

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联合光谱-空间信息的短波红外高光谱图像茶叶识别模型
[蔡庆空1  , 李二俊
, 李二俊2 , 蒋金豹3, * , 乔小军3 , 蒋瑞波1 , 冯海宽4, 5, 6 , 刘绍堂1 , 崔希民3 ]
, 李二俊, 乔小军|
|


作者简介: 蔡庆空, 1986年生, 河南工程学院土木工程学院讲师 e-mail: hnnzcqk@163.com
茶叶种类识别和等级划分的实践意义重大。 成像光谱技术较传统检测、 识别手段具有图谱合一及快速无损等优势。 获取了君山银针、 无锡白茶、 信阳毛尖、 和六安瓜片4种外观相近的线条形茶叶的短波红外(1 0002 500 nm)高光谱图像。 首先利用最小噪声分数(MNF)和非参数权重特征提取(NWFE)将高维高光谱数据投影到低维子空间, 然后用单因素方差分析(ANOVA)重新评估投影特征的可分性并选择对茶叶识别较为有效子空间, 同时考虑到“光谱和特征”能较好地表征物质反射属性, 将选择的投影子空间MNF1, MNF2, MNF4, MNF6, MNF8, NWFE1, NWFE2, 及“光谱和特征”一起作为光谱特征集并用SVM分类器获得光谱特征下像元的分类结果。 另一方面, 利用图像本质分解(IID)算法将高光谱图像的光谱分解为自身反射光谱R与阴影成分S; 在均质性较优的光谱范围(1 0061 900 nm)按照光谱距离对R求取梯度图像并用分水岭算法实现了图像空间分割, 得到空间相关度较高的分割子块。 最后, 将像元分类和图像分割结果进行融合, 具体: 在每个图像分割子块中, 重新统计像元分类结果并按照最大投票法对整个子块的类别进行赋值, 也即联合光谱-空间信息的茶叶识别模型。 结果表明, 构建的模型对4种茶叶的识别结果较为满意, 在仅为约1%水平的训练样本下, 茶叶的总体分类精度达94.3%, Kappa系数为0.92。 该模型还较好地克服了茶叶光谱的“同物异谱”现象, 并期待方法对实践生产具有指导意义。
, LI Er-jun, QIAO Xiao-junThe class-identification and grade-determination of tea have practical importance. Hyperspectral imaging possesses conspicuous advantages in data form of the combination of image and spectra, as well as in fast and undamaged checking in food safety, compared with traditional methods. In this study, hyperspectral images of four kinds of tea which have similar appearance were obtained at the spectral range from 1 000 to 2 500 nm. MNF (Minimum Noise Fraction) and NWFE (Nonparametric Weighted Feature Extraction) were used to rotate and project the hyperspectral data from high dimension to lower subspaces. Then, ANOVA (Analysis of Variance) was used to estimate and select the projected subspaces which have better separability, and they are MNF1, MNF2, MNF4, MNF6, MNF8, NWFE1, NWFE2. Then selected subspaces together with the sum of all original bands were fed to SVM classifier. On the other hand, Finally, IID (image intrinsic decomposition) was applied to decompose the original spectra into material reflectance spectra R and shadow spectra S. Next, gradient image was obtained from R, and watershed algorithm was adapted to segment image in spatial dimension. Finally, results of both pixel-classification and spatial segmentation were fused to have better tea identification. The proposed method was proved to have a satisfying result with an overall accuracy of 94.3% and Kappa coefficient of 0.92 given the only 1% training pixels of all the tea pixels. The proposed model well avoids the phenomenon of same material but different spectra, and significance of reference in practical production is expected.
中国是茶叶消费大国, 2016年茶叶种植面积达293.3万hm2, 产量和种植面积均为全球最多[1]。 茶叶的色泽、 外观、 滋味和香气等内外品质直接决定了其等级优劣; 加之长期以来茶叶市场为获取暴利, 对名茶以假乱真、 以次充好现象尤为突出, 因此茶叶的品质及品种识别显得十分重要。 传统的感官定级方法和电子鼻技术[2], 均不能客观且快速地评价茶叶品质。 后来, 光谱技术和图像分析技术逐渐被人们关注并应用[1], 但其都只利用了光谱或图像信息, 未能对茶叶的内外品质进行综合评价。 成像光谱技术(即高光谱成像)为食品品质检测提供了新的技术手段: 一方面其精细的光谱分辨率能较好地描述电磁波与茶叶等物质在特定波长处的化学响应特性, 另一方面图像信息不仅是茶叶外观品质的直观反映, 其对指导实践生产并提供准确的位置信息具有十分重要的现实意义[3]。 另外, 高光谱较其他茶叶检测方法还有简单、 高效、 无损等优点。
高光谱成像技术在茶叶中的应用研究主要分为: (1)栽培管理过程中的长势监测、 病虫害监测等; (2)茶叶生产加工过程中的定量指标反演(如茶多酚含量预测[4])与定性品质评价(如等级划分[5]); (3)茶类识别, 其不仅能鉴别名茶真伪, 还能对茶源原产地起到保护作用[6]。 然而, 目前在利用高光谱图像进行信息提取的过程中, 主要存在以下几个方面的问题: (1)大多研究以样本为研究主体, 即用随机采样的方法判别整批茶叶的品质, 而未从实时在线检测的角度给出全图象的茶叶品质分布图, 但其对实践生产意义重大。 如蔡健荣等[7]利用提取的主成分特征(principle component analysis, PCA)和图像纹理信息并用支持向量机(support vector machine, SVM)对240个碧螺春茶叶样品进行了分类识别, 但未给出识别结果图。 而Kelman等[8]利用最大似然和人工神经网络实现了对五类茶叶的分类, 给出了分类图并使识别结果一目了然。 (2)受成像环境和自身形状的影响, 茶叶的“ 同物异谱” 现象较为明显, 因此如何从高维度的茶叶高光谱数据中提取有效信息并避免“ 同物异谱” 的影响有待研究。
研究主要从在线检测的角度, 提取茶叶在“ 同物异谱” 影响下的有效特征, 并通过分类方法区分外观相似的茶叶, 以期为实践生产检测提供技术支持。
选取了君山银针、 无锡白茶、 信阳毛尖、 和六安瓜片4种外观相近的线条形茶叶, 为便于描述4种茎叶分别用A, B, C和D表示。 4种茶叶均从茶叶市场购买, 并对碎屑和疑似杂质的物质进行选择性去除, 以保证茶叶样品的统一性。
采用的成像光谱仪主要参数如表1所示; 更多光谱仪参数及信息可参阅文献[9]。 扫描成像时还获取了反射率参考板和暗电流数据, 便于进行辐射校正。
| 表1 成像光谱仪主要参数 Table 1 Main parameters of hyperspectral imaging system |
利用反射率参考白板与暗电流数据可对高光谱图像进行辐射校正。 同时利用5点加权平滑法对光谱数据进行了逐像元平滑。 具体的辐射校正、 光谱平滑公式请参阅文献[10]。 由于在光谱范围两端通道的信噪比较低, 以及部分波段存在信号突变, 对这些波段进行选择性剔除, 并最后保留了230个波段以便后续处理。 同时还对茶叶的背景, 即图像中盛放茶叶的盒子, 根据波段和特征(即230个波段反射率之和)的灰度直方图确定分割阈值并对其进行掩膜。 其他图像预处理包括图像裁剪, 拼接等。
1.3.1 光谱特征提取
由于高光谱数据的维度高, 以及“ 同物异谱” 的影响, 仅利用原始高光谱波段的反射率特征难以识别, 因此需用特征提取方法将高维数据映射到有效的低维空间, 通常的做法是寻找最优旋转矩阵并通过线性变换把高维数据旋转到能最大程度保留原始信息的子空间[10], 最小噪声分数(minimum noise fraction, MNF)是较为常见的投影降维方法。 MNF的本质是两次PCA的叠加以确保降维后的子空间特征能按照信噪比排序[11]。 选择MNF对原始高光谱数据进行特征空间旋转。
非参数权重特征提取(nonparametric weighted feature extraction, NWFE)同样是基于线性旋转的一种特征提取方法, 但其投影向量是通过训练样本分布边界确定的, 即其是一种监督降维方法[12]。 NWFE的算法思想和数学原理请参阅文献[12]。 已有研究验证NWFE在分类中一般能表现出较优的性能[11, 13]。 采用NWFE以期找到能区分不同种类茶叶的最佳投影方向。
另外采用单因素方差分析(ANOVA)检验了4种茶叶在MNF和NWFE空间中是否具有显著性差异[14], 并实现对MNF和NWFE的投影子空间进行有效筛选。 具体在每个MNF或NWFE特征子空间中对任意组合的两类茶叶构造如下假设
式(1)中i和j表示不同茶叶的类别组合, k表示投影子空间。 方差分析可以用F值进行假设检验, 统计量F的取值越大, 表示两类样本均值的差异显著性。
综上, 首先对高光谱数据分别进行MNF和NWFE投影变换; 然后利用ANOVA在每个投影变换子空间分别评估随机训练样本的差异性水平; 并根据统计量F值得大小选取可分性较优的投影特征。 最后将选取的MNF, NWFE子空间以及波段和特征组合为新的特征空间以便进一步SVM分类。
1.3.2 光谱本质分解与空间分割
为实现图像分割, 首先用本质分解(image intrinsic decomposition, IID)从原始光谱中提取仅与茶叶自身反射有关的光谱信息; 然后结合光谱距离和分水岭算法实现高光谱图像分割。
原始的光谱反射率可以理解为材料自身反射与非材料自身反射的叠加, 如光照度、 镜面反射和阴影等成分; 任何图像I均可分解为自身反射光谱R与阴影成分S, 即满足I=RS。 但在I已知的情况下求R和S为无约束问题, 可采用基于优化的算法实现R和S的提取[15]。 具体为式(2)
其中, Ri表示当前像元提取光谱; Rj表示当前像元i周围(2r+1)× (2r+1)窗口wi内各像元的提取光谱; Y表示图像强度, 通过取所有波段的反射率均值得到; A(Ii, Ij)为像元间光谱角;
1.3.3 光谱-空间信息融合
用SVM分类器对提取的光谱特征集进行分类可得到像元尺度的分类图像; 然后在图像分割子块中, 统计像元分类结果并按照最大投票法对整个子块的类别进行赋值。 图像分割分水岭像元的类别值同样按照3× 3窗口进行最大投票赋值。
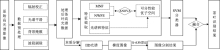
数据处理流程见图1。
 | 图1 数据处理流程Fig.1 Flow chart of data processing |
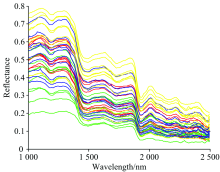
为便于了解茶叶的光谱响应差异, 从每种茶叶中随机选取了10个像元, 分别用红、 黄、 蓝、 绿表示4种茶叶, 如图2所示, 由于成像时茶叶的姿态差异, 混合像元的影响等, 使得茶叶的“ 同物异谱” 现象明显, 即四类茶叶的光谱重叠度较高。 因此, 仅以光谱反射率自身特征很难区分, 需利用更加可靠的光谱特征进行识别。
 | 图2 四类茶叶在近红外波谱范围的光谱响应特征Fig.2 Spectral responses of four kinds of tea in near-infrared region |
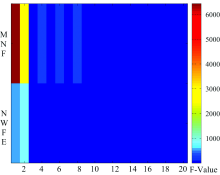
从图像的每类茶叶中随机选取了200个像元光谱作为训练样本(约为800/79 514≈ 1%), 以便求取NWFE投影方向、 ANOVA进行子空间选择和SVM分类器训练, 训练样本之外的所有茶叶像元为测试样本。 对高光谱数据进行MNF和NWFE变换并保留前20个主分量(即MNF1, MNF2, …, MNF20; NWFE1, NWFE2, …, NWFE20)。 本文未直接将所有保留的主分量作为分类的特征空间, 而利用ANOVA评估主分量对训练样本的可分性, 以期选择有效的投影特征并进行下一步分类, MNF和NWFE投影特征的可分性结果如图3所示, F值越大, 该子空间中类别可分性越好。 最后, 选择了MNF1, MNF2, MNF4, MNF6, MNF8; NWFE1, NWFE2较优的投影特征。 同时考虑到“ 波段和” 特征是反映物质反射率水平和茶叶自身吸收特性较好的特征, 将原始所有波段反射率求和作为“ 波段和” 特征, 并与选取的MNF和NWFE投影空间共8个特征形成特征集进行下一步分类。
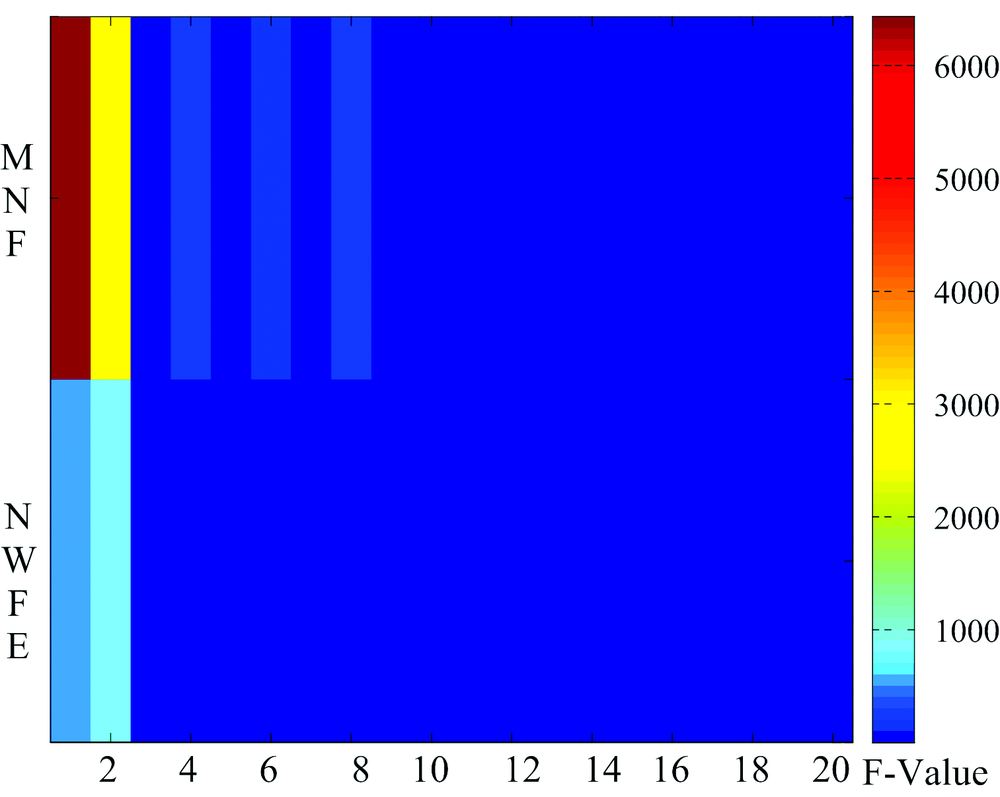 | 图3 MNF和NWFE子空间ANOVA的F值Fig.3 F values of ANOVA in MNF and NWFE projected subspaces |
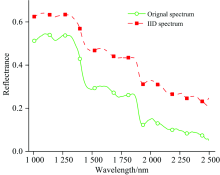
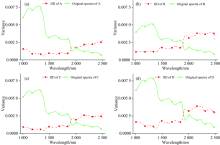
为显示图像本质分解的有效性, 从光谱和空间两个维度展示其分解结果。 由图4可知分解光谱与原始光谱在波形上较为相似, 均体现了物质的光谱响应规律。 为验证本质分解的空间相关性, 在5× 5窗口内统计了其光谱变化, 如图5所示; 在1 0061 900 nm范围IID的方差较原始高光谱图像显著减小, 但1 900 nm之后的方差变化较大且大于原始数据, 其可能原因为: (1)信噪比减小, (2)短波红外更有益于反映物质的本质反射属性。 最后选择1 0061 900 nm的IID数据进行梯度图像求取和分水岭分割。 图6为本质分解与原始波段的图像, 对比可以发现: 本质分解图像中茶叶的纹理和阴影被有效减弱, 茶叶像元的空间相关性和均质性被突出。
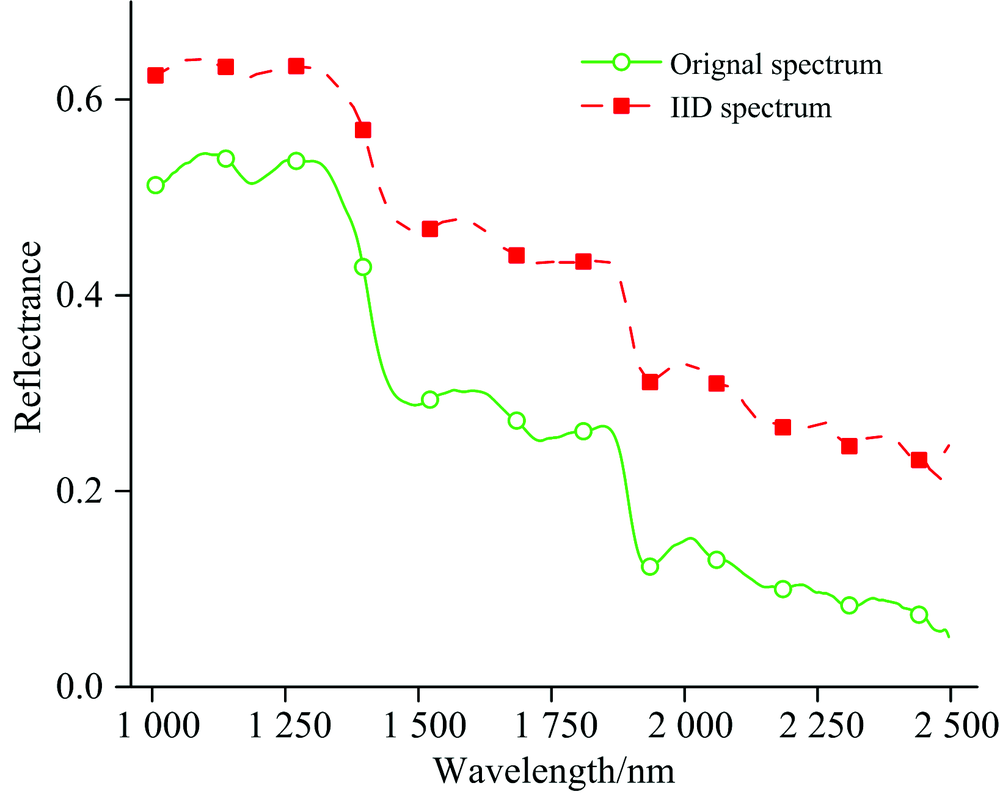 | 图4 图像本质分解光谱与原始光谱Fig.4 Spectra from image intrinsic decomposition (IID) and of original hyperspectral image |
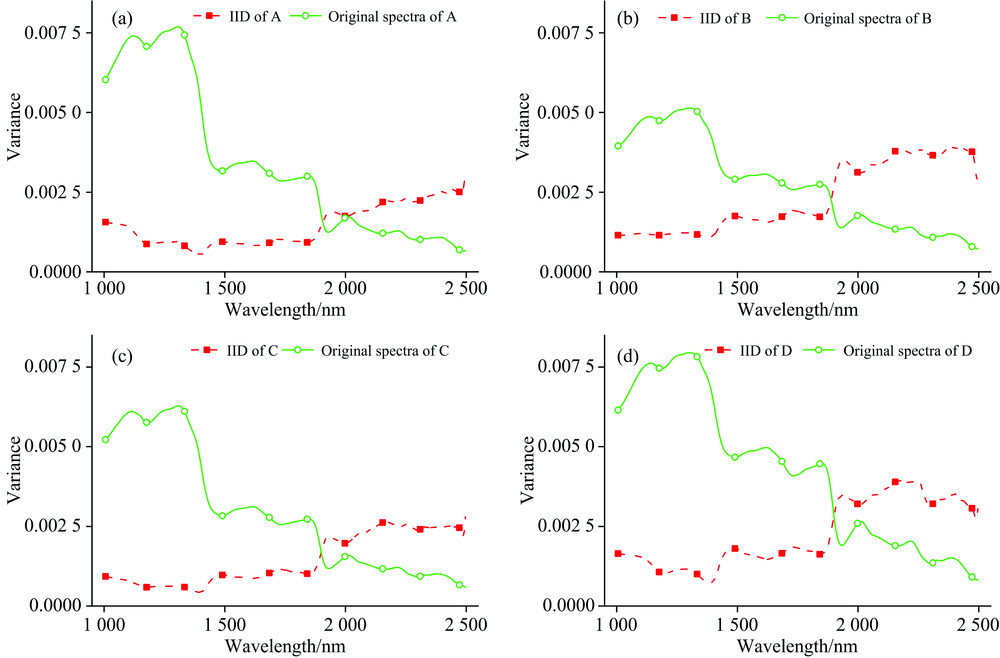 | 图5 图像本质分解光谱与原始光谱在5× 5窗口内的方差Fig.5 Variance of spectra from IID and from original hyperspectral image in the 5× 5 window |
 | 图6 原始波段(上一行)与本质分解(下一行)在1 941 nm的单波段图像Fig.6 Band image from image intrinsic decomposition (IID) (corresponding to the bottom row) and of original hyperspectral image (the top row) at 1 941 nm |
利用训练样本的特征空间训练SVM分类器, 对剩余测试样本进行预测分类。 其中核函数选择RBF, 最优参数C=1 000和γ =0.125通过5折交叉验证确定[17]。 最终, 4种茶叶的分类识别结果如图7, 分类结果统计和精度如表2所示。
| 表2 测试样本的SVM分类精度统计 Table 2 Accuracy estimation of testing-samples by SVM classification |
 | 图7 SVM分类识别结果图 (a)— (d)分别为A, B, C, D 4种茶叶实物图; (e)— (h)为对应的像元分类识别图Fig.7 Identification results of SVM classification (a)— (d) corresponding to the four kinds of tea of A— D; (e)— (h) pixel-wise identification results of classification |
与图7中实物图相比, 分类结果与类别真值基本一致; 类别分类精度在89%以上, 总体分类精度为94.3%, Kappa系数达0.92。 但边缘的混合像元以及部分茶叶存在误分, 可能主要因为: (1)茶叶和背景混合像元或茶叶遮挡的影响, (2)茶叶自身叶绿素含量偏低, 使得不同种茶叶之间的差异性变小。
获取了外观一致的4种茶叶的近红外高光谱图像, 提取并选择识别茶叶的有效投影特征, 利用SVM分类模型识别了不同种类的茶叶。 主要结论如下:
(1)通过重新评估投影特征的可分性并选择对分类识别有效的特征, 构建分类模型较好地克服了茶叶光谱受“ 同物异谱” 现象的影响。
(2)所提出的分类模型对4种茶叶的识别结果较好, 在仅为800/79 514≈ 1%训练样本下, 类别精度在89%以上, 总体精度为94.3%, Kappa系数为0.92, 表明识别模型的可行性。
从实时在线检测的角度, 对外观相近的4种茶叶进行了有效识别。 下一步研究将考虑结合光谱和纹理空间特征区分更多种类茶叶, 检验并提高模型的稳定性, 最终指导实践生产中茶叶真伪鉴别和茶叶等级划分等等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|