

{kind=link}
{kind=link}
{kind=link}
基于高光谱技术反演大豆生理信息的特征波长提取方法研究
[刘爽 , 于海业, 朴兆佳, 陈美辰, 于通, 孔丽娟, 张蕾, 党敬民, 隋媛媛
, 于海业, 朴兆佳, 陈美辰, 于通, 孔丽娟, 张蕾, 党敬民, 隋媛媛* ]
, 于海业, 朴兆佳, 陈美辰, 于通, 孔丽娟, 张蕾, 党敬民, 隋媛媛]
|
|


作者简介: 刘 爽, 1993年生, 吉林大学生物与农业工程学院博士研究生 e-mail: 13756900435@163.com
生理信息的准确获取及预测可为种植的精细化管理提供依据。 传统的大豆生理信息反演方法检测效率低、 操作过程繁琐且多为有损检测。 利用高光谱技术建立大豆生理信息的快速无损反演方法。 以大豆开花结荚期叶片为研究对象, 在2个日期(D1和D2)获取高光谱、 叶绿素含量、 净光合速率和光合有效辐射数据。 首先分别采用多元散射校正(MSC)、 标准正态变量变换(SNV)、 一阶导数(FD)、 二阶导数(SD)、 Savitzky-Golay平滑(SG)、 MSC-SG-FD、 MSC-SG-SD、 SNV-SG-FD和SNV-SG-SD共9种方法对原始光谱数据进行预处理, 随后结合偏最小二乘法(PLS)建立全波段模型, 比较分析, 选出最优预处理方法。 再分别利用竞争性自适应权重取样法(CARS)、 连续投影法(SPA)和相关系数法(CC)对特征波长进行筛选提取。 最后将优选出的预处理方法与特征波长变量进行PLS建模并对比分析, 以校正集和预测集相关系数 Rc和 Rp为模型评价指标, 最终优选出与大豆生理信息相关性最高的反演模型。 结果表明: 采用MSC-SG-FD预处理后建立的叶绿素含量全波段PLS模型的Rc和Rp最高, 分别为0.909和0.882(D1), 0.909和0.880(D2), 采用SNV-SG-FD预处理后建立的光能利用率全波段PLS模型的 Rc和 Rp最高, 分别为0.913和0.894, 0.902和0.869, 与原始及其他预处理后建立的模型相比表现出最高的模型性能特征。 进一步对比3种特征波长提取方法的建模, 发现SPA法筛选出的变量能将叶绿素含量反演模型的建模变量数由512个压缩至20个(D1)和23个(D2), 变量压缩率高达96.09%和95.51%, 同时能将光能利用率反演模型的建模变量数压缩至27个和37个, 变量压缩率高达94.73%和92.77%。 最终得出反演叶绿素含量的最优建模方法为MSC-SG-FD-SPA-PLS, Rc值为0.944(D1)和0.941(D2), Rp值为0.911和0.903, 反演光能利用率的最优建模方法为SNV-SG-FD-SPA-PLS, Rc值为0.929(D1)和0.925(D2), Rp值为0.912和0.907, 所建模型精度较高, 可为大面积检测大豆生理信息提供技术支持。
, YU Hai-ye, PIAO Zhao-jia, CHEN Mei-chen, YU Tong, KONG Li-juan, ZHANG Lei, DANG Jing-min, SUI Yuan-yuan
The accurate acquisition and prediction of physiological information can provide a basis for the fine management of planting. The traditional soybean physiological information inversion methods have low detection efficiency, cumbersome operation process and mostly damage detection. To this end, this paper uses hyperspectral technology to establish a rapid non-destructive inversion method for soybean physiological information. The leaves of soybean flowering and pod-forming period were taken as research objects, and the hyperspectral, chlorophyll content, net photosynthetic rate and photosynthetically active radiation data were obtained on 2 dates (D1 and D2). First, multiple scatter correction (MSC), standard normal variable transformation (SNV), first derivative (FD), second derivative (SD), Savitzky-Golay smoothing (SG), MSC-SG-FD, MSC-SG-SD, SNV-SG-FD and SNV-SG-SD methods are used to preprocess the original spectral data, then establish a full-band model by partial least squares (PLS), compare and analyze, and select the optimal preprocessing method. The feature wavelengths are filtered and extracted by competitive adaptive reweighted sampling (CARS), successive projections algorithm (SPA) and correlation coefficient (CC), respectively. Finally, the preferred preprocessing method and the characteristic wavelength variable are modeled and compared by PLS. The correlation coefficients Rc and Rp of the correction set and the prediction set are used as model evaluation indexes, and the inversion model with the highest correlation with soybean physiological information is finally selected. The results showed that the Rc and Rp of the full-band PLS model with chlorophyll content established by MSC-SG-FD pretreatment were the highest, 0.909 and 0.882 (D1), 0.909 and 0.880 (D2), respectively, the Rc and Rp of the full-band PLS model with light energy utilization established by SNV-SG-FD pretreatment are the highest, 0.913 and 0.894, 0.902 and 0.869, respectively, which shows the highest model performance characteristics compared with the original and other pre-processed models. Further comparing the modeling of the three characteristic wavelength extraction methods, it is found that the variables selected by the SPA algorithm can compress the modeling variables of the chlorophyll content inversion model from 512 to 20 (D1) and 23 (D2), and the variable compression rate is as high as 96.09% and 95.51%. At the same time, the modeling variables of the light energy utilization inversion model can be compressed to 27 and 37, and the variable compression rate is as high as 94.73% and 92.77%. Finally, the optimal modeling method for inversion of chlorophyll content is MSC-SG-FD-SPA-PLS with Rc values of 0.944 (D1) and 0.941 (D2), Rp values of 0.911 and 0.903, and the optimal modeling method for inversion of light energy utilization is MSC-SG-FD-SPA-PLS with Rc values of 0.929 (D1) and 0.925 (D2), Rp values of 0.912 and 0.907 The model has high precision and can provide technical support for large-area detection of physiological information.
生理信息的准确获取可使管理者根据其生长状况合理控制作物生长的环境参数, 使水、 肥、 农药等得到精确的管理, 因此, 生理信息准确获取技术的研究可提高农业生产的科学性, 有效促进我国农业整体水平的快速发展。 近年来光谱技术的应用推动了作物生理信息研究方面的快速发展, 尤其是高光谱技术, 获取的光谱波段是连续的, 光谱信息较精准, 因此被广泛应用于作物的生理信息研究[1]。 但是, 高光谱数据的波长间往往会包含一些其他的多余信息, 增加大量的计算工作, 因此对全波段的波长变量进行优选和精简十分必要。 目前的研究表明, 无关信息的存在会极大地降低模型的稳健性, 因此, 对高光谱数据进行特征波长的筛选提取是建立最优大豆生理信息反演模型的重要基础[2, 3, 4]。
近年来提出了一些新型的特征波长变量优选方法, 主要包括竞争性自适应权重取样法(competitive adaptive reweighted sampling, CARS)、 连续投影法(successive projections algorithm, SPA)、 相关系数法(Correlation coefficient, CC)和其他算法等[5]。 国内外学者针对不同特征波长提取方法在建立判别模型上的应用开展了大量的研究, Dai等[6]以虾为研究对象, 以冷冻和非冷冻为试验条件, 将SPA与SNV结合建立新鲜度检测的判别模型, 模型预测集的正确率均高于95%。 刘泽蒙等[7]应用离散萤火虫算法(DFA)进行光谱特征变量筛选建立发酵液丁二酸含量的PLSR模型, Rc和Rp值高达0.986和0.969, 模型精度优于全光谱建模。 牛智友等[8]应用CARS算法进行生物质秸秆中N和O元素含量的高光谱敏感变量优选, 用PLS方法建立了元素定量分析模型, 建模变量数分别为24个和10个, 相对分析误差RPD分别为3.11和2.32, 表明可进行实际应用。 目前对特征波长的提取方法研究, 多是应用在营养成分及元素含量等方面, 而针对农作物生理信息的研究鲜有报道。
本文通过高光谱技术采集大豆开花结荚期不同叶片的光谱、 叶绿素含量、 净光合速率和光合有效辐射数据, 采用9种预处理方法及3种特征波长筛选算法, 筛选出最优预处理方法和特征波长优选方法, 再结合PLS建模探讨不同建模方法组合对反演大豆生理信息(叶绿素含量和光能利用率)准确性的影响, 为研究精准、 无损且快速的大豆生理信息检测技术提供理论依据。
实验于吉林大学生物与农业工程学院日光温室内进行, 供试大豆品种为虎山60, 采用盆栽试验, 于2019年6月19日播种于塑料花盆中, 每盆播种1粒种子, 播种20盆, 所有植株均进行一致管理, 最后挑选10株长势较好、 形态均匀且健康无病虫害的大豆植株作为实验样本。
于2019年7月27日和8月4日(分别以D1和D2表示)进行2次数据采集, 2次采集的数据种类相同, 采样时间为9:00— 14:00, 测量时天气晴朗, 共采集50片大豆功能叶片的高光谱、 叶绿素含量、 净光合速率和光合有效辐射4种数据。 高光谱采用美国Analytical Spectral Devices分析光谱仪器公司产HH2地物光谱仪测定, 测量范围325~1 075 nm, 采样间隔1.4 nm, 分辨率3 nm@700 nm, 每片叶获取10条光谱数据。 叶绿素含量采用日本产SPAD-502测定, 每片叶获取3条数据。 因SPAD-502读数与叶绿素含量密切相关, 因此文中将其值代表叶绿素含量[9]。 净光合速率和光合有效辐射采用美国产LI-6400型光合作用仪测定, 每片叶获取3条数据。 以上4种数据均取其平均值作为分析所用数据。 所用的数据处理与分析软件为ViewSpec Pro, SPSS 24.0, Matlab R2015b和Origin 19.0。
采用5种单一预处理方法分别为MSC, SNV, SG, FD和SD及4种组合方法分别为MSC-SG-FD, MSC-SG-SD, SNV-SG-FD, SNV-SG-SD共9种方法对原始光谱进行处理, 采用梯度法选取40个样本作为校正集, 其余10个样本作为预测集建立全波段PLS模型, 模型的评价指标为校正集和预测集相关系数Rc和Rp, 其中, RAW预处理表示原始光谱, 作为其他预处理方法的对照, 结果如表1。 可以看出, 对于同一种生理信息, D1和D2建立的最优模型所用预处理方法相同, MSC-SG-FD预处理后建立的叶绿素含量模型校正集和预测集相关系数最高, D1所建模型的Rc和Rp分别为0.909和0.882, D2所建模型的Rc和Rp分别为0.909和0.880。 SNV-SG-FD预处理后建立的光能利用率模型校正集和预测集相关系数最高, D1所建模型的Rc和Rp分别为0.913和0.894, D2所建模型的Rc和Rp分别为0.902和0.869。 选取MSC-SG-FD作为建立叶绿素含量反演模型所用预处理方法, SNV-SG-FD作为建立光能利用率反演模型所用预处理方法。
| 表1 高光谱预处理方法优选结果 Table 1 Optimization results from hyperspectral pre-processing methods |
本研究采用的光谱仪有512个波长点, 光谱变量较多, 含有较多的冗余和共线性变量, 需对其进行优选以获取最有效的光谱信息。 将MSC-SG-FD和SNV-SG-FD预处理后的光谱进行特征波长筛选以分别建立大豆叶绿素含量和光能利用率的PLS反演模型。
2.2.1 CARS法筛选特征波长
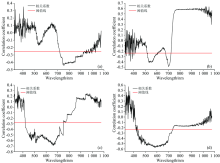
基于CARS法进行大豆生理信息反演模型的特征波长提取结果如图1。 CARS算法中, 每次通过自适应加权采样(adaptive reweighted sampling, ARS)保留PLS模型中回归系数绝对值权重较大的点作为新的子集, 去掉权重较小的点, 然后基于新的子集建立PLS模型, 经多次计算, 选择PLS模型交叉验证均方根误差(RMSECV)最小的子集中的波长作为特征波长。 由于CARS法中的蒙特卡罗采样随着采样次数的不同呈现不同的运算结果[11, 12], 所以本文通过设定不同的采样次数后分别进行运算以选取相对较优的波长变量, 图1为将采样次数设为50次的最优运算结果。 如图1(a)所示, 采样次数较少时, 由于指数衰减函数(exponentially decreasing function, EDF)的作用, CARS法保留的波长变量数快速降低, 当采样次数逐渐增加时, 保留变量数的降低速度逐渐减缓。 由图1(a)可见, RMSECV值呈现不同程度的波动, “ * ” 线标出最小RMSECV值所对应的采样次数, 即从开始到此次采样次数的运算过程中剔除了与大豆生理信息无关的信息, 则此次所选的波长子集即为建立大豆生理信息高光谱反演模型的最优波长, 所选的波长数量见图1(a)。 由图1(a)和(b)可知, 第25次(D1)和第18次(D2)采样时, RMSECV值最小, 对应的最优大豆叶绿素含量建模变量数分别为41个和96个, 剔除的变量数分别为471个和416个, 所选变量占全波段的8.01%和18.75%。 由图1(c)和(d)可知, 第24次(D1)和第27次(D2)采样时, RMSECV值最小, 对应的最优大豆光能利用率建模变量数分别为46个和32个, 剔除的变量数分别为466个和480个, 所选变量占全波段的8.98%和6.25%。
 | 图1 CARS法筛选特征波长 (a): 叶绿素含量(D1); (b): 叶绿素含量(D2); (c): 光能利用率(D1); (d):光能利用率(D2)Fig.1 Characteristic wavelengths selected by CARS algorithm (a): Chlorophyll content (D1); (b): Chlorophyll content(D2); (c): Light energy utilization (D1); (d): Light energy utilization(D2) |
2.2.2 SPA法筛选特征波长
基于SPA法进行大豆生理信息反演模型的特征波长提取结果如图2。 SPA法在运算过程中通过分析投影向量的大小进行特征波长变量的筛选, 通过计算校正模型的RMSE值, 其值最小时, 对应的波长子集即为优选波长[13]。 由图2可见, 随变量数的增加, RMSE值逐渐减小, “ □” 表示最小RMSE值, 对应的即为最优特征波长变量。 如图2(a)和(b)所示, 经SPA法后分别筛选出20个(D1)和23个(D2)特征波长用于建立最优的大豆叶绿素含量反演模型, 剔除的变量数分别为492个和489个, 所选变量占全波段的3.91%和4.49%。 如图2(c)和(d)所示, 分别筛选出27个(D1)和37个(D2)特征波长用于建立最优的大豆光能利用率反演模型, 剔除的变量数分别为485个和475个, 所选变量占全波段的5.27%和7.23%。
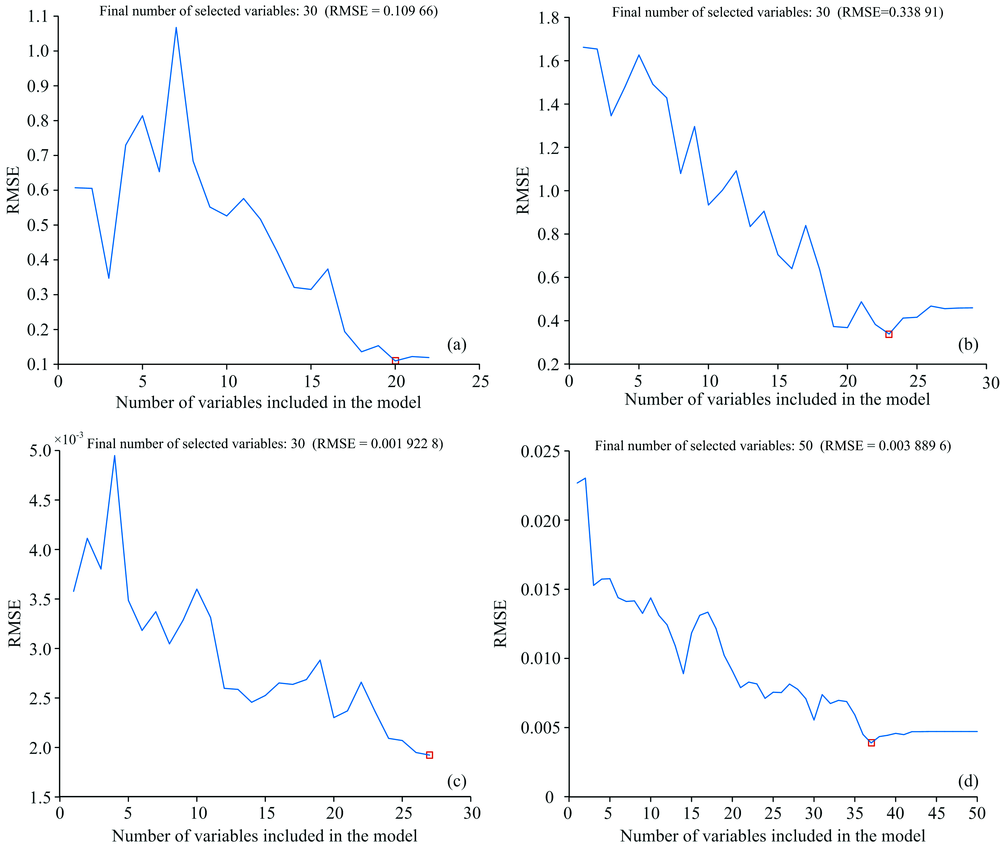 | 图2 SPA法筛选特征波长 (a): 叶绿素含量(D1); (b): 叶绿素含量(D2); (c): 光能利用率(D1); (d):光能利用率(D2)Fig.2 Characteristic wavelengths selected by SPA algorithm (a): Chlorophyll content (D1); (b): Chlorophyll content(D2); (c): Light energy utilization (D1); (d): Light energy utilization(D2) |
2.2.3 CC法筛选特征波长
基于CC法进行大豆生理信息反演模型的特征波长提取结果如图3。 CC法通过计算光谱中每一个波长下的光谱值与叶绿素含量和光能利用率的相关系数, 其值的绝对值越大, 越可能选此波长作为特征波长, 结合波长与对应的相关系数做出波长-相关系数图进行特征波长筛选。 由图3(a)和(b)可知, 大豆高光谱与叶绿素含量在0.05显著性水平下相关的阈值分别为 -0.254(D1)和 -0.236(D2), 阈值线以下的波长为筛选出的特征波长, 筛选出的特征波长变量分别为221个和97个, 剔除的变量数分别为291个和415个, 所选变量占全波段的43.16%和18.95%。 由图3(c)和(d)可知大豆高光谱与光能利用率在0.05显著性水平下相关的阈值分别为-0.279(D1)和-0.236(D2), 筛选出的特征波长变量分别为234个和224个, 剔除的变量数分别为278个和288个, 所选变量占全波段的45.7%和43.75%。
 | 图3 CC法筛选特征波长 (a): 叶绿素含量(D1); (b): 叶绿素含量(D2); (c): 光能利用率(D1); (d):光能利用率(D2)Fig.3 Characteristic wavelengths selected by CC algorithm (a): Chlorophyll content (D1); (b): Chlorophyll content(D2); (c): Light energy utilization (D1); (d): Light energy utilization(D2) |
将MSC-SG-FD和SNV-SG-FD预处理后的光谱与不同特征波长优选方法组合, 分别对应进行叶绿素含量和光能利用率的PLS建模。 基于上述3种波长优选方法的PLS建模结果如表2所示。 与全波段变量所建模型相比, 变量优选后所建模型的反演结果均有明显提升, 通过比较发现, SPA法所建模型的性能优于原始及另外2种特征波长提取方法所建模型。 其中, 叶绿素含量反演模型中, SPA法优选出的变量数最少, 变量压缩率高达96.09%(D1)和95.51%(D2), 模型的校正Rc值从0.909分别提高到0.944和0.941, 预测Rp值从0.882和0.880分别提高到0.911和0.903, 建模因子数从10个减少到7个。 光能利用率反演模型中, SPA法优选出的变量压缩率高达94.73%(D1)和92.77%(D2), 模型的校正Rc值从0.913和0.902分别提高到0.929和0.925, 预测Rp值从0.894和0.869分别提高到0.912和0.907, 建模因子数从10个减少到7个。 可见SPA-PLS模型的计算和预测性能较PLS, CARS-PLS和CC-PLS模型均有显著提高, 表明通过SPA法筛选后, 尽可能地剔除了噪声数据, 特征波长的有效信息完全释放了出来, 避免了有效特征信息被其他相关性不大的波长所遮蔽的现象, SPA法对大豆生理信息的反演表现出了最优的性能, 因此反演大豆生理信息模型的最优波长筛选方法为SPA法。
| 表2 大豆生理信息反演模型结果 Table 2 Soybean physiological information inversion model results |
以大豆开花结荚期叶片为研究对象, 在2个日期(D1和D2)进行了大豆叶片高光谱、 叶绿素含量、 净光合速率和光合有效辐射的数据测量, 采用5种不同的单一预处理方法、 4种组合预处理方法及3种特征波长变量筛选算法对全波段高光谱数据进行处理, 对筛选出的最优预处理方法和特征波长变量进行组合建立大豆生理信息(叶绿素含量和光能利用率)的反演模型。 结果表明: (1)在MSC, SNV, SG, FD, SD, MSC-SG-FD, MSC-SG-SD, SNV-SG-FD和SNV-SG-SD 9种全波段光谱PLS建模预处理方法中, MSC-SG-FD组合为大豆叶绿素含量反演模型的最优预处理方法, SNV-SG-FD组合为大豆光能利用率反演模型的最优预处理方法; (2)3种特征波长提取方法CARS, SPA和CC法均有效减少了建模变量数, 其中SPA法优选出的有效变量数最少, 从512个变量中分别优选出了20个(D1叶绿素含量)、 23个(D2叶绿素含量)、 27个(D1光能利用率)和37个(D2光能利用率)变量, 对应的变量压缩率分别高达96.09%, 95.51%, 94.73%和92.77%; (3)反演大豆叶绿素含量的最优建模方法为MSC-SG-FD-SPA-PLS, 所用变量数分别为20个(D1)和23个(D2), 建模因子数为7个, 对应的Rc值为0.944和0.941, Rp值为0.911和0.903; (4)反演大豆光能利用率的最优建模方法为SNV-SG-FD-SPA-PLS, 所用变量数分别为27个(D1)和37个(D2), 建模因子数为7个, 对应的Rc值为0.929和0.925, Rp值为0.912和0.907。 本研究可为大田及大范围大面积种植大豆时检测其生理信息提供参考, 具有重要的指导和实践意义。
高光谱技术在作物生理信息反演的实际应用中仍存在一些问题有待解决, 如不同品种的大豆或同一品种但生长地点不同时, 其吸收能量及光合作用等能力必然会存在不同程度的差异, 导致对光谱曲线及生理信息数据产生影响, 进而影响提取的特征波长变量, 则在进行生理信息反演时需要大量的数据及建模运算, 工作量较大。 另外, 本研究及大多数学者的研究多以单一大豆生长期为试验时期, 其结果应用于大豆的整个生长期时效果并不理想。 如何将单个时期与整个生长期的生理信息反演模型通用并达到一定的反演精度仍需更深入的探索与实践研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|