
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于近红外光谱与化学计量学的绿茶快速无损鉴别方法
[李跑1, 2  , 申汝佳
, 申汝佳1 , 李尚科1 , 单杨2 , 丁胜华2 , 蒋立文1 , 刘霞1 , 杜国荣1, 3, * ]
, 申汝佳]
|
|


作者简介: 李跑, 1989年生, 湖南农业大学食品科学技术学院讲师 e-mail: lipao@mail.nankai.edu.cn
绿茶是我国饮用范围最广、 最受欢迎的一类茶叶。 不同品种绿茶叶外观上差别较小, 非专业人员难以直接用肉眼进行辨别。 传统化学方法操作复杂、 检测费用较高, 对样品具有破坏性, 无法实现快速无损分析。 近红外光谱技术是一种简便、 快速、 无损、 重现性好、 可直接用于在线定性定量分析的新型分析技术。 由于种植方式以及土壤、 气候等生长环境的差异, 不同品种绿茶叶中含氢基团有机物的种类和含量也不相同, 因此可以通过扫描样品的近红外光谱, 得到不同品种绿茶叶的特征信息, 实现对不同品种绿茶叶的快速鉴别。 研究提出了一种基于近红外光谱与化学计量学技术对不同品种绿茶的快速无损鉴别方法。 使用近红外光谱仪得到了八个品种绿茶样品的光谱图, 用主成分分析方法对不同品种绿茶样品数据进行了聚类分析。 使用连续小波变换方法消除了光谱信号中的基线干扰, 从而提升聚类效果。 利用基于标准偏差与相对标准偏差的变量筛选方法进一步提高了聚类结果的准确性。 结果表明: 主成分分析后样品的第一主成分和第二主成分的方差贡献率之和在90%以上, 可以选取前两个主成分进行聚类分析。 直接采用原始数据进行聚类分析的准确率较低, 难以满足应用需要; 连续小波变换可以有效地消除光谱信号中的基线干扰。 与直接使用原始光谱聚类结果相比, 采用连续小波变换后聚类效果有显著提升, 但依旧不能实现所有品种茶叶样品的准确鉴别。 为了进一步提高方法的稳健性和分类结果的准确性, 选取了标准偏差和相对标准偏差较大的波长数据进行聚类分析。 在符合平均值大于1%的波长范围内, 剔除标准偏差小于5‰的波长, 进一步选择较大相对标准偏差值对应的波长点进行聚类分析。 采用这种方式, 可以仅使用几十个甚至是几个波长即可实现绿茶样品品种的准确聚类分析。 波长筛选方法可以大大提高主成分分析结果的准确性, 采用近红外光谱分析技术与化学计量学方法可以实现对不同品种绿茶的快速鉴别。 经过对各个光谱吸收区域波长所对应官能团分析后, 初步得出多酚、 酰胺类以及氨基酸类物质的种类不同或含量差异是形成绿茶品种差异的重要原因。 所提出的基于近红外光谱与化学计量学技术的方法具有较强的鉴别能力, 为绿茶的快速无损分析提供了一种新手段。
, SHEN Ru-jia
Green tea is the most popular type of tea in China. The differences of green tea leaves from different categories are very small, and it is hard to distinguish them for non-experts by appearances. Traditional chemical methods are complicated in operation and are destructive to samples and it is difficult to achieve fast and nondestructive analysis. Near infrared spectroscopy (NIR) is a new technology, which is simple, fast, non-destructive, good in reproducibility and can be used for on-line analysis. The differences in the composition and content of the organic components in tea samples would be formed due to different growing environments and panting patterns, which can be measured by the NIR spectra. With the help of NIR spectra, the characteristic information of hydrogen groups can be obtained. The difference information of green tea leaves from different categories can be obtained, and the identification of green tea samples can be achieved. In this study, NIR was applied for nondestructive analysis of green tea leaves from different categories with the aid of chemometric methods. The dataset consists of eight brands of green tea samples. A relation has been established between the spectra and the tea varieties. The data was analyzed with principal component analysis. Furthermore, baseline elimination by continuous wavelet transform was used for improving the accuracy of the method. The wavenumber selection based on standard deviation and relative standard deviation was used to further improve the accuracy. The results show that the total variance explained by the first two principal components in principal component analysis was over 90% and they were enough for further analysis. The result of classification analysis using the original data was poor and cannot be used for the real application. The baseline interference can be eliminated with continuous wavelet transform method and the classification results were improved. The wavenumber selection method based on standard deviation and relative standard deviation consists of two steps. At first, the wavenumbers with standard deviation below 0.005 and the average below 0.01 were removed. Then, the wavenumbers that have large value of relative standard deviation were selected as informative ones, because the larger value of the relative standard deviation, the more variation between the samples. It was found that acceptable classification results can be obtained when several or several tens informative wavenumbers are used. It was found that, the main differences between varieties of tea are polyphenols, amides and amino acids. The results show the classification of different brands of green tea samples can be achieved by the proposed method, which provides a new idea for the rapid analysis of tea samples.
中国是茶叶的发源地, 全国各地盛产不同品种的茶叶。 茶叶主要分为4种, 即不发酵的绿茶、 半发酵的乌龙茶以及发酵的黑茶和红茶, 其中绿茶是我国饮用最广、 最受欢迎的一类茶叶。 不同品类的绿茶叶在外观上差别较小, 非专业人员难以用肉眼实现对不同品种绿茶的辨别。 感官评价法和化学分析法是茶叶鉴别的两种主要方法。 其中感官评价法[1, 2]是一种较为快速、 简单的茶叶鉴别方法, 但是其准确度易受到许多主观因素和外界客观因素的影响。 化学分析法主要是通过测定茶叶的成分来实现不同种类茶叶的鉴别[3], 相较于感官评价法, 该方法结果更加准确可靠。 Miyauchi[4]等利用气相色谱法分析了人工培育茶叶的成分, 实现了对不同光照条件下培育茶叶的鉴别分析。 Wu等[5]使用高效液相色谱分析了绿茶、 黑茶和乌龙茶中的酚类化合物, 以此来区分各个品种的茶叶。 气相色谱与液相色谱操作较为繁琐、 检测费用相对较高, 对样品具有破坏性, 无法实现快速无损分析。 电子鼻[6]和电子舌[7]技术可以分析一定温度和体积下茶叶的香气和味道, 但是这些技术存在准确度偏低的问题, 所以开发一种简单快速无损的茶叶鉴别方法是十分有意义的。
近红外光谱技术是一种简便、 快速、 无损、 重现性好、 可直接用于在线定性定量分析的新型分析技术, 可以实现对复杂样品的快速鉴别[8, 9, 10]。 近红外光谱反映的是样品中有机物的含氢基团信息。 由于种植方式以及土壤、 气候的不同, 不同品种绿茶叶中含氢基团有机物的种类和含量也不相同, 因此可以通过扫描样品的近红外光谱, 获取不同品种绿茶叶的特征信息, 从而实现对不同品种绿茶叶的快速鉴别。 由于近红外光谱谱峰较宽, 实际样品中各种成分的吸收峰重叠严重, 近红外光谱定性和定量分析必须通过结合化学计量学方法来实现[11, 12, 13, 14]。 陈全胜等[15]分别采用了支持向量机、 K最邻近法、 软独立建模聚类分析法(SIMCA)的方法实现了不同茶叶的鉴别。 张龙等[16]利用近红外光谱分析技术结合主成分分析(principal component analysis, PCA)方法对不同发酵程度茶叶进行了判别分析。 有研究利用近红外光谱仪测定茶叶的光谱数据, 先用PCA对不同品种茶叶进行聚类分析, 再使用人工神经网络技术建立模型从而实现品种鉴别。 目前对不同品种绿茶的鉴别研究相对较少, 且使用的化学计量学方法参数较多, 操作也较为复杂。
连续小波变换[17]可以消除信号中的背景和基线干扰, 因此被广泛用于提高近红外模型的准确性和稳健性。 由于样品光谱波长变量有很多是冗余、 干扰的, 会降低定量定性分析结果的准确性, 因此在进行分析时常需要进行变量筛选。 常采用的变量筛选方法有蒙特卡罗-无信息变量消除(Monte Carlo uninformative variable elimination, MC— UVE)[18]以及随机检验-偏最小二乘回归(randomization test-partial least squares regression, RT-PLS)[19]等; 此外, 竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)以及改进方法[20, 21, 22]也被广泛应用到变量筛选中。 这些方法可以提高模型的稳健性以及结果的准确性。 当前, 可用于近红外光谱鉴别分析特别是无监督鉴别分析的变量筛选方法还较少, 本研究[23]提出了一种基于标准偏差(standard deviation, SD)与相对标准偏差(relative standard deviation, RSD)的变量筛选方法并成功用于了药片的快速无损检测。 本文通过结合连续小波变换以及变量筛选, 提出了一种适用于不同品种绿茶快速无损鉴别的方法。 该方法使用PCA对不同品种绿茶数据进行了聚类分析, 引入连续小波变换方法和基于SD与RSD的变量筛选方法提高聚类结果的准确性。 通过对国内八个不同品种绿茶叶样品分析, 结果表明本文提出的方法具有很好的分类和鉴别作用, 为茶叶品种的快速无损鉴别提供了一种新思路。
从茶叶厂商收集了不同产地的八个不同品种的绿茶叶样品(每个样品3 g): 小山茶、 大山茶、 杨山春绿、 九华山毛尖、 五云龙潭、 蓝天茶、 十八盘毛峰、 仰天雪绿等。 使用A— H代表上述八个品种的绿茶叶, 其中每个品种茶叶取10个平行样品, 合计80个样本。
实验采用QuasIR 4000近红外光谱仪(美国Galaxy Scientific), 采用积分球漫反射模式采集全部茶叶光谱。 光谱预处理与聚类分析由MATLAB R2010a(The MathWorks, Natick, USA)软件实现。
实验光谱的采集在室温下进行, 将样品放置在近红外光谱仪光斑的中心位置。 波长范围为12 000~4 000 cm-1, 最小间隔约为4 cm-1, 共采集2 098个数据点。 为了尽可能的获取样品信息, 测量中调整样品的位置, 同一样品测量3次, 取平均光谱作为该样本的原始光谱。
将采集的光谱数据导入 MATLAB R2010a软件中。 由于仪器和环境的干扰, 光谱信号中会出现噪声、 基线漂移。 为提高信噪比, 使用连续小波变换处理以降低背景噪声的干扰, 连续小波变换的小波基为“ haar” 小波基, 小波基的尺度参数为20。 为了进一步提高方法的稳健性和结果的准确性, 引入了基于SD和RSD的变量筛选方法。 首先计算同一波长点下不同样品光谱数据的平均值、 SD值和RSD值, 并剔除平均值小于1%的波长点, 然后剔除SD小于5‰ 的波长, 最后选择那些RSD值较大的波长点作为特征波长进行鉴别分析。 使用PCA方法对八类茶叶样品进行PCA聚类分析。
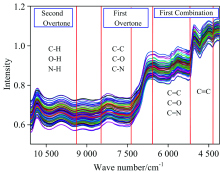
图1为八类绿茶叶样品的原始光谱图, 可以看出各谱线趋势大致相似。 不同样品具有相似的吸收峰, 说明其所含的主要成分相似, 峰强度不同的原因可能是组成样品的某些成分的含量存在一定的差异。 在11 000 cm-1周围有比较明显的谱峰, 为C— H, O— H, N— H二级倍频伸缩振动的特征吸收谱带; 8 000 cm-1附近为C— C, C— O, C— N的一级倍频组合吸收谱带; 5 500 cm-1附近为 C═C, C═O, C═N第一合频的组合吸收谱带; 5 000 cm-1周围为C≡ C的组合吸收谱带。 由图还可以清楚看到光谱存在着明显的背景干扰和基线漂移, 因此需要通过有效的光谱预处理, 以消除其影响。
 | 图1 茶叶原始光谱图Fig.1 Original spectra of tea |
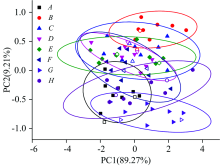
为了实现八个品种茶叶的鉴别, 采用PCA方法对数据进行聚类分析。 在计算中, 使用Kennard-Stone(KS)方法[24]选取64个样品用于建立模型, 16个样品用于验证。 第一主成分(PC1)与第二主成分(PC2)的方差贡献率之和在90%以上, 因此选取PC1和PC2进行PCA分析。 图2显示了不同品种茶叶原始光谱数据的聚类分析结果, 横坐标为PC1方差贡献率, 纵坐标为PC2方差贡献率。 验证集样本用空心图形进行了标注。 不同颜色的椭圆形为不同品种绿茶数据95%置信度的置信椭圆。 从图中我们可以看到, 所有置信椭圆都存在不同程度的重叠区域, 基于原始数据的PCA方法无法实现所有绿茶品质的准确鉴别分析。
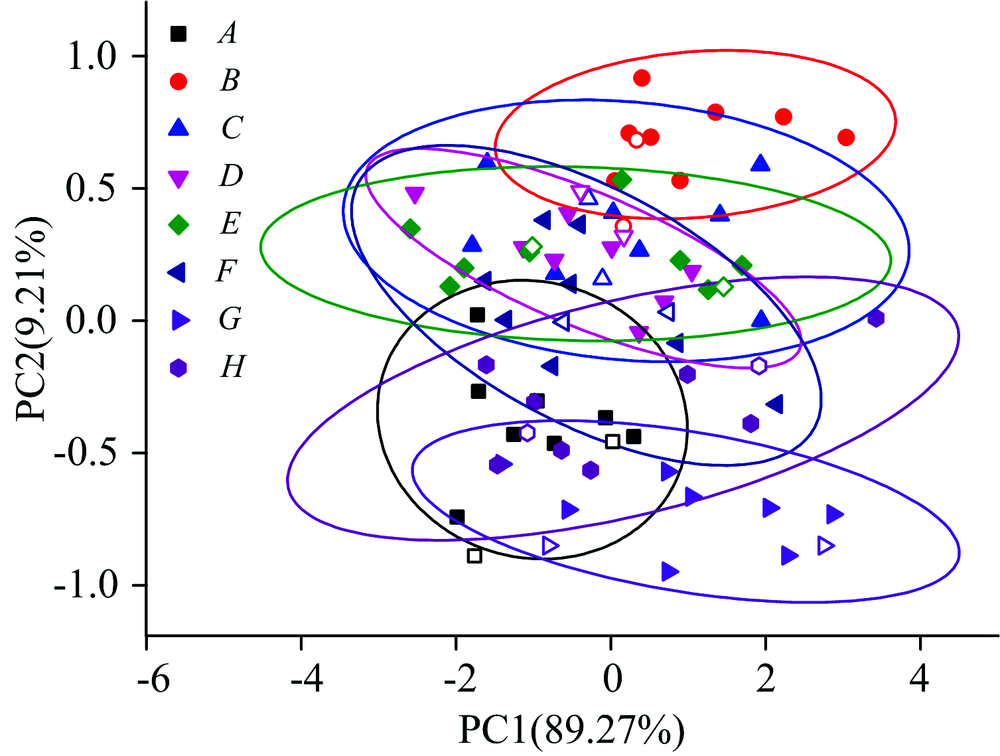 | 图2 原始光谱的PCA图Fig.2 PCA result of the original spectra |
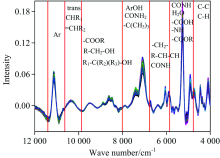
采用连续小波变换的预处理方法消除背景干扰和基线漂移。 图3是通过连续小波变换后的光谱。 从图中就可以看出背景干扰被有效扣除, 基线漂移也得到改善, 表明连续小波变换是消除背景干扰和基线漂移的良好工具。 此外, 从图3中还可以观察到, 相对于原始光谱, 预处理后光谱的特征谱峰明显增多且突出, 更加便于辨认和识别有机物基团[24]。 由图3分析可知, 在11 000 cm-1附近为苯基的特征吸收波段; 10 000~10 500 cm-1附近有峰表明可能存在反式CHR1=CHR2; 8 000~10 000 cm-1的峰群表明可能存在伯醇、 叔醇、 酯基和羧基; 从5 550~5 750 cm-1处的双峰可进一步判断存在酯基、 羧基、 氨基、 水以及CONH; 8 000~9 000 cm-1处的双峰也可证明存在酯基的C— O基团; 由6 500 cm-1附近的单峰可进一步推测存在CONH; 7 000~7 300 cm-1处的双峰是叔丁基的特征吸收峰。 从图3还可以发现, — CH2— 和C≡ C分别在6 900和4 500 cm-1附近有特征吸收, 表明可能包含有长链烷基(可能属于花色苷中的R基或色素类物质); 同时该波段也进一步证明了存在ArOH(可能来自黄烷醇类物质或单宁)。 从图3还可以看出各处的峰高略有不同, 说明不同品种绿茶叶的主要成分虽然相似, 但是各成分的含量有差异。 把图3中5 000 cm-1附近光谱放大后可以看出不同品种绿茶叶的4 720 cm-1峰型存在明显不同, 该波段为氨基酸R基的特征波段, 表明氨基酸的差别是区分不同品种绿茶叶的重要因素。
 | 图3 连续小波变换处理后的光谱Fig.3 Spectra after continuous wavelet transform |
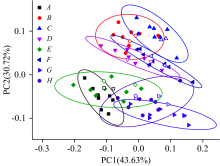
为了进一步提高聚类分析结果的准确性, 将连续小波变换预处理与聚类分析相结合进行分析, 结果见图4。 显然, 连续小波变换预处理后的结果明显优于图2不经过预处理的结果。 虽然连续小波变换处理后结果中D组和F组还是很相近, 但是可以清楚看到八类绿茶叶被明显分成了两大类, 其中A, E, G和H为一大类, 而B, C, D和F为另一大类。 不同绿茶成分存在差异, 导致不同品种绿茶叶光谱的不同。 由于生长海拔不同, 小山茶和大山茶(A和B)存在较大的区别, 可以实现准确鉴别分析。 从图4还可以看出, 即使是来源于同一地区的绿茶样品(C, D, G和H), 其成分也存在一定的差别。 结果表明: 在使用连续小波变换处理后, 变动的背景被有效地消除。 与直接使用原始光谱聚类结果相比, 采用小波变换后的聚类效果有着显著提升, 但仍然不能鉴别所有品种的绿茶叶。
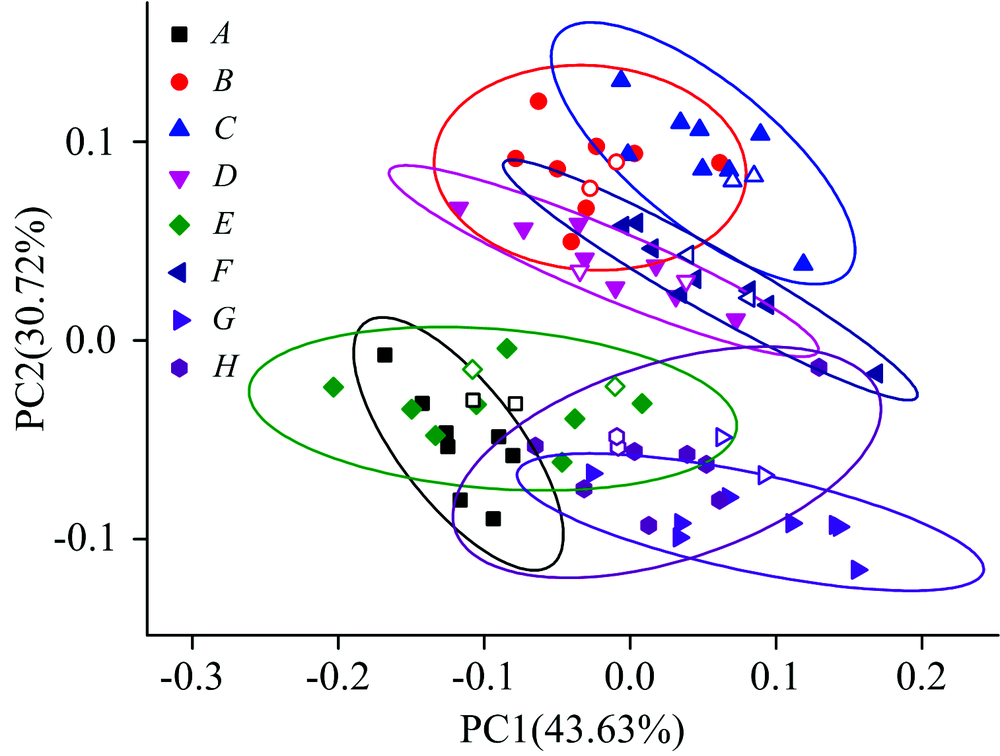 | 图4 连续小波变换处理后的PCA图Fig.4 PCA result processed by continuous wavelet transform |
为了进一步提高方法的稳健性和分类结果的准确性, 选用SD和RSD较大的波长点作为评价参数进行聚类分析。 通过一些有效的波长筛选方法, 选出特征波长, 有利于降低冗余波长变量对方法稳健性的影响, 提高结果的准确性。 计算同一波长点下不同样品光谱数据的平均值、 SD值和RSD值, 得到2 098个波长下的3组数值。 变量的SD值越大, 偏离平均值就越远, 一般认为SD小于5 ‰ 是由操作误差引起的波动, 所需要的正是偏离平均值较远, 能够体现样本差异的变量[21]。 因此剔除了SD小于5 ‰ 的波长, 对全部波长进行了一次初筛, 有效波长范围缩小到7 000~4 000 cm-1。 这个范围即是不同品种绿茶叶在成分上存在较大差异的吸收谱带, 有助于进一步推测不同品种绿茶叶中的差异性物质。 需要注意的是, 如果不同变量的响应差异过大, 或者数据量纲不同, 直接使用SD分析掩盖一些重要变量, 影响分析结果, 在这种情况下, 使用RSD消除测量尺度和量纲的影响将得到更好的结果。 RSD越大代表着样本间差异越大, 较大RSD值的变量更能够体现不同品种绿茶叶之间的差异。 因此在SD初筛范围基础上进一步选择那些RSD值较大的波长点。 由于连续小波变换处理后出现了大量数值接近于0的波长, 其RSD值很大, 但是大多为冗余变量, 如果不加处理会降低鉴定结果的准确性。 因此在使用RSD进行变量筛选前, 剔除了平均值小于1%的波长点。
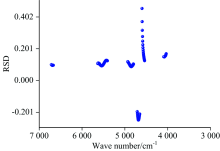
图5为连续小波变换处理后的RSD。 采用这种方式, 可以仅选用几十个甚至是几个波长即可实现准确的聚类分析。 本文选取了10个RSD值较大的波长进行后续计算。 根据图5可知RSD值均小于0.5, 拥有较大RSD值的波段均在4 500~5 000和5 500 cm-1附近, 表明该吸收谱带代表的物质在很大程度上可以代表不同品种绿茶叶的特征, 并且可以用于区分不同品种绿茶叶。 由图3可知该范围多为CONH, — NH, — COOH和— COOR的吸收波段, 表明多酚、 酰胺类以及氨基酸类物质的种类和含量差异是不同品种绿茶叶鉴别分析的物质基础。
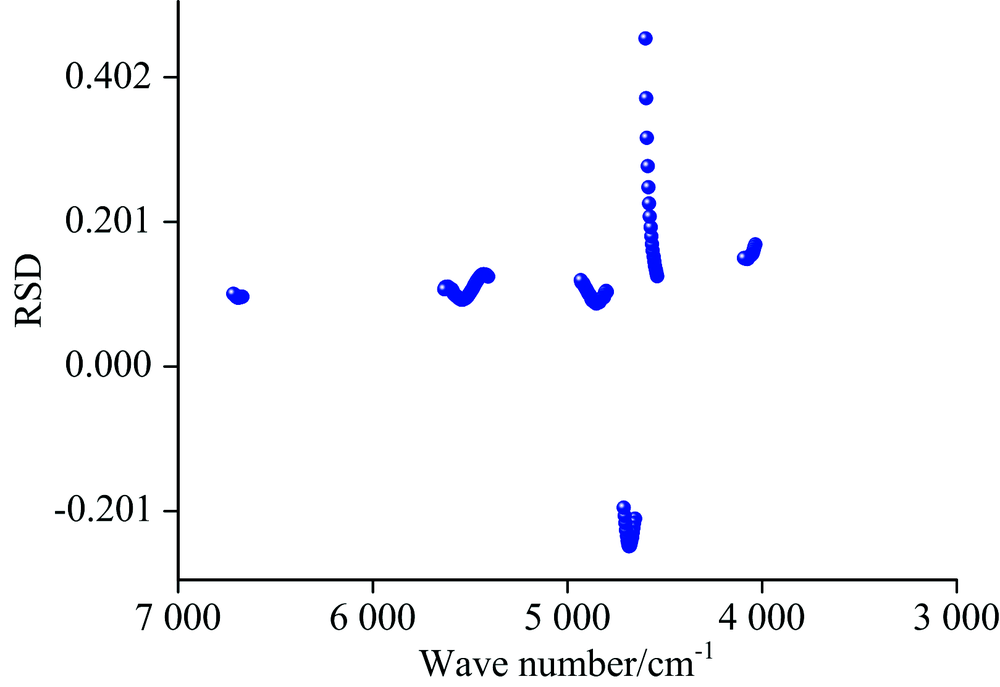 | 图5 连续小波变换处理后的RSDFig.5 RSD result with continuous wavelet transform |
在筛选的波段内用RSD值最大的10个波长点进行PCA聚类分析, 结果见图6。 可以看出, 相比只经过连续小波变换处理, 波长筛选后的结果有了显著改善。 由图6可以发现除F和G两组样品的置信椭圆有部分重叠, 其余各组均可被明显的区分开来, 表明进行波长筛选后可以获得满意的结果。 除了G组的一个验证集样品落入F和G组置信椭圆重叠区域外, 其余所有验证集样品均在各自品种的置信椭圆内, 验证结果准确率为93.75%。 结果表明, 当使用了背景扣除和波长筛选处理后, 可以通过对绿茶叶近红外光谱的分析, 实现对不同品种绿茶叶的快速、 无损、 准确鉴别分析, 并且可以初步判断多酚、 酰胺、 氨基酸及茶氨酸的种类不同或含量差异是形成绿茶叶品种差异的重要原因。
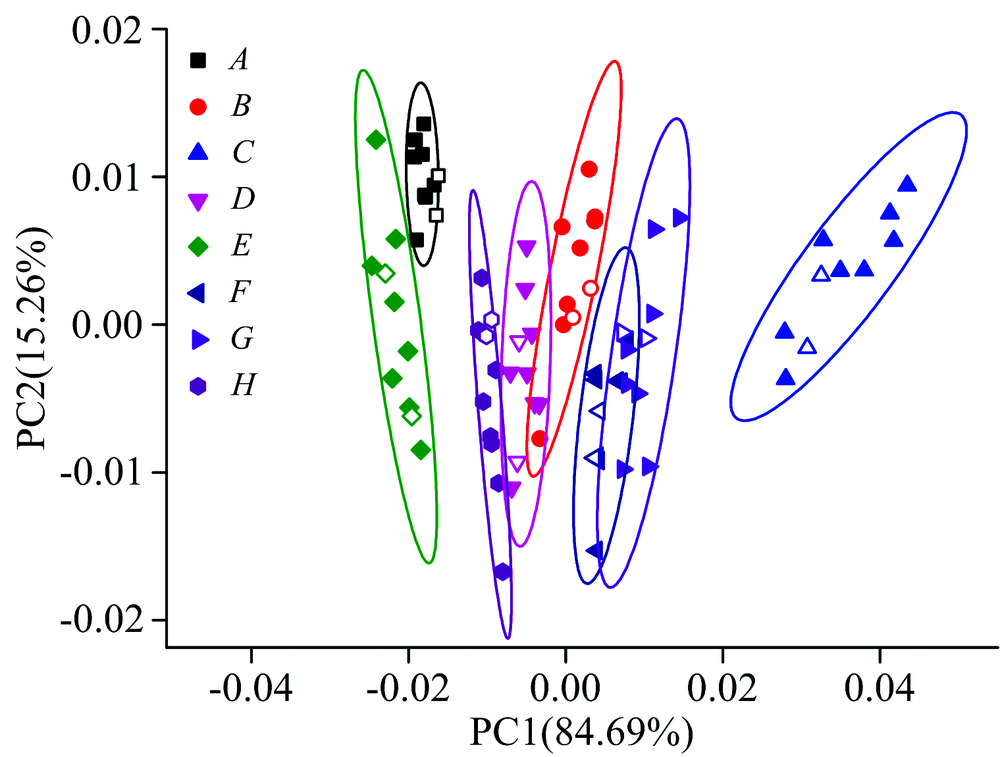 | 图6 小波变换和波长筛选后的PCA图Fig.6 PCA result after continuous wavelet transform and wavelength screening |
应用近红外光谱与化学计量学的结合实现了对绿茶叶的快速分析。 通过对原始光谱图分析发现, 不同品种绿茶叶的化学成分存在一定的差异, 但尚不能从原始图谱上对不同品种绿茶叶进行直接鉴别。 进一步使用连续小波变换预处理后可初步对绿茶叶成分进行大致的推测与判断。 在预处理基础上, 采用波长筛选可以只筛选得到几十个甚至是几个波长数据即可实现准确的聚类分析, 验证样品显示该方法的正确率为93.75%, 较好地实现了不同品种绿茶叶的区分。 经过对筛选波长所对应的官能团进行分析, 初步得出多酚、 酰胺类以及氨基酸类物质的种类不同或含量差异是形成绿茶品种差异的重要原因。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|