
{kind=link}
{kind=link}
{kind=link}
近红外技术的广西速生桉抽出物含量测定与模型优化
[朱华1, 2  , 吴珽
, 吴珽2, 3 , 房桂干2, 3 , 梁龙2, 3 , 朱北平2, 3 , 佘光辉1, 2, * ]
, 吴珽]
|
|


作者简介: 朱 华, 女, 1975年生, 南京林业大学林学院博士研究生 e-mail: jecy_zhu@163.com
为解决速生桉抽出物测定方法繁琐耗时, 木浆生产能耗居高不下等问题, 以引种的3种广西速生尾巨桉原料(DH32-29, DH32-26, DH33-27)为研究对象, 采集了144个样本的近红外光谱, 按国标方法测定全部样品的苯醇抽出物和1%NaOH抽出物含量。 在Matlab 8.0中采用信号平滑, 一阶、 二阶导数, 矢量归一化, 多元散射校正等方法预处理原始光谱, 用偏最小二乘法、 支持向量机法和人工神经网络法以及常用于宏观经济分析的LASSO法分别结合上述预处理方法建立模型, 筛选出最优建模方法。 运用遗传算法对波段进行选择, 提高了模型的精确度从而优化了模型。 确定了建立苯醇抽出物含量模型时, 可联用平滑、 MSC和一阶导数预处理光谱数据, 以1 345.0~1 821.4和2 127.8~2 241.3 nm区间波段参与建模, 建模方法为偏最小二乘法, 最佳主成分数为9时, 模型有最好的精确度。 其RMSEP值可达0.25%, 绝对偏差范围为-0.39%~0.38%。 筛选出的波段包含了如1 410和1 447 nm附近酚羟基伸缩振动的一级倍频, 2 133 nm处苯环上碳氢键的伸缩振动与碳碳双键伸缩振动的合频等苯醇抽出物的特征波段。 建立1%NaOH抽出物分析模型时, 可联用平滑、 矢量归一化和一阶导数预处理, 选择1 138.2~2 363.0 nm波段数据, 建模方法为LASSO, 选取的调整参数值 μ为12.61, 此时模型精确度最高。 RMSEP值为0.37%, 绝对偏差范围为-0.56%~0.53%。 筛选出的波段包含了1 158和1 170 nm附近乙酰脂基团CH3中C—H的伸缩振动二级倍频吸收, 1 666, 1 681和1 790 nm附近CH3中C—H伸缩振动的一级倍频吸收等特征吸收。 模型的预测能力从组分结构角度得到了解释。 模型的RPD值分别为4.67和5.77, 模型性能均可满足实际需求, 有望应用于制浆造纸生产线上的速生桉抽出物含量分析。 研究结果表明, 通过预处理方法选择和建模方法选择, 结合遗传算法的应用, 可以建立并优化广西速生桉木抽出物含量的近红外测定模型; 同时, LASSO算法作为一种新兴算法, 在近红外光谱分析中表现出了较好的处理共复线性数据的能力, 可以建立准确性较好的分析模型。
In pulping and papermaking industry, extractives of wood chips influence the impregnation efficiency, pulp energy consumption and pulp yield. But traditional analysis methods for the content of extractives are not applicable for industrial online monitoring because of being time consuming and costly. Therefore, the present study used near infrared (NIR) spectroscopy to predict rapidly extractives content of three species of fast-growing Eucalyptus urophylla× E.grandi chips (DH32-29, DH32-26, DH33-27) grown in China’s Guangxi Province. NIR spectra of 144 fast-growing Eucalyptus were collected using a holographic grating spectrometer equipped with a halogen illumination and array detector. The benzene-alcohol extractives and 1% NaOH extractives content of 144 samples were gravimetrically determined according to the Chinese national standard test method respectively. The near-infrared spectrum were pretreated using smoothing, first derivative, second derivative, vector normalization and multivariate scattering correction in Matlab 8.0, and the models were developed for various pretreatment methods by loading PLS, LASSO, SVR and ANN algorithm. The optimal modeling methods were selected. Genetic algorithm was used to select the bands, which improved the accuracy of the models and optimized the models. In conclusion, in order to develop analysis model of benzene-alcohol extractives, smoothing, MSC and first derivative methods should be used to preprocess the original spectrum, the bands of 1 345.0~1 821.4 and 2 127.8~2 241.3 nm were selected, meanwhile, the partial least squares algorithm was used with the optimal factor 9. The model had the best accuracy for the RMSEP value as low as 0.25%, and the absolute deviation range was -0.39%~0.38%. The optimal bands between 1 345.0~1 821.4 and 2 127.8~2 241.3 nm have been associated with O—H stretching (1st overtone) of phenolic compound (1 410 and 1 447 nm), as well as C—H stretching and C=C stretching group frequencies of benzene ring (2 133 nm) and other characteristic absorption. In order to establish the content analysis model of 1% NaOH, smoothing, vector normalization, first derivative should be used to pretreat the original data, the bands between 1 138.2~2 363.0 nm were picked and LASSO was adopted. The model had the best accuracy when the μ value was 12.61, the independent verification show the RMSEP value was 0.37%, and the absolute deviation range was -0.56%~0.53%. The optimal bands between 1 138.2~2 363.0 nm have been associated with C—H stretching (2nd overtone) of -C=OCH3 (1 158 and 1 170 nm), as well as C—H stretching (1st overtone) of —CH3 (1 666, 1 681 and 1 790 nm) and other characteristic absorption. The characteristic absorption of benzene-alcohol extractives and 1% NaOH extractives on the optimal bands was analyzed from the point of view of molecular structure, and the performance of models was explained theoretically. The models can meet the actual demand and can be applied to the analysis of the content of Eucalyptus extractives in pulping and papermaking industry. The results showed that performance of near-infrared models can be developed and optimized by the selection of pretreatment and modeling methods combined with the genetic algorithm for the prediction of Eucalyptus extractives. At the same time, as an emerging algorithm, LASSO algorithm has a good ability to process co-complex linear data in near-infrared spectroscopy, and can establish models with good analysis performance.
近年来宏观政策对进口废纸配额的限制, 影响了国内纸浆生产市场, 制浆造纸原料短缺的形势越发严峻。 与此同时, 草浆因污染重, 运输成本高等原因产量增速缓慢, 本应得到大力发展的木浆, 因天然林禁伐, 生态林保护等原因, 年进口比例超过了50%的警戒线。 因此, 加大国内速生林发展投入, 合理选择培育树种, 科学规划提高利用质量已成为增加国产优质木浆产量, 填补制浆造纸原料短缺的唯一出路[1]。 桉树作为南方人工速生林主要培育树种, 有着轮伐期短, 年生长量高的优势, 在两广、 海南、 云南等地区广泛种植。 桉树采伐后以木片原料的形式来到制浆生产线, 而各批次木片因生长来源情况, 运输保存时间的不同, 化学成分存在着较大的差异, 这些差异对桉木浆生产的药品用量, 能耗以及成浆质量有很大影响。 其中, 综纤维素/纤维素决定了木浆的得率, 而一些含量较少的抽出物也起着重要的作用, 如苯醇抽出物可用于表征制浆过程中的树脂沉积物障碍, 且与纸浆着色返黄相关; 1%NaOH抽出物则与原料腐朽变质程度有关。 因此, 研究木片原料抽出物含量的快速测定技术, 摆脱传统抽出物含量测定的繁琐耗时, 根据各批次木片抽出物含量情况实时调整制浆用药水平和电耗, 有利于木浆生产提质降耗目标的实现。
近红外光谱作为高效, 无损的分析方法, 在农业生产[2], 生物化学[3]等方面都得到了广泛的应用。 制浆造纸行业中分析检测项目多, 测试步骤繁琐, 前人尝试运用近红外技术实现原料鉴别分类[4], 卡伯值预测[5]的智能化控制, 已取得一定成果。 而在制浆原料抽出物分析方面, 因取样难度大, 抽出物含量较低且成分复杂, 光谱信息干扰严重, 基于近红外光谱的传统回归算法对其拟合建模效果往往不佳。 本研究以广泛种植的速生桉— — 尾巨桉杂交品系(DH32-29, DH32-26, DH33-27)为研究对象采集近红外光谱, 通过多种建模算法对比分析, 发现传统的偏最小二乘法适用于建立苯醇抽出物分析模型, 而在分析1%NaOH抽出物时, 采用LASSO算法压缩建模回归系数, 可以更有效的解决光谱数据共复线性问题, 得到更加精确的分析模型。 在此基础上结合遗传算法筛选特征波长变量, 提高了模型的预测性能和稳健性, 实现了广西速生桉中苯醇抽出物、 1%NaOH抽出物含量的快速分析测定。
选择广西速生尾巨桉杂交品系三个主要品种(DH32-29, DH32-26, DH33-27), 由金华林业原料林基地提供, 引种自广西东门林场, 树龄均为6年。 每个品种在树干不同部位截取48个圆盘为样本, 去皮, 经切片机切割后置于空气中充分平衡水分, 用粉碎机将木片磨成木粉, 经振动筛筛分出粒径40~60目之间的木粉, 同样平衡水分后作为样品, 共计144个。 每个品种以含量梯度法按3∶ 1的比例筛选12个样品作为验证集; 其余108个样品作为训练集, 用于速生桉苯醇抽出物、 1%NaOH抽出物模型的建立。
所使用近红外光谱仪器应能适应制浆造纸生产线复杂环境, 成本低廉且结构简单, 易于组装搭建, 因此选用上海复享光学股份有限公司的全息光栅分光(阵列检测器)近红外光谱仪NIR2500, 采集速生桉样品的近红外漫反射光谱。 设定仪器参数如下: 光谱范围900~2 500 nm, 信噪比为6 800∶ 1, 波长点数为256个。 采集光谱时, 取3~4 g木粉样品置于底部为石英玻璃的上置式样品杯中, 并用250 g砝码压住木粉样品以保证样品紧实度的一致性, 光源经光纤探头从样品杯底部照射样品。 每个样品重复取样3次, 取其平均光谱作为该样品代表性光谱。
用传统实验室方法(GB/T 2677.6— 1994, GB/T 2677.5— 1993)测定全部144个速生桉样品的苯醇抽出物和1%NaOH抽出物含量, 每个样品测3组平行数据, 以平均值作为样品测定值。
选择了常见的光谱预处理方法分别与偏最小二乘法(PLS), LASSO法, 支持向量机法(SVR)和人工神经网络法(ANN)结合建模, 得出两种抽出物含量分析的最优建模方法, 并通过遗传算法(genetic algorithm, GA)进行波段选择, 进一步优化模型。
其中LASSO法在近红外光谱分析中应用较少, 该算法主要原理是通过增加约束条件, 令回归系数的绝对值之和小于可调整的常数, 并最小化残差平方和, 将次要项、 干扰项的回归系数压缩为零, 从而使得所建模型更为准确。
设有P个自变量x1, x2, …, xp和因变量y, 满足
式中α 是常数项, β 1, β 2, …, β p是回归系数, ε 是随机误差项。
设(xi1, xi2, …, xip; yi), i=1, 2, …, n, 是自变量x1, x2, …, xp的观测值, 对其中心标准化, 即:
对回归系数的绝对值和进行惩罚
式(2)中λ ≥ 0是约束常数。 数据经过了中心标准化, 因此对任意约束常数λ ≥ 0, α 都存在解
其中μ 是惩罚系数。 随着μ 的增加, 最优解的
以
三种速生桉共计144个样本的抽出物含量如表1所示。 其中DH32-26样本的苯醇抽出物含量较高, 分布在1.07%~5.01%之间, DH32-29和DH33-27的苯醇抽出物含量分布没有显著差异, 均分布在0.85%~3.96%之间。 DH32-26和DH33-27的1%NaOH抽出物含量较低, 分布在11.65%~16.92%之间, DH32-29的1%NaOH抽出物含量分布较宽, 约11.61%~20.16%。 速生桉样本的两种抽出物含量分布较宽, 据此可建立有代表性的分析模型。
| 表1 样品含量分布情况 Table 1 Content distribution of samples |
控制实验室温度(20± 0.5)℃, 采集全部速生桉样品的近红外光谱, 如图1所示, 横坐标表示波长, 纵坐标表示漫反射吸光度。 速生桉样品成分结构复杂, 除了含量较少的苯醇抽出物(包括树脂、 蜡、 脂肪等), 1%NaOH抽出物(无机盐、 糖、 植物碱等)之外, 还含有作为主成分存在的纤维素、 半纤维素等多糖类及芳香族高聚物。 为降低无关信息影响, 需对速生桉原始光谱进行预处理。
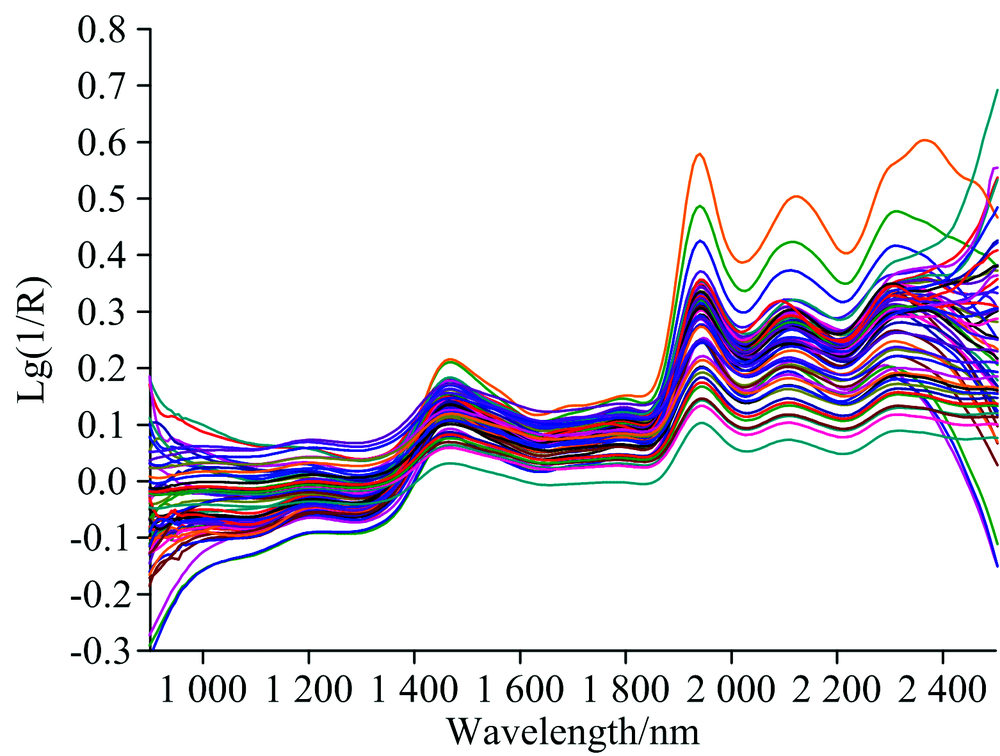 | 图1 速生桉样品近红外光谱Fig.1 The near infrared spectra of Fast-growing Eucalyptus |
常见预处理方法针对性较强, 如信号平滑可用于降低噪声, 导数则用于消除基线和背景干扰, 矢量归一化和多元散射校正用于消除光程变化和非特异性散射的影响[7]。 在Matlab8.0中将预处理方法组合联用处理原始光谱数据, 以期获得更好的效果, 并结合PLS, LASSO, SVR和ANN法对训练集样本进行五折交叉验证建模分析, 确定分别适用于分析苯醇抽出物和1%NaOH抽出物的预处理和建模方法, 16个模型的性能见表2。 可见当采用平滑、 MSC、 一阶导数的方法预处理原始光谱[图2(a)], 运用偏最小二乘法建立苯醇抽出物含量分析模型时,
| 表2 不同抽出物不同建模方法的模型评价 Table 2 Evaluation of models for different extractives using different modeling methods |
 | 图2 速生桉原始光谱的预处理 (a): 苯醇抽出物; (b): 1%NaOH抽出物Fig.2 Pretreatment of original spectra of Fast-growing Eucalyptus (a): Benzene-alcohol extractives; (b): 1% NaOH extractives |
仪器的近红外光谱区域为900~2 500 nm, 该区间包含一些无关或干扰信息, 可能影响模型的精确度和稳健性。 因此采用遗传算法(genetic algorithm, GA)结合相应的建模方法分别筛选出光谱中与苯醇抽出物和1%NaOH抽出物有较强相关性的波长变量, 以期建立更加稳健的分析模型。 对256个波长点分别进行二进制编码, 以“ 1” 代表该波长点被选中, 以“ 0” 代表该波长被剔除, 设定筛选波长数目范围为5~200, 种群规模100, 进化代数500, 交叉概率0.8, 变异概率0.1。
对于苯醇抽出物, 将每代筛选出的波长变量子集进行偏最小二乘建模, 以RMSECV作为适应度评价指标。 最终筛选出的最优波段为1 345.0~1 821.4和2 127.8~2 241.3 nm。 苯醇抽出物中含有树脂、 蜡、 脂肪、 固醇等, 同时还有少量单宁和色素, 该波段存在苯醇抽出物的特征吸收: 如1 360 nm附近C— H伸缩振动二级倍频和C— H变形振动的合频, 其中C— H来自抽出物中有机物所含的CH3; 1 410和1 447 nm附近酚羟基伸缩振动的一级倍频, 酚羟基来源于单宁和色素; 1 668 nm处苯环上C— H伸缩振动的一级倍频, 苯环上的C— H同样来源于单宁和色素。 1 695和1 721 nm处存在CH3中C— H的伸缩振动一级倍频; 1 820 nm附近存在O— H伸缩振动和C— O伸缩振动二级倍频的合频, 这类羟基和碳氧基源于抽出物中所含的固醇; 而2 133 nm附近苯环上存在C— H的伸缩振动和C=C伸缩振动的合频, 这两种官能团可能来自于色素[8, 9]。
对于1%NaOH抽出物, 将每代筛选出的波长变量子集进行LASSO法建模, 以RMSECV作为适应度评价指标。 最终筛选出的最优波段为1 138.2~2 363.0 nm。 1%NaOH抽出物中除了包含部分无机盐类、 环多醇以及多糖类如胶、 植物粘液、 淀粉等, 还含有一部分溶出的木质素、 聚戊糖、 树脂酸及糖醛酸, 成分复杂。 筛选出的波段包含了1 158和1 170 nm附近聚戊糖乙酰脂基团CH3中C— H的伸缩振动二级倍频吸收; 1 666 nm(聚戊糖)、 1 681 nm(聚戊糖)、 1 790 nm(木质素)附近CH3中C— H伸缩振动的一级倍频吸收; 2 133 nm附近苯环C— H伸缩振动和C=C伸缩振动合频的吸收, 两种官能团均源于木质素; 2 329 nm处C— H伸缩振动和C— H变形振动的合频吸收, C— H来自于聚戊糖; 2 360 nm附近则存在O— H变形振动和C— H伸缩振动合频的吸收, 同样源于纤维素[10, 11]。 用所得模型分析验证集样品光谱, 见表3, 可见通过遗传算法筛选出的波段所建立的抽出物分析模型比全波段建立的抽出物模型性能更好,
| 表3 不同波段所建抽出物模型评价 Table 3 Evaluation of models for extractives developed from different bands |
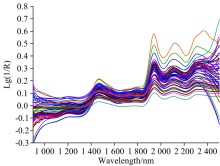
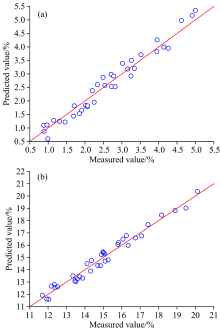
有着更低的RMSEP值和更小的绝对偏差范围。 一定程度上可以减少分析时间, 同时提升了模型精确度。 两种抽出物模型RPD值分别为4.67和5.77, 均高于3, 模型可用于质量控制。 根据独立验证情况作测定值-预测值散点图(图3), 所得点在斜率为45° 的直线两侧分布较为均匀, Bias值分别为-0.003 89%和-0.005 28%, 均小于0.01%, 可以认为模型不存在系统误差。
 | 图3 测定值-预测值散点分布 (a): 苯醇抽出物; (b): 1%NaOH抽出物Fig.3 The distribution of scattered points of measured value and predicted value (a): Benzene-alcohol extractives; (b): 1% NaOH extractives |
利用近红外技术结合多种预处理方法和化学计量学算法, 建立了广西速生桉木的抽出物分析模型并通过遗传算法对模型进行了优化。 确定了建立苯醇抽出物分析模型的方法为: 平滑、 MSC、 一阶导数预处理, 1 345.0~1 821.4和2 127.8~2 241.3 nm近红外波段参与建模, 建模方法为偏最小二乘法。 建立1%NaOH抽出物分析模型的方法为: 平滑、 矢量归一化、 一阶导数预处理, 1 138.2~2 363.0 nm区间波段参与建模, LASSO法建立模型。 针对广西速生桉抽出物进行近红外分析, 模型性能较好, 能够满足原料抽出物快速分析测定的要求; 同时创新性的在近红外光谱建模分析中引入LASSO算法, 为有效解决光谱数据的共复线性问题提供了更多的选择。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|