{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自适应粒子群算法的多峰谱线分离方法研究
[廉小亲1, 2  , 刘钰
, 刘钰1, 2 , 陈彦铭1, 2 , 黄静1, 2 , 龚永罡1, 2 , 霍亮生1, 2 ]
, 刘钰|
|


作者简介: 廉小亲, 女, 1967年生, 北京工商大学人工智能学院教授 e-mail: lianxq@263.net
电感耦合等离子体原子发射光谱分析法(ICP-AES)已成为一种常规的元素分析方法, 但在ICP-AES分析过程中, 大多元素的分析谱线会受到背景或其他谱线的重叠干扰, 形成的光谱干扰严重影响了谱线分析的准确性, 所以在元素的分析过程中, 需要通过适当的光谱干扰校正方法才能得到合适的元素分析线。 根据光谱强度具有叠加性的特征, 利用谱图将谱线形状表示为Voigt线型函数加和的多峰谱线叠加模型, 以多峰谱线叠加模型与目标谱线的均方根误差构建多元函数作为评价函数的数学模型, 设计自适应粒子群优化(APSO)算法寻找分离谱线特征参数的最优解, APSO算法在标准PSO算法的基础上, 引入压缩因子同时使得种群参数惯性权重根据粒子个体适应度值自适应变化以及学习因子线性变化, 在算法迭代过程中协调粒子种群内全局搜索能力和局部开发能力, 保证算法有效且迅速收敛, 实现多峰谱线分离, 减少干扰谱线的影响从而得到更精准的元素分析线。 以ICP-AES检测器返回的含Pr元素溶液特征波长为390.844 nm和汞灯特征波长为313.183 nm两条谱线的光强AD采样值作为两组实测数据, 以两个Voigt线型近似函数构成的三种不同重叠程度的叠加合成曲线作为三组模拟数据, 在数据曲线上分别选取50个能够包含曲线全部特征参数信息的点作为数据点, 通过对上述五组目标数据点进行APSO算法处理, 结果表明APSO算法得到的多峰谱线叠加模型相关参数能够较准确地拟合出相应的目标数据曲线, 目标数据点与拟合曲线函数值相对误差较低, 算法表明能够有效扣除谱线重叠干扰, 同组目标数据经过多次算法处理, 选择最小的最优适应度值相应的特征参数向量作为Voigt线型函数相关参数, 以此拟合出的多峰谱线叠加模型曲线精准度越高、 相对误差越小。 这种算法具有良好的收敛性和适应性, 可应用于ICP-AES在元素定性、 定量方面的分析研究。
Inductively coupled plasma atomic emission spectrometry (ICP-AES) has become a conventional elemental analysis method, but in the ICP-AES analysis process, most of the elemental analysis lines will be interfered by background or other spectral lines overlapping. Spectral interference seriously affects the accuracy of spectral line analysis. Therefore, in element analysis, an appropriate spectral interference correction method is needed to obtain a suitable element analysis line. In this paper, according to the characteristic that the spectral intensity is superimposed, the spectral line shape is expressed as a multi-peak spectral line superposition model summed by the Voigt linear function.Moreover, the root-mean-square error of the multi-peak spectral line superposition model and the target spectral line are used to construct a multivariate function as an evaluation function of the mathematical model. The adaptive particle swarm optimization (APSO) algorithm is designed to find the optimal solution of the separated spectral lines’ characteristic parameters. Based on the standard PSO algorithm, the APSO algorithm introduces a compression factor while making the population parameter inertia weight adaptively changed according to the individual fitness value of the particle and the linear change of the learning factor. Coordinate the global search capability and local development capability within the particle population during the algorithm iteration process to ensure that the algorithm effectively and quickly converges and achieve multi-peak spectral line separation. Reduce the influence of interference spectral lines to get more accurate elemental analysis lines. The two samples of light intensity AD sampling values of the two spectral lines at the 390.844 nm characteristic wavelength of the Pr element-containing solution and the 313.183 nm characteristic wavelength of the mercury lamp returned by the ICP-AES detector are used as two sets of measured data, and the two Voigt linear approximation functions. Three superimposed composite curves with different degrees of overlap are used as three sets of simulated data. On the data curve, 50 points that can contain all the characteristic parameter information of the curve are selected as the target data points. By performing the APSO algorithm on the above five sets of target data points, the results show that the relevant parameters of the multimodal spectrum superposition model obtained by the APSO algorithm can fit the corresponding target data curve more accurately. The error is low, and the algorithm shows that it can effectively deduct the interference of spectral line overlap. Under the same set of target data, select the characteristic parameter vector corresponding to the smallest optimal fitness value as the relevant parameter of the Voigt linear function, and the multi-peak spectral line superimposed model curve fitted by this method has higher curve accuracy and smaller relative error. This algorithm has good convergence and adaptability. The algorithm can be applied to the ICP-AES in the element qualitative and quantitative analysis of the study.
电感耦合等离子体原子发射光谱仪法(inductively coupled plasma atomic emission spectrometer, ICP-AES), 一定浓度的元素试样溶液经过ICP-AES仪雾化、 在炬管中进入等离子态, 试样中的组分被原子化、 电离、 激发, 以光的形式发射出能量, 通过测定试样溶液光谱图的特征与光强值进而对元素进行定性和定量分析, 该测量方法具有灵敏度高、 检出限低及多元素可同时测定的优点, 因此被广泛应用于稀土分析、 合金冶炼、 石油化工等领域。 然而ICP光源激发能高, 所以在元素测定过程中, 会产生大量发射谱线, 几乎每种元素分析线都会受到不同程度的光谱干扰。
光谱干扰分为背景干扰和谱线重叠干扰。 背景干扰是指均匀分布的带状光谱叠加在被测元素分析线上造成的干扰, 这是ICP光谱仪的固有问题; 谱线重叠干扰是指其他元素的谱线重叠在被测元素分析线上产生的干扰[1], 被测元素分析线与干扰线叠加后的合成曲线作为混合光谱分析线, 导致被测元素分析结果不精确, 因此研究光谱干扰校正方法就尤为重要。
近年来, 数学和统计学方法常用于ICP-AES信号处理, 为ICP-AES光谱干扰校正提供了新的途径, 李划新等[2]提出用自适应平方根卡尔曼滤波法校正ICP-AES光谱干扰, 需要在合适的参数条件下测定加入回收率及相对标准偏差, 此方法对参数设定要求较高; 沈兰荪等[3]提出以目标元素谱图作为目标数据输入, 选择元素理论谱线经仪器函数映射得到的元素物理谱线作为参考输入, 通过自适应滤波器输出元素谱线的最佳估计, 其操作较为复杂。 本文基于自适应粒子群优化(adaptive particle swarm optimization, APSO)算法在多峰函数优化、 全局寻优方面具有的良好优势, 以及基于多峰谱线分离的理论扣除谱线重叠干扰的方法, 利用多个Voigt线型函数叠加构造多峰谱线模型, 提出将APSO算法作为校正算法的设计思路, 通过APSO算法寻求重叠干扰线函数和被测元素分析线函数相关参数的最优解, 实现ICP-AES的多峰谱线分离。
激发态原子或离子由于不均匀展宽所致形成服从Gaussian函数分布的发射谱线, 均匀展宽的发射谱线具有Lorentzian函数分布特征。 在ICP-AES工作条件下, 激发态原子或离子的谱线是在均匀和不均匀展宽效应综合作用下形成的混合型谱线, ICP-AES发射光谱谱线为Lorentzian函数与Gaussian函数卷积得到的Voigt线型函数[4], 如式(1)所示。
式(1)中,
为了简便计算, 原子发射光谱谱线可以用Voigt线型近似函数来描述, 如式(2)所示。
式(2)中, I0为谱峰高度, λ 0为特征谱线中心位置, Δ λ V为谱线半峰宽, η 为Lorentz-Gauss比例系数, 0≤ η ≤ 1, I0, λ 0, Δ λ V和η 为Voigt线型近似函数的待确定参数。
ICP-AES实验曲线通常是由M条Voigt线型曲线与一个背景值叠加而成, 构成的多峰谱线叠加模型如式(3)所示。
式(3)中, BK为背景值,
以多峰谱线叠加模型拟合曲线与目标曲线数据点之间的均方根误差作为多峰谱线叠加模型函数f(λ ,
式(4)中, (λ k, Ik)为目标谱线上N个数据点, 数据点(λ k, Ik)是指在波长λ k下检测到的光强值Ik, 在ICP-AES目标光谱数据中, 表征不同波长λ k用波长所在位置点变量pos表示, Ik则为所在位置点即特定波长下检测到的元素光强值, 具有一一对应特性。 则多峰谱线分离方法归结为: 在一定范围内寻找多元函数全局最优解的问题, 即求解特征参数向量
本文考虑到APSO算法可以有效解决函数寻优问题、 具有较快的收敛速度的特点, 能够通过粒子的个体经验以及种群内的信息共享实现问题求解的智能化, 拟利用APSO算法实现ICP-AES多峰谱线的分离。
粒子群优化算法(particle swarm optimization, PSO)的根本思想来源于对鸟群捕食行为的研究, 模拟鸟群觅食的过程把每个粒子的运动过程比作小鸟, 为了寻找未知位置的食物即适应度值搜寻目前离食物最近的鸟的周围区域, 并根据自己的飞行经验找到最近的路线, 即算法中寻找最优解的过程[6]。 粒子群算法以适应度函数值作为判别标准, 每个粒子都有自己的位置和速度属性, 代表适应度函数的一种可能解, 在每次迭代中更新粒子个体最优解Pbest和全局最优解Gbest, 每一次迭代粒子在D维空间下搜索移动, 追踪当前最优粒子得到这两个适应度值, 根据式(5)和式(6)来更新粒子的速度和位置。
式中, k为迭代次数, ω 为惯性权重, c1和c2为学习因子, r1和r2为[0, 1]内的随机数,
在ICP-AES多峰谱线分离方法研究中, 多峰谱线叠加模型f(λ ,
为了解决PSO算法易陷入局部最优问题, 本文提出带压缩因子的自适应惯性权重和线性学习因子的APSO算法。 该算法中自适应惯性权重变化可以根据早熟收敛情况和粒子个体适应度值动态调整权重值, 学习因子线性变化能够有效解决粒子群算法在后期多样性减少陷入局部最优的问题, 引入的压缩因子能够均衡APSO算法局部搜索能力和全局搜索能力, 保持算法在整个迭代过程中全局收敛性和收敛速度的动态平衡[8]。
标准PSO算法中惯性权重ω 决定了粒子上一次迭代速度与当前次迭代速度的关联程度。 结合前期算法收敛情况, 为了提高PSO算法搜索效果的精准性, 在标准PSO算法的基础上将惯性权重ω 改进为自适应权重变化, 惯性权重ω 根据粒子适应度值进行动态调整, 如式(7)所示[9]。
式(7)中, f为当前粒子的适应度值, favg和fmin分别为当前所有粒子的平均适应度值和最小适应度值。 若当前粒子的适应度值优于所有粒子的平均适应度值, 说明该粒子当前位置接近全局最优解, 惯性权重ω 应选择较小值, 以达到保护该粒子的目的, 若当前粒子的适应度值差于平均适应度值, 则表明该粒子需要向接近全局最优的搜索区域靠拢, 惯性权重ω 应选择较大值[10]。
在标准PSO算法速度更新公式中, 当前次迭代粒子速度除了前次迭代粒子速度会产生影响外, 还要依据自我认知r1(
式中, T为当前迭代次数, Tmax为算法最大迭代次数。 自我学习因子c1先大后小动态变化, 社会学习因子c2则先小后大动态调整[11], 则算法在前期阶段搜索时, 移动粒子变化更多依据自身经验, 在后期阶段搜索时, 粒子位置变化则需要根据整个种群的社会经验, 追踪全局最优粒子位置, 维持收敛速度与搜索效果的稳定性[12]。
在算法计算过程中, 若种群内的粒子多样性减少, 且种群粒子远离全局最优位置时, 需要增强种群全局搜索能力探索粒子的全局最优位置, 当种群内粒子多样性不断增加时, 需要增强种群局部开发能力, 使种群内的粒子向全局最优位置靠近[13], 为了维护算法全局探索能力与局部开发能力的平衡, 在标准PSO算法速度更新公式的基础上乘以收缩因子, 加快收敛速度, 保证算法的收敛性, 此时速度更新根据式(10)调整。
式(10)中, χ 为收缩因子, 用式(11)表示。
式(11)中, φ 通常取4.1, 能够适当保持种群粒子的多样性。
本文采取惯性权重和学习因子动态变化, 同时引入压缩因子的改进粒子群优化算法, 该算法可以有效保证前期迭代尽可能全局探索最优解和后期迭代局部收敛于全局最优解, 具有更优的性能。
ICP-AES多峰谱线叠加模型的构成根据目标数据的复杂程度以及分布情况设定。 本文基于MATLAB设计APSO算法实现ICP-AES多峰谱线分离, 算法设定多峰谱线叠加模型包含两个Voigt线型近似函数, 则此时特征参数向量中包含9个参数变量, 即
APSO算法设置粒子个数为50个, 最大迭代次数Tmax=1 500, 惯性权重最大值ω max=0.6, 惯性权重最小值ω min=0.4, 收缩因子参数φ =4.1, 由于需要寻找9个参数变量的最优解, 因此种群维数D=9, 粒子速度和位置矢量初始化根据目标数据点(λ k, Ik)分布范围随机赋值。 粒子的位置矢量即所求特征参数向量, 特征参数向量包含五类参数, 分别是谱峰高度I0、 特征谱线中心位置λ 0、 谱线半峰宽Δ λ V、 Lorentz-Gauss比例系数η 以及背景值BK, 每类参数的取值范围如表1所示。 速度矢量初始化范围为位置最大矢量的± 15%。
| 表1 粒子位置矢量初始化参数范围表 Table 1 Particle position vector initialization parameter range table |
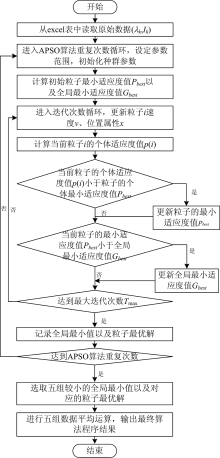
由于在粒子群寻优算法程序中粒子的速度和位置初始化具有随机性, 所以测试数据每次通过改进粒子群算法搜索得到的最优适应度值以及特征参数向量值会有小范围变化, 为了保证算法结果的准确性与稳定性, 在程序中设定算法重复处理同组目标数据20次, 最终20组数据结果中选取五组较小的全局最小值及相应的粒子最优解向量作为算法结果, 并将五组粒子最优解向量包含的每个对应的参数变量取五组平均, 得到的一组平均结果作为该组目标数据下多峰谱线叠加模型拟合曲线的特征参数向量。 APSO算法程序设计流程图如图1所示。
 | 图1 APSO算法程序设计流程图Fig.1 APSO algorithm program design flow chart |
将算法程序得到的特征参数向量结果代入多峰谱线叠加模型f(λ ,
(1)算法测试数据
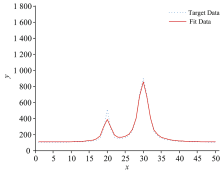
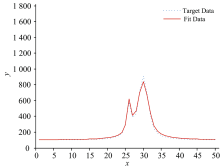
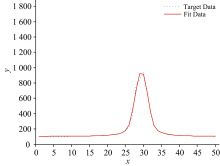
本文选取两类数据作为目标数据进行算法性能测试, 分别是模拟数据以及实测数据。 第一类模拟数据是由两个Voigt线型近似函数构成的三种不同重叠程度的叠加合成曲线上的坐标点作为三组模拟目标数据, x轴坐标表征为目标数据点的所在位置点, y轴坐标值表征为所在位置点的函数值, Voigt线型函数模拟数据1的目标数据曲线两峰几乎不重叠, 相互干扰很小; Voigt线型函数模拟数据2的目标数据曲线两峰部分重叠, 峰形发生变化, 但两峰中心位置清晰; Voigt线型函数模拟数据3的目标数据曲线两峰严重混叠难以分辨, 两峰变形同时峰中心位置移位, 峰值大小也受到严重影响。
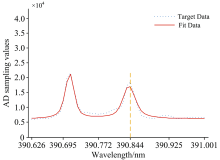
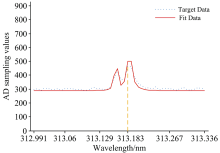
第二类实测数据是通过ICP-AES系统检测含有Pr元素溶液的谱线, 选择Pr的特征波长为390.844 nm; 检测汞灯谱线, 选择Hg的特征波长为313.183 nm, ICP-AES检测器返回的以上述两条谱线所在位置点与光强AD采样值的光谱数据点作为两组实测目标数据, 目标数据点的波长λ k用对应波长所在位置点pos表示, 所在位置点检测到的光强AD采样值即为该目标数据点的Ik。 实测数据与模拟数据均选择了50个能够包含曲线全部特征参数信息的点作为目标数据, 通过APSO算法搜索最优适应度值, 求解构成拟合曲线的两组Voigt线型近似函数待定参数和背景值。
(2)算法测试结果
两类目标数据经过APSO算法计算得到的平均粒子最优解以及平均相对误差结果如表2所示, 在相同坐标下五组目标数据点(λ k, Ik)曲线与最优粒子位置解作为多峰谱线叠加模型相关参数的拟合曲线图如图2— 图6所示。 图2— 图4中模拟数据的目标数据曲线以及拟合数据曲线以所在位置点x为横坐标, 目标数据和拟合曲线在所在位置点处的函数值y为纵坐标; 图5和图6中实测数据的目标数据曲线以及拟合数据曲线以所在位置点的波长λ 为横坐标, 目标数据曲线以光强AD采样值为纵坐标, 拟合曲线以在λ 下的pos求解函数值为纵坐标。
| 表2 五组目标数据APSO算法平均结果 Table 2 The average results of five sets of target data APSO algorithm |
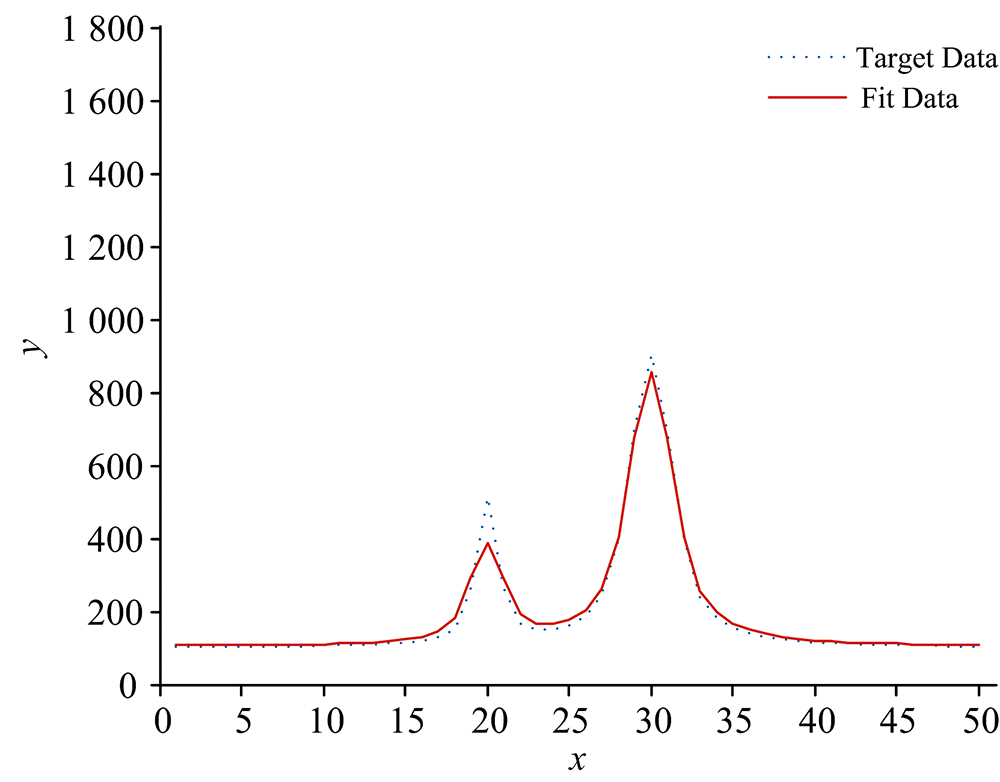 | 图2 Voigt线型函数模拟数据1曲线与拟合曲线Fig.2 Simulated data1 of Voigt linear function and fitting curve |
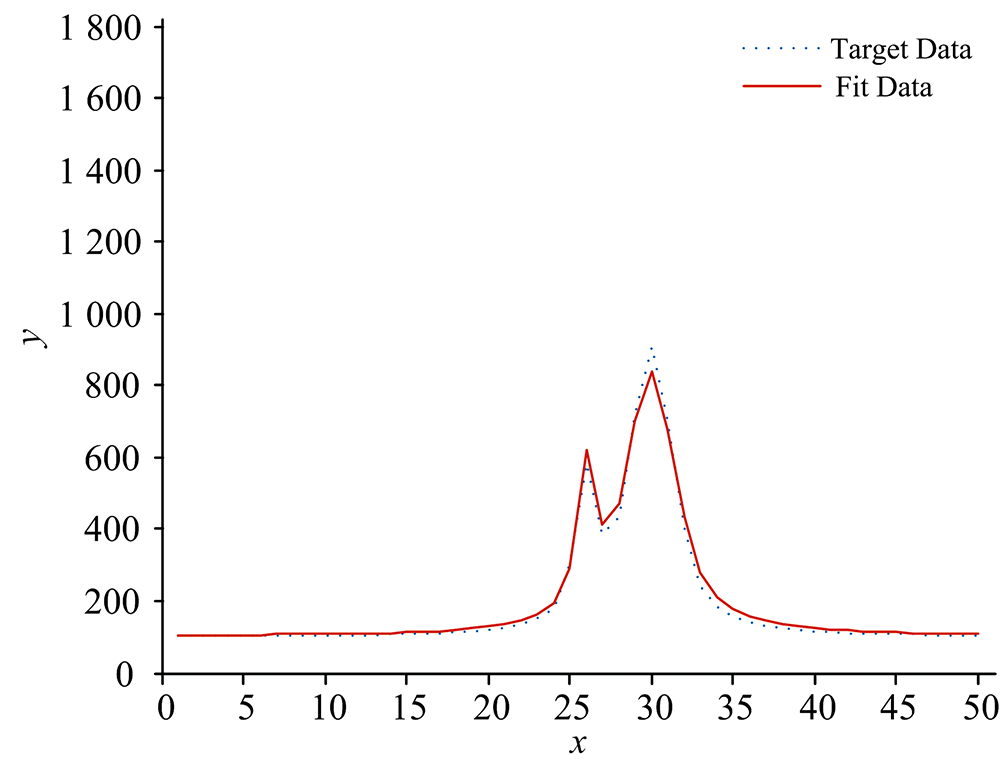 | 图3 Voigt线型函数模拟数据2曲线与拟合曲线Fig.3 Simulated data2 of Voigt linear function and fitting curve |
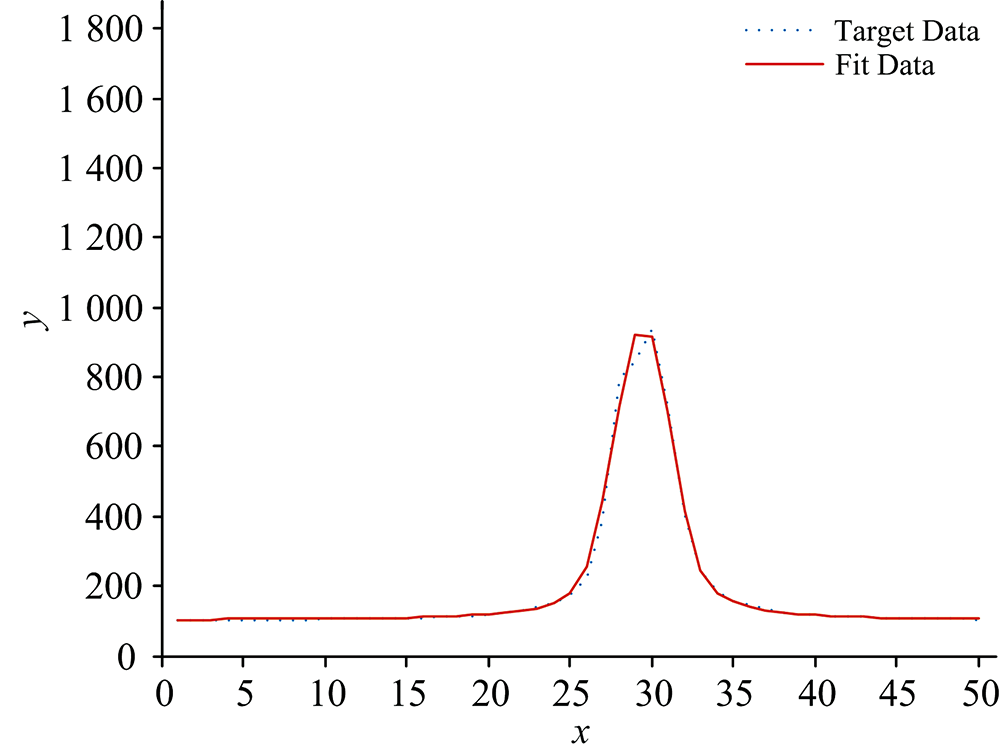 | 图4 Voigt线型函数模拟数据3曲线与拟合曲线Fig.4 Simulated data 3 of Voigt linear function and fitting curve |
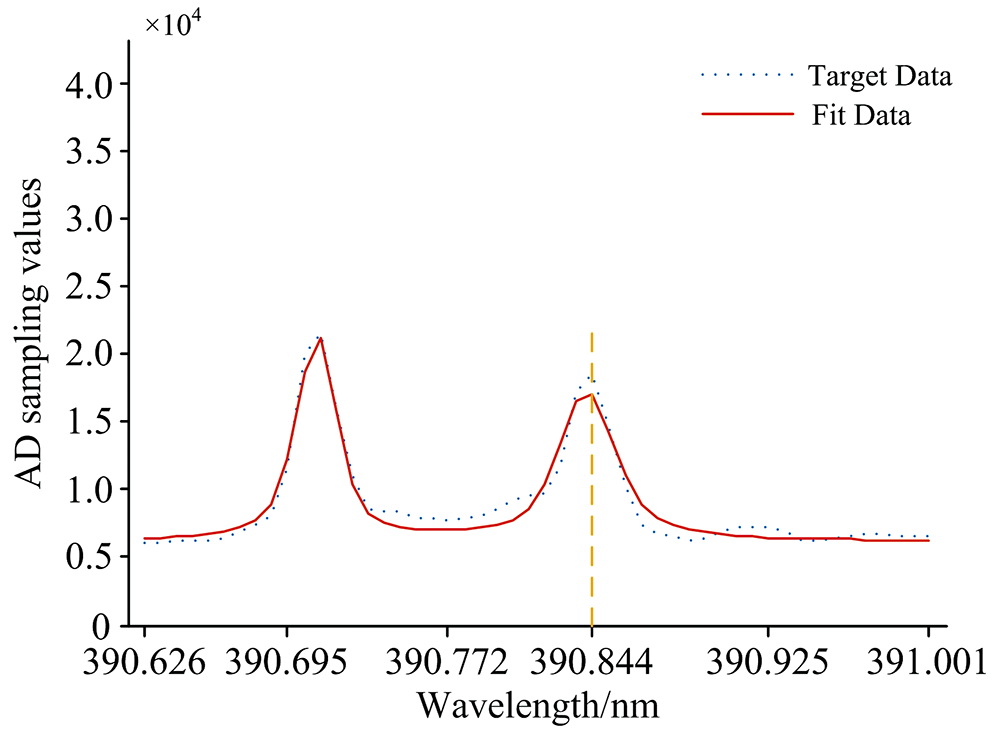 | 图5 390.844 nm Pr元素实测数据与拟合曲线Fig.5 390.844 nm Pr element measured data and fitting curve |
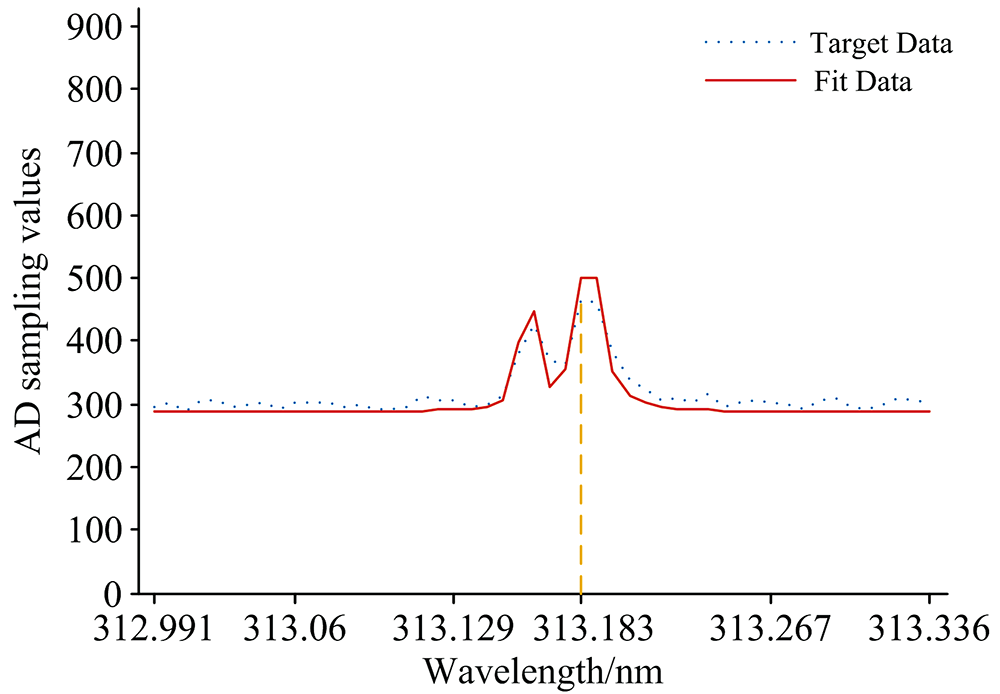 | 图6 313.183 nm Hg元素实测数据与拟合曲线Fig.6 313.183 nm Hg element measured data and fitting curve |
经过五组测试数据结果表明, 通过APSO算法得到的Voigt线型近似函数相关参数能够较准确地拟合出目标曲线, 相对误差较低, 同组目标数据下选择最小的最优适应度值相应的特征参数向量作为Voigt线型近似函数的相关参数拟合出的曲线精准度越高, 相对误差越小。 可见, 本文提出的APSO算法具有较强的泛化能力, 收敛速度快, 逼近能力强。
针对ICP-AES光谱重叠干扰问题, 以多峰谱线分离的数学原理作为理论依据, 提出用Voigt线型近似函数和背景值构成的多峰谱线叠加模型拟合目标曲线, 以二者之间的均方根误差构造APSO算法适应度函数, 设计APSO算法得到全局最优粒子解作为分离曲线的特征参数向量。 通过对实测目标数据和模拟目标数据的APSO算法处理, 结果表明该算法具有较好的泛化能力, 算法结果精确度较高, 能够成功实现元素光谱重叠谱线分离, 可以有效应用于ICP-AES在元素定性、 定量方面的分析研究。 但对于目标数据由两条谱线中心位置较近、 谱线半峰宽较小的Voigt线型近似函数合成谱线的情况, 需要进行多次算法处理才能取得较为精准的特征参数向量结果, 算法有待完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|