
{kind=link}
{kind=link}
{kind=link}
多光谱数据融合和GANs算法的COD浓度预测
[陈颖1  , 许扬眉
, 许扬眉1 , 邸远见1 , 崔行宁1 , 张杰1 , 周鑫德1 , 肖春艳2 , 李少华3 ]
, 许扬眉|
|


作者简介: 陈 颖, 女, 1980年生, 燕山大学电气工程学院教授 e-mail: chenying@ysu.edu.cn
水体中过高浓度的有机污染物含量危害巨大, 不仅会造成严重的环境污染, 而且会危害人类身体健康。 化学需氧量(COD)表征了水体中有机污染物的污染程度。 提出了一种将紫外(UV)光谱和近红外(NIR)光谱进行多光谱数据级融合(LLDF)和特征级融合(MLDF), 进而构建基于生成对抗式网络(GANs)算法的COD浓度定量预测模型。 首先按照一定的浓度梯度配制COD标准液样本, 分别采集标准液的UV光谱(190~310 nm)和NIR光谱(830~2 100 nm), 对获取到的UV和NIR光谱数据进行一阶导数和Savitzky-Golay (S-G)平滑的预处理, 消除基线漂移和干扰噪声; 基于预处理过的光谱, 直接进行数据级和特征级的数据融合, 结合GANs算法搭建COD浓度预测模型。 并使用评价参数相关系数的平方( R2)、 预测值与真实浓度值的均方根误差(RMSEP)和预测偏差来对模型进行评价。 结果表明, 不论是特征级融合模型还是数据级融合模型都不够理想。 分析原因可知, 由于UV和NIR波段数据量不均衡, 导致NIR波段掩盖掉了UV光谱的模型贡献度, 让光谱融合失去意义。 为了避免融合失败, 拟采用归一化的方法处理多光谱数据, 并讨论了标准归一化(SNV)、 最大最小归一化(MMN)和矢量归一化(VN)对建模的影响。 将经过归一化后的UV和NIR光谱数据再次进行融合, 分别作为GANs模型的输入 X, 将真实测量COD值作为输出值 Y, 建立不同归一化方法处理后的COD浓度预测模型。 建模结果显示, 采用不同归一化方法对多光谱数据融合模型的影响较大, 不论是数据级融合模型还是特征级融合模型的预测精度较未归一化之前有明显的提升, 其中采用最大最小归一化的预测模型效果提升最为明显。 与单一谱源的全波长UV波段的GANs预测模型、 全波长NIR波段的GANs预测模型进行对比来验证多光谱数据融合GANs预测模型的精度, 结果表明: 基于UV和NIR光谱的特征级光谱融合模型的 R2为0.994 7, RMSEP为0.976, 比数据级融合的预测模型误差降低了52.9%, 预测回收率为98.4%~103.1%, 远好于其他几组, 模型的泛化能力更强, 预测精度也更高。 与单一谱源的预测模型相比, 多光谱数据融合能反应更多的水体样品的化学信息, 更加全面揭示水体的污染物程度, 从不同的层面上反应水体中污染物的差异, 为在线监测水体中COD浓度提供一定的技术支持。
, XU Yang-meiExcessive concentration of organic pollutants in water is harmful, which causes not only serious environmental pollution but also endangers human health. Chemical oxygen demand (COD) can be used to characterize the pollution degree of organic pollutants in water. A quantitative prediction model of COD concentration based on generative adversarial networks (GANs) algorithm is proposed, which combines ultraviolet (UV) and Near Infrared (NIR) spectra with data-level fusion (DLDF) and feature level data fusion (FLDF). In this paper, firstly, COD standard samples are prepared according to a certain concentration gradient, and the ultraviolet spectrum (190~310 nm) and near-infrared spectrum (830~2 100 nm) of the standard sample are collected respectively. The first derivative and Savitzky-Golay (S-G) smoothing pretreatment of the obtained ultraviolet and near-infrared spectrum data are carried out to eliminate the baseline drift of the spectrum and the interference noise. Then, the data fusion of data level and featural level are carried out directly basing on the pretreated ultraviolet and near-infrared spectra, and the COD concentration prediction model is constructed by GANs algorithm. The model is evaluated by using the square of the correlation coefficient of the evaluation parameters ( R2), the mean square root error of the predicted value and the real concentration value (RMSEP) and the prediction deviation. The results show that neither FLDF model nor DLDF model is not ideal. The analysis shows that the model contribution of the ultraviolet spectrum is concealed in the near-infrared band due to the unbalanced data in the ultraviolet and near-infrared bands, which makes the spectral fusion meaningless. In order to avoid the problem of fusion failure, the normalizat-ion method is proposed to deal with the mixed spectrum in the text. The effects of standard normal variation (SNV), maximum and minimum normalization (MMN) and vector normalization (VN) on the modeling are discussed. Then the normalized ultraviolet and near-infrared spectral data are fused again under the given sub-interval number, the input X of GAN model is taken as the input X, and the real measured COD value is taken as the output Y. The prediction models of COD concentration are established after different normalization methods. The modeling results show that different normalization methods have a great influence on the hybrid spectral data fusion model, and the prediction accuracy of the data-level fusion model and the feature-level fusion model is significantly improved before it is normalized, among which the prediction model with the maximum and minimum normalization is the most obvious. Finally, in order to verify the accuracy of the multi-spectral data fusion GANs Prediction model, the GANs prediction model of the full wavelength ultraviolet band of a single spectral source and the GANs prediction model of the full wavelength near-infrared band of a single spectral source are established. The experimental results show that the correlation coefficient of the characteristic level spectral fusion model basing on the ultraviolet and near-infrared spectra is 0.994 7, the prediction mean square root error is 0.976, the prediction model error is reduced by 52.9% comparing with the data level fusion, and the predicted recovery rate is 98.4%~103.1%, which is much better than the other groups. The generalization ability of the model is strong and the prediction accuracy is high. Compared with the monitoring model of single spectral source, the data fusion of mixed spectra can reflect more the chemical information of water samples, and reveals the pollutant degree of a water body more comprehensively, reflects the difference of pollutants in a water body from different levels, provides some technical support for on-line monitoring of COD concentration in water.
大量的有机污染物排入到水体中, 导致河流、 湖泊和海洋都受到了不同程度的污染[1]。 化学需氧量(chemical oxygen demand, COD)指在一定环境下, 水体中的还原性物质被氧化分解时所消耗氧化剂的量, 单位以耗氧量mg· L-1表示, 化学需氧量表征水体受到有机物污染的程度[2], 因此, 化学需氧量可作为有机污染物监测的综合指标。
近年来, 各国学者进行了大量研究以致力于寻找快速、 环保的COD检测方法, 紫外光谱(ultraviolet, UV)与近红外光谱(near infrared, NIR)技术具有无损、 快速、 样品制备简单及可实现在线分析等特点, 因此广泛应用于水体的污染物监测。 在国外, Lepot等[3]将UV光谱与遗传算法引入COD建模, 效果良好; Abedinzadeh等[4]利用NIR光谱对造纸厂废水的COD进行了在线监测, 所得的预测误差大约为被测水样COD浓度的1/10; Martelo-Vidal等[5]采用UV光谱联合NIR光谱, 搭建了人工神经网络预测模型, 取得了不错的预测精度。 在国内, 赵友全等[6]利用主成分分析结合欧式距离分析UV光谱, 并基于偏最小二乘法建模, 实现了水样的分类预测; 仲洋等[7]基于UV和NIR光谱进行多光谱融合对水质COD进行检测, 证明了多光谱融合建模可有效提高COD的预测精度。
本文提出了一种基于UV光谱和NIR光谱的多光谱信息融合COD浓度预测模型, 通过一阶导数和S-G平滑对原始UV和NIR光谱预处理; 为了避免光谱融合过程中数据量不一致导致的融合失败, 提出并分析了标准归一化(standard normal variation, SNV)、 最大最小归一化(max-min-nor, MMN)和矢量归一化(vector normalization, VN)处理光谱的效果, 筛选出最合适的归一化方法; 采用数据级数据融合(data level fusion, LLDF)和特征级数据融合(feature level fusion, MLDF)[6]对归一化后的光谱进行融合; 基于生成对抗式网络(generative adversarial networks, GANs)算法建立最终的多光谱COD浓度预测模型。
生成对抗式网络是机器学习的模型, 它包含两个学习网络: G(Generator)网络和D(Discriminator)网络。 其中G网络是一个生成模型的学习网络, 它接受样本集的数据进行训练, 并生成一个预测模型, 记作G(z); D是一个判别网络, 判别预测模型的结果是不是“ 准确的” 。 它的输入参数是x, x代表准确值, 输出D(x)代表x为准确值的概率, 如果为1, 就代表预测准确性为100%, 依次类推[8]。
其中, x为真实值, z为输入的训练样本, 而G(z)表示G网络生成的预测模型; D(G(z))是D网络判断G生成的预测模型是否准确的概率, G应该希望自己生成的模型 “ 越接近准确值越好” 。 G取D(G(z))最大值, V(D, G)变小, 在式(1)标记为min_G。 同理, D的能力越强, D(x)越大, D(G(x))越小。 V(D, G)会变大, 此时标记为max_D。
实验室中, 用U251UV分光光计和NIR光谱测试装置(由激光器、 待测样品装置、 光谱仪、 电脑以及相应的连接光纤组成)完成UV光谱和NIR光谱检测, 德国Brand(1.5 mL)数字可调精密移液器、 50 mL比色管, 邻苯二甲酸氢钾标准液, 配制1 000 mg· L-1的邻苯标准液, 用蒸馏水定容至标线, 摇匀, 分别稀释成1~500 mg· L-1浓度备用。
采用透射光谱法, 将石英比色皿作为样品池, 空气作参比, 采集COD标准液的UV和NIR吸收光谱, 如图1所示, UV波段采集范围为190~310 nm, NIR波段范围为830~2 100 nm (12 500~830 cm-1), 分辨率为1 nm, 积分时间为3 ms, 每个样本重复测量10次, 结果取平均值。
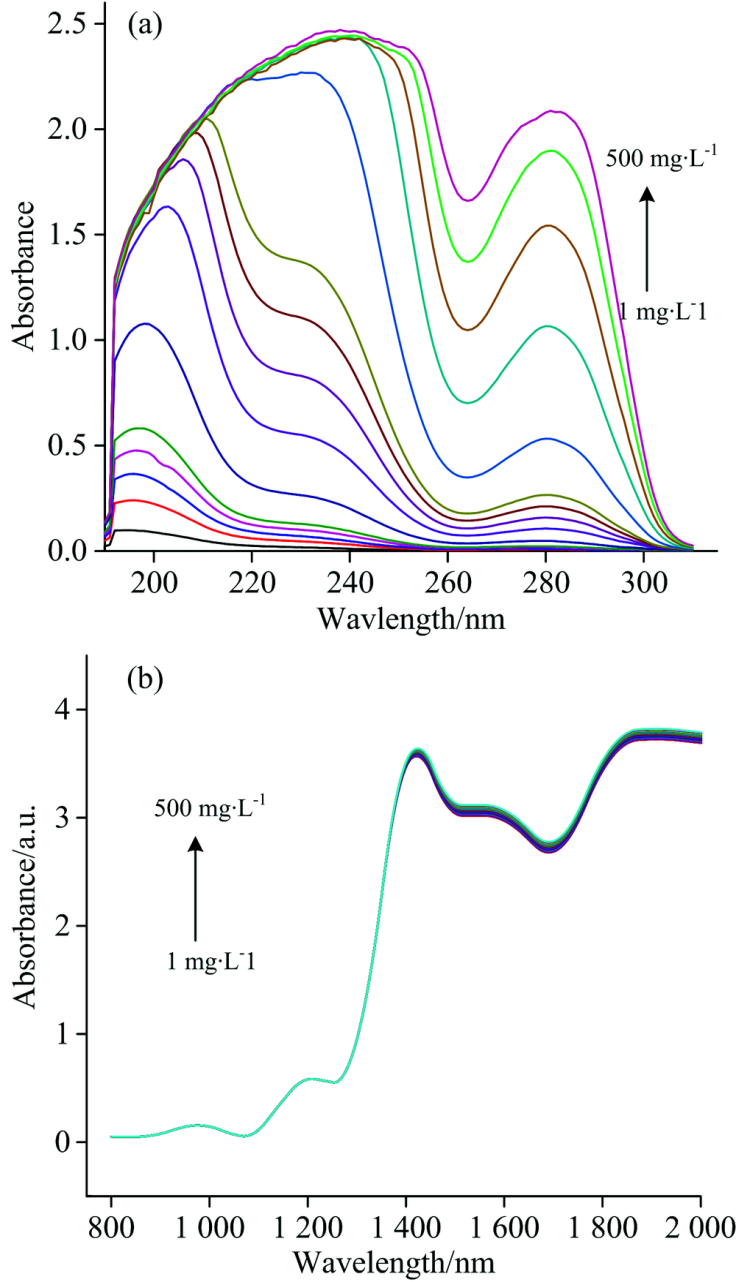 | 图1 COD水样光谱 (a): UV光谱; (b): NIR光谱Fig.1 COD water sample spectra (a): UV spectrum; (b): NIR spectrum |
由图1可知, 不同浓度的COD标准液的吸收谱在UV波段具有两个典型特征吸收峰。 从官能团的角度来分析, 第一个峰是羟基和羧基共同作用形成, 且随着邻苯标液浓度的升高, 该官能团吸收带出现明显红移, 并最终吸收趋于饱和; 第二个峰是苯环官能团作用形成, 且随着标液浓度的上升, 该官能团吸收带的吸收明显增强[9]。
水中有机物对NIR光的吸收很弱, 常被水的强吸收峰掩盖, 不易从原始光谱中直接观察到[10]。 因此, 在NIR波段建立模型之前, 需要将NIR吸收光谱进行处理以突出样品中污染物主要官能团的光谱特性。 将吸收光谱进行一阶导数谱, 在954, 1 286, 1 447和1 753 nm附近有明显的吸收峰, 这是污染水体含有的芳香烃化合物的C— H伸缩振动的一、 二级倍频和羰基二、 三级倍频的吸收带[10]。 UV波段与NIR波段相比可知, UV波段的吸收峰的信息含量并不高, 但稳定较好; NIR波段覆盖范围广, 反映污染物的种类也更加丰富。
光谱数据的采集受到外界环境影响, 通过对UV和NIR原始光谱进行一定预处理, 可以有效地降低外界环境的影响, 提高最终定量预测模型的预测精度。 采用一阶导数、 Savitzky-Golay平滑[11]等方法对光谱数据进行预处理。 一阶导数谱可以有效消除基线漂移、 旋转以及背景干扰, 然而, 在放大信息的同时, 噪声也被放大。 为了消除噪声影响, 采用S-G滤波, 对一阶导数谱进行滤波。
将所有的水体样本按照浓度随机打乱, 依照3:1的比例分为校正集和预测集, 测量值的最大最小样本归为校正集。
基于UV和NIR光谱建立数据级和特征级的融合预测模型, 对经过预处理之后的UV和NIR光谱数据进行融合。
在特征级融合的过程中, 将经过预处理之后的UV光谱数据和NIR光谱数据分别采用反向区间偏最小二乘算法[12]对其特征区间进行挑选, 其中反向区间偏最小二乘法划分的信息区间数量为15个, 最大因子数设为8, 在设定子区间数下, 具体筛选波段结果如表1所示。 将筛选出的特征区间吸光度— 浓度数据矩阵X, 作为GANs模型的输入, 将真实测量COD值作为输出值Y, 获得特征级融合UV-NIR的COD浓度预测模型。
| 表1 未归一化处理的数据级和特征级融合GANs模型 Table 1 Data fusion and feature level fusion GANs models without normalized treatment |
同理, 在数据级融合过程中, 将经过预处理之后的UV区间光谱数据和NIR区间数据直接串联形成一个新的吸光度— 浓度数据矩阵X, 获得数据级融合UV-NIR的COD浓度预测模型。
由表1可知, 不论是数据级融合还是特征级融合, 预测模型的精度都不够令人满意, 其中数据级融合模型不论是校正集还是验证集的误差都较大, 其R2分别为0.978和0.915, RMSECV分别达到了2.356和1.659, 偏差分别为0.318和0.764, 这说明模型的预测精度不高, 泛化能力也不能让人满意; 对比数据级融合模型, 虽然直接融合的特征级融合模型的R2, RMSEC, RMSEP和偏差较数据级融合有一定提高, 但是模型评价参数也不够理想, 不能达到精准预测的要求。
由于实验中得到的UV光谱(190~310 nm)和NIR光谱(830~2 100 nm)的数据量不均匀, 数据量占有绝对优势的NIR光谱可能在光谱融合的过程中掩盖掉UV光谱的贡献, 从而主导最终融合模型的结果。 经过反向区间偏最小二乘算法筛选过的优选区间也刚好处于NIR波段, 波段分别为820~952和1 719~1 836 nm, 而UV波段被掩盖住, 这就验证了在UV光谱和NIR光谱融合的过程中, 确实存在两种光谱对预测模型贡献度不平衡的问题, 其中NIR的贡献度远远大于UV光谱的贡献度, 从而导致UV波段被掩盖, 相应的多光谱的预测模型的精度也达不到要求, 让光谱融合失去了意义。 为了解决这一问题, 采用归一化方法处理UV和NIR光谱, 并讨论不同归一化方法对建模的影响, 分别采用标准归一化、 最大最小归一化和矢量归一化对光谱数据进行归一化处理, 将经过归一化后的UV和NIR光谱数据进行融合, 并使用反向区间偏最小二乘算法进行特征区间选择, 分别作为GANs模型的输入X, 将真实测量COD值作为输出值Y, 建立不同归一化方法处理后的COD预测模型, 具体如表2所示。
| 表2 不同归一化方法的GAN预测模型结果统计 Table 2 Statistics of the result of GAN prediction model using different normalization methods |
通过表2可知, 不论是数据级融合模型还是特征级融合模型的预测精度较未归一化之前都有明显的提高, 其中基于最大最小归一化进行数据处理后得到的多光谱的预测模型的性能最好, 不论从相关系数R2还是RMSECV, RMSEP和偏差, 都表现出很高的预测精度。
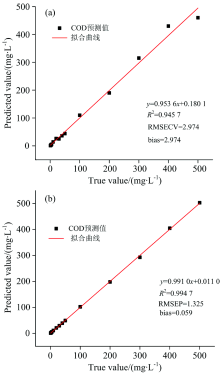
基于上面的研究进行数据级融合, 对UV区间光谱数据和NIR区间预处理后的数据进行归一化处理(采用Max-Min-Nor预处理), 直接串联形成一个新的吸光度-浓度数据矩阵X, 并获得最终的UV-NIR的COD浓度预测模型。 通过验证集实验验证模型的预测精度情况, 如图2(a)所示。
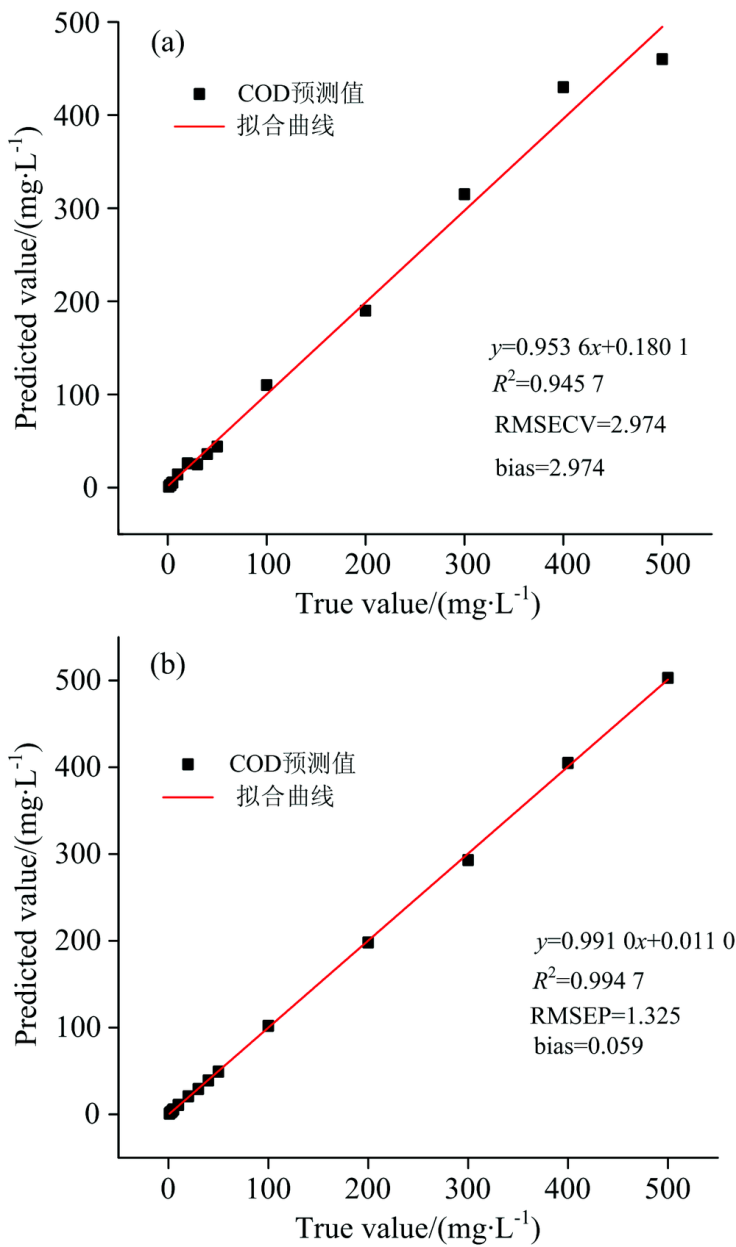 | 图2 基于GANs算法建立COD预测模型 (a): 数据级融合; (b): 特征级融合Fig.2 COD prediction model based on GANs algorithms (a): Data level fusion; (b): Feature level fusion |
同理, 进行特征级数据融合, 对UV区间光谱数据和NIR区间预处理后的数据进行归一化处理(Max-Min-Nor预处理), 通过反向区间偏最小二乘法筛选出特征区间, 并进行特征级数据(MLDF)融合, 采用GANs算法建立MLDF多光谱融合的COD浓度预测模型。 通过验证集实验验证模型的预测精度情况, 如图2(b)所示。
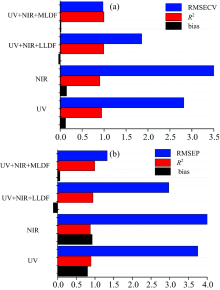
根据光谱类别以及融合方式的差异性, 建立不同的基于GANs算法的COD浓度预测模型, 包括单一谱源的UV全波段GANs模型、 单一谱源的NIR全波段GANs模型、 UV+NIR数据级融合的GANs模型和UV+NIR特征级融合的GANs模型, 并进行预测性能对比, 结果如图3和表3所示。
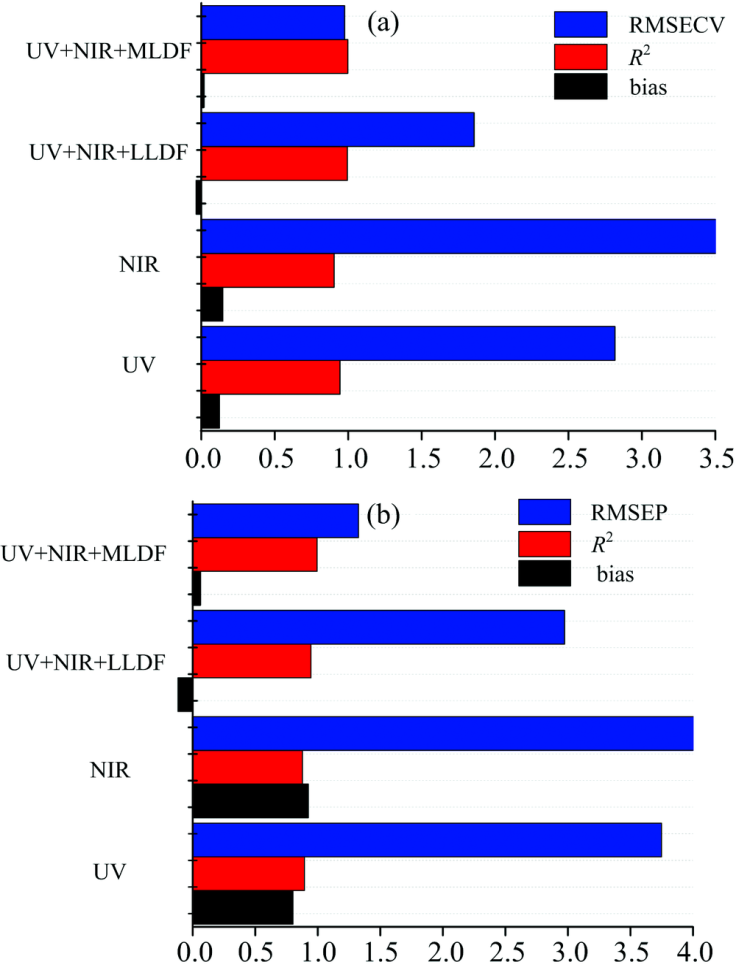 | 图3 不同定量预测模型评价参数的对比图 (a): 校正集评价参数; (b): 验证集评价参数Fig.3 Comparison of evaluation parameters of different quantitative prediction models (a): Correction sets; (b): Verification sets |
| 表3 不同定量预测模型评价参数表 Table 3 Evaluation parameters of different quantitative prediction models |
依据模型校正集和验证集的评价参数: 决定系数R2、 交叉均方根误差RMSECV, RMSEP和加标回收率, 可以得到以下结论: 对于校正集的水质COD预测模型而言, NIR吸收光谱的模型效果最差; UV吸收光谱模型的预测效果也较差; 而基于UV+NIR的数据级融合(LLDF)模型和特征级融合(MLDF)模型的校正集评价指标较单一谱源的预测模型提升明显, 其中MLDF模型的RMSECV较单一谱源UV模型、 NIR模型和LLDF提高189%, 261%和91%, R2提高5.4%, 9.3%和1.1%。
而对于验证集而言, 单一谱源的UV和NIR预测模型的评价参数较差, 不能满足监测的精度要求; UV+NIR的数据级融合模型的评价参数下降、 回收率不佳, 也不能满足实际的水体环境监测; UV+NIR的特征级融合则预测效果最佳, 模型的R2达到了0.994 7、 RMSEP为1.325, 回收率达到了98.4~103.1, 都是所有模型中效果最佳的, 其中MLDF模型的RMSEP较单一谱源UV模型、 NIR模型和LLDF模型提升了183%, 210%和124%, R2提升了10.1%, 11.8%和4.9%。 说明在实际日常监测中, 基于特征级信息融合的多光谱COD模型能够取得最佳的预测效果。
提出了一种基于多光谱融合和GANs算法的COD浓度预测模型, 该模型是基于UV光谱和NIR光谱进行信息融合, 结合GANs算法建立的非线性多光谱COD预测模型。
(1)基于未经归一化的UV和NIR光谱, 直接搭建数据级和特征级数据融合的COD浓度预测模型, 模型的整体效果不理想。 分析得知UV和NIR光谱的数据量不均衡, 让NIR光谱掩盖了UV光谱的贡献度。
(2)采取归一化方法处理UV光谱和NIR光谱, 克服光谱数据量不均衡的问题。 并讨论了不同归一化方法对建立COD浓度预测模型精度的影响。
(3)实验验证表明该模型相关系数的平方为0.994 7, 预测均方根误差为1.325, 比数据级融合的预测模型误差降低了52.9%, 预测回收率为98.4%~103.1%, 远低于其他几组, 模型的泛化能力更强, 预测精度也更高。 与单一谱源的监测模型相比, 多光谱数据融合能反映更多的水体样品的化学信息, 更加全面揭示水体的污染物程度, 提高最终的COD预测准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|