


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱影像的鲜桃可溶性固形物含量预测模型
[杨宝华 , 高志伟, 齐麟, 朱月, 高远]
, 高志伟, 齐麟, 朱月, 高远]
, 高志伟, 齐麟, 朱月, 高远]
|
|


作者简介: 杨宝华, 女, 1974年生, 安徽农业大学信息与计算机学院教授 e-mail: ybh@ahau.edu.cn
可溶性固形物含量(SSC)是决定鲜桃风味和品质的重要成分。 高光谱影像的特征提取为无损检测可溶性固形物含量提供了数据基础和方法路径。 先前的研究表明, 基于多光谱、 荧光谱、 近红外光谱、 电子鼻的水果内部品质评估取得较好的结果。 但是, 由于缺少多特征融合, 从而限制了水果品质的精准估测。 为此, 提出了一种基于堆栈自动编码器-粒子群优化支持向量回归(SAE-PSO-SVR)模型预测鲜桃可溶性固形物含量。 首先, 利用高光谱影像提取光谱信息、 空间信息及空-谱融合信息。 其次, 设置普适性堆栈自动编码器(SAE)提取光谱信息、 空间信息及空-谱融合信息的深层特征。 最后, 将深层特征作为粒子群优化支持向量回归(PSO-SVR)模型的输入数据进行鲜桃可溶性固形物含量的预测。 其中, 对于光谱信息作为输入的SAE模型, 设计了453-300-200-100-40, 453-350-250-150-50, 453-350-250-100-60的三个隐含层结构。 对于空间信息作为输入的SAE模型, 设计了894-700-500-300-50, 894-650-350-200-80, 894-800-700-500-100的三个隐含层结构。 对于融合信息作为输入的SAE模型, 设计了1347-800-400-200-40, 1347-750-550-400-100, 1347-700-500-360-150的三个隐含层结构。 实验结果表明, 对于输入数据分别为光谱信息、 空间信息及融合信息的SAE模型, 结构为453-300-200-100-40, 894-800-700-500-100和1347-750-550-400-100的模型效果较好, 而且基于融合信息的模型预测精度明显优于基于光谱信息或者图像信息的模型。 为了验证模型的普适性, 利用结构为1347-750-550-400-100的SAE模型提取融合信息的深层特征估测不同品种鲜桃的可溶性固形物含量并进行可视化。 结果表明, 基于结构为1237-650-310-130的SAE-PSO-SVR模型预测效果最好( R2=0.873 3, RMSE=0.645 1)。 因此, 所提出的SAE-PSO-SVR模型提高了鲜桃可溶性固形物含量的估计精度, 为鲜桃的其他成分检测提供了技术支撑。
Soluble solid content (SSC) is a key factor to evaluate the flavor and quality of fruits. The feature extraction of hyperspectral images provides the data basis and method path for the non-destructive estimation of the solid soluble content. Previous studies have shown that fruit internal quality evaluation based on multi-spectrum, fluorescence spectrum, near-infrared spectrum, and electronic nose has achieved good results. However, the lack of multi-feature fusion limits the accurate estimation of fruit quality. Therefore, this study proposed a model based on stacked autoencoder-particle swarm optimization-support vector regression (SAE-PSO-SVR) to predict the solid soluble content of fresh peaches. Firstly, hyperspectral images extracted spectral information, image pixel information corresponding to different bands, and fusion information. Secondly, a universal stacked autoencoder (SAE) was set up to extract the deep features of spectral information, spatial information, and space-spectrum fusion information. Finally, the deep features were used as the input data of the particle swarm optimization-support vector regression (PSO-SVR) model to predict the solid soluble content of fresh peaches.Among them, three hidden layer network structures were designed for the SAE model with spectral information as input data, including 453-300-200-100-40, 453-350-250-150-50 and 453-350-250-100-60. Three network structures of hidden layer nodes were designed forthe SAE model with image information as input data, including 894-700-500-300-50, 894-650-350-200-80 and 894-800-700-500-100. Three hidden layer network structures were designed forthe SAE model with fusion information as input data, including 1347-800-400-200-40, 1347-750-550-400-100 and 1347-700-500-360-150.The experimental results show that the models with SAE structures of 453-300-200-100-40, 894-800-700-500-100 and 1347-750-550-400-100 have the better estimation effect for spectral information, image information and fusion information as input data of the SAE model, and the prediction accuracy of the model based on the deep features of the fusion information was significantly better than that of the model based on spectral features or image features. The SAE model with the structure of 1347-750-550-400-100 was used to extract the deep features of the fusion information to estimate and visualize the solid soluble content of different varieties of fresh peaches. The results show that the prediction performance based on the SAE-PSO-SVR model was the best ( R2=0.873 3, RMSE=0.645 1). Therefore, the SAE-PSO-SVR model proposed can improve the estimation accuracy of solid soluble content of fresh peaches, which provide technical support for detecting other components of fresh peaches.
鲜桃是一种营养丰富和风味甜香的水果, 可溶性固形物含量(soluble solids content, SSC)作为影响鲜桃风味的重要成分, 也成为衡量鲜桃品质的重要参考标准, 因此, 精准估测SSC对于鲜桃分级和评价具有重要的研究意义和应用价值。
目前, 随着传感器和数据分析技术的快速发展, 无损估测水果可溶性固形物含量被广泛研究及应用。 其中, 近红外光谱、 多光谱、 荧光谱、 电子鼻等已经成功地检测鲜果SSC[1, 2, 3, 4]。 然而, 目前大部分研究基于单一特征检测, 从而限制了水果SSC预测模型的进一步探究。 近年来, 高光谱影像(hyperspectral image, HSI)不仅提供光谱维信息, 还提供空间维信息, 常常被广泛用来检测水果的SSC[5]。 Fan等融合了光谱特征和纹理特征成功检测苹果的SSC[6], Li等利用高光谱影像估测鲜桃的SSC[7]。 结果表明, 基于高光谱影像特征估测SSC的可行性。 然而, 大部分研究仅基于光谱维信息, 容易导致SSC估测模型过拟合。
随着深度学习在不同领域的应用, 为鲜桃SSC预测提供了新思路和新方案。 堆叠自动编码器(stacked auto-encoder, SAE)[8]作为深度学习方法, 具有较强的特征能力, 从而提高预测模型的精确性。 因此, 在这项研究中设计不同结构的堆叠自动编码器, 分别提取高光谱影像的光谱维、 空间维及空-谱维信息的深层特征, 为鲜桃SSC的定量分析提供技术路径。
1.1.1 鲜桃样本及SSC数据采集
2019年6月, 在市场上购买了不同品种的成熟鲜桃样本120个(黄金蜜桃、 蟠桃和油桃各40个, 单果重量在160~240 g之间)。 所有鲜桃表面被清洁处理后放置于25 ℃ 的环境中保存12 h, 使样品温度与室温基本一致。
通过手持型折射计(Model: LYT-330, Shanghai Linyu Trading Co., Ltd., China)测量鲜桃样本的SSC, 其测量范围为0~32° Brix, 分辨率为0.2° Brix。 测量鲜桃样本SSC时, 在样品进行光谱采集部位对应的鲜桃果肉深度为5~8 mm处, 取出果汁滴在折射计的检测窗口, 3次重复采集的均值作为鲜桃样本SSC的真实值。 所测样本集SSC含量在6.0~14.2° Brix之间。 共计120个样本, 按照3:1划分为校正集(90个)和验证集(30个)。
1.1.2 高光谱影像采集
利用高光谱影像采集系统获取鲜桃高光谱影像数据, 该系统包括1个光谱成像仪(Imspector V17E, Spectral Imaging Ltd., Oulu, Finland)、 1个摄像机为CCD相机(IPX-2M30, ImperxInc., Boca Raton, FL, USA), 2个150 W的卤素灯(3900, Illumination Technologies Inc., New York, USA), 1个数据采集暗箱, 图像采集和分析软件(Spectral Image Software, Isuzu Optics Corp., Taiwan, China)组成, 反射式线性光道管和电控位移平台(MTS120, 北京光学仪器厂, 中国), 光源照射方向与竖直方向呈45° , 整个采集系统置于暗箱内。
为了获得高质量的图像, 鲜桃样本的最高点到物镜距离为220 mm, 电动机控制速度和曝光时间分别设置为0.8 mm· s-1、 2 ms, 系统的光谱分辨率和图像大小分别为5 nm、 636×838像素。 为了尽可能降低图像噪声和暗电流的影响, 扫描鲜桃样本后, 使用标准白色和深色参考图像对获得的高光谱数据进行校准。
1.2.1 堆栈自动编码器
自动编码器(auto-encoder, AE)是一种运行在人工神经网络上的基于无监督学习, 由编码器和解码器两部分构成, 其功能就是对输入样本进行学习并在输出中重构数据。 通常将输入数据通过非线性激活函数映射到隐含层的阶段称为编码, 将隐含层映射至输出层称为解码。 因此, AE就是一个小型的深度学习模型, 该模型主要包括输入层、 隐含层和输出层。
堆栈自动编码器(SAE)是通过多个自动编码器堆叠构成的[10]。 按照无监督的方式, 利用贪婪训练的方法, 对每个自动编码器进行单独训练。 编码器相邻层中, 前一层的输出结果既是该隐含层的输出, 也是后一隐含层的输入。 SAE通过逐层训练可以从原始数据中获得有效的特征, 以减少原始信息的数据维数和干扰因素, 避免因过高的维数和原始数据的共线性等问题而导致过拟合现象。 因此, 最后一个隐含层的输出结果就是利用SAE提取原始信息的深层特征。
1.2.2 估测鲜桃SCC的模型构建及评价
精确地提取特征是模型构建的重要前提。 为了获取光谱信息和空间信息的特征, 首先获取鲜桃样本的光谱数据, 在鲜桃的邻近赤道部位选定一个200×200 pixels的图像感兴趣区域(region of interest, ROIs), 利用ENVI软件提取该区域范围内所有像素点的反射率; 其次, 利用HSI获得每个鲜桃样本的636×838×508图像; 然后, 提取有效波段对应高光谱影像的特征。 最后, 为了提取空-谱特征, 将光谱维和空间维的原始信息进行融合。
为了预测鲜桃SSC, 设计了堆栈自动编码器-粒子群优化支持向量回归(stacked autoencoder-particle swarm optimization-support vector regression, SAE-PSO-SVR)模型。 将光谱维、 空间维和融合信息分别输入到SAE模型, 在SAE提取光谱信息、 图像信息和融合信息的深层特征基础上, 采用粒子群优化支持向量回归(particle swarm optimization-support vector regression, PSO-SVR)模型估测鲜桃SSC, 如图1所示。 其中, 本研究设计的SAE结构包括三层隐含层, 隐含层神经元节点数通过模型训练及参数微调确定。 第三层隐含层的输出作为PSO-SVR模型的输入变量。
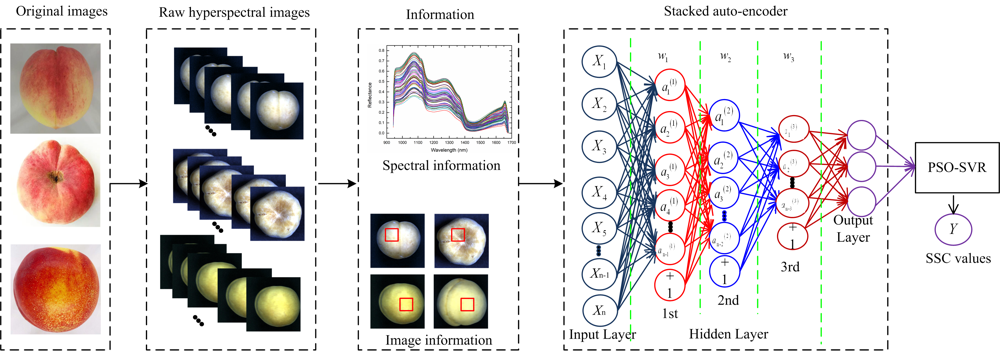 | 图1 基于堆叠式自动编码器-粒子群优化支持向量回归预测鲜桃可溶性固形物含量模型Fig.1 Model for predicting the soluble solid content of peaches based on stacked autoencoder-particle swarm optimization-support vector regression |
最后, 利用决定系数(coefficient of determination, R2)和均方根误差(root mean square error, RMSE)作为解释和量化预测鲜桃SSC模型的评价指标。 实验的硬件实验环境配置如下:主板为Z370 HD3-CF, CPU 为 Intel Core i7-8700, 显存为8GB GDDR5, 内存16 GB。 软件环境配置为:操作系统为 Windows 10(64 位), 编程软件和语言分别为 Anaconda3、 matlab2017和python3.6, 深度学习框架为 Keras。
图2所示为从不同鲜桃样本高光谱影像中提取的光谱反射率, 该光谱曲线包含508个波段(908~1 735 nm), 去除部分噪声明显的首尾波段, 包括光谱曲线首端908~940 nm共21个波段, 末端1 681~1 735 nm共34个波段。 剩余的453个波段(942~1 680 nm)作为光谱信息。 鲜桃样本的光谱曲线可以有效地反映鲜桃中SSC等主要成分的化学信息, 光谱反射强度与SSC含量存在一定的相关性。 因此, 含有不同SSC的鲜桃样本在不同波段下的光谱反射率存在一定的差异。
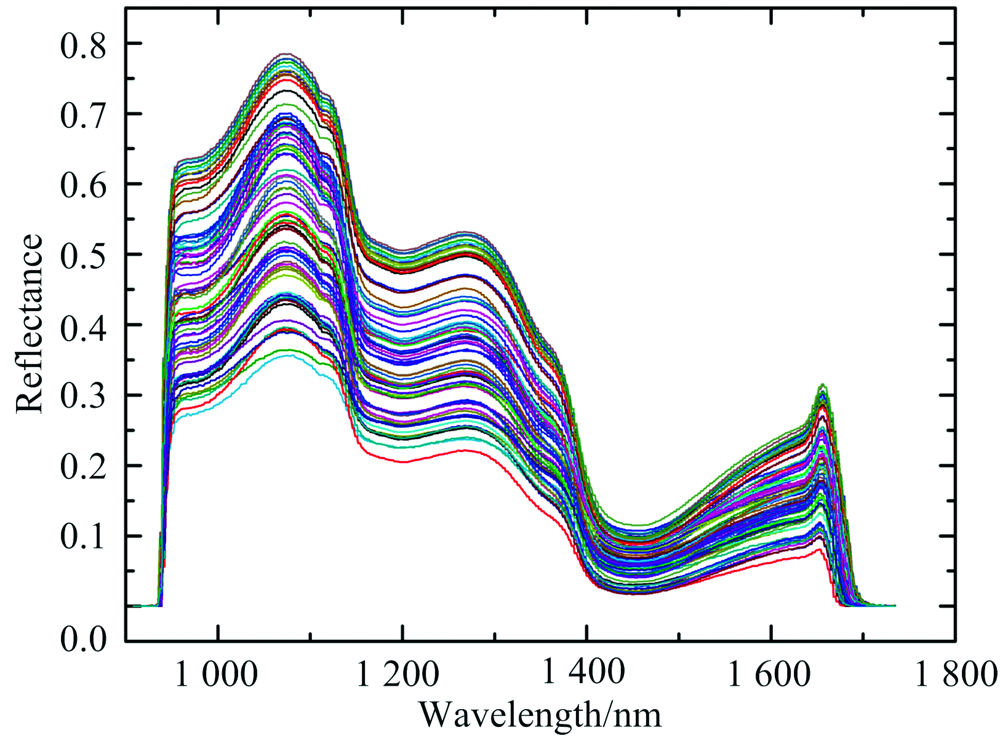 | 图2 鲜桃的高光谱原始曲线Fig.2 The original hyperspectra of fresh peaches |
为了获取空间维信息, 利用鲜桃样本高光谱影像设置5个不同的感兴趣区域(50×50 pixels)提取2 500维像素信息, 取其平均值作为该样本的空间信息。 为了提取敏感空间信息, 利用随机森林(random forest, RF)选取相对重要性大于0.11的信息(如图3所示), 共计894个敏感空间信息作为SAE的输入, 输出的结果就是高光谱影像的深层特征。 为了获取鲜桃高光谱影像的融合信息, 将453维光谱信息和894维空间信息融合, 共计1 347维融合信息。
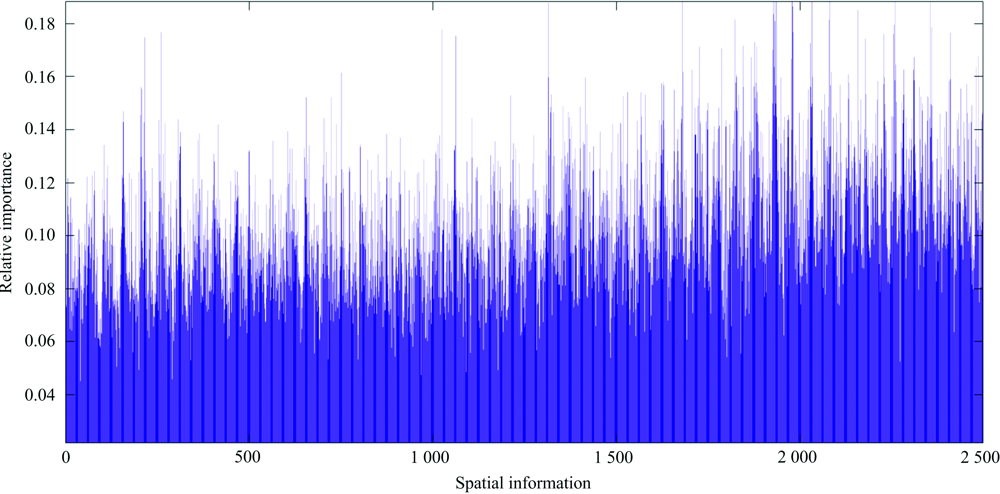 | 图3 鲜桃高光谱影像空间信息的相对重要性Fig.3 The relative importance of spatial information of fresh peach hyperspectral images |
为了对比不同SAE结构的预测效果, 分别利用光谱信息、 空间信息和融合信息设置不同的SAE结构提取深层特征, 作为粒子群优化支持向量回归(PSO-SVR)模型的输入变量, 构建鲜桃SSC的估测模型, 结果如图4所示。 对于校正集, 基于光谱信息深层特征、 图像信息深层特征、 融合信息深层特征的估测模型R2分别分布在0.723 4~0.826 9, 0.739 2~0.802 6和0.758 3~0.873 3之间。 对于验证集, 基于光谱信息深层特征、 图像信息深层特征、 融合信息深层特征构建的估测模型R2分别分布在0.677 5~0.782 5, 0.685 5~0.776 6和0.693 7~0.820 9之间。 其中, 基于融合信息提取的深层特征估测鲜桃SSC的效果出色。 尤其是, SAE模型结构为1347-750-550-400-100模型的R2达到0.873 3(校正集)和0.820 9(验证集), 比基于光谱信息的模型(SAE结构为453-300-200-100-40)R2提高5.3%和4.7%, 比基于图像信息的模型(SAE结构为894-800-700-500-100) R2提高8.1%和5.4%。
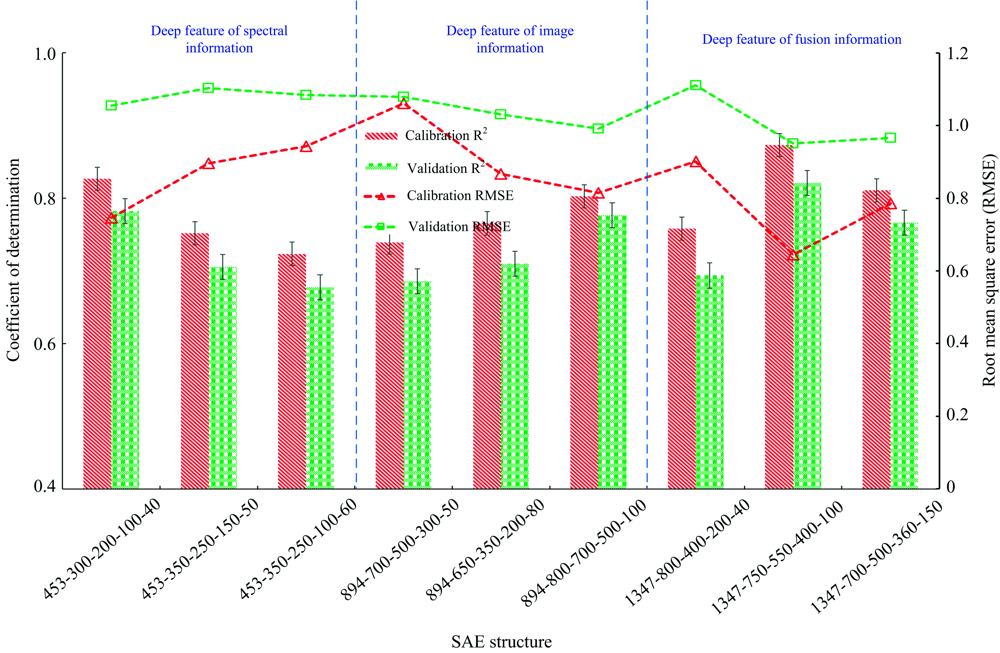 | 图4 基于不同结构的SAE-PSO-SVR模型预测鲜桃SSC结果Fig.4 The results of predicting SSC of peach based on the SAE-PSO-SVR model with different structures |
隐含层神经元节点是 SAE模型的关键参数之一, 设置合适的节点对提高模型精度起到重要作用。 因此, 根据鲜桃高光谱影像不同类型原始信息提取的深层特征, 经过参数调整、 数据训练以选择合适的SAE 模型。 对于光谱信息, SAE模型设置了三种结构(453-300-200-100-40, 453-350-250-150-50, 453-350-250-100-60)。 其中, 利用隐含层为300, 200和100的SAE提取深层特征进行鲜桃SSC预测的精度是最好的, 比其他两种SAE结构预测效果分别提高9.8%和13.4%。 对于空间信息, SAE模型设置了三种结构(894-700-500-300-50, 894-650-350-200-80, 894-800-700-500-100), 从模型训练的结果表明第一层、 第二层和第三层隐含层节点数为800, 700和500的SAE模型表现较佳, 比其他两种模型的预测结果提高11.7%和8.6%。 对于融合信息, SAE模型设置了三种结构(1347-800-400-200-40, 1347-750-550-400-100, 1347-700-500-360-150), 其中, 隐含层为750, 550和400的SAE提取的深层特征预测鲜桃SSC的精度最高, 比其他两种结构提取的深层特征预测精度分别提高15.5%和6.6%。
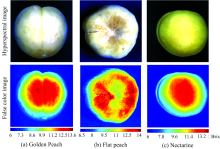
为了直观的表示鲜桃SSC, 选择成熟的黄金蜜桃、 蟠桃和油桃作为测试样本, 利用SAE- PSO-SVR模型预测其SSC含量, 可视化结果如图5所示。 从图5中可以看出, 第一行为鲜桃原始高光谱影像, 第二行为不同品种鲜桃SSC含量的伪彩色图。 由图例可以看出不同品种鲜桃样本含有不同的SSC。 其中, 黄金蜜桃样本的SSC含量范围为6.0~13.6° Brix, 蟠桃样本的SSC含量范围为6.5~14.2° Brix, 油桃样本的SSC含量范围为6.0~14° Brix。 由图5还可以直观看出, 黄金蜜桃和油桃的SSC分布于鲜桃赤道及桃核中心部分, 蟠桃的SSC主要分布于鲜桃核的四周区域。
 | 图5 不同品种鲜桃的可溶性固形物含量可视化Fig.5 Visualization of the soluble solid content of different varieties of fresh peaches |
可溶性固形物含量是衡量鲜桃品质和风味的关键因素。 提出了一种SAE-PSO-SVR模型估测鲜桃SSC。 将深度学习理论应用到鲜桃可溶性固形物含量估测中, 并将无监督训练的SAE特征提取与有监督训练的微调相结合。 主要结论如下:
(1) 通过对比不同隐含层神经元节点的SAE模型, 表明基于网络结构为1347-750-550-400-100模型估测效果最好。
(2) 通过对比输入不同信息的SAE模型估测效果, 表明基于融合信息的模型精度最高(校正集R2=0.873 3, 验证集R2=0.820 9)。
(3) 通过不同品种鲜桃样本的SSC可视化, 表明SAE-PSO-SVR模型具有较好的普适性。 基于SAE提取鲜桃高光谱影像的光谱信息和空间信息深层特征, 进一步通过融合信息的深层特征构建了基于SAE-PSO-SVR的鲜桃SSC估测模型, 有效的提高了模型的估测精度。 今后将利用不同深度学习方法验证及检测鲜桃的其他品质参数, 如酸度、 硬度及水分, 为鲜桃等水果的无损检测提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|