


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
X射线荧光光谱结合判别分析识别进口铁矿石产地及品牌
[张博1, 2  , 闵红
, 闵红2 , 刘曙2, * , 安雅睿1, * , 李晨2 , 朱志秀2 ]
, 闵红, 安雅睿, 李晨|
|


作者简介: 张 博, 1993年生, 上海理工大学理学院化学系硕士研究生 e-mail: 850824265@qq.com
铁矿石是钢铁工业的重要原材料, 不同产地、 品牌的进口铁矿石在元素组成、 含量上存在差异, 进口铁矿石掺杂、 掺假、 以次充好等现象虽集中于个案, 却危害经济安全。 故建立主要进口国铁矿石产地与品牌的快速识别模型, 对支撑进口铁矿石的风险监管, 保障贸易便利化。 该研究对象为澳大利亚、 南非、 巴西3个国家共14个品牌的236份进口铁矿石样品, 包括皮尔巴拉混合粉(块)、 杨迪粉铁矿, 纽曼混合粉(块)铁矿、 津布巴混合粉铁矿、 国王粉、 弗特斯克混合粉、 昆巴标准粉(块)、 卡拉加斯铁矿石等。 应用波长色散-X射线荧光光谱无标样分析法测定所有研究样品的元素组成及含量, 检出元素包括Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, K, S, Cr, Na, Sr, Zr, Zn, V, Cu, Gd, Ba, Cl, Ni和Co, 共计24种, 选择其中Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, Cr和S共12种所有样品全部检出的元素进行判别分析。 采用逐步判别法筛选出Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S共10个元素含量作为有效变量, 建立二维Fisher判别模型, 实现对澳大利亚、 南非、 巴西进口铁矿石的识别, 模型对建模样品识别正确率为97.40%, 交叉验证正确率为95.30%, 对测试样品的识别正确率达到95.50%。 针对14种品牌铁矿石, 使用Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S共10种元素含量, 建立十维Fisher判别模型, 模型对建模样品识别正确率为100%, 交叉验证正确率为97.90%, 对测试样品的识别正确率达到100%。 波长色散-X射线荧光光谱无标样分析虽然是一种半定量分析方法, 但分析快速, 稳定性好, 该方法结合逐步判别-Fisher判别分析, 能实现对铁矿石产地与品牌的识别。
Iron ore is an important raw material for the iron and steel industry. Imported iron ore with different origins and brands varies in elemental composition and content. Phenomena such as doping, adulteration and shoddy of imported iron ore are endangering the national security and economy safety, so it is necessary to establish a rapid identification model of the origin and brand of imported iron ore in major importing countries, can support the risk supervision of imported iron ore, and ensure trade facilitation. The research objects of this paper are 236 imported iron ore samples from 14 brands in Australia, South Africa and Brazil, including Pilbara Blend Fines (Lumps), Yandi Fines, Newman Blend Fines(Lumps), Jimblebar Blend Fins, Kings Fines, Fortescue Blend Fines, Kumba Standard Fines (Lumps), and Carajas Iron Ore, etc. The elemental composition and content of all research samples were determined by wavelength dispersive X-ray fluorescence spectrum standard-less analysis method, and it turned out that elements detected from iron ore samples are 24 in total, including Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, K, S, Cr, Na, Sr, Zr, Zn, V, Cu, Gd, Ba, Cl, Ni, and Co. Among them, we chose 12 elements and conducted a stepwise discriminant-Fisher discriminant analysis modeling, including Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, Cr, and S. Moreover, 10 elements including Fe, O, Si, Ca, Al, Mn, Ti, Mg, P, S were screened out as valid variables by the stepwise discriminant method. A two-dimensional Fisher discriminant model was thus established to realize the identification of imported iron ore from Australia, South Africa and Brazil. The recognition accuracy of the model for the modeled sample was 97.40%, the one of cross-validation was 95.30%, and that of the test sample reached 95.50%. For the 14 brands of iron ore, 10 elements including Fe, O, Si, Ca, Al, Mn, Ti, Mg, P, and S were used to establish a ten-dimensional Fisher discriminant model, and its recognition accuracy for the modeled sample was 100%. The accuracy of cross-validation was 97.90%, while one of the test samples reached 100%. Although wavelength dispersion X-ray fluorescence spectrum standard-less analysis method is a semi-quantitative analysis method, the analysis is fast and stable, wavelength dispersive X-ray fluorescence spectrum standard-less analysis method together with the stepwise discriminant-Fisher discriminant analysis can realize the identification of importing countries and brands of iron ore.
铁矿石是钢铁工业的重要原材料, 不同产地来源的铁矿石由于地质成因差异, 主次元素含量存在一定区域特征。 中国是全球最大的铁矿石进口国, 2017年进口量超过全世界海运铁矿石贸易量的75%。 进口铁矿石中不泛存在掺杂、 掺假、 以次充好的现象, 虽然集中于个案, 但对我国国门安全, 经济安全的危害不容小觑。 澳大利亚、 巴西、 南非是全球铁矿石最主要的出口国, 涉及国际大型矿业集团数十种品牌铁矿石。 品牌铁矿石批次多、 数量大、 质量相对稳定。 品牌铁矿石的识别, 可支撑进口铁矿石的风险监管, 保障贸易便利化。
可见光-近红外光谱、 微波介电光谱、 激光诱导击穿光谱[1, 2, 3]结合化学计量学或机器学习, 可实现不同种类铁矿石的识别。 波长色散-X射线荧光光谱具有制样简单、 无损分析、 稳定性好、 灵敏度高等优点, 能实现铁矿石中主次元素的快速测定, 在海关系统应用非常广泛, 有利于进口铁矿石的快速通关。 孟海东[4]、 Navid Khajehzadeh[5]等分别应用X射线荧光光谱结合神经网络, 实现铁矿石与铜矿石、 赤铁矿与磁铁矿的识别。 判别分析是一种多变量统计分析方法, 逐步判别能实现有效变量筛选, 特别是变量间相关系数较大时, 能剔除不合适的变量, 从而提高判别准确率。 武素茹等[6]以67个已知国别铁矿石样本X射线荧光光谱无标样分析数据为基础, 采用逐步判别法筛选出CaO, MgO, Al2O3, CuO, V2O5五个特征变量, 利用非参数判别方法建立进口国别的判别模型, 准确率为74.6%。 至目前为止, 尚没有参数判别分析方法在不同铁矿石识别中的报道。
澳大利亚、 巴西、 南非作为全球铁矿石最主要的出口国, 主要铁矿产区相对集中。 如: 澳大利亚90%的铁矿石资源量和产量都来自于西澳洲皮尔巴拉克拉通的哈默斯利成矿省, 主要铁矿床包括芒特维尔贝克、 汤姆普莱斯山、 帕拉伯杜等, 它们均产于元古宙早期布罗克曼BIF型含铁建造中[7], 这些矿床产出了PB粉、 PB块、 杨迪粉、 纽块、 纽粉、 津布巴粉、 国王粉(见表1)等知名铁矿石品牌。 由于地质成因相似, 与产地国别的识别相比, 同一国家不同品牌铁矿石的识别更有难度。 目前亦未有进口品牌铁矿石识别方法的报道。
| 表1 铁矿石样品信息 Table 1 The information of iron ore samples |
在全国主要铁矿石进口口岸采集了来自澳大利亚、 巴西、 南非的14种品牌铁矿石, 236批进口铁矿石代表性样品(见表1)。 采用波长色散-X射线荧光光谱无标样分析法共计检出24种元素, 选择236批样品全部检出的12种元素含量用于判别分析, 逐步判别法筛选出其中10种元素含量作为特征变量, 采用 Fisher判别分析建立了针对进口铁矿石产地和品牌的判别模型, 讨论了不同品牌铁矿石的化学成分差异, 通过建模样品验证、 交叉验证、 测试样品验证, 确证了模型的准确性和适用性。
根据GB/T 10322.1— 2014《铁矿石取样和制样方法》, 从我国主要的铁矿石进口口岸采集并制备来自澳大利亚、 南非、 巴西3个国家的进口铁矿石化学分析样品, 包含14个品牌的共计236批次样品。 样品容量大、 种类丰富, 有一定的独立性、 代表性, 包含了我国进口铁矿石主要来源国及主流品牌矿种。 样品信息如表1所示, 所在矿区及位置如图1所示。
 | 图1 品牌铁矿石分布图Fig.1 Distribution map of brand iron ore |
将样品分装到干燥瓶中于105 ℃下烘干4 h。 采用压片机对烘干样品进行压片, 压片前用乙醇清洗模具, 使用聚乙烯环使粉末样品聚拢, 压制样品在30 t压力下维持30 s。 检查压制样品表面均匀且无裂纹、 脱落现象, 测量前用洗耳球吹净样品表面。
使用德国布鲁克公司S4 Pioneer波长色散-X射线荧光光谱仪中的无标样分析方法检测铁矿石中元素的含量。 无标样分析也称半定量分析, 它的基本思路是由仪器和软件制造商测定校准样品, 储存元素谱线强度和校准曲线, 然后将这些数据转到用户的X射线荧光分析系统中, 并用参考样品校正仪器的漂移, 无标样分析法最大的优点是快速。 检测中使用铑靶光管, 四个分析仪晶体(LiF200, XS-55, PET和Ge), 流气计数器(FC), 闪烁计数器(SC)等元件。 表2列出了仪器的部分测量条件。
| 表2 仪器测量条件 Table 2 Instrument measurement conditions |
逐步判别分析属于有监督的分类方式, 先对已知的样品进行分类来建立模型, 再对未知样品来进行预测分类。 其中一个重要的思想就是逐步引入变量, 每次只引入一个变量, 同时也检验先前引入的变量; 如果引入的新变量导致之前变量的判别能力不再显著, 就将先前引入的变量从判别式中移除, 筛选至判别式中的变量都很显著[8]。
Fisher判别的基本原理是投影, 将高维数据投影到某个方向, 使得组与组之间区别最大, 组内的区别最小, 其判别函数的建立利用了方差分析的思想[9]。 根据该原则确定判别式, 将一未知样品的变量代入判别式。 根据判别函数和组质心处坐标函数, 计算每个样品坐标与质心的距离, 与哪个类别的质心最近, 该样品就判定为哪个类别。
本文分析来自我国主要铁矿石进口口岸的14个品牌共计236个铁矿石样品, 建模过程中选取191个样品作为训练集, 45个样品作为验证集检验模型的准确性。 训练样品及测试样品的选取如表1所示。
针对采集的236个铁矿石样品, 采用波长色散-X射线荧光光谱无标样分析共计检出Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, K, S, Cr, Na, Sr, Zr, Zn, V, Cu, Gd, Ba, Cl, Ni和Co共24种元素, 其中K, Cu, Zr, Zn, Na, Cl, V, Sr, Gd, Ni, Ba和Co共12个元素含量存在未检出的情况, 未检出比例分别为18.20%, 50.00%, 51.00%, 69.90%, 70.30%, 73.30%, 78.00%, 83.90%, 84.30%, 91.50%, 92.80%和97.00%, 建立铁矿产地及品牌的识别模型, 在满足实际应用的前提下, 应选择铁矿样品检出比例尽量高的元素, 本文选取236个样品全部检出的Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, Cr和S共12种元素含量用于后续分析。
针对不同进口国家、 品牌铁矿石的模式识别, 采用逐步判别分析对Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, Cr和S共12个元素含量进行变量筛选, 变量能否进入模型主要取决于协方差分析的F检验的显著性水平, 当F值大于指定值时保留该变量, 而F值小于指定值时, 该变量从模型中剔除。 选取合适的F值可以用最少的变量达到最佳的判别效果。 本文选取的F值为3.84, 经过逐步判别分析, Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S共10个元素保留在了模型中, Tb与Cr因未通过F检验(F值< 3.84)而从模型中剔除[10], 最终10个元素用于建立识别模型。
14种品牌铁矿石12个元素(Fe, O, Si, Ca, Al, Mn, Tb, Ti, Mg, P, Cr, S)含量的均值对比分析(图2)表明: 澳精粉Fe, Si和O含量与其他类别有显著差异, 巴西粉和混合粉的Si, Mn含量与其他类别有显著差异, 南非精粉Ca, Ti, Mg, P和S的含量明显高于其他类别, 不同类别铁矿石之间的Al, Mn, Mg, P和S的含量也存在明显的差异。 因此可以利用不同元素的含量组合建立线性判别模型, 对铁矿石进口国别、 品牌进行识别。 不同品牌铁矿石Tb和Cr含量的平均值在直方图上差异性不大, 这也解释了逐级判别分析将这两个元素剔除的原因。
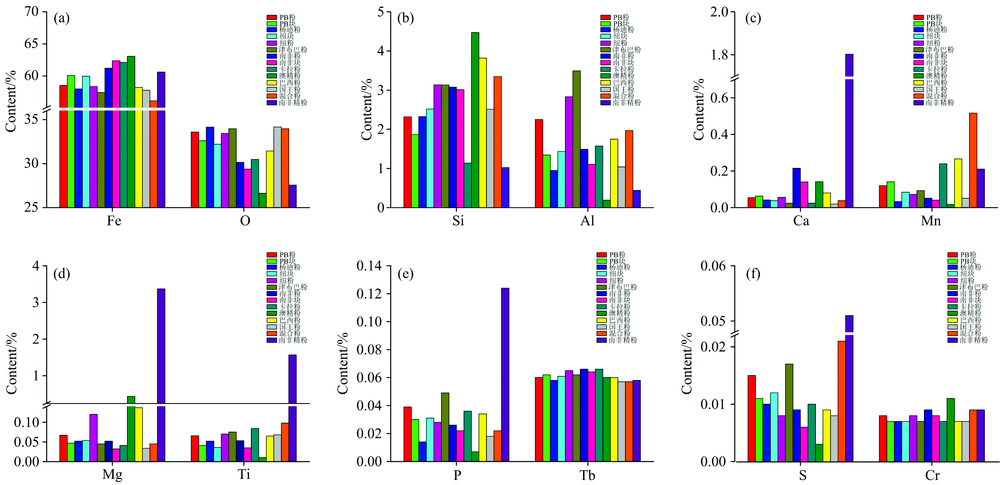 | 图2 铁矿石样本的元素平均含量条形图 (a): Fe, O; (b): Si, Al; (c): Ca, Mn; (d): Mg, Ti; (e): P, Tb; (f): S, CrFig.2 Bar chart of element average content in iron ore samples (a): Fe, O; (b): Si, Al; (c): Ca, Mn; (d): Mg, Ti; (e): P, Tb; (f): S, Cr |
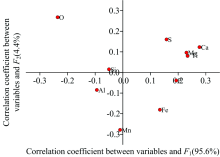
使用Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S共10个元素含量建立Fisher判别模型, 得到2组判别函数和相应的组质心处的坐标。 判别函数与各变量之间的相关性如图3所示, 横坐标为函数1(F1)与各变量的相关系数, 纵坐标为函数2(F2)与各变量的相关系数, 系数为正表示正相关, 系数为负表示负相关, 绝对值越大相关性越高。 Ca, O, Ti, Mg, P各元素含量与函数1(F1)的相关系数分别为0.277, -0.236, 0.234, 0.230, 0.193, Mn, O, Fe, S各元素含量与函数2(F2)的相关系数分别为-0.279, 0.268, -0.181, 0.160, 是相关性相对较大的元素。
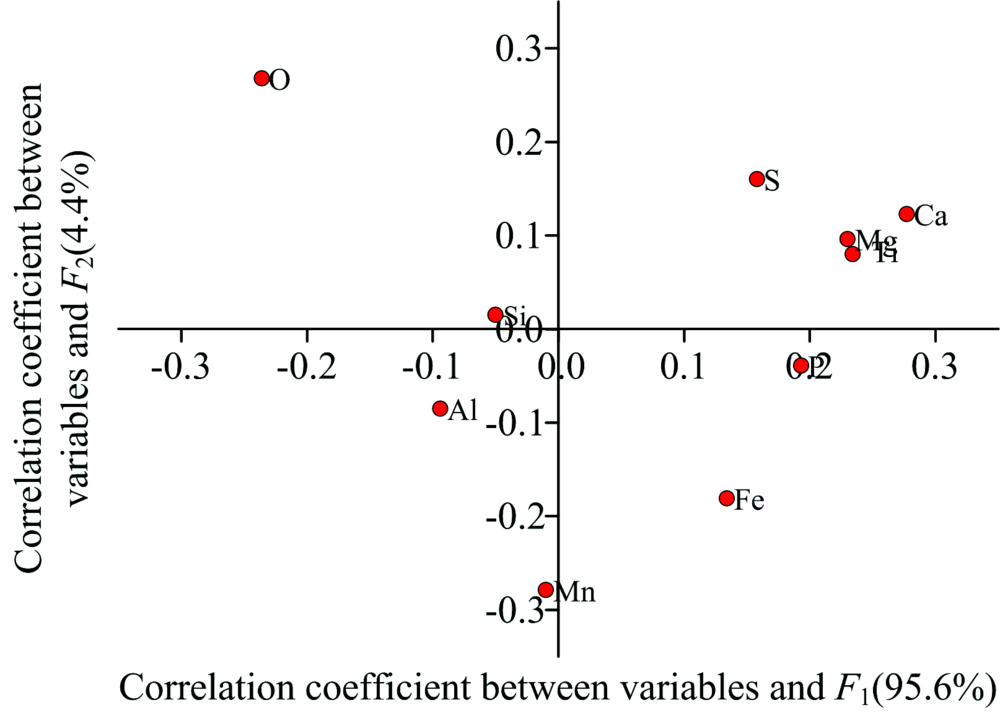 | 图3 变量与判别函数间的相关性Fig.3 Correlation between variables and discriminant functions |
判别函数:
F1=0.525X1-0.598X2+1.4X3+32.627X4+0.654X5-3.936X6+37.01X7-29.4X8-58.953X9-24.002X10-16.337
F2=0.569X1+0.855X2+0.122X3+7.559X4+1.23X5-4.789X6-9.846X7+4.281X8-128.56X9+147.622X10-61.555
式中X1— X10分别代表Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S的含量。
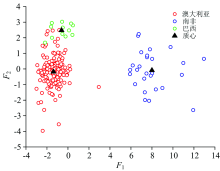
用函数1和函数2的判别得分作散点图(图4), 横坐标为函数1得分, 纵坐标为函数2得分, 可以看出模型对南非铁矿石和澳大利亚, 巴西两个国家的铁矿石区分明显, 澳大利亚与巴西散点存在重叠交叉的现象。
 | 图4 判别函数得分散点图Fig.4 Discriminant function decentralized point map |
建模样品为构建模型所用的样品, 可以回代到模型, 验证模型识别的准确性。 交叉验证是一种重要的判别效果验证方法, 该法可以非常有效地避免强影响点的干扰。 本文采用留一交叉验证法对建模所用的样品进行验证, 每次留出一个作为验证, 其余用来建模, 最后计算平均准确率作为对模型的评价。 测试样品为建模过程中预留的用于测试模型识别正确率的样品。 该模型对建模样品分类正确率为97.40%, 对南非的铁矿石样品识别正确率为100%, 对澳大利亚、 巴西铁矿石样品存在识别错误的情况, 正确率分别为97.40%, 91.70%。 模型交叉验证正确率为95.30%, 交叉验证的正确率高于80%, 说明该模型有很好的分类准确度。 为了确定模型是否可以对未包含在模型中的样品进行识别, 分析了建模时选择的45个作为测试样品的铁矿石样品, 模型对测试样品识别正确率达到95.50%, 其中对南非和巴西样品识别正确度都达到100%, 说明此模型可以对铁矿石的国别进行很好的识别[11]。
与进口铁矿石国别的识别相比较, 进口铁矿石品牌的识别更加具有难度, 因为不同品牌的铁矿石可能会来自相同国家相同的矿区, 它们物相结构一致, 元素含量的差异性也有可能不大。 在对铁矿石国别已能进行很好识别的基础上, 尝试对铁矿石品牌做进一步识别。 采用Fe, O, Si, Ca, Al, Mn, Ti, Mg, P, S10个元素含量建立Fisher判别模型, 得到10个判别函数和相应的组质心处的坐标。
判别函数:
F1=0.286X1-0.372X2+0.404X3-9.8X4-0.575X5-2.551X6+54.081X7+18.203X8-95.378X9-17.295X10-12.937
F2=0.726X1-1.244X2+2.718X3-2.715X4-0.808X5-5.169X6-23.321X7+15.246X8-160.116X9-18.187X10-2.608
F3=0.587X1-1.372X2+1.45X3+8.922X4+3.122X5+3.139X6+9.551X7-15.179X8+180.272X9+21.586X10-4.251
F4=0.257X1-0.263X2+0.896X3+33.291X4-1.573X5+1.075X6+37.848X7-34.022X8-62.815X9+25.649X10-6.865
F5=-0.4X1-0.453X2+1.121X3-13.49X4-1.417X5+11.016X6+9.278X7+0.466X8+19.539X9+87.158X10+35.004
F6=-0.012X1+0.213X2+1.171X3+6.748X4+2.843X5-6.586X6+12.703X7-2.634X8-138.53X9-59.512X10-9.303
F7=-0.189X1+0.221X2+2.048X3-4.649X4-3.679X5-0.974X6+10.841X7-7.985X8+221.911X9-69.058X10-0.463
F8=0.337X1+0.494X2+0.457X3+7.023X4-0.625X5-1.537X6-17.619X7+2.087X8+6.88X9+229.064X10-38.458
F9=0.518X1-0.035X2+0.885X3-14.995X4-0.257X5-5.636X6+26.099X7-4.9X8-30.377X9+159.188X10-31.76
F10=1.526X1+1.558X2+1.681X3-1.042X4-0.188X5+4.851X6+6.292X7+0.682X8+7.995X9-75.431X10-145.479
式中X1— X10分别代表Fe, O, Si, Ca, Al, Mn, Ti, Mg, P, S的含量。
前3个判别函数(F1, F2, F3)分别解释了总信息的90.6%, 5.7%, 2.0%, 累计解释98.40% , 用前3个函数建立判别模型, 并用判别得分来绘制三维散点图(图5), F1, F2, F3分别为判别函数F1, F2, F3的得分。 三维散点图分布表明, 14个品牌的铁矿石可明显地被划分为四个区域, 澳精粉和南非精粉与其他类别区分最为明显。 从图中还可以看出PB块与纽曼块分类略有重叠, 杨迪粉与国王粉的集群非常接近。 所建立判别模型的分类正确率如表3所示。 结果表明: 模型对澳精粉与南非精粉识别完全正确, 因为与其他类别的铁矿石相比, 这两类的Ti与Mg的含量与其他类别有明显不同。 模型对于PB块, 杨迪粉, 纽块会存在识别错误的情况。 这三个品牌的铁矿石都产于澳大利亚皮尔巴拉地区的哈默斯利铁矿带, 矿石成因类似, 元素含量比较接近, 因此相对于其他类别更难以区分。
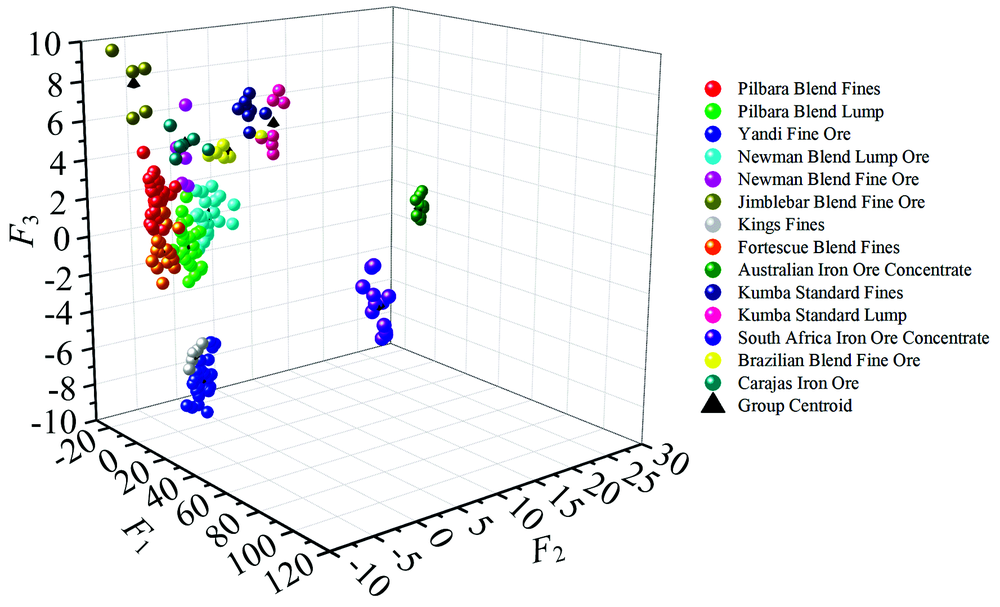 | 图5 判别函数得分三维散点图Fig.5 Discriminant function score three-dimensional scatter plot |
| 表3 判别模型的预测正确率(%) Table 3 Prediction accuracy of discriminant model(%) |
为追求更高的识别准确率, 选择使用全部10个函数来建立判别模型。 所建立判别模型的分类正确率如表3所示。 结果表明: 当使用全部10个函数建模时, 模型对测试样品识别的准确率有明显提高, 正确率达到了100%, 所建立识别模型具有很好识别效果。
利用波长色散-X射线荧光光谱无标样分析法测定澳大利亚、 南非、 巴西3个国家14个品牌236份铁矿石样品的元素含量, 选择191个样品作为训练样本, 45个样品作为测试样本, 采用逐步判别分析筛选出Fe, O, Si, Ca, Al, Mn, Ti, Mg, P和S共10种元素含量作为特征变量, 建立了识别铁矿石产地、 品牌的Fisher判别模型。 该模型为铁矿石品牌与元素之间的关系提供了基础数据与理论依据, 仅通过无标样分析法测量铁矿石样品10种元素含量建立判别模型, 便可以快速进行产地、 品牌的识别。 当然, 模型样品产地和品牌的确证和样本数量是限制模型正确率的关键要素, 当样本数量达到一定数量级之后, 所建立识别模型的准确率和普适性将得到进一步的提升。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|