{kind=link}
基于核局部保持投影的近红外光谱玉米单倍体识别研究
[刘文杰1, 2  , 李卫军
, 李卫军1, 2, * , 覃鸿1, 2 , 李浩光1, 2 , 宁欣1, 2 ]
, 李卫军, 覃鸿|
|


作者简介: 刘文杰, 1989年生, 中国科学院半导体研究所博士研究生 e-mail: liuwenjie@semi.ac.cn
实现快速、 精确地鉴别玉米单倍体籽粒对玉米单倍体育种技术十分重要。 近红外光谱分析技术可在线分析、 监测, 且无损、 分析速度快、 操作简便、 测试成本低, 对实现自动化的大规模鉴定并分拣玉米单倍体非常有帮助。 通过美国JDSU的近红外光谱仪进行玉米近红外光谱的数据采集, 交叉采集玉米单倍体、 多倍体数据。 数据处理时, 将数据分为训练集和测试集两部分。 依次对数据做预处理以消除噪声影响, 做核变换将其投射到更高维度空间中增强可分性并进行特征提取, 最后建立分类模型鉴别分析。 分别统计采用不同的特征提取算法并建立模型鉴别测试的正确识别率。 实验结果表明, 采用核局部保持投影(KLPP)的特征提取算法的正确识别率更高、 稳定性更好, 在两组测试集上的正确识别率的均值分别达到95.71%和96.43%。 通过分析可以得出, 玉米种子的近红外光谱数据经过非线性变换(为高斯核变换)投影到更高维度的空间后, 表现出更易于分类的分布特点, 保持数据的局部特性也更利于后续的分类。 这为玉米单倍体鉴定进一步研究提供了新的方向。
Haploid identification plays a key role in the field of maize-haploid breeding. To achieve mass and automated identification, Near-infrared Spectroscopy (NIRS) Analysis Technology is widely used. Its advantages include online monitoring, rapid analysis, easy operation, lossless process, cost-effectiveness, etc. At the beginning of the experiment, NIRS data of haploid and polyploidy maize seeds are cross collected via JDSU’s near-infrared spectrometer. To enhance validity, this experiment encompasses a testing set of data besides a training set. After pre-processing, experiment data is subsequently mapped in a higher-dimensional space to enhance its divisibility, and haploid feature is extracted. Then the experiment establishes identification models to predict whether maize seeds are haploid. It needs to point out that the experiment applies different feature extraction algorithms, thus different identification models are established accordingly. The experiment results show that the feature extraction algorithm of Kernel Locality Preserving Projection (KLPP) guarantees accurate recognition in a more stable way. Recognition rate of testing set and training set reaches up to 95.71% and 96.43%. The above experiment proves that NIRS data of maize seeds can be classified more effectively and accurately through non-linear transformation (Gaussian kernel transform in this experiment) and high-dimensional spatial mapping. The above process also maintains partial characteristics of NIRS data. Therefore, this paper may provide some new idea and method for Maize Haploid Identification technology.
玉米单倍体育种技术以其育种周期短、 效率高、 操作简便等特点, 在玉米的育种中有非常广阔的前景[1, 2, 3]。 然而在自然条件下产生玉米单倍体概率非常低[4], 因此如何快速、 精准地鉴别出玉米单倍体对玉米单倍体育种技术显得至关重要。
目前, 国内外的玉米单倍体检测鉴定的方法很多, 主要有: 遗传标记法、 形态学方法、 解剖学方法、 射线照射法、 分子生物学方法等[5, 6, 7]。 而这些方法鉴定时间长、 过程复杂、 鉴定成本高、 有损耗且需要大量的专业人才, 无法实现玉米单倍体鉴定的自动化。 近红外光谱分析技术可在线分析、 监测, 且无损、 分析速度快、 操作简便、 测试成本低[8]。 这对于实现玉米单倍体鉴定的自动化分拣非常有帮助。
将近红外光谱分析技术与玉米单倍体鉴定相结合, 并采用核局部保持投影(kernel locality preserving projection, KLPP)[9, 10, 11, 12, 13, 14]的特征提取算法, 取得了较好的效果。 通过实验说明可以采用分析近红外光谱的方法进行玉米单倍体鉴定, 而且玉米种子的近红外光谱数据经过非线性变换后在更高维度的空间中表现出更易于分类的分布特点, 保持数据的局部特性也更利于后续的分类。 这为玉米单倍体鉴定进一步研究提供了新的方向。
实验采用美国JDSU公司的MicroNIR-1700系列的微型近红外光谱仪。 波长范围: 950~1 650 nm, 分辨率: 12.5 nm, 测量时间(典型值): 0.25 s。
实验所用的玉米品种为: 国家玉米改良中心提供的导入Navajo遗传标记后杂交诱导产生的郑单958玉米单倍体和多倍体籽粒。
近红外光谱数据的获取: 为了验证模型的鲁棒性, 分别于2014年7月2日和7月3日的上午下午, 在外部条件(光源电压、 测试样本与光源的距离等)不变的情况下, 于室内采用漫透射的方式采集的玉米种子单倍体、 多倍体的近红外光谱数据。 在采集近红外光谱数据时, 采用单倍体和多倍体交叉采集的方法, 这是为了减小仪器参数的漂移对实验的影响, 而且实际生产检测中无法事先知道待检测玉米种子的单倍体、 多倍体情况, 更接近自动化检测。 每次采集的玉米种子样本数为50个, 每次每个样本采集一条光谱, 即每次采集的玉米单倍体、 多倍体的光谱数目为50条。
将近红外光谱数据, 分为训练数据和测试数据。 数据处理流程如图1所示, 在训练阶段, 首先对数据预处理, 然后对训练数据进行特征提取得到变换矩阵W, 最后采用支持向量机建立分类模型; 在测试阶段, 先对测试数据进行预处理, 再利用变换矩阵W进行特征提取, 最后用训练得到的分类模型进行分类, 得到数据的分类结果。 在进行数据预处理时, 采用平滑(smoothing)、 一阶导(first derivative, FD)和矢量归一化(vector normalization, VN); 进行数据分类建模时, 采用的是支持向量机(support vector machines, SVM)。
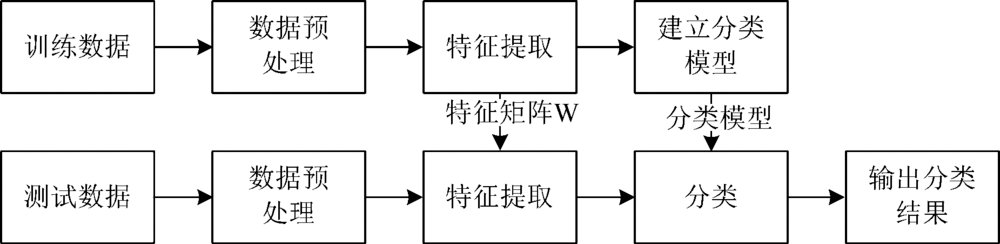 | 图1 实验数据处理流程图Fig.1 Flow chart of experimental data processing |
1.3.1 局部保持投影算法
局部保持投影(locality preserving projection, LPP)[12, 13, 14, 15, 16]是一种能很好地保持数据局部结构的线性特征提取降维方法。 LPP利用数据间的相似性构建数据集的邻接图, 来保持数据的内在几何性质和局部结构, 更加注意数据的局部结构的信息。
设原始样本空间X有n个样本, 每个样本xi为m维的数据, 则X=[x1, x2, …, xn] , xi=[xi1, xi2, …, xim] , i=1, 2, …, n。 通过矩阵变换W, 将原始样本X映射到新的保持了局部结构的低维特征空间Y=[y1, y2, …, yn], 即yi=WTxi。 LPP算法的目标函数为
其中, 矩阵S为原始数据X的邻接图, 其计算方式有如下2种
或者,
其中, 权值
经过对目标函数进行变换, 最终可将目标函数表示为求解(4)式的最小特征值和特征向量。
其中, D为对角阵, 对角线上的元素Dii=
假定求得的按升序排列后的l个特征值为λ 0< λ 1< …< λ l-1, 其对应的特征向量分别为W0, W1, …, Wl-1。 取其前k个特征向量组成最佳投影矩阵。
1.3.2 核局部保持投影
KLPP是一种非线性特征提取方法, 而且保持了数据的局部结构特性。 KLPP将原数据投影到更高维度的空间中, 并保留了数据的局部结构特性, 从而使其更容易分类。
假设原始空间为欧式空间Rn, H为映射后的Hilbert泛函空间, 存在非线性映射Φ : Rn→ H, 使得任意xi∈ Rn可映射为Φ (X)=[Φ (x1), Φ (x2), …, Φ (xn)]。
定义核函数
其中,
那么在H空间中, 式(4)可写为
由式(5), 式(6)和式(7)可得到
其中, K为数据经过核变换后的矩阵。
本文采用的核函数为高斯核函数, 也称作径向基核函数(radial basis function)
求得式(8)中的l个按升序排列的特征值和其对应的特征向量, 取前k个特征向量组成的投影矩阵即为所求的最佳投影矩阵。
分别选取每天上午单倍体、 多倍体各30条近红外光谱进行特征提取、 建立分类模型, 采用每天未参与训练的上午剩余的20条光谱和下午的50条光谱进行统一测试。
在实验中: (1)数据的预处理和建模分类部分, 采用的方法都相同; (2)数据的特征提取部分, 采用了不同的特征提取算法进行对比实验, 采用的特征提取算法包括: 主成分分析(principal component analysis, PCA), 正交化线性判别分析(orthogonal linear discriminant analysis, OLDA), PCA+OLDA, LPP, 核主成分分析(kernel PCA, KPCA)和KLPP。 其中PCA, OLDA, PCA+OLDA和KPCA为全局特征提取算法, 对于数据的全局特征有较好的处理作用; LPP和KLPP为局部保持特征提取算法, 对数据的局部特性有很好的保持作用; PCA, OLDA, PCA+OLDA和LPP为较低维度空间上的特征提取算法; KPCA和KLPP通过核变换将数据映射到更高维度上, 是高维空间中的特征提取算法。 采用不同的特征提取算法做对比实验, 实验结果如表1所示。
| 表1 基于不同特征提取算法的识别率结果统计 Tabel 1 The recognition rate results statistics of extraction algorithm based on different characteristics |
由表1的实验数据可以得出: (1)基于KLPP特征提取算法的识别率(7月2日为95.71%、 7月3日为96.43%)和基于KPCA特征提取算法的识别率(7月2日为95%、 7月3日为93.57%)明显高于基于LPP特征提取算法的识别率(7月2日为91.43%、 7月3日为85.71%)、 基于PCA特征提取算法的识别率(7月2日为87.86%、 7月3日为85%)、 基于OLDA特征提取算法的识别率(7月2日为82.14%、 7月3日为62.86%)和基于PCA+OLDA特征提取算法的识别率(7月2日为89.29%、 7月3日为84.29%)。 (2)基于KLPP特征提取算法的识别率和基于LPP算法的识别率略高于基于KPCA特征提取算法的识别率和基于PCA, OLDA和PCA+OLDA特征提取算法的识别率。 (3)基于KLPP和KPCA特征提取算法识别率的波动性较小, 且明显小于基于PCA, OLDA, PCA+OLDA和LPP特征提取算法的识别率的波动性。
通过对上述实验数据的分析, 可以得出: (1)基于核函数特征提取算法的识别率要明显高于传统特征提取算法的识别率, 识别率较高; (2)基于核函数特征提取算法的识别率的稳定性较高; (3)采用局部保持特征提取算法的识别率要略高于基于全局特征提取算法的识别率, 说明基于数据的局部结构特性的特征提取算法更为有效。 基于以上分析, 可以得出玉米近红外光谱数据在线性空间内难以找出较好的分类界面; 在保持了原始数据的局部结构特性的情况下, 通过核变换将其非线性的映射到高维空间中后, 数据展现出更易于分类的分布特性。
采用多种算法做特征提取, 通过对比试验得出: 基于核局部保持投影的特征提取算法能有效的改善玉米种子近红外光谱原始数据的分布方式, 使其更易于分类, 相比于未采用核变换和未保持局部结构的特征提取算法, 识别准确率高, 达到95%以上, 且稳定性较好。
本文从保持数据的局部结构特性和对数据进行非线性变换即核变换两方面验证了其特征提取的有效性, 为玉米种子单倍体鉴别研究提供了新的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|