

{kind=link}
{kind=link}
{kind=link}
可能模糊鉴别C均值聚类的茶叶FTNIR分类研究
[武斌1, *  , 傅海军
, 傅海军2 , 武小红2, 3, * , 陈勇2 , 贾红雯1 ]
, 傅海军, 陈勇|
|


作者简介: 武 斌, 1978年生, 滁州职业技术学院副教授 e-mail: wubind2003@163.com
茶叶傅里叶近红外光谱(FTNIR)中含有茶叶的有机物化学成分信息, 不同品种茶叶的化学成分和含量都有差异, 所以利用傅里叶近红外光谱进行茶叶品种分类是可行的。 由于茶叶近红外光谱数据具有维数高, 有波峰和波谷, 光谱重叠交错等特点, 所以准确分类光谱数据存在困难。 为此, 提出一种可能模糊鉴别C均值聚类(PFDCM)算法, 将模糊线性判别分析(FLDA)引入到可能模糊C均值聚类(PFCM)算法中, 在模糊聚类过程中FLDA可提取茶叶近红外光谱的鉴别信息和进行数据空间的转换。 PFDCM在对茶叶光谱进行模糊聚类后得到的模糊隶属度和典型值可实现茶叶近红外光谱的准确聚类, 具有聚类速度快, 准确率高等优点。 由于PFDCM的典型值没有隶属度之和为1的约束条件, 因而PFDCM在聚类含噪声的光谱数据方面优于模糊C均值聚类(FCM)。 采集岳西翠兰, 六安瓜片, 施集毛峰和黄山毛峰四种茶叶共260个样本, 采用Antaris Ⅱ型傅里叶近红外光谱仪采集茶叶的傅里叶近红外光谱。 光谱波数范围为10 000~4 000 cm-1, 实验所得近红外光谱为1 557维的高维数据。 首先, 将光谱数据用多元散射校正(MSC)进行预处理以减少光谱散射和噪声影响和增加信噪比; 其次, 用主成分分析法(PCA)降低光谱数据空间的维数, 经过PCA处理后光谱数据维数为7; 然后, 用线性判别分析(LDA)提取光谱数据中的鉴别信息并将光谱数据空间的维数进一步降低到3维; 最后, 分别用FCM, 可能模糊C均值聚类(PFCM)和PFDCM进行数据的聚类分析, 实现茶叶品种的准确分类。 实验结果: 权重指数 m=2.0, η=2.0, FCM, PFCM和PFDCM聚类算法的聚类准确率分别为93.60%, 93.02%和98.84%; FCM收敛时共迭代25次, 而PFCM和PFDCM收敛时分别迭代8次和23次; 模糊聚类收敛所消耗的时间, FCM最少, 而PFDCM最多。 FTNIR技术结合MSC, PCA, LDA和PFDCM提供了一种实现茶叶品种准确鉴别的分类模型。
Fourier transform near-infrared spectroscopy (FTNIR) spectra contain valuable information about the chemical constituents of tea. Furthermore, the chemical constituents and their content of tea reveal differences concerning different kinds of tea and, therefore, it is feasible to classify tea varieties by FTNIR. FTNIR spectra have the characteristics of high dimension, crests and troughs, spectral overlapping and staggering, so it is difficult to classify spectra. In order to solve this problem, possibilistic fuzzy discriminant c-means clustering (PFDCM) was proposed by introducing fuzzy linear discriminant analysis (FLDA) into possibilistic fuzzy c-means clustering (PFCM) for purpose of discriminating FTNIR spectra correctly. Interestingly, during fuzzy clustering FLDA can not only extract discriminant information from FTNIR spectra but can transform the data space. PFDCM can achieve the accurate classification of FTNIR spectra according to its fuzzy membership and typicality values, and it has some advantages such as fast speed and high accuracy. PFDCM is superior to fuzzy c-means (FCM) clustering in clustering spectra containing noisy data because the typicality values of PFDCM are no constraint that the sum of the membership degrees is one. Four varieties of tea samples, called Yuexi Cuilan, Lu’an Guapian, Shiji Maofeng and Huangshan Maofeng, were collected in this study, and a total of 260 tea samples were scanned over the range of 10 000~4 000 cm-1 by FTNIR spectrometer, and in the end the 1 557-dimensional data were acquired for further processing. For a start, spectral data were pretreated with multiplicative scatter correction (MSC) to reduce spectra scattering and noise effect and increase signal-to-noise ratio. Secondly, principal component analysis (PCA) was used to reduce the dimensionality of FTNIR spectra to seven. Thirdly, discriminant information was extracted from spectra and the dimensionality of data was transformed from seven to three by linear discriminant analysis (LDA). Finally, fuzzy c-means (FCM) clustering, PFCM and PFDCM were put into use, clustering data to classify tea variety correctly. The experimental results showed that under the condition of the weight index m=2.0 and η=2.0, the clustering accuracy rates of FCM, PFCM and PFDCM achieved 93.60%, 93.02% and 98.84%, respectively. After 25 iterations, FCM converged, but PFCM and PFDCM achieved 8 iterations and 23 iterations, respectively, and converged. As fuzzy clustering algorithms converged, FCM consumed the least time but the most time-consuming clustering was PFDCM. In conclusion, FTNIR coupled with MSC, PCA, LDA and PFDCM presented a classification model for the accurate identification of tea varieties.
作为茶的故乡, 中国具有历史悠久的茶文化, 中国人饮茶可以追溯到神农时代。 茶是一种人们喜爱的绿色健康饮品。 茶叶中富含有利于人体健康的多种氨基酸, 矿物质和维生素等。 国内茶叶品种繁多, 有普通品种和名优品种。 按照茶叶的发酵程度可分为绿茶, 红茶和黑茶等; 绿茶主要有: 杭州西湖龙井, 安徽黄山毛峰, 安徽六安瓜片、 河南信阳毛尖等。 不同品种的茶叶, 其生长环境不同, 组分及含量存在差异, 导致其功效也不尽相同。 因此, 利用当前的先进科学技术和仪器设计出一种简单易行且识别率高的茶叶品种分类模型具有重要的研究价值。
国内外研究人员近年来运用近红外光谱和中红外光谱技术等进行茶叶的定性和定量分析, 取得了一定的研究成果[1, 2]。 例如: 武小红等用FTIR-7600傅里叶红外光谱仪检测四川三种茶叶, 提出一种联合Gustafson-Kessel (AGK)聚类算法, 并用AGK进行茶叶聚类, 得到聚类准确率为93.9%[3]。 由于发生抹茶中渗入绿茶粉事件, Yu等研究了一种快速无损识别抹茶中绿茶粉的有效方法, 检测样本在500~700 nm之间的光谱, 数据建模采用主成分分析(PCA), 线性判别分析(LDA)和簇类软独立模型法(SIMCA)[4]。 Bartoszek等用电子顺磁共振(EPR)光谱和半经验数学模型探索绿茶, 黑茶和红茶的抗氧化性, 结果表明在绿茶中显示出儿茶素的存在而在红茶中缺乏儿茶素的指标, 那么儿茶素的存在是绿茶具有抗氧化性能的主要原因, 芳香质子含量和总抗氧化力值(TEAC)相关[5]。 Meng等采集福建省三个地区的乌龙茶共90个样本, 用质子磁共振和近红外光谱检测茶叶, 数据采用偏最小二乘判别分析(PLSDA)建立分类模型[6]。 Wang等采集湖北恩施108个新鲜茶叶样本, 用Thermo Antaris Ⅱ 傅里叶变换近红外光谱仪采集样本的近红外光谱, 用前馈人工神经网络和后向间隔偏最小二乘算法建立茶叶购买价格的预测模型[7]。 Hu等收集四种绿茶, 共150个样本, 用光谱仪获取样本的三维激发-发射矩阵荧光光谱, 发射光谱范围330~680 nm激发光谱范围300~500 nm, 用多线性主成分分析(MPCA), 自权重可变三线性分解(SWATLD)和多线性偏最小二乘判别分析(NPLSDA)处理光谱数据[8]。
模糊聚类是一种模式识别算法, 广泛应用于数字图像处理, 计算机视觉和模式分类中[9, 10]。 另一方面, 模糊聚类可以用来聚类光谱数据。 例如: 模糊C均值聚类(FCM)[11], 可能C均值聚类(PCM)[12], 模糊鉴别C均值聚类(FDCM)[13]和Gustafson-Kessel (GK)聚类可以聚类苹果近红外光谱数据。 聚类含噪声的数据是一个重要研究热点[14], 由于FCM处理噪声数据存在敏感性, 而PCM虽然能处理噪声数据但是存在一致性聚类问题, 为解决这些问题, Pal等提出一种可能模糊C均值[15]。 但是该算法在计算参数η i时需要先运行FCM, 为解决这个问题, 武小红等设计了一种新的可能模糊C均值(PFCM)[16]。 为了进一步提高PFCM的聚类准确率, 本文结合新的PFCM和模糊线性判别分析(FLDA), 提出一种可能模糊鉴别C均值聚类(PFDCM)算法, 并用该算法进行茶叶近红外光谱数据的聚类分析。
从安徽滁州当地超市采购安徽四种品牌茶叶: 岳西翠兰、 六安瓜片、 施集毛峰、 黄山毛峰。 每种茶叶有65个样本, 总共样本数为260。 四种茶叶经DXF-04D小型高速中药打粉机研磨粉碎, 然后使用40目筛过滤。 实验室温度和相对湿度保持相对不变, 将模式设置为反射积分球, Antaris Ⅱ 光谱仪扫描每个样本32次并计算光谱的均值; 光谱的波数变化范围是4 000~10 000 cm-1, 最后得到的茶叶样品光谱数据是1 557维; 每个样本采样3次, 取其平均值作为后续模型建立的实验数据。 四种茶叶样本的傅里叶变换近红外光谱如图1所示。 采用Matlab R2014b进行光谱数据绘图和模糊聚类算法的编程。
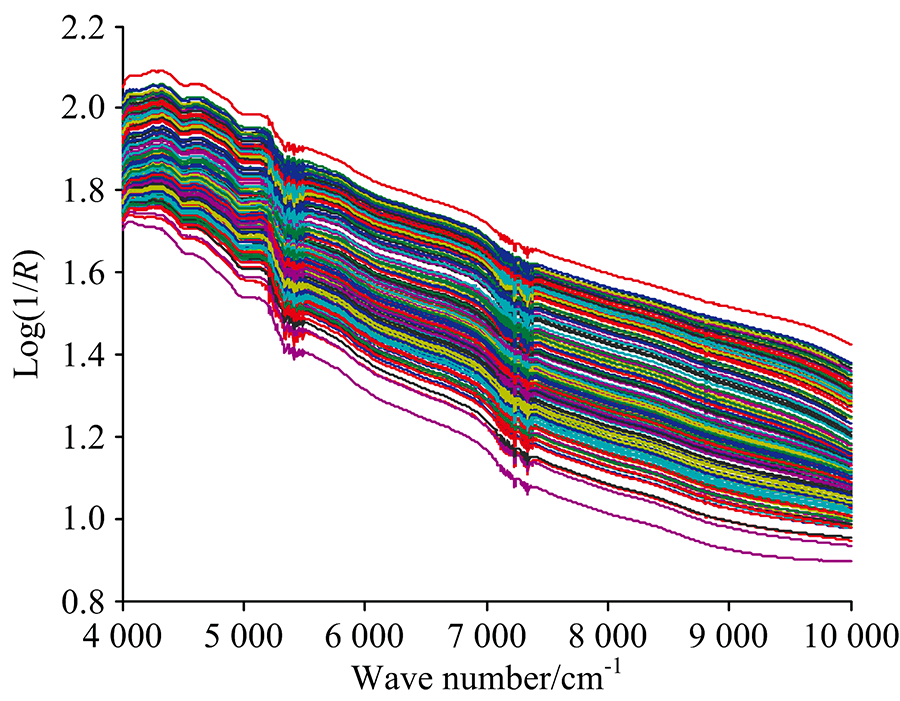 | 图1 茶叶的傅里叶变换近红外光谱图Fig.1 FTNIR spectra of tea samples |
可能模糊鉴别C均值聚类算法是一种迭代计算, 其主要步骤叙述如下:
(1)初始化: 设置权重指数m和η (m> 1, η > 1), 样本数为n, 类别数为c(n> c> 1), 参数a和b的值(a> 0, b> 0); 设置迭代次数初始值r和最大迭代次数rmax; 误差参数为ε ;
(2)计算样本的协方差
式中,
(3)构造模糊类间散布矩阵SfB
其中,
(4)构造模糊总体散布矩阵SfT
其中, xk是第k个样本。
(5)特征值和特征向量的计算
式(4)中特征值λ 和其对应的特征向量Ψ 。
(6)样本xk∈ Rq投影到特征空间(由Ψ 1, Ψ 2, …, Ψ p组成)
式(5)中, p和q表示维数, Ψ p是特征向量组中的第p个向量。
(7)同样将
其中,
(8)在特征空间中计算模糊隶属度函数值
式(7)中, u
(9)在特征空间中计算典型值
式(8)中, t
(10)在特征空间中计算第i类的类中心矢量v
(11)迭代次数r值增加, 即r=r+1; , 直到满足条件: ‖ v
(12) 迭代终止后, 根据模糊隶属度值对样本进行分类, 若u
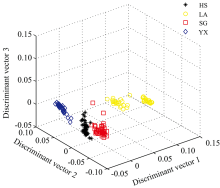
茶叶近红外光谱和茶叶有机物含氢基团的振动信息相关, 为检测茶叶的某种有机物含量提供了依据。 但是, 由于茶叶的样品颗粒度、 装填密度等因素造成的散射问题使茶叶近红外光谱和有机物含量的关联性受到影响。 为此, 需要采用多元散射校正(MSC)进行光谱预处理以减少散射影响和提高信噪比[17, 18]。 图1所示的茶叶傅里叶变换近红外光谱经过多元散射校正处理后, 其光谱数据维数仍为1557维, 需要降维处理以便减少计算量和提高分类准确率。 这里用主成分分析(PCA)对光谱数据进行压缩处理。 PCA的前7个主成分的累积贡献率达到99.95%, 所以选取PCA的前7个主成分进行光谱数据压缩后损失的信息少且可以降低数据维数。 将1 557维的茶叶傅里叶变换近红外光谱投影到PCA的7个特征向量上可得到7维的光谱数据。 选取88个茶叶样本(每个品种选取22个样本)作为训练集, 其余的样本组成测试集, 即测试样本共172个。 利用线性判别分析(LDA)计算训练集的鉴别向量和特征值, 计算得到的三个特征值为: λ 1=232.29, λ 2=16.13, λ 3=2.60。 将茶叶测试样本经过LDA特征空间转换后形成三维数据, 图2是线性判别分析的得分图。 如图2所示, 符号 “ * HS” , “ ○LA” , “ □SG” 和“ ◇YX” 分别表示黄山毛峰, 六安瓜片, 施集毛峰和岳西翠兰四种安徽茶叶光谱的测试样本。 根据图2的数据分布可知, 六安瓜片的数据分布比较松散, 其余三种茶叶数据分布较为紧密, 四种数据的每类之间区分较为明显。
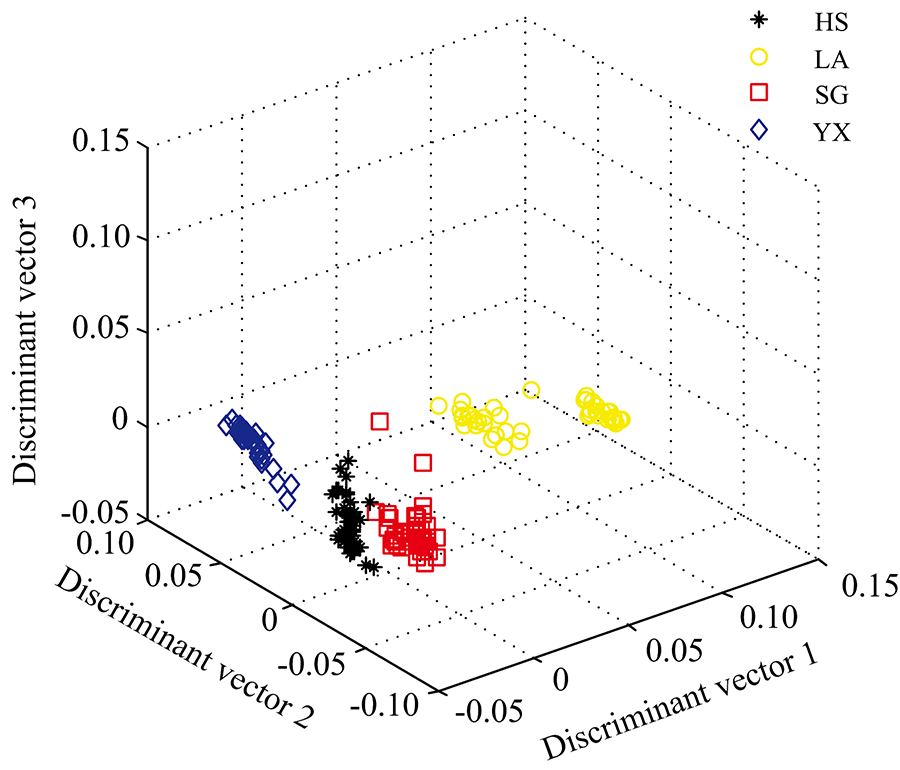 | 图2 LDA的得分图Fig.2 Scores plot of linear discriminant analysis |
2.2.1 模糊聚类的初始化参数设置
在运行FCM, PFCM和PFDCM聚类算法之前需要设置它们的初始化参数: 设置权重指数m=2.0, η =2.0, 参数a和b的值均为1, 待聚类的样本数为n=172, 类别数为c=4; 设置迭代次数初始值r=1和最大迭代次数rmax=100; 迭代最大误差参数ε =0.000 01。 设置FCM的初始聚类中心为
运行FCM, 经过25轮迭代计算终止后得到的聚类中心作为PFCM和PFDCM的初始聚类中心。
2.2.2 模糊聚类迭代次数和聚类时间
初始化参数设置同3.2.1节。 运行FCM, PFCM和PFDCM聚类算法以分析迭代次数及收敛情况。 三种模糊聚类算法达到收敛时迭代次数为: FCM 25次, PFCM 8次和PFDCM 23次。 所以, PFCM和PFDCM聚类算法的迭代次数均比FCM少。 计算机配置: CPU Intel Core i5-2005U 2.20 GHz, RAM 8GB, Windows 10。 运行Matlab R2014b, FCM, PFCM和PFDCM的聚类时间分别为0.218 7, 0.359 4和0.843 7 s。 由于PFCM和PFDCM运行前需要运行FCM以得到初始聚类中心, 因而聚类时间要多于FCM, 且PFDCM聚类时间最多。
2.2.3 模糊隶属度
设置FCM, PFCM和PFDCM聚类算法的初始化参数同2.2.1节。 分别运行FCM, PFCM和PFDCM聚类算法至迭代收敛后, 可分别得到FCM, PFCM和PFDCM聚类算法的模糊隶属度值uik, FCM, uik, PFCM和uik, PFDCM。 uik, PFDCM如图3所示。 若第k个测试样本xk的FCM模糊隶属度为uik, FCM, 则xk的第i类所有模糊隶属度之和为1, 即
 | 图3 PFDCM模糊隶属度值Fig.3 Fuzzy membership values of PFDCM |
可能模糊C均值聚类(PFCM)基础上结合模糊线性判别分析(FLDA), 提出一种可能模糊鉴别C均值聚类(PFDCM)算法。 PFDCM聚类算法可实现在模糊聚类过程中提取样本鉴别信息, 进一步提高了聚类准确率。 通过对茶叶傅里叶近红外光谱进行FCM, PFCM和PFDCM三种聚类算法进行光谱聚类分析。 结果表明: 当权重指数m为2时, PFDCM聚类算法的聚类准确率最高, 达到98.84%; PFCM和PFDCM的聚类迭代次数均少于FCM; PFDCM聚类时间要多于FCM和PFCM。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|