

{kind=link}
{kind=link}
{kind=link}
基于小波系数图和卷积神经网络的太赫兹光谱物质识别
[陈妍伶 , 程良伦
, 程良伦* , 吴衡* , 徐利民, 何伟健, 李凤]
, 程良伦, 吴衡, 徐利民, 何伟健, 李凤]
|
|


作者简介: 陈妍伶, 1997年生, 广东工业大学计算机学院硕士研究生 e-mail: jkjkre@qq.com
许多太赫兹光谱物质识别方法依靠寻找该物质在太赫兹波段范围内不同光谱表现出的不同特征来识别特定物质。 吸收峰提取法是常用的光谱特征提取算法, 但当光谱无明显特征吸收峰或峰位、 峰值相近或难以识别时, 难以利用吸收峰特征辨别物质。 将机器学习和统计学习技术用于太赫兹光谱的识别中虽减少了吸收峰的干扰, 但常常需要人为定义特征而导致分类误差。 深度学习法能自动提取特征, 但在识别前往往需要进行复杂的预处理操作, 并且在特征提取的过程中容易丢失部分特征从而导致分类误差。 针对以上问题, 提出了一种基于小波系数图和卷积神经网络的太赫兹光谱识别方法。 利用太赫兹光谱信号进行小波变换时, 由于小波系数矩阵的每一行系数与原始光谱信号存在着对应关系, 因此将太赫兹光谱的吸收系数通过小波变换在频率域上展开, 能得到不同的二维的频率-尺度分布图, 又称小波系数图。 然后构造一个卷积神经网络(CNN)对小波系数图进行分类, 可得到太赫兹光谱物质的分类结果。 为了验证所提出算法的有效性, 将三组小波系数图数据与原始光谱数据分别输入CNN、 Support Vector Machin (SVM)、 Multilayer Perceptron (MLP)三种不同的分类器作对比, 从实验结果可以发现本文算法在三组数据中的识别率均达到了100%, 说明相比于传统方法, 本文方法能准确分类没有明显特征吸收峰的光谱, 证明了使用卷积神经网络识别小波系数图的有效性。 为了体现本文算法的优势, 与小波脊线寻峰识别算法作对比, 实验结果表明本文算法几乎不受峰频、 峰位、 峰值的影响, 无论是识别不存在吸收峰的淀粉, 还是识别相似度高的蔗糖和葡萄糖, 都具有较高的识别率, 分类准确率达97.62%, 证明了所提算法的优越性。 该算法为太赫兹光谱数据识别提供了一种新思路, 同时也可以推广运用到其他谱图物质的识别中。
The terahertz spectrum material identification method mainly relies on finding the different characteristics of the different spectra of the substance in the terahertz band to identify a specific substance. The methods of absorption peak extraction are commonly used spectral feature extraction algorithm. However, when the spectrum has no obvious characteristic absorption peaks or peak positions, and peaks are similar or difficult to distinguish, it is difficult to use the absorption peak characteristics to distinguish substances. Although machine learning and statistical learning techniques to identify terahertz spectra reduces the interference of absorption peaks, it often requires an artificial definition of features to cause classification errors. The deep learning method can automatically extract features, but it often requires complex preprocessing operations before recognition, and it is easy to lose some features in the feature extraction process, leading to classification errors. A method of terahertz spectrum identification based on wavelet coefficient graph and convolutional neural network is proposed. When using the terahertz spectrum signal for wavelet transformation, each row of the wavelet coefficient matrix has a corresponding relationship with the original spectrum signal. The absorption coefficient of the terahertz spectrum is expanded in the frequency domain through wavelet transformation to obtain different two-dimensional frequency-scale distribution diagrams, which are also known as wavelet coefficient maps. Then a convolutional neural network (CNN) is constructed to classify the wavelet coefficient graph, and the classification result of the terahertz spectrum material can be obtained. To verify the effectiveness of the proposed algorithm, the three sets of wavelet coefficient maps and the original spectral data were input into three different classifiers of CNN, Support Vector Machin (SVM), Multilayer Perceptron (MLP) respectively for comparison. From the experimental results, we can find the recognition of the algorithm in the three sets of data. The rates reach 100%, indicating that compared with traditional methods, the method in this paper can still accurately classify spectra without obvious characteristic absorption peaks, which proves the effectiveness of using convolutional neural networks to identify wavelet coefficient maps. To show the advantages of the proposed algorithm in this paper, we compared it with the wavelet ridge peak-finding recognition algorithm. The experimental results show that the proposed algorithm is hardly affected by peak frequency, peak position, and peak value. Whether to identify the starch without an absorption peak or to identify high similarity sucrose and glucose, a high recognition rate is achieved by the proposed algorithm, and the classification accuracy rate is up to 97.62%, which proves the superiority of the proposed algorithm. The proposed algorithm provides a new idea for identifying terahertz spectrum data and can also be extended to the identification of other spectrum substances.
由于不同物质在太赫兹波段范围内会产生不同的分子振动[1], 从而每种物质在振动频率范围内都会表现出不同的特征吸收系数, 因此可以通过提取这些特征对光谱进行分类。
许多太赫兹光谱物质识别方法依赖于在太赫兹波段中寻找物质不同光谱表现出的不同特征来识别特定物质, 如何有效提取特征是光谱分类的关键。 由于许多物质在太赫兹波段内具有明显吸收峰[2], 因此吸收峰提取法是常用的光谱特征提取算法之一。 何伟健等提出了一种吸收峰混叠的太赫兹光谱区间拟合算法, 通过遗传算法得到最优的拟合子区间组合和吸收峰频率的近似值, 实现了纯净物和不同含量混合物的快速分类[3]。 解琪等通过提取不同场合的爆炸物特征吸收光谱进行比对, 实现爆炸物的识别[4]。 殷清燕等通过调用太赫兹光谱数据库, 采用模板匹配和吸收峰峰值, 面积比对的方法, 完成混合火炸药的太赫兹特征光谱识别[5]。 通过寻找特征峰虽能有效地识别物质, 但当光谱无明显特征吸收峰或峰位、 峰值相近或难以辨别时, 则难以利用吸收峰特征辨别物质, 并且传统寻峰算法对假峰、 弱峰、 混叠峰的识别能力有限。 相对于红外光谱、 X射线衍射以及拉曼光谱而言, 太赫兹光谱更易受到外界环境波动以及分子结构改变的影响, 导致峰值特性所对应的结构信息的确定性更低, 且局部特征不突出。 因此, 利用吸收峰提取法来识别物质存在一定的局限性。
除了吸收峰提取法外, 机器学习、 统计学习和深度学习技术也常应用于太赫兹光谱特征提取。 目前, 已有不少学者开展了相关的研究工作。 Liu等采用遗传算法对四种不同地区的特级初榨橄榄油的吸收光谱进行特征提取, 并使用最小二乘支持向量机进行分类, 准确率达96.25%[6]。 该方法对于小样本分类有较高的识别率, 但是对于多样本分类的数据集使用遗传算法往往容易陷入局部最优解, 后期搜索特征效率低。 Huang等通过对吸收光谱的特征进行采样, 得到不同的特征频率点, 结合K-均值聚类算法对16种样品进行分类, 准确率达75%[7]。 该方法需要人工预先定义光谱特征, 容易受到人为因素的干扰而影响分类的精确度。
小波变换是一种有效的信号分析方式, 能通过变换充分突出问题某方面的特征。 Lu等首先用连续小波变换法判断一个区间内是否存在混叠峰, 存在的话使用二阶导数识别其中的混叠峰, 并确定混叠峰位置及数量[8]。 但光谱中的噪声也会形成极大值, 对脊线形状造成了一定的干扰。 目前都是通过值比较来寻找脊线位置, 这限制了该方法对弱吸收峰的检测性能。 为了避免寻找吸收峰失误对太赫兹光谱识别的影响, 本文将太赫兹光谱的吸收系数通过小波变换在频率域上展开, 得到不同的二维的频率-尺度分布图, 又称小波系数图, 然后利用小波系数图的唯一性, 使用卷积神经网络(convolutional neural networks, CNN)对小波系数图进行分类, 将传统方法对一维光谱数据的识别转化为对二维图像数据的识别。 相对传统方法而言, 小波系数图无需经过复杂的预处理操作, 不容易受弱峰、 假峰、 混叠峰的影响, 也不过分依赖待测样品的成分以及含量等信息, 对于其他光谱数据处理依然有良好的泛化能力。
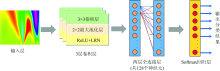
实验中的太赫兹吸收光谱数据由日本ADVANTEST公司的TAS7400太赫兹时域光谱仪系统采集, 光谱仪系统如图1所示。 该系统使用两个超短脉冲激光器(1.55 μ m)做偏置输出(太赫兹波产生)和信号输入(太赫兹波探测), 其中心波长为785 nm, 最大输出功率50 mW, 能够测量0.1~5 THz的太赫兹光谱。 其利用太赫兹波的特性, 可进行快速且多功能的光谱和成像的分析, 可用于药品等材料的非破坏性光谱分析, 并且全自动系统保留数据。
 | 图1 TAS7400太赫兹时域光谱仪Fig.1 TAS7400 terahertz time domain spectrometer |
实验所选用的样品纯度均在98%以上, 为了减少太赫兹波散射对采集信号的影响, 在测量样品光谱前需使用10 t千斤顶压片机将样品压片成直径约13 mm, 厚约1.5 mm的圆片。 完成样品制片后在干燥环境下使用光谱仪分步测量背景和样品。 首先测量背景, 当背景光谱曲线平滑, 没有明显的吸收峰时, 保存背景。 调用上述保存好的背景后, 接着分别测定样品的光谱曲线, 每次采集光谱后略微调整样品的位置, 每个物质分别调整30次, 每种样品共采集到30个吸收光谱数据, 其中, 截取了0.3~2.25 THz范围内光谱信号信噪比较高的频段。 实验共测得的样品种类为20种, 其中10种物质有明显的吸收峰, 10种物质无明显吸收峰或没有吸收峰, 共采集到600个太赫兹光谱数据, 样品种类汇总明细如表1所示。
| 表1 实验样品汇总表 Table 1 Summary of experimental sample |
1.3.1 连续小波变换获取太赫兹光谱小波系数图
对一维的太赫兹光谱信号进行连续小波变换。 在变换过程中使用不同的尺度控制小波的伸缩范围, 并与太赫兹光谱吸收系数f(x)做内积得到小波系数矩阵, 从而将一维的频率映射到二维的参数空间, 形成了一种能在频率和尺度上具有变化的小波系数图谱。 小波变换(wavelet transform, WT)以母函数为基础, 通过选取小波参数将数据或数据系列变为级数系列从而找到其类似的频谱特征[9]。 光谱信号的连续小波变换的二维频率-频率表达式为
式(1)中, τ 为平移因子, ∂ (∂ ≠ 0)为尺度因子, φ 为小波基函数, * 为复共轭。 f(x)为太赫兹的吸收光谱系数。 Wf(∂ i, τ i)是小波系数的二维矩阵, 包含i和j个维度, i表示为分解尺度(i=1, 2, 3, …, m), j表示光谱的频率范围(j=1, 2, …, n), 构成了m× n矩阵。
由于墨西哥帽小波(Mexican-hat, Marr)在时域和频域范围都具有良好的局部特性, 并且对各种信号都具有高度适应性, 因此选择Marr函数作为小波母函数对光谱信号进行小波运算, 通过尺度的变换和平移可以得到不同尺度范围内的频率分辨率, 能清晰地反映信号特征。 Marr函数为Gauss函数的二阶导数, 其表达式为
尺度参数∂ 越小, 能提取越多的光谱特征。 尺度参数的最大值应比谱线的最大半高宽大1.5~2倍, 尺度过大增加了计算量却无法提高精度。 由于尺度因子∂ 范围的设定对光谱特征的识别有一定的影响, 因此将尺度因子∂ 设置在合理的范围之内。 结合太赫兹谱线的特性, 本文将∂ 的范围设为[1, 40], 这有利于特征的提取以及增加计算效率。
平移因子τ 的选择应遍历整个光谱数据频率范围。 本文截取了0.3~2.25 THz范围内的光谱频段, 因此平移因子τ 的取值为0.3, 0.4, …, 2.25。
太赫兹光谱数据是一组包含频率-吸收系数的离散数据组, 一次循环输入所有数据组, 并将尺度参数∂ , 平移参数τ 以及Marr母小波函数代入式(1), 可得到一组在(∂ , τ )下的小波变换系数Wf(∂ i, τ i), 最终将二维的小波系数Wf(∂ i, τ i)输出为光谱信号的小波系数图。
1.3.2 基于卷积神经网络的小波系数图识别
卷积神经网络(CNN)是一种具有深度监督学习特性的多层神经网络, 能自动提取低、 中和高层特征[10]。 CNN一般用于处理二维图像数据, 使用卷积层, 池化层和完全连接层分类数据和产生输出[11]。 本文采用卷积神经网络训练模型, 设计的网络结构图如图2所示, 包括3个卷积层、 2个全连接层, 以及1个Softmax层, 其中卷积层又包括卷积层和池化层。
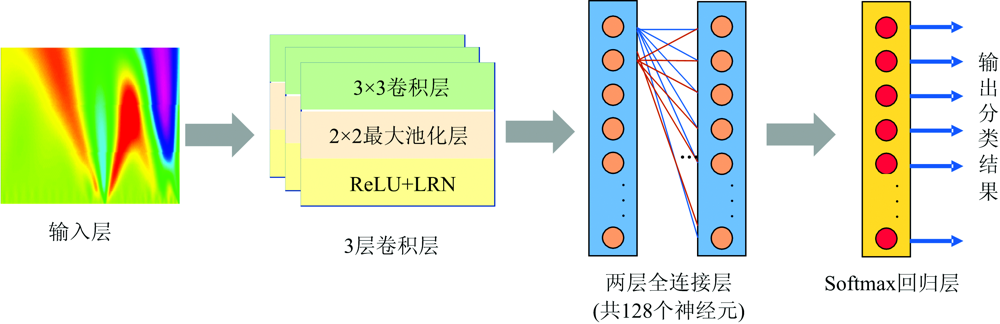 | 图2 卷积神经网络结构图Fig.2 Convolutional neural network diagram |
使用所得小波系数图中的随机选取样本{X, YP}作为卷积神经网络的训练集对其进行训练, 其中X表示待输入的图像, YP表示待输入图像实际类别。 在训练完成后, 用该网络对输入的未分类小波系数图进行分类。 其中, 卷积层用m个n通道的h× w的卷积核对小波系数图的图像进行步幅为1的卷积, 经过卷积层的计算得到新一层的特征图。 设通道数为n, 卷积核尺寸为3× 3, 第i个卷积核进行卷积运算的计算如式(3)
式(3)中, ω x, y, z为特征Xx, y, z的权重系数, b为偏置量, f(· )为线性整流函数(rectified linear unit, ReLU), 其中, ReLU的计算公式如式(4)
最大池化层采用滑动窗口分割图像, 取滑窗内最大值作为输出。 每次取3× 3滤波器尺寸进行最大池化, 设置步长为2, 则最大池化过程可表示为
经最大池化(max pooling)进行步幅为2的降采样后, 得到的n通道的
为了增强该模型的泛化能力, 对神经网络隐藏层的输出进行局部响应归一化操作(local response normalization, LRN)[12], 计算如式(6)
式(6)中, α , k和β 为超参数, 分别设置为e-4, 1和0.75。 m为卷积核的总数, t为同一位置上邻近卷积核的总数。 所有卷积完成后获得的输出结果作为全连接层的输入, 然后全连接层将网络中每一层的所有节点与相邻层中的所有节点连接起来。 待经过两个全连接层处理后, 再通过Softmax回归层将输出转变为概率分布, 最终可获得输入卷积神经网络的小波系数图属于某类别的概率, 实现太赫兹光谱物质分类。
依次将表1中20种物质的太赫兹光谱数据利用本文所提的小波变换方法得到小波系数图。 在这20种物质的600个光谱数据中, 从不同类别中随机选取两种物质的太赫兹光谱曲线图和小波变换图作为对比如图3所示。 从图3的光谱曲线图可知, 葡萄糖、 麦芽糖存在吸收峰, 而淀粉、 硫酸钠则不存在吸收峰。 因此当使用寻峰算法来识别光谱物质时, 可能会出现找不到吸收峰而无法识别出物质的情况。 同时, 太赫兹光谱仪在获取时域信号的过程中易受到环境、 设备以及样品因素的影响, 导致光谱中含有大量噪声。 由于不同物质在太赫兹波段范围内会表现出不同的特征吸收系数, 所以一般根据峰值信息所在位置人工截取相应的太赫兹波段作为特征范围, 而这种特征范围的选取往往是盲目的, 如本文截取的0.3~2.25 THz范围内光谱信号频段, 这部分频段在葡萄糖和麦芽糖具有较高的信噪比, 而对于淀粉或硝酸钠在1.5~2.25 THz波段内却有明显的噪声。 对于许多太赫兹光谱特征提取算法来说这部分噪声对光谱数据的干扰很大, 因此在特征提取前往往要预先平滑数据从而减轻或消除干扰因素。 而本文方法则避免了这类算法的局限性, 直接将原始的光谱数据通过小波变换转化为小波系数图。 从图3的小波系数图中可以看出, 四种物质的小波系数图都是唯一的, 其不受波段范围选取以及噪声的影响, 依然具有明显的特征。 不同物质的小波系数图对应其频率特征, 将其放入分类器训练能达到良好的分类效果。
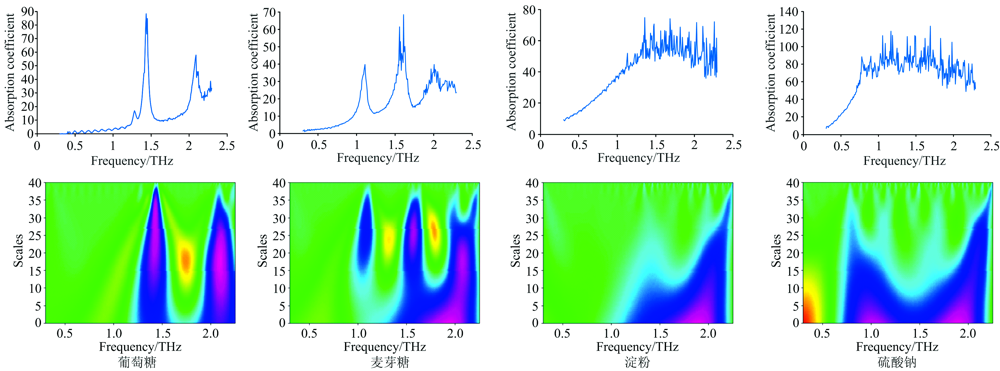 | 图3 太赫兹光谱曲线图和小波系数图Fig.3 Terahertz spectral curves and wavelet transform graph |
将表1样品的光谱数据按照有无吸收峰分成三组: 第一组包含乳糖、 葡萄糖、 果糖在内的10种含有吸收峰的光谱数据, 第二组包含红磷、 淀粉、 乙基麦芽酚在内的10种无明显吸收峰或不含吸收峰的光谱数据, 第三组为这20种物质的吸收谱数据。 每组的数据按照2: 8的比例划分为训练集和测试集, 将这三组数据经过小波变换得到小波系数图后分别采用CNN、 支持向量机模型(support vector machin, SVM)、 多层感知模型(multilayer perceptron, MLP)对小波系数图进行分类, 得到光谱物质的分类结果。 为了验证实验的有效性, 将原始的光谱数据输入上面三种模型作对比。 鉴于参数的选择对模型的影响比较大, 因此统一了模型的参数。 其中, MLP和SVM模型分别调用sklearn库里的MLPClassifier函数、 svm.SVC函数, 参数均使用默认参数。 本文的CNN模型采用学习率λ 为0.005的自适应时刻估计算法优化梯度下降。 其中第1个卷积层使用64个3通道的3× 3的卷积核, 第2个卷积层使用32个3× 3的卷积核, 第3个卷积层使用16个3× 3的卷积核, 卷积步长设置为1。 用于最大池化的滤波器尺寸均为2× 2, 步长设置为2。 每个全连接层包含128个神经元。 每种模型独立重复测量10次取均值作为该方法的识别率, 不同方法得出的识别率如表2所示, 其中, a代表用原始数据直接在分类器里识别的结果, b为将原始数据转化为小波系数图后的识别结果, CNN分类模型中的b组为本文所提算法。
| 表2 不同分类模型的识别率汇总 Table 2 Summary of pure substances recognition results |
从表2中可以发现, b的识别率普遍高于a, 其中SVM分类器提升幅度较明显, 每组的识别率均提升了一倍以上, 说明了将太赫兹光谱的一维数据转化为二维的小波系数图数据后识别有助于提高太赫兹光谱物质的识别率。 CNN模型上第一组的识别率均达到100%, 证明了卷积神经网络对太赫兹光谱识别的有效性。 由于受到吸收峰的影响, 第二组数据集在三种分类器中的分类性能总体低于第一组的分类性能, 但是其对b算法的影响较小, 说明转化为小波系数图后在三种分类器中均有良好的分类性能。 本文算法在三组中的识别率均达到了100%, 证明了使用卷积神经网络识别小波系数图的有效性。
取表1中麦芽糖、 乳糖、 果糖、 葡萄糖、 蔗糖、 淀粉这六种常见糖类的太赫兹光谱数据, 用本文算法与小波寻峰算法作对比。 在使用小波寻峰算法前, 由于光谱噪声对寻峰算法的影响比较大, 首先需要对光谱进行预处理, 本文选用非对称最小二乘法预处理光谱信号, 得到一组平滑后的光谱数据, 然后通过小波变换进行特征提取, 得到二维小波系数矩阵中各行的模极值并连接成脊线, 脊线中尺度最大的位置即为吸收峰的频率位置, 最后通过吸收峰频率匹配识别算法求出每种物质的识别率。 其中, 吸收频率匹配算法是将实验所求的吸收峰与太赫兹光谱数据库(http://thzdb.org/)的标准吸收峰的频率作比较得到的结果, 频率误差均在允许范围之内[13]。 重复20次实验, 取均值作为最终结果。 本文算法采用CNN模型进行光谱分类对比, 经过150次迭代后, 训练集的精确度达到100%。 对测试集的84张小波系数图片进行分类, 其中分类正确的小波系数图有82张, 准确率达到97.62%。
表3列出了两种方法的对比结果, 寻峰算法容易受到假峰、 弱峰、 混叠峰等因素的影响, 导致识别率明显低于本文算法。 葡萄糖有三个的标准吸收峰值, 分别为1.281, 1.435和2.080, 蔗糖的标准吸收峰为1.442, 与葡萄糖有着相似的吸收峰, 对于频率匹配算法来说影响相当大, 导致蔗糖的识别率仅为25%。 而本文算法几乎不受峰频、 峰宽、 峰值等因素的影响, 无论是识别不存吸收峰的淀粉, 还是识别相似度高的葡萄糖和蔗糖, 都具有较高的识别率, 证明了所提算法的准确性和有效性。
| 表3 两种方法的识别率汇总 Table 3 The recognition rate summary of the two methods |
针对太赫兹光谱物质识别所面临的问题, 如难以人工定义无明显吸收峰的特征或峰位、 峰值相近而难以辨别, 对假峰、 弱峰、 混叠峰的识别能力有限等, 提出了一种基于小波系数图的光谱物质识别方法, 把原始方法对一维光谱数据的识别转化为对二维图像数据的识别, 并通过CNN, SVM和MLP这三种不同的分类器对比验证, 结果显示每种分类模型都达到了较高的准确率, 与小波寻峰识别算法作对比, 识别率远远超越寻峰算法, 分类准确率达97.62%, 从而证明本文方法的有效性和准确性。 本文算法为太赫兹光谱数据识别提供了一种新思路, 也可以推广运用到其他谱图物质的识别中。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|