

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于模型集群的马铃薯叶绿素检测光谱变量筛选讨论
[刘宁1  , 邢子正
, 邢子正1 , 乔浪1 , 李民赞1 , 孙红1, * , QinZhang2 ]
, 邢子正, QinZhang|
|


作者简介: 刘 宁, 1995年生, 中国农业大学信息与电气工程学院研究生 e-mail: ningliu@cau.edu.cn
为了探究马铃薯作物叶绿素吸收特征, 充分解析光谱特征波长变量, 建立高精度叶绿素含量检测模型。 在马铃薯发棵期(M1)、 块茎形成期(M2)、 块茎膨大期(M3)和淀粉积累期(M4)4 个关键生长期, 利用ASD便携式光谱仪采集80个样本区的314组作物冠层反射率数据, 并同步采集叶片测定叶绿素含量。 在光谱数据预处理之后, 分析了马铃薯不同生长期的光谱反射率变化特征。 利用基于模型集群思想的蒙特卡洛无信息变量消除(MC-UVE)、 随机蛙跳(RF)、 竞争自适应重加权采样(CARS)三种算法筛选叶绿素特征波长, 建立叶绿素含量检测PLS模型。 对4个生长期的314个样本, 采用SPXY算法分别按照3:1的比例划分, 得到建模集240个样本、 验证集74个样本。 利用MC-UVE, RF, CARS三种算法筛选叶绿素特征波长, 讨论迭代次数( N)和特征变量个数(LV)对MC-UVE和RF算法、 迭代次数( N)对CARS算法筛选特征波长结果的影响, 对迭代次数设置6个梯度, 分别为 N=50, 100, 500, 1 000, 5 000和10 000; 对特征变量数设置4个梯度, 分别为LV=15, 20, 25和30。 以PLSR模型的验证集结果为评价指标, 分析迭代次数( N)和特征变量数(LV)的最优参数组合。 最后基于MC-UVE, RF和CARS算法筛选得到的最佳特征波长建立叶绿素检测PLSR模型, 分别记为MC-UVE-PLSR, RF-PLSR, CARS-PLSR。 结果表明, CARS, RF和MC-UVE三种算法的迭代次数( N)、 特征变量数(LV)参数最佳组合分别为: (1)MC-UVE: 迭代次数 N=50 特征变量数LV=30; (2)RF: 迭代次数 N=500、 特征变量数LV=30; (3)CARS: 迭代次数 N=100。 对比在最佳特征波长建立的MC-UVE-PLSR, RF-PLSR, CARS-PLSR叶绿素含量检测, 发现RF-PLSRRR模型的性能最优, $R^{2}_{v}$为0.786, RMSEV为3.415 mg·L-1; MC-UVE-PLS模型性能次之, $R^{2}_{v}$为0.696, RMSEV为4.072 mg·L-1; CARS-PLS模型的性能最差, $R^{2}_{v}$为0.689, RMSEV为4.183 mg·L-1。 以上结果说明: 在筛选马铃薯叶绿素特征波长方面RF算法优于MC-UVE和CARS, 得到的特征波长能够较全面地反映与马铃薯叶绿素相关的物质信息。
The paper was aimed to explore the chlorophyll spectral absorption characteristics of potato crops, fully analyze the spectral characteristic wavelength variables, and establish a high--precision chlorophyll content detection model. The 314 reflectance samples were collected using an ASD portable spectrometer at the seedling stage (M1), tuber formation stage (M2), tuber expansion stage (M3) and starch accumulation stage (M4). The chlorophyll content was determined by the simultaneous collection of leaves. After spectral data pre--treatment, the spectral reflectance changes of different growth stages of potato were analyzed. The algorithms based on model population analysis were used to select chlorophyll characteristiccharacteristic chlorophyll wavelengths, including Monte Carlo uninformative variables elimination (MC--UVE), random frog (RF) and competitive adaptive reweighted sampling (CARS) algorithm. The partial least square regression (PLSR) was used to establish the chlorophyll content detection model. The sample set was divided by a ratio of 3:1 in each growth stage using the sample set partitioning based on joint X-Y distance algorithm (SPXY) with the 240 calibration samples and 74 validation samples. The different algorithms (MC-UVE, RF, CARS) were used to select chlorophyll characteristic wavelengths. The influence of the number of iteration (N) and the number of the latent variables (LV) on the results of characteristic wavelength selection of MC-UVE and RF algorithms were discussed, and the influences of N on that of CARS algorithm were discussed. Six gradients were set for the number of iterations ( N), which were N=50, 100, 500, 1 000, 5 000 and 10 000, respectively. Four gradients were set for the number of latent variables (LV), which were LV=15, 20, 25 and 30 respectively. Taking the validation set result of PLS model as the evaluation index, the optimal parameter combination of N and LV was analyzed. Based on the optimal characteristic wavelengths selected by the three algorithms, the chlorophyll detection PLSR models were established and denoted as RF-PLSR, MC-UVE-PLSR, and CARS-PLSR, respectively. The research results showed that the chlorophyll characteristic wavelengths selection results were optimal when N=50 and LV=30 of MC-UVE, N=500 and LV=30 of RF, N=100 of CARS. By comparing the RF-PLSR, MC-UVE-PLSR, and CARS-PLSR models, it was indicated that the performance of the RF-PLSR model was best, the determination coefficient of validation ($R^{2}_{v}$) was 0.786, the root means square error of validation (RMSEV) was 3.415 mg·L-1; MC-UVE-PLSR was second, the $R^{2}_{v}$ was 0.696, the RMSEV was 4.072; and the CARS-PLSR was the worst, the $R^{2}_{v}$ was 0.689, the RMSEV was 4.183. Above results showed that the RF algorithm was superior to MC-UVE and CARS in selecting the characteristic chlorophyll wavelength of potato.
叶绿素含量是评价马铃薯作物光合作用能力与营养水平的重要指标之一[1, 2]。 在可见光-近红外区域, 分析含氢基团(O— H, N— H, C— H)振动合频和各级倍频的特性, 是开展作物叶绿素、 氮素、 水分等参数光谱学检测的理论基础, 取得了重要进展[3]。
作物叶绿素光谱学检测中, 常通过筛选特征波长来达到解析光谱变量、 剔除冗余信息、 压缩计算量、 提高诊断模型精度与鲁棒性等目的[4]。 因为相关分析筛选变量存在高度自相关导致的多重共线性问题, 在主成分分析的基础上, 连续投影算法(successive projection algorithm, SPA)、 无信息变量消除法(uninformative variables elimination, UVE)、 间隔最小二乘波长选择方法(interval partial least square, iPLS)、 变量投影重要程度系数法(variable importance in the projection, VIP)等算法被用于筛选特征波长并建立诊断模型[5, 6]。
上述一次性建模筛选特征波长的方法, 数据处理易受样本个数的影响[7]。 针对此问题Li等提出基于模型集群思想的蒙特卡洛无信息变量消除(Monte Carlo uninformative variables elimination, MC-UVE)[8]、 随机蛙跳(random frog, RF)[9]、 竞争自适应重加权采样(competitive adaptive reweighted sampling, CARS)[10]等变量筛选算法。 有报道应用CARS算法设置迭代次数为50, 选取10个波长建立南瓜叶绿素检测模型, 精度为0.846。 郑涛等[11]采用MC-UVE算法迭代次数为500, 选出12个马铃薯叶绿素特征波长。 程萌等[12]基于RF算法筛选小麦叶绿素特征波长, 迭代次数为10 000, 选出8个最优波长。
此类研究中尚有如下问题需要深入讨论, 一方面应用不同算法选取变量是否存在差异, 建立的模型是否最优且稳健; 另一方面, MC-UVE, RF和CARS等算法中初始参数迭代次数普遍采用固定值, 修改迭代次数与其他约束是否对变量筛选结果有影响, 需要开展比较和分析。
因而, 在马铃薯作物叶绿素光谱学检测中, 分别应用MC-UVE, RF和CARS算法, 讨论迭代次数(number of iteration, N)参数和特征变量个数(latent variable, LV)对特征波长筛选结果的影响。 通过建立PLS模型, 阐明特征波长分布与叶绿素含量的解析能力, 以模型验证集精度为评价标准, 明确参数最优组合, 以期为马铃薯叶绿素光谱降维与高鲁棒性诊断建模奠定基础, 也为同类研究提供参考。
2018年在北京市昌平区小汤山国家精准农业示范基地开展实验, 马铃薯品种为“ 大西洋” 。 30 m× 40 m范围内设80个采样区, 在发棵期(M1)、 块茎形成期(M2)、 块茎膨大期(M3)和淀粉积累期(M4)4个生长期跟踪采集马铃薯冠层光谱并进行理化测试。
采用ASD FieldSpec HandHeld2 便携式地物光谱仪测定325~1 075 nm内751个波长处作物冠层光谱反射率, 采样间隔1 nm, 每点重复采集3次取平均值。 同步随机采集叶片经浸提后, 利用紫外分光光度计测定叶绿素含量, 测定方法参考相关文献。 每个生长期采集80组数据, 其中M1因植被覆盖度较低导致无效数据, 保留74组有效数据后, 全生长期共获取314组数据。 数据采集预处理总体流程如图1所示。 其中, 采用标准正态变量(standard normal variate, SNV)方法, 对原始光谱曲线进行预处理来消除环境噪声的干扰。 光谱与处理、 特征波长筛选以及PLSR建模均在matlab2014.a环境中完成。
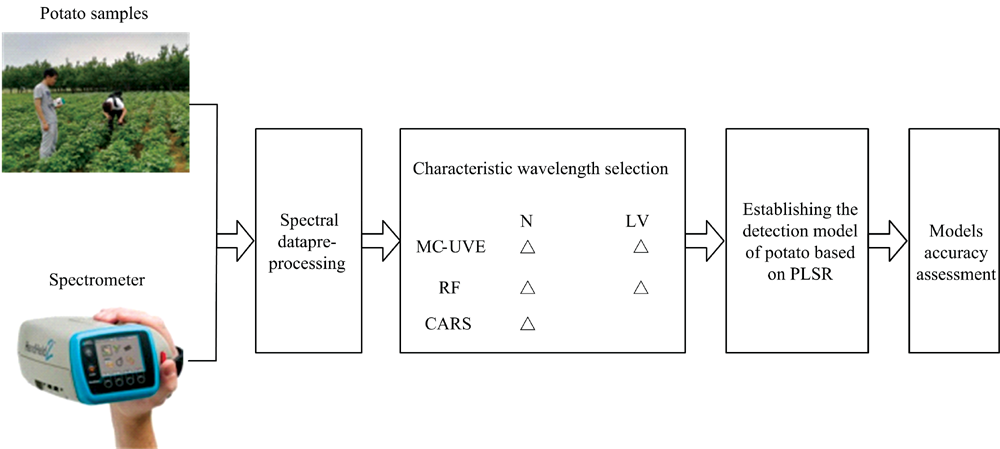 | 图1 数据处理总体流程图Fig.1 Flow chart of data processing |
基于模型集群分析的思想, 比较MC-UVE, RF和CARS 3种变量筛选算法, 在matlab2014.a libpls软件中实现。
(1)MC-UVE算法
MC-UVE算法基于偏最小二乘回归(partial least squares regression, PLSR)提出, 从训练集中取出一定数目(M个)样本构建PLS子集, 重复M次计算PLS回归系数矩阵, 引入变量稳定指数为筛选标准, 计算得到每个变量稳定指数值, 并从高到低排序筛选变量[6]。 其中, 保留的LV数量决定着模型的预测能力和模型的稳定性。
(2)RF算法
RF算法类似于可逆跳转马尔可夫链蒙特卡洛。 与PLSR相结合, 通过PLSR结果模拟一条服从稳态分布的马尔可夫链来计算每个变量被选择的概率, 从而进行重要变量的筛选[7]。
(3)CARS算法
CARS算法基于自适应重加权采样和指数衰减函数, 选取在PLSR模型中回归系数绝对值大的变量, 得到一系列波长变量子集; 然后对每个波长子集采用交叉验证建模, 从中挑选出模型均方根误差最小的子集[8]。 因此CARS算法筛选得到的特征变量个数一定。
为了检测作物叶绿素含量, 本研究以马铃薯作物为例, 对CARS算法的迭代次数(N)参数、 RF和MC-UVE算法的迭代次数(N)参数和特征变量数(LV)参数对叶绿素特征波长筛选结果的影响进行讨论。 迭代次数设置6个梯度, 分别为N=50, 100, 500, 1 000, 5 000和10 000; 特征变量数设置4个梯度, 分别为LV=15, 20, 25和30, 分析迭代次数(N)和特征变量数(LV)两个参数的最优组合情况。
利用偏最小二乘回归(PLSR)建模[13], 利用SPXY(sample set partitioning based on joint X-Y distance)算法分别在M1, M2, M3和M4个生长期按照3: 1的比例划分样本集, 采用留一交互验证法进行内部交互验证, 以交叉验证均方差(root mean square error of cross validation, RMSECV)为标准选取PLSR模型最优特征变量数。 特征波长筛选的结果以PLSR模型验证集模型决定系数(determination coefficients of validation set,
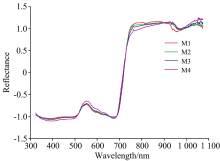
SNV校正后的各生长期的马铃薯冠层反射光谱曲线如图2所示, 总体而言, 在可见光波段, 由于色素体对蓝、 红光的强吸收存在400~500与611~710 nm低反射率区, 并在400和680 nm附近出现吸收谷; 520~610 nm体现为色素体的强反射, 550 nm附近为绿色反射峰。 受到叶肉内海绵组织结构内的空腔反射率增强影响, 近红外711~760 nm快速攀升后进入761~1 000 nm高反射平台区, 其中970 nm附近出现水分的微弱吸收谷。 由M1至M4推进, 在400~500和740~880 nm反射率降低; 在530~640和910~960 nm反射率升高, 且M4和M1分别呈现与其他生长期较大的差别。 综上说明作物光谱响应是对植物生长过程中色素体、 水分分子、 结构等的综合表现, 针对叶绿素指标, 挖掘全谱中特征波长十分必要。
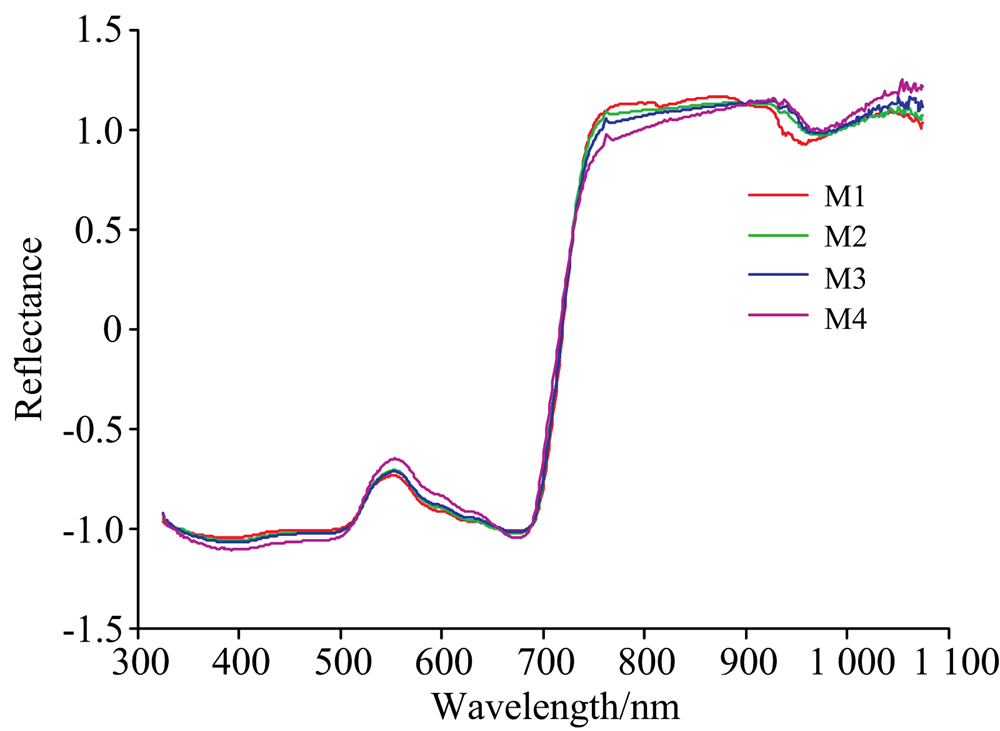 | 图2 SNV处理后生长期冠层平均反射光谱曲线Fig.2 Average spectrum of growth potato after SNV |
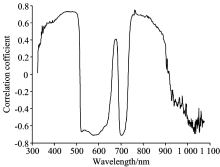
分析光谱反射率与叶绿素含量的相关性, 结果如图3所示。 在387~509, 519~633和744~844 nm波段, 二者相关系数绝对值(|r|)均高于0.6, 在678 nm达正相关峰值0.411; 在702 nm存在负相关峰值-0.715。 845~917 nm正相关系数逐渐降低, 917 nm之后呈负相关。 此结果与叶绿素吸收可见光蓝、 红光, 反射绿光的物理现象一致, 但相关性曲线显示相邻波长之间的相关系数接近。 若选取相关系数较高者为特征波长, 会存在波长冗余与多重共线性问题。 因此, 利用SPXY算法划分样本集结果如表1所示, 后续建模开展特征波长变量筛选方法讨论, 用建模集筛选特征波长、 建立回归模型, 以验证集的结果评价特征波长筛选结果。
 | 图3 光谱反射率与叶绿素含量相关性曲线Fig.3 Correlation between reflectance and chlorophyll content |
| 表1 建模集与验证集划分统计 Table 1 Statistical results of calibration set and validation set |
2.3.1 MC-UVE算法
由于MC-UVE算法对于同一批光谱数据, 设置同样的迭代次数, 运行多次计算变量的稳定指数不一致, 因此分别讨论迭代次数(N)和特征波长数量(LV)的影响。
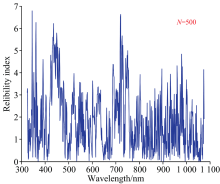
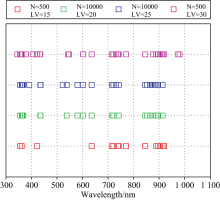
首先设置N分别为50, 100, 500, 1 000, 5 000和10 000次6个迭代梯度, 运行5次计算各个波长变量所对应的稳定指数平均值。 以N=500为例, 运行结果如图4所示, 稳定指数越高代表此波长变量越具有信息价值。 然后对6个迭代梯度改变LV, 按照稳定指数从高到低选择LV为15, 20, 25和30个建立马铃薯叶绿素检测PLSR模型。 共得到24种模型, 结果如表2所示。 当N值增加并未有效提升检测模型精度, 但是LV增加时, 建模特征变量增多可以提升建模型精度。 其中N=50时其特征波长的位置分布如图5所示, 精度最优的模型为LV=30时, 预测集精度
 | 图4 MC-UVE算法在迭代次数为500时的运行结果Fig.4 Run results of MC-UVE at N=500 |
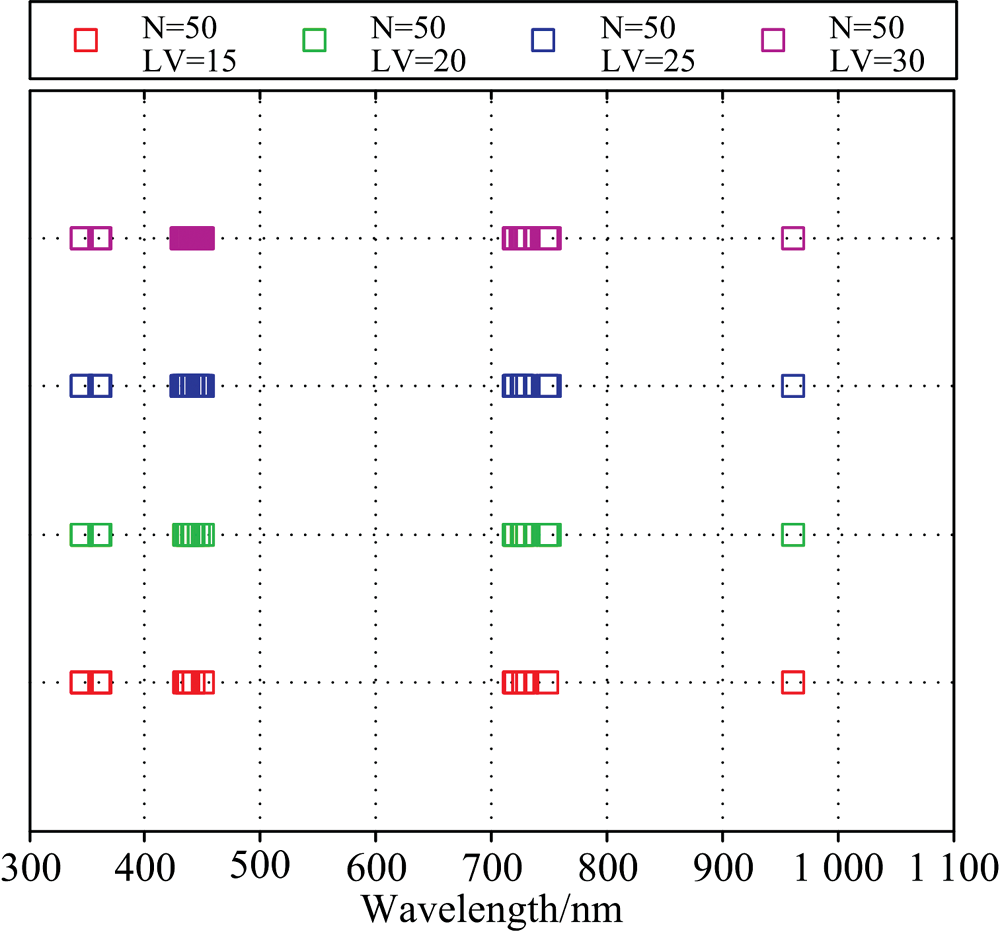 | 图5 MC-UVE在LV梯度下最佳迭代次数时特征波长位置Fig.5 Wavelengths selected by MC-UVE at LV gradients |
由图5对比相关性分析结果可知, N=50时LV从15增至30过程中, 被选取的波长数在400~500和720~800 nm范围增加。 该区间相关系数绝对值|r|> 0.6, 但是并未体现红光吸收特征, 使得该类马铃薯叶片叶绿素含量诊断模型验证集
| 表2 基于MC-UVE的叶绿素含量检测PLSR模型验证集结果(RMSEV: mg· L-1) Table 2 PLSR validation results on the chlorophyll content detection using MC-UVE (RMSEV: mg· L-1) |
2.3.2 RF算法
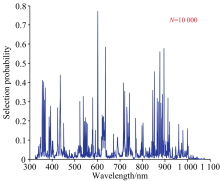
RF算法与MC-UVE算法类似, 首先讨论迭代次数N的影响, 分别设置N为50, 100, 500, 1 000, 5 000和10 000次6个梯度, 运行5次取平均值。 以N=10 000为例的运行结果如图6所示, 纵坐标为每个波长的被选择概率(selection probability), 被选择概率越高说明波长越重要。 其次讨论波长个数LV的影响, 按照选择概率从大到小设置LV分别为15, 20, 25和30建立马铃薯叶绿素检测PLS模型, 共得到24种模型。
 | 图6 RF算法在迭代次数为10 000时的运行结果Fig.6 Results of RF algorithmat N=10 000 |
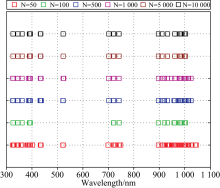
结果如表3所示, 整体而言N值增加使模型精度提升有限, LV增加模型精度上升趋势明显。 较优的组合选取特征波长结果如图7所示, 包括: N=500时LV为15或30组合, 与N=10 000时LV为20或25组合, 马铃薯叶片叶绿素含量诊断模型验证集
| 表3 基于RF在不同输入参数下的叶绿素含量检测PLSR 模型验证集结果(RMSEV: mg· L-1) Table 3 PLSR validation results on the chlorophyll content detection using RF with different setting(RMSEV: mg· L-1) |
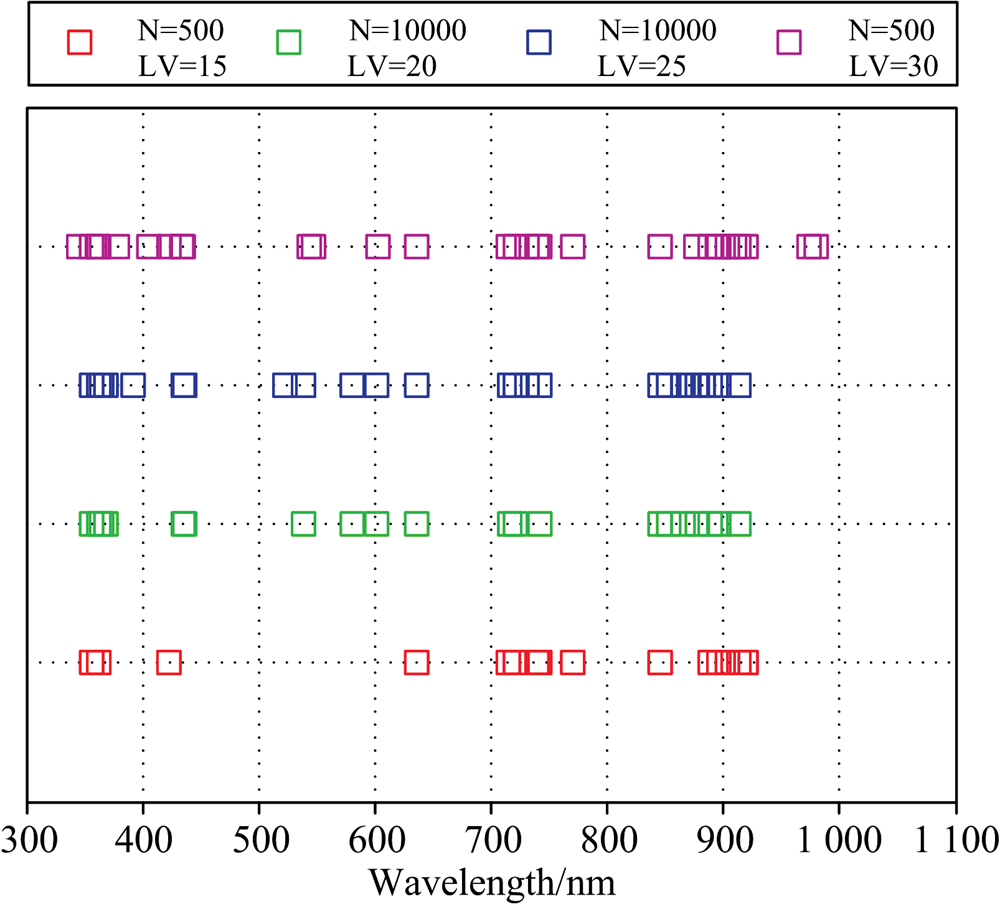 | 图7 RF在四种LV梯度下最佳迭代次数时特征波长位置Fig.7 Wavelengths selected by RF algorithm at LV gradients |
由图7对比相关性分析结果可知, 在LV从15增至30过程中分布愈加广泛, 反映的信息愈加全面。 在LV=15时, 在绿光区域没有筛选到特征波长, 而在LV=20, 25和30时, 筛选到的特征波长在蓝、 绿、 红区域均有分布。 LV=30时, 970 nm附近反映水分弱吸收的波长被选中, 说明该方法筛选波长对含氢基团具有较好的选择性。
2.3.3 CARS算法
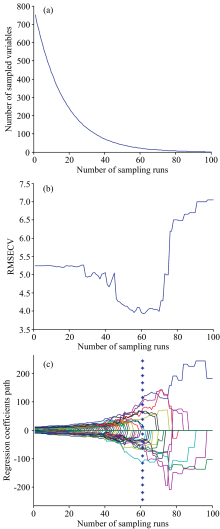
CARS算法与RF和MC-UVE不同, 对于同一批数据, 在相同的迭代次数(N)下变量筛选结果唯一, 所以仅考虑设置N为50, 100, 500, 1 000, 5 000和10 000次6个梯度。 N=100时的运行结果如图8所示, 图8(a)为筛选过程中变量数随着迭代次数N的变化曲线, 筛选的波长数(LV)随运行次数的增加而减少; 图8(b)为RMSECV随着迭代次数的变化曲线, 在前30次时RMSECV保持不变, 30次后下降, 在迭代61次时RMSECV的值最小为3.928, 之后逐步攀升; 图8(c)为各光谱波长的回归系数的变化趋势, 其中“ * * ” 列表示RMSECV最小时所对应的迭代运行次数。 运行后得到的波长变量集采用交叉验证, 根据RMSECV的值来确定最优波长变量子集为21个特征波长。
 | 图8 CARS在迭代次数N为100时运行结果 (a): 选择变量个数变化趋势; (b): RMSECV变化趋势; (c)回归系数变化趋势Fig.8 Results of CARS algorithm at N=100 (a): Trend of selected variable number; (b): Trend of RMSECV; (c): Trend of regression coefficient |
CARS算法筛选得到的特征波长位置如图9所示, 分别建立叶绿素诊断PLSR模型结果如表4所示, 当N值增加时CARS筛选得到的最优变量个数呈先上升后下降趋势; 参与建模波长数增加并不能提升诊断模型精度, 马铃薯叶片叶绿素含量诊断模型
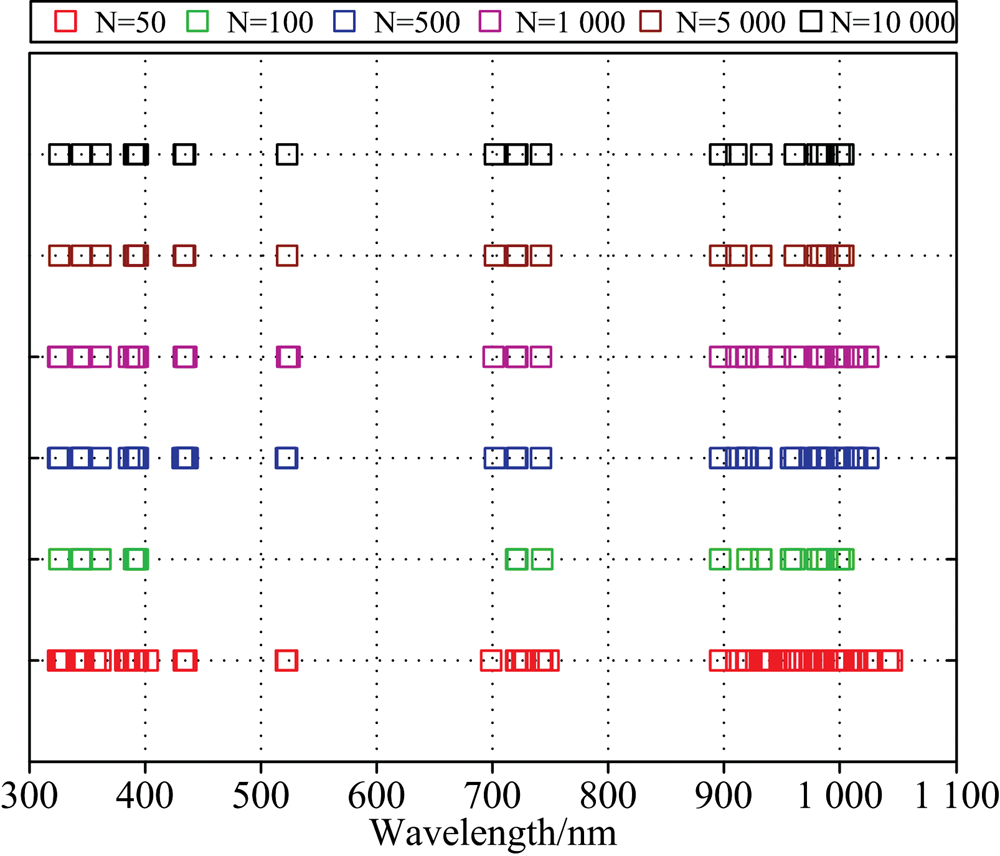 | 图9 CARS算法不同迭代筛选到的特征波长位置Fig.9 Location of wavelengths selected by CARS |
| 表4 基于CARS算法不同迭代次数的叶绿素含量检测 PLSR模型验证集结果(RMSEV: mg· L-1) Table 4 PLSR validation results on the chlorophyll content detection with iteration of CARS(RMSEV: mg· L-1) |
由图9对比相关性分析结果可知, 在N=50时, 筛选得到的特征波长存在显著“ 边缘指纹效应” , 即在325~500和900~1 100 nm区域信息冗余与噪声降低了模型精度和鲁棒性, 所以N=50时模型的验证集精度最低。 与其他迭代次数相比, N=100时在900~1 000 nm范围波长数精简, 冗余信息较少; N=5 000和N=10 000时, 筛选得到的特征波长基本一致。 其中, N=100时选取21个特征波长建立的模型最优, 预测集精度
综合上述三种方法, 当N值或LV个数增加时模型验证精度得到一定提升, 其中LV对MC-UVE算法影响较为显著, 马铃薯叶片叶绿素含量诊断验证集
| 表5 MC-UVE-PLSR, RF-PLSR和CARS-PLSR验证集结果 Table 5 Results of validation set of MC-UVE-PLS, RF-PLS and CARS-PLS |
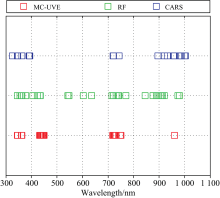
对比分析MC-UVE, RF和CARS筛选的最优特征波长, 位置如图10所示, 从特征波长分布角度, 在可见光范围(400~710 nm), RF算法筛选波长分布均匀; MC-UVE算法对550 nm附近绿光区域不敏感, 而在450 nm附近蓝光区域“ 波长聚集” 现象显著; CARS算法对该区域筛选变量较少。 在近红外区域(711~1 100 nm), RF算法得到的特征波长分布仍然较为均匀; MC-UVE在800~1 000 nm只筛选到一个特征波长; CARS筛选到的特征波长均聚集在900~1 000 nm内。 综上说明RF算法在可见光和近红外区筛选得到的特征波长对叶绿素光谱吸收和反射等特征具有较为全面的代表性。
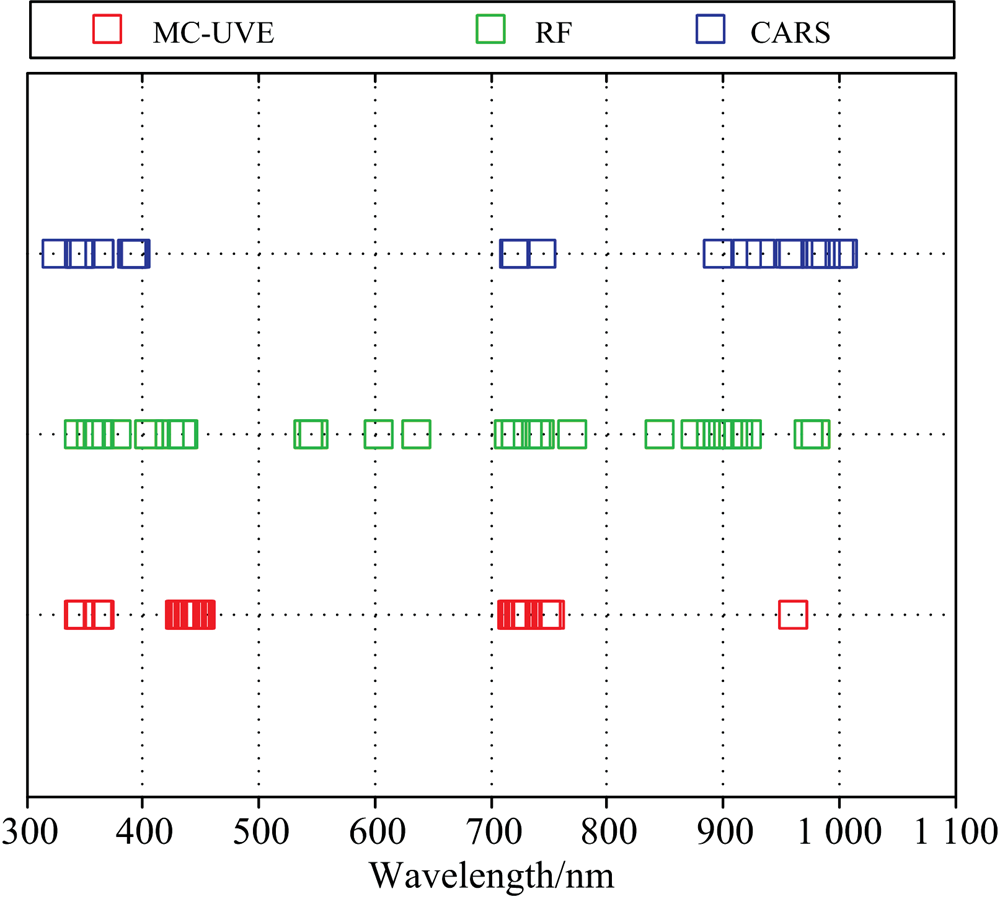 | 图10 MC-UVE, RF和CARS最优特征波长位置Fig.10 Wavelengths selected by optimal MC-UVE, RF, CARS |
从相关性的角度考虑, RF算法筛选得到的特征波长在叶绿素高相关范围(387~509, 519~633, 744~844和845~917 nm)和相关性峰值(702 nm)均有分布。 而MC-UVE算法筛选变量只在387~509和744~844 nm两个范围, CARS算法筛选变量则只有391, 392, 393, 394和896 nm五个波长落入高相关性范围内, 且前四个为相邻波长而存在波长信息冗余。 上述结果在PLSR模型中也得到了验证, RF-PLSR模型的精度最优, MC-UVE-PLSR模型次之, CARS-PLSR模型最差。
综上表明, 当合理选择N和LV参数时, RF算法对马铃薯叶绿素特征波长筛选能力优于MC-UVE和CARS两种算法, 同时也避免了高相关性区间筛选相邻波长存在的高度自相关导致的多重共线性问题。 所建立的RF-PLSR模型可为马铃薯叶绿素含量诊断提供支持, 而研究讨论的变量筛选方法与参数分析过程, 可为其他同类光谱学检测提供参考。
为了高精度地检测马铃薯作物叶绿素含量, 利用基于模型集群思想的CARS, RF和MC-UVE三种算法筛选叶绿素特征波长, 建立叶绿素含量检测PLS模型。 以PLS模型验证集结果为评价指标, 讨论三种算法的迭代次数(N)和特征变量个数(LV)参数对模型结果的影响, 确定三种算法的最佳输入参数组合, 对比分析MC-UVE, RF和CARS筛选的最优特征波长, 结论如下:
对叶绿素含量和光谱数据做相关性分析, 发现在387~509, 519~633和744~844 nm三个波段内, 叶绿素含量与光谱反射率的相关系数较高, 其相关系数绝对值均高于0.6; 在678和702 nm处存在相关性极值, 相关系数分别为0.411和-0.715。
当N值或LV个数增加时各算法模型验证精度得到提升, 其中LV对MC-UVE算法影响较为显著, 马铃薯叶片叶绿素含量诊断验证集
对比分析基于三种算法选取最优特征波长建立的叶绿素PLS检测模型可知: 迭代次数N=500、 特征变量数LV=30时, RF-PLSR模型性能最优,
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|