



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Kalman滤波与DBN的油脂中TFAs含量近红外光谱分析
[王立琦1  , 陈颖淑
, 陈颖淑1 , 刘雨琪1 , 宋旸2 , 于殿宇3 , 张娜2, * ]
, 陈颖淑]
|
|


作者简介: 王立琦, 1966年生, 哈尔滨商业大学计算机与信息工程学院教授 e-mail: hsdwlq@163.com
针对油脂脱臭过程中的反式脂肪酸(TFAs)含量控制问题, 提出一种基于近红外光谱分析的油脂中TFAs含量快速检测方法。 制备含不同TFAs的大豆油脂样本100个, 利用气相色谱(GC)法精确测定其TFAs含量, 扫描样本近红外光谱, 然后利用不同方法对光谱数据进行降噪处理, 发现多元散射校正的去噪效果最佳。 为了探讨TFAs在近红外区域的吸收特性, 采用多种iPLS方法对比分析, 筛选出7 258~7 443/6 502~6 691/6 120~6 309 cm-1 TFAs的特征波段, 再利用Kalman滤波算法进行特征波长变量的选择, 优选出27个TFAs的特征波长变量; 采用深度信念网络(DBN)建立校正模型, 通过多次对比发现, 当隐含层层数为3并且隐含层节点数为50-35-90时, DBN模型性能最佳。 最后将DBN模型与PLS方法建立的反式脂肪酸含量回归模型进行对比分析, 结果表明: 对降噪后的全谱进行建模, DBN模型的预测效果优于PLS, DBN模型预测集 R2为0.879 4、 RMSEP为0.060 3、 RSD为2.18%; 对筛选出的特征波段建模, PLS模型的预测效果优于DBN模型; 对优选出来的27个特征波长变量建模, DBN的预测效果较好, R2为0.958 4、 RMSEP为0.035 0、 RSD为1.31%, 说明DBN模型的泛化能力更好, 并且利用少量的波长变量就能达到较好的预测效果, 能够满足实际检测需求, 为实现油脂加工过程中TFAs含量的在线检测和调控, 生产低/零TFAs油脂产品提供技术支撑。
In order to control the content of trans fatty acids (TFAs) in the process of oil deodorization, this paper presents a fast method for detecting trans fatty acids (TFAs) content in soybean oil based on near-infrared spectroscopy. First, we prepared 100 soybean oil samples with different TFAs content, and detected precisely the values of TFAs contents by gas chromatography. Then, the near-infrared spectrum of oil samples was scanned and denoised by various methods, and it is found that the denoising effect of MSC was the best. In order to study the characteristic absorption of TFAs in near-infrared region, we used a variety of iPLS methods to select the characteristic band of the spectral data, and the characteristic absorption band of TFAs is selected as 7 258~7 443/6 502~6 691/6 120~6 309 cm-1. On this basis, the Kalman filtering algorithm is used to select the characteristic wavelength variables, and 27 TFAs characteristic wavelength variables are optimized. The deep belief network (DBN) is adopted to construct the correction model, and we found that the performance of the DBN model is the best adopting 3 hidden layers and 50-35-90 hidden layer nodes. Finally, the DBN model with this parameter is compared with the regression model of trans fatty acid content established by PLS. The results show that: when we used the whole denoised spectrum to construct model, the prediction effect of DBN is better than that of PLS, R2 is 0.879 4, RMSEP is 0.060 3 and RSD is 2.18%. When we used the selected characteristic band to model, the prediction effect of the PLS model is better than that of the DBN model. Using the 27 optimized characteristic wavelength variables to construct model, DBN has a good prediction effect, R2 is 0.958 4, RMSEP is 0.035 0 and RSD is 1.31%. It shows that the generalization ability of DBN is better, which achieved better prediction results by using a small number of wavelength variables. The proposed method in this paper can meet the practical needs, and provide technical support for online detecting and regulating TFAs content and producing low/zero TFAs oil products.
近年来, 食用油脂中反式脂肪酸(trans fatty acids, TFAs)含量超标问题已经引起了社会各界的广泛关注[1]。 研究表明, TFAs能促进动脉硬化; 促成Ⅱ 型糖尿病等多种疾病。 1994年, 世界卫生组织发表声明, 提出食品中TFAs含量应控制在4%范围内[2]; 自2006年开始, 美国食品药品监督管理局规定食品中的TFAs含量必须做出标注; 纽约市政府通过法案, 决定从2007年起逐步禁用直至全面封杀餐饮业使用TFAs; 世界卫生组织已给出建议, 认为食品中TFAs含量应在2%以下[3]。
油脂高温脱臭过程中, 随着温度上升、 时间延长, TFAs含量呈上升趋势[4]。 测定油脂中TFAs含量的方法主要有色谱法、 红外光谱法、 毛细管电泳法等[5], 但上述方法只适用于实验室检测, 近红外光谱(near-infrared spectroscopy, NIR)分析技术能够弥补以上检测方法的缺陷, 成为一种快速、 高效、 适合在线分析的有利工具[6]。 莫欣欣[7]等利用NIR技术对超市中的几种食用植物油(菜籽油、 玉米油、 葵花籽油、 花生油、 大豆油、 山茶油、 稻米油、 橄榄油以及调和油)中TFAs含量进行了快速定量检测。 有研究利用近红外漫反射实现了食品中反式脂肪酸的快速测定, 并利用SVM, KNN, PLSDA和SIMCA等方法建立了TFAs的识别模型, 最终发现PLSDA效果最佳。 本文针对大豆油脂加工脱臭过程中TFAs的产生和控制问题, 提出一种基于Kalman滤波和深度信念网络(deep believe net, DBN)的油脂中TFAs含量检测方法, 以期生产出低/零反式脂肪酸油脂产品。
脂肪酸甲酯标准品: 9 t-C18:1, 9 c-C18:1, 9 t, 12 t-C18:2, 9 c, 12 t-C18:2, 9 t, 12 c-C18:2, 9 c, 12 c-C18:2; KOH-甲醇溶液 (2 mol· L-1); 异辛烷(C8H18, 色谱纯); 其他试剂为分析纯; 配备InGaAs检测器的FT-NIR仪, 光源为25 W卤素灯。 直径为8 mm的透明玻璃管; GC-2010气相色谱仪: 配有FID检测器和GC SOLUTION数据处理工作站。
以一级大豆油为原料, 在钯碳催化剂添加量为0.05%~0.14%(Pd-C/oil)、 H2压力为2.5~7 MPa、 反应时间为0.5~2 h、 反应温度为80~160 ℃和搅拌速度为200~600 r· min-1的条件下, 对原料大豆油进行氢化, 再按照一定比例将其添加到一级大豆油中, 制得不同TFAs含量的氢化大豆油样本100个, 每个样本均为50 mg, 然后利用气相色谱仪准确测得100个大豆油样本的TFAs含量为0.1%~6.1%。
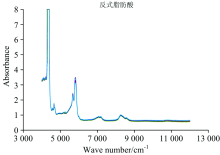
将100个大豆油样本分别注入到直径为8 mm的透明玻璃管中, 再依次放置到Thermo Nicolet Antaris傅里叶变换近红外光谱仪中, 在室温下进行透射扫描, 同时采用相同的空透明玻璃管作为参考。 扫描次数设置为32, 扫描范围4 000~12 000 cm-1, 分辨率4 cm-1, 测量环境的湿度需小于7%, 油脂样本近红外谱图如图1所示。
 | 图1 油脂样本傅里叶变换近红外光谱图Fig.1 FT-near infrared spectrum of oil samples |
首先对近红外光谱数据进行降噪处理, 寻找针对油脂光谱的最佳去噪方法; 然后采用多种间隔偏最小二乘(iPLS)进行油脂特征波段选择, 再利用Kalman滤波算法进行特征波长变量优选; 最后利用深度信念网络(DBN)建立TFAs含量校正模型并对模型进行评估。
1.5.1 样本分集
首先基于100个大豆油样本建立偏最小二乘PLS模型, 根据预测值与实际值的偏差剔除了5个异常样本。 将剩余的95个样本按TFAs含量的多少进行排序, 再根据一定梯度变化从中选取20组数据作为预测集样本, 其余75组作为校正集样本, 在样本的抽取过程中应该确保其分布均匀, TFAs含量的最大值与最小值都应包含在校正集中, 同时使校正集和预测集的均值、 方差尽量相近, 如表1所示。
| 表1 校正集和预测集样本统计结果 Table 1 Statistical results of correction set and prediction set samples |
1.5.2 光谱去噪
为了获得高信噪比、 低背景干扰的光谱数据用于建模, 采用多种方法对原始光谱进行降噪处理[8], 通过对比分析选出最适合的预处理方法, 不同方法去噪效果如表2所示。
| 表2 不同方法去噪效果对比 Table 2 Comparison of denoising effect by different methods |
由表2可知, 采用MSC-SNV方法去噪后的数据建立校正模型时, 校正效果最佳, R2为0.954 4, RMSEC为0.036 1, 但预测效果最好的却是MSC, 其R2为0.865 0, RMSEP为0.063 8, 预测均方根误差最小, 由于建模的最终目的是为了预测, 故采用MSC方法降噪后的数据为后面的研究所用。
通过图1能够观察出, 在4 000~4 420 cm-1波段油脂光谱存在异常吸收, 因此将该区间数据剔除, 然后分别采用iPLS, 反向间隔偏最小二乘(BiPLS)和组合间隔偏最小二乘(SiPLS)对经多元散射校正(MSC)降噪后的4 420~12 000 cm-1全谱数据进行波段选择, 不同方法筛选出的特征波段建模结果如表3所示。
| 表3 不同方法筛选出的特征波段建模结果 Table 3 Modeling results using characteristic bands selected by different methods |
由表3可以看出, 利用SiPLS方法筛选出的3个特征波段组合建模效果最佳, R2为0.984 7, RMSECV最小, 为0.027 6。 因此, 在SiPLS方法选择出的特征波段基础上进行后续特征波长变量优选。
通过SiPLS筛选出来的特征波段为7 258~7 443/6 502~6 691/6 120~6 309 cm-1, 共包含149个波长变量, 然后采用本研究提出的Kalman滤波法对此特征波段进行特征波长变量优选, 以期进一步提高建模效率。
在近红外光谱分析中, 光谱数据X和样本性质数据Y之间的线性模型如式(1)
式(1)中, B为待求解的系数矩阵, 利用Kalman滤波不断优化B, 直到误差减小到满足要求为止, 如式(2)— 式(4)
式中, k=1, 2, …, m, m为样本个数; bk是系统状态向量; yk是观测数据向量; X(k)是方程的系数矩阵; pk是B的估计误差协方差; Sw是系统过程误差协方差; Sz是系统的测量误差协方差; Kk是卡尔曼增益。 通过式(2)— 式(4)能够求解出模型参数B的估计值和B的估计误差协方差P。
利用Kalman滤波选择特征波长变量, 算法如下:
第一步: 计算B和P;
第二步: 计算B的估计误差的标准差, 即$\sqrt{P}$
第三步: 计算B/$\sqrt{P}$的绝对值, 此比值代表了波长变量对于模型的重要程度;
第四步: 利用PLS建模, 将B/$\sqrt{P}$绝对值排序后按照从大到小的顺序将对应的波长变量输入到模型中, 直到达到满意的预测效果为止。
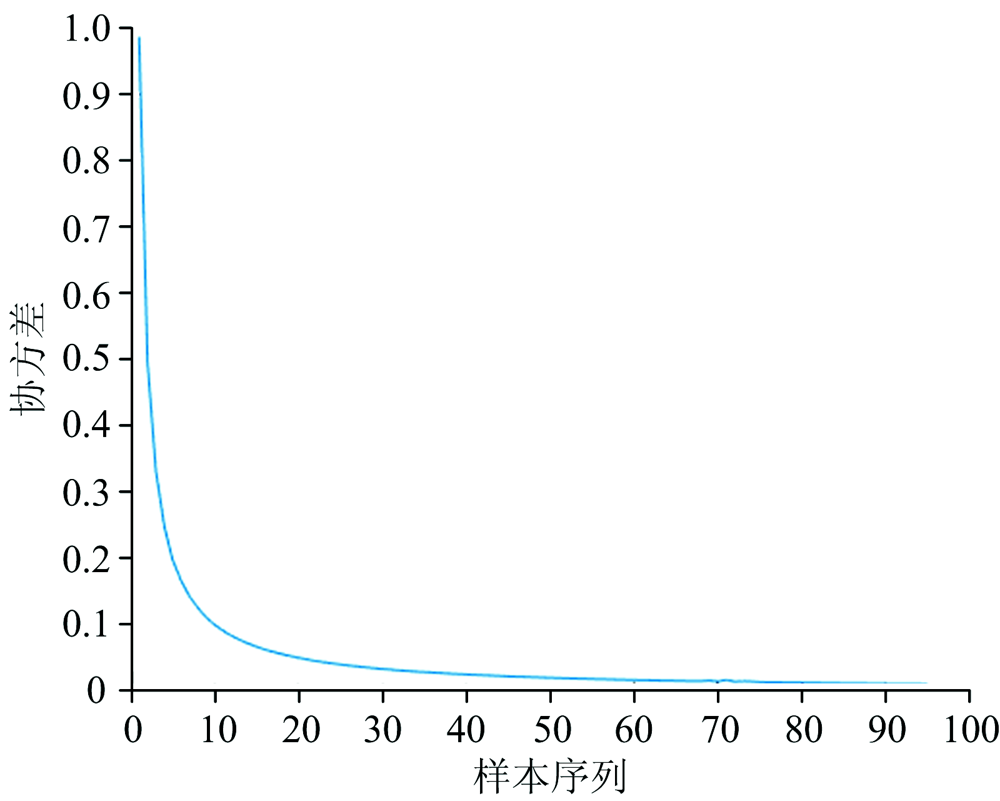
卡尔曼滤波迭代结果如图2所示。
 | 图2 Kalman滤波迭代结果Fig.2 Iterative results of Kalman filtering |
由图2可见, 模型的协方差随着样本依次加入逐渐减小, Kalman滤波收敛, 证明了算法的有效性。 模型精度随波长变量增加的变化趋势如图3所示。
 | 图3 模型精度变化趋势Fig.3 Trend of model accuracy |
由图3能够看出, 当不断地将波长变量输入到模型中时, PLS模型的RMSEC和RMSEP都存在着明显的下降趋势, 当输入的波长变量数达到27时, PLS模型的RMSEP数值最小, 但是, 当再次增加输入波长变量个数时, RMSEP反而有上升的趋势, 说明此时模型已经出现了过拟合现象, 无需再增加波长变量。 因此只利用这27个波长变量进行建模, 最终校正集R2为0.981 3、 RMSEC为0.031 7, 预测集R2为0.950 4、 RMSEP为0.056 2, 通过与149个波长变量的建模效果进行对比, 两者效果相当, 但是利用27个波长变量建模明显减少了计算量, 大大提高了检测效率, 减少开发专用仪器的硬件成本。 经Kalman滤波优选出的油脂反式脂肪酸特征波长变量如图4所示。
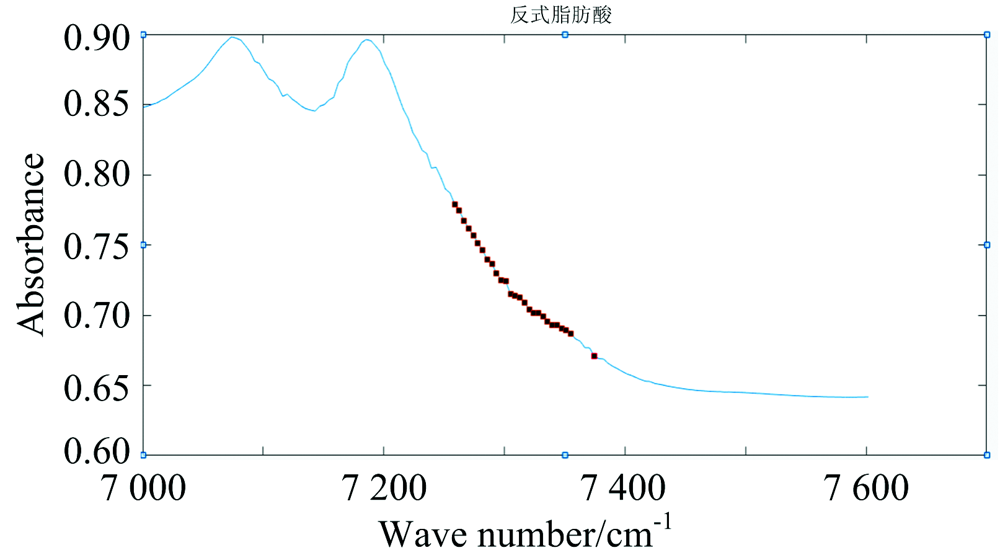 | 图4 Kalman滤波优选出的27个波长变量Fig.4 27 wavelength variables selected by Kalman filtering |
2.3.1 DBN模型结构
DBN由Geoffey Hinton教授在2006年提出, 具有深层网络结构和非线性激活功能[9]。 近年来, DBN已经成功应用于语言处理、 文本分类和图像识别等领域, 但在近红外光谱数据分析方面鲜有报道。 王静[10]等将DBN和SVM相结合, 建立了近红外光谱多分类模型。 Yang[11]等利用带漏检机制的DBN对近红外光谱进行建模, 漏检能够克服小样本的过拟合问题, 实验证明该方法能够有效鉴别药物, 相比于BP神经网络、 支持向量机等算法效果更佳。
DBN由多层节点构成, 其结构如图5所示。 从结构上看, DBN就是由一层有监督BP和多层无监督RBM组成的一种半监督学习网络[12]。
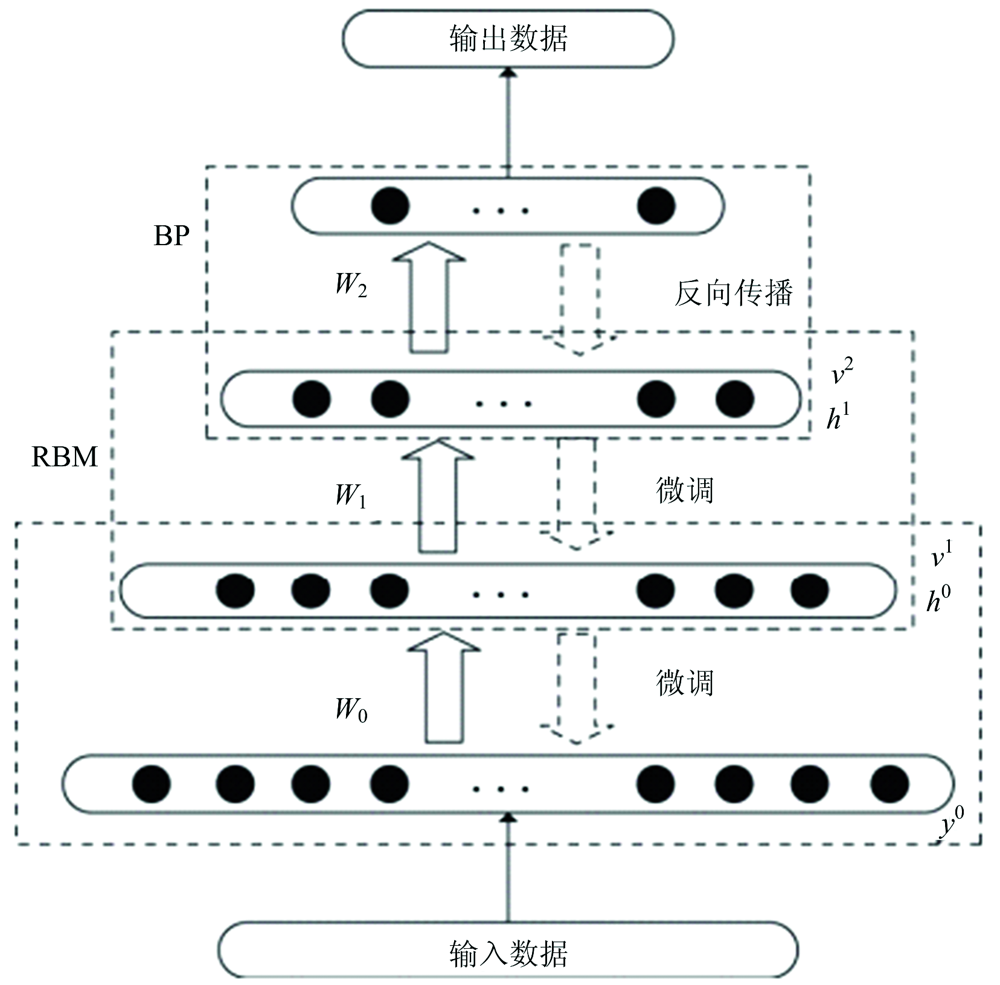 | 图5 DBN模型结构Fig.5 Structure of DBN model |
2.3.2 DBN模型参数设置
在DBN中隐层数量的设置取决于具体的样本, 利用训练样本去测试DBN的隐层数量。 选择3种不同DBN隐含层层数, 分别测其对DBN模型性能的影响, 结果如表4所示。
| 表4 隐含层层数的选择 Table 4 Selecting number of hidden layers |
由表4可见, 当隐含层层数为3时, DBN模型的预测结果最佳, 相关系数R2达到0.900 3, 预测误差均方根RMSEP为0.054 8, 相对标准偏差RSD为2.04%。
不同的隐含层节点设置对DBN模型的建模效果影响极大, 分别选择10种不同组合的隐含层节点数, 通过比较分析, 找到适合的隐含层节点设置方式, 结果如表5所示。
| 表5 隐含层节点数的选择 Table 5 Selecting number of hidden layer nodes |
由表5可以看出, 当隐含层节点数设置过多或者过少时, 预测集的R2都很低, RMSEP和预测集RSD相对较高, 说明隐含层节点数过高或者过低都会降低模型的性能, 通过多次试验对比分析, 当隐含层节点数为50-35-90时, 预测集R2达到0.958 5, RMSEP为0.035 0, RSD为1.31%, DBN模型性能最优。
通过上述研究, 确定了DBN回归模型的参数, 将隐含层层数设定为3, 隐含层节点数设置为50-35-90, 分别对全谱、 筛选出的特征波段和优选出的特征波长变量建立DBN模型并预测, 同时与PLS模型对比分析, 评价模型的预测效果, 如表6所示。
| 表6 DBN及PLS模型比较 Table 6 Comparison between DBN and PLS models |
由表6可见, 对MSC降噪后的全谱进行建模, 虽然PLS模型的校正效果比DBN好, 但是DBN模型的预测效果却优于PLS, 决定系数R2为0.879 4, 预测误差均方根RMSEP为0.060 3、 相对标准偏差RSD为2.18%, 说明DBN模型的泛化能力更好; 对SiPLS筛选出来的特征波段建模, PLS模型的校正和预测效果均优于DBN模型, 预测集R2为0.980 9, RMSEP为0.023 9、 相对标准偏差RSD为0.89%; 对Kalman滤波优选出来的27个特征波长变量建模, DBN模型预测集的R2为0.958 4, 预测误差均方根RMSEP为0.035 0, 相对标准偏差RSD为1.31%, 比PLS模型效果略好, 虽然比基于特征波段的PLS模型差, 仅用了27个波长变量, 大大降低了模型的复杂度和计算量, 提高了模型的稳定性, 可为专用油脂TFAs近红外分析仪器的开发节省硬件成本。
利用近红外光谱分析实现了油脂中TFAs含量的快速检测, 采用多种iPLS方法对光谱数据进行特征波段选择, 筛选出的特征波段组合共包含149个波长变量; 利用Kalman滤波算法进一步优选出27个特征波长变量; 然后利用深度信念网络DBN建立回归模型并与经典的PLS模型进行对比分析, 发现基于DBN的回归模型效果更佳, 利用27个特征波长变量建模, 相对标准偏差RSD为1.31%, 满足实际检测要求, 可以应用于油脂脱臭工艺中TFAs含量快速检测和调控, 为提升油脂加工智能化水平奠定基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|