{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
谱聚类结合LIF在矿井突水水源类型识别中的应用
[周孟然 , 宋红萍
, 宋红萍* , 胡锋, 来文豪, 王锦国]
, 宋红萍, 胡锋, 来文豪, 王锦国]
|
|


作者简介: 周孟然, 1965年生, 安徽理工大学电气与信息工程学院教授 e-mail: mrzhou8521@163.com
突水事故威胁井下人员的生命安全和造成财产损失, 因此准确检测出突水水源类型具有重大意义。 使用水化学分析法检测水源类型耗时长、 过程复杂。 激光诱导荧光(LIF)技术具有快速、 灵敏、 干扰小等优点, 将LIF技术结合智能算法建立突水水源识别模型可以准确检测出突水水源的类型。 目前这类模型一般需要对荧光光谱进行去噪、 降维、 波段选取等处理, 过程繁琐, 并且模型都是在均匀分组的突水水源荧光光谱上建立的, 并没有讨论不均匀分组对模型的影响, 也没有针对不均匀分组建立模型。 在实际工程应用中, 采集的样本数量是有很大概率呈现不均匀的, 因此本文提出一种飞蛾扑火(MFO)算法结合谱聚类(SC)的方法实现对不均匀分组的突水水源荧光光谱的识别。 实验中, 首先从淮南煤矿获取5种实验水样, 使用激光诱导荧光实验设备采集所有水样的荧光光谱, 五种水样的组数分别为75, 80, 80, 30和135。 其次, 建立MFO-SC水样识别模型, 通过对比后标签映射方式选择K-Means、 相似矩阵的计算方式选择高斯核函数和划分准则选择ncut, 用MFO对高斯核函数的参数寻优得到 σ的值为1.745并且固定模型的初始聚类中心。 随后, 分别建立K-Means, SVM和MFO-SVM3种水样识别模型。 对比MFO-SC模型与K-Means模型, 得到MFO-SC模型的最优准确率为100%且平均准确率也为100%, K-Means模型的最优准确率为99.75%, 而平均准确率为79.57%; 再分别计算SVM模型和MFO-SVM模型的训练集准确率和测试集准确率, SVM模型训练集准确率为80%, 测试集准确率为80%; MFO-SVM模型训练集准确率为100%, 测试集准确率为95.625%。 最后, 使用4种模型对其他三个不均匀分组的突水水源荧光光谱进行识别, 研究结果表明将MFO-SC算法用于突水水源类型的识别上是有效的, 可以准确地检测出突水水源的类型, 对煤矿生产安全有重要意义。
Water inrush accidents threaten the lives of people and cause property damage. Therefore, it has great significance in accurately detecting the type of water inrush. Hydrochemical analysis method takes a long time and has a complicated process to detect the type of water inrush. Laser-induced fluorescence (LIF) technique has the advantages of fastness, high sensitivity, and low interference. Water inrush source recognition model building with LIF technique and intelligent algorithms can accurately detect the type of water inrush. At present, such models generally require de-noising, dimension reduction, and band selection on the fluorescence spectra, and this process is complicated. The models are built on the fluorescence spectra of the water inrush source which is evenly grouped. The influence of the uneven grouping on the model is not discussed, and the model is not built for the uneven grouping. In practical engineering applications, the number of samples collected is highly likely to be uneven, so Moth-flame optimization (MFO) algorithm combined with spectral clustering (SC) is proposed to realize the uneven grouping of water inrush fluorescence spectrain this paper. In the experiment, firstly, five kinds of experimental water samples were obtained from Huainan coal mine. Laser-induced fluorescence experimental equipment was used to collect fluorescence spectra of all water samples. The number of groups of five water samples is 75, 80, 80, 30 and 135. Secondly, build MFO-SC water sample recognition model. After comparison, K-Means is selected for the label mapping method, the Gaussian kernel function is selected for the calculation method of the similarity matrix, and the ncut is selected for the partition criterion. The parameters of the Gaussian kernel function were optimized by using MFO to obtain the parameter value of 1.745, and the initial clustering center of the model was fixed. Subsequently, build three water sample recognition models of K-Means, SVM and MFO-SVM, respectively. Comparing the MFO-SC model with the K-Means model, the optimal accuracy of the MFO-SC model is 100%, and the average accuracy is 100%. The optimal accuracy of the K-Means model is 99.75%, and the average accuracy is 79.57%. Then calculate the training set accuracy and test set accuracy of the SVM model and MFO-SVM model respectively. The accuracy of the training set of the SVM model is 80%, and the accuracy of the test set is 80%; the accuracy of the training set of the MFO-SVM model is 100%, and the accuracy of the test set is 95.625%. Finally, four models were used to identify water inrush fluorescence spectra of the other three uneven groups. The research results show that the MFO-SC algorithm is effective in identifying the type of water inrush, and can accurately detect the type of water inrush, which has great significance on the safety of coal mine production.
随着煤矿开采深度的增加, 矿井突水问题越来越严重[1], 一旦发生矿井突水事件, 带来的不只是经济损失, 更严重的是造成井下人员伤亡。 因此, 建立突水预警模型和水样识别模型已经成为治理突水的关键。 目前突水水源类型识别方法主要利用水化学分析法[2, 3]和智能算法[4, 5]等。 利用水化学方法来识别突水水源类型, 需要检测pH值和电导率等, 获取这些变量通常需要较长的时间, 虽然可以比较准确地检测出矿井突水的水源类型, 但是不适合在现场建立水样识别模型。 激光诱导荧光技术具有分析精度高、 速度快等特点, 在化工、 医学、 环境等领域有很多的应用[6, 7, 8]。 近些年来, 也有许多人将激光诱导荧光技术应用于突水水源类型的识别, 具有很好的应用效果。 如: 文献[9]使用激光诱导荧光技术、 间隔偏最小二乘法(interval PLS, iPLS)结合粒子群(particle swarm optimization, PSO)联合支持向量分类算法(PSO-SVC)对突水水源的类型进行识别, 先用iPLS对水样的荧光光谱进行波段选取, 然后使用PSO-SVC对选取的波段进行识别, 实现对突水水源类型的识别。 此外还有使用主成分分析法[10](principal component analysis, PCA)等算法建立水样识别模型对突水水源的荧光光谱进行识别, 然而这些模型都是在突水水样荧光光谱进行均匀分组的基础上进行识别, 并没有对不均匀分组进行讨论, 也没有针对不均匀分组建立水样识别模型。 只有在理想情况下, 每种样本的数量才会是均匀分组的。 在实际的工程应用中, 采集的每种样本数量有很大可能是不均匀的, 因此本文在不均匀分组上建立模型更具有工程应用指导意义。
谱聚类[11](spectral clustering, SC)属于无监督学习, 可以实现对任意形状的数据集的聚类, 计算量较小、 实现简单、 聚类效果好并能很快收敛于全局最优解。 文献[12]是使用模糊估计谱聚类实现对癌症的检测。 飞蛾扑火算法[13](moth-flame optimization, MFO)是近几年提出来的优化算法, 具有参数少、 计算精度高等特点。
本文提出一种将激光诱导荧光与MFO-SC算法相结合建立水样识别模型, 先建立MFO-SC水样识别模型, 然后与其他模型进行性能对比, 最后在其他不均匀数据上进行验证。 MFO-SC水样识别模型在不需较多的先验知识前提下, 不需要对突水水源荧光光谱进行去噪、 降维、 波段筛选等处理, 过程简单, 可以直接对不均匀分组的突水水样荧光光谱进行识别, 准确率高, 具有很强的泛化能力。
根据淮南谢一矿突水水源的特点, 科学的选取了危害性较大的老空水、 砂岩水以及按一定体积比的老空水和砂岩水的混合水作为实验的研究对象, 并对水样进行密封和遮光处理, 带回实验室。 以2019年7月7号在淮南某矿区采集到的老空水、 砂岩水并按一定体积比混合后得到5种实验样本, 依次为老空水与砂岩水体积比为2∶ 1的混合水(以下简称“ 混合水1” )、 老空水与砂岩水体积比为1∶ 1的混合水(以下简称“ 混合水2” )、 老空水与砂岩水体积比为1∶ 2的混合水(以下简称“ 混合水3” )、 老空水和砂岩水。
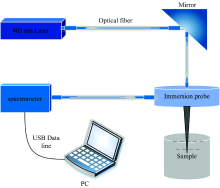
实验所选用的光谱仪是USB2000+光谱仪, 光谱仪检测荧光光谱的波长范围为340~1 021 nm, 激光由405 nm激光器提供。 激光通过石英光纤由FPB-405-V3型荧光探头垂直浸入实验水样中, 激光诱导水样发出的荧光由荧光探头接收传送给光谱仪。 实验采集荧光光谱的实验示意图如图1所示。
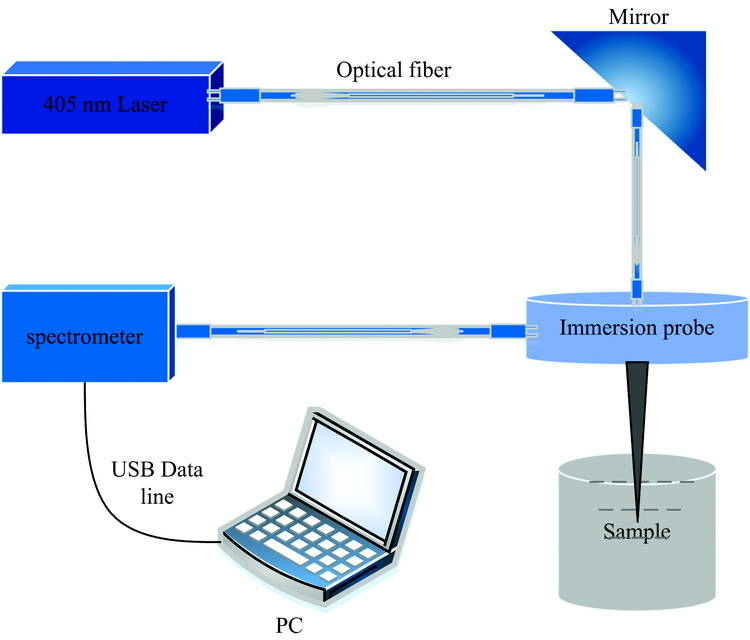 | 图1 激光诱导荧光实验示意图Fig.1 Schematic diagram of laser induced fluorescence experiments |
1.3.1 SC算法
谱聚类(SC)是一种无监督学习算法, 不需要样本的标签信息、 不需要对样本进行去噪、 降维、 波段选取等处理且能在任意形状的样本空间上聚类且收敛于全局最优解。 谱聚类将聚类转化为图的最优划分, 主要思想是将样本看作图中的点, 用边将点连接组成图, 计算两点之间的边权重, 最后对图进行分割, 分割后不同子图间的边权重和尽可能的低, 子图内的边权重和尽可能的高, 从而完成聚类。
谱聚类的算法流程:
输入: 样本集D=(X1, X2, …, Xn), 相似矩阵的计算方式, 划分准则, 标签映射的方法, 类别数K。
过程:
Step 1: 根据输入的相似矩阵的计算方式构建样本的相似矩阵S。
Step 2: 根据相似矩阵S构建邻接矩阵W, 构建度矩阵D。
Step 3: 构建拉普拉斯矩阵L, 根据输入的划分准则对L进行规范化得到矩阵L'。
Step 4: 计算矩阵L'最大的K个特征值各自对应的特征向量f。
Step 5: 将各自对应的特征向量f组成矩阵F, F按行标准化得到特征矩阵F'。
Step 6: 将F'的每一行作为一个新样本, 用输入的聚类方法进行聚类, 聚类的类别数为K。
Step 7: 得到簇划分C(C1, C2, …, Ck)。
输出: 簇划分C(C1, C2, …, Ck)。
1.3.2 MFO算法
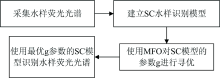
飞蛾扑火算法(MFO)是一种元启发式优化算法, 它的灵感来源于自然界中飞蛾的横向定位导航方法。 根据飞蛾与火焰保持固定的飞行角度的行为建立合理的数学模型。 每个飞蛾都是潜在的最优值, 飞蛾在解空间中的位置是所求问题的解, 飞蛾围绕火焰寻优并通过迭代的方式更新位置, 直至得到问题解的最优值。 使用SC算法对矿井突水水源荧光光谱数据建立模型后, 使用MFO算法对荧光光谱数据进行寻优的实验框图如图2所示。
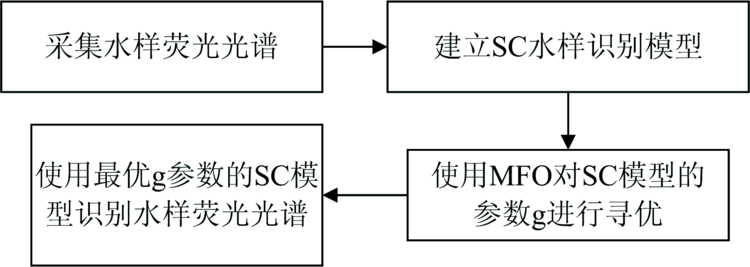 | 图2 MFO优化SC的实验框图Fig.2 Experimental block diagram of MFO optimized SC |
利用激光诱导荧光实验设备采集实验水样的荧光光谱, 实验在遮光、 同等温度和湿度的环境下进行, 5种水样采集的组数各不相同, 混合水1采集75组、 混合水2采集80组、 混合水3采集80组、 老空水采集30组以及砂岩水采集135组。
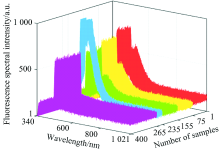
图3为400组的实验水样的原始荧光光谱图, 1— 75为混合水1、 76— 155为混合水2、 156— 235为混合水3、 236— 265为老空水、 266— 400为砂岩水。 从图3上可以很明显的看到不同实验水样的荧光光谱有所不同, 差异主要集中在400~650 nm之间, 并且老空水荧光光谱与其他实验水样的差异比较明显, 混合水1、 混合水2、 混合水3和砂岩水荧光光谱的差异相对较小。 因此, 很难通过观察去区分实验水样的类别, 需要研究实验水样的荧光光谱, 利用智能算法建立水样识别模型对实验水样进行识别。
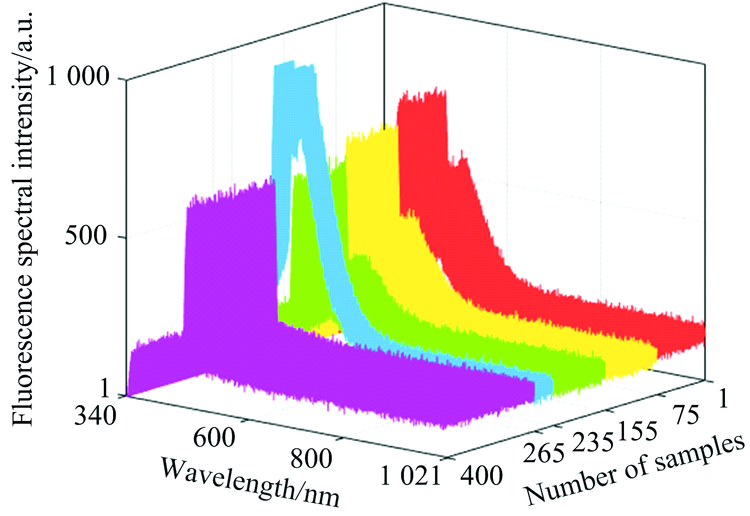 | 图3 原始荧光光谱图Fig.3 Original fluorescence spectra |
本文在建立模型时, 通过大量实验发现标签映射更能影响SC算法的性能, 因此建立模型时需要先确定标签映射的方式, 最后确定相似矩阵的计算方式和划分准则。
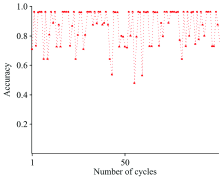
由于K-Means具有原理简单、 实现方便和收敛速度快等优点, 所以选用K-Means作为标签映射的方法。 实验对比了常见的6种核函数作为谱聚类的相似矩阵计算方式的性能最终选择高斯核函数作为相似矩阵的计算方式, 模型的划分准则选择ncut。 建立MFO-SC模型时高斯核函数的参数σ 设为5, 使用MFO-SC模型对实验水样的荧光光谱进行识别, 图4是实验100次模型准确率的变化图。 准确率在47.75%到96.25%之间来回波动, 虽然均值为86.29%, 但是波动的幅度较大。 原因是模型在进行识别时, 随机选择初始聚类中心导致模型最终的聚类中心不准确从而影响聚类的效果, 因此模型需要固定初始聚类中心, 选择准确率为96.25%的聚类中心作为模型的初始聚类中心, 初始聚类中心如表1所示。
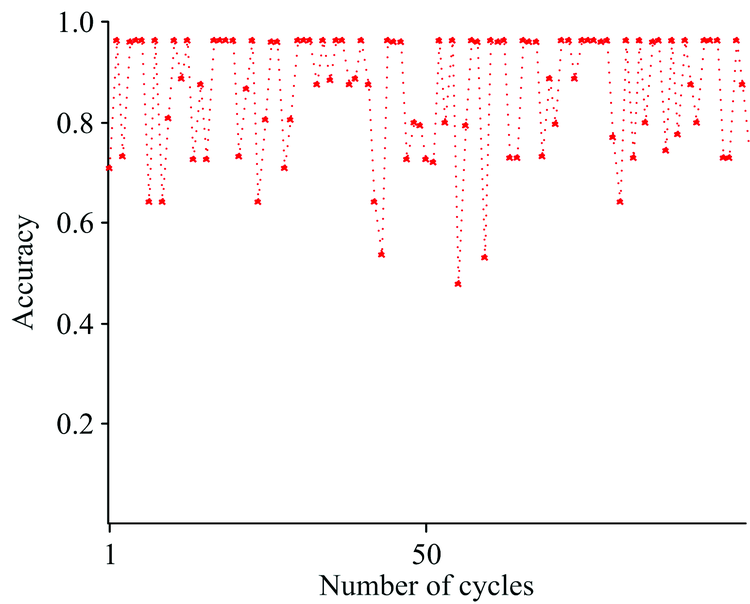 | 图4 未固定初始聚类中心的MFO-SC模型准确率的变化图Fig.4 Change diagram of accuracy of MFO-SC model without fixed initial clustering center |
| 表1 MFO-SC模型初始聚类中心 Table 1 Initial clustering centers of MFO-SC model |
高斯核函数的参数σ 对MFO-SC模型的准确率息息相关, 使用MFO寻优算法对高斯核函数的参数σ 进行寻优。
MFO进行参数寻优时, MFO的飞蛾数设为10, 火焰数设为10, 选择合理的寻优范围, 最大迭代次数设为50次。 得到高斯核函数的参数σ 最优值为1.745, 并且模型的准确率达到100%。
2.3.1 MFO-SC水样识别模型与K-Means水样识别模型对比
使用MATLAB软件建立K-Means水样识别模型。 针对实验水样, 使用K-Means水样识别模型和MFO-SC水样识别模型对其进行识别, 实验100次。 两个模型平均准确率、 最优准确率和准确率方差如表2所示。
| 表2 K-Means模型和MFO-SC模型性能比较 Table 2 Performance comparison of K-Means model and MFO-SC model |
从表2我们可以看到K-Means水样识别模型的最优准确率可以达到99.75%, 但是平均准确率只有79.57%, 而MFO-SC水样识别模型的最优准确率可以达到100%, 而且平均准确率也达到了100%, 通过比较可以看出MFO-SC水样识别模型稳定性更好, 识别率更高。
2.3.2 MFO-SC水样识别模型与监督学习水样识别模型对比
针对实验水样建立了两种基于监督学习算法的水样识别模型, 分别是SVM水样识别模型和MFO-SVM水样识别模型, 在建立模型之前需要合理的将实验水样划分成训练集和测试集, 经过多次实验, 最终将5种共400组实验水样按3∶ 2的比例划分为训练集和测试集, 训练集和测试集的划分结果如表3所示。
| 表3 实验水样数据集的划分 Table 3 Classification of experimental water sample data sets |
先使用MATLAB软件的libsvm工具箱建立SVM水样识别模型, SVM的惩罚系数和核函数参数g使用默认值。 然后使用libsvm工具箱建立MFO-SVM水样识别模型, 使用MFO寻优算法对SVM的c和g参数进行寻优, 飞蛾数设为10, 火焰数设为10, 最大迭代次数设为100次, c参数的范围设为[0.01, 50], g的参数范围设为[0.01, 50], 得到参数的最优值c=0.374 2, g=0.01。 最后使用SVM水样识别模型和MFO-SVM水样识别模型对实验水样的荧光光谱进行识别, 两种模型的训练集准确率和测试集准确率如表4所示。
| 表4 SVM模型和MFO-SVM模型的性能比较 Table 4 Performance comparison of SVM model and MFO-SVM model |
从表4我们可以看到使用SVM水样识别模型对实验水样的荧光光谱进行识别, 训练集的准确率为80%, 训练集的准确率较低说明模型的参数选择不合理。 SVM水样识别模型的测试集准确率也为80%, 如图5所示模型之所以将不属于砂岩水的实验水样误识别为砂岩水, 是因为400组实验水样中砂岩水有135组, 训练模型时训练集的240组实验水样砂岩水有81组, 不均衡分组导致训练好的模型在识别时更加倾向把实验水样分到训练集中实验水样组数更多的类型, 导致测试集的准确率不理想, 建立的模型不合理。 而使用MFO-SVM水样识别模型对实验水样的荧光光谱进行识别时, 使用MFO对参数进行寻优, 使得训练集的准确率达到100%同时测试集的准确率也达到了98.75%。 SVM水样识别模型和MFO-SVM水样识别模型在对不均匀分组的实验水样进行识别时都需要合理的划分测试集和训练集, 过程复杂, 需要较多的先验知识并且两种模型的准确率都小于MFO-SC水样识别模型的准确率。
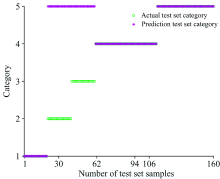
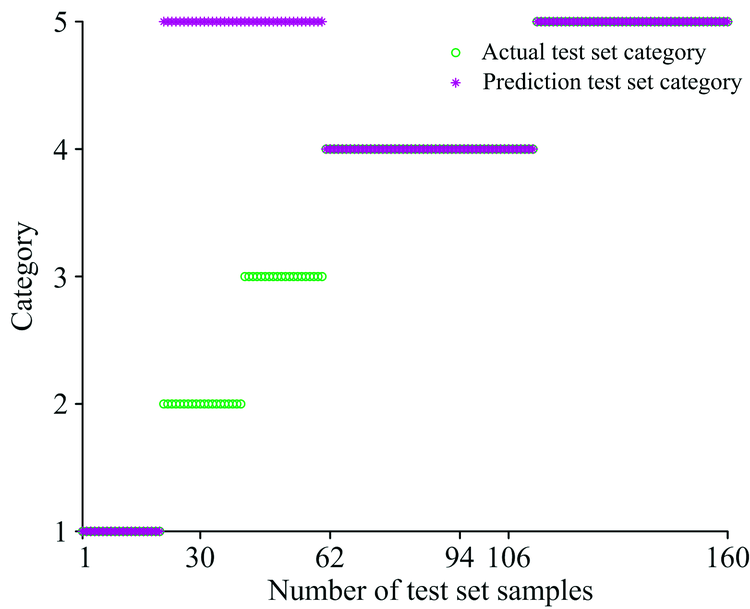 | 图5 SVM水样识别模型测试集的分类结果Fig.5 Classification results of SVM model test set |
2.3.3 在其他不均匀分组实验水样上的验证
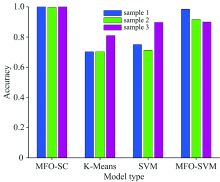
合理的对采集好的5种水样进行分组, 并且保持实验水样的总组数为400组, 得到3组不同的实验水样即水样1、 水样2和水样3。 使用建立好的四种水样识别模型分别对水样1、 水样2和水样3进行识别, 实验100次, 其平均准确率如图6所示, 使用SVM和MFO-SVM建立的水样识别模型的平均准确率是指测试集与训练集分类正确的实验样本与总实验样本数的比值。
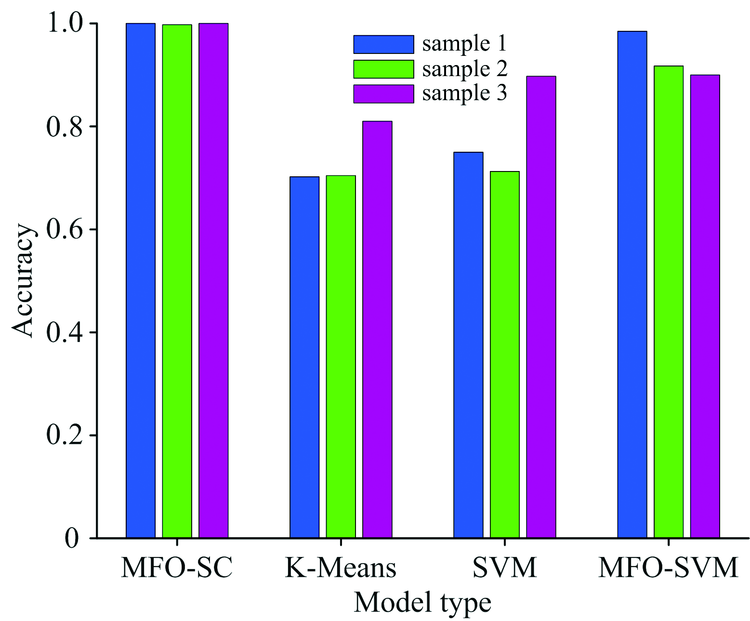 | 图6 四种模型平均准确率对比图Fig.6 Comparison chart of average accuracy of four models |
从图6我们可以看到在3组水样数据集上MFO-SC水样识别模型的平均准确率都是最高的, K-Means水样识别模型的平均准确率都是最低的, 并且在水样1上MFO-SVM水样识别模型的平均准确率高于SVM水样识别模型而在水样3上SVM水样识别模型的平均准确率要高于MFO-SVM水样识别模型。 针对3组水样, 4种模型的平均准确率都出现波动, MFO-SC水样识别模型的波动最小, MFO-SVM水样识别模型次之, K-Means水样识别模型和SVM水样识别模型的平均准确率波动最大, 说明K-Means水样识别模型、 SVM水样识别模型和MFO-SVM水样识别模型的泛化能力比MFO-SC水样识别模型较弱, MFO-SC水样识别模型的稳定性更好。
根据淮南煤矿突水水源的特点, 选取老空水、 砂岩水以及按一定体积比的老空水和砂岩水的混合水作为实验的研究对象, 先选取MFO-SC算法针对不均匀分组的水样荧光光谱建立水样识别模型, 然后将MFO-SC水样识别模型与另外三种水样识别模型进行了比较。 通过实验可以发现: 第一, 建立合理的MFO-SC水样识别模型可以很好的识别出不均匀分组的水样荧光光谱, 并且识别率可以达到100%; 第二, MFO-SC和K-Means都属于无监督学习算法, 都不需要划分数据集, 与K-Means水样识别模型相比, 使用MFO-SC水样识别模型的稳定性更好, 准确率更高。 使用监督学习算法SVM和MFO-SVM建立水样识别模型相对于MFO-SC水样识别模型来说需要合理划分数据集, 过程复杂, 并且识别的准确率都要低于MFO-SC水样识别模型的准确率; 第三, 通过验证, 使用MFO-SC建立水样识别模型对其他不均匀分组的水样荧光光谱的识别率均达到99%以上, 明显高于其他三种水样识别模型, 说明MFO-SC水样识别模型具有更好的泛化能力。 实验证明了使用MFO-SC算法建立水样识别模型具有可行性, 对识别矿井突水水源以及矿井安全生产有重大意义。 本文采用的MFO-SC水样识别模型不仅可以用于老空水、 砂岩水以及按一定体积比的老空水和砂岩水的混合水的水样识别, 也可以用于其他突水水源荧光光谱的识别, 同时也为激光诱导荧光技术在其他领域上的应用提供了一种简单、 有效的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|