


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
太赫兹光谱技术在生物活性肽检测中应用研究
[王璞1  , 何明霞
, 何明霞1, * , 李萌2 , 曲秋红2 , 刘锐3 , 陈永德4 ]
, 何明霞, 李萌|
|


作者简介: 王 璞, 1997年生, 天津大学精密仪器与光电子工程学院硕士研究生 e-mail: wp412005676@163.com
生物活性肽作为21世纪人类健康的新宠儿, 研究证明其对人体生命活动有着很好的作用, 其检测方法也是备受关注, 太赫兹时域光谱技术因为其独特的性质在检测生物活性肽中有着不可比拟的优势。 选用牛骨肽、 海参肽和牛肽这三种生物活性肽, 通过透射式太赫兹时域光谱系统得到其在0.5~2 THz的吸收系数曲线。 从太赫兹吸收系数曲线来看, 鱼肽吸收系数大于海参肽和牛骨肽。 因为生物活性肽的氨基酸种类和肽键的相互作用, 导致其在太赫兹频段内没有明显的吸收峰, 为了更好的对其进行检测区分, 建立分类判别模型, 寻找出最适合这类物质的方法。 在对太赫兹原始吸收系数数据进行S-G平滑处理, 归一化预处理之后, 随机选取四分之三预处理好的数据划分为训练集, 其余为预测集, 导入分类判别模型。 模型包括分类器和最优参数选取两部分, 分类器选取支持向量机, 随机森林和极限学习机等有监督的分类方法, 使用遗传算法、 粒子群算法和网格搜索等智能优化算法选取支持向量机最优参数。 为了减少原始光谱数据维数并提高模型的运算速度, 使用主成分分析进行预处理, 将降维之后的结果导入分类模型。 综合考虑其准确率和运行时间等因素, 虽然基于粒子群算法的支持向量机具有最高的准确率98.3%, 但是运行时间较长为180 s; 使用极限学习机能够有着最短的运行时间0.2 s, 但是准确率为73.3%。 基于网格搜索的支持向量机准确率为95%, 运行时间为11 s, 能够在准确率较高的情况下使用较短的时间, 证明基于网格搜索的支持向量机对生物活性肽太赫兹吸收光谱具有快速, 准确的分类结果。 研究结果表明, 利用太赫兹时域光谱技术结合机器学习算法能够实现快速、 无损检测生物活性肽, 为生物活性肽的检测提供了一种新思路, 同时也为THz-TDS结合机器学习对吸收峰不明显的多肽之间的鉴别提供参考。
Bioactive peptides, as the new darling of human health in the 21st century, have been proved that they have a good effect on human life activities, and their detection methods are also of great concern. Terahertz time-domain spectroscopy technology has incomparable advantage in detecting bioactive peptides because of its unique properties. In this paper, three bioactive peptides, bovine bone peptide, sea cucumber peptide and fish peptide, were used to obtain the absorption coefficient curve of 0.5~2 THz by the transmission terahertz time domain spectroscopy system. From the terahertz absorption coefficient curve, the absorption coefficient of the fish peptide is higher than that of sea cucumber peptide and fish bone peptide. Because of the interaction between the amino acid species of bioactive peptides and peptide bonds, there is no obvious absorption peak in the terahertz frequency band. In order to better detect and distinguish them, a classification discriminant model is established to find the most suitable for such substances. After the S-G smoothing and normalization preprocess performed on the terahertz original absorption coefficient data, two-thirds of the pre-processed data are randomly selected into training sets, and the rest are prediction set. The classification discriminant model is introduced. The model includes two parts: the classifier and the optimal parameter selection. The classifier selects the supervised classification method such as support vector machine, random forest and extreme learning machine, and uses the intelligent optimization algorithm such as genetic algorithm, particle swarm optimization and grid search to select the support vector machine optimal parameters. In order to reduce the original spectral data dimension and improve the computational speed of the model, Principal Component Analysis is used for preprocessing, and the results after dimensionality reduction are imported into the classification model. Considering the factors such as accuracy and running time, although the support vector machine based on particle swarm optimization has the highest accuracy rate of 98.3%, the running time is longer than 180 seconds; the ultimate learning machine can have the shortest running time of 0.2 seconds. However, the accuracy rate is 73.3%. The support vector machine based on grid search has an accuracy rate of 96% and a running time of 11 seconds. It can use a shorter time in the case of higher accuracy, and proves that the support vector machine based on grid search is better for detecting bioactive peptide. The results show that the use of terahertz time-domain spectroscopy combined with machine learning algorithms can achieve rapid and non-destructive detection of bioactive peptides, providing a new idea for the detection of bioactive peptides. It also demonstrates that THz-TDS combined with machine learning is a way better way for the identification of inconspicuous peptides.
生物活性肽是一类分子介于蛋白质和氨基酸之间, 由多种氨基酸以一定方式结合而成的二肽到多肽, 具有一定生理作用的低分子聚合物[1]。 生物活性肽相比于单个氨基酸, 更容易且更有效被人体吸收, 适合于年老体弱, 过敏体质的人群。 相比于蛋白质生物大分子, 能够发挥其整体结构所不具有的特殊功能。 具有降低血压, 抗衰老, 促进消化吸收及提高自身免疫调节能力等作用。 在功能食品, 药品, 疫苗制备等食品学和医学领域有着广泛的应用。 因此对它们的检测一直是国内外学者研究的重点。 目前国内外主要应用的分析方法为色谱法, 质谱法, 核磁共振光谱[2]。
太赫兹(Terahertz, THz)辐射是指波长在0.03~3 mm之间, 频率在0~10 THz, 介于红外和微波之内的光谱[3]。 THz波具有很好的透过性和特征光谱性质, 运用其特性可以进行物质非接触式鉴别。 多肽有其特定的氨基酸组成, 且相互之间有电偶极矩, 使其易受到太赫兹波段作用。 Kutteruf[4]等通过改变温度, 得到固相短肽链的THz吸收光谱吸收峰变化, 又通过改变肽链氨基酸的数量, 发现其吸收系数曲线变得复杂。 文献[5]报道了四种简单二肽的太赫兹吸收曲线和各自在0~2.7 THz的吸收峰, 并且通过对双甘氨肽、 丙谷二肽、 肌肤和谷胱甘肽这四种肽分子结构的分析和密度泛函理论模拟, 认为肽键的差异会导致肽类分子对太赫兹的吸收产生差别。
对于无明显太赫兹吸收峰的物质, 一般难以通过吸收系数谱进行分类识别, 需要结合机器学习算法和化学计量法进一步进行处理。 通过建立有效的分析模型与太赫兹光谱技术相结合将是这个方面的重点内容。 选择的预测模型为有监督的学习算法, 包括支持向量机[6](support vector machine, SVM), 随机森林[7](random forest, RF), 极限学习机[8](extreme learning machine, ELM)。 支持向量机的主要思想是结构风险最小化的近似实现。 但是由于支持向量机会由于数据维数过大而分类拟合效果不好等问题, 本文结合主成分分析进行降维比较。 随机森林是一种根据统计的思想, 根据决策树的判断类别得出结果的分类器, 拥有高预测精度和运算量小等特点。 极限学习机是一种针对传统单隐前馈神经网络而提出的分类模型, 有学习速度快, 泛化性能好等优点。 为了提高预测速度, 降低噪声干扰, 选择主成分分析法[9]进行对比, 主成分分析法(principal component analysis, PCA)是一种常用的可以用于降维的方法, 能够在丢失较少特征信息的前提下, 将较高维度的数据转化为较低维度的数据。 为了能寻找到支持向量机中参数的最优值, 选择网格搜索(grid search, GS), 粒子群优化(particle swarm optimization, PSO)和遗传(genetic algorithm, GA)[10]算法作为优化算法。 其中网格搜索通过穷举搜索选取最优参数; 遗传算法通过一系列内在机制, 仿照种群的进化过程, 得到适应度近似最优的状态; 粒子群算法不断调整速度和位置参数, 来寻求最优解。
本文主要利用海参肽、 牛骨肽、 鱼肽三种代表性生物活性肽的太赫兹光谱数据, 结合不同的机器学习算法, 创建分类模型。 主要以测试集预测准确率为考察标准, 以运行速度为辅助标准。 通过太赫兹光谱技术结合机器学习分类方法在生物活性肽检测领域进行探索。
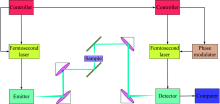
实验使用的是日本advantest公司的TAS 7500SU。 光谱范围为0.5~7.0 THz, 动态范围为57 dB, 频率分辨率为7.6 GHz。 本实验中用的是其透射模块, 其结构如图1所示。
 | 图1 太赫兹时域光谱系统Fig.1 Schematic of THz-TDS |
实验中所用的牛骨肽粉末, 海参肽粉末, 鱼肽粉末均由百德福生物科技有限公司提供, 纯度为99%, 白色粉末。 实验中为了保证测量的稳定性, 将样品在压片之前置于干燥柜中干燥6 h, 干燥柜湿度20%, 温度30 ℃。 将样品与聚乙烯按照2:1的质量比例混合, 充分研磨。 在10 MPa压力下, 压5 min, 压成厚度为(1.1±0.1) mm, 直径为13 mm的样品片, 每种多肽分别压制符合要求, 表面均匀的样品各30片。
在实验中, 以干燥空气作为参考信号, 每片样品分别在不同的位置测量3次。 为了保证结果的可重复性和精确性, 样品测完第一次之后放入干燥柜中保存24 h, 进行复测, 同样也是每片样品移动不同位置分别测量3次。 得到每片样品的吸收系数谱。
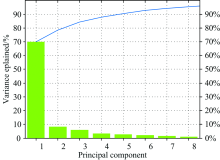
为了降低系统噪声和实验因素导致的噪声, 提高光谱的平滑性, 使用Savitzky-Golay(S-G)平滑预处理, 考虑原光谱的特性, 将平滑滤波器的拟合阶数设置为3阶, 并且考虑其平滑特性, 设置每15个点平滑一次。 由于光谱图两端噪声比较大, 选取0.5~2 THz范围内的198个光谱数据进行分析。 将数据进行标准化处理, 归一化到[0, 1]范围内。 如图2所示, 使用主成分分析法, 光谱数据降维到8维之后的贡献率之和为95%, 可以代替原光谱图。
 | 图2 PCA各成分得分Fig.2 PCA component score |
分类模型如图3所示, 其中对于支持向量机参数优化环节, 选择网格搜索、 遗传算法和粒子群算法对其参数优化。 训练模型选择的是支持向量机、 随机森林和极限学习机。 结果主要考察分类准确度和运行时间, 在确保准确率高, 大于90%的前提下, 考虑运行时间。
 | 图3 模型流程图Fig.3 Model flow chart |
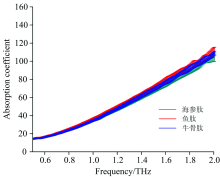
将两次测量得到的数据进行平均, 为了表示三种多肽的不确定度大小, 三种多肽在0.5~2 THz范围内的误差棒如图4所示, 从图中可以看出在低频段, 三种多肽样品几乎重叠, 难以直接区分; 在高频段, 区分度较好, 鱼肽吸收系数明显大于海参肽和牛骨肽。 从这些多肽的太赫兹吸收系数上不能很容易对其进行区分, 需要采用一些机器学习的算法。
 | 图4 海参肽、 鱼肽和牛骨肽的吸收系数误差棒Fig.4 Absorption coefficient error bars for sea cucumber peptides, fish peptides and bovine bone peptides |
将经过数据预处理后的全部样品加上标签, 随机选取四分之三数据量进行算法训练, 其余数据用来进行测试。
为了找到分类三种多肽最好的算法, 采用不同的机器学习方法进行对比验证, 图5(a)为网格搜索加5折交叉验证法的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为8, 核函数参数g的最优值是0.125, 训练集准确率81.1%, 测试集准确率95%, 用时11.7 s。
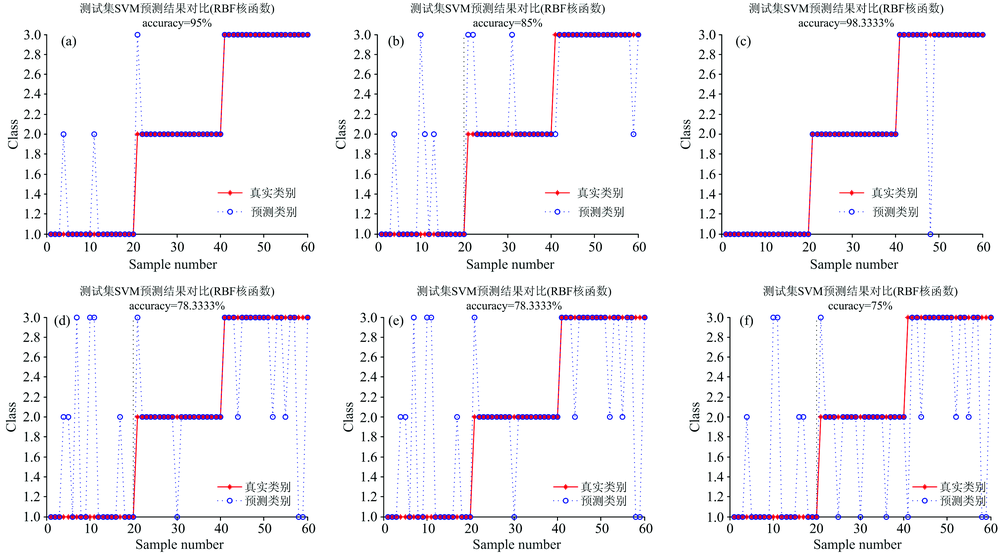 | 图5 不同优化方法下支持向量机分类结果 (a): GS-SVM; (b): GA-SVM; (c): PSO-SVM; (d): PCA-GS-SVM; (e): PCA-GA-SVM; (f): PCA-PSO-SVMFig.5 SVM classification results under different optimization methods (a): GS-SVM; (b): GA-SVM; (c): PSO-SVM; (d): PCA-GS-SVM; (e): PCA-GA-SVM; (f): PCA-PSO-SVM |
图5(b)为遗传算法寻优加5折交叉验证法的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为0.79, 核函数参数g的最优值是356.3, 训练集准确率63.9%, 测试集准确率85%, 用时152.8 s。
图5(c)为粒子群寻优加5折交叉验证法的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为83.44, 核函数参数g的最优值是0.01, 训练集准确率82.2%, 测试集准确率98.3%, 用时180.8 s。
图5(d)为主成分分析结合网格搜索下的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为1.414, 核函数参数g的最优值是2, 训练集准确率73.3%, 测试集准确率78.3%, 用时6.27 s。
图5(e)为主成分分析结合遗传算法下的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为1.543, 核函数参数g的最优值是2.2, 训练集准确率81.7%, 测试集准确率78.3%, 用时41.9 s。
图5(f)为主成分分析结合粒子群算法下的支持向量机模型结果, 结果表明, 向量机惩罚因子C的最优值为1.5, 核函数参数g的最优值是1.7, 训练集准确率82.2%, 测试集准确率75%, 用时65.3 s。
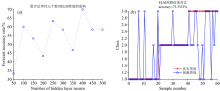
建立随机森林模型, 经过多次试验, 综合考虑准确率和运行时间, 参数选择如图6(a)所示, 最优的决策树个数为400, 准确率达到最优准确率, 时间最短。 随机森林模型本身自带降维的能力, 无需进行降维处理, 结果如图6(b)所示, 准确率为86.6%。
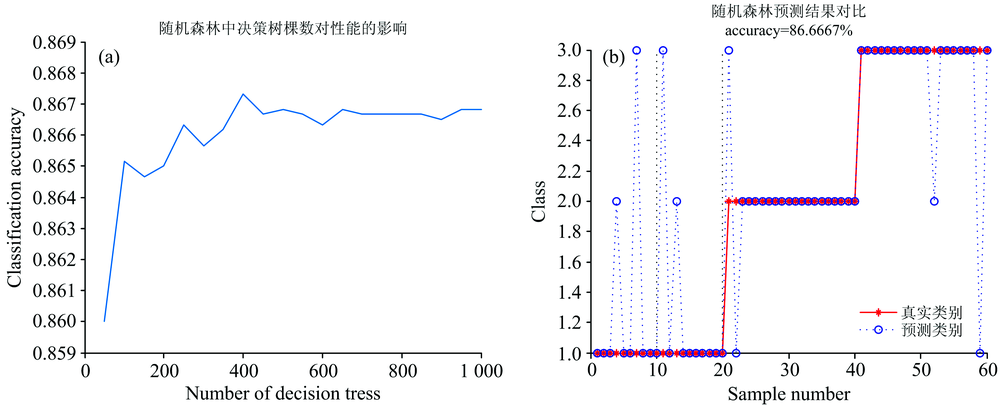 | 图6 随机森林分类结果 (a): 最优参数选择; (b): RF分类结果Fig.6 The classification result of RF (a): Optimal parameter selection; (b): RF classification results |
建立极限学习机模型, 经过多次试验, 综合考虑准确率和运行时间, 参数选择如图7(a)所示, 最优的隐含层神经元个数为400, 准确率达到最高。 极限学习机结果如图7(b)所示, 准确率为73.3%。
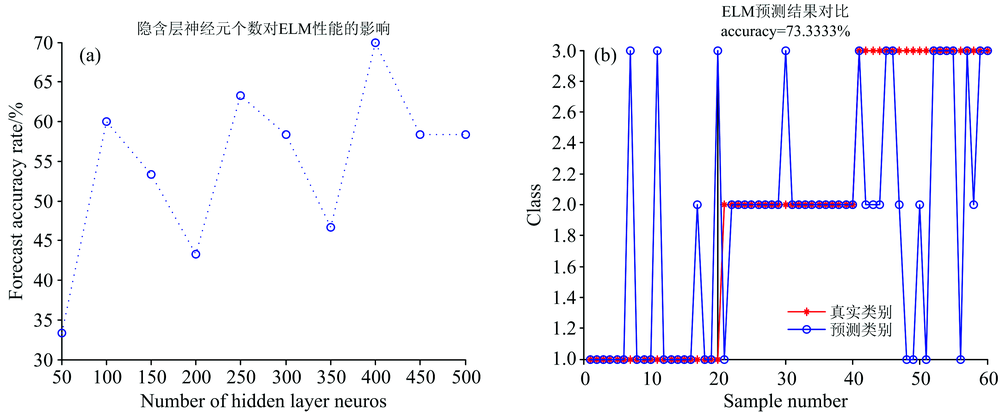 | 图7 ELM分类分类结果 (a): 最优参数选择; (b): ELM分类结果Fig.7 The classification result of ELM (a): Optimal parameter selection; (b): ELM calssification results |
表1给出了多种分类方法的预测精度和运行时间。 从表1看出, 数据进行PCA预处理之后, 测试集的准确率较未进行预处理有所下降, 但是运行时间也加快。 通过比较三种监督机器学习算法, 准确率最高的是支持向量机, 但是运行时间最快的是极限学习机。 准确率最高的是基于粒子群算法的支持向量机分类, 为98.8%(59/60)的准确率。 运行时间最短的是极限学习机, 只需要0.2 s。 但是, 在综合考虑测试集准确率和运行时间的情况下, 最适合分类这三种多肽的算法是基于网格搜索的支持向量机, 准确率为95%(57/60), 运行时间是11.7 s。
| 表1 建模方法对预测结果的影响 Table 1 The impact of modeling methods on forecasting results |
以牛骨肽, 海参肽, 鱼肽三种生物活性肽为研究对象, 验证了太赫兹时域光谱技术对其定性分析中的应有潜力。 为了更好的对其进行区分, 利用这些多肽的吸收光谱信息结合机器学习算法, 并且比较数据在PCA降维之后和未降维的分类对比情况, 得出最适合分类这些多肽的分类算法。 结果证明, 使用网格搜索的支持向量机结合太赫兹时域光谱技术, 可以实现对多肽的高效鉴别, 有望促进太赫兹时域光谱技术在生物医学检测领域的应用。
致谢: 感谢百德福生物科技有限公司对样品的支持, 以及莱仪特太赫兹(天津)科技有限公司提供太赫兹系统。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|