

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联合矩阵局部保持投影的近红外光谱特征提取
[胡善科1  , 秦玉华
, 秦玉华1, * , 段如敏2 , 吴丽君2 , 宫会丽3 ]
, 秦玉华, 段如敏|
|


作者简介: 胡善科, 1994年生, 青岛科技大学信息科学技术学院硕士研究生 e-mail: 1020447071@qq.com
近红外光谱存在高维、 噪声大、 重叠和非线性等特性, 严重影响建模准确, 因此提出了一种基于联合矩阵局部保持投影(JMLPP )的特征提取方法。 首先, 利用基于聚类的光谱特征选择方法对原始近红外光谱数据进行有效特征提取, 按种与分类相关性强的指标将样本分为种不同的聚类方式, 依据类内关联性强, 类间差异性大的聚类思想, 通过调节类内参数、 类间参数确定类内阈值与类间阈值, 分别对种不同聚类方式筛选光谱特征区间, 得到指标特征矩阵, 并集操作生成联合矩阵。 其次, 从两个方面对局部保持投影算法(LPP)进行了改进: 引入测地距离构造邻域距离矩阵, 较欧式距离更好的表达了高维数据样本点间的拓扑结构; 改进了边权矩阵, 解决了样本稀疏导致的不确定性, 避免了有效信息的丢失。 最后, 采用改进的LPP算法对联合矩阵进行降维操作, 从而得到最优光谱特征子集。 为验证JMLPP算法有效性, 首先从光谱投影方面将该算法与PCA、 LPP算法进行了对比, 结果表明JMLPP算法有较好的等级区分能力, 投影空间中的烟叶样品分类清晰, 明显优于PCA与LPP算法。 其次从模型分类准确性方面进行了对比, 分别采用全谱段与PCA, LPP和JMLPP降维后的特征建立烟叶等级分类模型, 实验结果表明, JMLPP算法建立的分类模型准确率为93.8%, 对5种烟叶分级的敏感度分别为95.2%, 93.1%, 94.2%, 92.1%和92.5%, 特异度分别为99.3%, 98.4%, 98.6%, 97.5%和97%, 模型准确率、 敏感度与特异度均明显优于其他3种方法。 该算法通过基于聚类的特征提取和改进的局部保持投影算法实现了烟叶分级特征的有效提取, 并保留原始数据的局部线性关系, 使最终建立的模型具有良好的稳定性和较高的准确性。
Aiming at the problem that the high-dimensional, high-noise, overlap and nonlinear features of the near-infrared spectrum seriously affect the modeling accuracy, a feature extraction method based on joint matrix local preservation projection (JMLPP) is proposed in this paper. First, the cluster-based spectral feature selection is used for effective features extraction. According to kinds of indicators with a strong correlation of classification, the samples are divided into kinds of different clustering modes. Based on the idea of strong intra-class correlation and great inter-class difference, the intra-class threshold and the inter-class threshold are determined by adjusting the intra-class parameter and the inter-class parameter . The spectral feature regions are selected according to kinds of different clustering modes, and feature matrices are obtained, whereas a joint matrix is generated by the union operation. Cluster-based feature extraction eliminates features with low intra-class correlation and high correlation between classes, and realizes the elimination of noise information in the spectrum. Secondly, the local preservation projection algorithm (LPP) is improved in this paper from two aspects: the geodesic distance is introduced to construct the neighborhood distance matrix, and the topology between the high-dimensional sample data is better expressed than the Euclidean distance. Meanwhile, the edge weight matrix is also improved, which solves the uncertainty caused by sample sparseness and avoids the loss of effective information. Finally, the improved LPP algorithm is used to reduce the dimensionality of the joint matrix, and the optimal spectral feature subset of the low-dimensional mapping is obtained. In order to verify the effectiveness of the JMLPP algorithm, this paper first compares the JMLPP with PCA and LPP from the perspective of spectral projection. The results show that JMLPP has better classification ability, and the tobacco samples in the projection space are clearly classified, and the effect is obviously better than PCA and LPP. In addition, the results of the model classification are also compared. The classification models were established by using the full spectra and dimension reduction features of the PCA, LPP and JMLPP. The experimental results show that the accuracy of the classification model established by JMLPP algorithm is 93.8%. The sensitivity of the five categories of tobacco grading classification are 95.2%, 93.1%, 94.2%, 92.1%, 92.5%, and the specificities are 99.3%, 98.4%, 98.6%, 97.5%, and 97%, respectively. The accuracy, sensitivity and specificity of the model are significantly higher than the other three methods. The JMLPP algorithm effectively extracts useful information of classification based on cluster-based feature extraction and local preserving projection algorithm, and maintains the local linear relationship of the original data. The stability and accuracy of model are desirable.
近红外光谱技术具有快速、 高效、 准确性好, 不损坏样品等特点, 目前大量用于石油化工、 环境科学、 食品药品等领域[1]。 我国是烟草大国, 每年的烟叶收购量庞大, 但烟叶质量受各种因素的影响, 需首先经过分级处理才能保证原料的合理利用。 然而目前烟叶分级主要以人工为主, 烟叶分级存在主观性强、 效率低、 误差大, 利用率低等问题[2]。 随着近红外光谱技术的发展, 近年来, 它在烟草自动分类中得到了很好的应用, 不仅能获得烟叶颜色的外观特征, 而且能反映烟叶的内在质量信息, 与人工、 图像视觉提取、 数学推理等分类技术相比具有天然优势[3]。 然而, 近红外光谱数据具有高维、 频带重叠、 噪声大和非线性等特点, 高维空间的稀疏性与空空间等现象也严重影响了结果的准确性, 针对这些问题, 对高维光谱数据进行与建模相关性高的特征提取尤为重要[4]。 鲁梦瑶等提出采用隔点采样的方法对光谱数据进行特征提取, 从而加快收敛速度, 但该方法容易丢失重要特征; 何勇等[5]采用主成分分析(principal component analysis, PCA)与神经网络相结合的方法对光谱数据进行降维, 并以PCA变换后的变量作为输入参数, 但PCA是一种线性降维方法, 无法获取数据的非线性结构特征; 高全学等[6]提出了改进(local preserving projection, LPP)的非线性降维算法, 在特征提取过程中, 融合了局部结构和差分信息, 但对稀疏数据的效果并不理想。
针对上述问题, 提出了一种基于联合矩阵的局部保持投影(local preserving projection algorithm based on joint matrix, JMLPP)特征提取方法。 首先, 通过基于聚类的特征提取[7]剔除类内相关度低、 类间相关度过高的特征, 实现了光谱中噪声信息的剔除。 其次, 采用改进的LPP算法对光谱数据进行降维, 解决了冗余特征和非线性结构的影响。 此外, 在LPP算法中引入测地线距离[8], 并对边权矩阵公式进行了改进, 解决了样本稀疏带来的不确定性。 JMLPP方法实现了烟叶分级信息的有效提取, 提高了烟叶分级准确性。
分类是一个复杂过程, 其中包括多个指标, 需要考虑与分类相关指标的最优特征范围是否相同, 很明显多个指标的最优特征范围不可能完全相同, 因此不同指标的最优特征范围之和会构成分类的最大且最优特征。 假设给定样本集共有n类, 每类有M个k维数据, 那么第l类有ml个样本, 第j个样本表示为
其中γ 1∈ [0, 1]。 通过调节类内参数γ 1找到合适类内阈值之后, 筛选出的光谱特征都具有较好的类内聚集性, 但有些特征存在每类均值都比较接近的问题, 这些特征无法较好的体现分类的作用。 依据聚类思想, n类样本的同维特征均值差异性越大, 均方差越大, 说明这一特征越典型, 应该保留; 反之, 应该剔除。 令n类样本的第i个特征集的均方差为
其中γ 2∈ [0, 1]。 通过调节类间参数γ 2找到合适类间阈值之后, 筛选出的特征具有较好的离散性。 联合类内阈值与类间阈值对光谱数据的处理, 最后得到筛选出的指标特征矩阵。
分类方式可能有N种, 可得到N个指标特征矩阵, 考虑到分级的准确性, 对得到的N个指标特征矩阵进行并集操作得到联合矩阵。 选取与烟叶分级相关性高的成熟度与部位指标进行分类, 从光谱矩阵中分别选出与成熟度和部位相关性高的特征, 从而得到两个特征矩阵, 并集产生一个联合矩阵。 通过联合矩阵运算可减少“ 维度灾难” 问题, 剔除与分类无关的噪声信息, 提高计算精度, 但仍存在光谱数据冗余、 非线性等特点。
局部保持投影(LPP)算法[9]是由何小飞教授于2003年提出, LPP是一种线性降维和非线性降维相结合的降维算法。 与PCA算法相比, LPP算法能够保留全局信息, 在线性降维的同时也保留局部非线性特征。 LPP生成的表现映射可看作LE (laplacian eigenmap)[10]的线性近似, 保留了数据的局部信息, 应用在高光谱数据和图像识别等领域[11]。
给定m个在欧式空间RN的N维数据样本X={x1, x2, …, xm}, xj∈ RN, (j=1, 2, …, m), LPP通过生成最近局部邻域图, 获得样本数据的k近邻域。 LPP的目标是将高维空间非线性流行数据X投影到低维空间特征映射矩阵Y, 找到最优转换矩阵Z, 其本质是Laplacian Eigenmap的线性逼近, 如式式(3)
优化目标函数后为
LPP算法为了保证映射后矩阵能最大程度保存数据局部结构属性, 使距离较近的样本xj, xi经过映射后仍保持较近距离, 引入相似性度量矩阵Wji
其中xj和xi互为k邻域内的点, δ 是一个常数, W为实对称矩阵。
对优化目标函数进行变化
式(6)中, D是对角矩阵, 即
则最小化目标函数为
即求解下式广义矩阵特征值
矩阵XDXT, XLXT是对称且半正定的, 式(9)得到前h个最小特征值的特征向量z1, z2, …, zh构成最优转换矩阵W=(w1, w2, …, wz)。
LPP算法在保持全局非线性结构的同时进行局部线性降维, 但烟叶光谱数据具有高冗余、 高噪声、 重叠、 离散性大等特点, 且LPP算法单纯依据欧式距离构造邻域图, 无法表达样本点间真实的拓扑结构, 对烟叶近红外光谱数据的处理存在一定不足。 本文对LPP算法作了如下改进: 用测地线距离代替欧式距离, 根据Dijkstra算法得到的最小距离构造邻域图, 并改进边权矩阵。 利用贪心算法得到样本中某一点距离较近的前k个顶点, 作为k近邻域。
设构造的邻域图为: G={V, E, W}, 其中V为样本顶点集合, E是边集合, W是边权矩阵, 设测地线距离为dG(xj, xi), 则改进后的边权矩阵为
在离散性大的高维流形数据中, 测地线距离可以较好的表达两点之间的实际距离, 使样本点整体分布趋于均匀, 相较于欧式距离具有明显优势, 提高了LPP的降维效果。
基于联合矩阵的局部保持投影(JMLPP)特征提取方法具体步骤如下:
(1)按N种与分类相关性强的指标将样本分为N种不同的分类方式, 每种分类方式筛选k个特征进行基于聚类的特征选择。
(2)基于聚类的特征选择需要挑选类内关联性强, 类间差异性大的特征。 通过调节类内参数γ 1、 类间参数γ 2确定类内阈值D(l)与类间阈值D, 分别对N种不同聚类方式筛选光谱特征区间得到N个指标特征矩阵M1, M2, …, MN, 并集操作生成联合矩阵M。
(3)将联合矩阵M采用改进的LPP算法进行降维操作, 得到去噪、 去冗余的数据特征子集Y={y1, y2, …, ym}。
来自某烟草企业提供的包括B2V, B1F, C4F, C1L, X2L五个不同等级共650个烟叶样品, 其中每个等级各130个。 将样品放置在60 ℃的烘箱中干燥2 h, 磨粉过60目筛, 密封平衡8 h后进行光谱采集。
使用赛默飞世尔公司Antaris Ⅱ 近红外光谱仪, 采用漫反射方式, 扫描范围为3 800~10 000 cm-1, 分辨率为8 cm-1, 室温保持在18~22 ℃, 每个样品取15 g压实后置于光谱仪中扫描3次, 计算其平均值作为最终光谱。
为了消除基线漂移和噪声的影响, 需要对采集到的光谱数据进行预处理, 经比较本文采用一阶导数和Savitzky Golay平滑[12]。
因影响烟叶分级的关键指标包括成熟度与部位, 分别从650个样品中按成熟度与部位选取部分特征明显的烟叶样品进行基于聚类的特征提取。 其中按成熟度分为成熟、 尚熟与假熟, 共选取了420个样品; 按部位分为上部、 中部与下部, 共选取了450个样品。 具体样品信息划分如表1所示。
| 表1 聚类特征提取实验样品划分 Table 1 Sample partition of cluster feature extraction experiment |
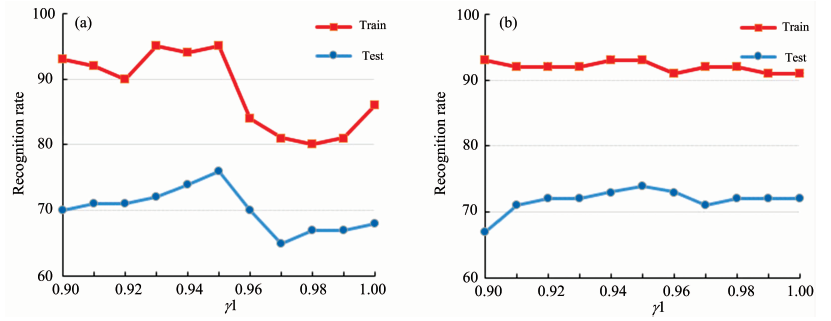
首先利用基于聚类的特征提取方法分别从成熟度和部位指标筛选与烟叶分级相关的特征。 根据文献[10]与实验分析, 类内参数γ 1、 类间参数γ 2的取值分别在0.9~1, 0~0.01之间细化搜索得到最佳取值。 图1和图2分别为γ 1和γ 2按部位和成熟度聚类的搜索结果。
 | 图1 γ 1细化搜索 (a): γ 1部位分组; (b): γ 1成熟度分组Fig.1 Refined search of γ 1 (a): γ 1 grouped by location; (b): γ 1 grouped by maturity |
 | 图2 γ 2细化搜索 (a): γ 2部位分组; (b): γ 2成熟度分组Fig.2 Refined search of γ 2 (a): γ 2 grouped by location; (b): γ 2 grouped by maturity |
可以看出, 按部位分组时, 类内参数γ 1=0.95, 类间参数γ 2=0.000 4时识别率较好, 提取的光谱数据特征为983个。 按成熟度分组时, 类内参数γ 1=0.95, 类间参数γ 2=0.001 4时识别率较好, 提取的光谱数据特征为892个。 为保证信息提取的完整性, 本文将两个特征子集进行并集操作生成一个联合矩阵, 联合矩阵的光谱特征从1 560减少到1 102个, 较全光谱数据减少了28.9%。
特征选择可消除对分级无关的噪声特征, 但筛选出的光谱数据仍存在冗余、 非线性特征, 这将对烟叶分级的准确性产生影响, 因此采用改进的LPP方法对提取的特征进行进一步降维处理, 从而消除冗余特征的影响。 图3— 图5为JMLPP与PCA, LPP的投影对比。
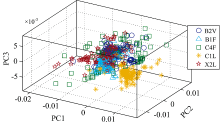
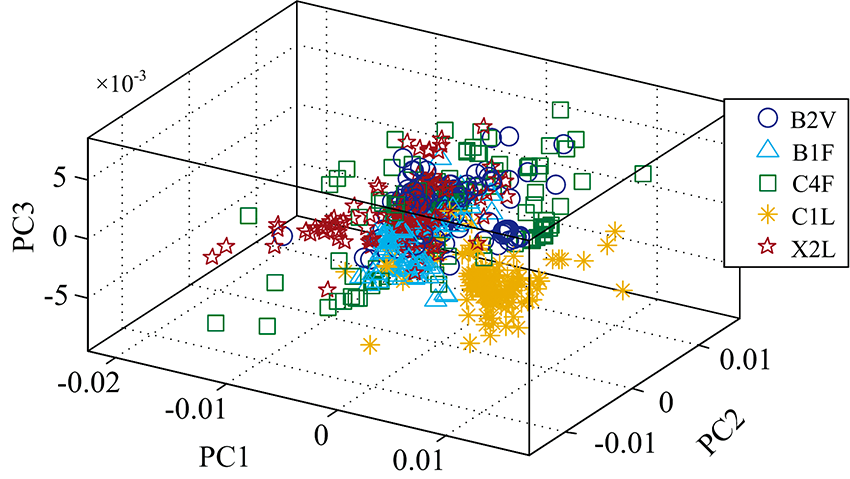 | 图3 PCA投影图Fig.3 PCA projection plot |
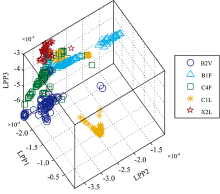
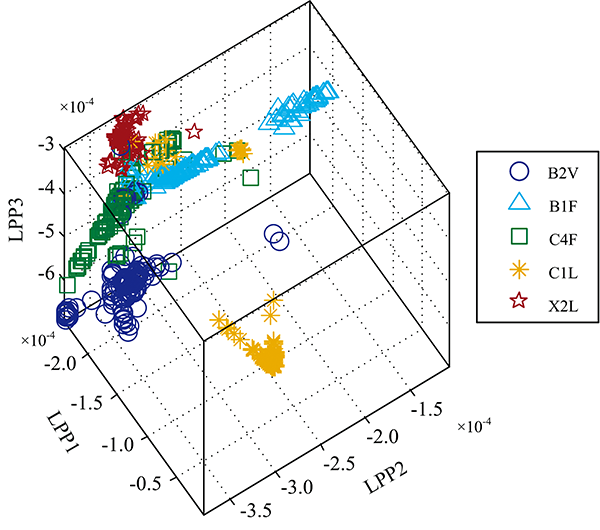 | 图4 LPP投影图Fig.4 LPP projection plot |
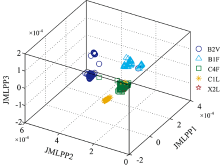
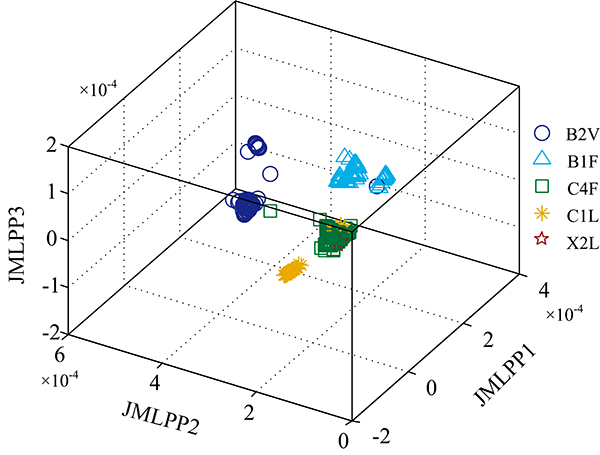 | 图5 JMLPP投影图Fig.5 JMLPP projection plot |
可以看出, PCA投影空间中样品混合现象比较严重, 各等级边界模糊, 难以实现烟叶等级的区分。 LPP投影空间中的烟叶等级分类效果好于PCA, 但仍存在较多样品区分模糊问题。 而JMLPP投影空间中的烟叶样品分类清晰, 效果明显好于PCA与LPP, 说明该方法有较好的等级区分能力。
选取75%的样本做为训练集, 25%的样本做为测试集, 分别采用全谱段与PCA, LPP和JMLPP降维后的特征建立烟叶等级分类模型。 几种降维方法选取前6个成分做为输入指标, 采用SVM做为分类器。 表2为几种方法下郴同等级烟叶分类准确性对比, 为防止偶然性, 准确率取5次实验结果的平均值。
| 表2 烟叶分级结果对比 Table 2 Comparison of tobacco leaf grading results% |
由表2可以看出, 对于每个等级烟叶的分类准确率, 全谱段做为输入特征效果最差, 主要由于高维光谱中存在较多噪声和冗余信息, 无法实现烟叶分级信息的有效提取, 影响了分类的准确性。 JMLPP方法烟叶总体分类的准确率为93.8%, 每个等级的分类准确性都明显高于其他方法, 说明该方法能较好的对烟叶分级信息进行提取, 这与前面投影分析结果一致。
敏感度与特异度可以分别衡量算法对于正例与负例的识别能力, 表3为几种分级算法模型对5种等级烟叶分类的敏感度与特异度对比。
| 表3 烟叶分级算法敏感度与特异度对比 Table 3 Comparison of sensitivity and specificity of tobacco leaf classification algorithms |
可以看出, JMLPP算法的敏感度、 对烟叶等级的识别错误率明显好于其他几种方法, 进一步说明JMLPP方法具有较好的鲁棒性。
基于联合矩阵局部保持投影算法较好的解决了光谱数据高维、 重叠、 高噪声的问题。 该方法通过聚类实现了与分类相关性强的多个特征子集的提取, 并集后得到联合矩阵, 有效降低了光谱数据维度, 减少了噪声干扰。 通过对LPP算法的改进, 解决了高维数据欧氏距离度量不准确的问题, 提高了降维效果。 实验结果表明, JMLPP方法对于烟叶等级判定具有更好的准确率与鲁棒性, 可以作为烟叶分级的一种新方法。 下一步, 需要提高算法效率, 拓宽算法的应用范围。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|