

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
拉曼光谱结合LSTM长短期记忆网络的樱桃产地鉴别研究
[卢诗扬1, 2  , 张雷蕾
, 张雷蕾1, 2 , 潘家荣1, 2 , 杨德红1, 2 , 眭亚南1, 2 , 朱诚1, 2, * ]
, 张雷蕾]
|
|


作者简介: 卢诗扬, 女, 1996年生, 中国计量大学生命科学学院硕士研究生 e-mail: shishisansi@163.com
现在樱桃市场上存在着大量以次充好的不良现象, 严重损害了名牌樱桃的品牌经济效益, 所以亟需一种能对不同产地樱桃实现快速无损鉴别的技术。 拉曼光谱溯源技术作为光谱溯源技术的一种, 由于具有快速、 高效、 无污染、 无损分析等优点, 逐渐得到相关研究者的重视。 长短期记忆(LSTM)网络是一种具有记忆性的反馈神经网络, 它是循环神经网络的一种变体。 LSTM网络克服了循环神经网络中梯度消失的缺点, 适合处理序列敏感的问题和任务, 目前被广泛应用在语音识别、 图像识别和手写识别等领域, 但LSTM网络在产地溯源方面的应用还有待研究。 基于此, 提出了一种LSTM网络与拉曼光谱技术结合的能对不同产地樱桃实现快速无损鉴别的技术。 将来自美国、 山东和四川的369个樱桃作为研究样本, 用拉曼光谱仪在785 nm激光下获得了不同产地樱桃的光谱数据。 并且以每条经过基线校正后的拉曼光谱数据作为网络输入数据, 基于LSTM网络构建了能对不同产地樱桃实现快速鉴别的判别模型, 并且以样本判别准确率 A、 样本精确率 P、 样本召回率 R和样本 F值作为评价指标, 探究了不同预处理方法对LSTM网络判别模型性能的影响。 结果表明: 当样本训练集和测试集的比例为85∶38时, 直接采用原始拉曼光谱数据的LSTM网络模型的产地鉴别能力不高, 鉴别准确率为79.87%。 但当使用预处理过后的拉曼光谱数据, 模型的鉴别准确率维持在92%以上。 并且光谱经过SG+MSC预处理后模型的鉴别准确度最好, 鉴别准确率达99.12%。 同时在采用SG+MSC预处理的方法下, LSTM网络鉴别模型的精确率、 召回率、 F值均较高, 表明了所提出的LSTM网络模型有较好的性能可实现对不同产地樱桃的鉴别, 为樱桃的产地溯源提供了一种新的思路。
At present, there are a lot of unhealthy phenomena in the cherry market, which have seriously damaged the economic benefit of famous cherry brands. As a kind of spectrum tracing technology, Raman spectrum tracing technology has been paid more and more attention because of its advantages of fast-speed, high efficiency, pollution-free and non-destructive analysis. And the long short-term memory (LSTM) network is a kind of feedback neural network with memory, which is a variant of the recurrent neural network. LSTM network overcomes the problem of gradient disappearance in the recurrent neural network, and is suitable for solving sequence-sensitive problems and tasks. At present, it is widely used in speech recognition, image recognition and handwriting recognition. However, there are few studies on the application of LSTM network in origin tracing. Therefore, a technology that can identify cherries of different origins quickly and non-destructively is urgently needed. Based on this, this study in this paper proposes a fast and non-destructive identification technique for cherries from different origins by using LSTM network and Raman spectroscopy. In this study, 369 cherries from the United States, Shandong and Sichuan are used to obtain the spectral data of cherries from different regions with the Raman spectrometer under the 785 nm laser. Moreover, the Raman spectral data after baseline correction is taken as the network input data, and a discriminant model is built based on the LSTM network to realize rapid identification of cherries from different origins. In addition, the sample discrimination accuracy A, sample precision P, sample recall R, and sample F values are used as evaluation standards to explore the effects of different prepossessing methods on the sample discrimination accuracy. The results showed that when the ratio of the sample training set to the test set is 85∶38, the LSTM network model that directly uses the original Raman spectral data has poor ability to identify the origin, and the identification accuracy is only 79.87% on average. But when prepossessed Raman spectral data are used, the average accuracy of the model remains above 92%. And the model has the best discrimination accuracy after using Stravinsky-Golay (SG) and multiplicative scatter correction (MSC) prepossessing methods, and the discrimination accuracy reaches 99.12%. At the same time, the accuracy rate, recall rate and F value of LSTM network discrimination model are all high when the preprocessing method named SG+MSC is used. It means that the LSTM discrimination model proposed in this paper can perform well in distinguishing cherries from different regions, which provides a new way of tracing the origin of cherries.
樱桃是一种具有较高价值的水果, 当前樱桃主要分布在美国、 澳洲、 智利等地, 中国主要产地有山东、 四川等。 不同产地由于地域特性的不同, 所生产的樱桃的质量也参差不齐。 樱桃市场上存在着大量“ 以次充好” 的不良现象, 给优质樱桃品牌造成了大量的经济损失, 因此对樱桃产地进行快速无损的鉴别具有重大经济应用价值。
由于拉曼光谱技术在对待检测样品进行检测时不需要对待检测样品做过多处理, 同时还具有快速、 高效、 无污染、 无损分析等优点, 近几年在实际生活和科研中得到了大量的应用[1, 2, 3]。 例如, Haslet Eksi Kocak等运用拉曼高光谱成像技术结合主成分分析成功的实现了开心果颗粒中的豌豆的掺假鉴别[4]。 Mandrile等基于葡萄酒的成熟度等特性运用拉曼光谱技术成功实现了对不同产地葡萄酒产地、 陈酿时间的鉴别[5]。 而在水果产地鉴别方面, 虽然已有光谱技术用于水果的产地判别, 例如高光谱溯源技术[6]等, 但运用拉曼光谱溯源技术进行水果产地溯源的研究寥寥无几。 目前拉曼光谱技术多用于水果的成分分析、 药残检测等, 但对于樱桃产地的快速溯源还有待于研究、 探索。
长短期记忆网络(long short-term memory, LSTM)是循环神经网络的变体, 它可以很好的处理序列数据, 并且解决了循环神经网络(recursive neural network, RNN)长期依赖的问题。 LSTM在原来的RNN结构上添加了3个门结构: 输入门、 输出门、 遗忘门。 相比于RNN, LSTM多了一个称为记忆细胞的隐藏状态来筛选保留信息, 故LSTM适用于处理包含较多冗余信息的光谱数据。 由于独特的设计结构, LSTM会只记住需要记住的信息, 遗忘掉无用信息, 这样LSTM会更加有效的保留有用信息, 于是LSTM就具有了长期记忆的特点。 因此LSTM适合于处理序列敏感的问题和任务, 例如处理利用拉曼光谱数据进行产地溯源的问题。
鉴于此, 本研究提出运用LSTM神经网络结合拉曼光谱技术的方法建立樱桃的产地判别模型, 将来自于美国、 中国山东和中国四川的369个樱桃样本作为实验对象, 并且研究了不同预处理方法对LSTM网络的产地判别模型效果的影响, 在合适的预处理后, 利用不同评价指标对建立的LSTM产地判别模型的判别效果进行了验证。 结果表明, 本文提出的判别模型具有很好的分类和鉴别作用, 为保护名牌产地的樱桃的品牌效应提供了一种新的方法。
实验共收集来自美国、 中国山东、 中国四川的369个樱桃样本, 其中美国、 中国山东、 中国四川各123个样本, 冷链运至实验室, 样品均用塑封袋密封置于同一4 ℃冰箱内。 在采集光谱前3 h取出, 置于室温。
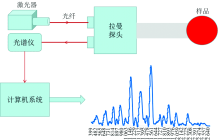
基于实验室自行组装的拉曼光谱检测设备(包括785 nm激光器、 Ocean Opticis公司的QE-Pro光谱仪、 光纤、 拉曼探头、 样品台等), 其原理图如图1所示。 实验参数设置: 积分时间为5 000 ms, 扫描次数为2次, 激光功率为350 mW, 采样间距为2~3 mm。 将樱桃表面擦拭干净以防药残等影响, 而后对每个樱桃样品任意选取5个位置进行拉曼光谱采集, 取均值。 为避免荧光干扰, 整个采集过程均在暗室内进行。 实验共采集369组拉曼光谱数据, 每组数据光谱范围为200~2 870 cm-1。 LSTM判别模型中每个产地取123组进行随机分组分为训练集与测试集, 其中训练集85组, 测试集38组。
 | 图1 拉曼光谱检测设备原理图Fig.1 The schematic diagram of Raman spectrum detection equipment |
因存在仪器热噪声、 样品本身可能存在荧光等干扰, 采集的拉曼数据中含有大量冗余信息, 因此需运用基线校正对拉曼数据进行处理来减少干扰。 由于采集到的不同产地的樱桃光谱极其相似, 裸眼无法区分, 因此需结合标准化、 归一化、 多元散射校正(MSC)、 SG平滑等预处理方式对拉曼信号进一步处理后, 建立LSTM模型对产地进行判别。
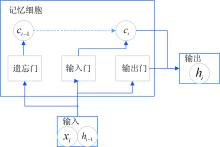
1.3.1 LSTM模型
图2为LSTM的结构图, 其中xi为当前序列的输入、 hi-1为上一序列点的隐藏层输出、 ci为经输入门后的临时单元状态、 hi为当前序列隐藏层的输出。 记忆细胞内包含遗忘门、 输入门、 输出门, 用来选择性的存储信息。 首先, 通过遗忘门将ci-1内的冗余信息清除, 已减少网络负担。 而后, 输入门根据当前序列输入信息更新单元状态变为ci。 而后, 输出门根据当前序列的输入与当前序列的状态得到新的输出, 该输出也为下一个序列点的输入[7]。
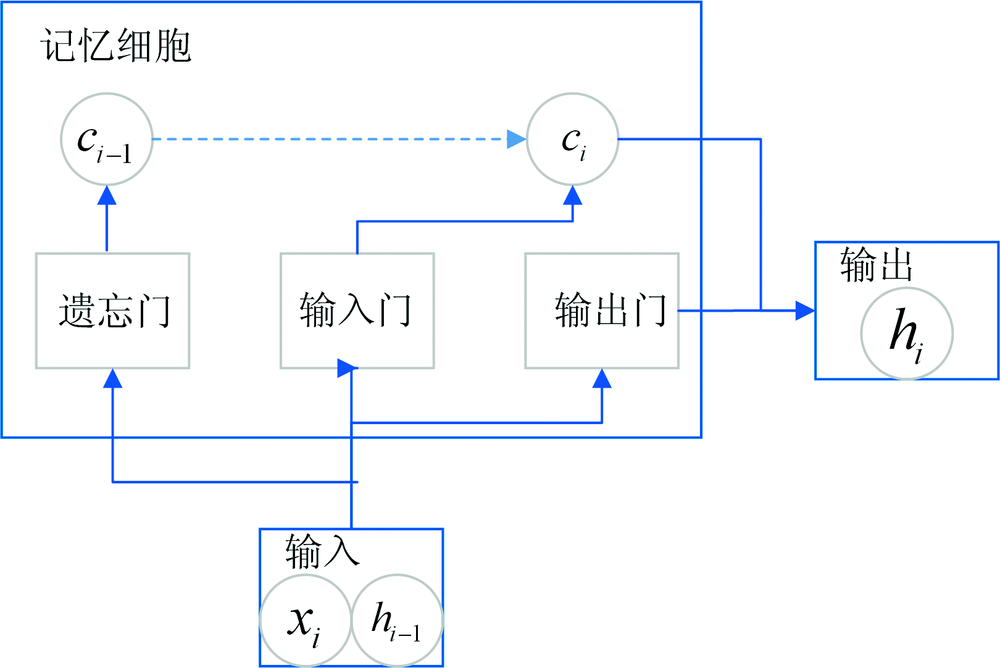 | 图2 LSTM结构图Fig.2 The structure diagram of LSTM |
1.3.2 LSTM模型的建立
首先对每个产地的样本的每条光谱数据用标签进行标记, 例如将美国、 中国山东、 和中国四川的樱桃光谱数据分别用标签“ 1” , “ 2” 和“ 3” 进行标记, 网络采用全连接神经网络结构, 网络通过利用训练集的光谱数据与光谱数据对应的标签形成一一映射的关系进行学习, 运用梯度下降的方法, 调整合适的学习率和训练周期, 使构建的LSTM模型能实现对未知样本的正确判别。 为了防止学习率过大不能收敛到最优解或者过小容易造成欠拟合的问题, 在模型的训练过程中加入了滑动学习率和正则化的方法。 运用MatlabR2018b软件进行建模。
1.3.3 LSTM模型评价指标
模型判别性能优劣以样本判别准确率(A)、 精确率(P)、 召回率(R)和F值来进行评估。 样本准确率(A)是通过对模型判别输出的预测值与真实值进行比较, 是正确判别的预测样本数与总样本数的比值; 样本精确率(P)是正确判别的预测样本数与所有预测为该产地的样本数的比值; 样本召回率(R)是正确判别的预测样本数与所有该产地的样本数的比值; F值是P和R的调和平均值, F=2PR/(P+R)。 样本准确率(A)、 样本精确率(P)、 样本召回率(R)、 F值越大, 模型判别效果越好。
图3(a)为测得的樱桃原始拉曼光谱图; 图3(b)为扣除背景不同预处理下的樱桃拉曼光谱图, Origin表示原始光谱, MSC表示多元散射校正, SG表示Savitzky-Golay平滑滤波, 由图所示, 经SG+MSC处理后的光谱更平滑、 峰形更明显; 图3(c)为SG+MSC预处理后的樱桃拉曼光谱图。 如图3(c)所示, 樱桃的拉曼特征峰主要集中在535, 723, 1 054, 1 174和1 333 cm-1处, 不同产地的樱桃具有相似的光谱图走势, 说明不同产地樱桃中所含有的主要成分相似, 而峰强度的不同可能是樱桃样本中主要相同成分的含量不相同。 1 333 cm-1所示峰可能主要是由于樱桃中糖类的C— H变形振动、 C— O伸缩振动[8]。 1 174 cm-1处的拉曼特征峰形成可能是由于樱桃中胡萝卜素的C— C对称伸缩振动模式, 1 054 cm-1处的拉曼特征峰形成可能是由于樱桃内含有的胡萝卜素的甲基面内摆动。 而535和723 cm-1两个峰可归类至指纹区, 主要原因可能是C— C— O变形振动、 C— S伸缩振动、 C— C— C变形振动和C— O扭曲振动等, 这和樱桃中含有的糖类和蛋白质有关[8]。
 | 图3 拉曼光谱图 (a): 樱桃原始拉曼光谱图; (b): 不同预处理后的樱桃拉曼光谱图; (c): SG+MSC预处理后的樱桃拉曼光谱图Fig.3 Raman spectra (a): Original Raman spectrum of cherry; (b): Raman spectrum of cherry after different preprossessing methods; (c): Raman spectra of cherry after SG+MSC |
表1展示了不同预处理方法对LSTM模型准确率的影响, 其中SVN表示标准正态变换。 由表1可知, 6种预处理方法均能改善所建模型的准确率。 其中SG+MSC处理后的数据所建模型的平均准确率最好, 达99.12%; MSC与归一化+MSC处理后的模型的平均准确率相等, 为98.25%; 二阶导+SVN+MSC处理后的模型的平均准确率为92.11%, 但山东的准确率仅为78.95%; 同样, SVN+MSC与标准化+MSC处理后的模型平均准确率分别为: 93.86%和94.74%, 其中山东的准确率分别为: 84.21%和86.84%。 综合平均准确率与各个产地的准确率, 可以发现SG+MSC处理后的建模准确率最好, 故后续建模中我们采用的预处理方法为SG+MSC。
| 表1 不同预处理方法对LSTM模型的樱桃产地判别准确率的影响 Table 1 The influence of different preprocessing methods on the discrimination accuracy of cherry original region in LSTM model |
在最佳预处理方法SG+MSC下, 对LSTM判别模型的性能进行分析。 其中LSTM判别网络模型所包含的隐藏单元数目是80, 最大训练周期数设为20, 分块尺寸为5。 为了模型能更好的达到最优解, 采用了正则化和滑动学习率的网络模型训练方法, 训练过程如图4所示。
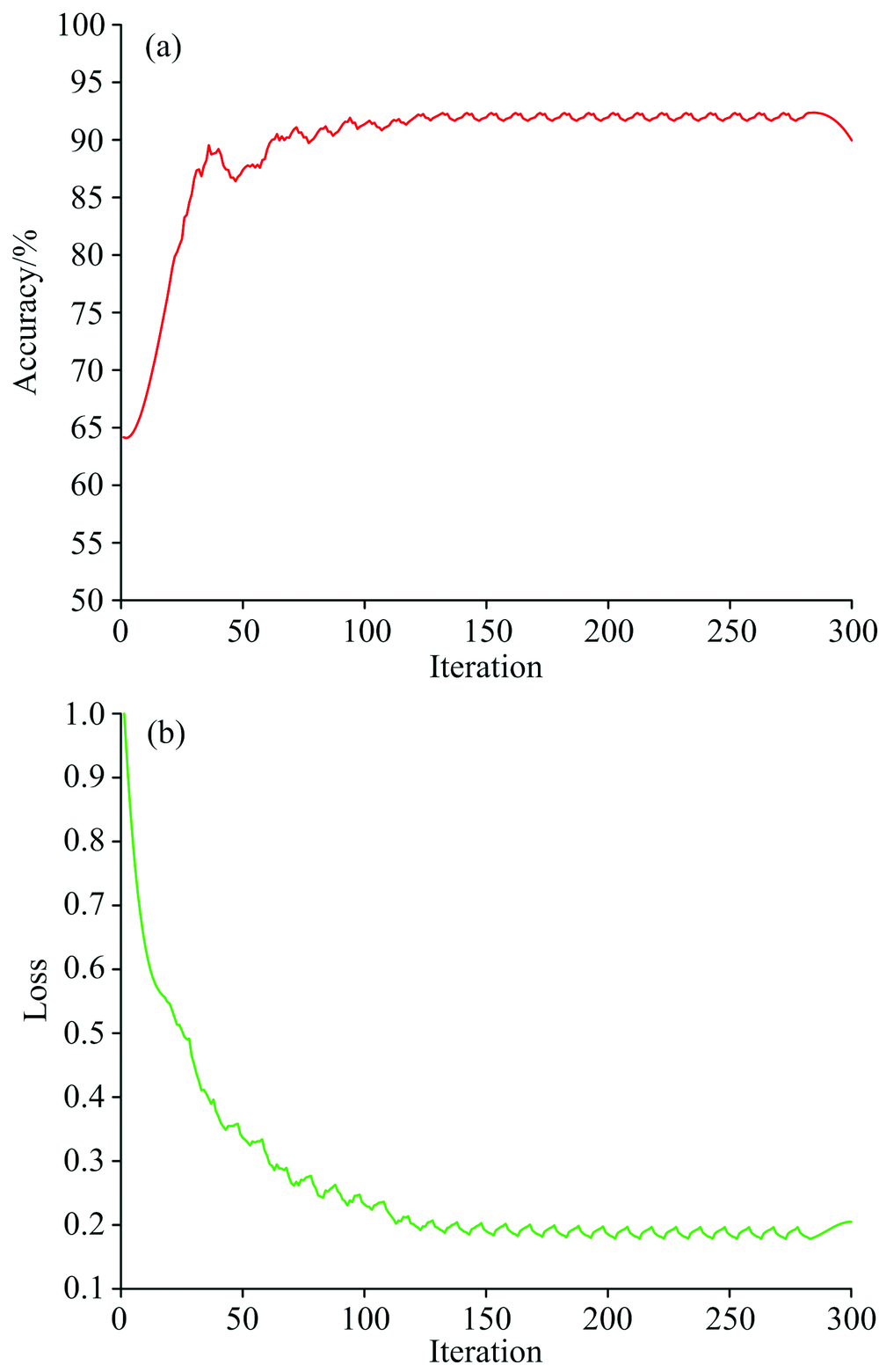 | 图4 LSTM模型训练过程 (a): 训练过程准确率变化趋势图; (b): 训练过程损失函数变化趋势图Fig.4 The training process of LSTM model (a): The changing trend diagram of accuracy on training process; (b): The changing trend diagram of loss function on training process |
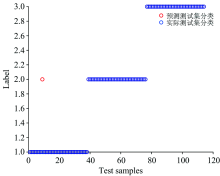
LSTM判别模型对不同产地樱桃样本的光谱进行识别, 识别效果如图5所示。 在图5中, 标签“ 1” , “ 2” 和“ 3” 分别表示樱桃的产地为美国、 山东、 四川。 通过图5可以看出, 所建立的LSTM产地判别模型能以较高的准确率实现不同产地樱桃的产地鉴别, 但也存在将美国产地的樱桃错判为山东的现象。
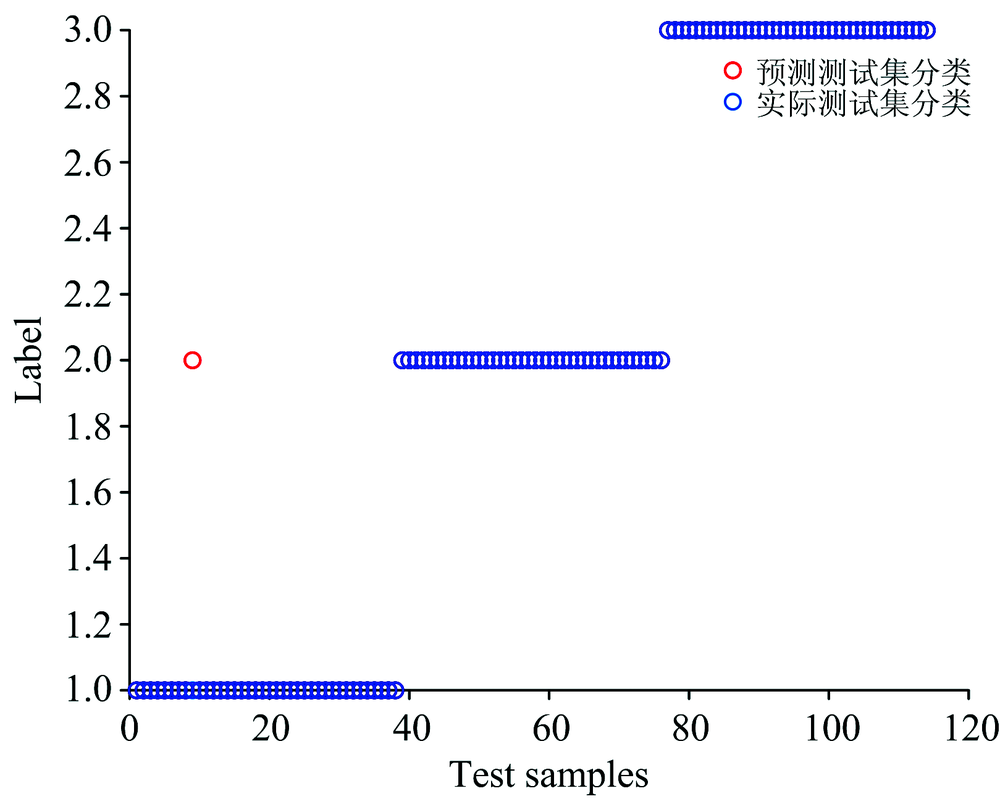 | 图5 LSTM模型对樱桃产地的判别结果Fig.5 The discriminant result of LSTM model on cherry original area |
表2表示了LSTM模型的判别性能。 精确率P是用来评价模型查准率的度量, 而召回率R是衡量模型查全率的度量。 这两个值的取值范围在0到1之间, 这两个度量的取值越大, 模型的查准率和查全率越高。 P和R是相互影响的, 有时会出现矛盾, 需用F值对P和R进行综合评价, F值是P和R的调和平均值。 由表2可知在SG+MSC最佳预处理方法下, LSTM模型的P值和R值均在97%以上, F值均在98%以上, 表明所建立的LSTM模型有较高查准率和查全率, 能以较好的性能实现对不同产地樱桃的产地鉴别。
| 表2 LSTM模型的判别性能 Table 2 The discriminant performance of LSTM model |
利用不同产地的樱桃拉曼光谱数据训练了LSTM网络, 构建了对樱桃产地实现鉴别的LSTM网络鉴别模型。 并研究了MSC、 SG+MSC、 标准化+MSC、 二阶导+SVN+MSC、 归一化+MSC等不同预处理方法对模型鉴别能力的影响, 结果表明采用SC+MSC的预处理方法模型的鉴别效果最好, LSTM鉴别模型能以较好的性能实现对不同产地樱桃的产地溯源, 对人工智能在产地溯源方面的应用进行了探索, 为产地溯源技术的发展提供了一种新的思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|