






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
IPSO-BP木材绝干密度近红外光谱预测模型
[于雷 , 陈金浩, 李龙飞, 李超
, 陈金浩, 李龙飞, 李超* , 张怡卓* ]
, 陈金浩, 李龙飞, 李超, 张怡卓]
|
|


作者简介: 于 雷, 1982年生, 东北林业大学林业工程博士后 e-mail: relayjfr@163.com
木材密度决定着木材力学性能, 是木材物理性能的重要指标之一。 近年来, 由于近红外光谱分析具有操作过程简单、 方便、 快速等优势, 已有学者应用近红外光谱数据预测木材密度, 但是, 在实际应用中, 数据集缺乏、 光谱特征欠优、 非线性拟合准确性低等问题还没有得到完全解决, 木材密度预测模型的精度有待于进一步提升。 木材密度中, 木材的绝干密度相对稳定, 测量结果相对精确, 以柞木绝干密度预测为研究对象, 通过采集不同含水率下的近红外光谱信息构建出适合不同含水率条件的绝干密度非线性预测模型。 首先, 选用德国INSION公司的近红外光纤光谱仪, 运用SPEC view 7.1软件对不同含水率的柞木样本采集光谱信息; 然后, 利用SPXY样本划分方法, 按2:1划分校正集与预测集, 并利用多元散射校正、 二阶导数光谱及S-G平滑方法进行光谱预处理, 以减少散射光和高频噪声的影响; 接着, 运用连续投影算法(SPA)提取有效的波长信息; 最后, 运用一种非线性权重粒子群算法优化的BP网络(IPSO-BPNN)建立不同含水率状态下的近红外光谱与柞木绝干密度之间的关联, 实现柞木绝干密度预测模型的构建。 实验过程中, 加工选取了100个柞木试件样本, 在绝干条件下测量样本试件密度和光谱信息, 并浸泡水中测量出不同含水率对应的光谱信息, 实验结果表明: SPXY保证了校正集样本的均匀分布, 提高了模型泛化能力; MSC、 二阶导数和S-G卷积平滑相结合的方法抑制了原始光谱中噪声高频信号, 同时使得峰值更加突出; SPA从117个光谱数据中优选出16个特征波长, 提高了建模精度; IPSO-BPNN模型较SPA-PLS, BP和PSO-BP具有更高的相关系数, 更小的均方根误差, 柞木绝干密度预测相关系数为0.938, 预测均方根误差为0.012 9, 方法可以对木材密度在线无损测量提供一定的理论基础。
Wood density is an important physical property, which determines the mechanical properties of wood. In recent years, as NIR has the advantages of simple, convenient and fast operation, it has already been used in terms of wood density prediction. However, in practical application, the sample sets shortage, spectral characteristics selection and non-linear fitting inaccuracy still not been solved definitely, and the accuracy of wood density prediction model needs to be further improved. Among all the wood density parameters, the absolute dry density of wood is relatively stable, and the measurement results are relatively accurate. In this paper, the prediction of absolute dry density of oak is studied. By collecting spectroscopy information under different moisture content, a non-linear prediction model of absolute drying density suitable for arbitrary moisture content is constructed. The near-infrared optical fiber spectrometer of INSION Company in Germany was selected, and the spectral information of oak samples with different moisture content was collected by SPEC view 7.1 software. Then, the calibration set and prediction set were divided according to 2:1 using SPXY sample partition method, and multivariate scattering correction, second derivative spectroscopy and S-G smoothing method were used to reduce the influence of scattered light and high-frequency noise; After that, continuous projection algorithm SPA was used to extract effective wavelength information; finally, a BP network (IPSO-BPNN) was used to establish the correlation between near-infrared spectra and oak absolute dry density under different moisture content, which was optimized by a non-linear weighted particle swarm optimization algorithm here. The density and spectral information of 100 samples of oak wood was obtained under absolute drying condition, and the spectral information was collected corresponding to different moisture content. The experimental results show that SPXY guarantees the uniform distribution of calibration samples and improves the generalization ability of the model; Using a combination of MSC, second derivative and S-G convolution can smoothly suppressthe high-frequency noise signal in the original spectrum and make the peak value more prominent;16 characteristic wavelengths were selected by SPA from 117 spectral data. Generally, IPSO-BPNN model has a higher correlation coefficient than SPA-PLS, BP and PSO-BP, own smaller root mean square error. The correlation coefficient of the absolute dry density of oak is 0.938, and the root mean square error is 0.012 9.
木材密度是木材的重要物理性能指标, 与木材力学性能有着密切的联系。 木材密度可分为基本密度、 气干密度和绝干密度, 三种密度之间可以通过公式相互转换。 其中, 绝干状态下的样本质量和体积相对稳定, 绝干密度测试结果更精确。 木材密度的检测方法有称重法、 机械力密度检测法和射线密度检测法[1]。 传统称重法测量结果准确, 但是操作过程复杂, 耗时长; 机械力密度检测法快速有效, 但属于破坏性实验; 射线密度检测方法能够快速无损检测木材密度, 但是实验环境要求严格, 射线会对操作人员产生危害。
近红外光谱分析技术具有操作过程简单、 方便、 时间快且无损等优点, 近年来已被应用到木材密度检测中[2, 3, 4]。 Alves利用近红外光谱建立了海岸松和落叶松密度的偏最小二乘法回归模型[5]。 Isik结合近红外分析与最小二乘支持向量机建立了木材密度、 力学强度的快速预测[6]。 Takkaaki运用近红外光谱分析出影响木材密度的敏感光谱波点, 并运用偏最小二乘建立了不同含水率下的木材密度预测模型[7]。 李耀翔等研究枫桦木材密度时, 探讨了小波压缩的近红外光谱处理方法, 并利用偏最小二乘回归方法对数据进行了建模[8]。 尽管国内外学者已经开展木材密度的近红外光谱预测方法研究, 但是, 多数研究是在含水率一定条件下建立的木材密度预测模型, 此外, 在建模过程由于缺少合理的样本集优选、 光谱预处理、 特征优选以及非线性建模等环节, 木材密度建模精度有待于进一步提升。
以柞木(Xylosma racemosum)绝干密度预测为例, 首先采集不同含水率下的柞木样本表面光谱数据, 并通过SPXY样本划分方法得到校正集与预测集; 然后, 对光谱进行预处理消除基线漂移、 散射影响和噪声; 最后, 运用SPA对光谱数据进行特征降维, 并运用IPSO-BP网络建立任意含水率条件下光谱信息与绝干密度间的联系。 具体建模过程如图1所示。
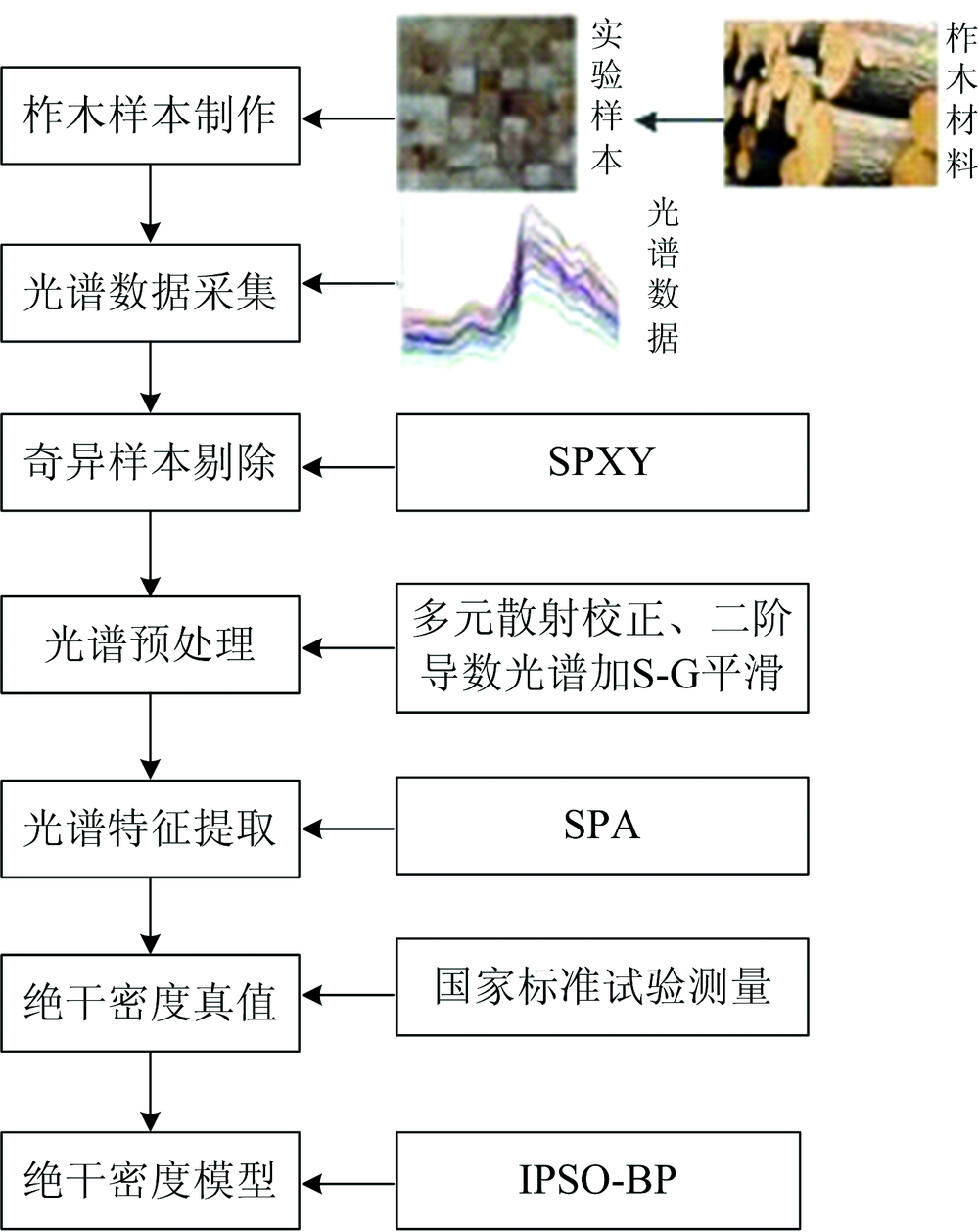 | 图1 木材绝干密度建模流程Fig.1 Modeling process of wood absolute drying density |
柞木样本来自于黑龙江省五常市林业局冲河林场, 按照国家标准(GB1929—2009)制作20 mm×20 mm×20 mm的密度标准样本, 选出其中100个无明显颜色差异且无缺陷的样本进行密度预测研究, 图2、 图3、 图4分别为加工的柞木样本试件、 样本干燥及称重过程。
 | 图2 部分样本实拍图Fig.2 Picture of some samples |
 | 图3 试样烘干Fig.3 Specimen drying |
 | 图4 试样全干状态质量测量Fig.4 Quality measurement of smples in dry state |
选用德国INSION近红外光纤光谱仪, 运用SPEC view 7.1软件对木材密度样本进行光谱信息采集。 该光谱仪分辨率小于16 nm, 光谱范围为900~1 700 nm, 共117个波长点。 在采集过程中, 温度控制在20 ℃, 平均相对湿度为50%。 为了采集不同含水率的柞木样本近红外光谱, 首先将样本充分浸泡在水中, 取出后, 从样本集中随机采集10个样本的光谱信息并记录其编号, 然后按照表1时间间隔, 从剩余样本中再随机选择10个样本采集光谱信息, 直到最终采集完全部试件光谱信息。 在采集绝干密度光谱信息时, 由于绝干材在空气中会很快地吸收水分而达到平衡含水率, 所以在测量木材绝干密度时要足够快。 实验证明, 1 s的时间差, 柞木样本含水率变化非常小, 可以忽略不计。 实测样本绝干密度和含水率分布如表2、 表3所示。 在光谱采集过程中, 探头高度保持1 mm不变, 分别在柞木样本的上下两个横切面采集4点, 并取其平均值。
| 表1 不同含水率样本制备 Table 1 Preparing process of samples with different moisture contents |
| 表2 样本绝干密度分布 Table 2 Distribution of absolute dry density |
| 表3 样本含水率分布 Table 3 Sample moisture distribution |
为了避免样本分布不均匀所带来的校正集不具备代表性的弊端, 选用SPXY样本划分方法提高模型的泛化性和稳健性。 由于样本光谱数据x和真值y对建模结果都有影响, 在考虑样本之间的距离时, 将自变量和因变量同时考虑在内; 此外, 为了确保x和y在空间具有同样的权重, 分别除以它们自己距离的最大值。 具体公式如式(1)—式(3)
特征波长选择会影响建模的精度和速度, 连续投影算法(SPA)是一种前向变量选择算法, 它能够使矢量空间的共线性达到最小化[9]。 SPA的工作原理是通过迭代对原始数据投影映射, 构造新的变量集, 建立回归模型评价预测效果。 该算法所筛选出的敏感特征波段具有重要性顺序, 能直接反映所筛选变量与因变量之间的定量关系。
运用一种改进的粒子群优化(IPSO)算法优化BP网络, 并建立柞木绝干密度近红外预测模型, 以克服BP网络容易陷入局部优化, 且训练的速度过慢的问题。 传统PSO算法可以描述为一个D维的潜在解空间中, 由n个粒子组成的种群x=(x1, x2, …xn), 其中第i个粒子表示为一个D维的向量xi=(xi1, xi2, …, xid), 代表第i个粒子在D维搜索空间中的一个潜在解。 根据目标函数可计算出每个粒子位置xi对应的适应度值。 第i个粒子的速度为vi=(vi1, vi2, …, vid), 其个体极值的位置pg=(pg1, pg1, pg2, …, pgd)。 在每一次迭代过程中, 粒子通过个体极值和全局极值更新自身的速度和位置, 更新公式如式(4)和式(5)
式中, ω 为惯性重, d=1, 2, …, D; i=1, 2, …, n; k为当前迭代次数; vid为粒子的速度; c1和c2为加速因子; r1和r2为分布于[0, 1]上的随机数。
针对粒子群优化算法中惯性权重线性递减策略影响收敛速度等一系列的问题, 弥补算法的不足, 采用一种对ω 非线性递减策略减少的群算法(IPSO)[10], 算法公式如式(6)
式中, ω max和ω min分别为最大惯性权重和最小惯性权重, k为算法当前迭代次数; Tmax为最大迭代次数, 通常ω max和ω min取0.9和0.4时算法的性能会获得较大的提升。
100个柞木样本以2:1的比例划分为校正集67个, 预测集33个。 为验证样本集划分的重要性, 在采集柞木表面近红外光谱数据后, 运用SPXY方法取处校正集和预测集, 运用PLS模型来评价预测结果有效性。 表4为运用SPXY和随机选择样本建模的比较, 参数表明: 基于SPXY方法的PLS模型的指标参数都有所改善。
| 表4 SPXY与随机样本选择建模比较 Table 4 Modeling comparison between SPXY and random selections |
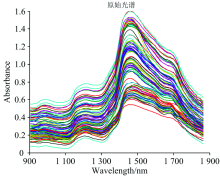
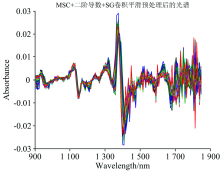
采用多元散射校正(MSC)、 二阶导数光谱加S-G平滑三种方法相结合对样本光谱进行预处理, 数据处理工具为MATLAB 7.0, 原始光谱如图5所示。 经过MSC预处理后, 原始光谱的散射光得以减弱, 光谱变得集中, 更能看出光谱走向和趋势, 但光谱依然存在信息强度不足和吸收峰不明显现象。 在此, 加入二阶导数操作, 并加入平滑处理, 以减弱噪声信号。 三种方法结合的预处理结果如图6所示。
 | 图5 原始光谱图Fig.5 Original spectra |
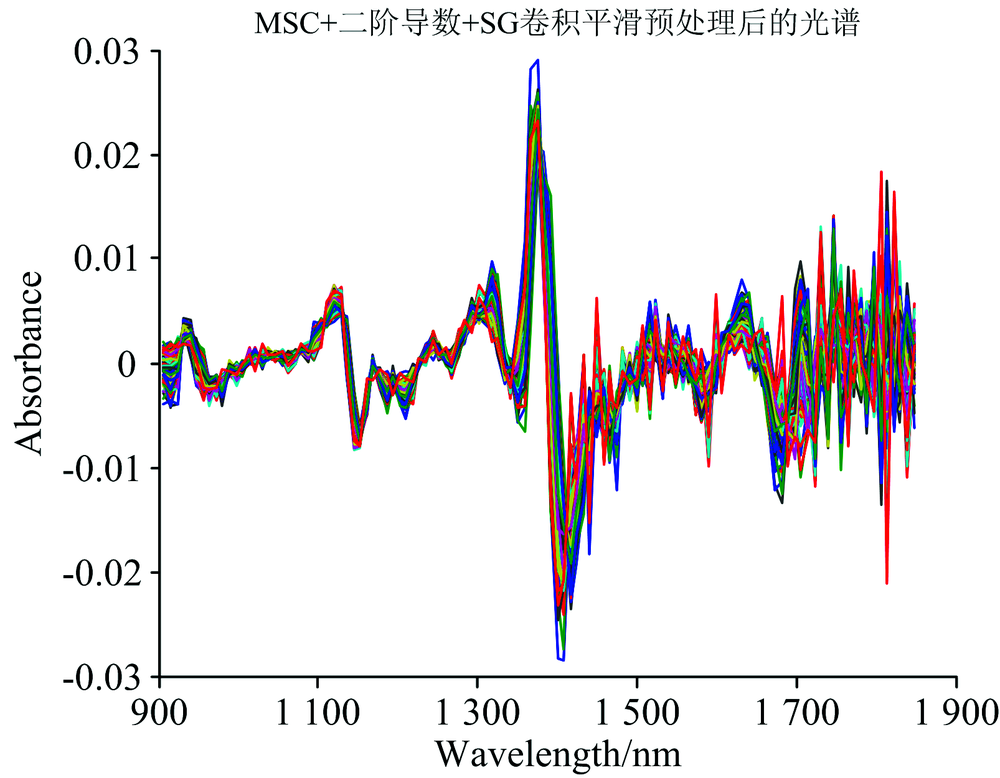 | 图6 预处理后的光谱Fig.6 Pretreated spectra |
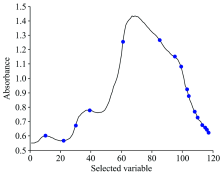
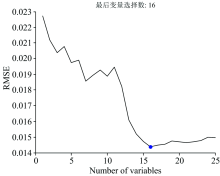
对近红外光谱的117个波长使用SPA进行筛选, 运用PLS进行优选结果分析。 在变量个数不断增加的过程中, RMSE值大幅度降低, 当变量个数为16时, RMSE值达到最小, 为0.014 6。 当选取变量继续增加时, SMSE也有所上升。 优选光谱中的位置如图7所示, 不同变量数的与RMSE的关系如图8所示。
 | 图7 选择变量在光谱中的位置Fig.7 The position of selected variables |
 | 图8 选择变量与RMSE之间的关系Fig.8 The relation between selected variables and RMSE |
利用SPA提取的16个特征, 分别建立PLS模型、 BP神经网络、 PSO-BP神经网络以及IPSO-BP神经网络模型, 并对33组数据进行验证, 预测结果如表5所示。 BP, PSO-BP和IPSO-BP均采用三层结构, 光谱优选波长为输入, 隐层节点数为10, 柞木绝干密度为输出, 隐含层为transing S型传输函数, 输出层为purelin线性函数, 训练函数为traingd梯度下降型函数, 学习速率设置为0.01, 学习训练次数为10 000次。 图9为PSO-BP模型预测值与真值散点分布图、 图10为IPSO-BP预测与真值散点分布图。
| 表5 四种建模方法的比较 Table 5 The comparison of 4 modeling methods |
 | 图9 PSO-BP预测值与真值散点分布图Fig.9 Scatter map of predicted value and true value based on PSO-BP |
 | 图10 IPSO-BP预测值与真值散点分布图Fig.10 Scatter map of predicted value and true value based on IPSO-BP |
从表5可以看出, PLS模型校正集与预测集的结果较稳定, 说明近红外光谱与绝干密度间存在一定的线性关系; BP网络预测结果相对较低, 可能因为BP网络陷入了局部寻优; PSO-BP网络相对BP的结果较好, 但IPSO-BP网络得出的结果最好, 通过图11和图12可知, 相比较PSO-BP, IPSO-BP达到全局最优的速度更快, 预测集相关系数达到0.938, 预测均方根误差为0.012 9。
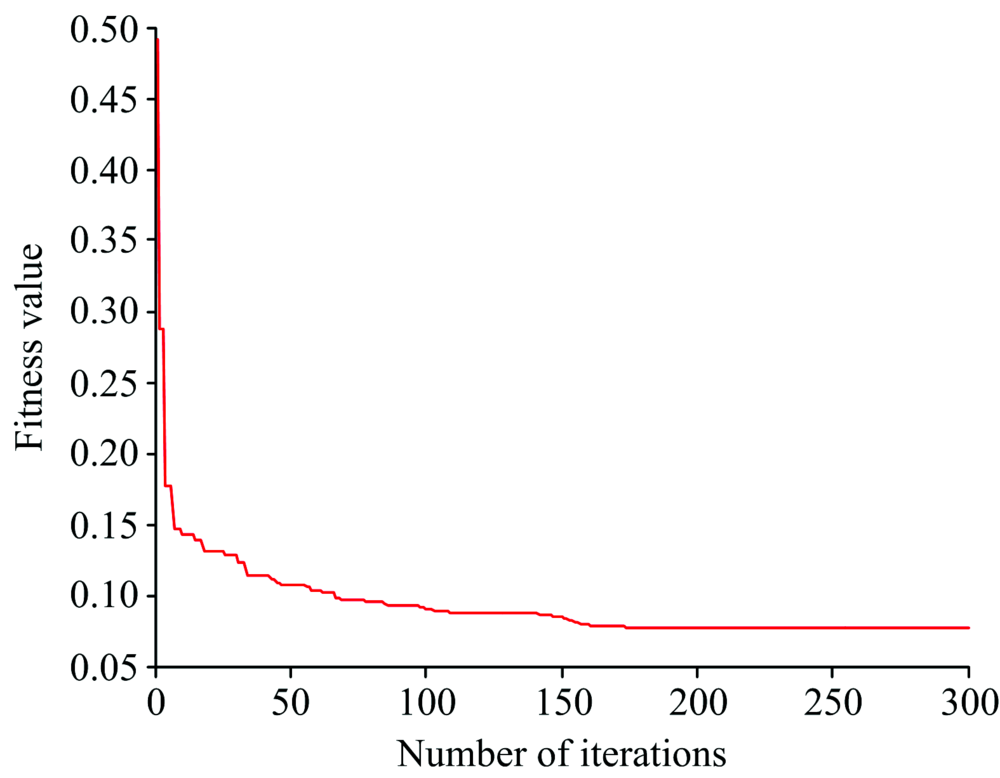 | 图11 PSO迭代次数曲线Fig.11 PSO iteration curve |
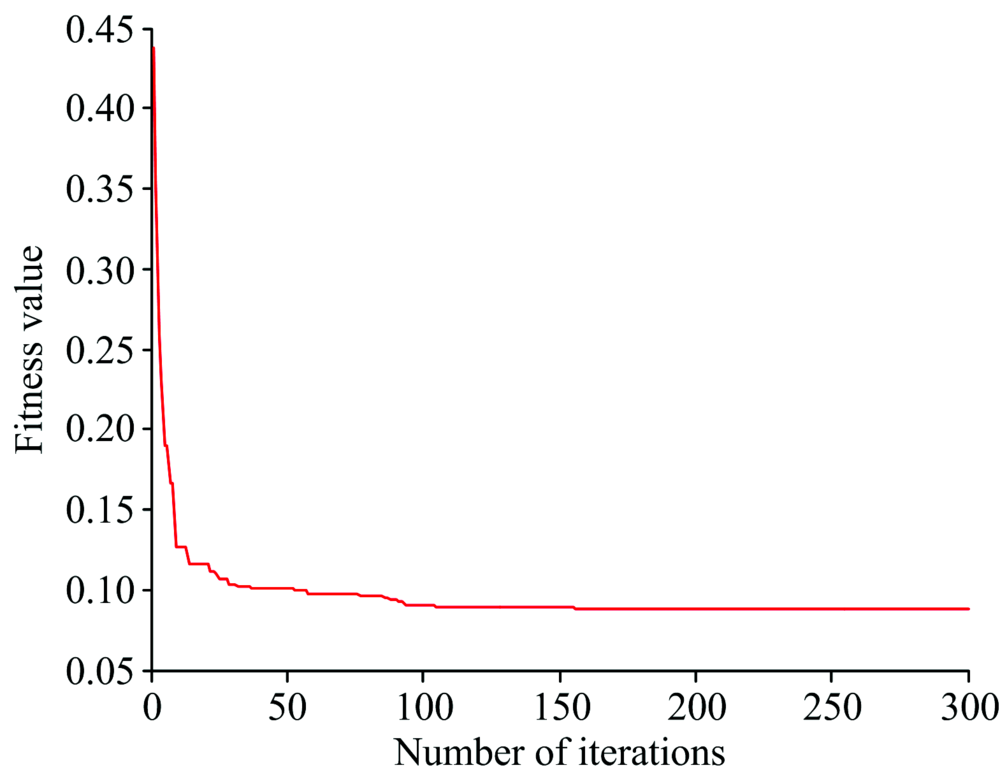 | 图12 IPSO迭代次数曲线Fig.12 IPSO iteration curve |
从提高木材预测密度精准度入手, 分别就样本优选、 光谱预处理、 特征优选以及光谱数据特征的非线性建模等部分环节进行了深入研究。 研究结果表明: SPXY保证了校正集样本的均匀分布, 提高了模型泛化能力; MSC、 二阶导数和S-G卷积平滑相结合的方法能够很好的抑制原始光谱中噪声高频信号, 同时使得峰值更加突出, 消除了基线漂移、 消弱了散射光的影响; SPA可以有效优选出光谱波段, 进而提高预测精度缩短预测时间; IPSO-BP网络在近红外光谱与柞木绝干密度建模上具有更好的结果, 对近红外光谱预测木材密度提供了新的思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|