



{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱的河蟹新鲜度快速检测研究
[李鑫星1  , 姚久彬
, 姚久彬1 , 成建红2 , 孙龙清1 , 曹霞敏3 , 张小栓4, * ]
, 姚久彬]
|
|


作者简介: 李鑫星, 1983年生, 中国农业大学信息与电气工程学院食品质量与安全北京实验室副教授 e-mail: lxxcau@cau.edu.cn
河蟹的新鲜度是大多数消费者在购买时所考虑的最重要的因素, 挥发性盐基氮(TVB-N)是当前国际通用的评价肉类新鲜度的指标, 但其检测工序繁琐、 耗费时间长, 无法满足当前市场对河蟹新鲜度评价的迫切需求。 因此, 建立一种快速检测河蟹新鲜度的方法是当前急需解决的一大难题。 将购于水产市场的河蟹, 采用聚乙烯充氧袋快速运至实验室, 样本数共126只。 在洁净的工作台上处理后, 将螃蟹分为42个实验样品, 每个样品3只鲜活螃蟹; 42个实验样品放在低温4 ℃的恒温生化培养箱中贮藏, 每天从培养箱中按时取出6个螃蟹样品进行光谱数据采集及新鲜度指标TVB-N的测定, 历时7 d。 采用近红外光谱(NIRS)对贮藏在不同时间下的河蟹新鲜度进行评价, 使用挥发性盐基氮(TVB-N)作为评价河蟹新鲜度的指标, 首先通过比较经五折交叉验证(5-fold CrossValidation)算法、 kennard-stone(KS)算法、 光谱-理化值共生距离(SPXY)算法三种样本划分方法处理后所建模型的预测效果确定最优样本划分方法, 最终采用五折交叉验证(5-fold CrossValidation)算法对样本进行划分。 其中的32个样品被划分为训练集进行模型构建, 其余的10个样品被划分为测试集用于模型检验。 然后在经过五折交叉验证法对样本进行划分的基础上, 分别采用小波变换(WT)、 Savitzky-Golay平滑、 一阶导数法(Db1)、 二阶导数法(Db2)这4种单一算法以及小波变换(WT)与Savitzky-Golay平滑相结合的算法进行预处理, 通过比较预处理后所建模型的预测效果, 确定了小波变换(WT)预处理为最优光谱预处理方法, 从而消除了光谱中的无用信息并提高了信噪比。 再次, 在WT预处理的基础上, 分别采用主成分分析(PCA)法和连续投影 (SPA) 算法提取光谱特征波段, 通过建模比较确定主成分分析(PCA)法为最优波长选择方法, 以所选的16个特征波长作为模型的输入, 不仅提高了模型的运行速度还可以提高模型的稳定性。 最后, 在经过PCA特征提取后, 分别采用偏最小二乘回归(PLSR)算法和多元线性回归(MLR)算法构建TVB-N定量预测模型, 通过比较两种模型的预测效果, 确定了偏最小二乘回归(PLSR)模型为最优建模方法, 最终确定的最优模型为基于WT-PCA-PLSR建立的模型, 模型预测决定系数 R2为0.89, 预测均方根误差RMSEP为3.00。 综上所述, 所建立的预测模型具有较高的精度, 可以实现对河蟹新鲜度的快速检测, 具有较好的市场应用前景。
The freshness of river crab is the most important factor that most consumers consider when buying. Total volatile base nitrogen (TVB-N) is a commonly used international index for evaluating meat freshness, However, its detection process is cumbersome and time-consuming, which can not meet the urgent needs of the current market for rapid and objective evaluation of river crab freshness. Therefore, it is an urgent problem to establish a rapid method for detecting freshness of river crabs. A total of 126 crabs purchased from aquatic market were rapidly transported to the laboratory by polyethylene oxygenation bag. After treatment on a clean bench, the crabs were divided into 42 experimental samples, with 3 fresh crabs in each sample; 42 experimental samples were stored in a constant temperature biochemical incubator at low temperature of 4 ℃. 6 crab samples were taken from the incubator on time every day for spectral data collection and freshness index determination for 7 days. In this paper, near infrared spectroscopy (NIRS) was used to evaluate the freshness of river crabs stored at different time, and total volatile base nitrogen (TVB-N) was used as an index to evaluate the freshness of crabs. Firstly, by comparing influence on the model prediction effect of 5-fold Cross Validation, Kennard-stone algorithm and sample set partitioning based on joint X-Y distance algorithm, finally, the 5-fold CrossValidation algorithm was used to divide the samples. 32 samples were used as training sets for model building, and the remaining 10 samples were used as test sets for model testing. Then, on the basis of dividing the samples by five fold cross validation algorithm, wavelet transform (WT), Savitzky-Golay smoothing, first derivative (Db1), second derivative (Db2) and wavelet transform (WT) combined with Savitzky-Golay smoothing were used to pretreat. Wave transform (WT) pretreatment was the best spectral pretreatment method, which eliminated the useless information in the spectrum and improved the signal-to-noise ratio. Once more, on the basis of the WT pretreatment, principal component analysis (PCA) and successive projection algorithm (SPA) were used to extract spectral feature bands, and the principal component analysis (PCA) was used as the optimal wavelength selection method by comparing the model prediction effect. With the selected 16 feature bands as the input of the model, which not only improved the running speed of the model, but also improve the stability of the model. Finally, after PCA feature extraction, by using partial least squares regression (PLSR) and multiple linear regression (MLR) built the TVB-N quantitative prediction model, by comparing the two kinds of model prediction effect to determined the partial least squares regression (PLSR) model for the optimal modeling method, this paper finally determine the optimal model based on WT-PCA-PLSR model, model prediction determination coefficient R2 was 0.89, and the root mean square error of prediction RMSEP was 3.00. In conclusion, the prediction model established in this study has a high accuracy, and this method can realize the rapid detection of the freshness of river crabs, and has a good market application prospect.
河蟹因其美味且富有营养而具有较高的经济价值, 近年来河蟹养殖产业极速扩张[1], 2014年产量达到796 535 t[2]。
河蟹的新鲜度是大多数人在购买时所考虑的最重要的因素, 挥发性盐基氮(TVB-N)是当前国际通用的评价肉类新鲜度的指标[3]。 然而其检测工序繁琐、 耗费时间长, 无法满足当前市场快速、 客观评价河蟹新鲜度的迫切需求。 因此, 建立一种快速检测河蟹新鲜度的方法是当前急需解决的一大难题。
近红外光谱(NIRS)具有快捷简便, 绿色无污染等优点, 并且已经在食品, 石油, 医药, 农业等领域进行了成功应用[4, 5, 6, 7]。 近年来, 国内外学者建立了许多基于近红外光谱的肉质新鲜度评价模型, 以快速评价肉类的新鲜度。 Abdel-Nour等[8]使用近红外光谱检测鸡蛋的新鲜度, 结果显示传输光谱学是评估鸡蛋新鲜度和蛋白PH值的一个很好的方法。 Huang等[9]结合近红外光谱和化学计量学, 实现了鱼新鲜度的快速和非破坏性评估。 Lin等[10]将近红外光谱与多变量分析相结合检测蛋的新鲜度, 结果表明近红外光谱结合多元校准在蛋新鲜度的分析方面具有显著的潜力。 Chuang等[11]采用独立成分分析与近红外光谱学相集成的方法来评价大米新鲜度, 结果证明该方法具有可行性。
采用近红外光谱评价河蟹的新鲜度, 收集腐败变质过程中蟹肉的光谱信息并测定其挥发性盐基氮含量, 采用多种光谱预处理方法与特征波段提取相结合, 建立了基于近红外光谱的河蟹新鲜度快速评价方法。
实验用的河蟹是2017年12月购于清河水产市场当天从河中捕捞的鲜活螃蟹, 采用聚乙烯充氧袋快速运至实验室, 共126只。 在洁净的工作台上处理后, 将螃蟹分为42个实验样品, 每个样品3只鲜活螃蟹; 42个实验样品放在低温4 ℃的恒温生化培养箱中贮藏, 每天从培养箱中取6个螃蟹样品将蟹肉取出并放入洁净的培养皿中充分压实, 采用近红外光谱仪进行光谱数据采集, 采用凯氏定氮仪进行新鲜度指标TVB-N的测定, 历时7 d。
本实验采用的仪器为德国BRUKER公司生产的MPA型Fourier Transformation近红外光谱仪。
 | 图1 MPA型光谱仪Fig.1 MPA spectrograph |
光谱仪的扫描波数范围为: 3 895~11 988 cm-1(834~2 567 nm), 扫描次数32次, 分辨率16 cm-1。 将蟹肉取出并放入洁净的培养皿中完全压实。 所得到的蟹肉如图2所示。
 | 图2 蟹肉Fig.2 Crab meat |
通过重新加载将每个样品连续扫描3次, 并将获得的3条光谱曲线平均用作待分析的样品光谱。 光谱仪所采集到的蟹肉原始光谱如图3所示。
 | 图3 蟹肉原始光谱曲线Fig.3 Crab original NIR spectra |
TVB-N的测定采用凯氏定氮法。 测量方法采用GB5009.228— 2016[12]中的方法, 其中每个实验样品做3个平行, 取平均值为样品TVB-N的含量(单位为mg· 100 g-1)。
模型的建立需要经过原始光谱样本集划分、 光谱数据预处理、 光谱特征波段提取与预测模型构建4个步骤, 其中每个步骤都是必不可少的, 每一步的结果都会影响到最终模型的预测效果。
用特定方法划分训练集与预测集是为了评价所用方法对未知输入的拟合效果, 每一次划分的训练数据组合均作为一次独立的建模过程训练模型, 并将对应的测试数据组合作为未知数据评价建模效果。 5-fold CrossValidation法、 kennard-stone法、 SPXY法是常见的三种样本划分方法, 用尽量多的数据组合方式来建模, 这样不仅可以选出效果最好的模型, 还可以对建模方法进行更加全面的评价。 分别采用上述3种方法将样本光谱划分为训练集与预测集, 其中的32个样品被划分为训练集进行模型构建, 其余的10个样品被划分为测试集用于模型检验。 为了确保所建模型的适用性, 要确保测试集样品的TVB-N含量在训练集样品的含量范围内。
偏最小二乘回归(partial least squares regression, PLSR)是自变量与因变量均为两种或以上的线性回归分析, 当各变量内部高度线性相关时, 用 PLSR非常有效。 PLSR适用于各种参数优化问题以及模型的最优求解问题, 该方法具有典型相关分析、 多元线性回归分析和主成分分析的优点。 因此, 对每种方法得到的样本划分结果分别采用PLSR全波段建模以确定最终的数据划分方式, 结果如表1和表2所示。
| 表1 基于五折交叉验证法的样本划分结果 Table 1 Five results of 5-fold cross validation method for sample selection |
| 表2 基于3种不同方法的样本划分结果 Table 2 Statistics description of sample selection for the aquaculture sample based on three different algorithms |
R2是模型决定系数, 并且R2越趋近1, 所建模型精确度越高; RMSEC是训练集均方根误差, RMSEP是预测集均方根误差, 模型的RMSEC和RMSEP越小, 所建模型精确度也就越高。 本文采用R2与RMSEP作为判别模型优劣的指标。 由表1可知, 采用第三组的样本划分方式所建立的模型决定系数最高, 均方根误差最小, 因此五折交叉验证最终选择第三组的方式进行样本划分。 由表2可知, 通过五折交叉验证法划分样本所建立的偏最小二乘回归模型训练集与预测集决定系数都在0.85以上, KS算法所建立的模型RMSEP最小, 而通过SPXY算法所建立的模型预测集R2最小且RMSEP最大, 模型精度最低。 与KS算法相比, 五折交叉验证法训练集决定系数、 预测集决定系数更大, 训练集均方根误差更小, 预测集均方根误差稍大, 综合考虑模型决定系数与均方根误差, 最终选择五折交叉验证法进行样本划分。 表3是最终训练集与预测集样本TVB-N含量, 单位mg· 100 g-1表示每100 g蟹肉中所含有TVB-N的含量。
| 表3 样品TVB-N含量 Table 3 TVB-N content of samples in training set and predition set |
原始光谱曲线不仅包含有用信息, 还包含噪声信号, 同时还可能存在诸如基线平移和漂移之类的问题, 所以对原始光谱进行S-G平滑、 小波变换处理以及导数处理是很有必要的。 在比较了经无预处理、 SG平滑、 小波变换(wavelet transform, WT)、 一阶导数法(first-derivative, Db1)、 二阶导数法(second-derivative, Db2)以及不同方法组合等预处理方法以后, 采用PLSR法建立了河蟹新鲜度检测模型, 结果如表4所示。
| 表4 基于不同预处理的PLSR预测效果比较 Table 4 PLSR models based on different pretreatment methods |
由表4可知, 不同的光谱预处理方法对模型的建立有明显的影响, WT, SG平滑及SG平滑与WT相结合的处理效果较好, Db1和Db2的处理结果较差, 结果甚至远劣于无预处理方法, 因而不适用于该模型的光谱预处理。 小波变换处理与SG平滑、 小波变换结合SG平滑处理相比, 模型决定系数更大, 均方根误差更小, 建模效果明显更好。 而小波变换处理与无预处理建模相比, 预测集决定系数0.850 7略低于0.863 6, 差值为0.01, 但预测集均方根误差3.379 3明显小于3.894 4, 差值为0.52。 决定系数本质是比较两列数据的协方差与对应方差积的比重, 由于数据本身存在一定的误差, 所以在R2相对接近的情况下, 采用RMSEP作为评价模型优劣的指标。 因此, 本研究采用WT作为预处理的方法。
由表4可知, 经小波变换处理采用全波段光谱建立的模型效果较优, 模型精度可以满足在线检测的要求, 但在线检测不仅要求精度要高, 而且还要求模型检测速度够快, 因此需要对模型进行优化。 特征波段提取不但能够提高模型的运行速度, 而且能够提高模型的稳定性。 目前常用的特征波段提取方法有连续投影变换(successive projection algorithm, SPA)、 主成分分析(principal component analysis, PCA)、 遗传算法(genetic algorithm, GA)、 无信息变量消除算法(uninformative variable elimination, UVE)等。 PCA通过筛选原数据集各组成向量(即原数据集矩阵的每个字段, 一个字段代表一个特征, 也可称为变量)协方差矩阵的累积方差, 组合出将原数据集矩阵变换到主元空间的变换矩阵, 原数据集矩阵与该变换矩阵的乘积即是原数据集各变量在主元空间的线性组合[13], 即利用原数据在主元空间上的映射来表示原数据矩阵, 由于在主元空间上可用更少的变量表示, 从而实现了对原数据集的降维。 SPA选择含有最少多余信息的波长变量组合以最小化信息重复叠加。 本研究所包含的光谱波段较多, 利用主成分分析法和连续投影算法可以对光谱特征波段进行有效降维, 有效地提高模型运行的速度。
采用PCA和SPA分别提取经过相同预处理的光谱特征波段, 然后对提取出的最优波段采用PLSR进行建模, 结果如表5所示。
| 表5 基于不同特征提取的PLSR效果比较 Table 5 PLSR models based on different feature extraction methods |
由表5可知, 与全波段建模相比较, 经过PCA特征提取之后建立的模型, 预测集决定系数更大, 均方根误差更小, 模型精度更高; 在SPA特征提取之后, 该模型具有更小的R2和RMSEP。 全波段建模包含了更多无用的光谱信息, 特征波段提取有效去除了干扰信息, 使模型性能得到优化。 本文选用PCA作为光谱特征提取的方法。
预测模型的建立
目前常用的建模方法主要有偏最小二乘回归(partial least squares regression, PLSR)、 主成分回归(principal component regression, PCR)、 多元线性回归(multivariable linear regression, MLR)、 人工神经网络(artificial neural network, ANN)等。 MLR可以通过线性拟合多个自变量和因变量之间的关系来确定模型的最优参数。 本研究中涉及多次最优求解问题, 因此本文采用PLSR与MLR进行建模。 本文利用偏最小二乘回归和多元线性回归分别对经相同预处理、 特征波段提取后的光谱进行建模, 获得建立河蟹TVB-N定量模型
的最优算法。 最终的建模结果如表6所示。
| 表6 基于PLSR和MLR的预测模型效果比较 Table 6 Comparison of PLSR and MLR model performance |
从表6可以看出, 通过PLSR获得的模型的预测决定系数R2大于通过MLR建模获得的模型的预测决定系数R2, 并且RMSEP小于MLR建模获得的模型的RMSEP, PLSR优于MLR, 因此本文最终选择PLSR作为建模方法。 实验构建的最佳河蟹挥发性盐基氮模型如图4所示。
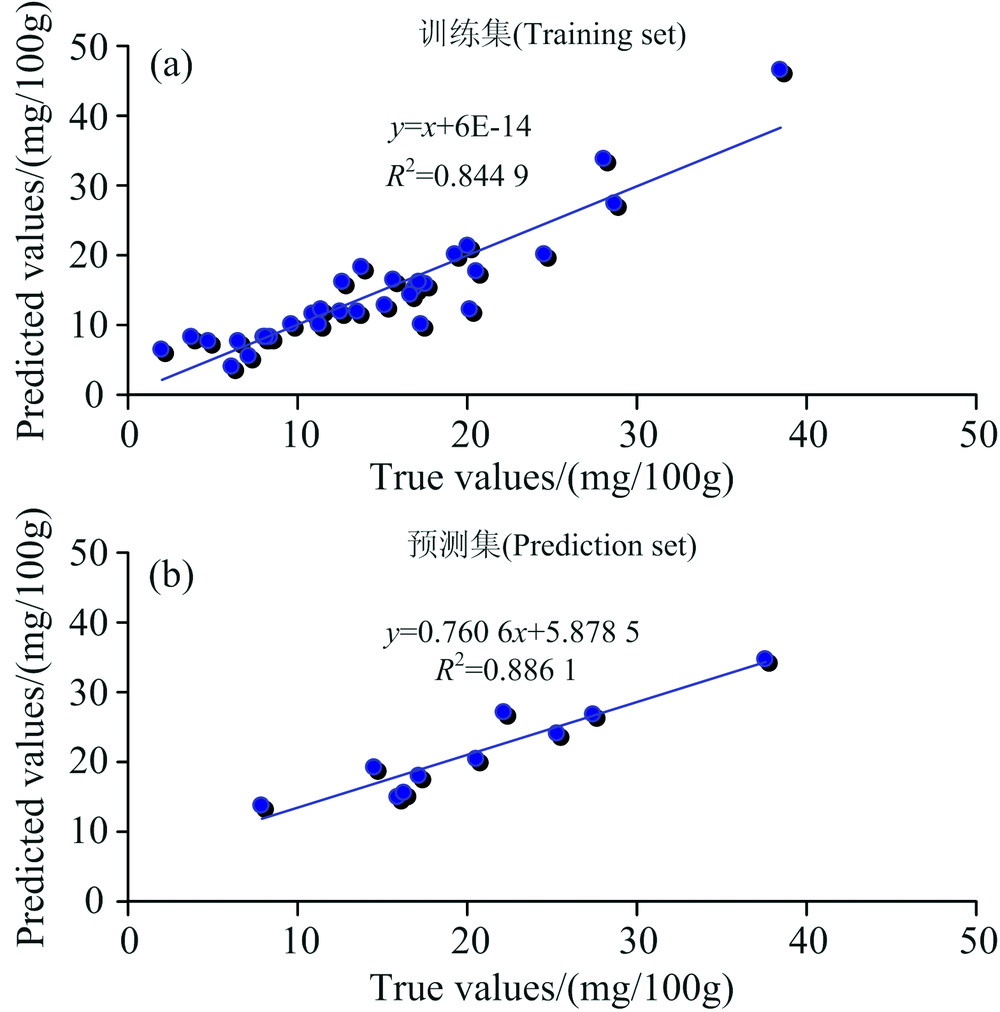 | 图4 TVB-N预测值与真实值散点图Fig.4 Scatter plots of TVB-N predicted value and true value |
利用NIRS构建了河蟹贮存过程中TVB-N预测模型。 首先采用5-fold CrossValidation法对样本进行划分, 其中的32个样品被划分为训练集进行模型构建, 其余的10个样品被划分为测试集用于模型检验。 然后利用WT对原始光谱进行预处理, 消除了无用的信息并提高信噪比。 再次, 采用PCA法提取光谱最优波段, 利用该最优波段作为模型的输入, 不仅提高模型的运行速度, 还可以提高模型的稳定性。 最后采用PLSR法构建了TVB-N定量预测模型, R2和RMSEP分别达到0.89和3.00。 结果表明, 预测模型具有较高的精度, 该方法可以实现对河蟹新鲜度的快速检测, 具有较好的市场应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|