
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合变量优选和GA-ELM模型的干制哈密大枣水分含量研究
[王文霞1, 2  , 马本学
, 马本学1, * , 罗秀芝1, 2 , 李小霞1, 2 , 雷声渊1, 2 , 李玉洁1, 2 , 孙静涛3 ]
, 马本学, 罗秀芝|
|


作者简介: 王文霞, 1992年生, 石河子大学机械电气工程学院硕士研究生 e-mail: wwx_0817@163.com
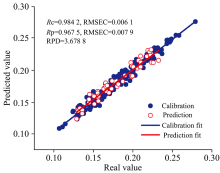
水分含量是哈密大枣干制过程中的重要指标, 对其外观、 口感、 贮藏和运输具有重要的影响。 因此, 为实现哈密大枣水分含量的准确预测, 采用近红外光谱结合变量优选方法, 建立干制哈密大枣水分含量的GA-ELM预测模型。 为提高模型的稳定性和预测精度, 开展并讨论了核函数和神经元个数对GA-ELM预测模型的影响。 采用多种预处理方法对全波段光谱进行处理, 对比分析发现标准正态变换方法(SNV)效果最佳。 对标准正态变换处理后的光谱利用连续投影算法(SPA)、 联合区间偏最小二乘(si-PLS)和遗传算法(GA)及其组合算法分别从全波段927.77~2 501.14 nm范围内筛选特征波长, 并建立对应GA-ELM预测模型, 同时与全波段的GA-ELM模型效果相比较, 采用SNV+SPA筛选的14个特征波长建立的GA-ELM模型效果最佳, 预测结果 Rc和 Rp分别为0.984 2和0.967 5, RMSEC和RMSEP分别为0.006 1和0.007 9, RPD为3.678 8。 研究结果表明: SNV+SPA+GA-ELM方法可实现干制哈密大枣水分含量的准确预测, 为近红外光谱技术应用于干制哈密大枣在线检测提供了参考。
, MA Ben-xue, LUO Xiu-zhiMoisture content is an important index in the drying process of Hami big jujubes which has an important influence on its appearance, taste, storage and transportation. Therefore, in order to realize the accurate prediction of the moisture content of Hami big jujubes, GA-ELM prediction model of the moisture content of dried Hami big jujubes was studied by using Near-Infrared spectroscopy combined with variable preferred method. In order to improve the stability and prediction accuracy of the model, the effects of kernel function and the number of neurons on the GA-ELM prediction model were discussed. Various pretreatment methods were used to deal with the spectrum of the whole band. The comparison analysis denoted that the standard normal variation (SNV) method was the best. The characteristic wavelengths were screened from the range of 927.77~2 501.14 nm by combining with successive projection algorithm (SPA), the synergy interval partial least squares (si-PLS, genetic algorithm (GA) and their combination algorithms after processing of SNV. Respectively, the corresponding GA-ELM prediction model was established. The GA-ELM model with 14 characteristic wavelengths screened by SNV and SPA had the best effect while compared with the full-band GA-ELM model. Furthermore, the predicted results could be given as follows: Rc and Rp are 0.984 2 and 0.967 5, RMSEC and RMSEP are 0.006 1 and 0.007 9 while RPD is 3.678 8. The results denoted that the SNA+SPA+GA-ELM method can realize the accurate prediction of moisture content of dried Hami big jujubes and provide a reference for the application of near-infrared spectroscopy in the on-line detection of dried Hami big jujubes.
哈密大枣是新疆特色优势果品, 个大肉厚, 外观紫红有光泽, 食之有药香, 是上等的滋补食品和药用食品[1]。 哈密大枣的鲜食期较短, 大量的鲜枣收获后进行干制, 将鲜枣的水分含量从70%降低到25%左右, 使其可溶性固形物的浓度达到微生物难以生存和利用的程度[2], 以便贮藏和运输。 水分含量(MC)作为干制哈密大枣重要品质参数之一, 干制过程中若含水量过少, 会使硬度增加, 口感变差; 若水分含量过高, 会使细菌容易繁殖, 在贮藏和运输过程中易腐烂变质。 因此, 如何实现干制哈密大枣水分含量的快速、 无损检测就显得尤为重要。
近红外光谱在农产品品质定量分析领域中得到广泛应用[3, 4, 5, 6]。 由于光谱变量中含有大量冗余信息, 从全波长中提取出对模型有效的特征波长变量, 可以进一步提高模型的稳定性和准确性[7]。 彭云发等[8]利用近红外光谱结合遗传算法(genetic algorithm, GA), 对白熟期灰枣的总糖含量进行预测, 建立的偏最小二乘(partial least squares, PLS)预测模型Rp达到0.9583; 胡晓男等[9]使用近红外光谱结合无信息变量消除法(uninformative variable elimination, UVE), 对晚熟期骏枣总酸进行预测, 建立的PLS模型Rp为0.8778; 彭海根等[10]利用近红外光谱结合联合区间偏最小二乘法(synergy interval partial leset squares, si-PLS), 对南疆灰枣进行糖度预测, 建立的PLS预测模型, 相关系数达到0.942; 以上研究主要以鲜枣为研究对象, 而对干制哈密大枣的研究却鲜有报道。 另外, 有国内外学者通过近红外高光谱对农产品水分含量进行研究。 Anisur Rahman等[11]使用高光谱成像对番茄水分含量进行预测, PLS模型相关系数为0.81; 杨传得等[12]使用近红外光谱技术对鲜食花生水分含量进行预测, PLS模型决定系数达到0.936 2。 他们的工作对干制哈密大枣水分检测具有一定的启示和借鉴作用。
采用多种预处理方法结合变量筛选方法, 将筛选出的与水分含量相关性较高波长变量, 作为遗传算法优化极限学习机(GA-ELM)的输入量, 建立干制哈密大枣水分含量的预测模型, 并评价相应的模型预测效果, 以此验证了GA-ELM模型应用于干制哈密大枣水分含量预测的可行性, 实现快速、 科学和准确的干制哈密大枣水分含量检测。
选取220个新疆哈密五堡乡果园采摘的哈密大枣为研究样本, 果实成熟后采用自然晾晒干, 颜色深红, 果实饱满有弹性, 大小均匀, 无损伤, 平均果重9 g左右。 将挑选好的干制哈密大枣表面擦拭干净, 并进行编号, 在室温条件下(28~31 ℃, 27~30% RH)放置48 h, 使样本温度和环境温度达到一致。 在样本赤道上选取3个点(间隔约120° )作为光谱采集点, 每个点采集1次, 对3条光谱取平均, 作为该样本的代表光谱。 使用SPXY方法将220个干制哈密大枣样本分为170个校正集和50个预测集样本, 用于建模分析。
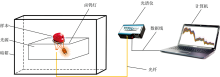
近红外光谱系统主要由光谱仪(NIRQuest 256-2.5, Ocean Inc., USA), 光源(卤钨灯, 30 W, 12 V, QP400-1-VIS-NIR, VIVO, Ocean Optics Inc., USA), 漫反射光纤, 暗箱和计算机组成, 如图1所示。 光谱范围为869.19~2 501.14 nm, 共256个波长, 分辨率为9.5 nm。 设置积分时间为18 ms, 扫描次数和平滑度分别为32和3, 最后将样本放置于VIVO光源载物台上进行近红外漫反射光谱采集。
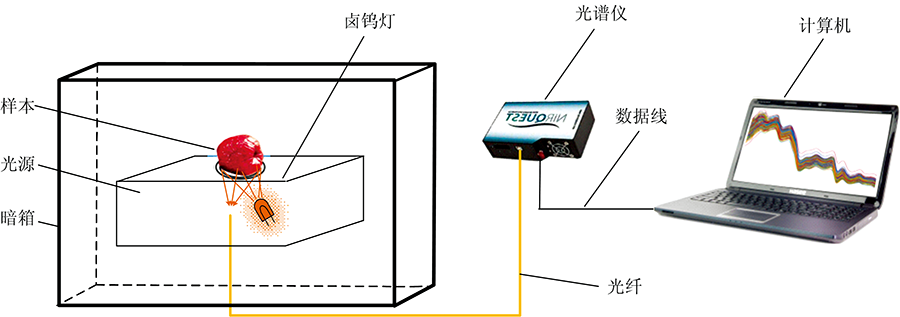 | 图1 近红外光谱采集系统的结构示意图Fig.1 Schematic diagram of near infrared reflectance spectrum acquisition system |
在近红外光谱数据采集后将完整的干制哈密大枣使用电子秤(JY/YP30002, 上海乐平科学仪器有限公司, 精度为0.000 1 g)测量干制哈密大枣的湿重。 然后放入烘干箱(DHG-9070 A, 220 V, 50 Hz, 1 550 W, 温控范围: 10~250 ℃)进行脱水, 干燥温度设定为105 ℃, 4 h后取出称重, 然后继续放入烘干箱干燥0.5 h, 重复操作直至前后两次重量误差不超过2 mg, 记录此时重量作为样本的干重值。 将湿重与干重的差值, 除以湿重, 计算出每个样本的水分含量。 表1为测得220个干制哈密大枣样本划分为校正集和预测集的水分含量统计结果。
| 表1 干制哈密大枣水分含量统计分析 Table 1 Statistical analysis of MC of Hami big jujubes samples |
1.4.1 预处理方法
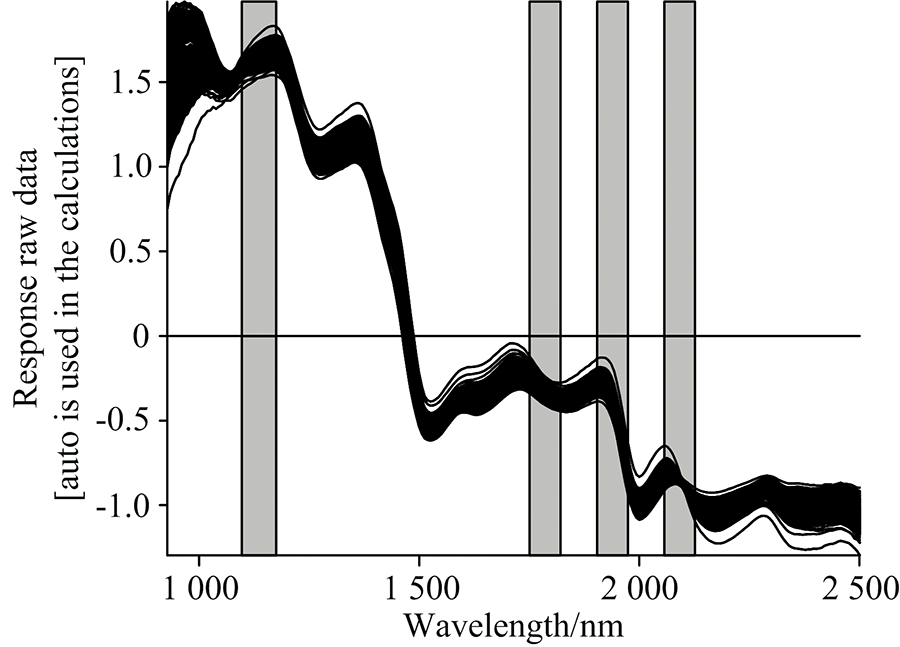
由于受到外部环境和仪器暗电流的影响, 在光谱数据采集过程中存在谱线重叠、 噪音信号和基线漂移等问题, 影响后续建模精度和稳定性[13]。 通过分析, 在869.19~927.77 nm光谱范围内存在较大的噪音, 因此采用927.77~2 501.14 nm范围内的光谱(共247个波段)用于下一步的数据分析。 为进一步消除干扰因素影响, 应用标准正态变换(standard normal variate, SNV)、 多元散射(multiplicative scatter correction, MSC)和矢量归一化(normalization, Norm)等方法处理。
1.4.2 变量优选方法
在建立预测模型时, 若模型中存在较多与干制哈密大枣水分含量无关的光谱信息, 会影响模型准确性和计算速度。 光谱特征波段的筛选对后续建模和预测效果具有较大影响。 因此, 采用联合区间偏最小二乘法(si-PLS)、 遗传算法(GA)、 连续投影算法(successive projections algorithm, SPA)及其算法组合等方法来提取特征波长以简化模型。
1.4.3 GA-ELM建模方法
极限学习机(extreme learning machine, ELM)是一种求解单隐含层前馈型神经网络(SLFN)的学习算法, 其学习速度快, 泛化性能好, 具有高效处理非线性数据回归拟合问题的能力[14]。 ELM与传统的函数逼近理论不同, 其预测精度与隐含层节点的个数密切相关。 输入层与隐含层间的连接权值wi和隐含层神经元阈值bi是随机生成的, 在给定参数时可能存在部分数值为0的情况, 导致隐含层输出矩阵不满秩, 使得部分隐含层节点失效, 进而降低模型的预测精度。 为增强ELM网络稳定性和预测精度, 用遗传算法(GA)对ELM神经网络的wi和bi进行优化选择, 以确定最优的ELM模型。
训练步骤如下:
(1)根据ELM神经网络的基本拓扑结构, 将输入权值和阈值级联起来, 产生k个初始种群。
其中, Qλ 为种群中的第λ (1≤ λ ≤ k)个个体, wij为第i个神经元与隐含层第j个神经元的连接权值, bl为第l个隐含层节点的阈值, 且均为区间[-1, 1]中的随机数。 适应度函数用于评价种群优劣程度, 将模型对验证集的预测均方根误差作为适应度函数, 适应度函数越小, 则模型精度越高。
(2)利用ELM算法隐含层激活函数(“ sig” 函数)计算出输出权值矩阵。 将归一化后的样本数据代入模型, 逐个计算每个个体的适应度(Fitness_best), 根据适应度函数值来确定适应度较优的个体。
(3)对适应度较优的个体利用交叉、 变异对种群进行进化, 得到新种群。 并检查进化代数g值, 当g小于P时, 返回到第(2)步, 直至g等于P则结束运算, 选出最优个体, 并将其拆分为初始权值和隐含层阈值, 即可确定最优的ELM模型。
模型校正和预测性能采用校正相关系数(Rc)、 预测相关系数(Rp)、 校正均方根误差(RMSEC)、 预测均方根误差(RMSEP)表示, 以及剩余预测偏差(RPD)作为评价模型预测能力的指标。 Nicolar[15]指出当RPD小于1.5时, 说明模型预测性能较差; 当RPD值在1.5~2之间说明模型对检测指标有一定的预测能力; 当在2~2.5之间说明可以粗略对检测指标进行定量分析; 当在2.5~3之间, 说明具有较好的预测精度。
在GA-ELM算法中, 参数的设置直接影响算法的寻优速度和质量。 其中, 核函数的类别和隐含层神经元个数对模型预测能力和稳定性的影响最直接, 因此针对GA-ELM模型中核函数选择和隐含层神经元个数进行研究。
(1)核函数对网络的影响: 核函数的种类一般有“ sig” , “ sin” 和“ hardlim” 等3种。 将220个干制哈密大枣样本的原始光谱作为GA-ELM模型输入量, 使用不同核函数建立的GA-ELM模型预测结果如表2所示。 从表中可以看出, 使用“ sig” 核函数建立的GA-ELM预测模型相关系数达到0.9以上, 具有较强的预测能力, 因此选择“ sig” 作为最优核函数。
| 表2 不同核函数建立GA-ELM模型的预测结果 Table 2 Prediction results of GA-ELM model established by different kernel functions |
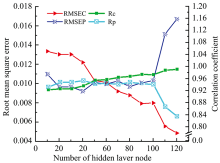
(2)隐含层神经元个数对模型的影响: 隐含层神经元数目太少会导致ELM网络“ 欠拟合” , 而数目太多会导致ELM网络“ 过拟合” 。 分别选取10, 20, …, 120个隐含层节点, 得到12种不同情况下GA-ELM网络的预测结果, 再次进行3次重复测试, 求平均值以比较其拟合情况, 结果如图2所示。 当隐含层神经元个数小于50时, Rp大于Rc, 模型存在过拟合现象; 当隐含层神经元个数在50~100时, Rp和Rc呈平稳上升趋势, 且Rc上升趋势较Rp要快, 模型稳定性显著提高; 当隐含层神经元个数大于100时, Rp急剧下降, RMSEP急剧上升, 模型精度大幅度下降。 因此, 本文选择隐含层神经元个数为100时, 作为最优隐含层神经元个数。
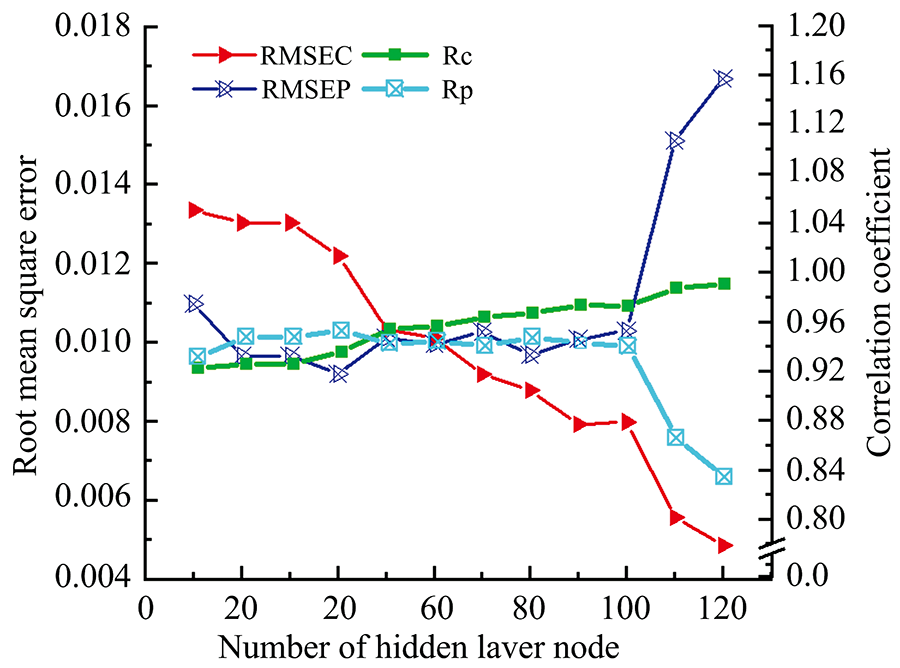 | 图2 隐含层神经元个数对网络的影响Fig.2 The influence of the number of neurons in the hidden layer on the network |
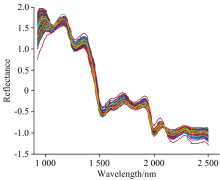
 | 图3 经过SNV后得到的反射光谱Fig.3 Reflectance spectra obtained by SVN pretreatment |
干制哈密大枣样本在光谱数据采集过程中易受到多种因素的干扰, 需要对其做必要的预处理[16]。 分别使用标准正态变换(SNV)、 多元散射(MSC)和矢量归一化(Norm)等方法对原始光谱进行预处理来减弱或消除干扰因素, 主要处理结果如表3所示。
| 表3 不同光谱预处理方法的SVM, ELM和GA-ELM水分含量预测结果 Table 3 Prediction results of SVM, ELM and GA-ELM models by different sectral preprocessing methods |
通过不同预处理方法处理后建立的SVM, ELM和GA-ELM建模比较分析, 利用SNV处理后的GA-ELM建模效果最佳, 相关系数Rp和Rc分别达到0.980 8和0.962 7, RMSEC和RMSEP分别达到0.006 8和0.008 2, RPD达到3.697 2。 因此选SNV处理后的光谱进一步进行特征波长筛选。
2.3.1 联合区间偏最小二乘法(si-PLS)
使用si-PLS方法将光谱数据划分为20个子区间, 尝试联合4个区间筛选干制哈密大枣水分含量的特征波长。 运行结果选择的最优子区间为[3 11 13 15], 交互验证均方根误差(RMSECV)为0.010 5, 同时该区间组合所对应的特征波长范围为1 096.99~1 175.04, 1 769.98~1 846.85, 1 936.23~2 012.57和2 101.29~2 177.00 nm共52个波长变量, 占全波段的21%, 如图4所示。 将选出的特征波长作为输入量, 建立GA-ELM预测模型, 结果如表4所示。
 | 图4 si-PLS波长提取Fig.4 Wavelengths selected by si-PLS method |
| 表4 不同波长提取方法的水分含量GA-ELM建模结果 Table 4 Results of GA-ELM modeling for MC with different wavelength selection algorithms |
2.3.2 遗传算法(GA)
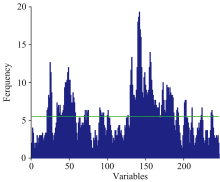
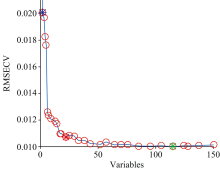
遗传算法(genetic algorithm, GA)是一种通过模拟自然进化过程搜索最优解的方法。 本研究中, 遗传算法的参数设定为: 初始种群50, 变异概率0.005, 遗传迭代次数为100和收敛率为0.5。 图5为GA迭代所选光谱变量的频率图, 图6表示被选波长变量数所对应的RMSECV值的变化, 图中绿色圆点表示当选取115个波长变量时, 其PLS模型的RMSECV最低(0.01), 所选取的波长变量占全波段的46.5%, 建立GA-ELM预测模型, 结果如表4所示。
 | 图5 GA筛选波段的频率分布Fig.5 Frequency distribution of bands selected by GA |
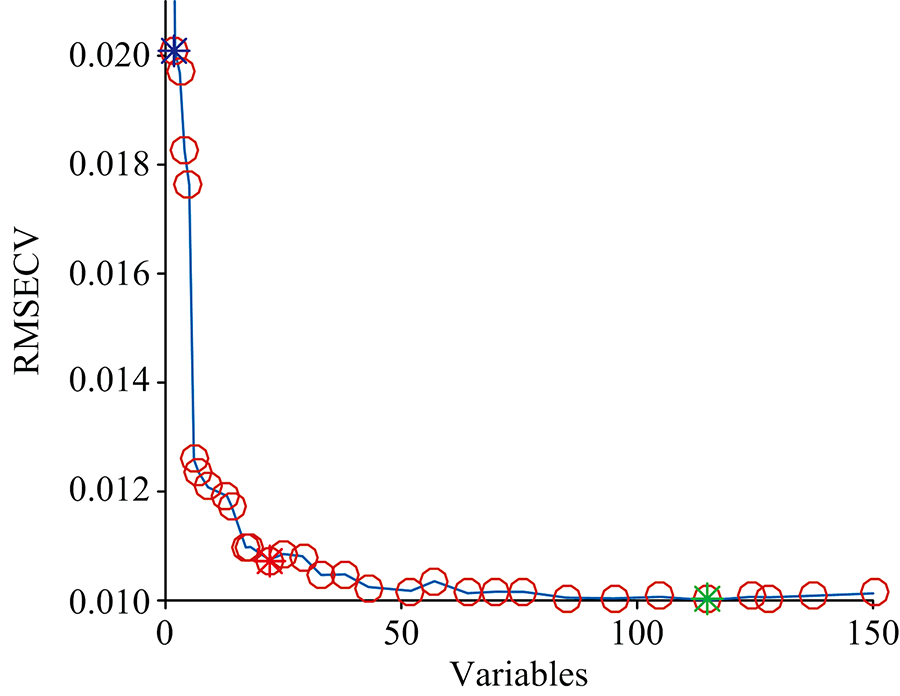 | 图6 GA波长提取Fig.6 Selection of wavelengths by GA |
2.3.3 连续投影算法(SPA)
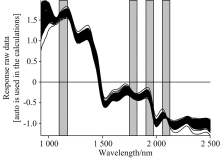
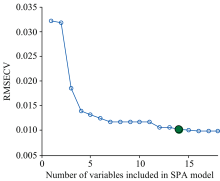
连续投影算法(successive projections algorithm, SPA)是一种新兴的特征波长筛选方法, 能够有效消除波长变量之间共线性的影响, 进而有效提取出特征波长变量[14]。 在干制哈密大枣水分含量特征波长筛选中, 指定波长数N范围设定为1~50。 图7为RMSECV值随SPA选择变量数增加变化图, 当m_max=14时, RMSECV值最低, 模型拟合效果最佳, 筛选出14个特征波长(927.77, 966.83, 1 090.48, 1 129.51, 1 298.49, 1 467.04, 1 680.03, 1 789.22, 1 840.45, 1 917.11, 1 974.44, 2 227.3, 2 314.97和2 464.1 nm)占全波长的5.6%。 将筛选的特征波长作为输入量建立GA-ELM预测模型, Rc和Rp分别达到0.984 2和0.967 5, RMSEC和RMSEP分别达到0.006 1和0.007 9, RPD为3.952 8。 其中Rp较全波长预测模型提高0.004 8, RMSEP降低0.000 3, RPD提高了0.255 6, 说明SPA能够从全波长中删除与水分含量不相关的光谱信息, 提取有效光谱信息, 提高模型预测精度。 图8表示所筛选的干制哈密大枣水分含量特征波段在全波段中的分布状况。
 | 图7 RMSECV值随SPA选择变量数增加变化图Fig.7 RMSECV vs variable numbers selected by SPA |
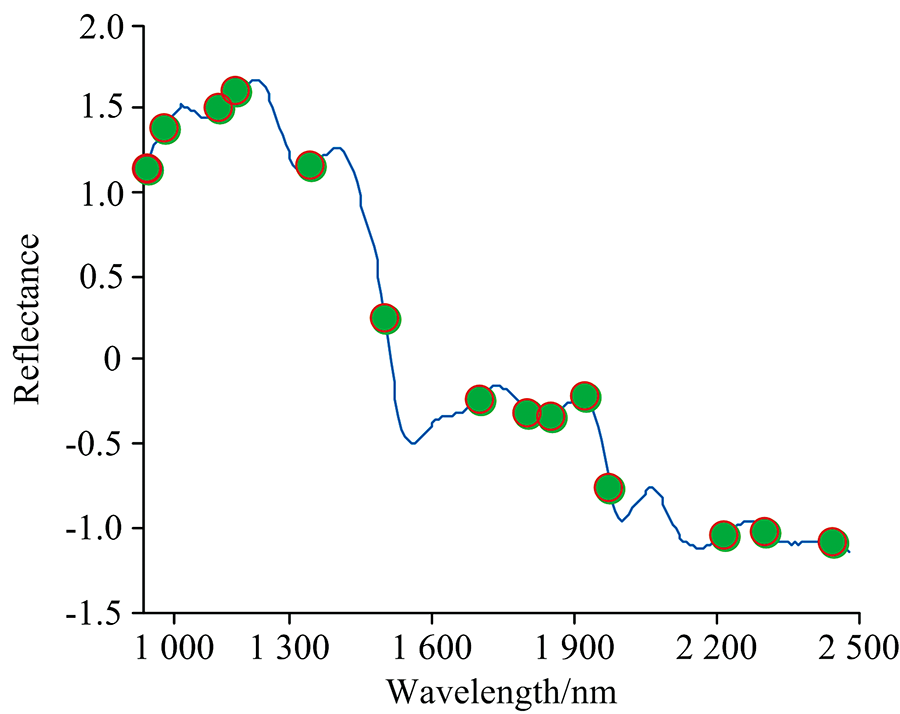 | 图8 SPA选择的14个特征波长分布图Fig.8 Plot of 14 Wavelengths selected by SPA |
为比较不同特征波长筛选方法对GA-ELM模型性能的影响, 对SNV处理后的全波段光谱、 GA、 si-PLS和SPA及组合算法提取的特征波长光谱数据分别建立对应的预测模型, 结果如表4所示。
结果显示, 采用SPA和GA-SAP方法筛选出的14个和13个特征波长建立的GA-ELM模型均得到较高的预测结果, 且SPA+GA-ELM预测结果中Rc和Rp的0.984 2和0.967 5均高于全波长的0.980 8和0.962 7, 进一步提高了模型的精度和稳定性, 图9和图10分别为GA优化进化过程和ELM预测结果。
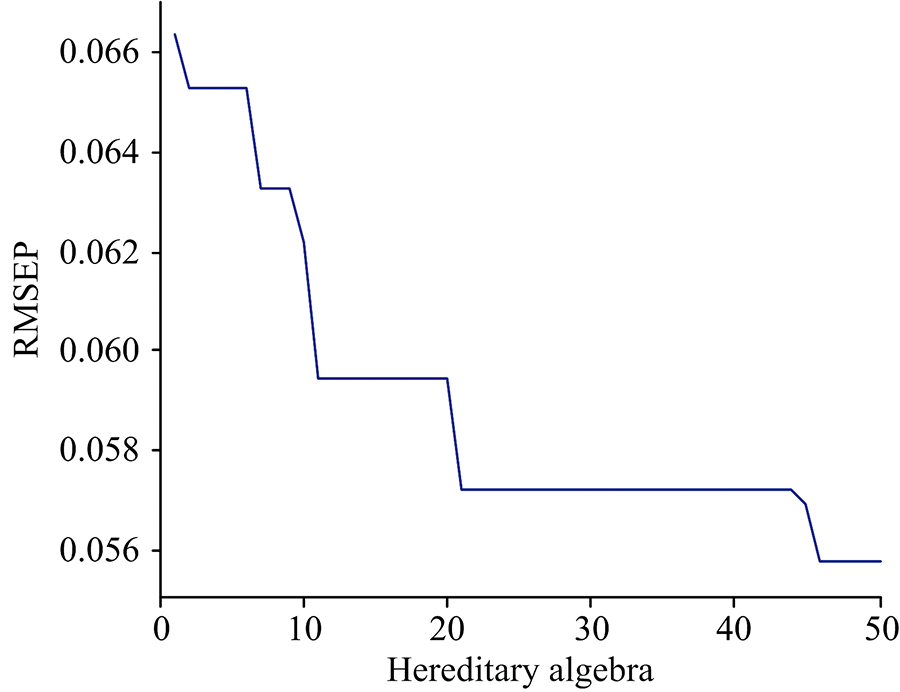 | 图9 进化过程Fig.9 Evolutionary process |
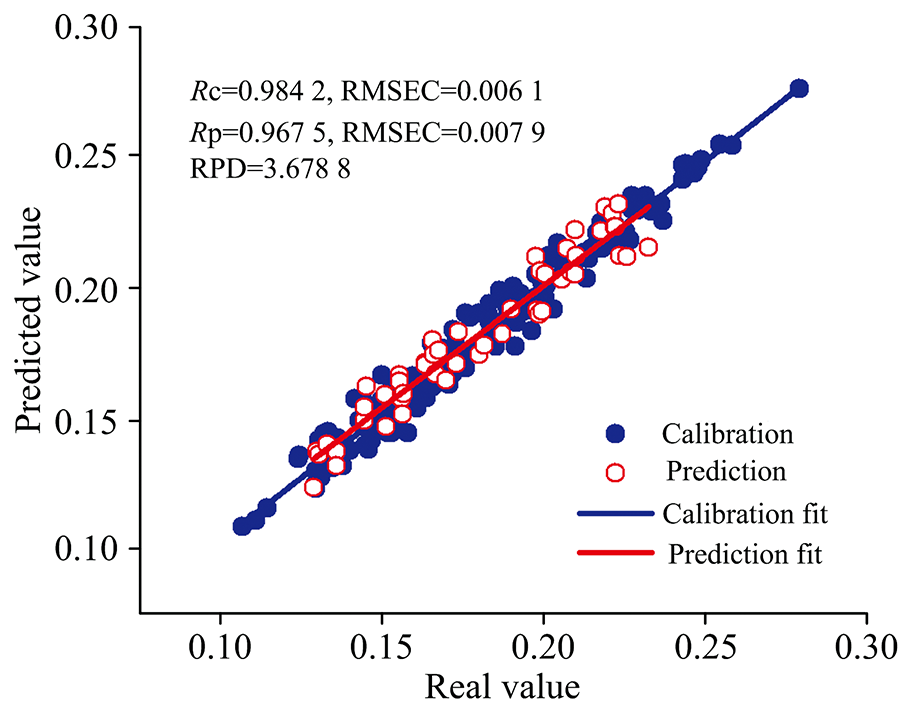 | 图10 校正集和预测集干制哈密大枣水分含量预测值与真实值的关系Fig.10 Correlation of predicted value and actual value of dried Hami big jujubes MC for calibration set and validation set |
采用近红外光谱结合GA-ELM神经网络建立干制哈密大枣水分含量预测模型, 通过多种预处理方法结合波段筛选方法, 能够有效提高模型的预测精度, 实现干制哈密大枣水分含量的准确预测。 以220个干制哈密大枣样本为研究对象, 按照170:50划分校正集和验证集, 使用多种预处理方法结合特征波长筛选方法(si-PLS, GA, SPA及它们的组合), 分别建立SVM, ELM和GA-ELM定量预测模型。 采用SNV+SPA组合提取的14个特征波长建立的GA-ELM预测模型效果最佳, Rc和Rp分别为0.984 2和0.967 5, RMSEC和RMSEP分别为0.006 1和0.007 9, RPD为3.678 8, 得到了较为理想的预测结果。 结果表明: GA-ELM预测模型具有较好的鲁棒性和泛化能力, 通过遗传算法对网络连接权值和阈值进行优化, 改善了普通ELM连接权值和阈值的随意性所带来预测精度不稳定性。 同时由于ELM神经元个数的大幅度缩减, 使得网络训练时间大大缩短, 且预测精度的有效提高, 对解决近红外光谱技术在农产品无损检测中数据量大、 数据波动大的问题具有重要的意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|