


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外特征光谱的羊肉TVB-N浓度预测模型
[张旭1  , 白雪冰
, 白雪冰1 , 汪学沛2 , 李新武2 , 李志刚3 , 张小栓2, 4, * ]
, 白雪冰]
|
|


作者简介: 张 旭, 1991年生, 中国农业大学信息与电气工程学院博士研究生 e-mail: zhxu@cau.edu.cn
为提高生鲜羊肉储存期内(4, 8和20 ℃环境)挥发性盐基氮(TVB-N)的近红外光谱(NIR)检测的稳定性和准确性, 选取特征光谱和预测模型是关键步骤。 以121个羊肉样品为实验对象, 采集生鲜羊肉680~2 600 nm波段的近红外光谱。 以多元散射校正(MSC)、 标准正态变换(SNV)等散射校正方法, Savitzky-Golay卷积平滑(SGS)、 移动平均平滑(MAS)等平滑处理方法, 以及归一化(Normalization)、 中心化(Centering)、 标准化(Autoscaling)等尺度缩放方法分别预处理光谱数据后建立偏最小二乘法(PLS)预测模型。 比较发现SGS处理的光谱建模效果最好。 利用蒙特卡洛采样(MCS)法及马氏距离法(MD)消除了羊肉光谱的5个异常数据。 运用光谱-理化值共生距离(SPXY)算法划分总样本的75%(87个)为校正集样本, 剩余29个为验证集样本, 利用竞争性自适应重加权法(CARS)、 无信息变量消除法(UVE)、 改进的无信息变量消除法(IUVE)和连续投影算法(SPA)提取特征光谱得到的波长个数分别为14, 713, 144和15。 将全光谱和4种方法提取的特征波长作为输入变量建立预测模型, CARS提取的波长所建立模型的性能优于UVE、 IUVE和SPA提取的波长所建立模型的性能, 表明CARS方法可以有效简化输入变量并提高预测模型的性能。 改进后得到的IUVE法相比于UVE法, 筛选出的波长数更少且模型性能有所提升。 以提取的特征波长建立PLS, 支持向量机(SVM)和最小二乘支持向量机(LS-SVM)预测模型, SVM模型得到最优的校正集预测结果, 其中CARS-SVM预测模型的校正决定系数($R_{C}^{2}$)和校正均方根误差(RMSEC)分别为0.939 1和1.426 7, 最优的验证集预测效果为LS-SVM预测模型得到, 其中IUVE-LS-SVM预测模型的验证决定系数($R_{V}^{2}$)和验证均方根误差(RMSEV)分别为0.856 8和1.886 2。 基于近红外特征光谱建立简化、 优化的生鲜羊肉储存期TVB-N预测模型, 为实现快速无损检测生鲜羊肉中的TVB-N浓度提供技术支持。
In order to improve the stability and accuracy of near-infrared spectroscopy (NIR) detection of total volatile basic nitrogen (TVB-N) in fresh mutton during storage (at 4 ℃, 8 ℃, 20 ℃), the selection of characteristic spectra and prediction models is the key step of NIR spectroscopy research. The 121 mutton samples were taken as experimental objects, the NIR spectra between 680 and 2 600 nm of fresh mutton samples were collected. The scattering correction methods, including multi scattering correction (MSC), standard normal transformation (SNV), and smoothing methods including Savitzky Golay convolution smoothing (SGS), moving average smoothing (MAS), and scaling methods including normalization, centring and auto scaling, were adopted to pretreat NIR spectra, and then PLS prediction models were built, by comparison, it is found that the spectra treated with SGS got the best modeling effect. Monte Carlo sampling (MCS) method and Mahalanobis distance method (MD) were used to eliminate 5 abnormal data of mutton spectra. The sample-set partitioning based on joint x-y distance (SPXY) algorithm was used to split 75% (87 samples) of the total samples as calibration set samples and the remaining 29 were validation set samples. The competitive adaptive reweighted sampling (CARS) algorithm, uninformative variable elimination (UVE) algorithm, improved uninformative variable elimination (IUVE) algorithm, successive projections algorithm (SPA) were employed to select characteristic wavelengths, and wavelength numbers were 14, 703, 144 and 15, respectively. The full spectra and the characteristic wavelengths selected by the four methods were taken as input variables to build prediction models, the results show that the performance of the model built with the wavelengths selected by CARS is better than the model built with the wavelengths selected by UVE, IUVE and SPA, and it shows that CARS method can effectively simplify the input variables and improve the performance of the prediction model. Compared with the UVE algorithm, the IUVE algorithm can select fewer wavelengths and improve the model’s performance. The PLS models, support vector machine (SVM) models and least squares support vector machine (LS-SVM) models were established with the selected characteristic wavelengths. The optimal prediction results of the calibration set are obtained by SVM models, in which the calibration determination coefficient ($R_{C}^{2}$) and root mean square error of calibration (RMSEC) of the CARS-SVM prediction model were 0.939 1 and 1.426 7, respectively. LS-SVM prediction model achieves the optimal prediction results of validation set, and the validation determination coefficient ($R_{V}^{2}$) and the root mean square error of validation (RMSEV) of IUVE-LS-SVM prediction model were 0.856 8 and 1.886 2, respectively. The simplified and optimized TVB-N prediction models for fresh mutton during the storage period are established based on NIR characteristic spectra, which provides reference and technical support for rapid and non-destructive detection of TVB-N concentration in fresh mutton.
中国的羊肉产量及羊肉消费量均居世界首位。 保证储存期内羊肉的新鲜度和防范质量安全问题愈发紧要。 在羊肉的贮藏过程中, 在微生物和内外源酶的作用下, 羊肉中的脂肪和蛋白质分解产生有毒的氨(NH3)和胺类(R-NH2)[1], 并与腐败产生的有机酸结合生成挥发性盐基氮(total volatile basic nitrogen, TVB-N), 因此TVB-N浓度是评估羊肉质量安全的关键参数。
食品安全国家标准中规定的TVB-N浓度的检测方法包括自动凯氏定氮仪法、 半微量定氮法、 微量扩散法。 这些化学检测方法需要破坏样品, 操作过程复杂, 耗时费力, 且结果易受操作水平影响, 不能满足快速、 非破坏的质量安全检测要求。
近红外光谱(near infrared spectroscopy, NIR)检测技术具有分析快速、 操作简便、 无破坏性等特点, 在肉品质检测领域已有大量研究。 被应用于新鲜度分级[2]、 掺假识别[3]、 等级划分[4]、 鲜冻肉鉴别等定性分析, 以及化学组成(包括胆固醇[5]、 脂肪[6]、 水分[7])分析、 感官品质(包括肉色[8]、 系水力、 嫩度[8])评价等定量分析。
原始近红外光谱数据中虽然包含与特定成分相关的有效信息, 但也受到噪声及散射等因素的干扰, 这些干扰会降低光谱模型的预测性能。 因此, 应用适当的光谱预处理方法(散射校正、 平滑处理、 尺度缩放)和变量筛选方法可有效消除与被测指标无关的噪声、 散射等干扰, 提高光谱与被测指标间的相关性。 将竞争性自适应重加权法(competitive adaptive reweighted sampling, CARS)[9]、 无信息变量消除法(uninformative variable elimination, UVE)[9]和连续投影算法(successive projections algorithm, SPA)等方法应用于简化和优化近红外光谱预测模型已有报道。
在回归预测分析中, 偏最小二乘(partial least squares, PLS)是被广泛应用的线性回归方法, 当被测指标与光谱数据间存在非线性关系时, 采用线性的回归方法无法实现光谱信息的充分提取, 影响模型准确性。 为解决光谱数据的非线性问题, 非线性算法包括支持向量机(support vector machine, SVM)和偏最小二乘支持向量机(least squares-support vector machine, LS-SVM)已被用于近红外光谱预测模型的构建。 为此, 探讨近红外光谱的线性及非线性预测模型对稳定可靠的定量分析非常必要。
本研究以反映生鲜羊肉质量安全的TVB-N浓度为预测对象, 采集样品680~2 600 nm的近红外光谱数据, 经2种方法剔除离散程度大的异常样本后, 对比多种预处理方法对预测模型性能的影响, 以不同变量筛选方法优选特征波长, 探讨线性及非线性建模方法的预测性能, 建立优化的生鲜羊肉储存期TVB-N预测模型, 为实现快速无损检测生鲜羊肉中的TVB-N浓度提供参考和技术支持。
在江苏省东台市华东山羊市场购买当天屠宰的绵羊, 取背最长肌, 切除其脂肪和肌膜, 整形切成3 cm×3 cm×1 cm(长×宽×高)的块状150个, 置入无菌袋并以4 ℃冷链运输车在24 h内运抵中国农业大学工学院实验室, 将样品置于生化培养箱(LRH-250, 上海一恒仪器公司)中, 分组后在0, 4, 8和20 ℃温度下储藏。 低温试验时每隔24 h各取出3个样品进行测试, 20 ℃下每隔12 h取2块样本进行测试, 共测试11 d, 共获得121份样本。
采用SpectraStar 2600 XT-R型近红外光谱仪(美国Unity Scientific公司)采集羊肉样本光谱, 扫描次数为12次, 扫描范围为680~2 600 nm, 分辨率为1 nm。
根据GB 5009.228—2016《食品安全国家标准食品中挥发性盐基氮的测定》中的微量扩散法测定样品的TVB-N浓度。
通过MATLAB R2018b软件(美国Mathworks公司)完成数据处理和模型构建。
1.4.1 异常值剔除方法
利用蒙特卡洛采样(Monte-Carlo sampling, MCS)法消除异常样本。 异常剔除阈值设置为式(1)和式(2)所示, 超过阈值之一的即为异常样本。
其中, Mthreshold为各样本预测误差均值的阈值, μM和σ M为各样本预测误差均值的均值和标准差; Sthreshold为各样本预测误差标准差的阈值, μS和σ S为各样本预测误差标准差的均值和标准差。
同时利用马氏距离法(Mahalanobis distance, MD)剔除MD过大的样本, 阈值设置为
式(3)中, MDthreshold为各样本MD的阈值, μ和δ 为各样本MD的均值和标准差。
1.4.2 样本集划分方法
剔除异常样本之后, 运用光谱-理化值共生距离(sample set partitioning based on joint x-y distance, SPXY)算法划分出75%的样本为校正集, 其余为验证集样本。
1.4.3 光谱预处理方法
根据处理效果预处理方法可分为散射校正、 平滑处理、 尺度缩放等。 散射校正包括多元散射校正(multiple scattering correction, MSC)和标准正态变换(standard normal variate, SNV), 用于消除样品颗粒尺寸差异和分布差异对漫反射光的影响。 平滑处理可有效提高信噪比, 常用的有Savitzky-Golay卷积平滑(S-G smoothing, SGS)、 移动平均平滑(moving average smoothing, MAS)等方法。 尺度缩放包括归一化(Normalization)、 中心化(Centering)、 标准化(Autoscaling)等, 用来消除数据尺度差异的影响。 分别采用这7种方法对样本进行光谱预处理, 以找到最佳预处理方法。
1.4.4 特征波长筛选方法
所采集羊肉光谱共1 921个波长, 存在冗余和多重共线性信息, 筛选特征波长取代全光谱可提高模型简洁性和计算效率。
CARS选择波数的方法是基于回归系数的权重, 权重值越大则代表该变量对模型建立的贡献越大, 被选取的概率越大。
UVE以输入变量及等量的随机噪声建立PLS模型得到回归系数矩阵, 计算各变量的稳定性并筛选稳定性大的变量, 阈值设为随机变量稳定性最大绝对值的0.99倍。 UVE选出的波长呈局部连续分布, 波段之间仍存在严重的多重共线性问题, 岭回归(ridge regression, RR)法是解决此类问题的有效方法, 但是鲜有研究将岭回归用于光谱检测中的特征波长筛选, 由此在UVE法的基础上引入岭回归法得到改进的无信息变量消除(improved uninformative variable elimination, IUVE)法, 以进一步简化模型和提高预测精度。
SPA以正交投影分析全部波长变量, 并保留对TVB-N敏感的特征变量, 使变量之间共线性达到最小, 降低模型输入量。
1.4.5 预测建模方法
PLS在主成分分析的基础上, 对光谱和理化值同时进行分解, 保留对光谱贡献大的主成分, 进而构建误差最小化的最佳线性回归模型。
SVM模型利用核函数将低维输入映射到高维特征空间, 并在高维特征空间进行线性回归, 适于处理小样本、 非线性以及高维数等问题。 LS-SVM是SVM的改进方法, 进一步降低计算复杂性和提高计算速度。 设定径向基函数(radial basis function, RBF)为SVM模型及LS-SVM模型的核函数, 以具备交互验证的网格搜索(grid-search)法对SVM模型的关键参数(C, γ ), 以及LS-SVM模型的关键参数(γ , σ 2)进行寻优。
选择校正决定系数
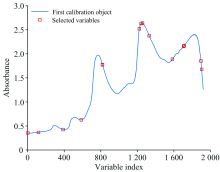
图1为121个羊肉样本的原始近红外漫反射吸光度光谱。 由于水分子中O—H键伸缩振动的二级倍频和一级倍频吸收, 在980, 1 440和1 940 nm附近呈现出吸收峰, 在1 200和2 400 nm附近则是与C—H键拉伸和伸缩振动相关的波峰[8]。 样本的光谱曲线趋势相似, 但不同波段的上升和下降的趋势不同, 说明其内部化学成分存在差异。
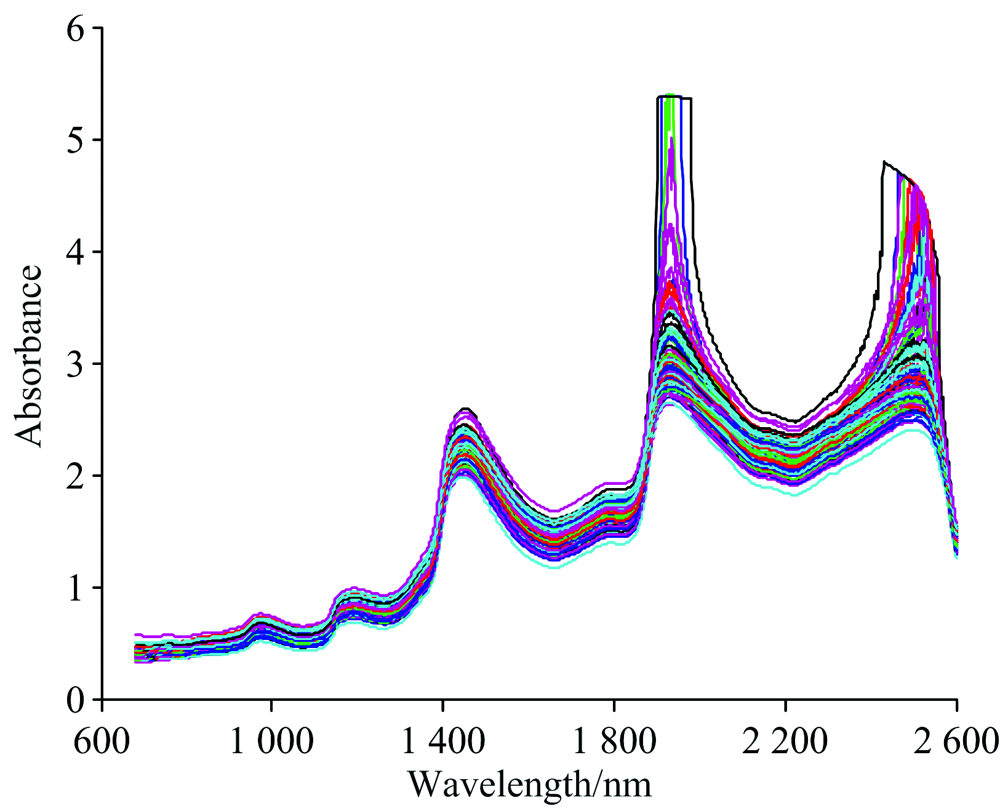 | 图1 羊肉样本近红外光谱图Fig.1 The NIR spectra of mutton samples |
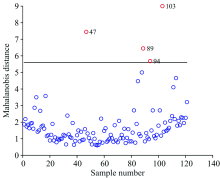
采用MCS法识别异常样本, 主成分个数设置为11, 预处理方法为Centering, 抽样次数1000次。 异常样本检测结果见图2, 得到阈值Mthreshold为6.4, Sthreshold为2.198, 第47, 89, 94, 103和121个样本被判定为异常样本。
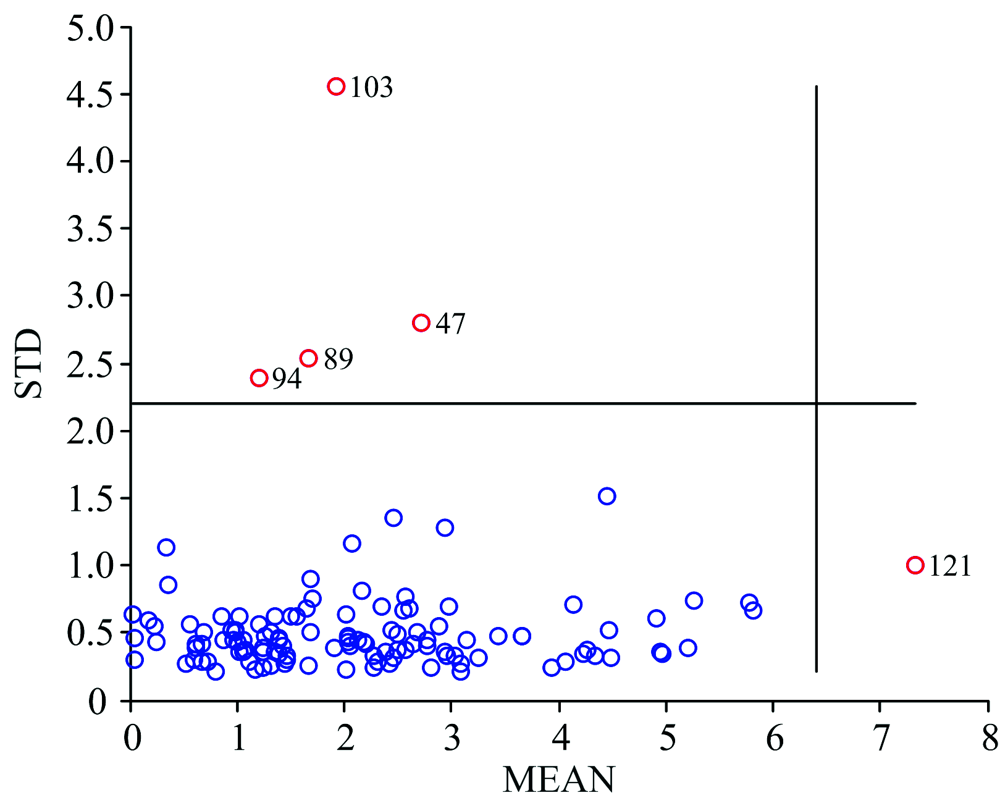 | 图2 蒙特卡洛采样法异常值检测结果Fig.2 The outlier results detected by Monte Carlo sampling method |
图3是121个光谱样本到平均光谱的MD分布图, 由MD的均值和标准偏差得到阈值为5.596, 超出此阈值的异常样本为47号, 89号, 94号, 103号, 与MCS法的检测结果重合度较高。
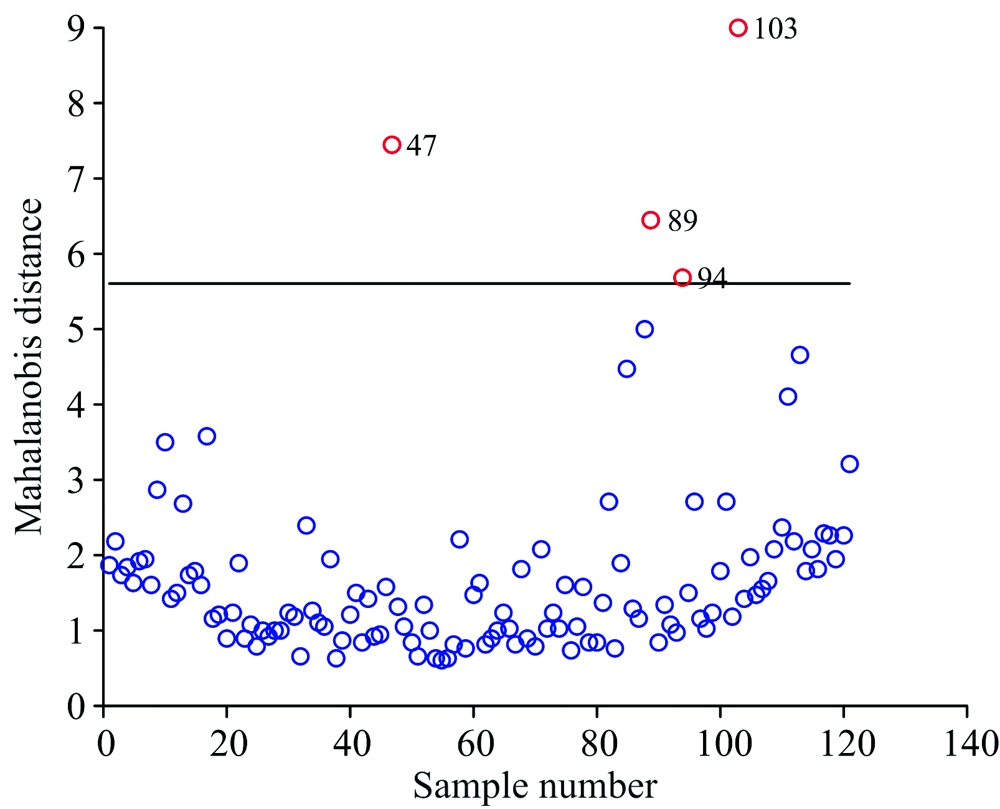 | 图3 羊肉样本的马氏距离分布Fig.3 Distribution of Mahalanobis distance of mutton samples |
将剔除异常值后的116个样本, 采用SPXY算法划分校正集和验证集样本。 羊肉TVB-N浓度的统计分析结果如表1所示。
| 表1 羊肉样品TVB-N浓度的统计结果 Table 1 Statistical results of TVB-N concentration of mutton samples |
分别使用原始光谱及经过7种方法预处理的光谱建立全波段的PLS预测模型, 建模结果见表2。 与原始光谱所建立的PLS模型相比, 由SNV, MSC, Autoscaling处理的光谱数据建立的模型性能均下降, 经Normalization, Centering, MAS处理的光谱数据所建立模型的性能没有明显改善, 而以SGS预处理的数据建模效果最好, 确定SGS为最优预处理方法。
| 表2 不同预处理方式的PLS预测模型比较 Table 2 Comparison of PLS prediction models with different pretreatment methods |
2.3.1 应用CARS筛选特征波长
采用CARS提取特征波长, 设置蒙特卡洛采样次数为50, 采用7折交叉验证计算。 随着采样次数增加, 图4(a)曲线呈指数衰减, 在运行次数1~5次, 变量选择个数曲线快速下降, 对应粗选过程, 之后进入缓慢递减的细选过程。 图4(b)为交互验证均方根误差的变化趋势图, 在运行次数1~36, 交互验证均方根误差缓慢波动降低, 随后逐渐升高。 从图4(c)回归系数曲线中的“ * ” 标出了交互验证误差的最低点, 在采样次数为36次时, 达到最小值2.206。 此时变量筛选个数为14个, 分别为720, 725, 823, 834, 925, 1 162, 1 230, 1 278, 1 441, 1 473, 1 867, 1 981, 2 484和2 554 nm。
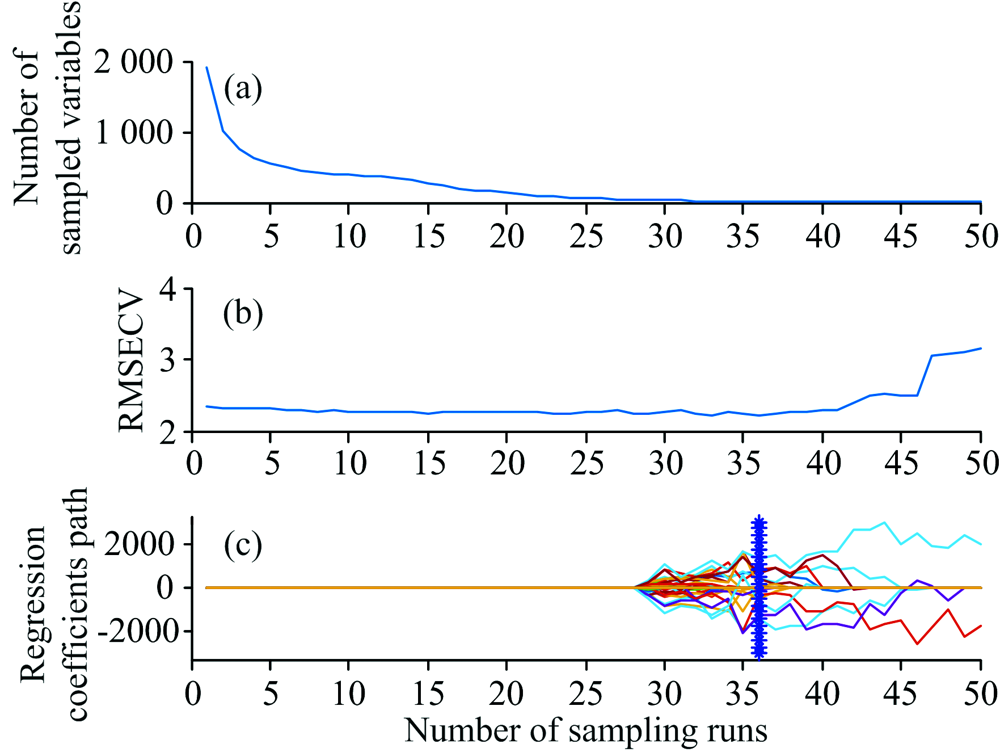 | 图4 基于CARS的变量选择过程Fig.4 Characteristic wavelength selection process using CARS |
2.3.2 应用IUVE筛选特征波长
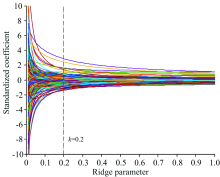
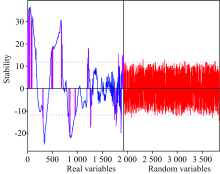
运行IUVE算法计算1 921个光谱波长和等量随机噪声的稳定性, 阈值设为± 11.76, 将超过阈值的输入变量进行岭回归分析, 以岭迹法确定岭回归参数k值为0.2, 变量筛选的原则参考文献[10]。 岭回归分析的结果如图5所示, 可以看出各回归系数的岭估计在k=0.2时基本稳定, 根据回归系数随k值的变化趋势结合误差选择变量。 IUVE与未改进的UVE的波长选择结果如图6所示, 蓝色的曲线为未改进的UVE法计算出的各变量稳定性曲线, 超过阈值的波长达到703个, 占总波长的36.60%, 洋红色竖线为结合岭回归分析的IUVE法最终选择出的144个有效变量, 占总波长的比值降至7.50%, 因此改进后的UVE可有效地消除各波长变量间的共线性。
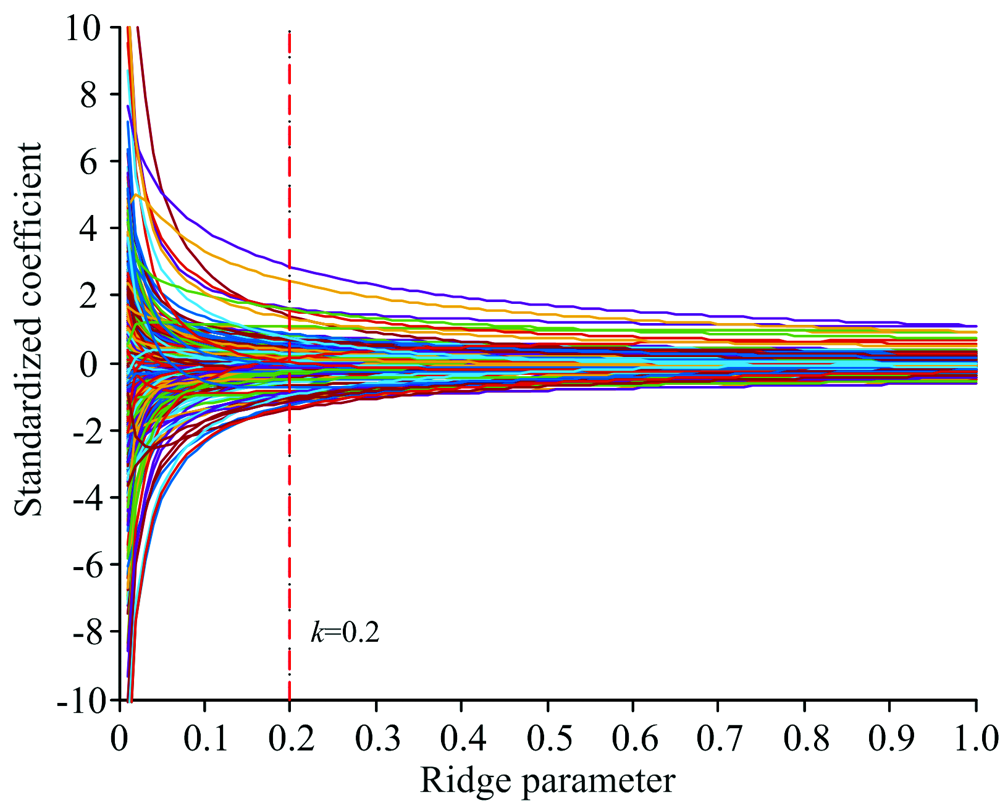 | 图5 岭回归分析岭迹图Fig.5 Ridge trace of ridge regression analysis |
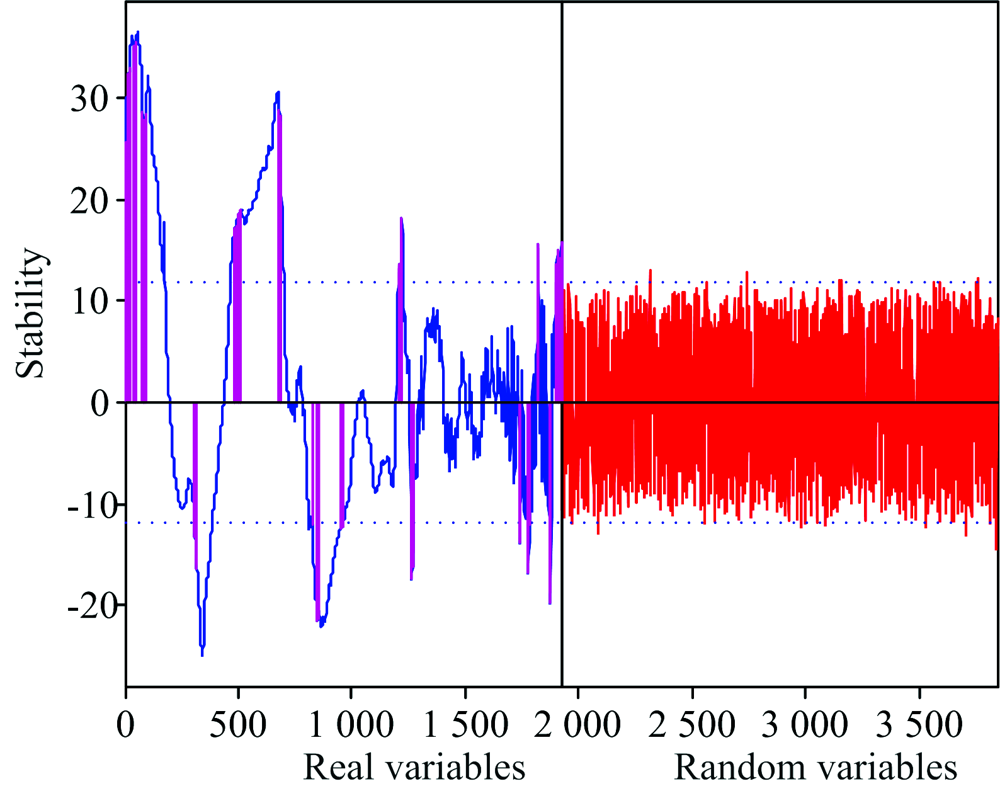 | 图6 基于IUVE的特征波长筛选Fig.6 Characteristic wavelength selection using IUVE |
2.3.3 应用SPA筛选特征波长
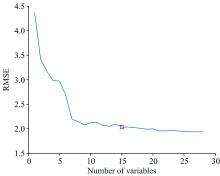
在变量个数1~28的范围内优选波长, SPA算法以RMSE的大小为依据确定特征波长数量。 随着特征波长数量的增加, RMSE的变化过程如图7所示。 当波长数量由1增加到7时, RMSE迅速下降, 表明此类波长变量为与羊肉TVB-N相关的重要波长变量。 当波长数量由7个增加到15个时RMSE呈波动式下降, 此类波长为有用信息变量。 随着波长数量由15个继续增加, RMSE继续缓慢下降。 因此以15个特征波长作为输入的特征变量。 图8为15个特征波长在全光谱中的位置分布, 分别为680, 798, 1 067, 1 266, 1 497, 1 498, 1 901, 1 920, 1 936, 2 009, 2 263, 2 386, 2 391, 2 575和2 583 nm。
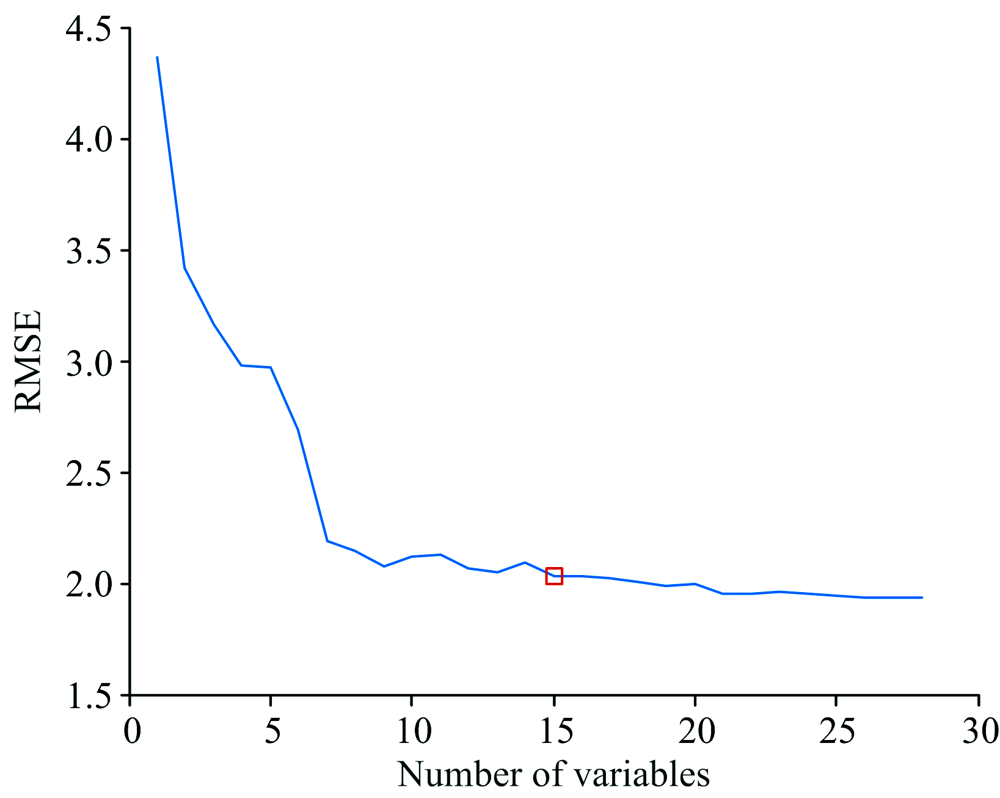 | 图7 基于SPA的波长个数选择Fig.7 Wavelength selection based on SPA |
 | 图8 基于SPA的特征波长选择Fig.8 Characteristic wavelength selection based on SPA |
2.4.1 PLSR模型
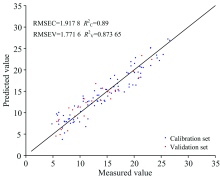
根据CARS, UVE及SPA的变量选择结果, 应用PLS方法分别建立羊肉TVB-N预测模型, 表3为各模型预测结果。 由表3可知, CARS-PLS模型的性能优于全光谱PLS模型, 校正集
| 表3 不同波长提取方法的PLS预测模型比较 Table 3 Comparison of PLS models with different wavelength selection methods |
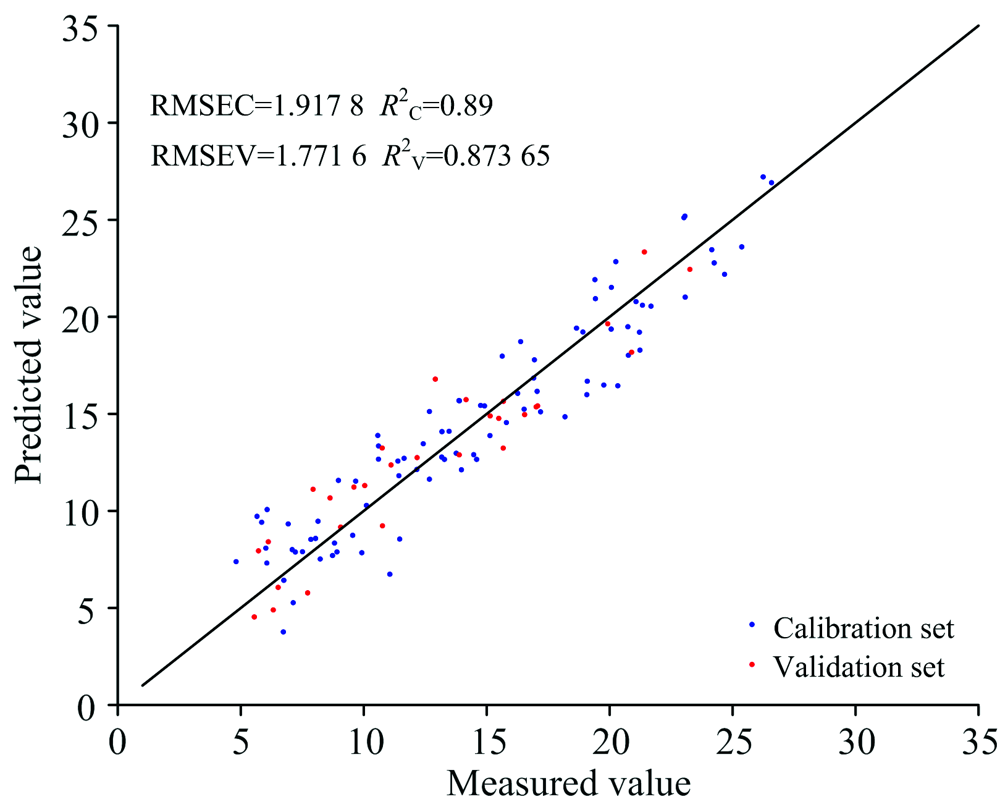 | 图9 CARS-PLS模型对羊肉TVB-N浓度的预测结果Fig.9 Prediction results of TVB-N concentration in mutton by CARS-PLS model |
2.4.2 SVM模型
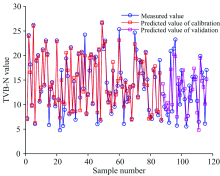
以全光谱和3种不同波长筛选方法获得的特征波长建立SVM预测模型, 建模预测结果见表4。 对比分析表4, 由CARS筛选的14个变量输入SVM模型取得了最好的校正集预测结果,
| 表4 不同波长提取方法的SVM预测模型比较 Table 4 Comparison of SVM models with different wavelength selection methods |
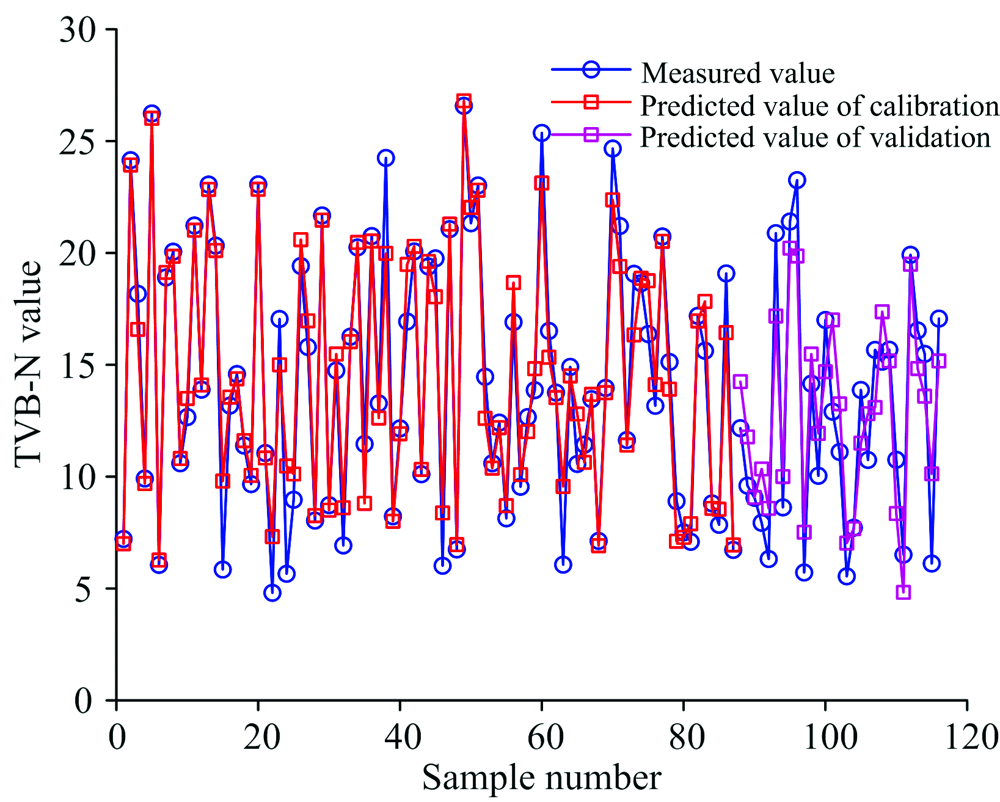 | 图10 CARS-SVM模型对羊肉TVB-N浓度的预测结果Fig.10 Prediction results of TVB-N concentration in mutton by CARS-SVM model |
2.4.3 LS-SVM模型
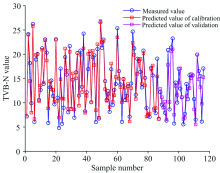
利用变量筛选得到的特征波长建立LS-SVM非线性预测模型, 预测结果如表5所示。 分析表5可知, CARS-LS-SVM模型的
| 表5 不同波长提取方法的LS-SVM预测模型比较 Table 5 Comparison of LS-SVM models with different wavelength selection methods |
 | 图11 CARS-LS-SVM模型对羊肉TVB-N浓度的预测结果Fig.11 Prediction results of TVB-N concentration in mutton by CARS-LS-SVM model |
利用近红外光谱对羊肉TVB-N浓度进行预测, 主要结论如下:
(1)以MCS法和MD法剔除了羊肉的光谱数据的5个异常值, 且2种方法的检测结果重合度和可信度较高。
(2)以原始光谱和6种不同方法预处理的光谱建立了PLS预测模型, SGS处理的光谱建模效果最好, 平滑处理、 尺度缩放方法的建模效果整体上好于散射校正方法。
(3)利用CARS, UVE, IUVE, SPA提取特征光谱得到的波长个数分别为14, 703, 144, 15, 占全光谱1921个波长的0.73%, 36.60%, 7.50%, 0.78%。 对比全光谱和各方法提取的特征波长所建立的预测模型, CARS提取的波长建立的模型性能最优。 对比UVE法, IUVE可消除波长间的共线性和提高模型性能。
(4)对提取的特征波长建立了储存期生鲜羊肉TVB-N的PLS, SVM和LS-SVM预测模型, 最好的校正集预测结果由SVM模型取得, 最好的验证集预测效果由LS-SVM模型得到, 这两种方法的建模效果与模型参数和建模样本密切相关。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|