

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度架构网络的矮新星自动分类研究
[赵永健 , 郭瑞, 王璐瑶, 姜斌
, 郭瑞, 王璐瑶, 姜斌* ]
, 郭瑞, 王璐瑶, 姜斌]
|
|


作者简介: 赵永健, 1968年生, 山东大学(威海)机电与信息工程学院副教授 e-mail: zhaoyj@sdu.edu.cn
矮新星是一类特殊而稀少的半相接双星。 发现更多的矮新星对于深入研究物质转移理论、 理解密近双星演化过程意义深远。 利用深度学习技术提取天体光谱特征并进而分类是天文数据处理领域的研究热点。 传统的自编码器是仅包含一个隐层的经典神经网络模型, 编码能力有限, 数据表征学习能力不足。 模块化拓宽神经网络的深度能够驱使网络继承地学习到天体光谱的特征, 通过对底层特征的逐渐抽象学习获得高层特征, 进而提高光谱的分类准确率。 以自编码器为基础构建了由输入层、 若干隐藏层和输出层组成的基于多层感知器架构的深度前馈堆栈式自编码器网络, 用于处理海量的光谱数据集, 挖掘隐藏在光谱内部具有区分度的深度结构特征, 实现对矮新星光谱的准确分类。 鉴于深度架构网络的参数设置会严重影响所构建网络的性能, 将网络参数的优化分为逐层训练和反向传播两个过程。 预处理后的光谱数据先由输入层进入网络, 再经自编码器算法和权值共享实现对网络参数的逐层训练。 反向传播阶段将初始样本数据再次输入网络, 以逐层训练所得的权值对网络初始化, 再把网络各层的局部优化训练结果融合起来, 根据所设置的输出误差代价函数调整网络参数。 反复地逐层训练和反向传播, 直到获得全局最优的网络参数。 最后由末隐层作为重构层搭建支持向量机分类器, 实现对矮新星的特征提取与分类。 网络参数优化过程中利用均值网络思想使网络隐层单元输出按照dropout系数衰减, 并由反向传播算法微调整个网络, 从而防止发生深度过拟合现象, 减少因隐层神经元间的相互节制而学习到重复的数据表征, 提高网络的泛化能力。 该网络分布式的多层次架构能够提供有效的数据抽象和表征学习能力, 其特征检测层可从无标注数据中隐式地学习到深度结构特征, 有效刻画光谱数据的非线性和随机波动性, 避免了光谱特征的显式提取, 体现出较强的数据拟合和泛化能力。 不同层之间的权值共享能够减少冗余信息的干扰, 有效化解传统多层次架构网络易陷入权值局部最小化的风险。 实验表明, 该深度架构网络在矮新星分类任务中能达到95.81%的准确率, 超过了经典的LM-BP网络。
Dwarf nova (DN) is a special and rare class of semi-contiguous binary star. To discovery more DNs is significant for the further study of matter transfer theory. It also has been profound for understanding the evolution of close binary stars. It is a research hot spot to extract features of celestial spectra and then classify them by deep learning. Traditional auto-encoder is a classical neural network model with only one hidden layer. However, its coding ability is limited and data representation learning ability is insufficient. Broadening the depth of the neural network with modularity can make the network learn features of the celestial spectrum successively. High-level features can be obtained through gradual abstract learning of underlying features so as to improve the spectral classification accuracy. In this paper, a deep feedforward stack network is constructed consisting of an input layer, several hidden layers and an output layer on the basis of auto-encoder. This network with multi-layer perceptron architecture is utilized to process massive spectral data sets. It excavates the depth structure features hidden in the spectra and realizes the accurate classification of DN spectra. Parameters set for the network with deep architecture will seriously affect the performance of the constructed network. In this paper, the optimization of network parameters is divided into two processes: hierarchical training and inverse propagation. The preprocessed spectral data first enter the network from the input layer, and then the network parameters are trained layer by layer with the auto-encoder algorithm and weight sharing policy. In the reverse propagation stage, the initial sample data are input into the network again, and the network is initialized with the weights obtained from the hierarchical training process. Then the local optimization training results of each layer are fused and the network parameters are adjusted according to the set output error cost function. Hierarchical training and inverse propagation are operated repeatedly until the global optimal network parameters are obtained. Finally, the last hidden layer is adopted as the reconstruction layer to connect the support vector machine classifier, and the feature extraction and classification of DNs are realized. In the process of network parameter optimization, the idea of mean network is utilized to make the output of network hidden layer unit attenuate according to dropout coefficient. The reverse propagation algorithm is adopted to fine-tune the entire network to prevent depth overfitting in the network. Such operation can reduce to extract duplicate feature caused by mutual moderation of hidden layer neurons, and improve the generalization ability. The distributed multi-layer architecture of the network can provide effective data abstraction and representational learning. The feature detection layer can learn the depth structure features implicitly from the unlabeled data, and effectively characterize the nonlinearity and random fluctuation of spectral data, thus avoiding the explicit extraction of spectral features. The network shows strong data fitting and generalization ability. Weight sharing between different layers can reduce the interference of redundant information and effectively resolve the risk that the traditional multi-layer architecture network is prone to fall into the local minimization of weight. Experiments show that that of the accuracy of the deep architecture network in DNs classification is 95.81%, higher than the classical LM-BP network.
矮新星(dwarf nova, DN)是激变变星一个亚型, 是由来自伴星(K型或M型矮星)物质吸积的吸积盘和弱磁(≤ 10 T)白矮星构成的双星系统[1, 2]。 矮新星是一类爆发相对频繁的半相接双星, 两星间具有多种物质交流和角动量转移过程即吸积过程[3]。 通过矮新星可以进一步理解密近双星的演化过程, 有助于深入研究物质转移理论, 进而帮助人们研究X射线双星、 黑洞和活动星系核。 具有距离近和轨道周期短优势的矮新星是各类天体中研究吸积过程和引力波问题的最理想标的, 已成为现阶段检验和发展吸积盘理论的最常用证据[3, 4]。
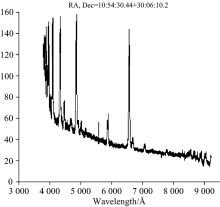
目前已经证认的矮新星数量稀少, 这对该类天体的研究形成了很大制约。 国家大科学工程郭守敬望远镜(LAMOST)[4]的巡天已经产生了海量的光谱数据, 这为发现更多的矮新星提供了数据源, 同时也提出了高效、 准确地从海量光谱中搜索矮新星的需求。 LAMOST光谱中矮新星样例如图1所示。
 | 图1 LAMOST矮新星光谱Fig.1 Dwarf nova spectra from LAMOST |
深度学习(deep learning)在计算机视觉、 模式识别和机器翻译等领域取得的突破性进展是推动本研究的重要因素[5, 6, 7, 8, 9, 10]。 Daniel[5]首次用卷积神经网络(convolutional neural network, CNN)对天体光谱进行高维特征表述, 通过相对松弛的光谱类别先验分布实现了不同天体(quasar, star, galaxy)光谱的粗分类。 然而作为一种浅层网络, CNN欠缺对数据特征的抽象学习能力, 容易陷入维度灾难。 Bengio[6]以判别学习的方式从大量混合光谱中拟合出具有稳定分布的卷积核, 基于宽度准则和K-means算法确定神经网络的超参数, 实现了若干发射线与吸收线光谱的分类。 该方法旨在发现并提取光谱的底层特征, 往往会导致严重的数据过拟合, 模型欠缺泛化能力。 Bazarghan[8] 在局部线性嵌入算法(locally linear embedding, LLE)的基础上针对JHC光谱库引入自组织映射网络(self-organizing map, SOM)对光谱聚类, 发现了由LLE生成的特征子空间与光谱温度之间的关系, 为进一步减少特殊天体的分类误差提供了有效先验。 SOM模型需要事先获取精确的先验信息, 对于低信噪比光谱仅能达到45%的分类准确率。
自编码器[1, 5](auto-encoder, AE)是仅包含一个隐层的经典神经网络模型, 能够自动挖掘样本数据的低层次特征。 然而一层AE编码能力有限, 数据表征学习能力不足。 具有多层次分布式架构的网络可弥补浅层模型在数据表征学习方面的欠缺, 对混乱无序的海量原始数据进行抽象, 挖掘隐藏在数据内部具有区分度的潜在特征[10]。 本文结合AE算法在参数估计上的计算优势, 以AE为基础构建了基于多层感知器架构的深度前馈堆栈式自编码器网络, 其深度分布式结构能够提供有效的数据抽象和表征学习能力, 特征检测层可从无标注数据中隐式地学习到其深度结构特征, 有效刻画光谱数据的非线性和随机波动性, 体现出较强的数据拟合和泛化能力。 网络不同层之间的权值共享(shared weights)可减少冗余信息的干扰, 有效化解传统多层次架构网络易陷入权值局部最小化的风险。
在针对矮新星光谱的实验中我们发现: 模块化拓宽神经网络的深度能够驱使网络继承地学习到天体光谱的特征, 通过对底层特征的逐渐抽象学习获得高层特征, 进而提高光谱的分类准确率。 针对这一特点, 我们构建了如图2所示的深度架构网络(deep architecture network, DAN)。
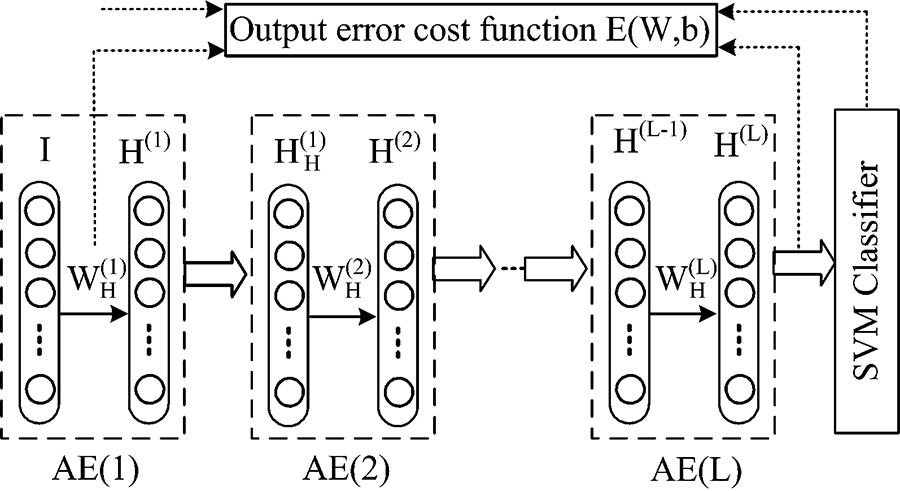 | 图2 深度架构网络结构Fig.2 The structure of a deep architecture network |
由L个非线性计算单元[AE(1)— AE(L)]堆叠而成的DAN网络实质上是由输入层I和L个隐层H(1), H(2), …, H(L)及输出层构成的堆栈式深度前馈网络, 其神经元可以响应周围单元。 预处理后的光谱数据先由输入层I进入DAN网络, 再经L个隐层H(1), H(2), …, H(L)实现逐层的数据抽象和特征抽取。 为防止数据冗余和网络权植陷入局部最小化, 把网络前一层学习到的稳定特征作为后一层的输入以实现权值共享。 经充分学习后得到数据合适的特征表示即H(L), 最后由隐层H(L)作为重构输出层搭建支持向量机(support vector machine, SVM)分类器, 完成对矮新星的特征提取与分类。
深度架构网络DAN的训练分为逐层训练(layer-wise training)和反向传播(back propagation)两个过程。 逐层训练采用AE算法[5, 10]: 每次仅训练DAN网络的一个非线性计算单元, 即只训练一个包含唯一隐层的AE网络[设为AE(i)], 仅当AE(i)训练结束后才着手训练AE(i+1)。 训练AE(i)时首先固定已训好的前i-1个单元, 然后将AE(i-1)的输出作为AE(i)的标准输入值, 通过无监督训练调整AE(i)的权值
其中,
式中, W为DAN网络的权重向量; b为网络各层节点偏置所组成的向量; M为输出节点总个数; Ti和f(zi)为AE(i)输出端的标准值和实际值; f(· )为网络激活函数; β 为稀疏惩罚项权重因子; h为隐层神经元数目;
深度架构网络涉及诸多参数, 训练样本的抽样有偏或训练过度都会使网络发生过拟合现象[7]。 设计dropout准则防止过拟合: 训练网络时按一定比例(该比例称为dropout系数)随机使某些隐层单元失效并保持其权值不变, 使这些单元不再参与该次网络传播过程, 下一次迭代时先激活所有单元再按dropout系数重新随机舍弃部分单元(与上一次选择的单元大概率不相同)。 利用均值网络思想[7, 8]使网络隐层单元输出按照dropout系数衰减, 并由反向传播算法微调整个网络, 使一个隐层单元不能与其他单元完全协同合作(因不能确定其他单元是否被激活), 减少因隐层神经元间的相互适应而学习到重复的数据表征, 提高网络的泛化能力。
自LAMOST光谱库中选取不同信噪比的矮新星及其若干候选体的光谱共计213条和由随机筛选获得的负样例光谱8 000条, 波长统一为3 800~7 322 Å , 信噪比为5~20。
设计特征学习算法的目的是抽象出能解释观测数据的变化因素(factors of variation)。 DAN是由多层非线性运算单元AE堆叠而成的堆栈式网络。 为了保持原始数据潜在信息的完整性和一致性, 对每一条原始光谱通过式(5)归一化
其中si表示波长为i的光谱流量; mean(· )为均值算子; δ (si)为标准差算子。
深度架构网络中超参数的设定会严重影响所构建网络的性能。 本文实验基于网格搜寻法[5]选取DAN网络的超参数: 稀疏性参数η 为0.05, 正则项因子λ 为3× 10-3, 稀疏因子β 为3, Dropout系数为0.15。 核函数选择径向基函数(radial basis function, RBF)。 实验表明RBF在海量光谱中的分类效果最佳(核参数σ 为0.01, 惩罚参数ξ 为80)。
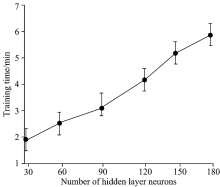
隐层神经元数量过少会使所构建的网络欠缺数据表征力, 反之又易发生数据过拟合。 光谱数据是高维非线性的。 实验中将隐层层数分别设置为{1, 2, 3, 4, 5, 6}, 隐层神经元数目依次取自序列{30, 60, 90, 120, 150, 180}, 连接SVM分类器对预处理后的天体光谱进行分类, 各重复实验50次。 矮新星光谱分类准确率与DAN网络隐层神经元数量之间的关系如图3所示(4个隐层)。 矩形盒中的横线表示该次分类准确率的平均值, 盒子上下边缘表示该次分类准确率的标准差, 两端盒须分别表示该次分类准确率的极小值与极大值。 训练时间与DAN网络隐层神经元数量之间的关系如图4所示(4个隐层)。 圆点表示该次网络训练时间的平均值, 竖线表示该次网络训练时间的总体范围。 实验表明, 增加隐层或隐层神经元数量可在一定程度上改善所构建网络的性能, 但同时网络的训练成本也会急剧增长。 当分类错误率不再快速下降时, 就应寻求其他的网络性能改良方法。 隐层神经元数目为120(4个隐层)时, 矮新星光谱能达到最佳分类准确率95.81%, 训练时间~4 min。
 | 图3 隐层神经元数量对DAN网络分类精度的影响Fig.3 The influence of the number of hidden layer neurons on the classification accuracy of DAN network |
 | 图4 隐层神经元数量对DAN网络训练时间的影响Fig.4 The influence of the number of hidden layer neurons on the training time of DAN network |
为验证DAN网络的性能, 实验选取了基于LM-BP[5, 6]的普通三层神经网络做进一步的比较分析。 表1给出了LM-BP和DAN的矮新星分类性能比较。 LM-BP的隐层神经元个数根据式(6)得出
其中i和o分别表示LM-BP网络输入端及输出端神经元数目, N为1~10间的随机数。
实验表明, 对于经典的LM-BP网络, 隐层神经元数目过少易发生数据欠拟合, 过多又会降低网络的泛化能力, 导致网络训练时间急剧增加。 当取值15时, 三层LM-BP网络展现出较好的特征选择和数据拟合能力, 分类准确率达到86.36%。
| 表1 LM-BP和DAN分类性能比较 Table 1 The comparison of classification performance between LM-BP and DAN |
逐层训练后的DAN网络, 其参数只是局部而非全局最优, 导致网络反向传播前的分类准确率仅达67.98%。 从输出层开始的反向传播通过误差逐层稀释使误差校正信息愈来愈弱, 反映出反向传播对堆栈式深度网络性能优化的重要性。 经过反向传播, DAN的分类精度达到95.81%, 体现出深度模型逐层学习和反向迭代策略的优越性。 实际上, 易陷入局部最优的普通BP网络欠缺对天体光谱随机性和非线性的特征表达能力, 无法有效地训练多层次架构, 受限于隐层神经元数量难以实现对天体光谱理想的表征学习。 DAN网络的计算成本略高于LM-BP。 实验表明, DAO的训练时间主要消耗于反向传播阶段。 若预选的网络参数足够合理, 输出误差代价函数值会随着权值及梯度的调整大幅度缩减, 进而算法快速收敛, 训练时间大大降低。
在海量光谱中搜索未证认的矮新星, 可以扩展矮新星的实测光谱库, 为矮新星的进一步研究提供数据支持。 本文将多个AE堆叠在一起构成分布式深度架构网络DAN, 用于处理海量的天体光谱数据集, 通过无监督学习挖掘出隐藏在光谱内部的数据表征, 以实现对矮新星光谱的准确分类。 具有深度堆栈式架构的DAN网络包含多层非线性运算单元, 既可构建海量光谱数据的深层特征表达, 又能避免节点数目呈指数级增长, 可以实现对天体光谱数据表征的充分学习。 实验及与传统神经网络LM-BP的对比说明了DAN网络的拟合精度与泛化能力。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|