


{kind=link}
{kind=link}
{kind=link}
{kind=link}
铁矿粉中全铁含量的SFIM-RFR高光谱预测模型
[高伟1  , 杨可明
, 杨可明1, * , 李孟倩2 , 李艳茹1 , 韩倩倩1 ]
, 杨可明, 李孟倩|
|


作者简介: 高 伟, 1997年生, 中国矿业大学(北京)硕士研究生 e-mail: gw970606@163.com
铁矿是全球储量最高的金属矿产之一。 全铁含量是评价铁矿石、 铁矿粉品质的重要指标, 在铁矿开采、 矿石精选、 矿粉冶炼等生产环节中有特殊意义。 传统的铁矿粉全铁含量化学分析方法存在耗时久、 操作复杂、 污染严重等缺点, 因此, 探寻一种快速、 有效、 无污染的检测方法越来越成为矿山环境的研究热点。 高光谱技术具有光谱分辨率高、 曲线连续、 无损伤、 无污染、 可对物质特征或成分进行精确探测等特点。 使用铁矿粉高光谱数据, 通过建立用于光谱特征筛选的光谱特征重要性评分(SFIM)指标, 并结合随机森林回归(RFR)方法构建铁矿粉全铁含量预测的SFIM-RFR模型。 以河北省阳原县三义庄铁矿为研究区, 于2018年11月与2019年3月在研究区收集铁精粉、 铁尾砂原料, 分别制作第一批次的训练组和验证组铁矿粉试样以及第二批次的二次验证组铁矿粉试样, 并使用ASD Field Spec4型光谱仪测量试样的光谱反射率; 然后使用第一批次的训练组光谱数据训练SFIM-RFR模型, 对第一批次的验证组样本的全铁含量进行预测, 同时采用常规RFR、 线性回归(LR)预测模型来对比分析铁矿粉样本全铁含量预测结果; 最后使用二次验证组光谱数据检验多模型鲁棒性。 结果表明: SFIM-RFR, RFR和LR模型全铁含量预测结果与2018年11月采集的验证组样本全铁含量真实值的确定系数(R-Square)分别为0.991 8, 0.988 4和0.898 7, 均方根误差(RMSE)分别为0.016 9, 0.020 1和0.059 6, 多模型预测效果总体较好, SFIM-RFR模型预测结果误差最小, 说明了SFIM-RFR模型用于预测铁矿粉中全铁含量的可行性和有效性, 且SFIM-RFR模型预测效果优于常规的预测模型; SFIM-RFR, RFR和LR模型全铁含量预测结果与2019年3月采集的二次验证组样本全铁含量真实值的R-square分别为0.976 8, 0.974 5和0.914 0, RMSE分别为0.034 6, 0.036 2和0.071 9, 证明了SFIM-RFR模型的预测效果较为理想且鲁棒性很强。
Iron ore is one of the most abundant metallic minerals in the world. Total iron contents is an important index to evaluate the quality of iron ore and iron ore powder, and it has a special significance in iron ore mining, ore dressing, ore smelting and other production links. The traditional chemical methods have the disadvantages of a time-consuming, complex operation, seriously pollution. Therefore, exploring a new method of rapid, effective and pollution-free detection has become a hot spot in mine environment research. Hyperspectral technology has the characteristics of high spectral resolution, continuous curve, no damage, no pollution and accurate detection of characteristics or components of materials. The purpose of this paper is to establisha data evaluation index of spectral feature importance measures (SFIM) and to screen spectral features based on the hyperspectral data of iron ore powder, and then combined with random forest regression (RFR) to establish the SFIM-RFR prediction model and predict the total iron contents of iron ore powder. First, taking Sanyizhuang iron mine in Yangyuan county, Hebei province as a research object, based on the iron concentrate and iron powder tail collected in the research area in November 2018 and March 2019, the first batch of iron ore powder samples in the training group and the testing group and the second batch of iron ore powder samples in the second testing group were made respectively. Spectral data of samples were measured by the ASD Field Spec4 spectrometer. Then, spectral data of the first batch of training group were used in the SFIM-RFR model training, and the total iron contents in the samples of the first batch of the testing group were predicted. Meanwhile, conventional methods, including RFR and linear regression (LR) prediction model, were used to compare and analyze the predicted results of total iron contents in iron ore powder samples. Finally, the spectral data of the second testing group were used to validatethe robustness of the multi-model. The results show that the R-Square values of prediction results of total iron contentsby the SFIM-RFR, RFR and LR models were 0.991 8, 0.988 4, 0.898 7, and RMSE valuesare 0.016 9, 0.020 1, 0.059 6. The results of multi-model prediction overall are good, and the SFIM-RFR model has the minimum error, which indicates the feasibility and effectiveness of this model in predicting the total iron contents of iron ore powder. Moreover, the prediction ability of SFIM-RFR model is better than that of conventional prediction models. The R-Square values of the prediction results of total iron contents by the SFIM-RFR, RFR and LR models are 0.976 8, 0.974 5 and 0.914 0. The RMSE values are 0.034 6, 0.036 2 and 0.071 9, which proves that the prediction ability of the SFIM-RFR model is the best and the robustness of the prediction model is the best.
铁是人类最早发现、 用途最广泛、 用量最大的一种具有战略性地位的金属。 铁矿粉中全铁含量的测定在铁矿开采、 铁矿石精选、 铁矿粉冶炼等环节及铁矿粉品质评价等方面有重要意义, 目前国内外使用最广泛的铁矿粉全铁含量测定方法为化学分析法[1, 2], 但此类方法存在时间长、 药品昂贵、 化验废液污染环境等诸多缺点。 高光谱遥感数据具有光谱分辨率高、 谱线连续、 隐含信息丰富等特点[3], 已广泛应用于物质含量预测与丰度反演, 如基于高光谱数据的变换等处理, 可采用线性回归(linear regression, LR)、 多元逐步回归(stepwise multiple linear regression, SMLR)、 偏最小二乘回归(partial least-squares regression, PLSR)、 支持向量机(support vector machine, SVM)等方法预测植物叶绿素含量[4, 5]; 采用模糊识别(fuzzy recognition, FR)、 SMLR、 PLSR等方法预测土壤中有机碳含量、 有机质含量和重金属元素含量[6, 7, 8]; 也有学者使用高光谱数据结合PLSR和LR等回归分析方法对土壤、 植物叶片中全铁及其他形态铁的含量进行预测研究[9, 10]。
国内外学者在使用光谱数据进行铁矿物质全铁含量预测方面取得了一定成果。 Yangmin G[11]等将稀疏偏最小二乘(hybrid sparse partial least-squares, SPLS)与最小二乘支持向量机(least-squares support vector machine, LS-SVM)结合, 建立了分析铁矿石纯度的SPLS-LS-SVM模型, 模型性能较传统的SPLS模型和LS-SVM模型更好; 李颖娜[12]等建立了基于反向传播(back propagation, BP)和径向基函数(radial basis function, RBF)的集成神经网络多物相铁矿石全铁含量预测模型, 实现了铁矿石物相分类与全铁含量预测; 何群[13]等建立了条带状铁建造铁矿石全铁含量的PLSR预测模型, 全铁含量的预测误差为3.43%。 现有的全铁含量预测模型存在一定的局限性, 如预测范围有限, 偏重对铁矿石全铁含量的预测等。 因此, 本文以河北省三义庄铁矿为研究区, 基于在研究区提取的铁精粉和铁尾砂原料, 制备铁矿粉样本, 对其进行全铁含量测定和光谱数据采集, 将光谱特征重要性评分(spectral feature importance measure, SFIM)与随机森林回归(random forest regression, RFR)相结合, 构建高光谱遥感的铁矿粉全铁含量SFIM-RFR预测模型; 同时, 通过比较分析SFIM-RFR模型与常规RFR、 LR模型的预测结果以及样品化学分析的测定结果, 验证SFIM-RFR模型的预测精度与鲁棒性, 探索快速、 有效、 无污染检测铁矿粉全铁含量的新方法。
随机森林是聚合多棵分类与回归树(classification and regression tree, CART)的随机抽样判别模型, 随机森林进行回归预测时, CART树的返回结果为离散值, 取所有CART树返回结果的平均值为最终输出结果[14]。
变量重要性评分(variable importance measure, VIM)是随机森林中的指标参数, 在其原理基础上构建光谱特征重要性评分(SFIM)来表征各特征波段光谱数据对随机森林预测结果的影响程度。 每个特征波段(xj)的SFIMj计算依据是xj在随机森林中每棵CART树(fk)处未参与抽样数据预测误差的均方差, xj在fk处的SFIMjk为
式(1)中, mk是第k棵CART树处的预测例数, yp是参与抽样数据产生的第p个预测结果, yp1是未参与抽样数据产生的第p个预测结果, yp2是将xj随机置换后未参与抽样数据产生的第p个预测结果。 所以, xj的SFIMj为
式(2)中, SFIMjk为xj在fk处的光谱特征重要性评分, n为随机森林中CART树的数量。
将SFIM与RFR相结合, 建立SFIM-RFR预测模型。 依据光谱数据各特征波段的SFIM对光谱数据进行遴选, 由SFIM高的特征波段构成优势光谱数据集, 使用优势光谱数据集进行训练、 预测。 SFIM-RFR模型适用于多特征目标的预测, 同时减少了无关光谱波段信息的影响, 较常规模型具有优势。
实验研究区为三义庄铁矿, 三义庄铁矿位于河北省阳原县化稍营镇, 处于辽西— 冀北地区华北地台北缘大型多金属成矿带的西部, 地理位置如图1所示, 该矿区的矿体形态、 矿化组合特点等方面较为复杂, 矿石组分各有不同。
 | 图1 三义庄铁矿地理位置示意图Fig.1 Map of geographical location of Sanyizhuang iron mine |
2018年11月、 2019年3月从河北省三义庄铁矿分别采集了两批次的铁精粉和铁尾砂原料, 在实验室对铁精粉、 铁尾砂原料做干燥、 研磨、 过筛等处理, 化验测定原料的全铁含量真实值。 原料的全铁含量分别为: 0.7%(2018年11月铁尾砂)、 67.34%(2018年11月铁精粉)、 2.67%(2019年3月铁尾砂)、 64.34%(2019年3月铁精粉)。 使用2018年11月批次的铁精粉、 铁尾砂原料按不同质比配制28组铁矿粉样本, 使用2019年3月批次的铁精粉、 铁尾砂原料按不同质比配制7组铁矿粉样本, 计算得到每组样本的全铁含量, 再将每组样本搅拌均匀后分成5份平行试样(A, B, C, D和E), 共计35组175个试样。
依据验证组占比25%的原则, 将2018年11月批次原料制备的28组样本划分为21组训练组样本和7组验证组样本, 将2019年3月原料制备的7组样本划分为二次验证组。 依据样本全铁含量对试样进行标记, 训练组21组样本的标记情况如表1所示, 验证组7组样本的标记情况如表2所示, 二次验证7组样本的标记情况如表3所示。
| 表1 训练组样本全铁含量及标记 Table 1 Total iron contents and labeling of training group samples |
| 表2 验证组样本全铁含量及标记 Table 2 Total iron contents and labeling of testing group samples |
| 表3 二次验证组样本全铁含量及标记 Table 3 Total iron contents and labeling of second testing group samples |
光谱采集仪器为ASD Field Spec4型光谱仪, 该仪器的探测器由检测波长范围为350~1 000, 1 001~1 800和1 801~2 500 nm的三个传感器拼接而成。 测量光谱时, 将样本平铺在黑色不反光纸上, 保持样本表面平整, 光源为光谱仪探头内置光源, 将探头底部垂直贴近样本, 确保不漏光。 对每种样本的A, B, C, D和E平行试样分别进行5次光谱数据采集, 每组样本数据采集后重新进行标准化白板校正, 共获得875次光谱测量结果。
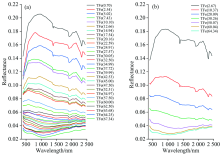
为了消除ASD Field Spec4型光谱仪三个传感器拼接造成的误差影响, 对采集的光谱进行拼接校正(splice correction, SC)。 使用Savitzky-Golay(SG)卷积平滑算法对光谱曲线进行处理; 由于仪器自身结构的影响, 所获取的光谱数据在“ 首” 、 “ 尾” 存在较大的噪声, 可对边缘光谱以50 nm为限值进行剔除, 保留400~2 450 nm的光谱信息。 剔除各组样本的A, B, C, D和E平行试样内光谱数据的异常值后, 求取各组内剩余试样的均值光谱, 即获得35条不同全铁含量的铁矿粉样本光谱曲线, 如图2所示。
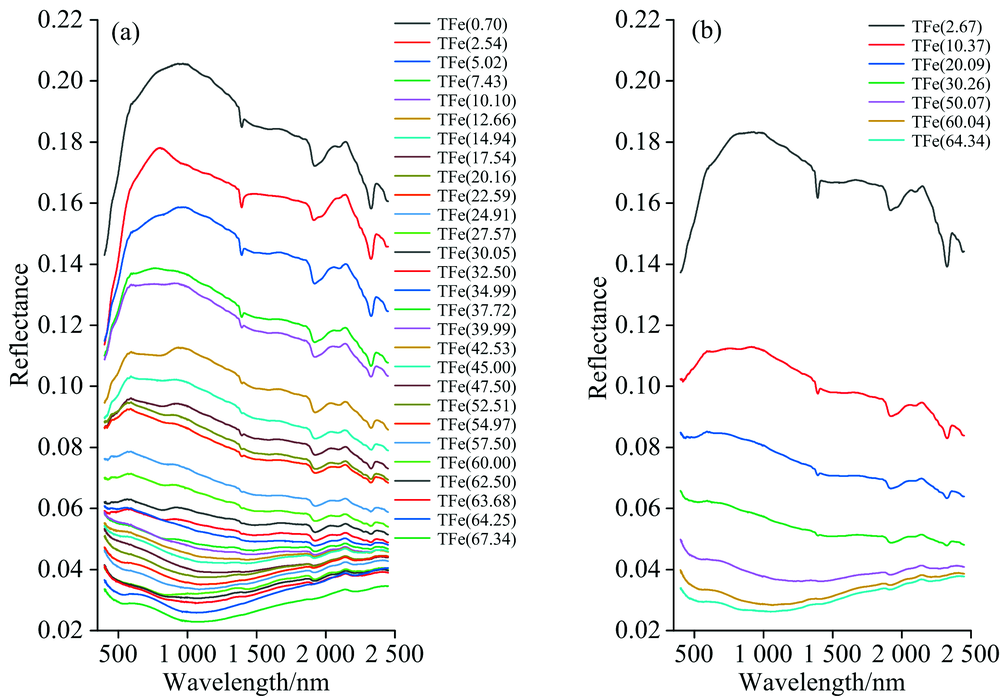 | 图2 铁矿粉样本光谱曲线预处理结果图 (a): 2018年11月批次铁矿粉样本光谱曲线预处理结果; (b): 2019年3月批次铁矿粉样本光谱曲线预处理结果Fig.2 Spectral curve processing results of iron ore powder samples (a): Samples collected in November 2018; (b): Samples collected in March 2019 |
1.6.1 SFIM-RFR模型构建与预测
为了检验SFIM-RFR模型的预测效果, 将训练组数据和验证组数据输入SFIM-RFR模型, 训练模型并对验证组铁矿粉样本全铁含量进行预测, 得到多次预测的结果平均值, 以及平均确定系数(R-Square)和平均方根误差(RMSE)。 SFIM-RFR预测模型的α 次预测过程为:
(1)输入训练组数据和验证组数据;
(2)设置SFIM-RFR模型中CART树的数量;
(3)使用训练组数据训练SFIM-RFR模型, 并对验证组数据进行预测;
(4)计算各特征波段的SFIM;
(5)将SFIM最大的波段选入新特征波段集;
(6)若新特征波段集中的波段数不等于阈值γ , 转到(3); 若等于, 转到(7);
(7)依据新特征波段集组建新训练组数据、 新验证组数据;
(8)使用新训练组数据训练SFIM-RFR模型, 并对新验证组数据进行预测;
(9)依据预测结果, 计算R-Square和RMSE;
(10)设i=i+1(初始i为0);
(11)若i不等于阈值α , 转到(8); 若i等于阈值α , 转到(12);
(12)输出α 次预测结果、 R-Square和RMSE的平均值。
1.6.2 RFR模型构建与预测
为与SFIM-RFR模型进行对比, 结合RFR原理, 建立RFR全铁含量预测模型, 将训练组数据和验证组数据输入RFR模型, 训练模型并对验证组铁矿粉样本全铁含量进行预测, 得到多次预测的结果平均值, 以及平均R-Square和平均RMSE。 RFR模型的β 次预测过程为:
(1)输入训练组数据和验证组数据;
(2)设置RFR模型中CART树的数量;
(3)使用训练组数据训练RFR模型, 并对验证组数据进行预测;
(4)依据预测结果, 计算R-Square和RMSE;
(5)设i=i+1(初始i为0);
(6)若i不等于阈值β , 转到(3); 若i等于阈值β , 转到(7);
(7)输出β 次预测结果、 R-Square和RMSE的平均值。
1.6.3 LR模型构建与预测
LR是最常用的回归分析方法之一, 故基于LR建立全铁含量预测的LR模型, 将光谱反射值与样本全铁含量相关系数最大的波段作为模型的输入值。 计算铁矿粉样本各波段光谱反射值与样本全铁含量之间的相关系数, 结果显示, 铁矿粉样本的光谱反射值与样本全铁含量之间的相关性整体较强, 相关系数绝对值最大的波段为400 nm处, 相关系数达到-0.953 5, 呈显著负相关。 使用与样本全铁含量相关系数绝对值最大的400 nm处的光谱数据训练LR模型, 表达式为y=-689.9x400+83.87, 对验证组铁矿粉样本全铁含量进行预测, 得到预测结果、 R-Square和RMSE。
SFIM-RFR模型、 RFR模型、 LR模型对验证组铁矿粉样本全铁含量的预测结果与真实值的差异如图3所示, 由图3(a)与图3(b)所示SFIM-RFR模型和RFR模型得出的预测值与真实值的差异较小, 而图3(c)所示LR模型得出的预测值与真实值的差异略大。 3个模型得到的样本全铁含量预测值与真实值的R-Square与RMSE见表4, SFIM-RFR模型的R-Square为0.991 8, RMSE为0.016 9; RFR模型的R-Square为0.988 4, RMSE为0.020 1; LR模型的R-Square为0.898 7, RMSE为0.059 6; 可见, SFIM-RFR模型的预测结果最好, RFR模型的预测结果较好, LR模型的预测结果较差。 总体来说, 利用铁矿粉高光谱数据建立的LR模型、 RFR模型、 SFIM-RFR模型对铁矿粉的全铁含量都有一定的预测能力, 其中SFIM-RFR模型的预测精度最好。
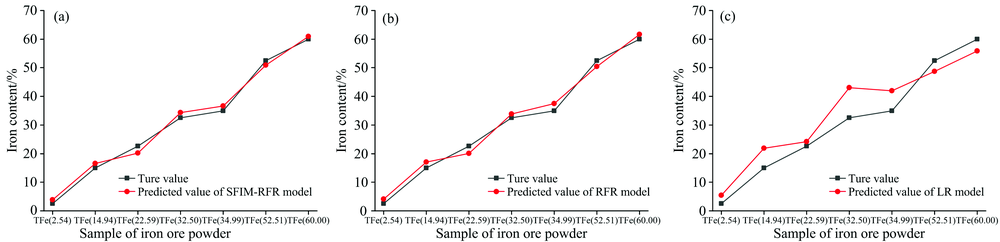 | 图3 全铁含量的SFIM-RFR、 RFR与LR模型预测值与真实值差异图 (a): SFIM-RFR模型; (b): RFR模型; (c): LR模型Fig.3 The difference between the predicted value and the true value of total iron contents (a): SFIM-RFR model; (b): RFR model; (c): LR model |
| 表4 基于训练组和验证组数据的模型预测精度表 Table 4 Prediction accuracy of the model based on the training and testing data |
为了检验模型的鲁棒性, 使用二次验证组数据对SFIM-RFR模型、 RFR模型、 LR模型进行检验。 3个模型得出的样本全铁含量预测值与真实值的差异如图4所示, 由图4(a)与图4(b)所示SFIM-RFR模型和RFR模型得出的预测值与真实值的差异较小, 而图4(c)所示LR模型得出的预测值与真实值的差异较大。 3个模型得到的样本全铁含量预测值与真实值的R-Square与RMSE见表5, SFIM-RFR模型的R-Square为0.976 8, RMSE为0.034 6, 预测值与真实值较为接近, 预测效果较好, 模型鲁棒性较强; RFR模型的R-Square为0.974 5, RMSE为0.036 2, 预测值与真实值差异略大, 预测效果不甚理想; LR模型的R-Square为0.914 0, RMSE为0.071 9, 预测值与真实值差异较大, 预测效果较差。 总的来说, SFIM-RFR模型的预测结果较为理想, 与样本全铁含量真实值较为接近, 模型预测能力较为稳定, 鲁棒性较强, 可以在一定精度范围内实现通过铁矿粉样本高光谱数据对样本全铁含量进行预测。
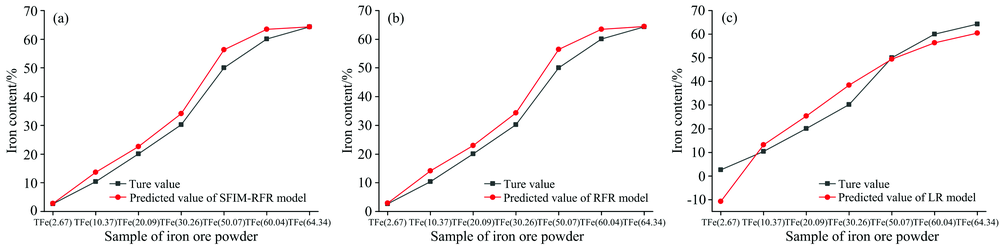 | 图4 全铁含量的SFIM-RFR、 RFR与LR模型预测值与二次验证组数据差异图 (a): SFIM-RFR模型; (b): RFR模型; (c): LR模型Fig.4 The difference between the predicted value and the second testing data of total iron contents (a): SFIM-RFR model; (b): RFR model; (c): LR model |
| 表5 基于二次验证组数据的模型检验精度表 Table 5 Test accuracy of the model based on the second testing data |
SFIM-RFR预测模型可利用铁矿粉高光谱数据对铁矿粉的全铁含量进行有效预测, 通过与常规RFR、 LR模型预测结果进行比较, 可以发现:
(1)使用2018年11月采集的训练组数据与验证组数据进行预测, 结果说明SFIM-RFR模型对全铁含量的预测能力最强, R-Square为0.991 8, RMSE为0.016 9; RFR模型的预测能力次之, R-Square为0.988 4, RMSE为0.020 1; 而LR模型的预测能力最差, R-Square为0.898 7, RMSE为0.059 6。 3个模型都能基于铁矿粉高光谱数据对全铁含量进行一定程度的预测, 证明了使用高光谱数据进行铁矿粉全铁含量预测的可行性, 其中SFIM-RFR模型的预测效果最好。
(2)使用2019年3月采集的二次验证组数据对SFIM-RFR模型、 RFR模型、 LR模型的鲁棒性与普适性进行检验, 结果显示LR模型的R-Square为0.914 0, RMSE为0.071 9, 预测值与真实值差异较大, 模型鲁棒性较差; RFR模型的R-Square为0.974 5, RMSE为0.036 2, 预测值与真实值差异略大, 模型鲁棒性一般; SFIM-RFR模型的R-Square为0.976 8, RMSE为0.034 6, 预测值与真实值最为接近, 预测效果最好, 模型预测能力最为稳定, 鲁棒性最强, 可以在一定精度范围内实现依据铁矿粉高光谱数据的全铁含量预测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|