




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像的猕猴桃形状特征检测
[黎静1, 2, 3  , 伍臣鹏
, 伍臣鹏1 , 刘木华1, 2, 3 , 陈金印3 , 郑建鸿1 , 张一帆1 , 王威1 , 赖曲芳1 , 薛龙1, 2, * ]
, 伍臣鹏]
|
|


作者简介: 黎 静, 女, 1978年生, 江西农业大学工学院副教授 e-mail: lijing3815@163.com
猕猴桃形状特征是猕猴桃在产后分级处理过程的一项重要指标, 不仅影响果实外观, 也决定果实等级高低的划分。 传统的形状分级方法大多采用人工分级, 存在耗时长、 效率低、 重复性差且易受人为主观影响等问题。 针对传统猕猴桃形状分级存在的问题, 研究利用高光谱成像建立猕猴桃正常果和畸形果的分类检测方法。 以成熟期的248个金魁猕猴桃(正常果107个, 畸形果141个)作为研究样本, 先利用可见-近红外高光谱成像系统采集猕猴桃样本的光谱数据, 再采用主成分分析法对光谱数据进行降维, 得到第一主成分图像。 随后提取第一主成分图像的3个特征波长(682, 809和858 nm), 并对其进行融合计算, 生成新的光谱图像(融合图像)。 然后利用四叉树分解算法对融合图像进行分割处理, 并计算掩膜图像所对应的12组形状特征参数, 结合偏最小二乘线性判别分析(PLS-LDA)、 反向传播神经网络(BPNN)、 最小二乘支持向量机(LSSVM)建立判别模型, 对比分析, 最终得到猕猴桃形状特征的最佳分类模型。 结果表明, 所建立的三种分类模型中, BPNN和LSSVM模型的分类效果较好, 总体分类准确率均在95%以上; PLS-LDA的效果略差, 训练集和测试集的总体准确率分别为80.12%和76.83%。 其中BPNN模型训练集和测试集的总体分类准确率分别为98.19%和97.56%, 总体误判个数分别为3和2, 而LSSVM模型的总体准确率分别为97.59%和95.12%, 总体误判个数分别为4和4。 对猕猴桃正常果的检测, 三种模型的分类效果分别为: LSSVM最好、 BPNN其次、 PLS-LDA最差。 对猕猴桃畸形果的检测, 三种模型的分类效果分别为: BPNN最优、 LSSVM其次, PLS-LDA效果最差。 因此, 猕猴桃形状特征的最佳分类模型是BPNN模型。 试验结果说明, 可利用高光谱成像对猕猴桃形状特征进行分类判别。 为猕猴桃形状特征的快速、 准确无损检测研究提供了理论支持。
, WU Chen-peng
The shape characteristic of kiwifruit, an important indicator in the post-harvest grading process, not only affects the appearance quality of fruits but also determines the level division of them. Most of the traditional shape grading methods were adopted manual grading, which had the disadvantages of long time-consuming, low efficiency, poor repeatability and strong subjective influence. This paper used visible and near-infrared (VIS/NIR) hyperspectral imaging technique to discriminate normal and malformed kiwifruit. Firstly, 248 mature “Jinkui” kiwifruit (107 normal samples and 141 malformed samples) were prepared. The visible-near-infrared hyperspectral imaging acquisition system (400~1 000 nm) was constructed to acquire the hyperspectral image of kiwifruit. After completing the spectral image acquisition, used principal component analysis (PCA) method to reduce dimensions and obtain the first principal component image for extracting three characteristic wavelengths (682, 809 and 858 nm). Then, the wavelengths were calculated to generate a new spectral image (fused image). Furthermore, the image was segmented by the quadtree decomposition algorithm, and the corresponding 12 sets of shape characteristic parameters were calculated based on the extracted mask images. The classification models by partial least squares-linear discriminant analysis (PLS-LDA), backpropagation neural network (BPNN), and least squares support vector machine (LSSVM) were established. Finally, compared and analyzed, the best model of kiwifruit shape characteristics was obtained. The results showed that among three classification models, BPNN and LSSVM models had better classification consequences: the overall classification accuracy was above 95%; The effects of PLS-LDA model was slightly worst: the overall accuracy of the training and test sets were 80.12% and 76.83%, respectively. Among them, the overall classification accuracy of BPNN was 98.19% and 97.56% in training and test set, respectively, and the total number of misjudgments were 3 and 2, respectively. Yet, the overall accuracy of LSSVM model was 97.59% and 95.12%, respectively, the total number of misjudgments were 4 and 4, respectively. For the classification effects of kiwifruit normal, the performances of three models were: LSSVM best, BPNN followed, and PLS-LDA bottom. For the classification effects of malformation, the performances of three models were: BPNN optimal, LSSVM followed, and PLS-LDA foot. Therefore, the best classification model for kiwifruit shape characteristics was BPNN. The experimental results showed that the shape characteristics of kiwifruit could be classified and identified and had an ideal effect. In the future, it is feasible to detect fruit shape combining the visible-near-infrared hyperspectral imaging technique. The result can provide the theoretical support for the rapid and accurate non-destructive detection of kiwifruit shape features using spectral information.
中国是猕猴桃的原生中心, 也是猕猴桃的最大生产国, 果园面积与产量均居世界第一。 作为江西盛产的“ 金魁” 猕猴桃, 有其独特的天然优势, 果实个头大, 耐贮性强, 果肉品质极佳, 营养价值高, 深受广大消费者的喜爱[1]。 但金魁猕猴桃存在一个普遍现象: 畸形果居多。 畸形果的一般特征: 果实有棱状肋起、 斜肩、 侧扁等多处发生形变。 而正常果一般呈圆柱形, 果形端正, 且大小均匀、 整齐一致, 果面较为完好。 目前, 猕猴桃产后分级处理主要采用人工分级, 效率低且人为主观因素大, 导致分级效果不佳。 畸形果的出现不仅加重产后分级处理的难度, 也严重影响了果实的外观和商品价值。 因此, 如何高效准确对猕猴桃形状分类检测研究具有重要意义和巨大的发展前景。
近年来, 国内外学者将形状特征应用于各类农产品外部品质研究。 Š ukilovi
主要研究内容:
(1)利用主成分分析法提取特征波长, 融合成新的图像;
(2)采用四叉树分解算法对图像分割, 以保证猕猴桃边界信息完整;
(3)提取12组猕猴桃形状特征参数, 利用可见-近红外高光谱成像结合偏最小二乘线性判别分析、 反向传播神经网络、 最小二乘支持向量机建立分类模型, 以验证模型的可行性, 然后比较模型优劣, 选出最佳分类模型。
以“ 金魁” 猕猴桃为研究对象, 采购于江西奉新某猕猴桃果园, 剔除损伤、 被异物污染的样品。 猕猴桃畸形果和正常果的分类由多位专业果形分析人员综合评定, 得到正常果107个, 畸形果141个, 共用样品248个。 实验前将样品表面可能残留杂物或者绒毛擦拭掉, 对其分别编号, 再进行高光谱图像的采集。 图1为采购的两种不同果形的猕猴桃样品。
 | 图1 购买的猕猴桃样品 (a): 正常果; (b)— (d): 畸形果Fig.1 Purchased kiwifruit samples (a): Normal; (b)— (d): Malformation |
高光谱图像采集系统如图2所示。 该系统主要由1台CMOS照相机(Photonfocus, Switzerland), 1台行扫描光谱摄制仪(Spectrograph V10E), 2个250 W的光纤卤素灯(ALPHA-1501, 21 V/250 W Halogen Tugsten Lamp)和一套光学移动平台(由步进电机控制的载物台)等部件组成。 为防止采集的图像受噪声和杂散光的干扰, 将其他硬件设备(除电脑外)全放置暗箱中。 图像采集范围是400~1 000 nm, 光谱分辨率约为1 nm, 曝光时间40 ms。 光谱采集软件为Spectral Cube(Spectral Imaging Ltd. , Finland)。
 | 图2 高光谱采集系统 (a): 示意图; (b): 实物图Fig.2 Hyperspectral acquisition system (a): Schematic diagram; (b): Actual picture |
采集高光谱图像前, 设定设备相关参数, 然后将仪器预热30 min。 为了避免光线和强电流对图像的影响, 必须对图像进行校正。 首先采集反射率为99.9%的白板得到白标定图像Iwhite, 然后拧上相机镜头得到黑标定图像Iblack, 然后对采集的原始图像Ioriginal, 利用校正式(1)处理得到校正图像I。 校正公式
式(1)中, I为校正后的高光谱图像, 作为后续处理时的原始图像。
高光谱图像由光谱信息和图像信息合成, 数据量大, 信息冗余度高, 直接处理不方便。 采用ENVI4.3(Research System, Inc., USA)软件对高光谱图像光谱区域进行主成分分析(principal component analysis, PCA), 减少无关变量的输出[7]。 选取500~918 nm波段的图像进行PCA处理, 大于918 nm和小于500 nm的波段受噪声影响较大。 每个PC图像是原始光谱波段的线性组合, 由相应的光谱权重系数加权[8]。
图3显示了猕猴桃第一主成分(PC-1)图像的光谱权重系数, 根据波峰、 波谷等特征位置得到3个特征波长(682, 809和858 nm), 在图上已标明。 利用3个特征波长, 对原始图像进行加权计算, 融合成一个和PC-1很接近的图像。 图4显示了波长为800 nm的原始图像及由PC-1的融合图像, 对比可看出, 融合图像[图4(b)]前景和背景差异性较大, 猕猴桃区域亮度更高, 边界更清晰, 便于处理。
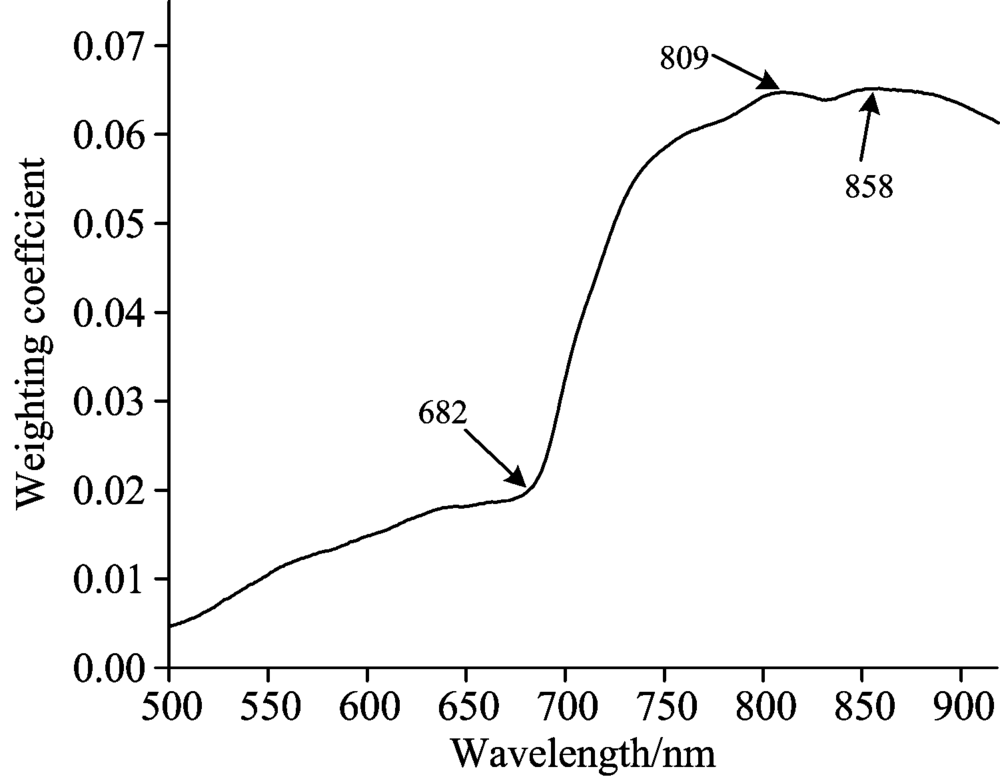 | 图3 猕猴桃PC-1图像的光谱权重系数Fig.3 Spectral weight coefficient of kiwifruit PC-1 image |
 | 图4 单波长和特征波长下灰度图像的对比 (a): 波长为800 nm; (b): 特征波长Fig.4 Contrast of grayscale images at single wavelength and characteristic wavelength (a): Wavelength at 800 nm; (b): Characteristic wavelength |
由于猕猴桃表面覆盖绒毛, 果实边缘像素值极低, 采用基于区域的图像分割技术难以将背景分离, 或者不能保证图像边缘的完整性。 基于四叉树的图像分割法能够有效解决这个问题, 保持图像细节更优越[9], 因此采用基于四叉树分解方法对融合图像进行分割。
四叉树分解过程: 首先将图像分成4个区域, 把具有一致性的像素分到同一区域, 若像素间不满足一致性标准, 则继续分成4个区域, 以此类推, 直到图像中的所有区域都满足一致性标准才停止。
图5显示了利用四叉树分解对畸形果和正常果图像分割过程。 图5(a)表示由3个特征波长融合而成的新图像(融合图像), 然后利用四叉树分解算法对融合图像进行分割, 再进行形态学腐蚀、 膨胀等处理得到掩膜图像[图5(b)], 从图5(b)中可以看出, 掩膜图像的边缘较为完整, 细节部分提取较好。
 | 图5 基于四叉树分解提取掩膜图像的过程 (a): 融合图像; (b): 掩膜图像Fig.5 The process of extracting mask images based on quadtree decomposition (a): Fused image; (b): Mask image |
形状特征是果实图像比较直观的外形特征, 也是果形分类研究最稳定的特征, 采用MatlabR2018a(Math Works, USA)对形状特征参数进行提取。 形状特征参数的定义及计算方法如下,
(1)面积(Area)
衡量猕猴桃大小的度量单位, 定义为目标区域的实际面积(像素个数), 用V1表示。
(2)周长(Perimeter)
表示包围目标区域的边界轮廓长度, 用V2表示。
(3)离散度(Dispersion)
用于描述果实形状复杂的指数, 表示在果实区域内, 单位面积内的周长的大小。 其计算公式如式(2)所示,
(4)圆形度(Circularity)
圆形度是猕猴桃与圆、 矩形的接近程度的参数, 如该参数越接近1, 说明猕猴桃越接近圆形, 参数接近0.79时, 猕猴桃形状接近矩形[4]。 其计算公式如式(3)所示,
(5)离心率(Eccentricity)
与猕猴桃区域具有相同标准二阶中心矩的椭圆的离心率定义为猕猴桃离心率, 表示椭圆两焦点间的距离和长轴长度的比值[10]。 其计算公式如式(4)所示,
式(4)中, focallength是与猕猴桃具有相同标准二阶中心矩的椭圆的半焦距, longaxis是其长半轴。
(6)质心比(Centroid ratio)
质心比表示目标图像的质心到边界距离的最大值和最小值(Rmax, Rmin)的比值, 该值体现其形状的复杂性, 其计算公式如式(5)所示,
(7)椭圆率(Ellipticity)
将猕猴桃区域的最小外接矩形的长和宽比值定义为椭圆率, 用于表示目标猕猴桃形状与椭圆的相似程度。 其计算公式如式(6)所示,
(8)矩形度(Rectangularity)
猕猴桃区域面积和猕猴桃区域的最小外接矩形的长和宽的乘积比, 其计算公式如式(7)所示,
(9)当量直径(Equivalent diameter)
当量直径表示与猕猴桃区域面积大小相等圆的直径[4], 其计算公式如式(8)所示,
(10)紧凑度(Compactness)
将当量直径和最小外接矩形的长之比定义为紧凑度[4], 其计算公式如式(9)所示,
(11)分形维数(Fractal dimension)
分形维数也称分维, 主要用于描述复杂形体的不规则性[11]。 分形维数的计算公式如式(10)所示,
式中, ε 表示小立方体的长度, N(ε )表示此小立方体覆盖被测形体所得的数量。
(12)傅里叶描述子(Fourier descriptors)
为了定性描述猕猴桃形状特征, 提取傅里叶描述子进行计算, 首先计算目标图像中心坐标, 然后计算中心坐标到边界各点的半径序列并归一化, 最后采用离散傅里叶变换得到傅里叶描述子, 这里取离散傅里叶变换的前15项分量描述边界信息[5]。 其计算公式如式(11)所示,
式中, m是边界点坐标个数, rk表示归一化后的半径序列, exp是傅里叶变换函数, w是频率。
为了消除形状特征参数因个别数据差异性过大, 或者由于单位量纲不同、 自身变异所引起的误差, 需要对数据进行归一化处理。 归一化可以把有量纲的表达式经过变换变成无量纲的数, 计算公式如式(12)所示,
其中, x表示需要处理的数据, xmax是数据中最大值, xmin是数据中最小值, x* 表示已处理完成的数据。
在建模前, 一般将样本集划分为训练集和测试集, 采用Kennard-Stone(KS)算法划分选样, 该算法是从所有样品中选择预定数目的样本作为训练集, 剩余样品本作为测试集。 KS选样过程:
(1)首先计算两两样本间的欧几里德距离, 选择距离最大两个样品;
(2)然后分别计算剩余的样本与已选择的两个样本之间的距离;
(3)对于剩余每个样本而言, 其与已选样品间的最短距离被选择, 然后选择这些最短距离中相对最长的距离所对应的样本作为测试集;
(4)重复步骤(3), 直至所选的样本数等于需要的数目为止[12]。
采用KS算法以2:1的比例对猕猴桃样本进行划分, 结果如表1所示, 训练集样本数包含正常果、 畸形果共有166个, 同样测试集样本包含正常果、 畸形果共有82个。 训练集用于建立猕猴桃形状特征的分类模型, 测试集则验证模型的分类性能。
| 表1 猕猴桃样品划分统计结果 Table 1 Statistical results of kiwifruit sample division |
(1)偏最小二乘线性判别分析
线性判别分析(linear discriminant analysis, LDA)的目标是从高维空间中找到最具分辨能力特征值, 将同一类别的样本聚集在一起, 从而达到模式分类识别。 但传统的LDA在训练样本没有足够多时不能保证类内离散度矩阵可逆, 而偏最小二乘(partial least squares, PLS)最初为一种基于特征变量的回归方法, 为拟合变量集和反应变量集之间的线性关系。
因而, 偏最小二乘线性判别分析(partial least squares-linear discriminant analysis, PLS-LDA)的基本思路: 首先利用PLS算法将矩阵X和y进行主成分分解, 得到X矩阵的主成分T。 然后利用T和各样本的y值做线性判别分析, 最终导出判别函数[13]。
(2)反向传播神经网络(BPNN)
反向传播神经网络, 由Rumelhart和McClelland为首的科学家于1986年提出, 是一种按照误差逆向传播算法训练的多层前馈神经网络, 具有任意复杂的模式分类能力和优良的多维函数映射能力。 基本思想是梯度下降法, 利用梯度搜索技术, 以期使网络的实际输出值和期望输出值的误差均方差为最小[14]。
(2)最小二乘支持向量机
支持向量机(support vector machines, SVM)是Corinna Cortes和Vapnik于1995年首先提出, 在解决小样本、 非线性及高维模式识别中表现出许多特有的优势。 最小二乘支持向量机(least squares support vector machines, LSSVM)是SVM的一种扩展, 在利用结构风险原则时选取不同的损失函数, 对数据分析和模式识别有较大优势, 可用于分类和回归分析[15]。
模型的性能评价以训练集分类准确率、 测试集分类准确率及总体分类准确率作为评价指标。
以正常果(赋值1)、 畸形果(赋值0)的分类形状为指标, 利用12组形状特征参数分别建立PLS-LDA, BPNN和LSSVM模型, 然后进行模型判别分析。
3.1.1 PLS-LDA建模分析
对于PLS-LDA模型的建立, 首先是通过交叉验证得到最小错分率为0.162 7, 最优主成分数为8, 利用最优主成分数来建模, 表2为PLS-LDA模型的分类结果。 从表中可知, 利用PLS-LDA模型对正常果的分类, 其分类准确率较高, 训练集中误判个数为5个, 而测试集的分类准确率达到100%, 对畸形果的分类效果较差, 训练集和测试集的准确率分别为69.15%和59.57%。
| 表2 PLS-LDA模型分类结果 Table 2 Classification result of PLS-LDA model |
3.1.2 BPNN建模分析
利用BPNN建立模型, 参数的合理选择尤其重要。 隐藏层数取2, 节点数为7, 学习速率为0.3, 最大训练次数为1 000, 最小均方误差为1× 10-8。 表3表示不同果形的猕猴桃样品结合BPNN判别结果。 结果表明, 利用BPNN分类判别, 训练集效果较好, 正常果、 畸形果的误判样本数分别为1和2, 总体准确率为98.19%; 测试集的分类效果也较为理想, 正常果没有出现误判, 畸形果误判个数为2, 准确率为95.74%, 而总体准确率也高达97.56%。
| 表3 BPNN判别结果 Table 3 Discriminant result of BPNN |
3.1.2 LSSVM建模分析
对于LSSVM模型, 参数选择也较为重要。 先是采用7-折交叉验证得到最优参数, 其中正则化参数和内核参数分别为816.486 9和11.175 4。 利用最优参数建模, 然后对模型进行训练、 仿真得出分类结果, 表4为猕猴桃的LSSVM模型分类结果。 结果表明, 利用LSSVM建立模型, 训练集畸形果有4个误判, 准确率为95.74%, 正常果零误判, 总体准确率达到97.59%; 测试集中4个误判样本均为畸形果, 总体准确率为95.12%。
| 表4 LSSVM模型分类结果 Table 4 Classification results of LSSVM model |
3.2.1 模型比较
结合PLS-LDA, BPNN和LSSVM建立的分类模型, 对于正常果的检测, 训练集的误判样本数: PLS-LDA, BPNN和LSSVM分别为4, 1和0, 对应的其分类准确率均在94%以上, 而三种模型测试集均未出现误判, 分类准确率为100%, 模型总体分类效果较好, 模型性能依次是LSSVM最好、 BPNN其次、 PLS-LDA最差。 对于畸形果的检测, PLS-LDA, BPNN和LSSVM模型训练集的误判样本数分别为29, 2和4, 前者的分类准确率低于70%, 后两者在95%以上, 三种模型测试集的误判个数分别为19, 2和4, 分类准确率分别为59.57%, 95.74%和91.49%, 模型分类效果: BPNN最优、 LSSVM其次, PLS-LDA效果最差。
综合比较猕猴桃形状特征的PLS-LDA、 BPNN和LSSVM分类模型, 可以看出PLS-LDA模型的分类效果最差, 训练集和测试集的总体准确率分别为80.12%和76.83%, BPNN和LSSVM模型效果较接近。 BPNN模型对正常果的检测, 训练集中出现1个误判, 但是测试集误判样本数仅为LSSVM模型的一半, 同时在畸形果的检测中, BPNN模型的分类效果均优于LSSVM, 训练集和测试集的总体分类准确率均大于LSSVM, 故认为BPNN是最优模型, 具有最高的总体分类准确率(98.19%和97.56%)。
3.2.2 误判样本分析
在最优模型BPNN模型中, 共有5个样品未能正确分类, 训练集中2个畸形、 1个正常样品, 测试集中2个畸形; 出现误判有多方面的原因。 如图6(a)所示, 融合图像(左边)包含样品表面缺陷、 边界形状双重特征, 由专业分析人员定义为畸形果, 但仅根据该样品的轮廓(右图)进行判别, 模型容易出现错分。
 | 图6 BPNN模型的误判样本 (a): 畸形果误判; (b): 正常果误判Fig.6 Misjudged samples of BPNN model (a): Misjudged malformation; (b): Misjudged normal |
其次, 影响正常样品未正确分类的另一个因素是果梗的存在, 如图6(b)所示, 果梗的存在与否, 将直接影响提取的形状特征参数值, 然后影响模型分类能力, 导致模型的准确率不高。 在今后的试验中, 将改进试验方法, 尽量保证样品特征的一致性(同种特征参与建模计算), 减少不同特征的差异性, 以提高模型分类准确率。
基于猕猴桃形状特征, 利用高光谱成像结合多种建模方式对猕猴桃正常果、 畸形果进行分类判别具有如下结论:
(1)采用主成分分析法对光谱数据降维并提取特征波长, 对特征波长进行组合计算; 利用四叉树分解算法来分割背景, 得到的掩膜图像, 没有杂散光和噪声影响, 边界信息保留较为完整。
(2)提取了12组猕猴桃形状特征参数, 结合PLS-LDA, BPNN和LSSVM建模分析。 结果表明, BPNN和LSSVM模型的分类效果较为理想, 总体的准确率均达到95%以上, 表明了利用高光谱成像来检测猕猴桃形状是可行的。
(3)基于猕猴桃形状特征参数建立的3种模型, 其最佳分类模型为BPNN模型, 总体分类准确率分别为98.19%和97.56%。 该技术为猕猴桃形状分类提供方法和理论依据, 为农产品外形无损检测奠定了理论基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|