes the size of the collecting population limited. The rapid and non-destructive detection of crop traits information can be achieved by using hyperspectral technology. In lodging resistance breeding of rice, rice stem cellulose content is one of the important character information. In order to explore the near-infrared spectral inversion model of cellulose content in rice stem, the bottom 2 and 3 segments of rice stem base formfilling stage to maturity stage were collected as experimental samples by field plot experiment, and the stem near-infrared reflectance spectrum data were measured by NIRQuest512 hyper-spectrometer in the laboratory. Standard normal variate (SNV), continuous wavelet transform (CWT), and the combination of the two methods (SNV-CWT) were used to pretreat the original near-infrared reflectance spectrum. Through comparative analysis, it was found that the original spectrum was optimized when it is firstly processed by SNV and then decomposed by CWT at 6 scales, and then the spectral characteristic variables are screened by the synergy interval PLS (SiPLS) method and iteratively retaining informative variables (IRIV) method for the characteristic spectral curve obtained by the optimal pretreatment (SNV-CWT). 64 and 16 characteristic variables were extracted, respectively. To optimize the model and improve its accuracy, the IRIV algorithm was used to conduct secondary screening of the characteristic variables selected by SiPLS, and 6 characteristic variables were obtained with the characteristic wavelengths of 1 200, 1 207, 1 325, 1 470, 1 482 and 1 492 nm. Finally, the support vector machine regression (ε-support vector machine regression, εSVR) and the kernel-based extreme learning machine (KELM) prediction model were established based on the selected characteristic variables. The model parameters (penalty coefficient C, kernel function coefficient γ and insensitive parameter ε) use grey wolf optimizer (GWO), differential evolution grey wolf optimizer (DEGWO) and self-adaptive differential evolution grey wolf optimizer (SaDEGWO) adaptive proposed in this paper for optimal selection. The results show that the SaDEGWO optimized εSVR model constructed by the characteristic variables selected by the SiPLS-IRIV method after spectral pretreatment with SNV-CWT method has the highest accuracy. The model parameters C, γ, ε are 302.838 2, 0.087 7, 0.070 8, respectively, and the coefficient of determination (
倒伏是影响农作物产量的一个重要因素。 水稻茎秆细胞壁组成(木质纤维素)极大地影响茎秆的机械强度并决定其抗倒伏能力[1]。 在水稻抗倒伏育种中, 茎秆纤维素含量检测一般采用传统的化学方法, 费时费力, 成本较高[2], 而近红外光谱检测具有高效、 无损等优点, 已广泛应用于农业领域的各项指标检测。 在利用近红外光谱对水稻茎秆纤维素含量进行定量检测的研究中, Diallo[3]利用近红外光谱结合竞争性自适应加权(CARS)筛选特征波段建立偏最小二乘回归模型(PLSR)对水稻茎秆纤维素等元素含量进行预测, 模型测试集RMSE为25.4 mg· g-1。 Huang[4]等在利用近红外光谱法检测转基因水稻生物质糖化壁聚合物, 建立了水稻茎秆纤维素含量的偏最小二乘(PLSR)回归预测模型, 模型的RPD为2.79。 Huang[5]等利用近红外光谱结合标准多元散射校正(SMSC)与偏最小二乘回归模型(PLSR)对水稻茎秆纤维素含量快速估计, 模型的RPD为2.36。 上述研究表明利用近红外光谱对水稻茎秆纤维素含量定量检测的可行性, 但所采用的预处理和光谱特征选择方法得到的光谱特征变量中仍存在一定的噪音和冗余信息; 鉴于此, 本研究在光谱预处理和特征波长选择中进行了一定的研究, 采用SNV-CWT方法对光谱进行预处理, 降低由散射所导致的光谱噪声, 采用SiPLS-IRIV特征波段选择方法有效的去除了光谱中存在的冗余信息, 并建立了支持向量机回归(ε -support vectormachine regression, ε SVR)和核极限学习机(kernel-based extreme learning machine, KELM)的水稻茎秆纤维素含量反演模型, 以期为水稻茎秆纤维素含量反演提供一定的科学依据。
试验样本于2018年8月— 9月在辽宁省沈阳市沈北新区清水台镇柳条河村(123° 63'E, 42° 01'N)试验田获取。 试验田总面积为1 333 m2, 等分4个试验小区, 进行4个梯度的氮肥处理, 分别为0, 50, 100和150 kg· hm-2, 试验水稻品种为秋光, 种植密度为13.3 cm× 30 cm。 在水稻灌浆期至成熟期共进行15次田间采样, 每次对各个小区进行4次重复采样, 截取水稻茎秆基部倒数2和3节进行杀青烘干处理, 经粉碎机粉碎成可通过筛孔为1 mm(18目)的样本, 样本的农学参数为水稻茎秆纤维素含量值, 采用VanSoest干重法测定, 剔除异常含量值后, 共计234个样本。 采用Kennard-Stone(KS)方法, 按照7∶ 3的比例将样本集划分为训练集(163)和测试集(71), 如表1所示, 训练集和测试集的茎秆纤维素含量范围分别为141.86~399.39和155.46~351.16 mg· g-1, 测试集茎秆纤维素含量在训练集范围内, 标准差相差不大, 样本分散度基本一致, 训练集和测试集的样本具有较好的代表性。
| 表1 训练集和测试集统计分析 Table 1 Statistical analysis of the train set and test set |
水稻茎秆近红外光谱数据采用OceanOptics公司生产的NIRQuest512型号非成像高光谱仪于实验室内获取。 光谱采集系统由HL-2000系列卤钨光源, 适用于可见光近红外波段(360~2 000 nm), SLIT-10光栅分光系统, 滨松铟镓砷化物(InGaAs)阵列探测器和QR400-7-VIS-NIR反射探头组成。 光谱波段范围为900~1 700 nm, 采样间隔为1.5 nm, 共512个波段。 光谱数据采集时, 光源预热15 min达到热平衡和稳定后, 关闭快门, 进行暗噪声测量; 将反射探头垂直固定在试验台架上, 使用标准漫反射板测量反射光谱作为标准漫反射, 然后将反射探头与水稻茎秆贴合; 设定光谱扫描次数为10次, 每个样本重复测量3次取平均光谱作为该样本的光谱反射率。
尽管使用多次扫描的平均光谱作为样本光谱, 但由于反射探头与光谱仪采用6绕1光纤束连接, 测量过程中, 难以避免光纤位置变化, 导致部分光纤内的光会因散射损失带来一定的光谱误差; 同时由于水稻茎秆为柱形结构且相对粗糙, 存在一定的表面散射, 光谱噪声仍不可避免。 为了提高模型预测能力, 采用标准变量正态变换(standard normal variate, SNV)、 连续小波变换(continuous wavelet transform, CWT)[6]及两种方法结合进行光谱去噪。 为进一步减少模型输入量, 去除光谱中的冗余信息, 采用联合区间偏最小二乘法(synergy interval PLS, SiPLS)、 迭代保留信息变量法(iteratively retaining informative variables, IRIV)[7]及两种方法结合进行光谱特征提取, 提取的光谱特征变量作为模型输入。
选用引入不敏感函数的支持向量机(ε SVR)和核极限学习机(KELM)两种方法进行建模, 模型均采用核函数作为非线性特征映射函数, 核函数的选择和模型参数确定直接影响模型的精度, 因此选择适用性和稳定性较好的径向基函数(radial basis function, RBF)作为核函数, 采用灰狼算法(grey wolf optimizer, GWO)[8, 9], 差分进化灰狼算法(differential evolution grey wolf optimizer, DEGWO)[10], 自适应差分进化灰狼算法(self-adaptive differential evolution grey wolf optimizer, SaDEGWO)三种优化算法确定模型的惩罚系数C, 核函数系数γ 和不敏感参数ε (ε SVR)。
选用训练集的决定性系数(coefficient of determination,
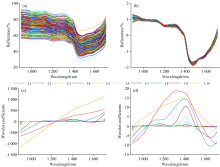
为降低原始光谱中的噪声, 提升光谱对茎秆纤维素含量的解析性, 分别采用了SNV, CWT和SNV-CWT对原始光谱进行处理。 如图1所示, 所有样本的原始光谱曲线趋势基本一致, 光谱反射特征具有一定差异, 与原始光谱对比明显看出经SNV处理后的光谱反射特征差异更为明显, 光谱分布更为集中。 CWT处理光谱时, 选择双正交, 紧支撑和对称性, 且具有线性相位特性的bior1.1小波函数作为基函数, 分别在21, 22, 23, 24, 25, 26, 27, 28, 29, 210尺度下对光谱进行分解, 得到对应尺度的小波系数, 尺度因子越小, 小波系数越小, 对应的频率越高, 具有较好的时间(波长)分辨率但频率分辨率较差, 尺度因子越大则相反。 通常噪声为高频信号, 分解尺度越大, 小波系数越大, 频率越低, 降噪性能越好, 但时间(波长)分辨率降低, 使有效信息特性被消减, 因此需要确定合适的分解尺度, 保证较高的频率分辨率同时具有较好的时间(波长)分辨率。 如图1(c)和(d)分别为对单个样本的原始光谱和经SNV处理后的光谱进行不同尺度分解得到的小波系数曲线, 8~10尺度的光谱特征曲线起伏较大, 具有较好的频率分辨率, 但时间(波长)分辨率低, 1~4尺度的光谱特征曲线起伏变化较小, 具有较好的时间(波长)分辨率, 但频率分辨率较差, 而5~7尺度的光谱特征曲线起伏相似, 具有较好的频率分辨率和时间(波长)分辨率, 为确定最佳分解尺度, 对不同分解尺度得到的小波系数与水稻茎秆纤维素含量进行了相关性分析, 如图2(a)和(b)所示, 从7尺度到10尺度相关性较低, 呈递减趋势, 而1尺度到6尺度相关性呈现递增趋势且相关性系数大于0.7的光谱区域逐渐增宽, 表明随着分解尺度的增大, 有效去除高频噪声, 适当增大分解尺度可有效的发掘光谱中隐含信息, 当分解尺度过大, 导致有效信息被消除。 因此确定CWT和SNV-CWT的最佳分解尺度为6。
 | 图1 样本的光谱曲线 (a): 原始光谱曲线; (b): 经SNV处理光谱曲线; (c): CWT不同尺度分解光谱曲线; (d): SNV-CWT不同尺度分解光谱曲线Fig.1 The spectra of samples (a): Raw spectral curve; (b): Processed by SNV; (c): CWT different scale decomposition spectrum curve; (d): SNV-CWT different scale decomposition spectrum curve |
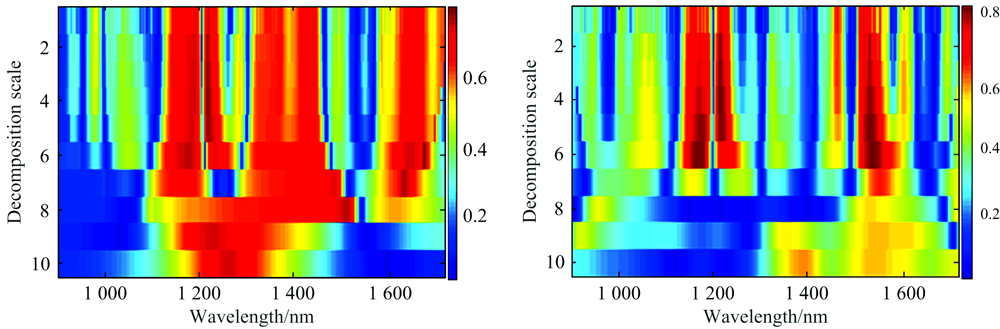 | 图2 小波能量系数与纤维素的相关系数 (a): CWT; (b): SNV-CWTFig.2 Correlation coefficient between wavelet energy coefficient and cellulose (a): CWT; (b): SNV-CWT |
为了进一步探究预处理方法的有效性, 分别对原始全光谱、 SNV处理光谱、 CWT处理光谱和SNV-CWT处理光谱采用10折偏最小二乘法建立水稻茎秆纤维素含量的定量分析模型。 结果如表2所示。 采用经过SNV-CWT-bior1.1-26预处理后的全光谱建立的模型的测试集RPD为2.71, 高于未处理建立的模型(RPD=2.34)、 SNV处理的模型(RPD=2.60)及CWT-bior1.1-26处理建立的模型(RPD=2.55)。 表明采用SNV-CWT-bior1.1-26预处理方法能有效的减少光谱中的噪声, 提升了光谱对茎秆纤维素含量的解析能力, 因此确定该方法作为光谱预处理方法。
| 表2 基于不同预处理方法的结果比较 Table 2 Comparison of results based on different pretreatment methods |
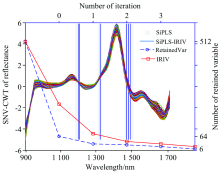
由于全波段光谱数据中存在一定的无用和冗余信息, 影响建模的精度, 因此首先采用SiPLS方法将全波段512个光谱变量按16个波段等分成32个区间, 设定4个区间组合, 依据交叉验证选取RMSE最小值确定最优联合区间, 最终第12, 17, 23和24区间组合为最优联合区间, 区间对应波长范围分别为1 182~1 207, 1 310~1 334, 1 462~1 486和1 487~1 511 nm, 所选区间在全波段光谱中的位置如图3所示。 SiPLS方法对全波段光谱按照预设区间值进行划分, 以各区间排列组合方式, 确定特征波长的范围, 一定程度上去除了无用信息和干扰信息, 然而受区间值的限制, 难以避免优选区间中仍然存在冗余信息。 因此, 采用IRIV算法对优选区间进一步进行特征波段筛选, 全波段光谱经过SiPLS方法将光谱变量数由512个降至64个, 再经过IRIV进行3次迭代, 变量消减至17个, 反向消除11个, 最终得到6个特征波长, 特征波长为1 200, 1 207, 1 325, 1 470, 1 482和1 492 nm, 如图3所示, 依据前人研究纤维素的贡献波段范围主要分布在1 140~1 200 nm的C— H伸缩振动的第二倍频带, 1 350~1 470 nm的C— H和O— H的第一倍频带, 1 490~1 600 nm的O— H的第一倍频带[12]。 本研究的结论基本一致, 但因受氢键效应、 振动耦合因素影响, 使得纤维素在近红外吸收峰的位置存在部分位移。 为了进一步说明SiPLS和IRIV方法组合的合理性, 采用IRIV方法对全波段光谱进行特征波长选择, 结果如图3所示, 512个光谱变量经4次迭代后, 变量缩减至30个, 再经过反向消除14个, 得到最终特征波长16个(987, 1 033, 1 138, 1 141, 1 157, 1 217, 1 285, 1 287, 1 296, 1 330, 1 336, 1 480, 1 481, 1 483, 1 485和1 508 nm), 说明IRIV方法能够有效的去除全波段光谱数据中的无用信息和干扰信息。 对比SiPLS-IRIV和IRIV方法发现, SiPLS-IRIV选取的特征波长更少, 波长间的共线性程度相对更低。
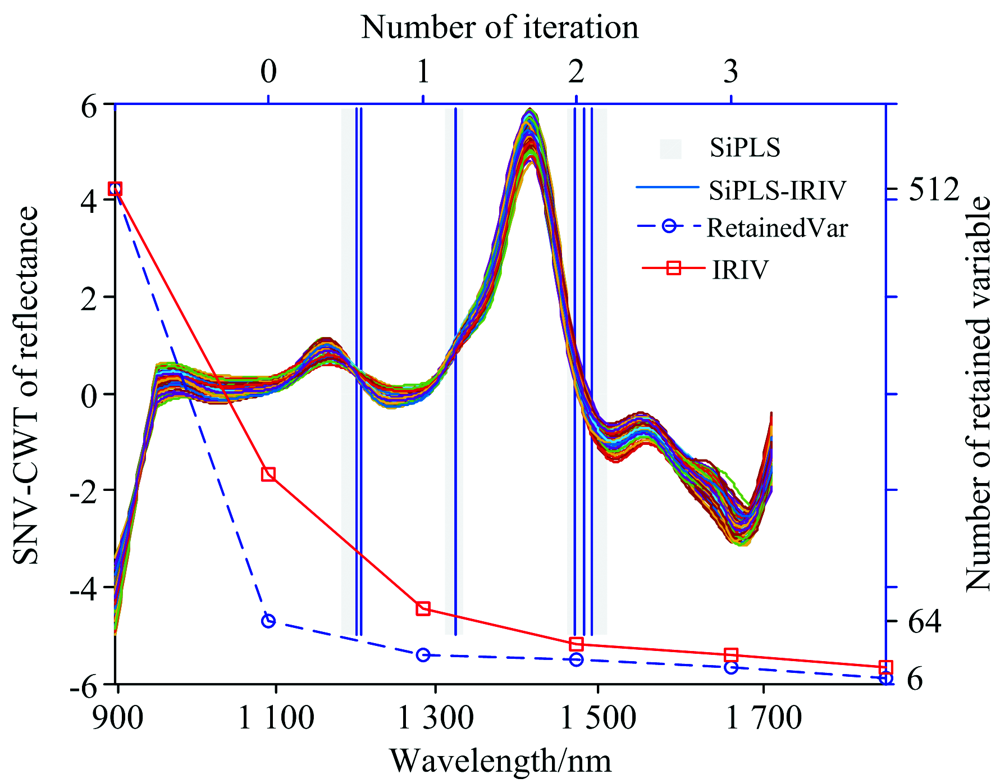 | 图3 基于SiPLS-IRIV算法的光谱特征变量优选Fig.3 Optimization of spectral characteristic variables based on SiPLS-IRIV algorithm |
为了探究特征选择方法的有效性, 分别对SiPLS, IRIV和SiPLS-IRIV特征选择方法采用10折偏最小二乘法建立水稻茎秆纤维素含量的定量分析模型。 结果如表3所示。 采用SiPMS-IRIV特征选择方法选取的6个特征波长建立的模型的测试集RPD为2.79, 相对全光谱(RPD=2.71)、 SiPLS特征选择方法(RPD=2.72)及IRIV特征选择方法(RPD=2.75)选取的特征波长建立的模型测试集PRD均有所提升, 同时变量压缩率高达98.83%, 表明在保证模型预测精度前提下, SiPLS-IRIV特征选择方法有效简化了建模的复杂性。
| 表3 基于不同特征变量选择方法的结果比较 Table 3 Comparison of results based on different feature variable selection methods |
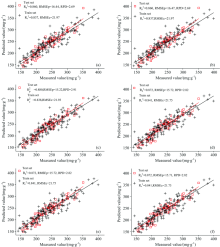
在模型构建中, 将模型参数(C, γ 和ε )的搜索范围均设定为[2-10 210], 种群数和迭代次数分别为20和100, 其中DEGWO变异因子范围为[0.1 0.9], 交叉概率因子为0.1, SaDEGWO变异因子和交叉概率因子范围为[0.1 0.9]。 模型参数选择结果如表4所示。 基于优化算法得到的参数建立的ε SVR和KELM模型结果如图4所示, 散点图中黑色和红色直线分别代表训练集和测试集的实测值与预测值的拟合度。 模型参数优化对比表明, SaDEGWO算法在优化KELM模型参数C, γ 和ε SVR模型参数C, γ 和ε 时, 较GWO和DEGWO算法优化的模型精度均有提升, 说明SaDEGWO算法在相同参数范围内可以搜索到最优参数, 其中GWO和DEGWO算法优化的SVR模型精度低于采用预处理全波段、 SiPLS和SiPLS-IRIV筛选的特征变量所构建的PLS线性回归模型, 且由表4所示, 采用SaDEGWO优化的模型参数C, γ 和ε 与采用GWO和DEGWO算法差异较大, 表明GWO和DEGWO算法在对SVR回归模型参数优化时陷入了局部最优。 模型对比表明, SaDEGWO-ε SVR模型的测试集
| 表4 基于不同优化算法的模型参数选择结果比较 Table 4 Comparison of parameter selection results of models based on different optimization algorithms |
 | 图4 GWO, DEGWO和SaDEGWO优化ε SVR(a, b, c)和KELM(d, e, f)模型的训练和测试结果Fig.4 Training and test results of GWO, DEGWO and SaDEGWO optimization algorithm ε SVR(a, b, c) and KELM (d, e, f) model |
在构建基于高光谱水稻茎秆纤维素含量的定量反演模型过程中发现SNV-CWTbior1.1-26光谱预处理方法使得模型精度提升效果较好, 因光谱采集过程中, 受环境等不可避免因素影响, 造成光谱中含有一定噪声, 经SNV处理消除噪声的光谱通过连续小波变换在时域和频域进行不同尺度展开, 从光谱信号中有效提取重要信息, 进而使得模型精度提升。 采用未去噪声的光谱进行连续小波变换, 分解得到光谱信息中可能会保留一定噪声信息。
在光谱特征筛选过程中, 发现采用IRIV方法提取光谱特征变量作为模型输入, 精度高于SiPLS方法, 由于IRIV方法能够有效的去除光谱中无信息变量和干扰信息, 而SiPLS方法提取的联合区间仍然包含部分无用信息和干扰信息; 同时发现SiPLS-IRIV优于IRIV, 原因在于IRIV方法在全波段范围进行特征筛选时, 相对变量数明显增多, 存在一定的变量辨识度降低的问题, 同时表明采用IRIV对SiPLS联合区间再进行光谱特征提取方法的可行性, 进一步表明适当缩小IRIV变量筛选范围一定程度上提升该方法的有效性。
最后从模型对比发现, 采用GWO, DEGWO及SaDEGWO优化KELM模型的精度基本一致, 且略高于PLSR线性回归模型, 采用SaDEGWO优化ε SVR模型精度均高于其他模型, 原因在于在解决本研究问题中, ε SVR模型对径向基函数的高维映射解析力更强, 适用性更好。
此外, 在采用SaDEGWO优化建立ε SVR模型时, 收敛速度相对较慢, 未来将在变异策略进行改进, 并考虑变异因子和交叉概率因子整体分布, 及个体之间的变异因子扰动。
(1) 根据不同的光谱预处理方法分析结果得出, SNV-CWT-bior1.1-26方法能够有效去除原始光谱中的噪声, 预处理后全波段光谱PLSR模型的测试集
(2) SiPLS-IRIV方法能够有效的剔除光谱中无用信息和干扰信息, 特征波长分别为1 200, 1 207, 1 325, 1 470, 1 482和1 492 nm, 变量压缩率为98.83%。 基于6个特征波长构建的PLSR模型测试集
(3) 采用SaDEGWO算法优化的ε SVR模型测试集
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|