


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于SPA和多分类SVM的紫外-可见光光谱饮用水有机污染物判别方法研究
[黄平捷 , 李宇涵, 俞巧君, 王柯, 尹航, 侯迪波
, 李宇涵, 俞巧君, 王柯, 尹航, 侯迪波* , 张光新]
, 李宇涵, 俞巧君, 王柯, 尹航, 侯迪波, 张光新]
|
|


作者简介: 黄平捷, 1974年生, 浙江大学控制科学与工程学院副教授 e-mail: huangpingjie@zju.edu.cn
快速、 有效地识别饮用水中污染物类别对于降低突发饮用水污染事件影响十分重要。 目前基于紫外-可见光光谱法的饮用水污染物判别模型大多使用主成分分析(PCA)进行特征提取, 然而, 对于光谱相似度较高的有机污染物, 仅从数据驱动的角度提取其方差最大的方向作为特征进行识别效果往往不佳。 针对有机污染物光谱数据多重共线性以及谱峰重叠干扰的问题, 开展了基于连续投影算法(SPA)和多分类支持向量机(M-SVM)的紫外-可见光光谱饮用水有机污染物判别方法研究。 首先, 使用紫外光谱仪测量苯酚、 对苯二酚、 间苯二酚和间苯二胺的原始光谱数据并进行预处理, 在对四种污染物进行了波长与浓度的相关关系对比分析后, 发现苯酚和间苯二酚、 对苯二酚和间苯二胺的谱峰重叠较为严重; 特征提取时, 引入SPA筛选有机污染物紫外-可见光光谱数据的特征波长组合, 并对不同波长个数时的光谱吸光度进行多元线性回归分析, 选取对应最小预测标准偏差的参数及波段组合作为最优参数组合; 基于最优特征波长组合, 构建基于多分类SVM的饮用水有机污染物分类识别模型; 最后, 对比分析了全光谱、 PCA及SPA特征提取后的光谱数据在不同分类方法及不同污染物浓度下的分类效果, 进一步说明了SPA的适用性和稳定性。 实验结果表明, SPA作为一种提取光谱数据原始特征波段的方法, 可以有效的对有机污染物的紫外-可见光光谱进行特征提取, 提升不同物质之间的差异, 在一定程度上消除多重共线性和谱峰重叠干扰, 从而提高分类模型的准确率。 该方法对于解决饮用水中谱峰重叠的污染物类型判别问题具有参考价值。
Quickly and effectively identifying the water contaminants is vital for reducing the impact of sudden drinking water pollution incidents. PCA is mostly used to extract the feature of different contaminants in drinking water with UV-Vis spectra. However, for the organic contaminants with high similarity in UV-Vis spectra, the identification result is ineffective when only extracting the feature of the largest variance direction from the data-driven point of view. This paper studies the classification of organic contaminants in water distribution systems developed by SPA and multi-classification SVM using UV-Vis spectroscopy. Firstly, the original spectral data of phenol, hydroquinone, resorcinol and m-phenylenediamine are measured by UV spectrometer and pretreated. The correlation between wavelength and concentration of four contaminants was compared. The peaks between phenol and resorcinol, hydroquinone and m-phenylenediamine are overlapped seriously, the classification results can interfere easily. In feature extraction, the SPA is introduced to select the organic contaminants’ characteristic wavelengths of UV-Vis spectra. Then, multiple linear regression analysis is carried out to choose the optimal parameter combination, which corresponds to the minimum prediction standard deviation. Based on this, the multi-classification support vector machine is used to form an identification model for drinking water organic contaminants. Finally, the classification results of spectral data based on full spectrum, PCA and SPA under different classification methods and different concentrations are compared and analyzed, and the applicability and stability of SPA are further explained. Experimental results demonstrate that SPA-based feature extraction method eliminates the interference of multi-collinearity and amplifies the difference among the UV-Vis spectra of different organic contaminants, thereby improving the accuracy of the classification model. This method has certain reference value for solving the problem of identifying the types of pollutants with overlapped peaks in the drinking water.
近年来, 饮用水污染事件频发, 给居民正常生活带来很大影响[1]。 为了及时应对此类污染事件, 需要在线监测水质并识别污染物, 以防止此类事件造成进一步的影响。 相较于传统检测手段, 基于光谱法的水质检测方法因其具有快速、 无需试剂、 样本无需预处理、 设备简单、 检测原理成熟等优点, 从而吸引了众多学者针对基于光谱法的水体污染物识别技术展开研究[2, 3]。 在众多光谱波段中, 紫外-可见光光谱波段因其检测速度快、 检测原理成熟, 并且可以间接的反映水中有机物、 悬浮物等理化参数, 从而受到广泛的关注[4, 5]。
现有的基于紫外-可见光光谱的水体污染物检测识别方法大多是基于PCA进行特征提取。 例如, 赵明富[6]等利用水体紫外-可见光谱波段, 使用主成分分析并结合Fisher判别法对水质进行了较好的分类; Hou[7]等提出了一种融合主成分分析法和卡方分布的水质异常检测算法, 通过紫外光学传感器实现对水质异常状况的判别; 郭冰冰[8]等提出一种基于基线校正和主元分析的水质异常检测方法, 利用主成分分析方法提取正常水质的紫外-可见光光谱的特征并利用统计量识别异常光谱。 PCA对紫外-可见光光谱数据进行了降维并提取了数据的特征, 有效的提高了污染物识别的效果, 但仍然存在一些问题, PCA仅从数据的方差最大的方向对数据进行压缩, 没有考虑到紫外-可见光光谱的实际的物理特征, 因此, 寻找一种更合适的污染物光谱数据特征提取方法来解决饮用水中谱峰重叠的有机污染物分类问题显得十分迫切和必要。
针对现有紫外-可见光光谱法对于有机污染物特征提取效果不佳的问题, 本文确定了有机污染物之间吸收峰的重叠范围以及光谱的相似度, 选用物理意义更强的SPA对有机污染物的紫外-可见光光谱进行特征波段提取, 并根据特征提取后光谱数据构建分类模型, 实现对不同浓度的有机污染物分类, 从而确定异常事件的污染物的类别。
使用紫外光谱仪得到有机污染物的紫外光谱原始数据后, 为了确定污染物类别, 还需要以下三个步骤:
(1)光谱数据预处理, 通过预处理方法消除紫外-可见光光谱数据中的噪声和基线漂移干扰。
(2)特征提取, 由于部分有机物的紫外-可见光光谱的相似度较高, 吸收峰所在波长范围部分重叠, 因此需要对紫外-可见光光谱数据进行特征提取, 增大不同污染物之间的差别。
(3)建模与预测, 根据特征光谱数据构建分类模型, 基于分类模型对未知样本进行分类。
基于紫外-可见光光谱的有机污染物分类方法的流程如图1所示。
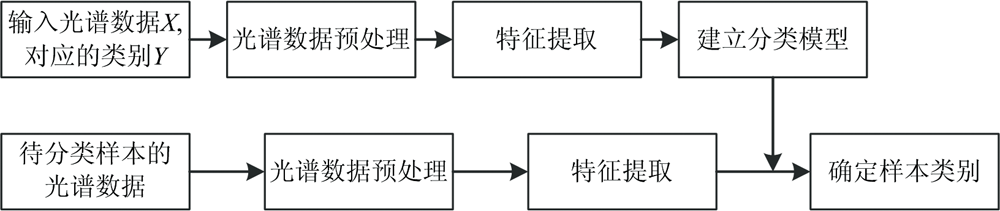 | 图1 基于紫外-可见光光谱的有机污染物分类的一般流程Fig.1 General procedure for classification of organic contaminants based on the UV-Vis spectra |
SPA是一种使矢量空间共线性最小化的前向变量选择算法, 在有效信息获取和降低共线信息的研究中取得了较好的效果[9, 10]。 最初的应用场景是近红外光谱的定量模型中光谱变量的选取, 通过投影方式选取线性关系最小的波长组合, 从光谱信息中寻找含有最低冗余信息的变量组, 使得变量之间的共线性达到最小, 同时保留原始数据的绝大部分特征, 被选取的特征波长物理意义明确, 具有很强的解释能力, 因此, 可以有效的提高建模的速度以及模型的稳定性, 该算法简要介绍如下:
设xk(0)为选取的原始光谱矩阵的某个波长的吸光度向量, N为需要选取的特征波长的个数, 初始的光谱矩阵为m列, 每次迭代开始前选取的光谱数据第一列不同, 算法需要对以下的步骤循环m次:
(1) 迭代开始前, 任选光谱矩阵的1列, 用i表示, 即把原始光谱矩阵的第i列xi赋值给xk(0);
(2) 把原始光谱矩阵中未选入的列向量位置的集合记为s, 记为s={j, 1≤ j≤ m; j∉{k(0), …, k(n-1)}};
(3) 计算当前的所选变量xk(n-1)对剩下原始光谱数据的列向量xi(i∈ s)的投影: Pxi=xi(
(4) 提取投影最大值的波长变量序号, k(n)=arg[max(‖ Pxi‖ )];
(5) 令xi=Pxi, i∈ s;
(6) n=n+1, 如果n< N, 回到步骤(2)循环计算。
最后, 提取的特征波长变量为{xk(n), n=0, …, N-1}。 对应于每一个k(0)和N, 每循环一次算法, 对提取的特征波长处的光谱吸光度进行多元线性回归分析, 计算验证集的预测标准偏差, 其中最小预测标准偏差对应的k(0)和N就是最优的特征波长组合。
大多数有机物的紫外-可见光光谱具有专属特点, 称为指纹特性[11], 可以根据有机物的紫外-可见光光谱的指纹特性确定类别。 本文选择多分类SVM对不同浓度有机污染物的紫外-可见光光谱数据进行分类。
SVM是基于统计学习理论的一种模式识别方法[12]。 SVM算法最初是针对二分类问题设计的, 由于饮用水有机污染物分类是一个多分类问题, 因此, 需要对SVM进行适当变化, 从而构造多分类器[13]。 本文选用一对一方法构造多分类SVM模型, 该方法与样本分布无关, 分类器组合比较方便[14]。 主要算法流程如下:
(1) 对于不同的污染物样本, 需要在任意两类样本之间构造一个SVM, k类样本就需要设计k(k-1)/2个分类器;
(2) 对一个新样本进行分类时, 通过多个分类器投票决定分类结果。
为了验证基于紫外-可见光光谱的有机污染物分类的可行性, 选取了四种典型的有机污染物, 分别是苯酚、 对苯二酚、 间苯二酚和间苯二胺。 这些物质在工业生产中使用较为广泛, 被列入2017年公布的《世界卫生组织国际癌症研究机构致癌物清单》中, 尤其值得关注。 配置多浓度梯度的四种污染物水溶液, 浓度依次为30, 40, 50, 100和200 μ g· L-1。 训练集中每个浓度的紫外-可见光光谱数据为10个。 测试集中苯酚71个, 对苯二酚58个, 间苯二酚72个, 间苯二胺79个。 考虑到水质波动的影响, 训练集与测试数据的采集时间间隔一周。
根据朗伯-比尔定律, 紫外-可见光光谱的吸光度会随着特征污染物浓度的增大而增大, 如果该点的吸光度与特征污染物的浓度阵之间的关系为正相关, 说明特征污染物在该波长点会对光子产生吸收。 将特征污染物的紫外-可见光光谱的每个波长对应的吸光度向量x与浓度向量y进行相关性分析, 计算公式如下所示
式中,
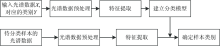
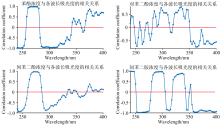
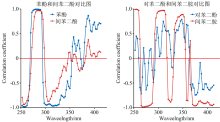
四种特征污染物的浓度与各个波长的吸光度之间的关系如图2所示, 其中正相关关系所在的波长范围与吸收峰所在位置基本一致。 苯酚与间苯二酚、 对苯二酚与间苯二胺的相关关系对比图如图3所示。
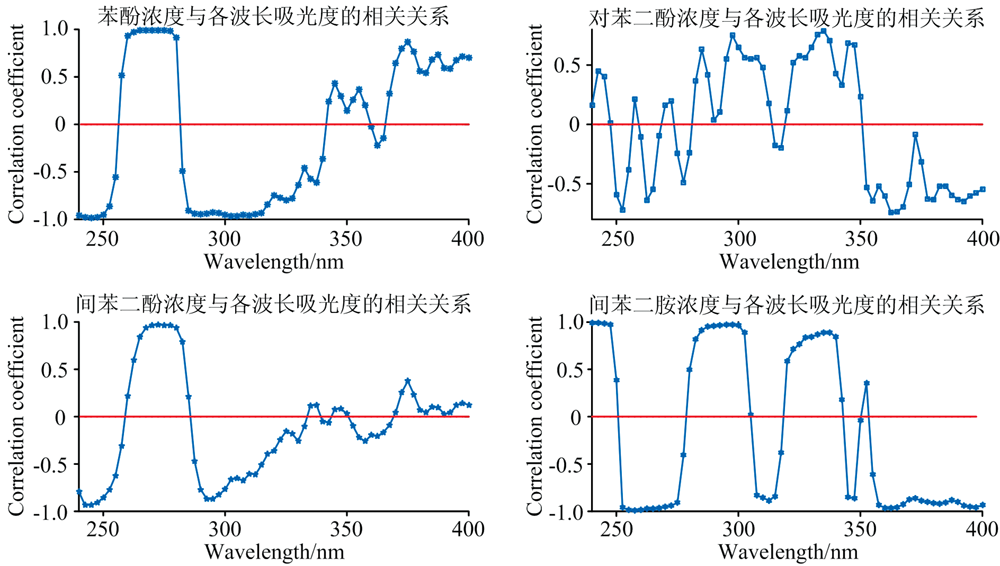 | 图2 四种有机污染物浓度与各波长吸光度相关关系图Fig.2 Correlation between the concentration of four organic contaminants and the absorbance at each wavelength |
 | 图3 四种有机污染物的相关关系对比图Fig.3 Comparison of the correlation between four organic contaminants |
从图2和图3可以看出, 四种特征污染物之间存在部分谱峰重叠, 其中苯酚和间苯二酚的谱峰重叠比较严重, 原因是两者的分子结构相似, 其生色团基本一致, 只是助色团的数量和位置不一样, 分类时容易相互干扰。 对苯二酚和间苯二胺的助色团差别较大, 存在部分谱峰重叠, 分类决策容易受到浓度的干扰[15]。 此外, 四种特征污染物的紫外-可见光光谱存在部分谱峰重叠, 相互之间存在一定的干扰, 需要选择合适的方法提取光谱数据的特征, 增大光谱数据之间的差别。
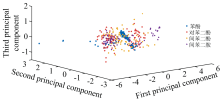
使用PCA对四种有机污染物分别提取前三主成分, 四种有机污染物的前三主成分如图4所示。 从图中可以看出, 有机污染物的主成分分布比较相似。
 | 图4 四种有机污染物的前三主成分的散点图Fig.4 Scatter plot of the top three principal components of four organic contaminants |
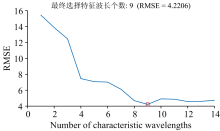
采用SPA方法对训练集数据进行特征波长选取时, 由于200和100 μ g· L-1的数据浓度较高, 光谱数据的吸光度与污染物浓度存在一定的非线性, 30 μ g· L-1数据中的干扰较大, 因此在选取特征波长时, 采用的浓度为50和100 μ g· L-1。 对不同特征波长个数下的四种污染物紫外-可见光光谱吸光度进行多元线性回归分析, 计算得到的RMSE分布曲线如图5所示, 图中红色方框表示SPA算法选择的污染物紫外-可见光光谱特征波段的数量。
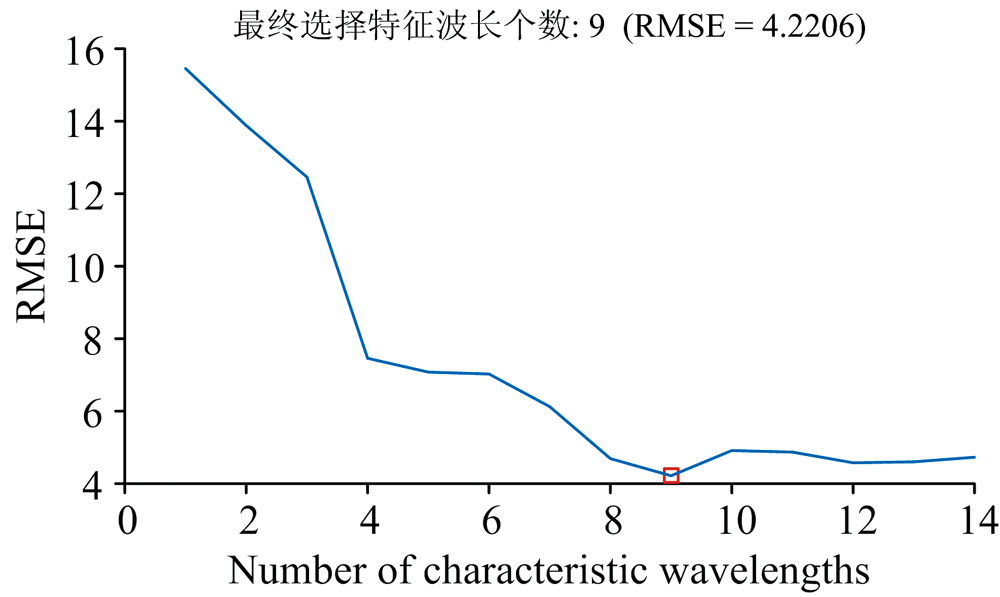 | 图5 SPA不同特征波长个数时RMSE分布曲线Fig.5 RMSE distribution curve of SPA with different characteristic wavelengths |
最后选取的特征波长数为9个, 根据重要性排序, 波长依次为277.5, 382.5, 295, 322.5, 252.5, 260, 337.5, 310和315 nm, 这些波长基本都是四种有机污染物的吸收峰所在。 四种有机污染物各个波长段的吸光度分布如图6所示。 从图中可以看出, 所选取的波长处的相似有机污染物的吸收光谱的重叠度较低。
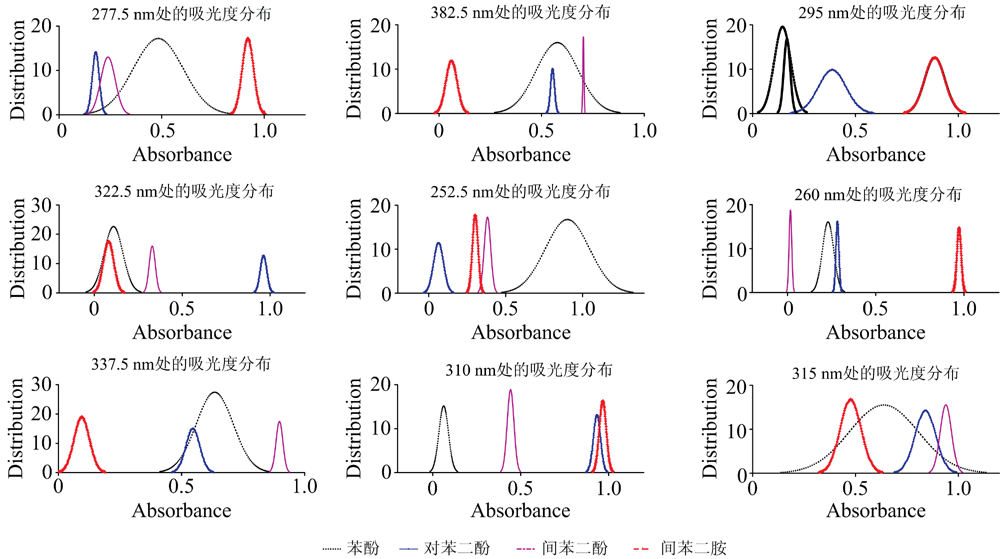 | 图6 SPA选取的特征波长处的有机污染物的吸光度分布Fig.6 Absorbance distribution of organic contaminants at characteristic wavelengths selected by SPA |
根据特征光谱波段数据构建KNN模型和多分类SVM模型, 其中PCA方法选取前三主成分, SPA选取9个特征波长, 根据特征提取方法对训练集和测试集的数据进行特征提取, 构建对应的训练集和测试集。 为了对比研究, 也使用基于原始光谱的65维的数据建立了相应的分类模型。 表1显示三者对训练集数据以及测试集数据的分类准确度。
| 表1 有机污染物在不同特征提取方法下的分类效果 Table 1 Classification effect of organic contaminants under different feature extraction methods |
通过对比表1中不同特征提取方法的分类效果, 可以得出以下结论: 基于全光谱的分类模型对训练集的分类精度较高, 但是对于测试集的分类精度相对较低, 说明模型的预测能力较差, 原因是全光谱中存在较多的干扰信息和冗余信息; 基于PCA的特征光谱数据模型对训练集和测试集的分类精度相对较低, 原因为在PCA提取特征的过程中, 根据协方差对数据进行降维, 引入了干扰信息, 相似污染物之间的干扰比较严重, 因此分类的准确度不高; 基于SPA筛选的特征波长模型对训练集和测试集的分类精度都较高, 说明模型的稳定性和预测能力都较好。 SPA仅选取了全光谱的13.8%的变量, 变量之间的共线性更小, 有助于构建一个相对简单、 稳定的分类模型, 并且SPA在两种分类方法下的分类准确率都很高, 表明该方法的适用性较强。
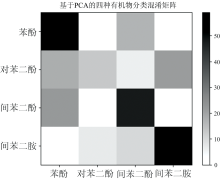
整体分类准确率虽然可以反映多分类SVM模型整体的分类效果, 但是无法反映有机污染物之间的相互干扰, 因此, 需要通过混淆矩阵分析多分类SVM模型对有机污染物的分类结果。 基于全光谱的四种有机污染物分类效果如图7所示; 基于PCA特征提取的分类效果如图8所示; 基于SPA特征提取的分类结果如图9所示。 混淆矩阵图中, 颜色越深代表对应的两种污染物相似度越高, 所有的正确分类都集中在矩阵的对角线上。 如果一张混淆矩阵的图呈现出对角线相似度很高的特征, 则认为该模型分类效果较好[16]。
 | 图7 基于全光谱的有机污染物分类效果Fig.7 Classification effect of organic contaminants based on full spectrum |
 | 图8 基于PCA特征提取的有机污染物分类效果Fig.8 Classification effect of organic contaminants based on PCA |
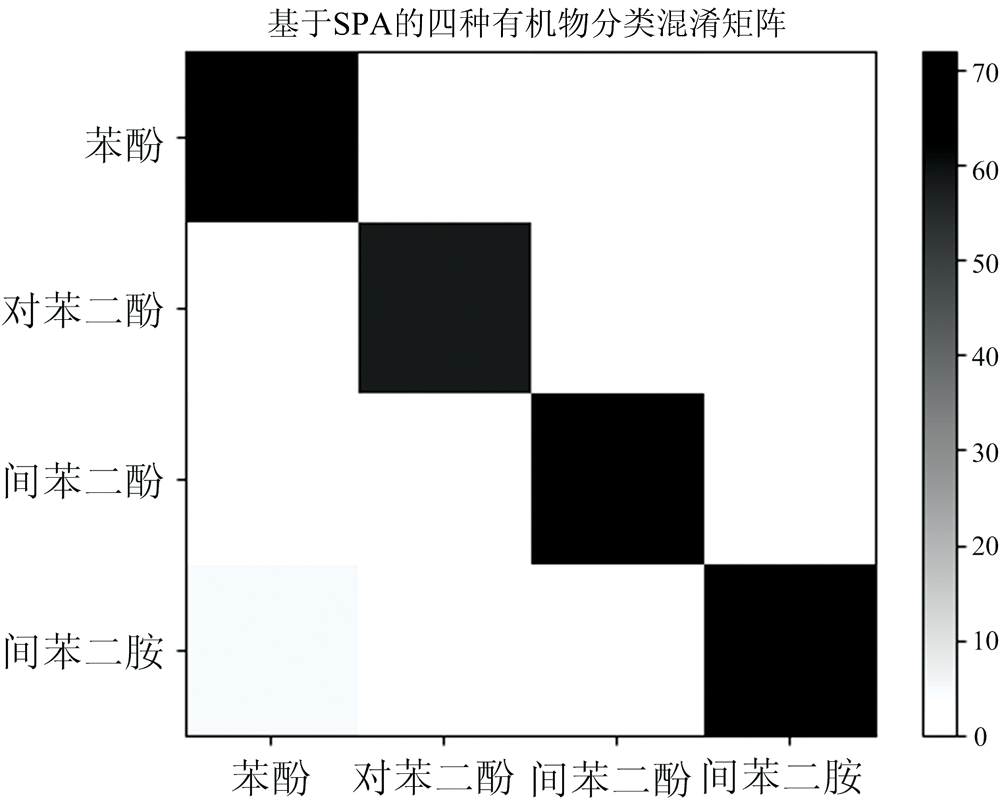 | 图9 基于SPA特征提取的有机污染物分类效果Fig.9 Classification effect of organic contaminants based on SPA |
通过对比可以看出, 基于SPA的四种污染物分类混淆矩阵对角线相似度最高, 说明该模型下四种污染物之间的相互干扰最小, 分类性能比较稳定; 而基于全光谱和基于PCA的分类模型中, 混淆矩阵相似度分布相对更加平均, 表明污染物之间相互干扰严重, 性能不够稳定。
为了分析浓度的干扰, 需要分析不同浓度下有机污染物的分类准确率, 从而评估其分类性能。 基于全光谱的不同浓度有机污染物分类准确率如表2所示; 基于PCA特征提取的不同浓度有机污染物分类准确率如表3所示; 基于SPA特征提取的不同浓度有机污染物分类准确率如表4所示。
| 表2 基于全光谱的不同浓度有机污染物分类准确率(%) Table 2 Classification accuracy of organic contaminants at different concentrations based on full spectrum (%) |
| 表3 基于PCA特征提取的不同浓度有机污染物分类准确率(%) Table 3 Classification accuracy of organic contaminants at different concentrations based on PCA (%) |
| 表4 基于SPA特征提取的不同浓度有机污染物分类准确率(%) Table 4 Classification accuracy of organic contaminants at different concentrations based on SPA (%) |
上述不同浓度分类准确率的结果表明, 全光谱+多分类SVM模型对低浓度和高浓度的对苯二酚分类效果较差, 对其他三种有机污染物的分类效果较好; PCA+多分类SVM模型对各浓度梯度的有机污染物分类精度较差; SPA+多分类SVM对各浓度梯度的有机污染物分类效果较好, 对四种有机污染物的分类精度可以达到90%以上, 稳定性较好。
针对有机污染物紫外-可见光光谱存在谱峰重叠导致分类效果不佳的问题, 开展了有机污染物特征提取和判别方法的研究。
通过实验获取苯酚、 对苯二酚、 间苯二酚、 间苯二胺这四种谱峰相似有机污染物在不同浓度下的紫外-可见光光谱数据, 并比较了不同特征提取和分类方法对不同浓度有机污染物的分类效果。 实验结果表明, 与全光谱和PCA特征提取方法相比, SPA能有效地提取有机污染物紫外吸收光谱的特征波长组合并表征各类有机污染物的特征, 不仅能够消除光谱数据的多重共线性干扰以及相似污染物之间的干扰, 同时增强了有机污染物之间的差别, 具有很好的物理意义和解释性, 结合多分类SVM可实现对不同浓度有机污染物的有效分类, 为实现饮用水中谱峰重叠污染物类型的判别提供有效方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|