
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
t-SNE降维的红松籽新旧品性近红外光谱鉴别
[李鸿博 , 曹军, 蒋大鹏, 张冬妍
, 曹军, 蒋大鹏, 张冬妍* , 张怡卓* ]
, 曹军, 蒋大鹏, 张冬妍, 张怡卓]
|
|


作者简介: 李鸿博, 1990年生, 东北林业大学机电工程学院博士研究生 e-mail: nefuzdhlhb@163.com
新旧品性是体现红松籽食用价值和育种价值的重要标准。 贮存期长短不同的红松籽的深加工价值不同, 但是通过外观形态、 重量和质地等很难分辨。 目前仍采用传统生物化学方法对红松籽化学性质及种子活性进行检测, 判断其新旧品性, 这种方法耗时较长难以满足在线检测的需求, 并且试剂处理不当会对环境造成污染。 近红外光谱检测在食品和林业领域中被广泛应用, 对带壳坚果类林产品的定性分析有实际和指导意义。 采用近红外光谱分析技术, 对成熟于当年和往年的红松籽进行无损检测研究。 首先, 将随机抽选的120个按新旧分类的红松籽作标记, 为了减少测量过程中的漏光现象并且使实验数据具有一般性, 统一采集松籽样本同一侧面的近红外漫反射光谱; 然后, 利用标准正态变量变换(SNV)、 一阶导数以及卷积平滑(SG)算法对原始光谱进行预处理, 以减少实验过程中人为因素及预处理方式带来的影响, 突出近红外光谱的特征信息; 随后, 使用主成分分析(PCA)和t-分布邻域嵌入(t-SNE)对预处理之后的数据进行线性与非线性降维, 聚类分析并比较降维效果。 通过数据可视化以及聚类参数的输出, 比较得出效果较好的降维方案。 红松籽近红外数据应用非线性降维处理效果优于传统线性方法, 于是运用t-SNE对数据降维以得到优化后的特征变量; 最后, 以降维之后的数据作为输入, 将2/3的试样数据作为校正集用于建立新旧籽分类的支持向量机校正模型, 将1/3的试样数据作为验证集用以对模型性能进行验证。 结果表明: 使用SNV、 求导和SG叠加的方法对光谱进行预处理能够有效消除噪声, 使吸收峰更明显, 光谱轮廓更加清晰平滑, 更有助于后期模型的建立; 将数据使用t-SNE方法降至二维作为分类模型的输入, 并且当核函数选择RBF, K取值为5, γ取82.54, 惩罚系数 C为383.12时, 所建立的SVM分类模型分类效果最好, 准确度可达97.5%, 平均耗时0.02 s。 利用近红外光谱分析方法能够对红松籽新旧品性实现无损检测。
The new and old characteristics of pinus koraiensis seeds is an important property reflecting the edible value and breeding value. The pinus koraiensis seeds with a short storage period also have high deep processing value. However, it is difficult to distinguish by appearance, weight and texture. At present, traditional biochemical methods are used to detect the chemical properties and germination percentage of pinus koraiensis seeds to judge their new and old quality. It takes a long time to meet the needs of online detection, and improper treatment of chemical reagents can cause environmental pollution. Near-infrared spectroscopy (NIRS) is widely used in the field of food detection and forestry. Therefore, it has practical significance and guiding significance for qualitative analysis of nuts with shells. In this study, near infrared spectroscopy was used to conduct nondestructive testing of pinus koraiensis seeds matured in the current year and in previous years. Firstly, the 120 pinus koraiensis seeds were randomly selected and labeled according to new and old classifications. In order to reduce the leakage of light during the measurement process and make the experimental data more generally, the near-infrared diffuse reflectance spectra of pinus koraiensis seeds samples on the same side were collected uniformly. Then, the original spectrum was pretreated by using a standard normalized variable (SNV), first derivative and Savitzky-Golay (SG) algorithm, so as to reduce the influence caused by human factors and pretreatment in the experiment process, and highlight the characteristic information of the near-infrared spectrum. After that, principal component analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) were used to reduce the dimension of the pretreated data and compare the effect of dimension reduction. Through the visualization of the data and the output of the clustering parameters, a better dimension reduction scheme was obtained by comparison. The non-linear dimensionality reduction method has a good effect in the near-infrared spectral data processing of pinus koraiensis seeds. Therefore, the t-SNE method was used to reduce the dimensionality of the data, and the optimal characteristic variables were obtained. Finally, taking the reduced dimension data as input. Using two-thirds of the sample data as a correction set to establish a support vector machine (SVM) correction model for classification of new and old seeds, and a third of the sample data were used as a validation set to validate the model performance. The results indicate that. The superposition of SNV, first derivative and SG to pretreat the spectrum can effectively eliminate the noise, it makes the absorption peak more obvious. Meanwhile, it also makes the spectral profile clearer and smoother, which is more conducive to the establishment of the later model. The method of t-SNE is used to reduce the data to two-dimension as the input of the classification model, and when the kernel function selects the RBF, the value of K is 5, γ is 82.54 and the penalty coefficient C is 383.12, the SVM classification model has the best classification effect, the accuracy can reach 97.5%, and the average time consumption is 0.02 s. Near-infrared spectroscopy can be used to achieve non-destructive testing of the new and old characteristics of pinus koraiensis seeds.
红松籽(pinus koraiensis seeds)盛产于中国北方, 它是国家二级保护植物红松的果实, 新鲜的红松籽仁有很高的经济和营养价值。 因自然氧化等原因, 陈旧红松籽仁相比较于新鲜红松籽仁营养流失十分严重。 经过同样加工流程后, 从带壳红松籽外观、 质地和重量上很难判断新旧差异。 传统的鉴别方法是将红松籽去壳得到红松籽仁并研成粉末, 再运用索氏抽提法或者凯氏定氮法进行脂质和蛋白质性质及含量的检测, 从而进行新旧鉴别。 此方法测量精确, 但是检测工序繁琐、 耗时长而且成本高, 很难满足大批量样本检测以及实际生产的需求。 基于此原因, 亟需一种快速、 无损、 准确的带壳坚果成熟年份鉴别方法。
近红外光谱技术(NIR)是一种快速、 无损、 稳定性好的间接分析技术, 已经广泛应用于农业、 食品、 医药、 材料、 石油化工等众多领域, 并获得了丰硕的成果[1]。 近年来, 近红外光谱技术在食品科学研究中的应用也越来越广泛, 包括对食品营养物质种类的分析以及各营养物质含量的检测, 相似种类食品品种区分、 生长环境影响、 产地鉴别等。 Guo等在2016年通过比较近红外短波与长波的建模效果, 结合新型颜色补偿法对苹果可溶性固形物含量进行预测[2]。 Veró nica Loewe等在2017年用近红外光谱对智利人工林以及地中海地区不同产地松果作鉴别分析, 运用偏最小二乘法建立的判别模型能够快速区分不同地理来源的松籽样品[3]。 Cortes等在2017年运用可见/近红外光谱检测判断柿子的特殊涩味程度, 比较了不同采样点和不同模型的预测效果[4]。 Toktam Mohammadi-Moghaddam等在2018年运用可见/近红外反射光谱结合PLSR建模分析预测烤开心果籽粒的水分含量和结构特征, 并对织构特征进行准确预测[5]。 于慧伶等在2018年运用SA-PBT-SVM的分类方法对实木表面缺陷进行近红外光谱识别[6]。 Patrizia Firmani等在2019年运用近红外光谱对产于大吉岭的红茶进行品种以及掺假情况的鉴别[7]。 Muhammad Arslan等在2019年运用近红外光谱结合化学计量学算法, 对中国枣的抗氧化活性进行了快速检测[8]。
本文提出一种基于近红外光谱技术的红松籽新旧品性快速无损检测鉴别方法。 首先, 使用标准正态变量变换、 一阶导数以及卷积平滑算法对采集的近红外吸收光谱进行预处理; 然后, 利用t-分布随机近邻嵌入将光谱数据降维; 最后, 运用支持向量机建立红松籽新旧品性鉴别的校正模型和预测模型。
选用东北地区的红松松籽作为试验样本, 由分别成熟于2016年、 2017年秋季的陈旧松果和2018年秋季的新松果经机械和人工加工而成。 经过机器筛选达到进一步精加工处理要求并达到储藏标准。 为保证新旧样本在后期实验中均占有一定比例, 首先随机挑选出无疵试样各120个, 并分别对其进行O-1—O-120和N-1—N-120编号。 将制成的试样放入独立密封袋, 并且置于恒温恒湿环境内进行保存, 为下一步进行近红外光谱扫描做准备。
1.2.1 样本分类处理
光谱采集前, 将标记好的所有新旧样本打乱混合, 从中随机抽取120个样本按照2:1的比例分为校正集和验证集, 使用80个校正集样本建立校正模型, 使用剩余40个验证集样本对模型进行外部验证。
1.2.2 光谱数据的采集
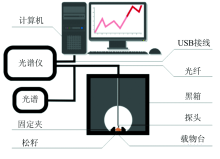
通过研究发现, 波长在1 000~1 800 nm范围内的光谱携带的信息能够较好地反应本研究所需性质[1]。 实验选用的光谱采集仪器是由德国INSION公司研发生产的One-chip微型集成光纤光谱仪, 光谱适用范围900~1 800 nm, 分辨率9 nm, 热波长稳定性小于0.03 nm·K-1。 采用两分叉光纤探头采集样本的近红外光谱, 室内温、 湿度控制在20 ℃和50%。 利用INSION公司开发的SPECview7.1软件进行光谱数据采集和存储, 所得光谱数据以Excel的形式导出。 开机后需要对光谱仪进行预热, 并利用聚四氟乙烯白板对光纤探头进行校准, 之后将光纤固定在支架上, 光纤探头伸入测量黑箱顶端的小孔内, 使其与黑箱底部载物台上固定的松籽样本靠近, 对样本进行垂直、 接触并且无漏光测量, 待光谱谱线稳定后, 对本采样点扫描30次自动平均输出1个光谱。 实验所需的近红外光谱数据采集系统示意图如图1所示。
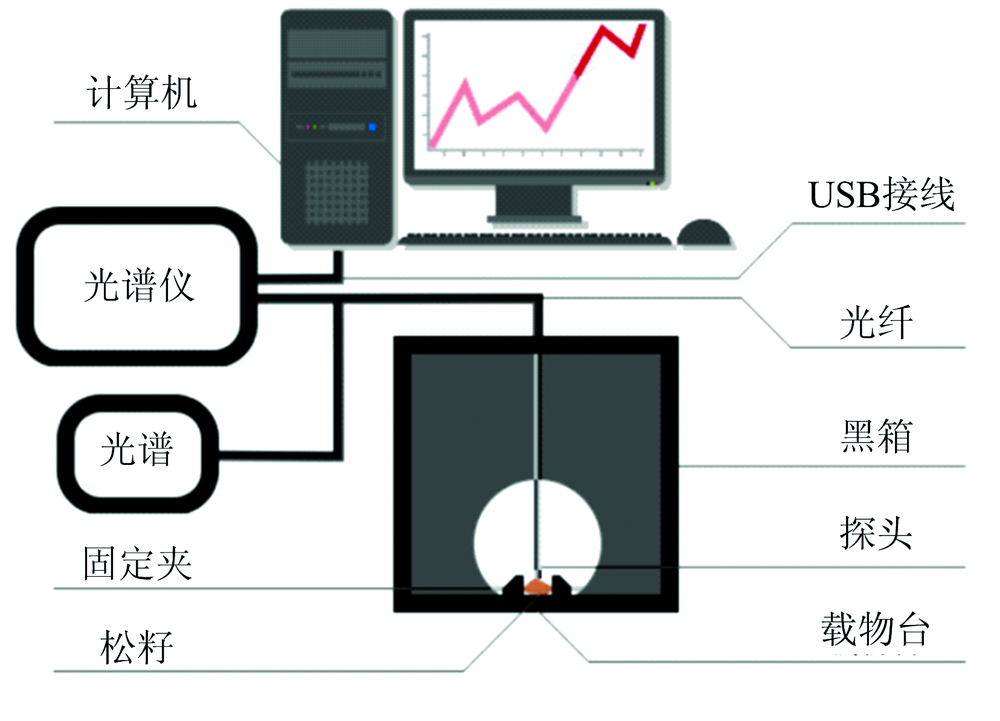 | 图1 近红外光谱数据采集系统示意图Fig.1 Schematic diagram of near infrared spectral data acquisition system |
红松籽的生长特性导致了红松籽每个被采集面的近红外吸收光谱吸收峰不同, 在对比同一红松籽样本不同采样位置的光谱曲线时发现: 完整带壳松籽和松籽壳的光谱曲线趋势高度相似, 去壳带皮松仁和去壳去皮松仁的光谱曲线虽在近红外吸收数值上有显著差异, 但是光谱图像的趋势相似, 即在光谱采集范围内, 不同状态的样本光谱数据变化趋势基本相似, 如图2所示。 本研究采集样本(完整松籽)的单侧平面光谱, 采集数据取平均值后用于分析和建模。
 | 图2 试样不同状态和不同采集位置的光谱对比Fig.2 Spectral comparison of samples in different states and sampling locations |
1.2.3 光谱预处理
对样本进行光谱数据采集的过程中, 由于抖动、 光线散射等原因会产生光谱基线漂移、 噪声干扰等影响[9, 10]。 因此, 需要先对原始光谱数据进行预处理。
标准正态变量变换(standard normalized variable, SNV)能够消除表面散射、 固体颗粒大小以及测量过程中光程变化对近红外漫反射光谱的影响[8, 11]。 对需要进行SNV变换的光谱Xi, k按式(1)计算
式(1)中, Xi为第i样本光谱的平均值, k=1, 2, …, m, m为波长点数; i=1, 2, …, n, 其中n为校正集样本数[8]。
为削弱由样本间(特别是不同分组样本之间)相互干扰导致的吸收光谱谱线重叠的现象, 在SNV处理的基础上求取一阶导数, 一阶导数如式(2)所示[12]
式中, xt为波长t处的离散光谱, g为窗口宽度。
求导过程会引入噪声, 使信噪比降低。 运用Savitzky-Golay(SG)卷积对光谱进行平滑, 能够有效去除光谱噪声、 提高信噪比。 SG卷积平滑算法如式(3)所示[4]
式(3)中, x是吸光度, i和j是波长点数范围内的序号, k!是求导阶数的阶乘, ak是权重系数。
1.2.4 t-SNE降维及效果评价
近红外光谱波长范围较大, 预处理未改变数据维度, 在建立分类模型前需对输入数据进行降维, 降维后的数据要保存本质结构信息。 传统降维是对光谱信息进行特征提取, 以剔除与所需性质无关的变量。 本研究运用流行学习的方法进行降维, 保留了样本全部数据信息和数据间隐含信息。
常用的线性降维方法是主成分分析(principal component analysis, PCA)[4], 经过预处理之后的数据依然高度非线性, 而非线性降维方法中t-SNE是目前公认效果最好的方法。
t-分布邻域嵌入(t-distributed stochastic neighbor embedding, t-SNE)算法基于邻域嵌入(stochastic neighbor embedding, SNE)算法改进而来, 在SNE算法中, 用条件概率pj|i表示高维空间的邻近数据点xi与xj间的相似度(两点邻近的条件概率), qj|i表示低维空间数据点yi与yj邻近的条件概率分布, 条件概率pj|i符合高斯概率分布, pj|i如式(4)所示[13]。
其中, ‖ xi-xj‖ 2表示邻近点xi和xj距离的平方; σ i是以数据点xi为中心的高斯函数的方差。 σ 的值可由每个点的K近邻值计算得到, K值取有效的最邻近点数量。
若要得到低维空间的最佳模拟点, 需将pj|i与qj|i的KL(kullback-leiber)距离之和最小化, 可用代价函数C表示, 如式(5)所示。
此处的P与Q分别为高维空间和低维空间中形成的条件概率分布, C值越小说明高维低维分布越一致, 低维空间数据点yi由梯度下降法得出最小值, 可用二维或三维坐标形式输出。
t-SNE算法将高维空间数据点之间的条件概率改进为与低维空间模拟数据点的联合概率[13]。 同时通过在高维空间采用高斯概率分布, 映射后低维空间采用自由度为1的t分布函数度量两点之间的相似度。 pij与qij分别表示高维空间数据点xi, xj与低维空间数据点yi和yj之间的联合概率, 如式(6)和式(7)所示。
qij可以用来表示嵌入空间上两个点的相似度, 目的是为小范围成对的相似点能够更精准地建模提供更大的空间, 同时也很好地解决了拥挤问题。
此时新的代价函数C与联合概率分布P与Q即高维与低维之间的KL距离等价, 如式(8)所示。
t-SNE算法实现维数约减与数据可视化的原因是因其能够从高维数据中恢复低维流形结构的特性, 并得到与其相应的嵌入映射。
数据降维即聚类的性能度量非量化指标可以通过比较数据可视化结果的方式: 参照标注属同类的样本点在低维空间中要求距离邻近; 反之, 不同类的样本点则要求尽量彼此远离。
本研究涉及降维效果的量化指标有Silhouette Score(轮廓系数)、 Calinski-Harabasz和Mutual Information(互信息, MI)。 Silhouette Score的取值范围是[-1, 1], 同类样本相近、 不同类样本远离时, 输出数值较高。 Calinski-Harabasz输出数值越大则聚类效果越好, 即类别内部数据的协方差越小、 类别之间的协方差越大聚类效果越好。 MI取值范围为[0, 1], 输出值反映聚类结果与真实情况的相符程度, 为正比例关系。
1.2.5 分类模型及性能评价
在完成对光谱数据的降维处理之后, 建立红松籽新旧品性鉴别的支持向量机(SVM)分类模型, 核函数选择RBF, C在10-2~103范围内取13个值, γ在10-9~103范围内取13个值, 模型因子数由网格搜索算法K重交叉验证确定, K取值为5, 得到的校正模型用查准率(Precision)、 查全率(Recall)与F1三项指标评价模型性能, 三项指标在0~1范围内取值越趋近于1说明模型的性能越好。 最后, 使用验证集样本对模型进行验证。 用分类准确率表示模型的预测能力强弱以及预测精度, 平均耗时表示模型的分类速率。
上述光谱预处理、 数据降维、 降维数据可视化输出、 模型的建立与评价等均采用PyCharm 2017软件完成。
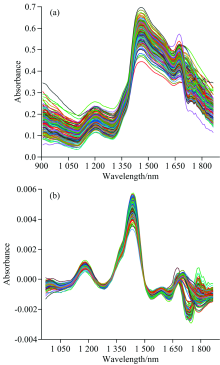
图3所示为120个实验样本的近红外光谱, 以及依次采用SNV、 求取一阶导数和SG卷积平滑算法预处理之后的光谱。 比较原始光谱与预处理光谱, 处理后的光谱轮廓更清晰, 噪声基本消除, 吸收峰更明显。
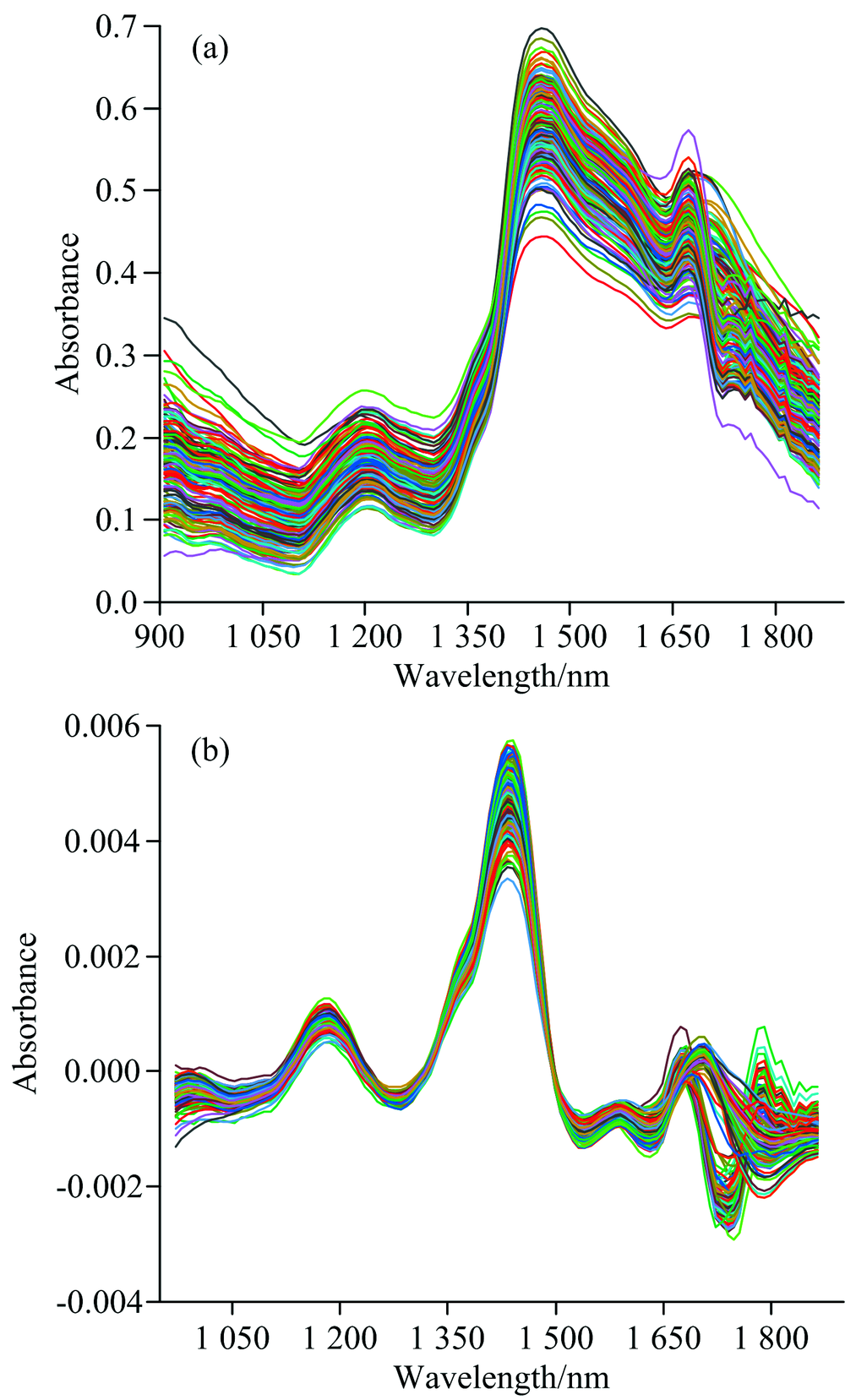 | 图3 原始光谱曲线和预处理结果 (a): 原始光谱; (b): SNV+一阶导数+SGFig.3 The original and pretreated spectra (a): Original; (b): SNV+First-order derivative+SG |
2.2.1 降维数据可视化
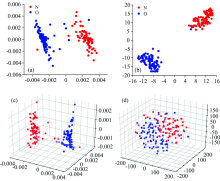
将预处理之后的光谱, 使用PCA将高维数据降至二维和三维的数据可视化输出如图4(a)和(c)所示。 图4(a)中, 用PCA方法降至二维的数据点簇间仅有少量交叉, 图4(c)中, 降至三维的数据点在三维空间中依然有少量交错现象; 图4(b)中的两簇数据点距离更远, 并且簇间没有交叉, 从数据可视化效果可以对比出t-SNE降至二维的降维效果更优。 这是因为t-SNE方法将低维空间中的高斯分布用t分布代替, t分布的长尾性质(中心部位偏低, 尾部偏高偏长)使不同类数据点更明显地分离。 而t-SNE降至三维应用于本研究样本数据, 交叉重叠较多, 降维效果不理想, 如图4(d)所示。
 | 图4 数据降维结果可视化 (a): PCA降至二维; (b)t-SNE降至二维; (c): PCA降至三维; (d): t-SNE降至三维Fig.4 Feature extraction results of UVE method (a): Reduced to two-dimensional by PCA; (b): Reduced to two-dimensional by t-SNE; (c): Reduced to three-dimensional by PCA; (d): Reduced to three-dimensional by t-SNE |
2.2.2 降维效果评价
在上一节可视化数据比较结果的基础上, 对各种降维方案的降维效果进行准确衡量并比较, 依据各量化指标的计算方法得出不同降维方案的降维效果评价指数。 输出各指数的数值以及对比结果如表1所示。
| 表1 PCA和t-SNE降维的评价指标比较 Table 1 The influence of different pretreatment methods for MOE modeling results |
从表1可知, 运用PCA降至二维和三维的效果几乎没有差异, t-SNE降至二维时输出的各项指标均优于其他方法。 特别是Silhouette Score和Calinski Harabaz Score两项指标, 输出值分别为0.820 0和2 972.012 7。 运用t-SNE方法降至二维的方案明显优于其他方案, 降维效果较好。
在完成光谱数据降维工作后, 将降维后的数据作为模型建立的输入数据, 使用SVM建立红松籽新旧品性鉴别的校正模型, 其预测性能结果的比较如表2所示。
| 表2 不同建模方法结果比较 Table 2 Comparison of the results of different modeling methods |
通过分析表2中的实验结果可以得出, 相较于原始光谱, 经过三种方法预处理并且运用t-SNE降至二维后的光谱数据所建立的校正模型预测准确率最高, 为98.75%。 此时, 校正模型的查准率为1, 查全率与F1趋近于1, 并且其输出值分别为0.974 4和0.987 0, 均优于其他各方案, 这也表明模型的预测性能得到了提升, 即所建立模型的效果最佳。 同时, 经过降维后的光谱数据维数从117降为2, 显著降低了输入数据维度, 使得数据量减少、 运算复杂度降低, 最终缩短建模时间。
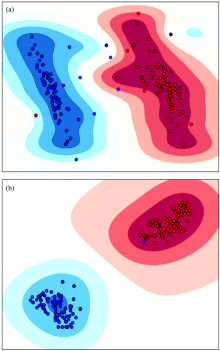
除此之外, 比较运用PCA和t-SNE方法降至二维建模的可视化效果可以得出: t-SNE将输入数据降至二维后, SVM模型分类效果更佳。 建模效果对比如图5所示。
 | 图5 二维输入建模效果 (a): PCA结合SVM建模效果; (b): t-SNE结合SVM建模效果Fig.5 Modeling effect of two-dimensional data input (a): Modeling effect of PCA combined with SVM; (b): Modeling effect of t-SNE combined with SVM |
完成校正模型建立工作后, 需使用验证集样本对校正模型的实际预测能力进行检验。 分别采用三种方案建立红松籽分类的近红外光谱预测模型, 对所有验证集样本进行分类预测, 并对预测的准确率和平均消耗时间进行比较分析, 结果如表3所示。
| 表3 预测模型结果比较 Table 3 Comparison of the prediction model results |
从表3可知, 依据原始光谱建立的SVM分类模型的分类准确率较低, 经过预处理的光谱数据对建模准确率的提升有一定效果, 但是依然消耗较长时间。 相较于其他两种模型, SNV、 一阶导数与SG叠加的预处理方案结合t-SNE降维的SVM分类模型分类准确率最高且消耗时间显著减小, 预测结果与真实情况较一致, 因此, 该模型能够准确、 快捷地定性预测红松籽的新旧品性。
构建了近红外光谱与东北红松籽新旧品性的关系。 利用SNV、 一阶导数以及SG卷积平滑算法对原始光谱进行预处理, 光谱中的重叠、 噪声得到有效消除。 预处理之后, 运用t-SNE对高维光谱数据进行降维处理, 此方法明显优于传统线性降维PCA的降维效果, 有效降低了数据的维度和建模的运算复杂度。 使用t-SNE降维后的光谱特征信息建立的SVM红松籽新旧品性分类模型, 验证集预测准确度高达97.5%, 平均耗时仅有0.02s, 表明该模型能够实现对东北红松籽新旧品性的无损鉴别检测, 并且识别速率较快, 能够满足实际生产在线检测的需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|