


{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱的不同产地柑橘无损鉴别方法
[张欣欣1  , 李尚科
, 李尚科1 , 李跑1, 2, * , 单杨2 , 蒋立文1 , 刘霞1 ]
, 李尚科, 单杨|
|


作者简介: 张欣欣, 1997年生, 湖南农业大学食品科学技术学院博士研究生 e-mail: zxxhunauyjs@yeah.net
柑橘是世界第一大水果。 不同产地的柑橘内部品质和价格有所不同, 但其外观差别较小, 外行人较难通过肉眼实现准确鉴别分析。 DNA标记法与仪器分析操作复杂、 成本较高, 且对样品具有破坏性, 无法实现快速无损分析, 影响了产品的二次销售。 近红外光谱技术是一种快速无损的新型检测手段, 可以用于不同产地农产品的鉴别分析。 由于柑橘皮对光谱的干扰较大, 导致现阶段柑橘产地无损鉴别研究匮乏。 此外柑橘体积较大, 因此需要对光谱采样点进行优化。 为此, 基于近红外光谱技术与化学计量学方法, 提出了一种用于不同产地柑橘无损鉴别的新方法。 使用近红外光谱仪得到了120个来自云南、 湖南、 广西武鸣、 广西来宾的沃柑漫反射光谱数据。 采用单一和组合光谱预处理方式以消除光谱中的多种干扰; 采用主成分分析方法对数据进行降维处理, 并以此作为输入值结合Fisher线性判别分析方法构建柑橘产地鉴别模型, 并与主成分分析模型进行对比。 此外, 考察了不同光谱采样位置(赤道线4个采集点、 果梗部以及果顶部)对结果的影响。 结果表明: 主成分分析方法结合优化光谱预处理的方法不能实现不同产地柑橘的准确鉴别分析, 最优鉴别率仅为5%; 而采用主成分分析-Fisher线性判别分析方法, 利用赤道线4个点的平均光谱结合去偏置校正或多元散射校正预处理方法可实现不同产地柑橘的100%鉴别分析; 采用主成分分析-Fisher线性判别分析对6个点的平均光谱数据进行处理时, 采用原始光谱便可实现不同产地柑橘的100%鉴别分析。 为此, 通过对光谱预处理方法以及光谱采集点的优化, 利用主成分分析-Fisher线性判别分析方法即可建立准确的柑橘产地鉴别模型, 为不同产地柑橘的快速鉴别提供了新途径, 为后续各种柑橘类水果的鉴别分析提供了参考。
Citrus is one of the popular fruits in the world. There are differences in internal quality and price of different-regions citrus. However, the appearance differences are small, and it is difficult for laypeople to identify by appearance. Methods such as DNA labeling and instrumental analysis are complex in operation and destructive to samples, which cannot achieve rapid and non-destructive analysis, affecting the secondary sales of products. Near-infrared spectroscopy is a fast and nondestructive detection method that can be used to identify different-regions agricultural products. Due to the large interference of citrus peel on the spectra, there is a lack of nondestructive identification of citrus origin. Besides, citrus is large. Therefore, it is necessary to optimize the spectral collection points. This paper proposed a new method for nondestructive identification of different-regions citrus based on near infrared spectroscopy and chemometrics. The diffuse reflectance spectra of 120 fertile oranges from Yunnan, Hunan, Wuming and Laibin of Guangxi were obtained by near-infrared spectroscopy. Single and combined spectral pretreatment was used to eliminate multiple interferences in the spectra. The principal component analysis method was used to reduce the data dimension, which was used as the input value. Combining with Fisher linear discriminant analysis method, the citrus origin identification model was obtained and compared with the principal component analysis model. In addition, the effects of different spectral collection locations (4 collection points along the equator, top and bottom) on the results were investigated. The results showed that the principal component analysis method combined with the optimized spectral pretreatment method could not accurately identify different-regions citrus, and the best identification accuracy was 5%. When the principal component analysis-Fisher linear discriminant analysis was used, the average spectra of 4 collection points along the equator combined with De-bias correction or multivariate scattering correction pretreatment method could achieve 100% identification analysis of different-regions citrus. Furthermore, the average spectra of 6 collection points combined with raw data could achieve 100% identification analysis of different-regions citrus. Therefore, by optimizing the spectral pretreatment methods and spectral collection points, the accurate identification model of different-regions citrus can be established by using principal component analysis-Fisher linear discriminant analysis method, which provides a new method for rapid identification of different-regions citrus.
柑橘是柑、 柚、 橙、 枳、 橘(桔)等的总称, 是世界第一大水果。 柑橘富含水分、 维生素、 常量以及微量元素、 矿物质、 酚类、 萜类等营养和生物活性物质[1]。 由于气候、 土壤、 水分差异, 不同产地柑橘在口感、 质地方面有所差别, 但不同产地的柑橘外观相似, 表皮气味相近, 非专业人士难以实现准确鉴别分析。
国内外许多学者利用化学分析与DNA标记等方法实现了柑橘及其副产物的品种、 产地、 病害的鉴别分析。 Xiao等[2]利用感官评定、 气相色谱质谱联用与气相色谱-嗅觉评判三种方法对不同产地甜橙精油的挥发性成分进行了分析。 Nicolosi等[3]利用DNA标记法实现了柑橘品种的鉴别分析。 这些方法准确度高, 但费时费力, 不利于大面积推广, 且对样品具有破坏性, 无法实现快速无损分析, 影响产品的二次销售。 近年来, 近红外光谱技术因其快速无损、 绿色环保的特点在食品鉴别分析领域得到了广泛应用[4, 5, 6]。 然而由于柑橘皮对光谱的干扰较大, 导致现阶段柑橘产地无损鉴别研究匮乏。 此外柑橘体积较大, 因此需要对光谱采样点进行优化。
由于光谱采集过程中存在环境、 样本、 操作人员等的影响, 所以光谱往往存在谱峰重叠、 较大背景、 基线漂移等干扰。 为了消除这些干扰, 需要结合化学计量学方法对光谱数据进行预处理[7, 8, 9, 10]。 现阶段提出了很多光谱预处理方法, 如去趋势校正(DT)[11]、 去偏置校正(De-bias)[12]、 多元散射校正(MSC)[13]、 小波变换(WT)[14, 15]等, 不同光谱预处理方法适用范围不同, DT和De-bias用于消除光谱中存在的基线漂移, MSC等用来消除颗粒分布不均匀及颗粒大小不同所产生的散射对光谱的影响, WT等求导算法常用来扣除仪器背景或基线漂移对信号的影响。 但实际分析光谱中往往存在多种干扰, 仅用单一预处理方法无法实现对光谱的优化。 为此, 在处理光谱数据时通常需采用预处理组合的形式以消除多种干扰[9]。 结合光谱预处理方法, 可以建立准确的鉴别和定量模型。 常用的鉴别算法有无监督的主成分分析(PCA)方法与有监督的Fisher线性判别分析(FLD), 其中Fisher线性判别分析方法要求样本数大于变量数, 需要对数据进行降维处理。 本文通过结合PCA与FLD的优势, 利用近红外光谱, 提出了一种不同柑橘产地无损鉴别的方法。 通过单一与组合预处理对获得的柑橘光谱进行预处理, 利用PCA-FLD方法建立鉴别模型, 并与PCA方法模型进行对比, 以期为不同产地柑橘的快速无损鉴别提供一种新方法。
云南、 湖南、 广西武鸣和来宾是国内常见的沃柑主产区, 且这四个产地沃柑在本地超市容易购得。 它们外观上十分相似, 但在价格上存在一定的差别。 从本地水果超市购买新鲜的云南沃柑、 湖南沃柑、 广西武鸣沃柑、 广西来宾沃柑各30个, 共计120个, 擦拭表皮, 于室温下放置12 h。
傅里叶变换近红外光谱仪, (AntarisII, 美国Thermo Scientific公司), 采用积分球漫反射模式采集完整光谱, 波数范围为10 000~4 000 cm-1, 最小间隔约为4 cm-1, 共采集1557个数据点。 使用MATLAB R2010b(The Mathworks, USA)软件进行数据分析与处理。
光谱采集在室温下进行。 直接将沃柑立放在近红外光谱仪光斑的中心位置, 待重心平衡后, 开始对样品进行扫描, 利用漫反射模式对沃柑的果梗部、 果顶部以及赤道线(四等分)进行光谱采集, 每个样品共采集6个点的光谱, 每个点测量3次, 取其平均值作为原始光谱。 用Kennard-Stone(KS)分组方法将120个沃柑样品数据以2: 1的比例分为80个校正集与40个验证集。 此外, 对每个类别样品分别进行KS分组计算以保证每类样品在校正集和验证集集的平衡。
为了消除仪器和环境的干扰, 提高信噪比, 采用DT、 De-bias、 MSC、 最大最小归一化(Min-Max)、 标准正态变量变换(SNV)、 一阶导数(1st)、 二阶导数(2nd)以及连续小波变换(CWT)等预处理方法对光谱进行处理。 近红外信号中存在非常明显的基线漂移干扰, 求导预处理可以消除基线漂移干扰, 强化谱带特征; 由于柑橘样品物理性状原因, 信号中存在光散射的干扰, 而MSC和SNV是常用的校正散射影响的方法。 因此我们采用了求导和消除光散射预处理的组合方式以消除光谱中的多种干扰。 采用1st-DT, 1st-SNV, 1st-MSC, CWT-SNV, CWT-MSC和SNV-1st等组合预处理方法对光谱进行优化。 为了实现不同产地柑橘无损鉴别分析, 采用PCA及FLD方法建立鉴别模型。 FLD方法要求样本数为变量数的3~5倍, 因此采用PCA方法对数据进行降维处理, 利用得到的主成分建立PCA-FLD鉴别模型。
图1为不同光谱采集点的原始光谱。 光谱的大致走势与其他学者采集的柑橘光谱相似, 在8 500~8 300, 7 100~6 900, 5 700~5 500和5 200~5 000 cm-1四处有较为明显的波峰, 分别为CH第三泛频带、 CH第二泛频带、 CH的第一泛频带和CH与CO组合带[16, 17], 可能与柑橘中的还原糖、 果胶、 有机酸的近红外吸收有关。 此外, 原始光谱中存在明显的谱峰重叠、 较大背景、 基线漂移等干扰。 仅通过原始光谱无法实现不同产地柑橘的鉴别。 因此在建立鉴别模型前需采用预处理方法对原始光谱进行优化处理。
 | 图1 原始光谱图 (a)— (h): 赤道线1— 4、 果梗部、 果顶部、 赤道线4个点平均以及6个点平均Fig.1 The raw spectra (a)— (h): equator 1— 4, top, bottom, average of 4 points, average of 6 points, respectively |
采用PCA方法结合光谱预处理方法以建立不同产地柑橘的鉴别模型。 图2为赤道线4个采集点平均光谱结合单一预处理的PCA结果。 其中校正集样本用实心图标, 验证集样本用空心图标表示。 因为前两个主成分(PC1和PC2)对沃柑光谱数据变量的累计方差贡献率在90%以上, 因此选择PC1和PC2进行PCA分析。 从图2(a)可知, 不同产地沃柑数据的置信椭圆呈现交织状态, 鉴别率为0%; 经MSC, Min-Max和SNV单一预处理优化后鉴别率得到了提高, 但最佳鉴别率仅为5%[图2(b— i)]。 其他光谱采集点以及6个采集点平均光谱得到的结果也较为类似。 以上结果表明, 采用单一预处理结合PCA模型无法实现柑橘产地的鉴别分析。 为了进一步消除光谱中的多重干扰, 采用组合预处理优化光谱数据, 并建立PCA鉴别模型。 然而, 即使结合组合预处理优化处理, 赤道线4个点平均光谱的最佳鉴别率仅为2.5%。 此外, 在6个点的鉴别结果中, 组合预处理后的最佳鉴别分析结果也仅为5%, 可能是因为不同产地柑橘果皮干扰较大, PCA方法无损挖掘得到隐藏在柑橘皮中的差异信息。
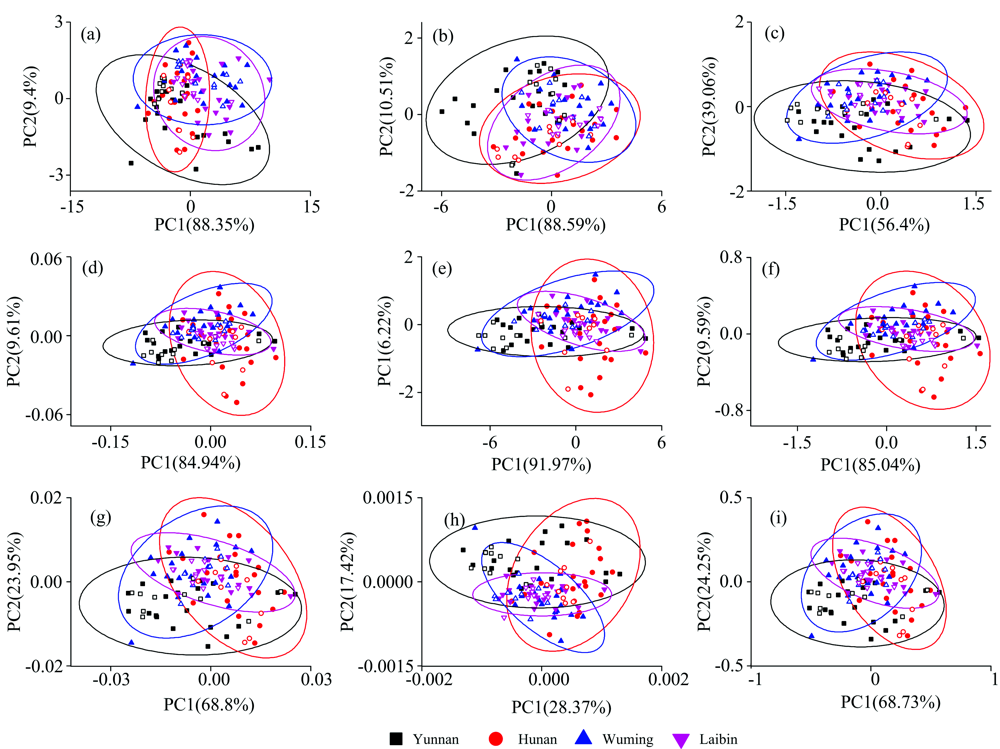 | 图2 赤道线4个采集点平均光谱结合单一预处理的主成分分析结果 (a)— (i): 原始光谱, DT, De-bias, MSC, Min-Max, SNV, 1st, 2nd和CWTFig.2 PCA results of 4 equator points average spectra with single pretreatment methods (a)— (i): raw spectra, DT, De-bias, MSC, Min-Max, SNV, 1st, 2nd and CWT, respectively |
FLD是一种有效的有监督分类方法, 常用于寻找目标类之间的最优边界。 为了使样本数达到变量数的3~5倍, 我们采用PCA方法对数据进行降维处理。 图3为随着主成分(PC)数量增加的累积方差贡献率。 可以看到, 随着PC数量的增加, 其方差贡献率迅速增加最终趋于100%。 除2nd预处理方法以外, 前30个主成分基本包含所有信息(> 99.99%), 且样本数刚好达到了变量数的3~5倍。 因此我们采用PC数为30的PCA-FLD方法对数据进行降维处理。
 | 图3 不同部位光谱分析的累计方差贡献率 (a): 赤道线4个点; (b): 赤道线4个点+果梗部+果顶部Fig.3 Cumulative variance contribution rates at different positions (a): 4 points on equator; (b): 4 points on equator+stem+top |
利用PCA-FLD结合单一与组合预处理优化以实现不同产品柑橘无损鉴别, 并考察不同光谱采集部位对结果的影响。 表1为不同预处理方法后的PCA-FLD结果。 由表中可以看出, 与PCA分析模型相比, PCA-FLD模型鉴别率得到了显著提高。 利用PCA-FLD方法分析4个点平均光谱数据时, 无需结合光谱预处理即可达到97.5%的鉴别准确率; 结合De-bias或MSC预处理可获得100%的鉴别准确率; 最低的鉴别率结果为经过2nd预处理后的67.5%, 可能原因是2nd预处理的累计方差贡献率小于99%。 采用6个点平均光谱数据时, 无需结合预处理方法, 便可实现不同产地柑橘的100%鉴别; 除CWT外, 其他单一预处理优化后的PCA-FLD模型鉴别结果均达到了100%; 经组合预处理优化的模型鉴别结果均超过90%。 图4为原始光谱经过De-bias预处理后的PCA-FLD结果, 表明PCA-FLD模型可以实现所有产地沃柑的鉴别分析。
| 表1 基于不同预处理的PCA-FLD模型鉴别准确率 Table 1 Identification accuracies by PCA-FLD with different pretreatment methods |
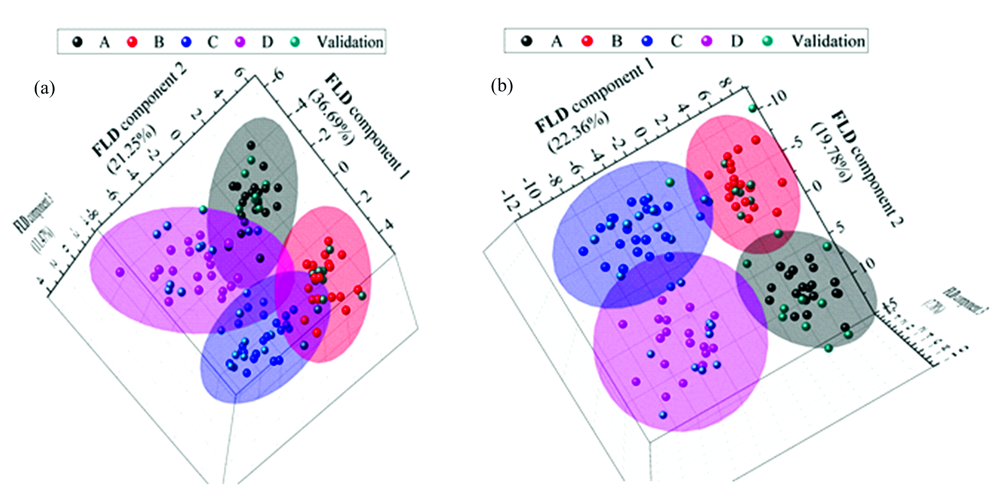 | 图4 De-bias预处理的PCA-FLD结果 (a): 赤道线4点平均光谱数据; (b): 6点平均光谱数据Fig.4 PCA-FLD results with De-bias method (a): 4 points average spectra; (b): 6 points average spectra |
基于近红外光谱结合化学计量学方法, 建立了不同产地柑橘的快速无损的鉴别方法。 在不破坏沃泔样品的情况下, 获得了沃柑赤道线及其果梗部、 果顶部共6个位置的光谱数据。 用光谱预处理方法对光谱进行优化处理, 并利用PCA与PCA-FLD模式识别方法建立鉴别模型, 同时对柑橘的光谱采集位置进行了优化。 结果表明: 仅通过预处理和光谱采集位置的优化, PCA方法都不能实现不同产地柑橘的鉴别分析, 最高鉴别率仅为5%; 采用PCA-FLD方法建立的模型鉴别结果显著优于PCA方法, 采用4个点平均光谱获得的鉴别率可达到97.5%, 结合De-bias或MSC预处理可以实现不同产地柑橘100%的鉴别; 当采用6个点平均光谱数据时, 无需预处理即可实现对不同产地柑橘的100%鉴别。 PCA与PCA-FLD的结果有很大差别, 主要原因是PCA为无监督的模式识别方法, 而采用有监督模式识别的FLD方法对不同产地沃柑6点平均光谱进行处理可实现100%的聚类分析, 因为该方法需提供类别的先验知识, 在处理分类问题时有更好的降维与分类效果。 本实验为不同柑橘产地的无损鉴别提供了一个参考, 在今后的研究中, 将对其他柑橘水果进行进一步分析, 以建立适用性更强的鉴别模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|