





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像的机采籽棉杂质分类检测
[常金强 , 张若宇
, 张若宇* , 庞宇杰, 张梦芸, 扎亚]
, 张若宇, 庞宇杰, 张梦芸, 扎亚]
|
|


作者简介: 常金强, 1992年生, 石河子大学机械电气工程学院硕士研究生 e-mail: changjinq@163.com
机采籽棉杂质分类检测为调整棉花清理机械加工参数和工序提供参考依据, 对提升皮棉品质具有重要意义。 但由于籽棉棉层分布不均匀, 使得图像检测难度增大, 使用传统的检测方法无法有效检测各类杂质。 采用高光谱成像方法对机采籽棉中的棉叶、 棉枝、 地膜和铃壳(内外)五种杂质进行分类判别检测。 首先采集120个机采籽棉样本的高光谱图像, 选取感兴趣区域获取平均光谱曲线。 发现由于物质构成的差异, 不同杂质体现出不同的吸收和反射特性, 不同种类物质之间的光谱差异大于同类物质。 对提取的平均光谱曲线进行主成分分析(PCA), 结果显示棉花、 残膜和铃壳外与其他三类相比, 有较好的聚集性和可分性, 但是棉叶、 铃壳内和棉枝三类相互叠加在一起, 空间分布存在严重交叉重叠。 以提取的平均光谱曲线为训练样本, 选择线性判别分析(LDA)、 支持向量机(SVM)和神经网络(ANN)三种分类判别算法, 对算法参数进行寻优, 并建立机采籽棉杂质分类判别模型。 其中, 经过LDA模型降维后的样本空间较PCA表现出了更好的聚集性和可分性, 采用正则化防止过拟合, 得到训练集准确率为86.4%, 测试集准确率为86.2%; SVM模型的参数寻优结果为 C=105, g=0.1, 其训练集准确率为83.42%, 测试集准确率为83.40%; ANN模型参数寻优得到隐含层数和神经元个数分别为2和17, 训练集准确率为82.9%, 测试集准确率为81.8%。 对三种模型的分类效果和检测用时进行比较, LDA模型结果最优。 通过对高光谱图像进行像素等级分类判别, 结果显示棉花识别效果较好, 植物性杂质都被有效检测, 但是地膜和棉花存在误识别, 分类效果与杂质光谱的分类判别模型结果一致。 因此, 采用高光谱成像技术可以快速、 无损的检测和识别籽棉杂质, 为棉花加工装备提供反馈参数, 对棉花加工机械化和智能化有重要意义。
The classification and detection of impurities in machine-harvested seed cotton provides a reference for adjusting cotton cleaning mechanical processing parameters and has important significance for improving lint quality. However, the uneven distribution of seed cotton makes image detection more difficult, and traditional detection methods cannot effectively detect various impurities. The hyperspectral imaging method was used to discriminate the five impurities (cotton leaf, cotton stem, plastic film, hull inner, and hull outer) in the machine-harvested seed cotton. The hyperspectral images of 120 machine-harvested seed cotton samples were collected, and the region of interest was selected to obtain the average spectral curve. Due to the difference in the composition of materials, various impurities showed different spectral absorption and reflection characteristics, and the spectral difference of the characteristics of different materials was greater than that of similar materials. Principal component analysis (PCA) of the extracted average spectral curve showed that cotton, plastic film and hull outer were better separable than the other three types. However, the spectral distributions of cotton leaf, hull inner, and cotton stem overlapped seriously. Based on the extracted average spectral curve as the training sample, three discrimination algorithms of linear discriminant analysis (LDA), support vector machine (SVM) and neural network (ANN) were used to optimize the algorithm parameters and finally established the impurity detection model. Among them, the sample space after dimensionality reduction of the LDA model shows better separability than PCA. Regularization was used to prevent overfitting in LDA, and the accuracy rate of the training set was 86.4%, and the accuracy of the test set was 86.2%. The parameter optimization result of the SVM model was C=105, g=0.1. The accuracy of the training set was 83.42%, and the accuracy of the test set was 83.40%. The parameter optimization result of the ANN model was that the number of hidden layers and neurons were 1 and 10, respectively. The accuracy rate of the training set was 82.9%, and the accuracy rate of the test set was 81.8%. Comparing the classification accuracy and detection time of the three models, the results of the LDA model were all the best. Through the pixel level discrimination of hyperspectral images, the results show that both cotton and botanical impurities were effectively detected. However, there were misidentifications between plastic film and cotton, which was consistent with the results of the impurity spectrum classification discrimination model. Therefore, hyperspectral imaging technology can detect and identify seed cotton impurities quickly and non-destructively and provide feedback parameters for cotton processing equipment, which is of great significance to the mechanization and intelligence of cotton processing.
近年来棉花全程机械化生产比例增加, 机采籽棉需要在后续加工过程中进行多道清理工艺, 但是清理机械会对棉花纤维造成损失, 降低加工所得皮棉的品质, 影响最终产品价格和经济效益。 因此对棉花杂质进行检测, 并将杂质进行分类判别, 为调整棉花清理机械加工参数和工序提供参考依据, 对提升皮棉品质具有重要实际生产价值和意义。
由于皮棉中异纤含量对价格影响较大, 国内的研究主要集中在异性纤维检测[1, 2]。 张志峰等[3]提出了一种基于改进的自适应迭代阈值法皮棉疵点快速检测方法; 张林等[4]采用LED与线激光的双光源一次成像方法, 可以检测出各种颜色的异性纤维; 张成梁等[5, 6]、 王昊鹏等[7]提取机采籽棉可见光图像中杂质的颜色、 形状和纹理特征, 对各类植物杂质进行分类检测; 倪超等[8]采用深度学习方法对短波近红外高光谱图像中的地膜进行检测。
国外的研究主要集中在植物性杂质的检测, Wang等[9]采用基于自动视觉检测系统的伪异性纤维检测方法, 提高了棉花中异性纤维的分类精度。 Fortier等[10]建立棉花中植物杂质的近红外光谱库, 进行杂质光谱分类识别。 Li等[11, 12, 13, 14, 15]基于高光谱成像技术, 采用反射、 透射和荧光等成像方式, 应用降维、 特征波段选择、 分类判别算法等分析方法, 对皮棉中多种植物和异纤杂质进行检测。
上述研究对象主要是皮棉, 由于皮棉经过杂质清理和轧花去籽处理, 杂质含量小, 棉层均匀易于图像中杂质的检测; 而机采籽棉中不仅含有较多杂质, 且棉籽导致棉层不均匀, 使得图像检测难度增大, 使用传统的检测方法无法有效检测各类杂质。
基于高光谱成像检测技术, 根据棉花和各类杂质的光谱特征, 针对机采籽棉中存在的植物和残膜杂质建立分类判别模型; 并充分利用光谱图像的空间信息, 实现对机采籽棉各类杂质的像素等级分类判别, 为棉花加工设备提供快速信息反馈。
共取样籽棉10 kg, 其中籽棉取自棉花加工企业, 地膜取自采收后的棉花地。 将籽棉和杂质手动混合均匀, 每个样本(30± 0.5) g, 使用电子天平称重(量程1 000 g, 分度值0.01 g), 共120个籽棉样本。 样本中检测的杂质有棉叶, 棉枝, 铃壳(内和外)和地膜共5种杂质, 如图1所示。
 | 图1 机采籽棉和主要杂质Fig.1 Machine-harvested seed cotton and main impurities |
高光谱图像采集系统如图2所示, 由成像光谱仪(Imspectral V10E-QE, Finland)、 CCD相机(C8484-05G, Hamamatsu Photonics, Japan)、 镜头、 光源(150 W卤素灯, China)、 电动位移平台(PSA200-11-X, Zolix)和电动位移平台控制器(CS300-1A, Zolix)、 暗箱、 PC计算机等组成; 在PC上用Spectral软件进行图像采集软件控制。 高光谱成像系统光谱范围为360~1 000 nm, 光谱分辨率为2.7 nm, 采集的图像有256个波段。
 | 图2 高光谱图像采集系统 1: CCD相机; 2: 光谱仪; 3: 调焦镜头; 4: 卤素灯; 5: 样品; 6: 位移台; 7: 控制器; 8: 计算机Fig.2 Hyperspectral imaging system 1: CCD camera; 2: Spectrograph; 3: Lens; 4: Halogen lamps ; 5: Sample; 6: Stage; 7: Controller; 8: Computer |
为保证视野足够, 调节镜头和样本的间距为25.5 cm; 为矫正速度不匹配带来的空间畸变, 使用一张打印有一个圆圈的A4纸调试平台的速度, 转速设定为940 pulses· s-1; 曝光时间为3.5 ms。
将样本置于内部大小为15 cm×20 cm×3 cm的样本盒中, 分布均匀, 将样本盒固定于移动平台上进行图像采集。 样本盒覆盖有黑色背景纸, 有利于后期掩膜去除背景以及后续处理。
为减少光源光强分布不均匀导致的图像信息噪声影响, 使用的高光谱成像系统在采集图像之前需要进行黑白校正。 扫描聚四氟乙烯白板获得白校正图像; 镜头拧上镜头盖并关闭光源采集黑校正图像, 该图像包含有相机暗电流噪声信息。 图像采集后用软件SpecView(V2.9.2.7)按式(1)进行校正
其中: I为原始图像, Ib为黑校正图像, Iw为白校正图像, Ia为获取校正后的图像。
使用PCA(principal component analysis, PCA)对平均光谱数据进行分析, 将成百个相互高度相关波段数据降维至少数个新的主成分变量上, 用来代替原来数据的大部分信息, 并通过绘制分布散点图体现原光谱数据的分类识别可行性。
采用LDA, SVM和ANN三种有监督的分类判别分析方法建立机采籽棉杂质多分类判别模型。 模型训练的过程为: 首先将提取的平均光谱数据按照7:3的比例, 随机划分为训练集和测试集; 然后根据不同模型的参数特点和数据特性, 使用训练集采用5折交叉验证, 确定最佳的模型参数, 并使用测试集对模型结果进行评估。
2.1.1 平均光谱曲线提取与变化规律
经过黑白校正后的图像, 在可见至近红外波段上, 共有256个波段。 意味着在空间域上每个像素具有256个特征, 这些特征组成该像素对应的光谱曲线。 因高光谱图像中存在噪声, 单一像素对应的光谱曲线可能在噪声的影响下, 表现出较大的变化。 因为光谱成像仪的特性, 高光谱图像在首尾的波段图像噪声较大, 有用信息较少, 所以将这些波段剔除, 即去除395 nm以前和970 nm以后的光谱图像波段, 将395~970 nm区间共226个光谱波段的数据作为后续分析数据。
从每幅图像中提取10条平均光谱曲线, 共1 200条光谱曲线, 其中棉叶、 残膜、 铃壳外、 铃壳内、 棉枝和棉花分别为457, 173, 88, 193, 63和226条。 绘制机采籽棉中具有代表性的棉花和各类杂质的平均光谱曲线, 如图3所示: 各类物质在430 nm处附近反射率均为最小, 吸收最强; 棉花的反射率较其他物质在大部分波段范围高; 残膜整体上和棉花变化趋势一致, 但是数值比棉花低, 验证了从图像上检测残膜的难度较大; 铃壳内的反射率在750 nm前低于棉花和残膜, 但是在750 nm后超过了棉花和残膜; 棉叶、 棉枝和铃壳外在趋势和数值上都比较相似, 但是棉叶在680 nm处出现了吸收峰, 此现象对应了叶绿素的吸收波段。 从630 nm开始到近红外波段范围内, 铃壳外的反射率比棉叶和棉枝都高。
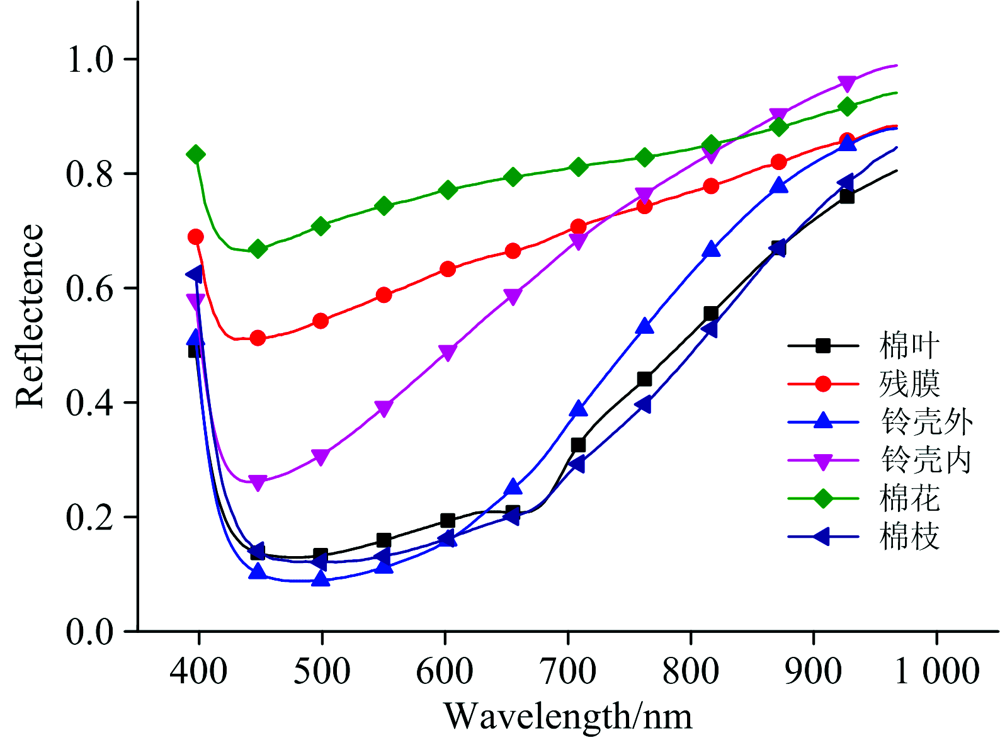 | 图3 机采棉和各类杂质平均光谱曲线Fig.3 Mean spectra of mechine-harvested cotton and impurities |
综上所述, 虽然棉花和各类杂质的光谱曲线趋势相同, 但还是体现出不同的吸收和反射特性。 不同种类物质(棉花、 化学纤维和植物)之间的差异大于同类物质之间的光谱差异, 同种物质之间的差异不能通过单个波段进行判别, 所以需要进行数据分析和建模。
2.1.2 机采籽棉光谱曲线PCA分析
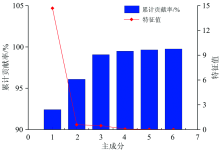
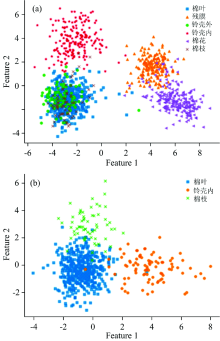
对提取的平均光谱曲线进行PCA变换, 如图4所示, 前2个主成分的累计贡献率达到了97.2%, 前6个主成分的累计贡献率达到了99.9%, 能够代表原始光谱数据的大部分信息。 PCA前两个主成分的散点图如图5所示, 6类物质光谱变换后的新变量分布于整个空间中。 由图可知, 棉花、 残膜和铃壳外与其他三类相比, 有较好的聚集性和可分性, 但是由于棉叶、 铃壳内和棉枝三类的物质组成(纤维素和木质素)相似性较高, 光谱特征相似, 导致相互叠加在一起, 空间分布存在严重交叉, 无法有效区分类别。 由于PCA为无监督降维方法, 无法有效利用分类信息, 因此需要使用有监督的数据建模方法, 对光谱分类数据进行学习拟合, 实现对杂质类别的准确识别。
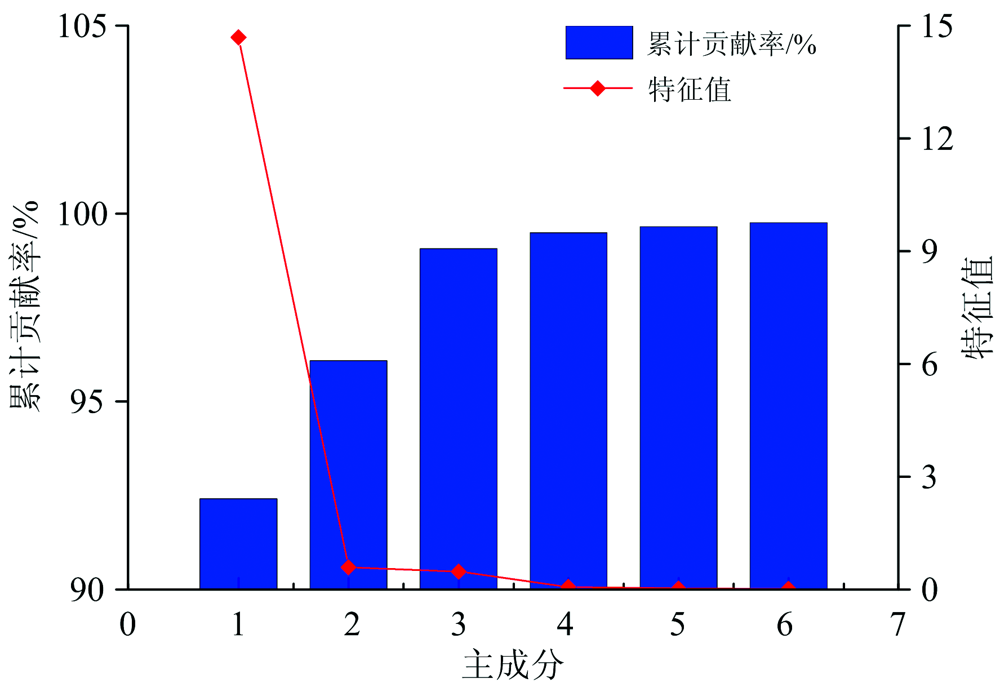 | 图4 前6个主成分的特征值和累计贡献率Fig.4 Eigenvalues and cumulative contribution rates of the first 6 principal components |
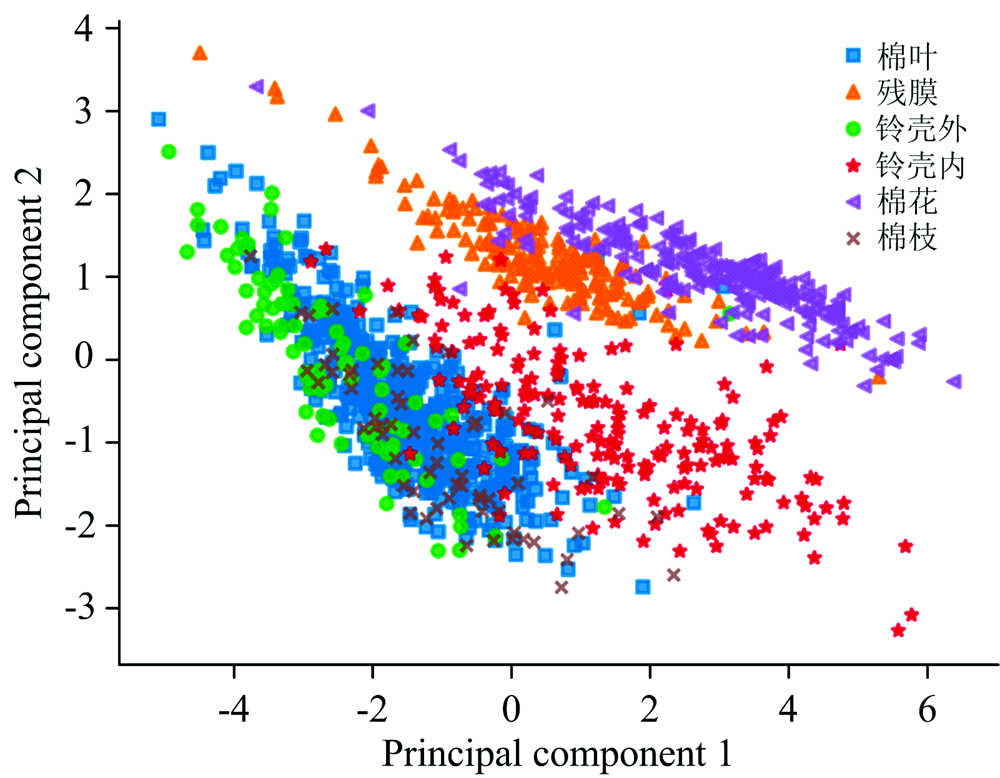 | 图5 前2个主成分分类散点图Fig.5 Scatter clusters of the first 2 principal components |
2.2.1 线性判别分析(LDA)模型
线性判别分析(linear discriminant analysis, LDA)是将原始数据投影到更低的维度上, 减少特征之间的线性相关性导致的特征冗余问题。 通过LDA进行降维, 可以达到提升分类准确率的目的。
与PCA中的分布相比, 图6(a)中棉花、 残膜和铃壳外有更好的聚集性和可分性, 表明有监督的LDA模型降维方法变换后的数据具有更好的可分性; 但是棉叶、 铃壳内和棉枝这三类还是相互叠加在一起, 空间分布存在严重交叉, 无法有效区分类别。 因此针对该三类重新进行了LDA降维, 见图6(b)中的棉叶、 铃壳内和棉枝表现出了较高的可分性, 验证了LDA模型在机采籽棉多分类上的可行性。
 | 图6 LDA前两个特征的类别散点图 (a): 全部6类物质; (b): 棉叶、 铃壳内和棉枝Fig.6 Scattering clusters of the first 2 variables of LDA (a): All 6 types of materials; (b): Leaf, bell shell inner, stem |
因LDA易出现过拟合, 因此在LDA模型构件中采用正则化防止过拟合, 建立分类模型, 得到训练集准确率为86.4%, 测试集准确率为86.2%, 其差值较小, 未出现过拟合现象。
2.2.2 支持向量机(SVM)模型
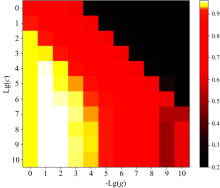
支持向量机(support vector machine, SVM)广泛应用于建立分类判别模型。 在SVM分类模型构建中采用RBF径向基函数构建了分类模型, 对gamma(g)和cost(C)两个参数进行寻优, 将Lg(g)和-Lg(c)参数区间设置为[0, 10]。 由图7可知, 在C=105、 gamma=0.1时, 交叉验证集的准确率最高达到95.19%。 根据最优参数模型得出训练集准确率为83.42%, 测试集准确率为83.40%, 两者差值较小, 未出现过拟合现象。
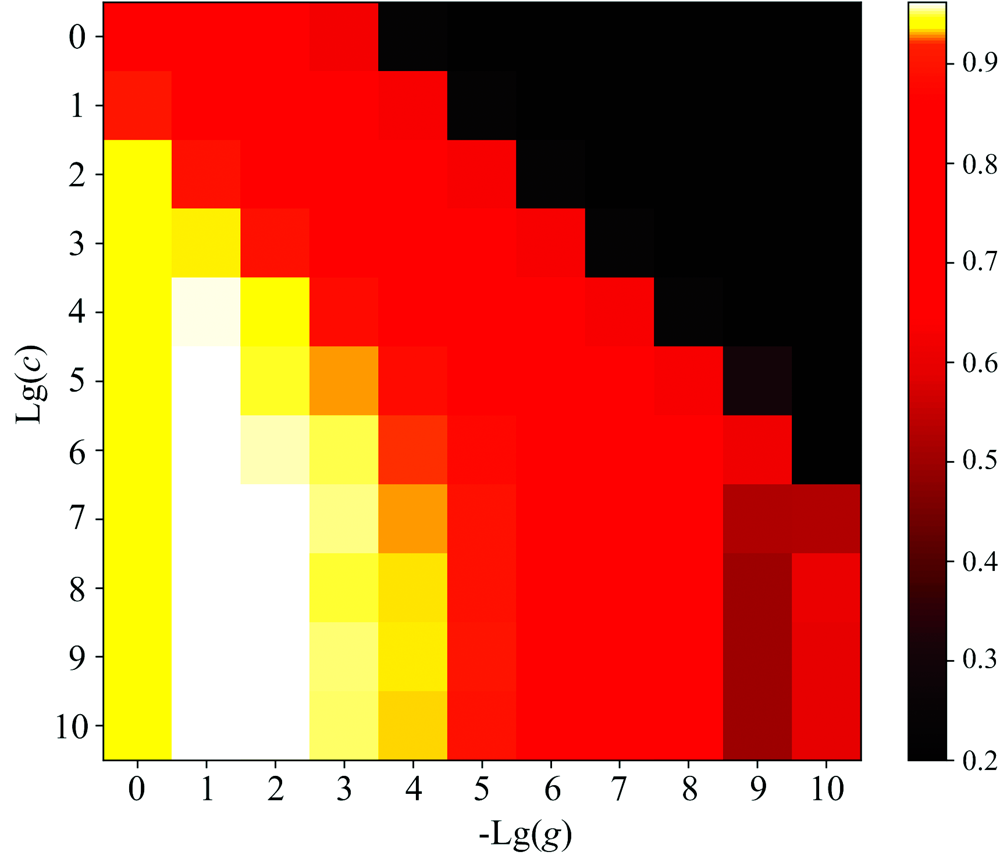 | 图7 SVM模型寻优结果Fig.7 Parameter optimization results of SVM model |
2.2.3 人工神经网络(ANN)模型
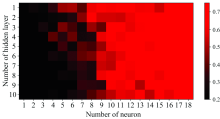
人工神经网络(artificial neural network, ANN)是一种影响强、 分类效果好的神经网络分类算法, 在解决非线性问题上具有较强能力。 在ANN分类模型构建中, 设置隐含层层数区间为[1, 10], 隐含层神经元个数区间为[1, 18], 激活函数选择Relu函数进行参数寻优。 由图8可知, 在隐含层层数为2, 隐含层神经元个数为17, 交叉验证集的准确率达到最高为73.92%。 以寻优所得到的参数, 建立ANN分类模型并输出, 训练集准确率为82.9%, 测试集准确率为81.8%, 没有发生过拟合。
 | 图8 ANN参数寻优结果Fig.8 Parameter optimization results of ANN model |
对上述的多分类模型准确率性能进行对比, 如表1所示, 结果显示LDA模型的准确率高于SVM模型和ANN模型, 训练集和预测集的准确率达到了86.4%和86.2%。 由于高光谱波段之间有较高的相关性, 分类模型无法有效筛选信息, 会引起误差的产生。 LDA在分类前对光谱特征进行了降维, 减少了特征之间的相关性, 保留了大部分类间信息, 因此在多分类问题中, 相较于SVM和ANN具有更好的效果。
| 表1 光谱曲线分类模型准确率和时间 Table 1 Accuracy and runtime of three classification models |
三个模型预测效果如图9所示。 在LDA模型中, 地膜、 铃壳(内和外)和棉花的准确率较高, 均高于90%; 棉叶和棉枝的准确率较低, 分别为59.84%和77.08%, 其中有26.77%的棉叶被识别为棉枝, 9.72%的棉枝被识别为棉叶, 9.72%的棉枝和8.66%的棉叶被识别为铃壳内; 与LDA模型相比较, SVM模型和ANN模型的铃壳内准确率有所降低, 误差类别分布一致但较高。 分析认为这些识别错误的原因主要是棉叶、 棉枝和铃壳内的物质成分相似度高, 导致在波段范围内表现出光谱曲线相似的特点。
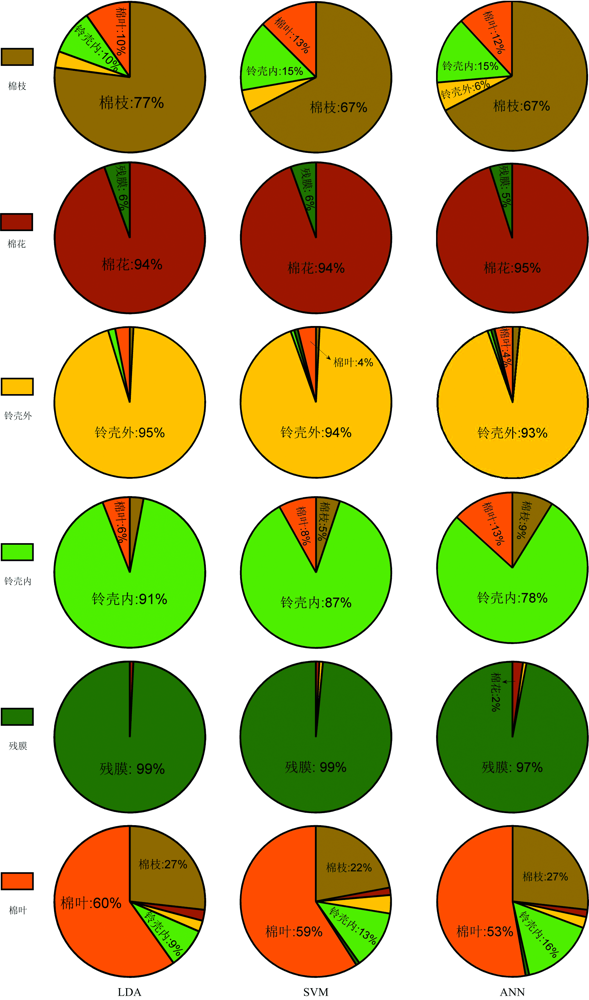 | 图9 分类模型预测集效果Fig.9 Pie chart of prediction |
根据三种算法对120个高光谱图像进行检测分类, 并将运行时间进行平均, 得到每个模型检测高光谱图像所需运行时间。 结果如表1所示, SVM, LDA和ANN的运行时间分别为73.65, 1.86和2.58 s, 综合比较, LDA的分类准确率较高且运行时间少, 确定LDA分类模型为最优模型。
使用训练的LDA模型对高光谱图像进行像素等级分类, 分类效果如图10所示。 可看出棉花识别效果较好; 部分棉叶和棉枝不能有效识别; 地膜虽然被检测出来, 但因地膜的光谱曲线在大部分波段上和棉花相似, 亮度较棉花低, 所以部分棉花中表面不平导致的亮度较低的区域被识别为地膜。 上述分类效果与杂质光谱的分类判别模型结果一致。
 | 图10 高光谱图像像素等级分类识别结果 (a): 原图像; (b): 分类判别结果Fig.10 Hyperspectral image classification results in pixel level (a): Original image; (b): Classification result |
(1) 通过参数优化, 建立了三种机采籽棉杂质分类判别模型。 其中LDA的分类准确率较高, 训练集和测试集的准确率分别为86.4%和86.2%。 由于棉叶和棉枝的物质成分相似, 光谱曲线相似, 导致棉叶和棉枝杂质的分类准确率较低。
(2) 对于像素等级杂质检测, 该方法能够识别大部分杂质, 检测效果明显。 LDA算法需要的时间约为1.86 s, 少于ANN的2.58 s, 且远少于SVM的73.65 s, 能够满足实际生产对于检测的需求, 因此LDA为最佳模型。
(3) 在后续研究中可以基于该方法, 增加样本数量, 选择覆盖范围更大的波段和加入纹理特征, 提升棉叶和棉枝的检测效果; 并根据光谱图像数据分析提取特征波段, 开发多光谱成像检测系统, 实现更高效率的机采籽棉杂质实时检测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|