
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度残差网络的恒星光谱类别预测
[王天翔1, 2  , 范玉峰
, 范玉峰1, * , 王晓丽1 , 龙潜1 , 王传军1 ]
, 范玉峰, 王晓丽|
|


作者简介: 王天翔, 1995年生, 中国科学院大学云南天文台硕士研究生 e-mail: wangtianxiang@ynao.ac.cn
近年来, 随着各大光谱巡天项目的陆续实施, 观测得到的天体光谱数据急剧增长。 大型光谱巡天项目对光谱的自动分类和分析提出了更高的要求。 本文将分类问题转化为回归问题, 提出一种基于深度残差网络的光谱类别预测方法, 对恒星光谱进行光谱次型预测。 网络主要包括25个卷积层, 1个最大池化层, 1个平均池化层, 全连接层以及12个残差结构。 最大池化层用来筛选特征, 卷积层提取特征, 平均池化层用于减少模型参数, 提高效率。 残差结构可以防止网络退化, 加深网络来提取高维抽象特征以及提高训练速度。 考虑到数据有非零几率存在错误标签以及损坏数据, 采用Log-Cosh作为损失函数来降低坏样本带来的负面影响。 实验数据使用的是从LAMOST DR5中随机抽取的80 000条光谱, 由于光谱质量等原因, 每个光谱型的光谱数量不一。 经过剔除坏值, 流量归一化后, 按7:1:2分为训练集、 验证集和测试集。 实验包括两个部分, 第一个部分是使用数据集训练网络在光谱次型上进行类别预测, 使用最大绝对误差、 平均绝对误差以及标准差来比较不同形状卷积核的性能。 将预测值作为横坐标, 标签作为纵坐标, 对测试集所有样本点使用二阶非线性拟合, 得到了一条与 y= x重合的直线。 证明模型可以很好的预测光谱次型。 第二部分是对模型进行内部分析, 使用类别激活映射的方法分别研究了模型预测A, F, G和K四种类型光谱时所关注的主要特征, 赋予了模型可解释性。 在文中数据集上, 该方法对91.4%的光谱预测误差在0.5个光谱次型以内, 预测的平均绝对误差为0.3个光谱次型。 并与非参数回归、 Adaboost回归树、 K-Means三种方法进行同数据集比较, 结果表明文中提出的方法可以很好地预测光谱次型并且速度更快, 准确率更高。
In recent years, the spectral data of celestial bodies observed have achieved a dramatic increase thanks to the successful implementation of various projects of spectral sky survey. Therefore, higher requirements for the automatic classification and analysis of spectrum are proposed for large-scale projects of spectral sky survey. The classification problem is transformed into a regression one in this paper, and a method of spectral category regression based on the residual depth network is put forward to conduct a prediction of MK spectral subtype on stellar spectrum. The network is mainly composed of 25 convolution layers, 1 maximum pooling layer, 1 average pooling layer, full connection layer and 12 residual structures. The maximum pooling layer is used to filter features, the convolution layer to extract features, and the average pooling layer to reduce parameters and improve efficiency. The residual structure can prevent the degradation of the network, extract high-dimensional abstract features by deepening the network and improve training speed. Considering the non-zero probability of data with false labels and corrupted data, Log-Cosh is adopted as a loss function in this paper to reduce the negative impact of bad samples. 80 000 spectra that are randomly selected from LAMOST DR5 are used as the experimental data. The spectra are divided into the training set, verification set and test set according to the proportion of 7:1:2 after eliminating the bad value and normalizing the flow. The experiment includes two parts. In the first part, the network is adopted to carry out a prediction on the spectral subtype, and the maximum absolute error, the average absolute error and the standard deviation are used to compare the performance of convolution kernels with different shapes. The predicted value is taken as the abscissa and the label as the ordinate, and the second-order nonlinear fitting is used for all sample points in the test set, a straight line that is coincident with y= x is obtained, proving that the model can predict the spectral subtype well. The second part is concerning the internal analysis of the model. The main characteristics of the model in predicting four types of spectra, A, F, G, K, are mainly explored with the method of category activation mapping, thus endowing the model with interpretability. In the text data set, 91.4% of the spectral prediction errors of this method are within 0.5 spectral subtypes, and the average absolute error of the prediction is 0.3 spectral subtypes. It is shown that the method proposed in this paper can better predict spectral subtypes with faster speed and higher accuracy according to the comparison of the same data set with nonparametric regression, Adaboost regression tree and K-means.
LAMOST, 全称“ 大天区面积多目标光纤光谱望远镜” , 是世界上光谱获取率最高的望远镜, 可同时获得4 000个天体光谱[1]。 目前LAMOST已经发布7季数据, 在最新发布的DR7中光谱数量已经高达1 448万条, 如何对海量光谱进行有效利用成为亟待解决的问题。 对这些光谱进行分类是天文数据处理的重要一环。 通过对恒星光谱的分类, 研究人员可以从中获取有效温度、 质量和半径等物理信息, 也可以研究银河系的结构和演化过程[2]。 目前主流的恒星分类系统是MK光谱系统。 每个恒星都根据其有效温度由高到低排序, 依次分为O, B, A, F, G, K和M七种光谱型, 每种光谱型又根据温度从高到低细分为0— 9的次型光谱, 本文不涉及光度型分类。
目前光谱自动分类的方法主要有三种类别, 分别是基于距离度量的方法、 机器学习的方法和基于模糊逻辑知识系统的专家系统。 Schierscher等[3]将Artificial Neural Network(ANN)运用在对Sloan Digital Sky Survey(SDSS) DR7恒星光谱的分类上。 Liu等[4]对LAMOST数据使用线指数和SVM算法对恒星光谱进行MK分类。 其中SVM方法对A, F和G型恒星分类效果达到90%的准确率, 对O, B, K和M型恒星只有52%的准确率。 Kaushal等[5]针对已标注数据太少, 难以训练深层神经网络分类器的问题, 提出一种半监督方法。 该方法在无监督学习阶段使用自动编码器对无标签数据进行提取特征和聚类, 用有标签数据进行微调, 最后在主要光谱类别的平均准确率达到89%。 在涉及光谱次型的分类模型上, Gray等[6]提出一种专家系统, 通过直接与MK分类标准对比来将恒星光谱分类。 在信噪比大于100的数据集上可以达到0.6个光谱次型的精度。 刘蓉等[7]使用非参数回归的方法在分类精度上达到了2.2个光谱次型。 Kheirdastan等[8]使用ANN, SVM, K-means方法, 分别达到1.39, 1.53, 1.65个光谱次型的精度, 光谱次型的分类精度尚待提高。 本文参照He等[9]提出的残差网络提出一种基于深度学习的方法来实现光谱次型高精度预测, 并分析网络的预测依据。
本文的主要贡献有两个, 第一是提升了光谱次型的预测精度, 在LAMOST数据集上平均绝对误差为0.3个光谱次型。 第二是让模型定位光谱特征, 对光谱分类结果有一定的解释能力。
模型主要由卷积层、 激活层、 最大池化层、 平均池化层、 全连接层和恒等映射组成。 在第一个卷积层使用形状为1* 7的较大的卷积核来提取光谱的总体特征, 并使用内核为1* 3的最大池化层进行特征筛选。 最大池化层可以在尽可能保留特征的同时减少参数, 防止过拟合, 提高模型的泛化能力。 后面卷积层的卷积核大小可以在1* 3, 1* 5和1* 7等形状中选择, 文章将在第2节分析使用不同形状卷积核得到的结果。 模型采用GELU作为激活函数, 可根据光谱数据分布进行非线性激活, 表达式可以近似为
在最后一个卷积层使用平均池化层对特征图的参数求均值, 得到一个Channel* 1的向量作为全连接层的输入, 其中Channel为特征图的通道数。 全连接层的输出是一个标量, 作为对输入光谱的预测结果。 由于激活函数的不可逆性, 以及卷积核提取光谱特征时或多或少会有信息丢失, 深层模型存在退化问题。 文献[9]中提出的残差结构的恒等映射使这个问题得到缓解。 在训练网络时, 由于残差结构的存在, 反向传播可以同时沿着残差连接进行传播, 提高了训练效率。 如图1所示, 这里以1* 5的卷积核为例, 其中黄色方块为卷积层, 红色方块为最大池化层, 粉红色为平均池化层, 橙色为GELU激活层, 紫色为全连接层。 鉴于LAMOST数据集有非零几率存在错误标签, 本文使用Log-Cosh作为损失函数来降低坏样本影响。 Log-Cosh函数定义见式(2)
其中,
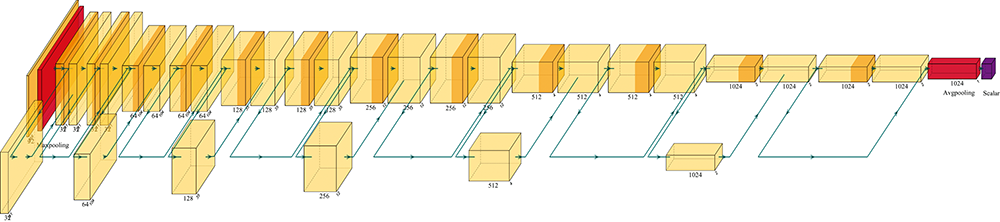 | 图1 模型总体架构Fig.1 Model architecture |
实验采用的数据来自于LAMOST DR5中的部分恒星光谱。 从星表中随机抽样, 选取共80 000条恒星光谱, 并剔除掉红移偏差为-999以及信噪比在u, g, r, i和z任一波段内为-999的异常数据, 确保数据的有效性, 数据集详情见Github(https://github.com/HubCatt/LAMOST-)。 对数据集所有光谱截取3 699~8 750 Å 波段, 然后进行max-min光谱流量归一化
其中x为原始数据, min和max分别为光谱的最小、 最大流量, X* 为归一化后的光谱。 归一化可以加快梯度下降求最优解的速度, 加速模型收敛。 个别类别缺乏数据, 但由于本实验采用的是回归模型, 所以并不影响训练效果。 使用0.0~6.9来标记光谱类型, 其中整数部分表示光谱型, 小数部分表示光谱次型。 例如2.2表示A2型恒星光谱。 O型光谱由于数量较少, 在本实验中都标记为0, 各类别光谱数据按照7:1:2分为训练集、 验证集和测试集。
使用训练集对模型进行训练, 并在验证集上进行超参数调整。 最后在测试集上对模型进行评估。 定义以下三种误差来衡量模型性能。
最大绝对误差
式(4)中, n为样本个数。
平均绝对误差
标准差
为了选择最优的卷积核形状, 本文对4种不同卷积核的网络在测试集上的预测结果进行对比, 结果如表1所示。 实验表明: 网络使用1* 5的卷积核时所得结果平均绝对误差小, 预测误差分布集中在较小值。 可以取得较好的结果, 91.4%的光谱预测误差在0.5个光谱次型内, 平均绝对误差降低到了0.3个光次谱型。
| 表1 各形状卷积核实验结果 Table 1 Experimental results of convolution kernels with different shapes |
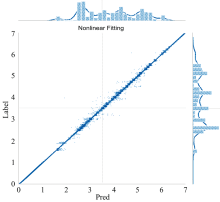
将预测值作为横坐标, 标签作为纵坐标画一个平面, 平面上的一个点代表一条光谱, 对测试集上共16 249个点作二阶非线性拟合, 设置置信度为95(如图2所示), 可以看出, 所得到的函数基本可以看作斜率为1的直线, 并且置信区间与直线基本重合, 这表示模型可以很好的预测光谱型和光谱次型。
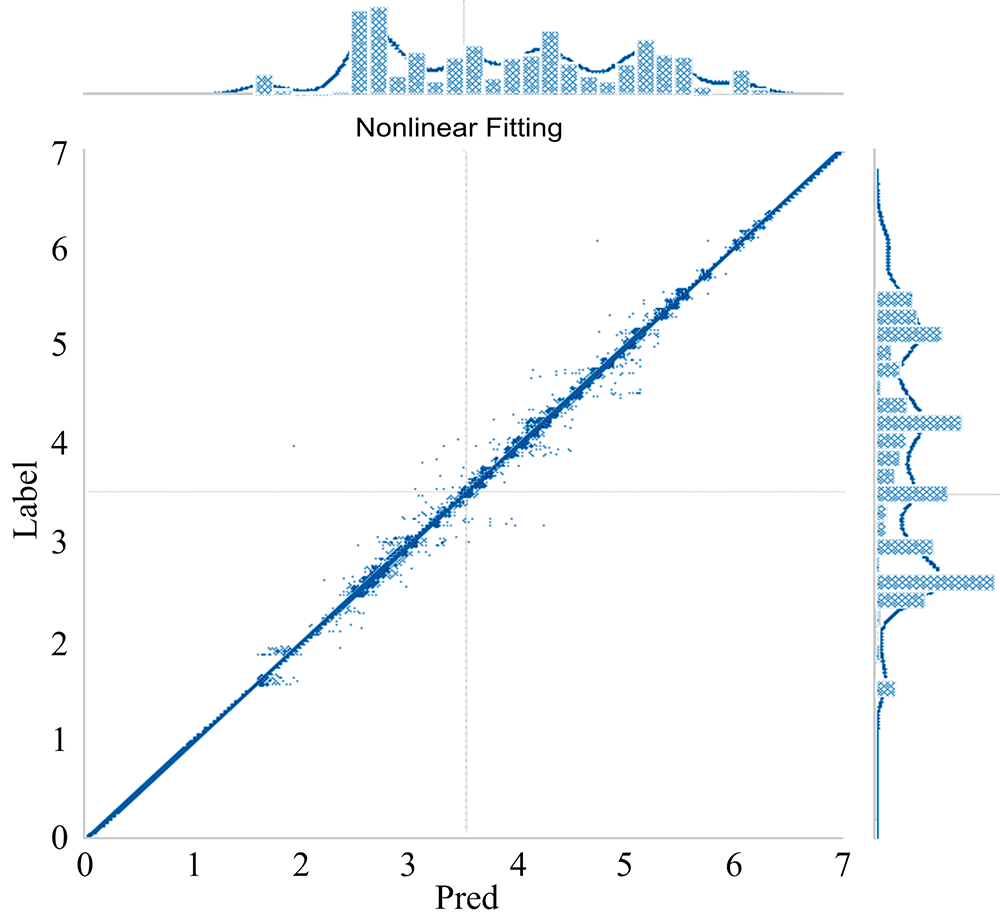 | 图2 二阶非线性拟合Fig.2 Second-order nonlinear fitting |
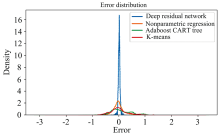
将文献[7, 8]中使用的非参数回归、 K-Means方法, 以及Adaboost CART回归树算法运用在本文中的训练集和测试集上。 表2为深度残差网络与上述三种方法的预测误差统计, 图3为深度残差网络与其余三种方法预测误差的分布情况。 可见深度残差网络性能远优于非参数回归等方法。 由于非参数回归中的核宽采用自适应方式, 取待预测样本与训练集各个样本的最小距离, 故在大样本数据集上耗时过大。 与非参数回归相比, 训练良好的深度残差网络预测速度快, 并且准确率更高, 误差更小, 更符合大数据时代光谱处理的要求。 相较于Adaboost算法需要训练多组弱回归(分类)器, 本文的深度残差网络只需训练一个模型即可。
| 表2 深度残差网络与非参数回归等方法的预测误差统计 Table 2 The statistical error of prediction by Deep residual network, Nonparametric regression, et al. |
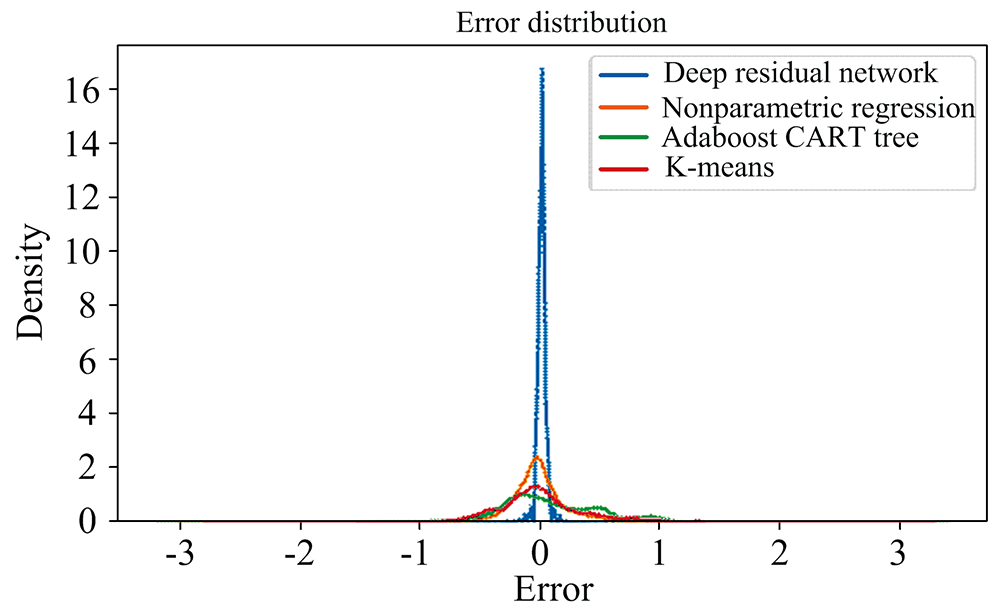 | 图3 深度残差网络与非参数回归等其他方法预测误差分布情况Fig.3 The error distribution of prediction by Deep residual network, nonparametric regression et al. |
利用文献[10]中提出的类别激活映射(CAM)方法分析模型在给一条光谱预测时所关注的一些特征, 通过此分析模型可以对分类结果做出解释。 将得到的CAM进行伪彩色变换, 拉伸, 并与光谱图像加权求和, 便可得到图4所示的类别特征映射图像, 其中颜色越接近红色的波段对分类越重要。 实验中从A, F, G, K各抽取2条光谱画出CAM图像, 并在每幅图下给出了各类别的分数。 对于A型恒星光谱, 模型关注的区域为H原子吸收线存在的波段, 红色精确覆盖了Hbeta, Hgamma和Hdelat, 但忽视了Halpha, 初步推断是Halpha较弱的原因。 对于F型恒星光谱, 模型的关注区域为一阶Ca离子线存在的波段, H原子吸收线存在的波段, 以及一阶S离子线存在的波段。 在F型恒星中, 中性H原子谱线和一阶金属离子谱线都是比较明显的。 对于G型恒星光谱, 模型关注区域大致在3 800~4 400 Å 波段, G型星中Ca离子线达到了最强, 并且出现一阶Fe离子线与一阶Ti离子线, 这些谱线存在于这个波段。 对于K型恒星光谱, 其主要以金属谱线为主, 模型主要以Mg线5 179 Å 附近以及3 699~4 390 Å 波段为判别依据。
 | 图4 类别特征映射图(CAM)Fig.4 Class activation mapping |
光谱分类是天文数据处理的重要一环, 目前被广泛使用的模板匹配方法存在计算冗余、 依赖数据质量等问题, 其他一些方法大都没有涉及光谱次型的分类。 本文提出基于深度残差网络的深度学习模型来对光谱类别进行预测, 并赋予了模型可解释性。 实验结果表明, 本方法在所使用的LAMOST数据集上可以将91.4%光谱预测误差保证在0.5个光谱次型以内, 预测平均绝对误差为0.3个光谱次型。 与非参数回归等方法相比有更高的准确率和预测速度。 在模型分析中, 本文讨论了模型分类依据, 主要包括Balmer线系、 金属离子谱线。 对比文献[4]中线指数分类提出的, Hgamma, Fe和Mg的组合对O-G分类较好, Fe, TiO2和G4300的组合对晚期恒星分类较好, 本文CAM图像与文献[4]的结果基本相符, 下一步工作将通过修改模型输出维度来提高CAM的定位精度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|