
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于SIMCA-SVDD方法的分子光谱分析及其在食用油分类中的应用
[赵众1, *  , 李彬
, 李彬1 , 吴妍娴1 , 袁洪福2 ]
, 李彬|
|


食用油是日常生活中的必需品。 市场上食用油在成分、营养价值及价格上有很大的不同。 为避免欺诈行为, 亟需建立一套有效的市场销售的食用油品质分类方法。 常规的食用油检测方法速度慢而且需要复杂的实验室预处理过程。 分子光谱从分子水平上反映了物质的组成与结构信息, 分子光谱分析速度快而且是无损监测, 因此分子光谱分析结合化学计量学的方法正成为食用油分类方法的趋势。 SIMCA(Soft Independent Modeling of Class Analogy)是应用广泛的分子光谱分析方法, 然而在SIMCA中使用欧氏距离于对基于PCA和F检验提取的特征进行分类, 难以区分不规则的特征空间。 由于食用油样本分子光谱差别细微, 通常难以用SIMCA方法进行分类。 SVDD(Support Vector Domain Description)算法是一类基于支持域的非线性单类分类方法, SVDD利用求解凸二次规划得出一个尽可能包含所有目标样本的最小超球体进行分类。 本文提出了一种基于SIMCA-SVDD方法的分子光谱分析方法并用于食用油的快速分类。 为鉴别不同种类的食用油, 在ATR-FTIR光谱仪上扫描四种食用油的红外光谱。 应用SIMCA方法提取分类特 T2和 Q, 由于提取的特征 T2和 Q分布的不规则性, 不同于SIMCA中的欧氏距离, 本文采用SVDD用于对提取的不规则特征进行分类。 由于SVDD能通过映射函数将分类特征映射到高维空间, 因此可以通过求解凸二次规划来训练最优的分类超球面对分类特征进行分类。 采用本文所提的SIMCA-SVDD方法及传统的SIMCA方法, 对同样的样本进行了对比实验。 对比实验证实了本文所提的SIMCA-SVDD方法具有比传统的SIMCA方法更好的分类结果, 所提的方法为实现基于分子光谱进行食用油快速分类提供了一条新的途径。
Biography: ZHAO Zhong, (1970—), Professor, College of Information Science and Technology, Beijing University of Chemical Technology
Edible oil is a necessity in daily life. The nutritional value and price of different types of edible oils on the market vary a lot. Because of the spurious activities in the market, it is necessary to establish effective detection methods to classify the quality of the edible oils in the market. Traditional edible oil classification methods are usually time-consuming and requiring complex pre-treatment in the lab. Molecular spectroscopy can elucidate the sample information of both compositions and properties at the molecular level, and molecular spectra analysis has the advantages of fast speed detection and non-destructive testing for edible oil classification. Molecular spectra analysis combined with the chemometrics is becoming a popular method for rapid classification of edible oil. SIMCA (Soft Independent Modeling of Class Analogy) is widely applied to molecular spectra analysis. However, the Euclidean distance is used in SIMCA to classify the extracted features with PCA and F test. Therefore it is difficult to classify the irregular feature spaces. When the molecular spectral differences among the different types of samples are tiny such as edible oils, it is usually difficult to identify them with the traditional SIMCA method. SVDD(Support Vector Domain Description)algorithm is a support domain method for solving the one-class classification problem. SVDD can get a hypersphere to include as many objective samples as possible by solving the convex quadratic programming problem. In this work, a method of molecular spectra analysis based on SIMCA-SVDD method for rapid classification of edible oils is proposed. In order to accomplish recognition of the different types of edible oils, the attenuated total reflectance infrared spectra of four types of edible oil are scanned on ATR-FTIR. SIMCA is applied to extract the classification features T2 and Q. Since the extracted edible oil classification features T2 and Q distribute irregularly, instead of classification with Euclidean distance in SIMCA, Support Vector Domain Description (SVDD) is applied in this work to classify the extracted features. Since SVDD can map the extracted classification features to high dimensional space by mapping functions, then an optimal classification hypersphere can be trained to classify the irregular distributing feature spaces by solving the convex quadratic programming problem. Comparative experiments to identify the same molecular spectra samples with the proposed SIMCA-SVDD method and the SIMCA method have also been done. Comparative experiment results have verified that the classification results with the proposed SIMCA-SVDD method are obviously better than that with SIMCA. The proposed SIMCA-SVDD method has provided a new way to classify the edible oil rapidly based on molecular spectra analysis.
Edible oil is a necessity of daily life. There are many kinds of edible oil such as the peanut oil, rapeseed oil, soybean oil, corn oil, tea seed oil, sesame oil and olive oil in the market. The nutritional value and prices of different types of edible oils vary a lot according to their composition change. In order to avoid market fraud, it is necessary to establish an effective detection method to classify edible oils. There are some methods that have been reported to detect the quality of edible oil[1, 2]. However, these detection methods are usually time-consuming and requiring complex pre-treatment. Spectral analysisbased detection methods[3, 4] have been developed to analyze the edible oils with the advantages of fast speed and non-destructive testing.
SIMCA (Soft Independent Modeling of Class Analogy)[5] is the widely applied method to molecular spectra analysis and chemometrics. In SIMCA, PCA and F test are used to extract T2 and Q as the classification features. Then, Euclidean distance is used to classify the extracted features. The range defined by Euclidean distance, which is a circle in the plane of T2vs Q, can not accurately classify the extracted features distributing in irregular feature spaces. Support Vector Domain Description (SVDD)[6] is a supervised machine learning method based on SVM theory. SVDD can map the nonlinear feature data to the high-dimensional space with different kernel functions. A closed and compact sphere can be optimized to classify the nonlinear feature data. Since SVDD can be optimized with the distribution of the classification data, it can be used to classify the irregular feature spaces[7, 8]. In this work, a method of molecular spectra analysis based on SIMCA-SVDD method for rapid classification of edible oil is proposed. Comparative experiments to identify the same samples with the proposed SIMCA-SVDD method, and SIMCA have also been done. Comparative experiment results have verified that the classification results with the proposed SIMCA-SVDD method are obviously better than that with SIMCA.
SIMCA is a supervised pattern recognition method, PCA is applied to decompose sample matrix of each class as
where
where E is residual matrix. The fraction of the total variation can be estimated as
where PRESS is the sum of squares of the prediction errors and SS is the sum of squares of the residuals of the previous component. According to selected A components, the Hotelling T2 for observation i is calculated as
where
where v is correction factor, eik denotes the residuals value of the ith score value and the kth loading value in the correction set, K is the number of load vector and Fcrit is the critical value of F test.
In this work, SVDD instead of Euclidean distance is applied to classify the extracted features
where C is the penalty coefficient and ξ i is a relaxation factor. According to Eq. (8), the Lagrangian function is defined as
where α i(α i≥ 0) and γ i(γ i≥ 0) are Lagrangian multipliers. The class center of the sphere a and the radius R can be obtained by solving MaxMinL(R, a, ξ i, α i, γ i). According to Eq.(9), there are
Substituting Eq.(10), Eq.(11) and Eq.(12) into Eq.(9), there is
Use kernel function to replace the inner product in Eq.(13) and maximize L, then
According to Eq.(14) and defined C, α can be solved for every feature sample. The radius R can be calculated as
where p is the support vector. For multi-classification, the relative distance is defined as
According to the minimum Di in Eq.(16), the feature samples are classified.
54 edible oil samples are provided by the National Institute of Metrology (NIM) of China, which belong to four types of edible oil. 43 samples are chosen as the calibration set and the remaining 11 samples are chosen as the validation set with the Rank-KS method[9]. The number of calibration set and validation set for each types of samplesis shown in Table 1.
| Table 1 Statistics of samples |
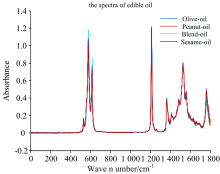
The infrared spectra of the samples are scanned by Attenuated Totalinternal Reflectance Fourier Transform Infrared (Agilent 5500) spectrometer. The spectra are collected from 650 to 4 000 cm-1 with a resolution 4 cm-1and with 32 scans. Each sample is scanned three times and the average is used for analysis. The spectra of all samples measured on ATR instrument are shown in Fig.1.
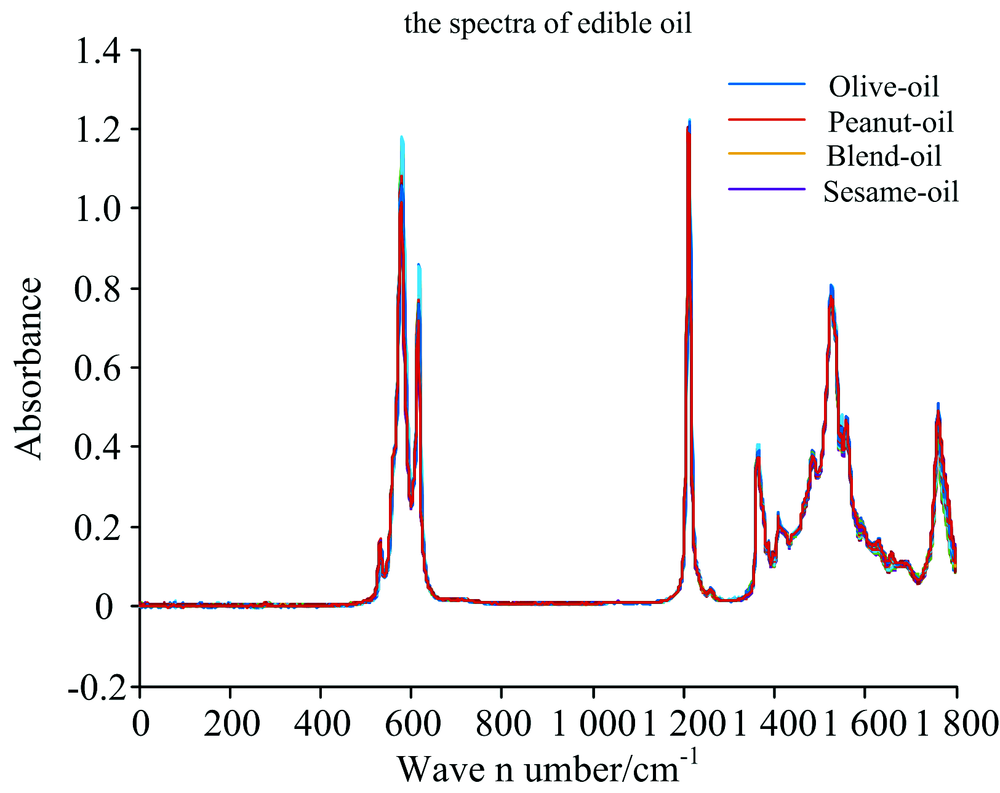 | Fig.1 Original spectrum of four types of oil samples measured on ATR spectrometer |
All data have been analyzed with MATLAB 2017a (The Mathworks Inc.).
Eliminate the side effects of surface scattering and the change of optical path on infrared diffuse reflection spectra, and spectral mean centeringis applied to the spectral data.
Correct classification rate (CCR) is applied to evaluate the qualitative recognition results[9].
PCA is applied todecompose the preprocessed spectra samples. According to PRESS, cross validation is used to determine the number of principal components. Then, the classification features of
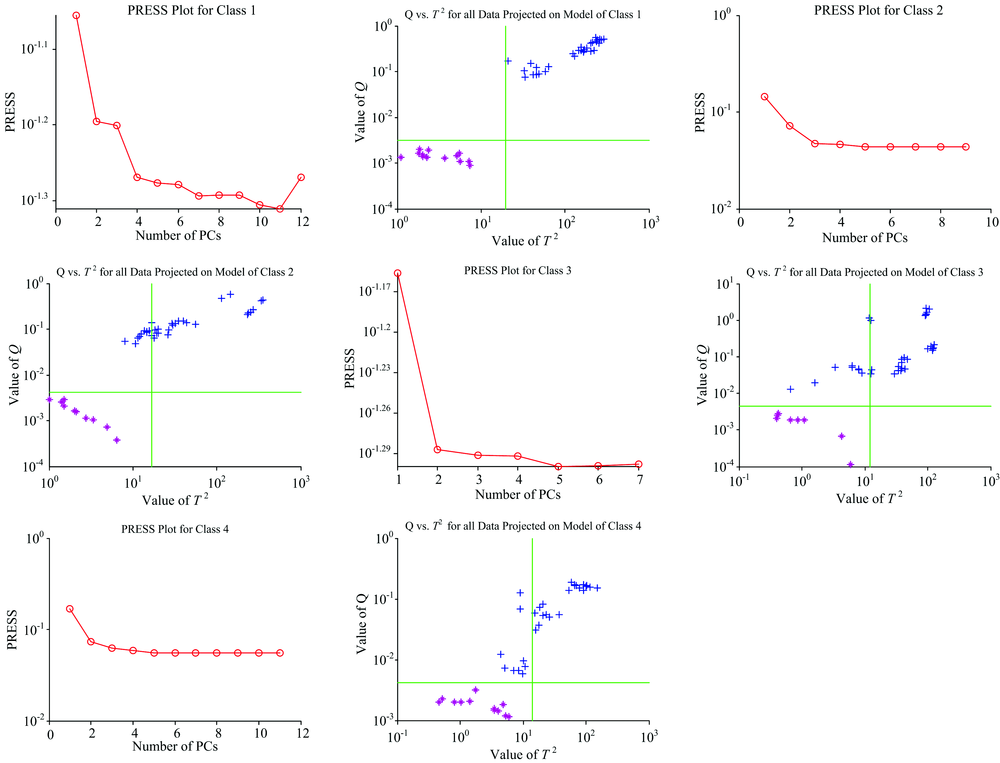 | Fig.2 PRESS and Q-T2 distributions for the spectra samples |
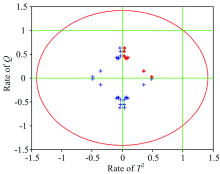
The Euclidean distance discrimination for blended oil samples is shown in Fig.3. Euclidean distance discrimination in SIMCA treats the classification features
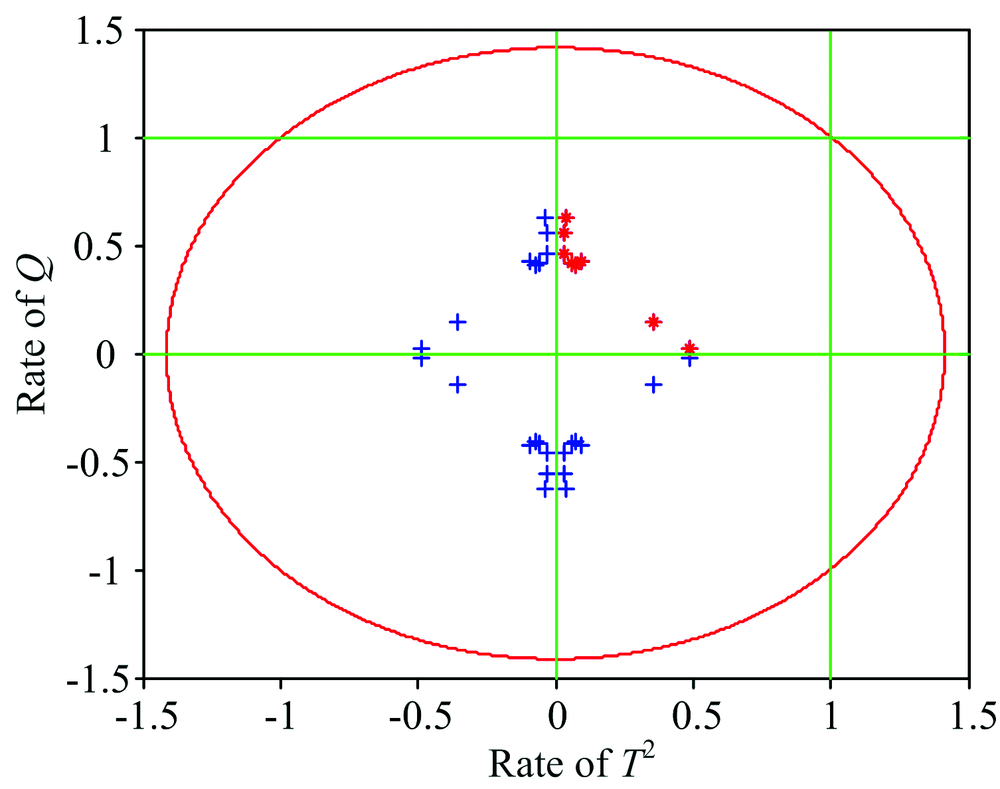 | Fig.3 Euclidean distance discrimination for blended oil samples |
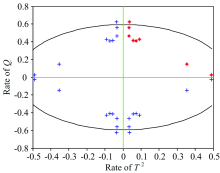
In this work, the radial basis function (RBF)is applied in SVDD to classify the features
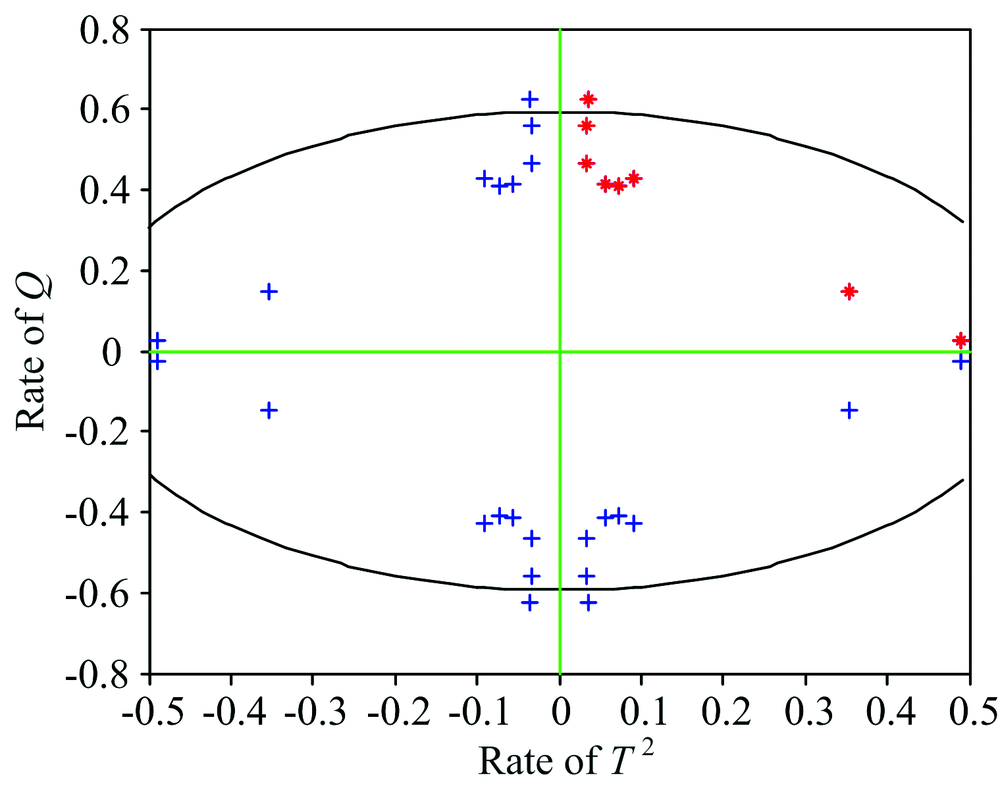 | Fig.4 SVDD discrimination for blended oil samples |
The comparative experiments for edible oil classification based on molecular analysis with SIMCA and proposed SIMCA-SVDD have been done. The classification results are shown in Table 2. According to Fig.2, it is noticed that the extracted edible oil features based on molecular spectra analysis with SIMCA are different. Then, the extracted features can be used for classification. But, the extracted features based on molecular spectra analysis with SIMCA are not always linear separable. The discrimination area for feature spaces with Euclidean distance in SIMCA is a circle, and then it is difficult to classify the irregular feature spaces such as the linear inseparable feature spaces. SVDD can map the linear inseparable feature data to a high-dimensional space with kernel tricks. Then, the minimum hypersphereis trained with SQP to include as many class samples as possible. According to the comparative experiments, the blended oil samples in the validation set can be recognized with SIMCA-SVDD accurately.
| Table 2 Classification results of SIMCA and SIMCA-SVDD |
For SIMCA, the decision plane is a circle, and its indicator is the radius in which Judging indicator is too single. After the features are extracted, the characteristic distribution rules of single oil can be distinguished within the regular area. However, for mixed oil, changes in its composition lead to irregularities in the decision plane. The SIMCA-SVDD method can change the irregular decision area by the parameters of the kernel function, so better classification results are achieved.
In this work, a method of edible oil classification based on molecular spectra analysis with SIMCA-SVDD is proposed. The IR spectra of four types of edible oil are scanned on ATR-FTIR. For a single oil sample, SIMCA and the proposed SIMCA-SVDD method can better classify the sample. However, due to changes in the composition of the mixed oil and changes in the content of the components, SIMCA does not distinguish well between the mixed oil and the single oil. SIMCA-SVDD!can correctly distinguish mixed oils in many samples. SIMCA is applied to extract the classification features T2 and Q. Instead of classification with Euclidean distance in SIMCA, SVDD is applied in this work to classify the extracted linear inseparable features. The comparative experiment results have verified that the proposed method had a better classification of edible oils than the traditional SIMCA method. The proposed method has provided a new way to classify the edible oil rapidly based onmolecular spectra analysis.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|