

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像的柑橘病虫害叶片识别方法
[吴叶兰1  , 陈怡宇
, 陈怡宇1 , 廉小亲1 , 廖禺2 , 高超1 , 管慧宁1 , 于重重1 ]
, 陈怡宇|
|


作者简介: 吴叶兰, 女, 1970年生, 北京工商大学人工智能学院副教授 e-mail: wuyel@th.btbu.edu.cn
为监测柑橘生长状况, 实现病虫害无损识别, 利用高光谱成像技术和机器学习方法进行柑橘病叶分类研究。 使用高光谱成像仪采集46片柑橘正常叶、 46片溃疡病叶、 80片除草剂危害叶、 51片红蜘蛛叶和98片煤烟病叶的高光谱图像, 在478~900 nm光谱范围内对每个叶片一个或多个发病区提取5×5的感兴趣区域(ROI), 将ROI内每个像素的反射率值作为光谱信息, 则一个ROI得到25个光谱信息样本, 最终五类叶片共得到13250个光谱样本。 利用随机法将全部样本划分为9 938个训练集和3 312个测试集。 分别采用一阶求导(1stDer)、 多元散射校正(MSC)和标准正态变换(SNV)三种方法对原始光谱信息进行预处理, 对不同预处理方法后的数据采用主成分分析法(PCA)提取特征波长。 1st Der预处理后得到7个特征波长, 分别是520.2, 689.0, 704.8, 715.4, 731.2, 741.8和757.6 nm; MSC和SNV预处理后得到7个相同的特征波长, 分别是551.9, 678.5, 704.8, 710.1, 725.9, 731.2和757.6 nm; 原始光谱得到7个特征波长, 分别是525.5, 678.5, 710.1, 720.7, 725.9, 757.6和762.9 nm。 分析PCA后的样本分布散点图可知, 正常叶片、 溃疡病叶片和红蜘蛛叶片样本有一定程度聚类, 除草剂叶片和煤烟病叶片样本有大量重叠, 仅依据PCA不能完成病虫害叶片的识别。 对全波段(FS)和PCA特征波长数据在不同预处理方法下进行支持向量机(SVM)和随机森林(RF)建模, 结果表明: 数据在1stDer预处理方法下识别效果最佳, 1st Der-FS-SVM模型总分类精度(OA)为95.98%, Kappa系数为0.948 2, 1st Der-FS-RF模型OA为91.42%, Kappa系数为0.889 2, 1stDer-PCA-SVM模型OA为90.82%, Kappa系数为0.881 6, 1stDer-PCA-RF模型的OA为91.79%, Kappa系数为0.894; 对PCA选择的特征波长数据建模, SVM和RF模型下识别率均达到84%, 全波段下模型识别率在88%以上, FS数据建模效果优于PCA特征波长。 研究结果表明, 高光谱成像技术结合机器学习方法进行柑橘叶片分类是可行且有效的, 为柑橘病虫害的无损准确识别提供理论根据。
To monitor citrus growth and realize nondestructive identification of pests and diseases, the leaf classification of citrus diseases was studied using hyperspectral imaging technology and machine learning method. Using hyperspectral imager to collect hyperspectral images of 46 normal citrus leaves, 46 canker leaves, 80 herbicide-damaged leaves, 51 red spider diseased leaves, and 98 soot diseased leaves. A 5×5 regions of interest (ROI) were extracted from one or more diseased areas of each leaf in the 478~900 nm spectral range. Taking the reflectance value of each pixel in the ROI as the spectral information, one ROI would get 25 spectral information samples, and finally the five types of leaves get a total of 13 250 spectral samples. The samples were divided into 9938 training sets and 3 312 test sets by random method. The first derivative (1st Der), multiple scattering correction (MSC) and standard normal transformation (SNV) were used to preprocess the original spectral information, and principal component analysis (PCA) was used to extract the characteristic wavelength of the data after different preprocessing methods. After 1st Der pretreatment, 7 characteristic wavelengths were obtained, which were 520.2, 689,704.83, 715.38, 731.2, 741.75 and 757.58nm respectively. After MSC and SNV pretreatment, 7 identical characteristic wavelengths were obtained, which were 551.85, 678.45, 704.83, 710.1, 725.93, 731.2 and 757.58 nm, respectively. The original spectrum obtained seven characteristic wavelengths, which were 525.48, 678.45, 710.1, 720.65, 725.93, 757.58 and 762.85 nm, respectively. The scatter plot of sample distribution after PCA analysis showed that there was a certain degree of clustering of normal leaves, canker leaves and starscream leaves, and a large amount of overlap between herbicide leaves and soot leaves, so the identification of pest and disease leaves could not be completed only based on PCA. Support vector machine (SVM) and random forest (RF) were used to model the all-band spectrum (FS) and PCA characteristic wavelength data under different pretreatment methods, and the results showed that: The OA of 1st Der-FS-SVM model was 95.98%, the Kappa coefficient was 0.948 2, the OA of 1st Der-FS-RF model was 91.42%, the Kappa coefficient was 0.889 2, the OA of 1st Der-FS-SVM model was 90.82%, and the Kappa coefficient was 0.881 6, OA and Kappa coefficient in 1st Der-PA-RF model was 91.79% and 0.894 respectively. For PCA characteristic wavelength data modeling, the recognition rate of SVM and RF models reached 84%, and the recognition rate of the full-band spectrum model was above 88%. The FS data modeling effect was better than that of PCA characteristic wavelength. The results show that it is feasible and effective to classify citrus leaves by hyperspectral imaging technique combined with machine learning method, which provides a theoretical basis for the accurate and nondestructive identification of citrus pests and diseases.
我国是柑橘生产大国[1]。 受种植环境气候影响, 柑橘易感染病虫害, 如柑橘溃疡病病原属于细菌, 感染后轻则果皮呈现疤痕、 果熟后不耐贮藏易腐烂, 重则导致落果; 除草剂轻则导致柑橘叶片生长缓慢, 重则导致枯萎死亡; 柑橘红蜘蛛吸食叶片、 果实汁液, 引起落叶、 落果; 煤烟病由多种真菌引起, 发病初期, 表面出现暗褐色点状小霉斑, 后继续扩大成绒毛状黑色或灰黑色霉层。 病虫害的发生会影响柑橘的产量及质量, 严重会造成经济损失。 因此, 研究一种精准的柑橘病虫害检测方法在实际生产过程中有重要意义。 传统的柑橘病虫害检测方法主要有人工检测方法, 根据种植户或专业人员的经验知识来判断患病与否, 主观性强; 病理分析法, 对柑橘的生物化学性质分析检测, 周期长, 成本高。
高光谱成像技术是结合光谱和成像技术发展起来的, 可同时获取物体的空间和光谱信息[2]。 随着高光谱遥感技术的迅速发展, 高光谱成像技术用于农作物病害诊断已成为重要的研究领域, 结合现代建模和数据分析可准确地识别农作物内部属性和外部特性, 为早期病害鉴定提供有利条件[3]。 刘燕德等[4]结合LS-SVM和PLS-DA两种方法对柑橘正常、 缺素和不同程度黄龙病叶片进行判别, 用二阶导数处理原始数据, 采用主成分分析和连续投影算法提取特征波长, PLS-DA模型误判率为5.6%。 梅慧兰等[5]为实现柑橘黄龙病早期鉴别及病情分级, 采用一阶微分和移动窗口拟合多项式平滑两种预处理方法, 结合PLS-DA建模, 验证集相关系数均达0.954 8以上。 兰玉彬等[6]采用SG平滑、 一阶导数和反对数变换对柑橘黄龙病植株光谱数据进行预处理, 完成主成分波长和全波段的KNN和SVM建模, 得到全波段下一阶导数光谱的SVM模型分类准确率达94.7%, 测试集误判率为3.36%, 实现了柑橘黄龙病监测。 邓小玲等[7]为了实现柑橘黄龙病植株分类, 对全波段使用BP、 XgBoost算法, 对特征波段使用逻辑回归和SVM算法, 准确率分别达95%, 95%, 93%和96%。 Abdulridha等[8]在实验室内对无症状、 早期和晚期感染溃疡的柑橘叶片和未成熟果进行高光谱成像, 利用神经网络径向基函数, 得到不同时期下染病叶片分类准确率为94%, 96%和100%, 健康和晚期的果实分类准确度为92%, 基于无人飞行器搭载同一成像系统对室外柑橘树检测, 准确率达100%。 楚秉泉等[9]对真菌感染柑橘进行高光谱成像, 二次主成分分析后得到615和680 nm两个特征波长, 使用特征波长的第2主成分图像进行柑橘腐烂部位识别, 识别率达100%。 上述研究表明高光谱技术在柑橘病虫害方面的研究主要为黄龙病和溃疡病的检测与分级, 结合传统机器学习方法已能取得较好结果, 但目前有关其他柑橘病虫害的研究仍较少。
本文针对柑橘溃疡病、 除草剂、 红蜘蛛、 煤烟病和正常叶片, 利用高光谱成像和机器学习技术进行分类识别, 得到最佳病叶分类模型, 为柑橘生长状况监测及病虫害识别提供理论基础。 主要研究内容有: (1)采用一阶求导、 多元散射校正和标准正态变换三种预处理方法对原始光谱数据进行预处理; (2)对不同预处理方法下数据进行主成分分析以提取特征波长; (3)对全波段数据和特征波长数据分别进行支持向量机和随机森林建模, 分析实验结果。
实验样本来自江西省新余市渝水区柑橘果园, 采摘时间为2019年2月底, 包括柑橘正常叶片46片、 柑橘溃疡病叶片46片、 柑橘除草剂危害叶片80片、 柑橘红蜘蛛叶片51片、 柑橘煤烟病叶片98片。
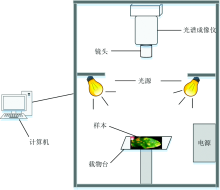
高光谱成像系统如图1所示, 主要由高光谱成像仪、 光源、 计算机、 样本、 载物台和电源等构成。 高光谱成像仪采用SOC710VP, 光谱范围为350~1 050 nm, 光谱分辨率为1.3 nm, 光谱波段数为128, 镜头类型为C-Mount, 焦距可调。 光源选用4个12 V的卤素灯, 亮度可调、 角度可调。
 | 图1 高光谱成像系统Fig.1 Hyperspectral imaging system |
本文设定高光谱图像采集时曝光时间为150 ms, 物距为57.6 cm, 扫描速度30行· s-1, 32 s· cube-1, 采集的原始图像大小为696× 520, 获取的光谱图像原始数据是像元亮度值(digital number, DN), 需将像元亮度值转化成光谱反射率供后续处理。 图2为五类柑橘叶片高光谱图像, 依次为正常叶片、 溃疡病叶片、 除草剂叶片、 红蜘蛛叶片和煤烟病叶片。
 | 图2 五类柑橘叶片高光谱图像Fig.2 Hyperspectral images of leaves of five citrus species |
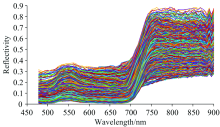
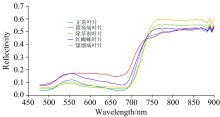
在ENVI中导入反射率.float文件, 去除400和1 000 nm附近受噪声影响较大的波段, 选择478~900 nm间81个波段作为有效光谱范围, 在每个叶片一个或多个发病区提取5× 5的感兴趣区域(region of interest, ROI), 将ROI内每个像素的反射率值作为光谱信息, 则一个ROI得到的光谱信息为25× 81, 五类柑橘叶片共提取530个ROI, 得到13 250× 81的光谱信息矩阵。 图3为所有样本的光谱曲线图, 图4为五类叶片平均光谱曲线。 由平均光谱图可知在478~500 nm的蓝光波段内光谱反射率低, 形成一个波谷; 在550 nm左右由于叶绿素反射作用呈现一个反射率峰; 在红光波段内的680 nm附近由于叶绿素强吸收作用光谱曲线有一个波谷, 700~900 nm为高反射率区域。 五类叶片光谱曲线呈现典型绿色叶片特征, 而不同病虫害有不同特征, 各类叶片的光谱曲线不完全一致, 溃疡病叶片光谱曲线与其余四种在680 nm之前有明显差异; 在全波段光谱(full-band spectral, FS)范围内正常叶片、 除草剂叶片、 红蜘蛛叶片和煤烟病叶片光谱曲线相似度高, 仅反射率值存在差别。 依据光谱曲线无法进行准确类别区分, 还需后续建模处理。
受测量环境和高光谱仪器性能影响, 获得的光谱信号易存在噪声和谱线漂移等干扰, 需对其进行预处理以消除干扰[10]。 利用The Unscrambler X 10.4软件对光谱数据分别进行一阶求导(first derivative, 1stDer)、 多元散射校正(multiplicative scatter correction, MSC)和标准正态变换(standard normalized variate, SNV)预处理, 对不同预处理方法下的光谱数据建模以得到最优分类结果。
 | 图3 13 250个样本光谱曲线Fig.3 Spectral curves of 13 250 samples |
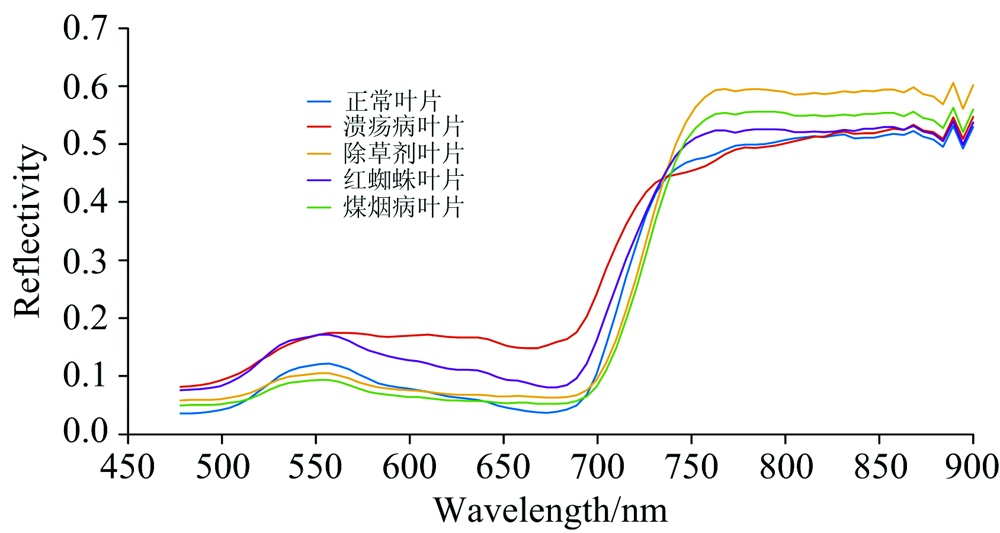 | 图4 五类叶片平均光谱曲线Fig.4 Average spectral curves of five types of leaves |
高光谱数据在光谱维含有上百个连续波段, 存在冗余信息, 若利用这些全波段光谱数据进行实验, 计算量大, 影响准确率, 因此可采用降维方法筛选出特征波长代入模型。 主成分分析(principal component analysis, PCA)是一种正交线性变换技术, 通过线性投影的方法, 将目标分量根据其信息含量分布到新的坐标空间中[11]。 采用PCA将高光谱图像信息进行压缩, 去除波段间的冗余信息, 实现降维。 PCA特征波长提取原理如下。
(1)光谱数据X为m× n的矩阵, m表示样本数, n表示特征维度;
(2)计算X的协方差矩阵C(n× n);
(3)求C的特征值和特征向量, 并按从大到小的顺序排序, 选择其中最大的k个, 将其对应的k个特征向量分别作为列向量组成新的特征向量矩阵U(n× k);
(4)将样本投影到选取的特征向量上, 如式(1)
投影后的数据Y为m× k的二维矩阵, 则原始的n维特征变成了k维, 达到了降维与特征波长提取目的。
支持向量机(support vector machines, SVM)是核变换技术的代表算法之一, 具有精度高、 运算速度快、 泛化能力强等优点[12]。 SVM依据结构风险最小理论, 在解决小样本、 非线性、 高维模式等问题上具有优势, 近年来广泛应用于高光谱数据处理。 SVM算法的原理是构造一个分类超平面, 该平面使得特征空间上正负样本的间隔最大化[13]; 对于线性不可分情况, 将低维空间问题映射到高维空间, 引入核函数代替预测样本和支持向量内积, 避免高维复杂运算。 常用的核函数有线性核函数、 RBF核函数、 多项式核函数和Sigmoid核函数。 线性核函数是RBF核的一个特例, 多项式核函数参数多会影响模型复杂程度, Sigmoid核函数在某些参数上近似RBF核的功能, 综上本文选择RBF核函数。
随机森林算法(random forest, RF)是决策树分类器的集合[14], 具有较高的分类准确性, 不易出现过拟合现象[15]。 基本思路为使用Bootstrap法从原始训练集中采样生成k个训练子集, 构建k棵决策树, 形成森林, 通过每棵决策树的预测投票决定最终结果。 “ 随机” 指两方面: 一是随机抽样训练子集; 二是决策树构建时随机地从总的特征中选取远小于总特征个数的特征子集。 随机性的引入使得每两棵树之间的差异度增加, 从而使得模型的泛化能力提高, 近年来随机森林算法已逐渐应用于高光谱分类。
目前基于支持向量机和随机森林算法进行柑橘病虫害分类识别的研究较少。 本文选择上述两种算法建立五类柑橘叶片的分类模型, 使用随机法将总样本划分为9 938个训练集和3 312个测试集, 训练集与测试集之比为3: 1。 采用测试集的总分类精度(overall accuracy, OA)和Kappa系数作为模型评价标准。
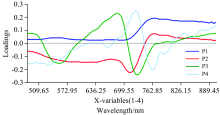
主成分分析使原始光谱波段经过线性组合得到主成分, 根据主成分的载荷(loadings)绝对值大小来确定特征波长。 载荷是主成分与原始波长变量的相关系数, 用于反映主成分和各波长变量间的密切程度。 图5所示为原始光谱前4个主成分的载荷曲线, 每条主成分曲线的波峰和波谷位置处载荷绝对值较大, 对应的波长即为特征波长。 由此原始光谱得到7个特征波长, 分别是525.5, 678.5, 710.1, 720.7, 725.9, 757.6和762.9 nm。 运用相同的方法, 1st Der预处理光谱得到7个特征波长, 分别是520.2, 689.0, 704.8, 715.4, 731.2, 741.8和757.6 nm; MSC预处理光谱和SNV预处理光谱得到7个一致的特征波长, 分别是551.9, 678.5, 704.8, 710.1, 725.9, 731.2和757.6 nm。 由于病虫害影响, 叶片表面颜色和叶绿素含量发生改变, 红光波段高反射率区域受影响较大, 故特征波长多落于此区间, 绿光波段内受叶绿素影响原反射率峰附近也出现特征波长, 所以特征波长集中在520~760 nm范围内。
 | 图5 原始光谱前4个主成分载荷曲线Fig.5 The first four principal component load curves of the original spectrum |
通过主成分分析还能得到光谱样本的散点图, 用来分析样本的分布情况。 图6显示了不同预处理下光谱数据样本的散点图, 编号1— 5分别表示柑橘正常、 溃疡病、 除草剂、 红蜘蛛和煤烟病叶片。 由图6可知, PC-1和PC-2累计贡献率达86%以上, 解释了原始数据的绝大部分信息, 五类叶片呈现出一定聚类效果。 经MSC和SNV预处理后, 正常叶片、 溃疡病叶片和红蜘蛛叶片有较为清晰的分类界限, 除草剂和煤烟病叶片样本重叠较多。 经1st Der预处理后聚类效果差, 五类叶片样本均有大量重叠。 因此还需对PCA后光谱数据作进一步处理以实现重叠样本的分类。
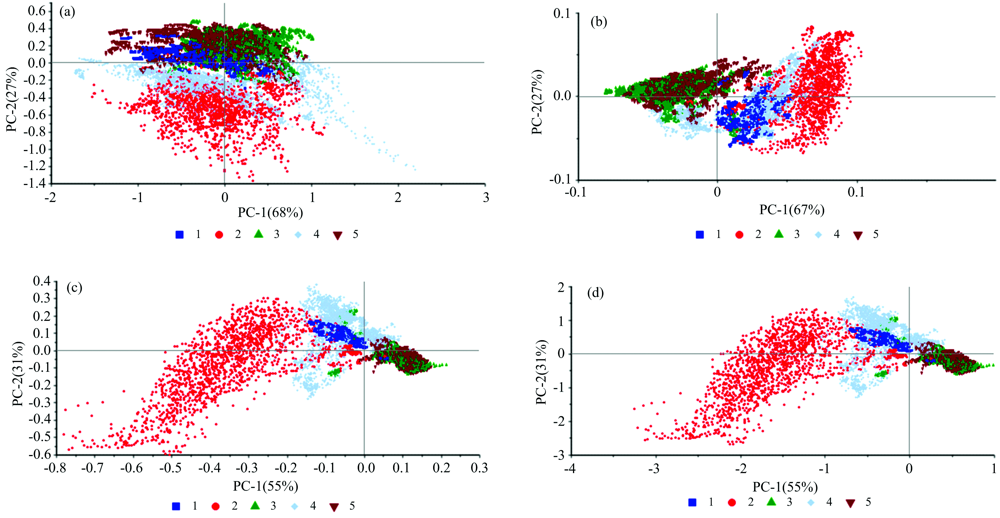 | 图6 样本分布散点图 (a), (b), (c)和(d)分别表示原始及经1st Der, MSC和SNV预处理后光谱得到的样本分布散点图Fig.6 Sample distribution scatter diagram Figure (a), (b), (c) and (d) respectively represent the scatter plots of sample distribution using original spectra and the spectra after preprocessing by 1st Der, MSC and SNV |
对全波段数据(FS)进行SVM和RF建模, 运用网格搜索法和交叉验证法确定不同预处理后数据在SVM模型的最优参数。 C是惩罚系数, 表示对误差的宽容度, 值越大, 表示越不能容忍出现误差, 易过拟合。 gamma是RBF核自带的参数, 决定了数据映射到新的特征空间后的分布情况, 值越大, 支持向量个数越少。 最终得到原始光谱数据下, C为16, gamma为128; 1st Der数据下, C为8, gamma为8 192; MSC数据下, C为8, gamma为512; SNV数据下, C为4, gamma为16。 RF建模时, 选择决策树颗数为500。 表1为不同预处理方法下全波段数据测试集的识别结果, 由表1可知, 对柑橘正常叶片、 溃疡病叶片和红蜘蛛叶片, 模型识别率分别可达98%, 97%和96%。 除草剂叶片识别率在原始数据和经1st Der预处理数据的SVM模型下可达90%, 1stDer-FS-SVM模型识别率为91.05%。 在进行RF建模后识别率均较低, 最高为原始数据下84.91%。 对煤烟病叶片, 均在经1st Der预处理数据的模型下有最高识别结果, 1st Der-FS-SVM模型识别率为94.09%, 1st Der-FS-RF模型识别率为93.29%, 但与正常、 溃疡病和红蜘蛛叶片相比, 识别率不够稳定。 除草剂叶片在五类叶片中识别结果最差, 煤烟病叶片次之, 其他三种叶片识别率均较稳定维持在96%之上。
| 表1 全波段数据建模结果 Table 1 Modeling results of full-band data |
对PCA特征波长数据进行SVM和RF建模识别, 利用网格搜索法和交叉验证法得到不同预处理后数据在SVM模型的最优参数: 原始数据下, C为128, gamma为512; 1st Der数据下, C为4 096, gamma为8 192; MSC数据下, C为4, gamma为4 096; SNV数据下, C为4, gamma为256。 RF建模时, 决策树棵树设为500。 表2为PCA特征波长数据测试集的识别结果, 分析可知, 对柑橘正常叶片、 溃疡病叶片和红蜘蛛叶片, 模型识别率分别可达97%, 96%和93%。 除草剂叶片在经1st Der预处理数据的模型下有最高识别结果, 1st Der-PCA-SVM和1st Der-PCA-RF模型识别率分别为79.28%和80.05%, 识别效果不佳, 与图6中除草剂叶片样本大量重叠于煤烟病叶片样本现象吻合。 与除草剂叶片相同, 煤烟病叶片也在经1st Der预处理数据的模型下有最高识别结果, 1st Der-PCA-SVM模型识别率为87.27%, 1st Der-PCA-RF模型识别率为91.58%。 综合五类叶片, 除草剂叶片识别结果最差, 煤烟病叶片次之, 其他三种叶片识别率均较稳定维持在93%之上。
| 表2 PCA特征波长数据建模结果 Table 2 PCA characteristic wavelength modeling results |
全波段数据(FS)和PCA波长数据在不同预处理方法下的模型识别效果如表3所示。 全波段光谱数据下SVM模型的总分类精度(OA)均高于91%, 1st Der-FS-SVM模型总分类精度(OA)最高, 为95.98%, Kappa系数为0.948 2; RF模型OA均高于88%, 原始数据下FS-RF模型OA最高, 为93.84%, Kappa系数为0.9205。 对PCA特征波长, SVM模型的OA均高于86%, RF模型的OA均高于84%。 经1st Der预处理数据的建模效果最佳, 1st Der-PCA-SVM模型OA为90.82%, Kappa系数为0.8816; 1st Der-PCA-RF模型OA为91.79%, Kappa系数为0.894。 同时由表3可知各模型Kappa系数均维持在0.8以上, 表明其一致性良好。
| 表3 FS和PCA波长数据不同预处理方法下建模结果 Table 3 Modeling results under different pretreatment methods of all-band and PCA wavelength data |
综合来看, SVM模型下识别效果优于RF, FS数据建模效果优于特征波长。 分析PCA特征波长下建模结果较全波段数据差的原因: PCA提取的特征波长大多集中在700~770 nm, 波长范围窄, 忽略了对分类识别有效的其他波长; 提取的特征波长数量较少, 包含信息量不全面, 不能很好地解释全部数据。 后续可采用其他方法提取特征波长进行分类识别。
为了识别柑橘正常、 溃疡病、 除草剂、 红蜘蛛和煤烟病五类病虫害叶片, 利用SOC710VP高光谱成像仪采集五类柑橘叶片高光谱图像, 在478~900 nm范围内提取ROI得到光谱数据。 采用1st Der, MSC和SNV预处理方法对原始光谱数据进行预处理, 对不同预处理方法后数据进行PCA以提取特征波长。 分别以FS和PCA特征波长光谱数据进行SVM和RF建模, 结果表明: (1)一阶求导预处理方法能够优化光谱数据, 经其预处理后的数据在各模型下总分类精度达90%, Kappa系数达0.88; (2)对不同预处理后光谱数据进行PCA, 均得到7个特征波长, 分别建立SVM和RF模型, 1st Der-PCA-SVM和1st Der-PCA-RF模型下OA最高, 分别为90.82%和91.79%; (3)综合来看FS数据建模效果优于PCA特征波长, 前者模型识别率在88%以上, 后者识别率达到84%, 分析可知特征波长相对集中在700~770 nm, 范围跨度窄, 包含信息不全面, 故PCA模型的OA值较FS数据低。 研究结果表明结合高光谱成像技术和机器学习方法可以实现柑橘病虫害叶片的分类, 为柑橘病虫害的无损准确识别提供了理论根据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|