










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
集成学习算法的红外光谱定量回归模型
[蒋薇薇1  , 鲁昌华
, 鲁昌华1, 2 , 张玉钧2 , 鞠薇3 , 汪济洲4 , 偶春生1, * , 肖明霞1 ]
, 鲁昌华, 肖明霞|
|


作者简介: 蒋薇薇, 女, 1978年生, 合肥工业大学计算机与信息学院讲师 e-mail: jiangww@hfut.edu.cn
近年来, 深度学习在数据挖掘领域研究较多, 深度学习中的集成学习算法也越来越多地应用到分类和定量回归中, 但是, 集成学习算法在红外光谱分析领域的应用研究较少。 提出一种基于Blending模型融合的集成学习定量回归算法, 利用GBDT算法、 线性核支持向量机(LinearSVM)和径向基核支持向量机(RBF SVM)作为基学习器, 将基学习器预测结果通过LinearSVM模型完成数据融合。 以公开数据库中的药片和柴油近红外光谱数据为研究对象, 首先对光谱数据进行一阶导数预处理, 分别采用单核支持向量回归模型、 GBDT模型和Blending集成学习模型, 将模型预测结果进行分析比较。 药片活性物含量和硬度性质采用RBF SVM模型的预测结果最优, RMSEP最小, RPD最大; 其次为Blending集成学习模型; GBDT模型预测结果最差。 药片质量采用Blending集成学习模型预测的 R2最高, 达到0.837 4; RBF SVM的RMSEP最小, 为2.140 6, RPD最大, 达到7.487 8; LinearSVM的预测结果最差。 对于柴油沸点、 闪点和总芳香烃三种性质, Blending模型预测效果最好, 优于三种单模型预测结果。 对于十六烷值, GBDT模型和RBF SVM模型预测结果优于Blending集成学习模型。 对于密度, 仅GBDT模型优于Blending集成模型, 并且, 使用单模型和集成模型的预测结果均较为理想, 除了LinearSVM模型 R2为0.944 5, 其他模型 R2均高于0.99。 对于冰点的预测, RBF SVM和LinearSVM的预测效果优于Blending集成学习模型。 对于黏性性质的预测, 仅RBF SVM的预测效果优于Blending集成算法模型。 由结果可以看出, 由GBDT, LinearSVM和RBF SVM集成的Blending模型由于融合了单模型的特征, 与单模型相比, 预测效果较优或者最优, 证明集成学习Blending模型用于红外光谱定量回归具有较强的适用性, 且具有较高的预测精度和泛化能力, 对于进一步研究集成学习算法在红外光谱定量回归中的应用具有重要的意义。
, LU Chang-hua, XIAO Ming-xiaIn recent years, deep learning has been studied more and more in the field of data mining, and the integrated learning algorithm in deep learning has been applied to classification and quantitative regression more and more, but the application of integrated learning in the field of infrared spectrum analysis is little. In this paper, an integrated learning quantitative regression algorithm based on Blending model is proposed. GBDT algorithm, linear kernel support vector machine (LinearSVM) and radial kernel support vector machine (RBF SVM) are used as the basic learners, and the prediction results of the basic learners are fused by LinearSVM. The first derivative preprocessing was carried out for the spectral data. The prediction results of the model were analyzed and compared by using the GBDT, LinearSVM, RBF SVM and the Blending integrated learning model respectively. RBF SVM model is the best model for predicting the content of active substance and hardness, R2 is the highest, the RMSEP is the smallest, and the RPD is the largest, and the GBDT model is the worst. The R2 of tablet quality predicted by Blending model is the highest, reaching 0.837 4, while the RMSEP of RBF SVM is the lowest, 2.140 6, and the RPD of RBF SVM, 7.487 8, is the largest. For the boiling point, flash point and total aromatics of diesel oil, Blending model is the best one, which is better than the single model. For the cetane number, GBDT model and RBF SVM model are better than Blending model. For the density property, the single model and the integrated model have better prediction results, except that the R2 of LinearSVM model is 0.944 5, R2 of other models are all higher than 0.99. For the prediction of freezing point properties, RBF SVM and LinearSVM are both better than Blending model. For the prediction of viscosity, only RBF SVM is better than Blending model. It can be seen from the results that the Blending model integrates the characteristics of GBDT, LinearSVM and RBF SVM model, compared with the single model, the prediction of Blending is better or optimal. It is proved that Blending integrated learning model has strong applicability for infrared quantitative regression, and has a high prediction accuracy and generalization ability. It is of great significance for further research on the application of integrated learning algorithm in infrared quantitative regression.
红外光谱是一种常用的物质定量分析和化合物结构鉴定方法, 当使用红外光谱仪记录物质的光谱信号时, 有机物化合分子会选择性地吸收红外光的某些特定频率的能量, 通过分析被分子吸收后的光谱能够获取光谱对应的样本组分含量或样本性质。 常用的红外光谱定量回归方法有多元线性回归(MLR)、 偏最小二乘(PLS)、 支持向量机(SVM)、 最小二乘支持向量机(LS-SVM), 以及机器学习中的最小绝对收缩和选择算子(LASSO)[1]、 极限学习机(ELM)[2]和卷积神经网络(CNNs)[3]等算法。
近年来, 深度学习算法在数据挖掘领域的研究较为广泛, 深度学习中的集成学习算法如自适应提升(AdaBoost)[4]、 决策树(DT)[5]、 随机森林[6]、 梯度提升决策树(GDBT)[7]等越来越多地应用到分类及定量回归领域。 但是, 集成学习算法及不同集成学习算法的融合模型在红外光谱分析领域的应用研究较少。 李盛芳等利用随机森林对不同类型的水果糖分进行近红外光谱预测, 随机森林模型的预测结果明显优于PLS模型[见本刊2018, 38(6): 112]。 戎念慈等[8]利用可见-近红外多光谱构建以k最近邻算法、 SVM和随机森林为基模型的融合模型, 分析预测血迹年龄, 融合模型预测精度高于单独采用一个算法的模型。 本文提出一种基于Blending模型融合的集成学习定量回归算法, 利用GBDT算法、 线性核支持向量机(LinearSVM)和径向基核支持向量机(RBF SVM)作为基学习器组成算法融合, 探讨Blending模型融合集成学习算法应用于红外光谱定量回归分析的适用性, 以及集成学习模型的泛化能力和回归精度, 为红外光谱定量回归提供借鉴和参考。
数据1: 药片数据(http://www.eigenvector.com/data/tablets/index.html)。 数据集光谱测量区间为600~1 898 nm, 间隔为2 nm, 包括建模集155个样本, 验证集40个样本和测试集460个样本。 将校正集、 验证集、 测试集三部分合在一起, 共655个药片红外光谱数据。
数据2: 柴油数据(http://www.eigenvector.com/data/SWRI/index.html)。 数据集光谱测量区间为750~1 550 nm, 波长间隔为2 nm, 包含784个未经预处理的柴油原始光谱及其7种性质(沸点、 十六烷值、 密度、 闪点、 冰点、 总芳香烃和黏性), 有些样本性质参数有缺失值(NaN), 在对某个性质进行预测建模之前, 先将存在缺失的光谱数据进行剔除。
将有效光谱数据以随机抽样的方式按照90%, 5%和5%的比率分为训练集1、 训练集2和测试集。
导数法光谱预处理可以消除背景干扰、 基线漂移、 区分混叠谱峰, 提高光谱分辨率, 故采用一阶导数法对光谱进行预处理。
采用测定系数(coefficient of determination, R2)、 预测集均方根误差(root mean square error of prediction, RMSEP)和预测相对分析误差(relative percent deviation, RPD)评价模型的性能。
支持向量机(SVM)能够处理分类问题和回归问题, 被用于回归分析时被称为支持向量回归(SVR)。 SVM采用统计学习理论的结构风险最小化原则和VC维理论, 具有拟合度高、 学习能力强、 训练时间短、 选择参数少、 泛化能力好等优点, 为解决小样本、 高维数和非线性等问题提供了有效的工具[9]。
1995年, Freund和Schapire将决策树作为弱学习器提出AdaBoosting算法[4]。 梯度提升决策树(GBDT) 算法是在AdaBoosting的基础上发展演变而来的, 一经推出即被认为是与SVM算法一样具有良好泛化能力的机器学习算法[10], 与SVM算法比较, 调参时间短且准确率高。 GBDT的每棵决策树只学习观测数据的预测残差部分, 不易出现过拟合现象。
Blending集成学习方法考虑的是异质弱学习器, 本工作构建二层Blending模型, 采用GBDT、 LinearSVM和RBF SVM算法作为基学习器, LinearSVM为元模型, 如图1所示。 首先将训练集按比例分为两组: 训练集1和训练集2, 训练集1用于训练第一层基学习器(GBDT, LinearSVM和RBF SVM)产生基模型, 然后将训练集2通过每一个基模型Model1, Model2和Model3产生的预测结果{P1, P2, P3}作为新训练集, 对元模型进行训练, 把测试集经第一层基模型的预测结果{T1, T2, T3}作为新测试集, 如式(1)和式(2)所示, 最后将新测试集通过训练后的元模型生成最终的预测结果。
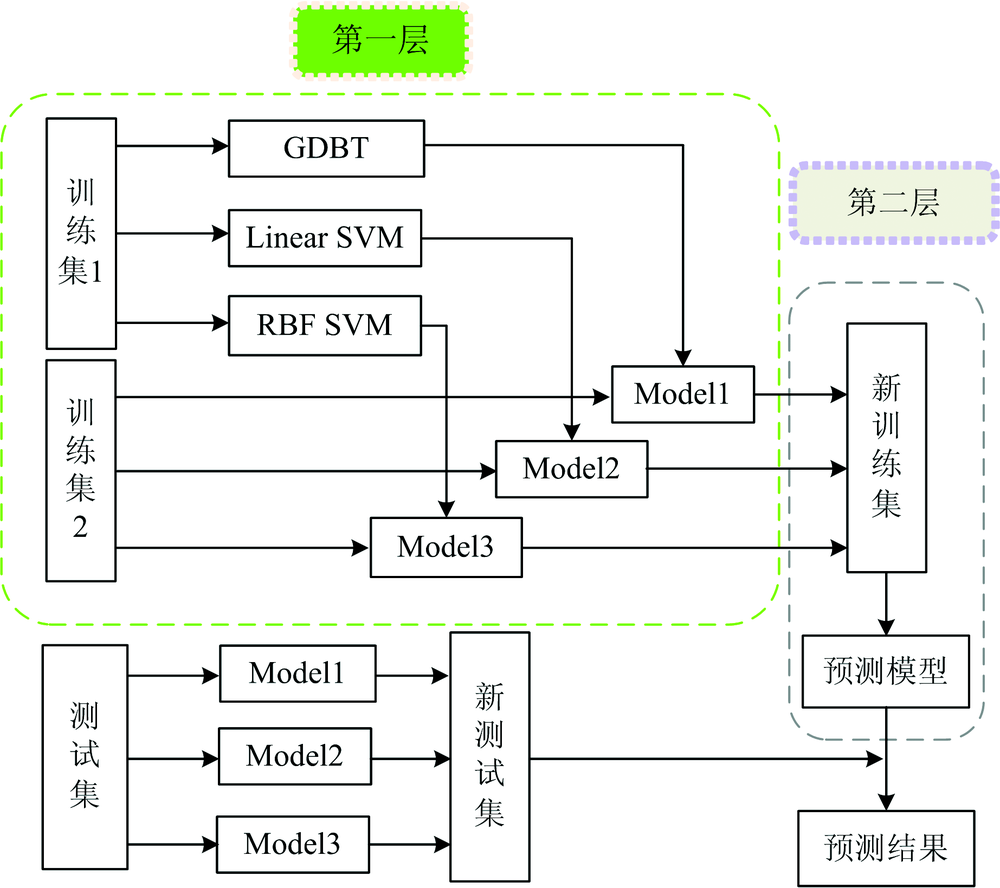 | 图1 Blending集成学习示意图Fig.1 Blending integrated learning diagram |
药片光谱Blending集成学习模型使用训练集1训练三个弱学习器(GBDT, LinearSVM和RBFSVM), 训练集2的预测结果作为新训练集, 测试集经由基模型的预测结果作为新的测试集, 通过LinearSVM元模型得到集成学习预测结果。 Blending模型得到的预测结果是三个模型融合的综合结果, 具有更强的适应性。 为便于比较, 使用药片光谱数据训练集1和训练集2组成的包含光谱数据集95%的数据作为训练集, 分别建立GBDT模型、 LinearSVM模型和RBFSVM模型, 对测试集数据进行预测。 采用四种模型对药片活性物含量、 硬度和质量的预测结果分别如图2、 图3和图4所示, 将三种性质通过不同算法获得的预测结果列于表1。
 | 图2 药片活性物含量预测值与测量值相关关系图Fig.2 Plots of predicted vs. measured active substance content of tablets |
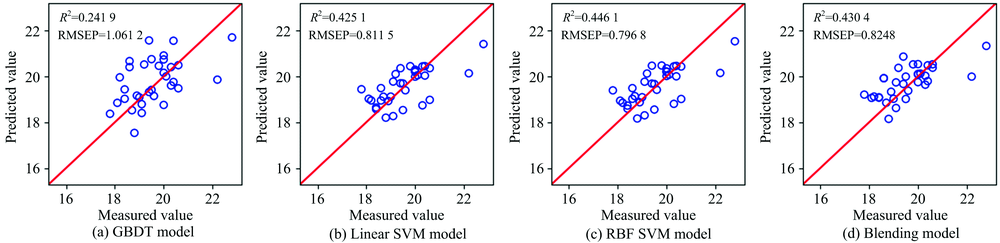 | 图3 药片硬度预测值与测量值相关关系图Fig.3 Plots of predicted vs. measured tablet hardness |
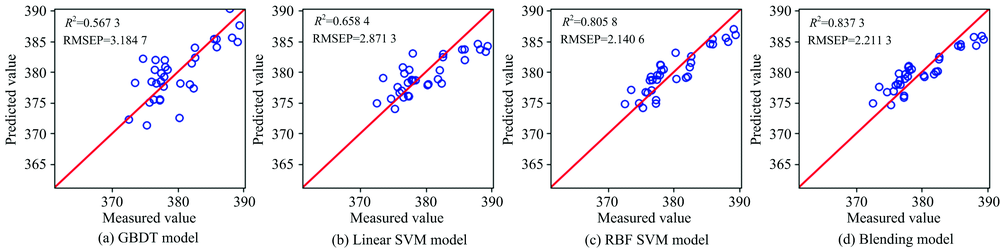 | 图4 药片质量预测值与测量值相关关系图Fig.4 Plots of predicted vs. measured tablet quality |
| 表1 药片性质预测结果 Table 1 Predicted results of tablet properties |
通过图2— 图4和表1可以看出, 对于药片活性物含量和硬度的预测情况, RBF SVM的预测结果最优, R2最高, RMSEP最小, RPD最大; Blending集成模型次之; GBDT算法的预测结果最差。 对于药片质量的预测情况, Blending集成学习算法的R2最高, 达到0.837 4; RBF SVM的RMSEP最小, 为2.140 6, RPD最大, 达到7.487 8; LinearSVM的预测结果最差。
单模型和集成模型对药片活性物含量的预测结果较为理想, R2均高于0.95; 单模型和集成模型对硬度的预测结果均不甚理想; 对质量的预测, Blending集成模型结果明显优于GBDT, LinearSVM和RBFSVM三种单模型预测效果。
采用相同方式, 根据柴油光谱训练集1和训练集2数据建立Blending集成学习预测模型, 对测试集数据进行预测, 同时分别建立GBDT, LinearSVM和RBFSVM模型。 柴油沸点、 十六烷值、 密度、 闪点、 冰点、 总芳香烃和黏性7种性质的预测结果如图5— 图11和表2所示。
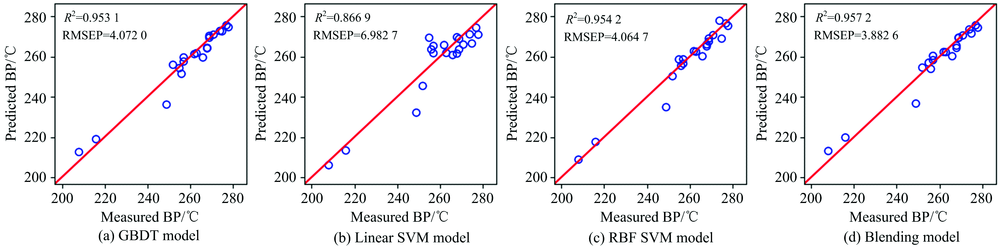 | 图5 柴油沸点预测值与测量值相关关系图Fig.5 Plots of predicted vs. measured boiling point (BP) |
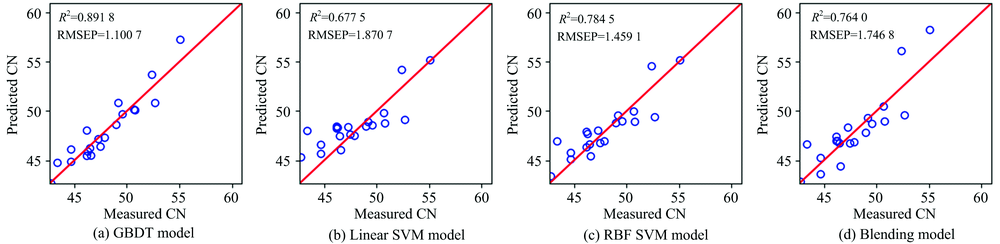 | 图6 柴油十六烷值预测值与测量值相关关系图Fig.6 Plots of predicted vs. measured diesel cetane number (CN) |
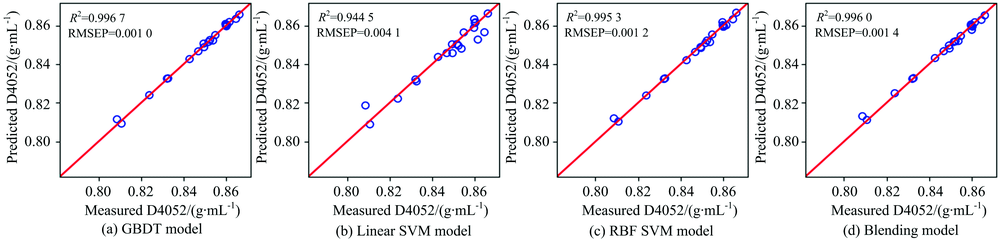 | 图7 柴油密度预测值与测量值相关关系图Fig.7 Plots of predicted vs. measured diesel density (D4052) |
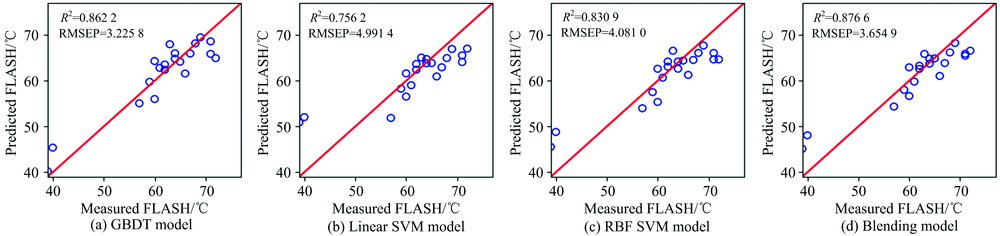 | 图8 柴油闪点预测值与测量值相关关系图Fig.8 Plots of predicted vs. measured diesel flash point (FLASH) |
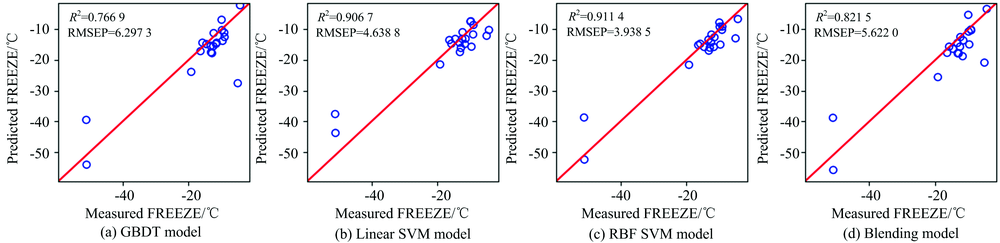 | 图9 柴油冰点预测值与测量值相关关系图Fig.9 Plots of predicted vs. measured diesel freezing point (FREEZE) |
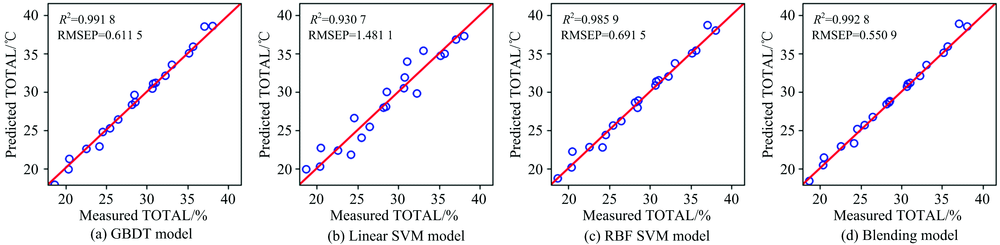 | 图10 柴油总芳香烃预测值与测量值相关关系图Fig.10 Plots of predicted vs. measured diesel total Aromatics (TOTAL) |
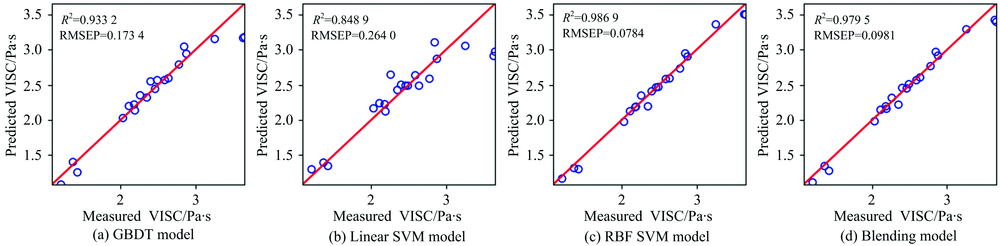 | 图11 柴油黏性预测值与测量值相关关系图Fig.11 Plots of predicted vs. measured diesel viscosity (VISC/Pa-S) |
| 表2 柴油性质预测结果 Table 2 Predicted results of diesel properties |
从图5— 图11以及表2可以看出, 对于沸点、 闪点和总芳香烃三种性质, Blending集成模型预测效果最好, 优于三种单模型预测结果。 对于十六烷值, GBDT模型预测效果最好, 其次是RBF SVM, Blending集成学习模型预测结果仅优于LinearSVM。 对于密度性质, 单模型和集成模型预测结果均理想, 除了LinearSVM模型R2为0.9445, 其他模型R2均高于0.99。 对于冰点性质的预测, RBF SVM的预测效果最好, LinearSVM的预测效果次之, Blending集成学习模型预测结果仅优于GBDT算法。 对于黏性性质的预测, RBF SVM的预测效果最好, 其次是Blending集成学习模型, LinearSVM的预测结果最差。 除了冰点性质之外, 其余性质采用LinearSVM模型进行预测的预测效果均最差, 这可能是由于柴油性质光谱的非线性造成的。
Blending集成学习模型是数据挖掘领域的热门技术, 在红外光谱分析应用研究较少。 构建了采用GBDT, LinearSVM和RBF SVM为基模型, LinearSVM为元模型进行融合的Blending集成学习回归模型。 分别采用对药片和柴油两组近红外光谱建立四种定量分析模型, 预测药片活性物含量、 硬度和质量, 以及柴油沸点、 十六烷值、 密度、 闪点、 冰点、 总芳香烃和黏性。 实验结果表明, Blending集成学习模型由于融合了单模型的特征, 与单模型相比, 预测效果较优或者最优, 至少优于其中一种单模型, 证明了Blending集成学习模型用于红外光谱定量回归具有较强的适用性、 较高的预测精度和泛化能力, 具有在光谱分析领域进一步研究的价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|