

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于DCGAN的拉曼光谱样本扩充及应用研究
[李灵巧1, 2 , 李彦晖2  , 殷琳琳
, 殷琳琳4 , 杨辉华1, 2, * , 冯艳春3 , 尹利辉3 , 胡昌勤3 ]
, 殷琳琳, 冯艳春|
|


作者简介: 李彦晖, 1994年生, 桂林电子科技大学计算机与信息安全学院硕士研究生 e-mail: 1703201023@mails.guet.edu.cn
拉曼光谱检测方法依赖于化学计量学算法, 深度学习是当下最炙手可热的方向, 可应用于拉曼光谱进行建模。 但是深度学习需要大样本进行训练, 而拉曼光谱采集受制于器材和人力成本, 获取大批量的样本需要更大成本, 且易受荧光等因素干扰, 这些问题都制约了将深度学习应用于拉曼光谱。 针对以上问题, 通过引入深度卷积生成对抗网络(DCGAN)提取拉曼光谱内部特征, 对抗生成新的拉曼光谱, 从而达到扩充数据集目的。 同时和另一个扩充数据集的方法——偏移法进行对比, 证明DCGAN的可靠性。 设计生成光谱选取标准, 选取高相似性的光谱填充数据集, 为深度学习在拉曼光谱中的应用奠定基础。 为了验证生成的光谱比原始光谱有更好的适用性, 设计四组实验: (1)使用原始拉曼光谱输入到SVM进行分类, 得到51.92%的分类准确率; (2)使用原始拉曼光谱输入到CNN进行分类, 得到75.00%的分类准确率; (3)采用偏移法生成光谱, 输入到CNN里进行分类, 得到91.85%的分类准确率; (4)使用DCGAN生成光谱, 输入到CNN里进行分类, 得到98.52%分类准确率。 实验结果表明, DCGAN能在只有少量拉曼光谱的情况下, 通过对抗学习得到较好的生成光谱, 且生成的光谱相比原光谱更加清晰, 减少了可能的干扰因素, 具有光谱预处理效果。 通过DCGAN对抗生成大量高质量的数据填充到原有拉曼光谱数据集, 扩充数据集的样本量, 使得深度学习模型能够得到更好的训练, 从而提高模型的准确率。 该研究为深度学习方法应用于拉曼光谱分析技术提出了一个可行的方案。
, YIN Lin-lin, FENG Yan-chunThe detection method of Raman spectroscopy relies on the chemometrics algorithms, and deep learning is the most popular are at present, which can be applied to the modeling of Raman spectroscopy. However, deep learning requires large samples for training, while Raman spectral collection is limited by equipment and labor cost. Obtaining large quantities of samples requires a higher cost, and also is suffered by fluorescence and other factors, which all restrict the application of deep learning to Raman spectral. In view of the above problems, the paper introduces the deep convolution generation counter network (DCGAN) to extract the characteristics of Raman peaks in the Raman spectrum, and generates a new Raman spectrum to expand the data set. At the same time, the reliability of DCGAN was proved by comparing with the slope-bias adjusting method, another method to expand the data set. In this paper, spectral selection criteria are designed and generated to fill the dataset with highly similar spectra, which is the first step for the application of deep learning in Raman spectra. In order to demonstrate that the generated spectrum has good comformality with the original spectrum, the paper sets up four groups of experiments for comparison: (1) the original Raman spectrum is input to SVM for classification, and the classification accuracy is 51.92%, (2) the original Raman spectrum was input to CNN for classification, and 75.00% classification accuracy was obtained, (3) the slope-bias adjusting method was used to generate the spectrum, which was input into CNN for classification, and the classification accuracy of 91.85% was obtained, (4) DCGAN was used to generate the spectrum, which was input into CNN for classification, and the classification accuracy was 98.52%. The comparison of the four groups of results proves the superiority of the Raman spectrum generated by DCGAN. The experimental results show that DCGAN can generated much alike spectrum through antagonism learning with only a small amount of Raman spectrum, and the generated spectrum is clearer than the original spectrum, reducing some interference factors, and has a preprocessing effect on the spectrum. Taking the advantage of DCGAN, a large number of high-quality data can be generated and filled into the original Raman spectral data set, and the sample size of the data set can be expanded, so that the deep learning model could be better trained, thus improving the accuracy of the classification or other model. This paper proposes a feasible scheme for applying deep learning method to Raman spectroscopy.
食品药品的安全一直是人们重点关注的对象, 常用的食品药品检测手段有吸收系数法、 化学法和HPLC法等, 不仅繁琐, 而且局限于实验室。 因此需要一种可以快速检测的手段, 近年来发展较好的是近红外光谱检测和拉曼光谱检测。 拉曼检测技术是基于拉曼光谱特征位移峰而产生的一种检测技术。 当光照射到物体分子上时会发生弹性散射, 额外会有少量光子发生非弹性散射, 这些光子就是拉曼光子, 拉曼光子转移能量到分子上, 产生位移散射光, 位移的距离对应分子的信息。 不同的距离长短对应了不同的分子结构, 由此产生拉曼谱图。 根据谱图就可以明确样品化学与分子信息和含量[1]。 相比红外光谱法, 拉曼光谱提供的是无损定性定量分析, 对样品无特殊要求, 短时简便高灵敏度, 避免了因为样品的破坏或者样品自身的缺陷导致的误差[2]。
由于仪器和方法的改进升级, 使用拉曼分析对食品药品进行鉴别和分类得到了广泛应用。 目前主流的分类算法线性学习机(linear learning machine, LLM)、 软独立建模分类法[3](soft independent modeling of class analogy, SIMCA)、 人工神经网络[4](artificial neural network, ANN)、 K-最近邻[5](K-nearest neighbor method, KNN)等。 最近两年, 我们将浅层机器学习方法应用于近红外光谱药品分类[6], 并取得了较好的分类结果。 这些方法各有优点但较为传统, 目前深度学习方法在图像分割[7]、 图像增强[8]和图像检测[9]等方面大放异彩, 将深度学习应用到光谱学是必然趋势。 现有拉曼光谱采集需要较高的人力和时间成本, 采集到的数据样本量较少和存在干扰因素, 不能满足深度学习需要用大样本进行训练的条件, 因此将深度学习应用在拉曼光谱中的研究较少。
鉴于此, 本文提出一种将深度学习应用到拉曼光谱的方法: 使用深度卷积生成对抗网络[10](deep convolutional generative adversarial networks, DCGAN)生成新光谱, 并输入CNN进行分类。 目前GAN在光谱分析中应用不多, 仅见应用于高光谱分析, 而在拉曼和近红外光谱分析方面未见报道。
在搭建深度学习模型的过程中, 常遇到因训练数据集样本量不够导致欠拟合的问题。 解决该问题除了在算法层面的优化, 还需拓展训练集样本数量。 常用的数据增强方法有形状变换、 监督式抠取、 GAN等。 本文采取的DCGAN则是在原始GAN的基础上引入卷积, 借助卷积层的特征提取能力, 提取拉曼光谱的深层特征, 生成高度相似的光谱。
采用DCGAN扩充拉曼光谱, 扩充训练集样本量并提升CNN分类精度。 设置数据增强扩充光谱并输入CNN进行分类, 与DCGAN的结果进行对比。 实验结果表明: DCGAN生成的光谱能够被CNN识别并进行分类, 增加的数据集样本量提升了CNN的分类精度。 其次, DCGAN可以实现使用少量原始拉曼光谱对抗生成新光谱, 达到扩充数据集的样本量目的, 有效减少人力和时间成本。
1.1.1 算法介绍
CNN通常包含卷积层、 池化层、 全连接层, 先正向传播得到输入数据特征, 然后反向传播使用梯度下降进行迭代, 完成权值更新。
卷积层通过卷积运算提取输入数据特征, 卷积公式如式(1)
式(1)中:
池化层对卷积层提取得到的特征进行进一步降维, 加快运算速率。 池化层的公式如式(2)
式(2)中:
1.1.2 改进的CNN
卷积神经网络主要用于图像分类, 输入一般为n× n维的图像, 对应卷积核及池化操作均是n× n的矩阵, 并不适用于光谱, 需要针对光谱对网络进行修改。 这里修改卷积核尺寸为1× 5。 光谱谱线中最重要的是每个波长点的峰强信息, 然而CNN里的池化操作会使得光谱信息大量丢失并不利于分析, 所以这里舍弃池化层。 同时为了减小运算量, 将网络输出层和中间层修改为单层感知器。 经过改进后设计为一个5层的CNN网络, 具体网络结构如表1。
| 表1 CNN网络各层设计 Table 1 CNN network design |
1.2.1 算法介绍
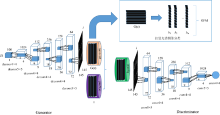
DCGAN的网络结构如图1: 图中左边是G(Generator)网络, 右边是D(Discriminator)网络。
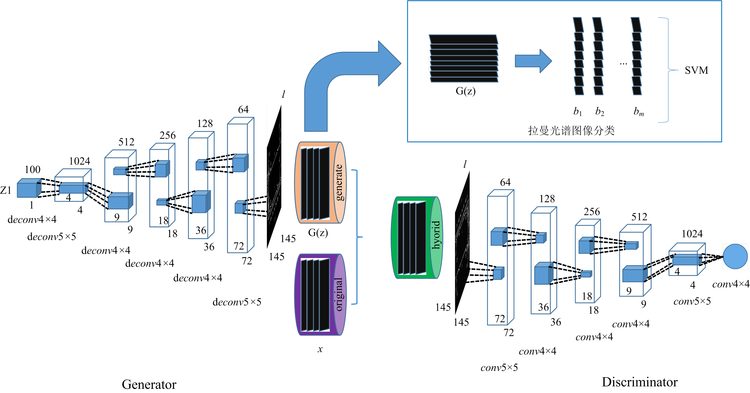 | 图1 用于拉曼光谱分类的DCGAN网络结构示意图Fig.1 Diagram of DCGAN network structure for Raman spectrum classification |
G是生成网络, 给它输入一个随机噪声z, 最终能生成一张图片, 标记为G(z)。
D是判别网络, 用来判别某张图片真实的程度。 给它输入一张图片x, 会输出D(x), 代表x是真实图片的概率, 若概率数值是1就说明图片完全真实。 若概率数值为0就说明图片作假。
DCGAN引入卷积计算图像整体区域特征信息, 从而具有很强特征提取能力。 由于卷积网络中池化层(pooling)的下采样会造成图像信息部分损失, 不能采用, 因此把G和D网络中的池化层替换为反卷积层和步进卷积层, 减少图像信息损失。 然后引入Batch Normalization (BN)构造更加稳定的网络。
1.2.2 改进的卷积层
传统的DCGAN网络的卷积层主要面向图像分类为主。 该网络层默认输入一般是二维图像, 因此网络层的卷积核和池化窗口都是大小为n× n维的矩阵。 如此来看这样的网络结构并不适用于光谱数据, 因此需要对传统DCGAN网络的卷积层进行改进, 也就是将DCGAN中卷积层的卷积核修改为一维向量卷积核, 使之能够处理拉曼光谱数据。
1.2.3 DCGAN网络结构设计
针对Raman光谱数据设计的生成网络和判别网络的结构见表2。
| 表2 用于Raman光谱扩充的生成网络和判别网络 Table 2 Generator network and Discriminator network for Raman spectral augmentation |
仅使用DCGAN生成光谱来进行分类缺少算法效果对照。 增加一个数据增强方法生成光谱, 通过两种方法对生成的光谱进行分类对比。
数据增强是一个扩展数据集最常用的技术, 它已成功地应用于许多领域, 从图像分类到分子建模。 其核心思想是通过模拟数据集中的各种数值变化, 从有限的标记样本数目中扩展训练样本的数目。 对于光谱数据, 采用随机偏移量、 斜率的随机变化和随机乘法来扩展数据集。 偏移量为训练集标准差的± 0.10倍, 叠加次数为训练集标准差的1± 0.10倍, 斜率在0.95~1.05之间均匀随机调整。 其函数表达如式(3)和式(4)
式中, k为缩放比例, b为偏移项, 表示对光谱每个数据点随机向上偏移, 每个点的偏移量呈线性递增或递减形式。 m为倾斜度, n为倾斜时的偏移, a为步长从0到1之间的向量。 x表示原光谱, x'表示用x生成的光谱。
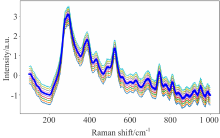
图2是数据增强生成光谱的示意图, 图中粗蓝线为原始光谱, 其余为偏移法生成光谱。
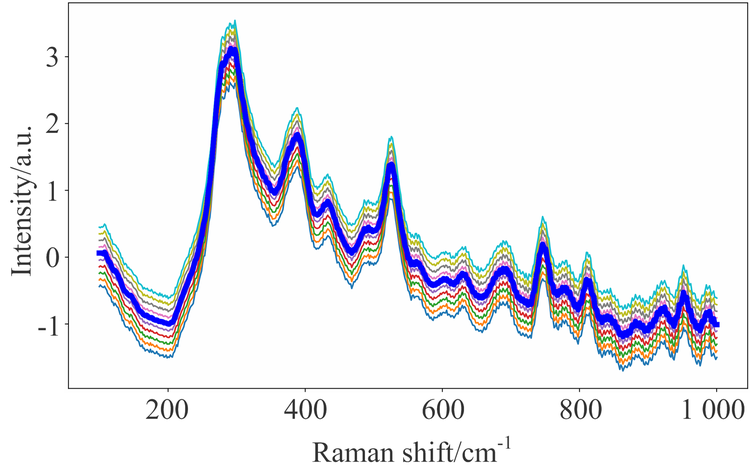 | 图2 偏移法扩增光谱示意图Fig.2 Spectral augmentation by slope-bias adjusting |
分类方法有以下几种: 无监督分类、 半监督分类、 有监督分类。 常见的无监督分类算法有K聚类、 Fuzzy Means[11]; 半监督学习则是DBSCAN最常用; 对于有监督分类来说, 常用的有支持向量机(support vector machine, SVM)。
根据需要选择分类方法, CNN上文已提到不再赘述, 增加一个机器学习分类方法作为CNN分类方法参照, 这里选用SVM方法。 生成的拉曼光谱数据表示为G(z)=[b1, b2, …, bm], m为样本总数, SVM的分类函数的对偶形式表示为
其中k(bi, bj)本文选择径向基函数(RBF)
建模选择LibSVM软件, 这里有两个参数c和g, c就是式(5)中的C, g=1/2σ , 参数设置为: c=200, g=0.01。
1.5.1 扩充样本的选取标准
对生成图像进行评估有一定的困难, 一般只能通过人工样本筛选和主观判断的方法来进行评价, 不仅耗时而且费力。 结构相似度(structural similarity index, SSIM)指标能够很好的判断两个样本的相似性, 故引入该指标对生成光谱进行评判。 见式(7)[12]
式中μ x, μ g, σ x, σ g为x和g的均值和方差, σ xg为x和g协方差。 c1和c2为常数, 用来保证函数稳定性, c1=(k1L)2, c2=(k2L)2, L=255, 是图像像素最大值, k1=0.01, k2=0.03。
SSIM取值范围[0, 1], 大小与图像相似度成正比。 这里设置SSIM阈值为0.9, 因为高相似度的生成光谱才能用于样本扩充。 计算原始光谱和生成光谱之间SSIM值, SSIM值大于等于0.9才采用该生成光谱, 否则不用。
1.5.2 模型分类结果的评价方法
本实验采用分类准确率定量评价分类结果。
当光谱输入到分类器时, 计算其分类的准确率P。 分类准确率P。 可表示为
式中: Nc为正确分类的样本数, Nr为样本数。
实验中使用的数据为中国食品药品检定研究院测取的药品拉曼光谱数据集, 选取9类药品, 药品分布如表3。 测量仪器为同方威视RT6000、 Metage OPAL 3000和Opto Trace RamTracer-200-HS拉曼光谱仪, 测量参数Metage OPAL 3000和Opto Trace RamTracer-200-HS积分时间设为25 s, 积分次数设为3次, 同方威视RT6000积分时间设为25 s, 积分次数为自动。 为了避免实验中因为样本波段不一致而导致的结果不理想, 以下实验均选择每种药品在100~1 000 cm-1的光谱。 同时为了验证DCGAN在生成光谱中具有预处理的作用, 实验所采用的所有光谱均只进行基线校正和归一化预处理, 为减少计算量, 采样间隔选择隔13点采样。
| 表3 中检院数据集对应的药品分布 Table 3 Distribution of corresponding drugs in data set National Institute for Food and Drug Control |
卷积神经网络学习率设置为0.001, 梯度更新块大小设置为32。 训练过程中手动调整以保持所有层具有相同的迭代速度。 对卷积层设置权值初始化为0.01标准差的零均值高斯分布。 对全连接层的权重设置0.005标准偏差。 由于卷积后的结果会导致光谱首尾数据的丢失, 因此输入前对原始光谱采用0填充。 目标函数采用最小化预测值和真值的交叉熵
式(9)中, N为样本数, yi是样本i的类别标记,
DCGAN中卷积网络的激活函数选择LeakyReLU, 设定leak的斜度值为0.2, 整个网络设定数值为2的batch size, 网络的学习率不能太大, 否则时间过长, 这里设置为0.000 2, 卷积层还需要使用优化器并设置动量参数, 优化器使用Adam, 参数设置为0.5时可以稳定训练。 D训练两次, G训练一次, 迭代次数设置为800。 每迭代10次输出一次SSIM的平均值, 作为选取扩充样本的标准。
将原始拉曼光谱作为初始数据集, 通过对抗生成新的数据集, 为了有所区别, 这里给生成网络设定100个服从标准正态分布的噪声z, 通过反卷积网络后能够生成和真实图像相似的“ 假” 样本。 然后将真假样本同时输入判别网络, 通过卷积层能够得到范围为0到1的概率值, 根据概率值判断样本的真假程度。 训练分为两个部分:
(1)训练生成网络, 提前设定好判别参数, 用以优化生成网络, 直到生成的“ 假” 样本判别网络无法识别, 此时生成网络输出大概率真实的样本, 映射到函数内就是最大化D(G(z)), 亦即最小化1-D(G(z))。
(2)训练判别网络, 类似地, 给定生成网络的参数, 区性优化判别网络, 这样能大大提高判别网络的精度, 这里期望最大化D(x)。 生成样本G(z)需要使得D(G(z))最小。 对判别网络的目标函数优化为lnD(x)+ln(1-D(G(x)))。
最终得到目标函数
然后固定生成网络的参数, 以优化判别网络, 使得V(D, G)最大
为了式(11)最大, 这需要式(12)
取得最大值。 显然有: 对任意非零的Pdata(x), Pg(x), 且实数值D(x)∈ [0, 1]时, 式(12)在Pdata(x)/(Pdata(x)+Pg(x))处取得最大值, 列出最优的生成网络D的函数
对生成网络进行优化时, 有Pdata=Pg时生成网络取得最优解, 使得生成网络更好地再现真实样本的分布。
设计四组实验。 分别是SVM对原始光谱进行分类的参照组、 CNN对原始光谱进行分类的对照组、 CNN对DCGAN生成光谱进行分类的实验组和CNN对偏移法生成光谱进行分类的实验组。
由于SVM和CNN需要进行训练, 在原始光谱的实验中, 选取70%作为训练集, 剩下30%作为测试集。 在生成光谱的实验中, 分别用数据增强方式和DCGAN方式将每种药品的谱图数扩充到100个, 再选取70%的光谱对CNN进行训练, 剩下30%的光谱进行测试。
表4展示了对原始光谱的训练集和测试集的划分情况, SVM分类原始拉曼光谱的结果如表5所示。 以SVM直接对原始的拉曼光谱分类产生的结果来看, 对拉曼光谱的分类准确率并不高。 对于Pefloxacin和Cefixime两个样本最少的药品来说, 几乎无法准确分类。 从表5中可以看出由于总体数据集样本量不大, 其分类精度依然有待提高。
| 表4 药品样本训练集、 测试集划分情况 Table 4 The training set, test set distribution of drug samples |
| 表5 中检院拉曼光谱数据判别详细结果-SVM(%) Table 5 Detailed results of Raman spectrum discrimination of China food and drug institute-SVM (%) |
用于CNN分类的训练集和测试集的划分同表4。 表6展示了相同波段的原始光谱输入CNN的分类实验结果。 表中分别列出了CNN对原始拉曼光谱分类结果(训练集分类准确率78.38%, 测试集分类准确率75.00%)。 同样对于Pefloxacin和Cefixime两个样本最少的药品来说, 分类准确率略有提升。 由于CNN具有很强的特征提取和分类能力, 因此CNN对拉曼光谱的总体分类精度高于SVM。
| 表6 拉曼光谱数据判别详细结果-CNN(%) Table 6 Detailed results of Raman spectrum discrimination CNN (%) |
上述实验仅用原始光谱进行分类对比实验, 为了实验的严谨性, 需要考虑到生成的光谱是否具有相同的优越性。 因此需要扩增谱图和原始谱图分类对比来查看情况, 先用偏移法将每个药品光谱扩充到100个, 训练集和测试集划分见表7。 分别输入CNN训练并分类得到结果, 图3为单个药品生成10个谱图和原始谱图的叠加图。 表8是生成光谱数据判别详细情况。 实验结果表明, 偏移法生成谱图具有较好的分类准确率; 另一方面, 分类过程中出现了一些误分类的情况, 即把本该分类到某种药品的谱图认为是另一种药品的谱图。 出现这种现象的原因是偏移法生成的光谱有些波长点的峰强信息会改变, 此时该拉曼峰可能会被认为是另一种分子。 同时, 由于偏移法生成光谱是对原光谱的重塑, 因此有必要评估生成光谱相比原光谱的失真度。 局部方差估计法LVE(local variance estimation method)是一个较好的能够估计图像失真程度的方法, 其算法原理是先计算每张图片像素局部方差, 最大的局部方差为信号方差, 最小的局部方差为噪声方差, 计算信号方差和噪声方差的比值, 并转换成dB表示。 表9为图3生成的10个谱图对比原始谱图的信噪比, 从实验结果可以看出生成光谱相对原始光谱的失真程度。
| 表7 药品样本训练集、 测试集划分情况 Table 7 The training set, test set distribution of drug samples |
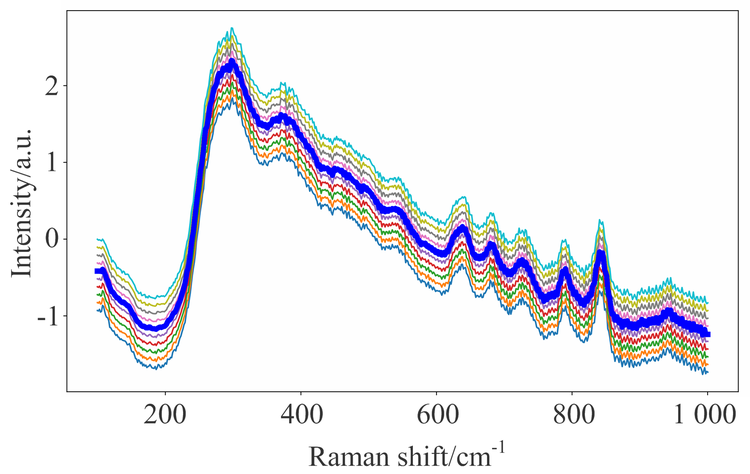 | 图3 偏移法生成谱图Fig.3 Spectral generation by data augmentation |
| 表8 中检院拉曼光谱数据判别详细结果-偏移法+CNN(%) Table 8 Detailed results of Raman spectrum discrimination of China food and drug institute-Data augmentation and CNN (%) |
| 表9 偏移法扩增谱图的LVE方法信噪比(对应图3) Table 9 LVE signal to noise ratio of augmented spectral by slope-bias adjusting (corresponding to Fig.3) |
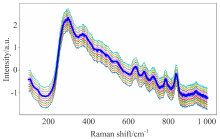
同样使用DCGAN将每个药品光谱数量扩充到100, 训练集与测试集划分同表7。 图4为原始的中检院数据中随机选取的10个药品光谱如图4(a), 和DCGAN进行对抗生成的10个新的光谱如图4(b)的展示。 从视觉上看出生成的光谱相较原始光谱更加平滑清晰, 说明DCGAN在生成光谱的过程中能够起到预处理的作用。 将划分好的训练集和测试集输入CNN进行训练分类, 得到如表10所示的判别结果。 实验结果表明生成谱图具有高分类准确率。 同样评估DCGAN生成光谱相比原光谱的失真度, 实验结果见表11, 从实验结果可以看出生成光谱的失真程度对比原始光谱差异较小, 相比偏移法, DCGAN生成的光谱较好的保留了原始谱图的信息。 图5是四个实验的训练集和测试集的分类准确率对比, 从分类准确率来看, DCGAN生成的拉曼光谱数据更有利于准确分类。
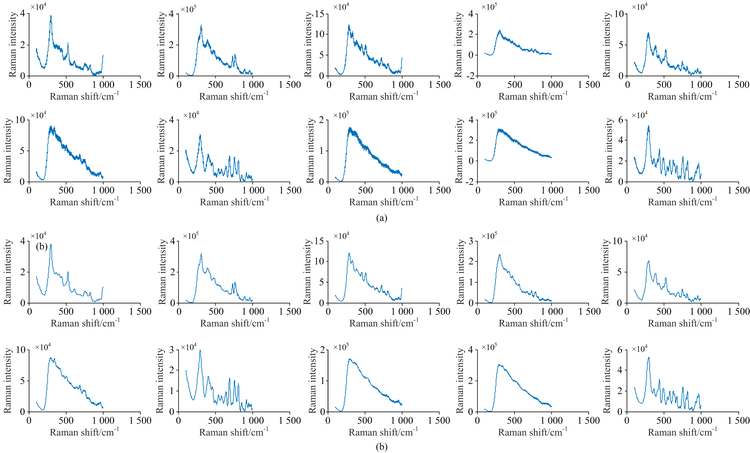 | 图4 原始谱图(a)和DCGAN生成谱图(b)对比Fig.4 The original spectra (a) were compared with the generated spectra (b) of DCGAN |
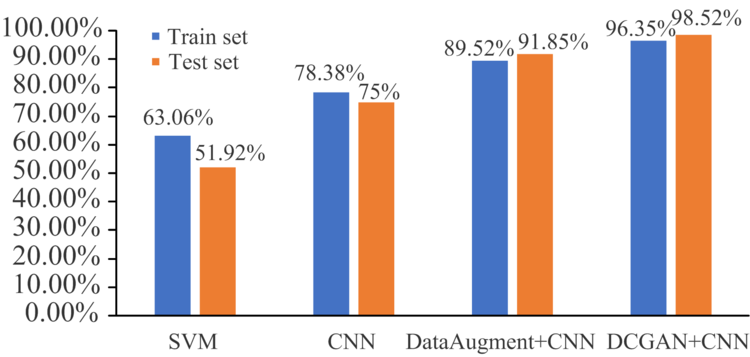 | 图5 训练集和测试集的分类准确率对比图Fig.5 Comparison of classification accuracy of training set and test set |
本文提出的基于DCGAN的数据扩充可有效扩充Raman光谱数据, 并可由此提高对扩充后数据分类的准确率。 使用
中检院的药品拉曼光谱数据集进行实验, 实验结果表明:
(1)由于中检院药品数据集样本量不大, 该方法实现由少量的拉曼光谱生成更多的拉曼光谱扩充数据集, 对解决由于数据集样本量不够而引发的深度学习分类精度较低的问题提出了一个新的思路;
(2)使用DCGAN网络对光谱进行生成甚至超分辨率重建是可行的, 并且效果较好;
(3)基于DCGAN左右互搏的思想, 使得生成的光谱图和原始光谱图在不断互相“ 欺骗” 的过程中, 提高了模型对光谱特征的识别和分类精度。
本文提出方法也存在不足之处, 例如DCGAN是对原谱图进行重塑, 不能应用常用的图像评价指标, 因此如何更直观地反映生成谱图和原谱图的关系还有待研究; 另一方面由于数据集的样本量不够大, 在大样本容量时的实验结果仍需进一步验证。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|