
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于中红外光谱和化学计量学算法鉴别核桃产地及品种
[何勇 , 郑启帅, 张初, 岑海燕
, 郑启帅, 张初, 岑海燕* ]
, 郑启帅, 张初, 岑海燕]
|
|


作者简介: 何 勇, 1963年生, 浙江大学生物系统工程与食品科学学院教授 e-mail: yhe@zju.edu.cn
为探究中红外光谱快速检测核桃产地和品质的可行性, 基于中红外光谱分析技术, 并将化学计量学的算法应用于中红外光谱判别分析之中, 对中国四大核桃主产区的10类主要核桃品种进行检测, 取得较好效果。 通过提取核桃粉末的光谱透射率, 去除原始光谱首尾部分的明显噪声, 对保留的700~3 450 cm-1范围的光谱采用小波分析(wavelet transform, WT)算法进行去噪预处理, 并采用无信息变量消除结合连续投影算法(UVE-SPA)提取光谱特征波数, 采用主成分分析法(PCA)对光谱定性分析, 基于反向传播神经网络(BPNN)、 极限学习机(ELM)、 随机森林(RF)、 径向基函数神经网络(RBFNN)及偏最小二乘判别分析(PLS-DA)对全谱和特征波数建模对比。 在4类不同产地核桃判别中, 得到12个特征波数: 803, 1 355, 1 418, 1 541, 1 580, 1 727, 1 747, 1 868, 2 338, 2 462, 2 824和3 166 cm-1, 基于特征波数分类的正确率高于全谱的分类结果, BPNN算法结合特征波数建模得到的识别正确率高达97%, RF算法分类判别效果最差, 正确率仅69.70%; 在10类不同品种判别中, 得到10个特征波数: 903, 1 275, 1 507, 1 541, 1 563, 1 671, 1 868, 2 311, 2 845和3 437 cm-1, 基于特征波数分类的正确率依然高于全谱的分类结果, BPNN算法结合特征波数建模得到的识别正确率高达83.3%。 在特征波数通用性方面, 两组特征波数范围中有2个特征波数相同: 1 541和1 868 cm-1, 其他大多特征波数也都相近, 将10类品种特征波数作为输入变量对4类不同产地的核桃进行分类, 分类结果较差, 因此, 在10类品种监督值下选取的特征波数无法适用于4类产地的判别问题, 由此推断, 即使是同一原始数据, 基于不同判别问题得到的特征波数在建模时通用性较差。 结果表明, 经UVE-SPA算法提取特征波数后, 变量数可减少99%以上, 有效地简化了模型, 减少计算量, 提高预测的稳定性; 总体上, 每个分类器的表现为: BPNN>RBFNN>ELM>PLS-DA>RF; 基于小波变换结合特征波数选取和反向传播神经网络算法能有效地实现核桃的产地和品种识别。
To explore the feasibility of rapid detection of the origin and quality of walnut by using mid-infrared spectroscopy, mid-infrared spectroscopy and chemometrics algorithms were used to classify walnuts of ten varieties from four major origins and finally good results were achieved. After extracting the transmittance spectra of walnut powder, the apparent noise was removed in the head and the tail of the original spectrum, and the remaining spectrum of 700~3 450 cm-1 was denoised by wavelet transform (WT) algorithm. The spectral characteristic wavenumber was extracted by uninformative variable elimination combined withsuccessive projections algorithm (UVE-SPA). Qualitative analysis of the spectrum was performed by principal component analysis (PCA). Back propagation neural network (BPNN), extreme learning machine (ELM), random forests (RF), radial basis function neural network (RBFNN) and partial least squares discrimination analysis (PLS-DA) were used for modeling based on the full spectrum and characteristic wavenumbers. For the discrimination of four different origins, 12 characteristic wavenumbers were selected: 803, 1 355, 1 418, 1 541, 1 580, 1 727, 1 747, 1 868, 2 338, 2 462, 2 824, and 3 166 cm-1, the discrimination accuracy of characteristic wavenumbers was much higher than that of full spectrum, and the accuracy of BPNN algorithm combined with characteristic wavenumbers reached 97%. The result of RF algorithm was the worst, and the accuracy was only 69.70%. For the discrimination of ten varieties, 10 characteristic wavenumbers were selected: 903, 1 275, 1 507, 1 541, 1 563, 1 671, 1 868, 2 311, 2 845, 3 437 cm-1, the discrimination accuracy of characteristic wavenumbers was still much higher than that of full spectrum. The accuracy of BPNN algorithm combined with characteristic wavenumbersreached 83.3%. In terms of the versatility of characteristic wavenumbers, there were two same characteristic wavenumbers in the two sets of characteristic wavenumbers: 1 541 and 1 868 cm-1, and most of the other characteristic wavenumbers were similar. The spectra based on characteristic wavenumbers of 10 varieties were used as input variables to discriminate walnuts’ origins, and the result was poor. Therefore, the characteristic wavenumbers selected under the supervisory value of 10 varieties could not be applied to discriminate 4 types of producing origins. Even with the same original data, characteristic wavenumbers selected based on different discriminant problems were less versatile in modeling. After extracting the characteristic wavenumbers by UVE-SPA algorithm, the discrimination results showed that the number of variables can be reduced by more than 99%, which effectively simplified the model, reduced the amount of calculation, and improved the stability of prediction. In general, the performance of each classifier is: BPNN>RBFNN>ELM>PLS-DA>RF. The experimental results showed that the identification of walnut origins and varieties can be realized effectively based on wavelet transform, characteristic wavenumber selection and back propagation neural network algorithm.
核桃仁含有丰富的蛋白质、 脂肪酸和多种微量元素, 对人体有益, 具有重要的营养、 药用和保健功能[1]。 核桃内富含的多元不饱和脂肪酸和油脂, 可用于调味和烹饪, 从而丰富饮食结构, 对心脏保护和骨质疏松有积极影响[2, 3]。 经常食用核桃可降低妇女患糖尿病的风险[4], 帮助人体抗衰老, 防止细胞老化, 还有降低胆固醇、 降低血压和抑制其他慢性病的功效[5, 6]。 由于产地和种类不同, 核桃的品质也有差别, 因此根据核桃的品质进行分级具有重要意义。 核桃产地和品种的鉴别主要依赖于感官体验, 甚至更复杂的过程(例如化学实验分析), 这种传统方法较主观, 且费时费力。 所以, 找到一种快速简便的判别核桃品质的方法具有重要的意义。
红外光谱, 例如近红外(near infrared, NIR)光谱和中红外(mid-infrared, MIR)光谱, 是一种可以检测物质中特殊分子不同吸收频率的化学分析工具。 不同的分子结构可以产生不同的吸收谱带[7]。 光谱技术在食品组分分析方面有着快速、 简单、 灵敏等优势, 而中红外光谱是由分子的基频振动组成的光谱, 其吸收带多而窄, 吸收强度大, 有显著的吸收特性, 提供了更多的频率和强度信息; 而且大多典型官能团的特征振动峰大多分布于中红外区; 因此, 中红外光谱被广泛应用于替代化学方法的定性和定量分析领域[8]。 吴迪等[9]用中红外光谱法快速检测了奶粉中蛋白质和脂肪含量。 Clegg等[10]将中红外应用于制药, 监测化学转化过程。 Botelho等[11]使用中红外光谱检测牛奶中是否有掺杂物。 Vermeulen等[7]和Zhou等[12]利用中红外光谱技术对酒糟的产地来源进行了分类判别以区分其品质。 Kanakis等[13]利用中红外光谱技术对薄荷的产地进行了识别, 识别结果最高可达90%。 贾昌路等[14]利用近红外光谱对新疆产地不同品种的核桃进行了相对区别。 不同的核桃主产区, 其生长环境(温度, 湿度, 降雨量, 光照时间等)存在很大的差异, 所生产的核桃品质也会有不同, 而中红外在核桃产地和品种检测方面鲜有研究。
红外光谱携带有大量信息, 其中部分信息对于建立模型无相关性, 甚至还会干扰建模效果, 因此需要剔除无用的信息, 选出相关的特征波数用于建模。 本研究的主要目的是根据中红外光谱结合特征波数选择算法和化学计量算法检测核桃的产地和种类。
从中国主要生产核桃的4个省份采集了10个核桃主产品种, 每个品种重复20个样本。 此10个品种的核桃肉眼区分度很小, 若将其去壳后用肉眼更是无法辨识。 实验前, 将核桃去壳, 取每个品种的核桃研磨成粉末, 称量约10 g作为该品种的一个样本并装入干燥密封袋中。 剔除8个无效样本, 余下的192个样本作为实验样本, 样本详细信息见表1。 所有样品放在真空干燥器中以防止吸水。 实验时, 将核桃粉末与溴化钾晶体按照1:49的比例混合均匀, 压片。 红外光谱采集在25 ℃恒温下进行。 采用日本分光株式会社生产的Jasco FTIR 4100傅里叶变换光谱仪, 测量范围为400~4 000 cm-1, 分辨率为4 cm-1, 每个样品扫描32次后取平均值作为该样品的光谱值。
| 表1 样本信息 Table 1 General information of samples |
无信息变量消除结合连续投影算法(uninformative variable elimination-successive projections algorithm, UVE-SPA)是一种结合无信息变量消除法(uninformative variable elimination, UVE)和连续投影算法(successive projections algorithm, SPA)的特征变量选择算法, UVE可去除大量的无效信息, 基于UVE选择的变量建模可以避免模型过拟合, 并提高其预测能力。 SPA主要解决共线性问题, 用于选择具有最低冗余信息的波数, 获得具有最小共线性的有用变量, 在选取光谱特征变量中取得了广泛的应用[7, 15]。 因此, 结合这2种算法的优势, 首先使用UVE算法, 根据建模时各个变量的稳定性选取带有有效信息的变量, 然后再将UVE选出的变量输入SPA算法, 选择的变量数从1到35范围内变化, 通过比较不同变量数对应的建模最小均方根误差(root mean square error, RMSE), 选出变量的数量。
主成分分析法(principal component analysis, PCA)是一种被广泛应用到光谱数据的定性分析方法。 PCA通过线性变换将原始光谱数据投射到一些新的主成分变量(principal components, PCs), 每一个主成分都是由原始数据线性组合而成, 只需要几个方差最大的主成分即可反映数据信息, 大大降低了数据维度[16]。
极限学习机(extreme learning machine, ELM)是一种单隐层前馈神经网络, 亦是一种快速、 简单的回归和分类方法。 在ELM算法中, 只有隐含层神经元节点数需要被设置以获得独特的最佳解决方案, 通过对不同神经元节点个数下的效果比较, 选择出最优解。 本研究隐层中的神经元以步长1进行寻优, 设定其数量从1到建模集合的上限变化, 根据训练误差最小的原则得出ELM模型中隐藏神经元的数量[17]。
随机森林(random forests, RF)是一种使用多种决策树的综合方法。 RF构造不同的决策树, 决策树相互独立。 为了构建随机森林, 对每个决策的样本进行随机抽样。 决策树节点的特征也从训练集的特征中随机选择。 基于每个决策树输出分类结果。 此算法训练快速并且可调, 同时无需担心要像支持向量机一样调大量参数[18]。
偏最小二乘判别分析(partial least squares discrimination analysis, PLS-DA)算法基于PLS回归模型对目标进行判别分析[15, 19], PLS-DA根据代表类别的整数建立类别关于光谱的回归模型。 然而, 所建立模型判别样本时得出的结果带有小数位, 需要对判别结果设置阈值以确定样本属于哪个类别, 设置阈值为0.5。
反向传播神经网络(back propagation neural network, BPNN)广泛应用于回归分析和判别分析[20]。 利用错误反向传播修改每个训练阶段后的内部网络权重, 直到训练错误或网络的训练阶段达到目标为止[21]。 采用Matlab自带的Neural Network Toolbox工具箱, 判别时的判别阈值与PLS-DA一样, 设置为0.5, 设定目标偏差为10-5, 学习速率为0.6, 迭代1 000次。
径向基函数神经网络(radical basis function neural network, RBFNN)是另一个普遍使用的人工神经网络, 与BPNN都是非线性多层前向网络, RBFNN通常有3层: 输入层, 带有非线性RBF激活函数的隐藏层和线性输出层。 网络的输出是输入和神经元参数的径向基函数的线性组合[22]。
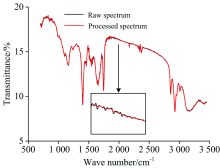
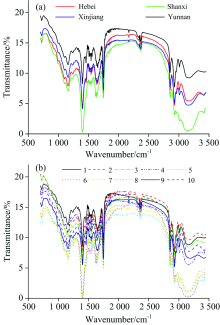
由于实验仪器、 环境和操作等引起的系统误差, 原始光谱的首尾部分有明显噪声, 最终保留700~3 450 cm-1范围的光谱, 并用小波变换对光谱数据进行平滑去噪预处理。 应用小波函数Daubechies的正交小波基Db3进行光谱信号去噪, 其中分解尺度为4。 图1为随机选取某一样本处理前后的光谱, 从中可以看出平滑去噪效果明显。 图2(a)和(b)分别为4类产地核桃和10类品种核桃经预处理后的中红外光谱。 可以看出, 各类光谱之间存在一定的差异, 并且在1 060~1 800 cm-1波数范围内有很多明显的吸收峰, 主要的峰为1 200 cm-1附近的C— C振动峰, 1 401 cm-1N=N振动峰, 1 600 cm-1附近的— COOH-和— N
 | 图1 随机选取样本的原始光谱和小波变换处理后的光谱Fig.1 Raw mid-infrared spectrum and mid-infrared spectrum preprocessed by wavelet transform of a randomly selected sample |
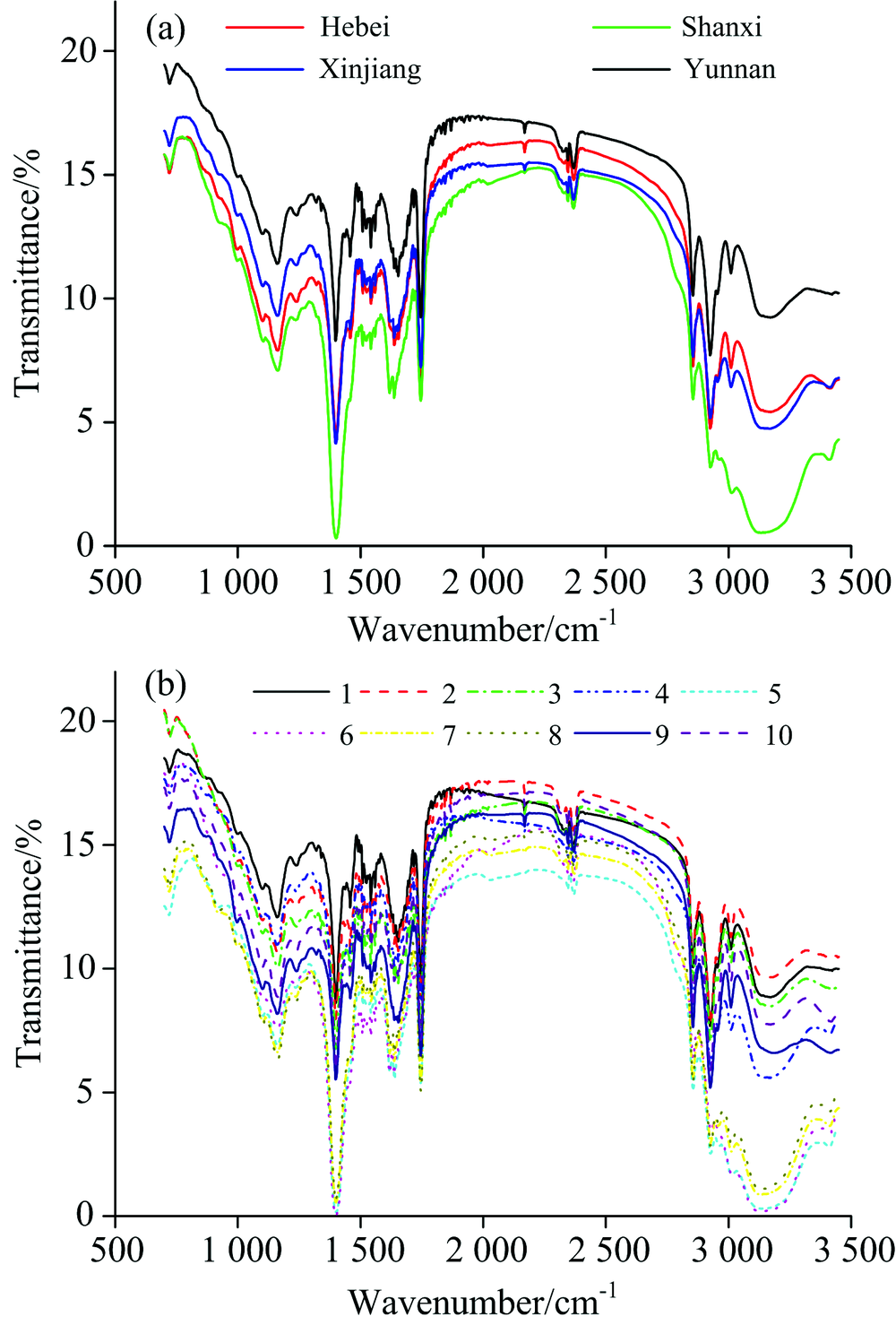 | 图2 4类产地预处理后的平均光谱(a)和10类品种预处理后的平均光谱(b)Fig.2 Average spectra after preprocessing of four origins (a) and average spectra after preprocessing of ten varieties (b) |
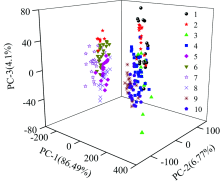
利用PCA对进行平滑预处理后的光谱数据分析, 结果如图3所示。 从中可以发现: PC1, PC2和PC3分别解释了86.49%, 6.77%和4.1%方差, 前3个主成分的解释方差可达到97.36%; 云南产地与陕西产地的核桃区分明显, 新疆产地的核桃与其他3类产地的核桃略有重合, 河北产地的核桃与其他产地的核桃区分度不大。
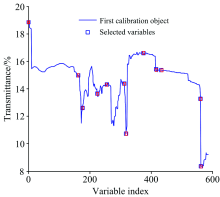
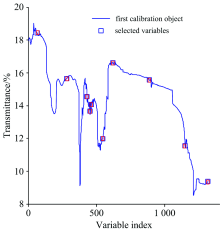
对4类产地数据进行特征波数选取时, UVE算法提取变量数为586, SPA建模使用变量数为12(803, 1 355, 1 418, 1 541, 1 580, 1 727, 1 747, 1 868, 2 338, 2 462, 2 824和3 166 cm-1)时对应的均方根误差最小为0.341 1, 图4为最终选出的特征波数结果。
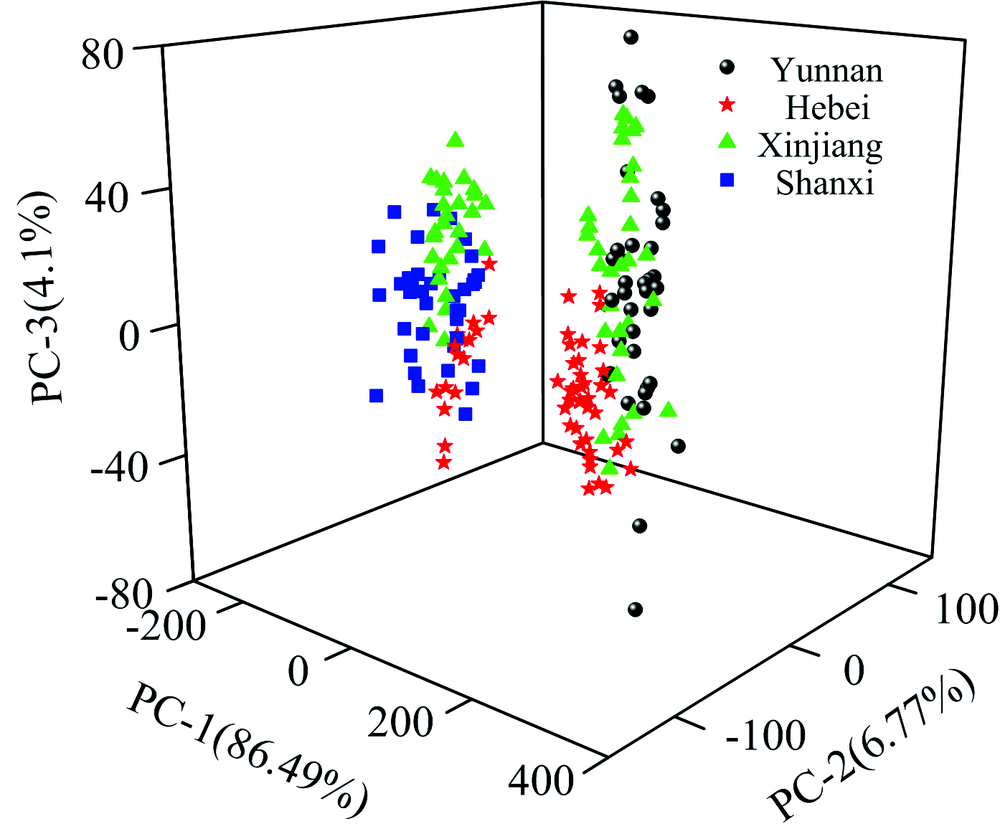 | 图3 不同产地得分图Fig.3 Score plot for different origins |
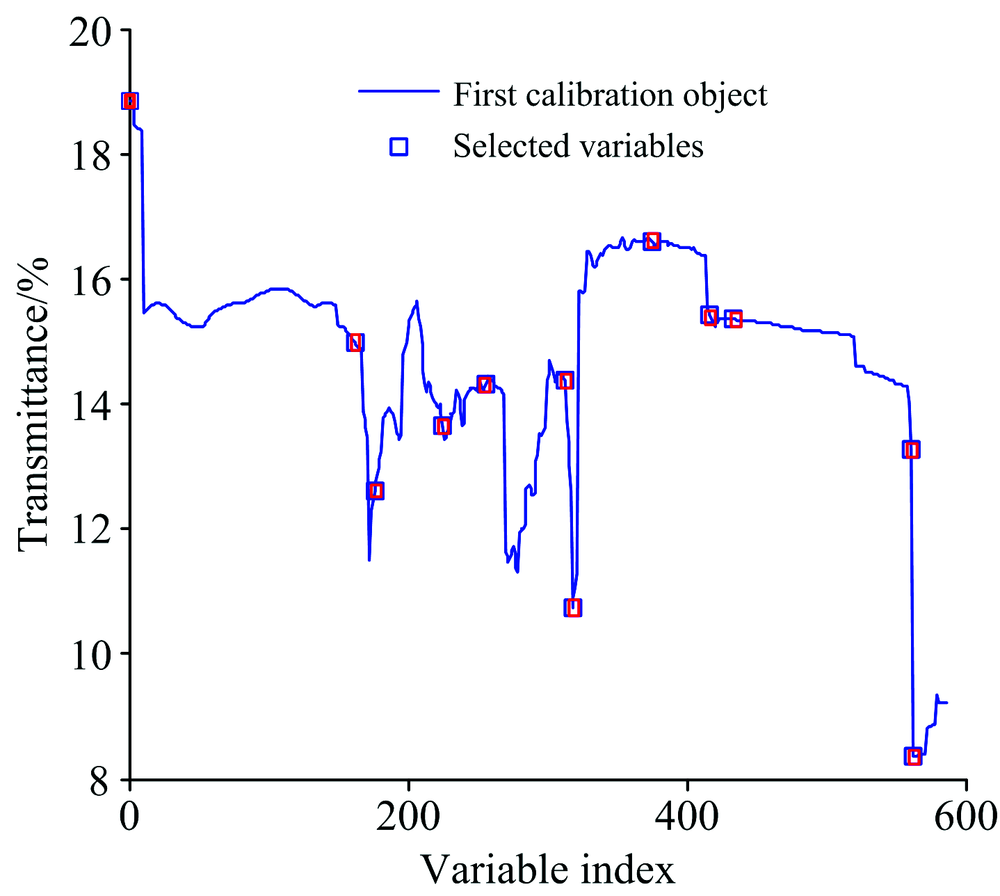 | 图4 四类产地特征波数选择结果Fig.4 Result of characteristic variables selection of four origins |
如表2所示, 将全光谱和选取的4类产地特征波数作为输入量对几种分类器进行比较, 校正集样本数量:预测集样本数量=2:1。 通常4类不同产地的分类难度并不大, 平均正确率能达到80%以上。 从表2可以看出, 基于特征波数分类的正确率高于全谱的分类结果。 BPNN取得了最好的效果, 正确率达到97.0%。 RF分类判别效果最差, 最高正确率仅69.70%, 且对全谱和特征波数的判别没有明显差别, 说明可能RF不适合作为核桃产地的分类器。 PLS-DA分类器对输入的特征波数表现良好, 然而对全谱的判别结果较差, 分析认为该分类器对噪声较为敏感。 RBFNN的识别效果较为良好, 且模型比较稳定, 受输入变量变化的影响较小。 ELM虽建模效果比较稳定, 但是判别结果一般。
| 表2 不同产地分类结果 Table 2 Classification results of different origins |
在比较4类不同产地判别分析后, 尝试对10类不同品种的核桃进行分类。 同样用PCA对10类数据进行分析, 结果如图5所示。 不同产地之间区分明显, 而同一产地不同品种之间区分度不高, 每个品种都与其他几类品种有重叠, 与图3相同, 同一产地的核桃聚集较明显, 而来自新疆产地的第3, 4和5个品种较分散, 且与其他品种混淆, 尤其第3类品种分散明显。
 | 图5 不同品种得分图Fig.5 Score plot of different varieties |
对10类品种数据进行特征波数选取时, UVE算法提取变量数为1 316, SPA建模使用变量数为10(903, 1 275, 1 507, 1 541, 1 563, 1 671, 1 868, 2 311, 2 845和3 437 cm-1)时对应的均方根误差最小为0.777 2, 图6为最终选出的特征波数结果。 4类产地识别和10类品种识别选取的特征波数中, 有2个特征波数相同: 1 541和1 868 cm-1, 其他大多特征波数也都相近。 由于核桃主要成分是脂肪和蛋白质, 查阅文献[8]可知, 选出的特征波数大多落在脂肪和蛋白质的特征峰范围内。
 | 图6 十类品种特征波数选择结果Fig.6 Result of characteristic variables selection of ten varieties |
将校正集样本数量与预测集样本数量的比例依然设为2:1, 利用分类器分类结果如表3所示。 随着判别种类增多, 同产地不同品种之间的区别度较小, 分类难度也随之加大, 只有BPNN的判别正确率可以达到80%以上, RBFNN的判别效果次于BPNN, 最高可达68.2%, RBFNN表现依然比较稳定, 这说明RBFNN判别方法对输入变量的变化不敏感。 ELM与RBFNN效果相当, PLS-DA与RF选择效果最差。 整体上, UVE-SPA特征波数建模效果好于全光谱。
| 表3 不同种类分类结果 Table 3 Classification results of varieties |
在对4类不同产地以及10类不同品种进行判别分析后, 为比较因监督值不同选取的特征波数对建模效果的影响, 尝试将10类品种特征波数作为输入变量对4类不同产地的核桃进行分类, 判别结果如表4所示。
| 表4 不同输入变量产地判别结果 Table 4 Classification results of different input variables |
通过比较表2和表4, 可以明显看出, 基于4类产地监督值选取的特征波数的判别结果总体优于基于10类品种监督值选取的特征波数。 结合前2个判别部分可知, 虽然在选择特征波数时监督值类别为10, 但其所选特征波数并不能应用于监督值类别为4的分类判别。
基于中红外技术鉴别核桃产地和品种, 采用小波变换算法对提取出的光谱数据进行平滑去噪处理, UVE-SPA算法提取特征波数后建模, 在特征波数仅10和12个的情况下, 变量数由原来的2 853减少了99.6%, 由模型结果显示基于特征波数建模的判别效果好于基于全谱的识别效果, 表明中红外光谱结合特征波数选择方法可有效地简化模型, 减少计算量。 采用UVE-SPA算法对去噪后的光谱提取特征波数, 应用化学计量学算法建模判别, 结果显示, BPNN算法的分类判别效果最优, 10类品种判别正确率可达83.3%, 四类产地判别正确率可达97%, 而对于同一原始数据, 在10类品种监督值下选取的特征波数无法适用于四类产地的判别问题, 由此推断, 即使是同一原始数据, 不同类别的判别效果也不一定好, 在今后的研究中可以就同一物质光谱特征波数的建模共享性问题做出更深入的研究。
基于中红外光谱和化学计量学算法对中国四大核桃主产区的10类核桃进行了光谱检测识别。 综合实验结果表明, 基于小波变换结合特征波数选取和BPNN算法能有效地实现对核桃的产地和品种识别。 后期研究可将尽可能多的核桃品种作为研究对象, 探索核桃专属特征波数, 建立更稳健、 适用范围更广的核桃判别模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|