



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
无监督学习AE和MVO-DBSCAN结合LIF在煤矿突水识别中的应用
[来文豪1  , 周孟然
, 周孟然1, * , 李大同1 , 王亚2 , 胡锋1 , 赵舜3 , 顾煜林1 ]
, 周孟然, 李大同|
|


作者简介: 来文豪, 1992年生, 安徽理工大学电气与信息工程学院博士研究生 e-mail: whlai9@163.com
快速准确的识别突水类型和突水来源对煤矿安全开采具有重要意义, 激光诱导荧光(LIF)技术在检测中具有快速性和灵敏性, 将LIF应用于煤矿突水的检测, 再结合模式识别算法, 可快速识别出突水来源。 目前用于识别水样光谱的算法过于依赖预先建立的水样光谱数据库, 当突水水源不在该库中时, 易引发误识别。 无监督学习算法DBSCAN在聚类时不需样本集的标签和类别信息, 能降低对未知类别的误识别, 因此把DBSCAN算法用于突水的激光诱导荧光光谱识别, 并将MVO用于DBSCAN的参数寻优, 省去繁琐的人工参数寻优过程。 实验中, 从谢桥煤矿采水点获取四个水样, 利用像素为2 048的USB2000+光谱仪采集水样的荧光光谱, 每种水样采集30组光谱数据。 首先, 利用无监督学习算法自动编码器(AE)对原始光谱数据降维, 以减少光谱数据中冗余信息对聚类的影响, 设计的AE的结构是介于浅层和深层之间的多层网络模型, 可将原始光谱数据降到2维; 为使降维模型具有稀疏性, 在传统的AE算法中加入一个Dropout层, 由实验可知, 加入Dropout层后的降维模型具有较快的收敛速度。 将多元宇宙优化(MVO)算法用于DBSCAN参数寻优, 在参数寻优过程中, DBSCAN对降维后的水样光谱识别率最高为97.5%, 此时参数所对应的取值范围为[0.023 66 0.040 65]; 为验证AE对水样光谱数据降维的有效性, 把归一化后的未降维的光谱数据用于DBSCAN聚类识别, DBSCAN对原始水样光谱的识别率最高为95%, 比降维后的后水样光谱识别率低了2.5%, 结果表明, 使用AE降维光谱数据, 可提高DBSCAN对不同光谱的识别率。 最后, 用监督学习算法K最近邻(KNN)识别降维后的水样光谱, 将识别结果和无监督学习算法DBSCAN的识别结果对比, 其中训练集选用三种水样, 测试集使用四种水样; 在测试集中, 监督学习算法只能准确地识别训练集所包含的水样类别, 但把训练集没有的类别全部识别错误, 而DBSCAN能准确的识别出训练集中没有的水样光谱。 非线性降维算法AE能实现对高维的水样光谱数据降维, 把MVO-DBSCAN用于煤矿突水水源的LIF光谱识别, 可有效降低因矿井水源光谱数据库建立不完备而引起的误识别。
Quick and accurate identification of water inrush types and sources of water inrush is of great significance for safe mining of coal mines. Laser-induced fluorescence (LIF) technology is rapid and sensitive in detection, which applies LIF to the detection of water inrush in coal mines and uses pattern recognition algorithm to quickly identify the source of water inrush. The current algorithms for identifying water samples are too dependent on pre-established water sample spectral databases When the water source is not in the library, it is easy to cause misidentification. The unsupervised learning algorithm DBSCAN does not require the label and category information of the sample set when clustering, which can reduce the misidentification of unknown categories. Therefore, the DBSCAN algorithm is used to identify the laser-induced fluorescence spectra in water inrush, and MVO is used for the parameter optimization of DBSCAN, which can eliminate the cumbersome manual parameter optimization process. In the experiment, four water samples were taken from the water intake point of Xieqiao Coal Mine, and 30 sets of spectral data were collected for each water sample. The fluorescence spectra of the water samples were collected using a USB2000+ spectrometer with a pixel of 2 048. First, the unsupervised learning algorithm automatic encoder (AE) reduces the dimension of the original spectral data to reduce the influence of redundant information in the spectral data on the clustering. The structure of the AE designed in this paper is a multi-layer network model between shallow and deep layers, which can reduce the original spectral data to 2 dimensions. In order to make the dimensionality reduction model sparse, the author adds a Dropout layer to the traditional AE algorithm. It can be seen from the experiment that the dimensionality reduction model after adding the Dropout layer has a faster convergence speed. Then, using the multivariate optimization (MVO) algorithm to optimize the DBSCAN parameters. In the parameter optimization process, the spectral recognition rate of the water sample after DBSCAN is up to 97.5%, and the corresponding range of the parameter Eps is [0.023 66 0.040 65]. The normalized unscaled spectral data is used for DBSCAN cluster identification to verify the effectiveness of AE on the dimensionality reduction of water sample spectral data. The recognition rate of the original water sample spectrum by DBSCAN is up to 95%, which is 2.5% lower than that of the post-dimensional water sample. The results show that using AE dimensionality reduction data can improve the recognition rate of DBSCAN for different spectra. Finally, the supervised learning algorithm K nearest neighbor (KNN) is used to identify the water sample spectrum after dimension reduction, and the recognition result and the unsupervised learning algorithm DBSCAN are compared. The training set uses three water samples, and the test set uses four water samples. For the test set data, the supervised learning algorithm can only accurately identify the water sample categories contained in the training set, but all the categories that are not in the training set are identified incorrectly. On the contrary, DBSCAN can accurately identify the water sample spectrum not in the training set. The nonlinear dimensionality reduction algorithm AE can achieve dimensionality reduction on high-dimensional water spectral data. The use of MVO-DBSCAN for LIF spectral identification of coal mine water inrush can effectively reduce the misidentification caused by the incompleteness of the mine water source spectrum database.
矿井发生突水, 不仅给煤矿开采带来巨大的经济损失, 而且严重威胁井下工人的生命安全。 中国有着丰富的地下水资源, 伴随着开采深度和开采强度的增加, 煤矿面临突水的威胁也越来越大, 在煤矿发生突水后, 准确快速地判断突水类型和突水来源, 采取最为合适的应对措施, 能最大程度减少损失。 激光诱导荧光(laser induced fluorescence, LIF)技术具有很好的快速性和灵敏性, 在检测中应用较为广泛, 如: 王文坦等[1]将LIF技术用于液体混合的定量可视化测量研究, 张会书等[2]将LIF用于测量规整填料内的液体分布, 李嘉铭等[3]将LIF结合激光诱导击穿光谱用于检测波玻璃中的微量元素, 等。 将LIF技术应用于矿井突水检测, 再结合模式识别算法, 可快速的判别出矿井突水类型及来源。 目前已用于矿井突水光谱识别的算法可分为两类, 一是监督学习算法, 如K最邻近(KNN), 极限学习机(ELM)[4], 主成分分析(PCA), 反向传播(BP), 卷积神经网络(CNN)[5]和偏最小二乘判别分析(PLS-DA), MVO(多元宇宙优化), AE(自动编码器)等, 二是无监督学习算法, 如FCM算法。 基于监督学习算法的突水光谱识别, 虽有较高的准确率, 但是需预先建立不同水源的光谱数据库, 由于矿井环境较为复杂, 难以预先获取井下所有水源的光谱数据; 当发生的突水水源不在预先建立的光谱数据库中, 利用监督学习算法识别突水光谱, 就会引起误判; 无监督学习算法FCM在聚类时, 虽不需预先知道所有样本的具体标签, 但是仍要准确知道被聚类样本的类别信息, 因此, 需要一种不依赖于样本标签和类别信息的水样光谱识别方法。
DBSCAN算法是Ester等[6]提出的一种基于密度的无监督学习聚类算法, 在聚类时DBSCAN不需样本的类别数, 也不需样本的标签信息, 本文将其用于煤矿突水的识别。 MVO是Mirjalili等提出的一种较新的启发式寻优算法[7], 具有需要调节的参数较少, 适应性强, 搜索效率高及优化能力好等特点。 Faris等[8]将MVO用于训练多层感知器神经网络, 有效避免其陷入局部最优并且还具有较好的收敛速度; 本研究将MVO用于改进传统的DBSCAN算法, 以实现其参数自寻优, 省去繁琐的人工参数寻优工作。 原始光谱数据含有大量高维信息, 为降低冗余信息的干扰, 减少DBSCAN算法的计算量, 把无监督学习算法自动编码器用于原始光谱数据的降维, 为改善自动编码器降维模型的性能, 在传统的AE算法中加入一个Dropout层。
提出一种基于无监督学习算法的矿井突水光谱识别方法, 将基于密度聚类的DBSCAN算法用于识别突水光谱, 并将MVO用于改进DBSCAN算法, 省去繁琐的人工参数寻优工作; 在传统的AE算法中加入一个Dropout层, 用于降维原始光谱数据, 减少光谱数据中冗余信息的干扰, 提高了DBSCAN对突水光谱的识别率。
激光照射被测样品诱使其发出荧光即激光诱导荧光(laser induced fluorescence, LIF), 分子的荧光光谱与荧光物质的能级结构有关, 水样中包含的物质不同或其浓度不同, 都会有不同的荧光光谱。 此外, 在溶液中, pH值和温度[9]对其荧光光谱都有影响。 煤矿中不同的含水层, 其水化学特征、 pH值和温度等都有差异, 将激光诱导荧光用于矿井突水水源识别, 能充分利用不同水源的差异性, 提高对不同水源的识别率。
将激光诱导荧光技术用于煤矿突水识别, 光谱仪选用的是USB2000+个性化配置型光谱仪(OceanOptics公司, 美国), 像素为2048, 其他可调参数设置如表1所示。 激光器为北京华源拓达激光技术有限公司生产的405 nm蓝紫光半导体激光器。 实验时, 激光器发射的高能激光, 经石英光纤由浸入式微型探头射入实验水样中, 诱导水样发出荧光, 再由浸入式微型探头接收荧光传送至光谱仪。
| 表1 实验仪器参数 Table 1 The USB2000+ spectrometer parameters |
以淮南地区谢桥煤矿为实验区域, 从谢桥煤矿各采集点采集四个水样, 水样的采集由谢桥矿的水样采集员完成, 水样采集点和坐标如表2所示。
| 表2 水样采集地点 Table 2 Water sample collection location |
水样采集好后密封, 带回实验室, 利用激光诱导荧光设备采集水样的光谱数据, 每个水样采集30组LIF光谱图。 四个水样的全部LIF光谱图如图1所示。
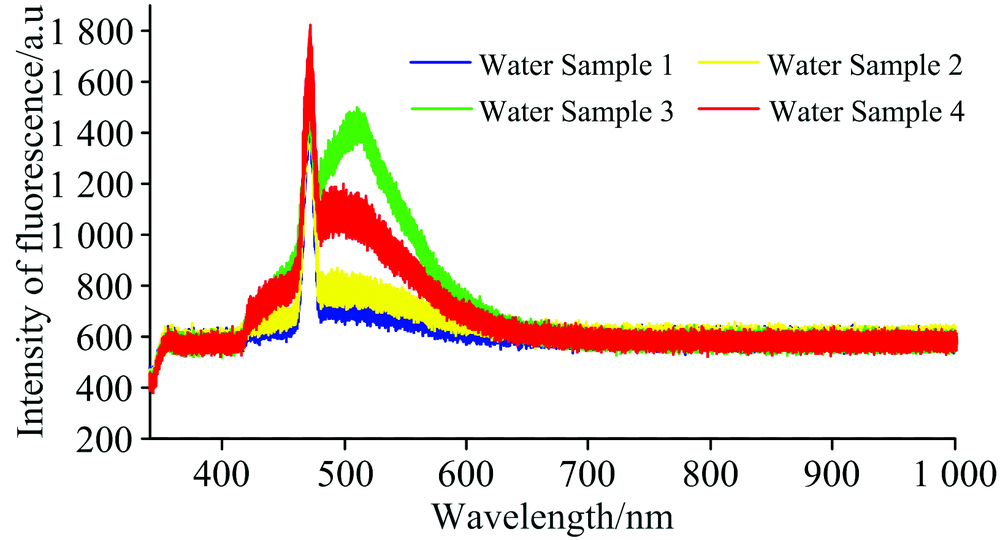 | 图1 水样LIF光谱图Fig.1 LIF spectra of water samples |
图1为共有120组水样LIF光谱图, 每种颜色各代表一种水样的光谱。 从图1中可知, 四种水样的LIF光谱的差异主要集中在波段[400~700 nm]之间, 并且水样3和水样4差异较明显, 水样1和水样2差异相对较小。
无监督学习(unsupervised learning), 即在学习时不赋予模型非常明确且具体的信息, 让模型以无监督的方式自己学习。 目前, 常用的无监督学习算法可分为4种, 分别为聚类算法[10]、 自动编码器[11]、 PredNet和生成模型[12], 其中聚类算法已广泛的应用于模式识别和机器学习领域。
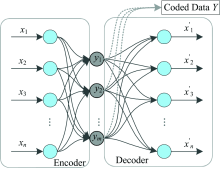
由于选用的光谱仪像素为2 048, 获取的每条光谱曲线有2 048个数据, 选用自动编码器(auto encoder, AE)降维水样光谱数据。 AE最初是由Rumelhart提出的一种无监督学习算法, 主要用于高维复杂数据的处理, 即数据的降维。 AE算法主要包括两部分, 一是Encoder(编码), 二是Decoder(编码), 其中Encoder和Decoder可以是任意的学习模型, Rumelhart曾用神经网络作为学习模型, 这在当初也促进了神经网络的发展, 自动编码器的模型结构简图如图2所示。
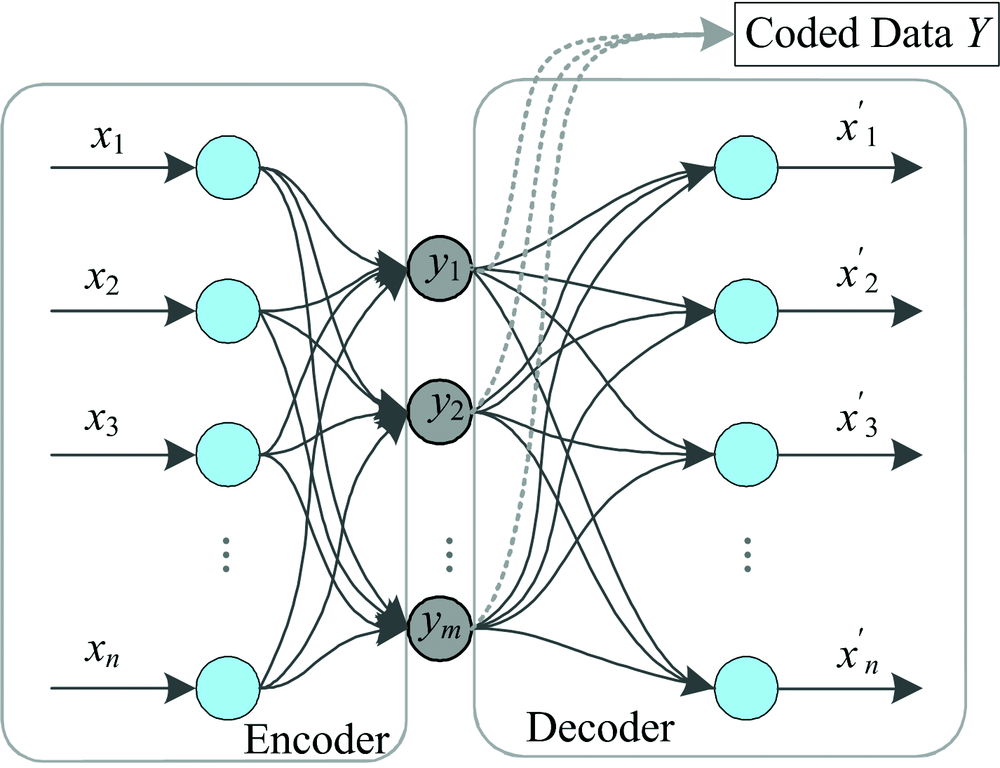 | 图2 自动编码器结构图Fig.2 The schematic diagram of the AE |
图2为最基本的AE算法结构图, 模型的输入节点和输出节点数目相同, 编码和解码均采用人工神经网络模型, 从X到Y过程为编码, Y到X'过程为解码。 当隐层节点数小于输入节点数时(m< n), 通过学习使输出向量X'等于输入向量X, 即可实现复杂数据的降维, 降维后的数据为Y。
Dropout层是Hinton等[13]提出的一种用于改进卷积神经网络模型性能的方法, 其作用类似于L2正则化, 可防止卷积神经网络模型过学习, 加快模型的训练速度。 目前, Dropout层已广泛应用于基于卷积神经网络的深度学习模型中, 为使AE降维模型具有稀疏性, 同时改善AE降维模型的训练性能, 文中在传统的AE算法中加入一个Dropout层。
1.2.1 MVO算法
多元宇宙优化算法是Mirjalili等在2015年提出的一种启发式优化算法[7], 灵感来源于物理学中的多元宇宙理论, 主要根据多元宇宙理论的三个主要概念— — 白洞、 黑洞和虫洞来建立数学模型。 作为一种新的智能算法, MVO 算法由于需要调节的参数较少, 适应性强, 搜索效率高及优化能力好等特点, 已经成功用于焊接梁设计、 压力容器设计和悬臂梁设计等经典工程问题中。
白洞: 是一个只发射不吸收的特殊天体, 并且是诞生一个宇宙的主要成分;
黑洞: 刚好与白洞相反, 它吸引宇宙中一切事物, 所有的物理定律在黑洞中都会失效;
虫洞: 连结白洞和黑洞的多维时空隧道, 将个体传送到宇宙的任意角落, 甚至是从一个宇宙到另一个宇宙, 而多元宇宙通过白洞、 黑洞、 虫洞相互作用达到一个稳定状态。
1.2.2 DBSCAN算法
带有噪声的基于密度聚类(density-based spatial clustering of applications with noise, DBSCAN)是Martin Ester等提出的一种无监督聚类的算法, 广泛应用于模式识别和数据挖掘领域。 DBSCAN的实现思想是根据密度可达关系, 在样本数据集中找出最大密度相连样本的集合, 被分在该子集的样本即为同一类。 关于DBSCAN算法几个基本的概念如下:
设样本集为C=(c1, c2, c3, …, cn), 对于子样本ci, 其Eps-neighborhold包含样本集C中与ci的空间距离不大Eps的子样本集为NEps(ci)={cj∈ C|dis(ci, cj)≤ Eps}, 样本个数为|NEps|。
核心对象: 任一样本ci∈ C, 如果其Eps-neighborhold对应NEps(ci)的至少包含MinPts个样本则ci是核心对象;
噪音点: 不是核心对象, 也不在核心对象的邻域内的样本;
密度直达: 若ci的Eps-neighborhold为NEps(ci), 且cj∈ NEps(ci), 则称ci是cj密度直达。
密度可达: 对于ci和cj, 存在样本序列满足p1, …, pn, …, pt, 且p1=ci和pt=cj, 若pn是pn+1密度直达, 则ci和cj密度可达。
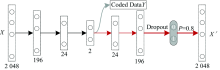
实验采集的水样LIF光谱数据的维度为2 048, 含有较多的冗余信息, 利用自动编码器降维水样光谱数据。 自动编码器采用多层网络结构, 结构简图如图3所示。
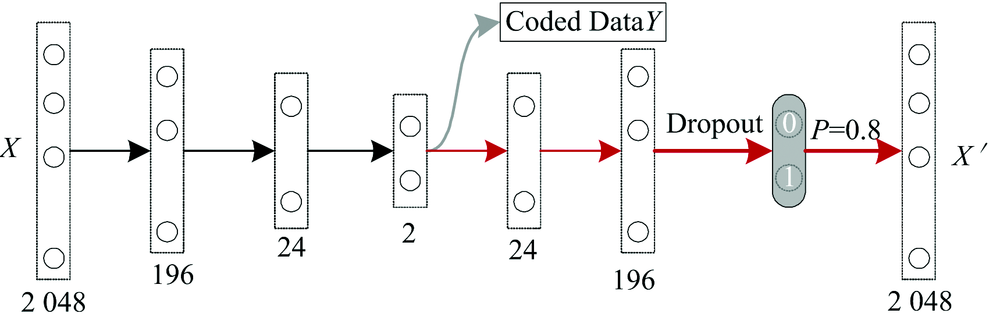 | 图3 设计的AE降维模型Fig.3 The designed AE dimension reduction model |
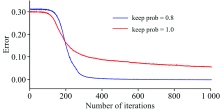
图3中, 黑色箭头为编码过程, 红色箭头为解码过程, 第一层和最后一层节点数为2 048, 中间层节点数为2, 即水样LIF光谱数据由2 048维降到2维。 为改善AE降维模型的训练性能, 在输出层前加入Dropout层, 使网络具有稀疏性。 所设计的降维模型实现平台为Google公司开发的深度学习框架Tensorflow-CPU, 戴尔笔记本电脑, 内存为8G; 降维模型训练时, 学习率设为0.007 5, Dropout层的参数取值为0.8, AE的训练误差曲线如图4所示。
 | 图4 降维模型的训练误差曲线Fig.4 Curve of dimension reduction model training error |
实验中, 降维模型训练迭代了2 400次, 为更加直观的看出加入Dropout层给降维模型训练速度带来的提升, 图4中只画出其前1 000次迭代的误差曲线。 Keep_prob为模型参数, 其越小, 模型相对会越稀疏, 当keep_prob取值为1时, 表示网络中的Dropout被删除。 从图4可知, AE中加入Dropout层后, 初始训练误差会有所增加, 但其误差减少速度也明显增加, 大约经历200次迭代, 其训练误差就已低于未加入Dropout层的AE的训练误差, 大约经历500次的迭代, 加入Dropout层的AE降维模型训练完毕, 而此时未加入Dropout层的AE降维模型的训练误差依然较大。 经对比分析, 自动编码器中加入Dropout层可明显加快模型的收敛速度。
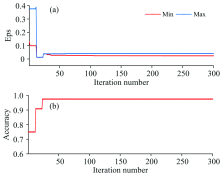
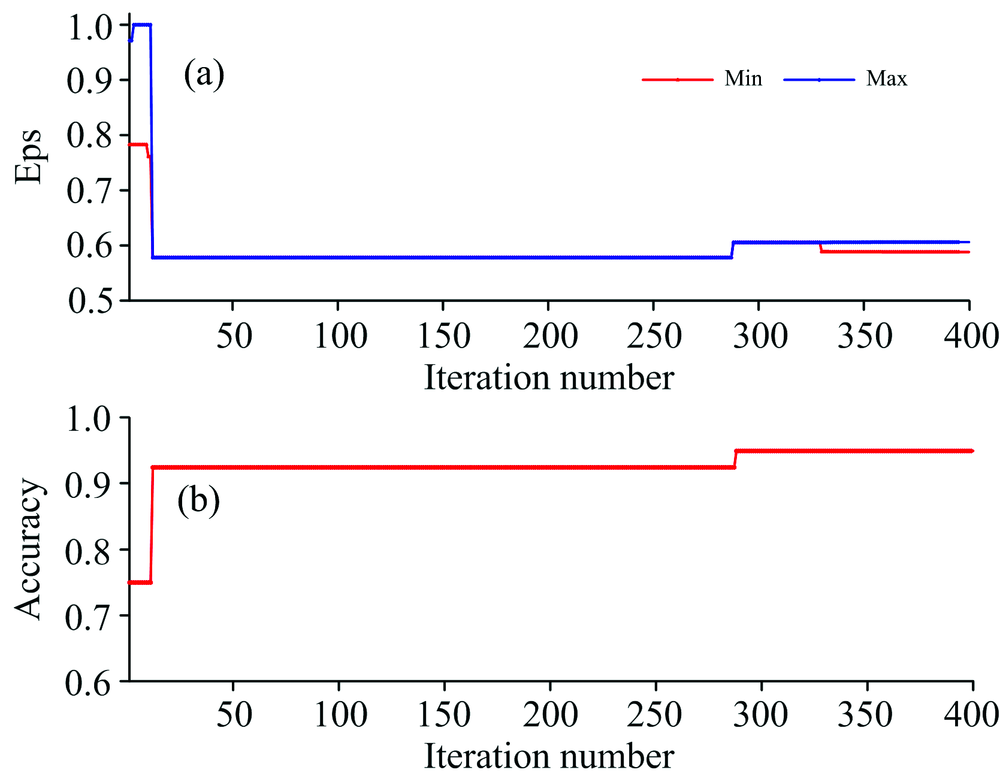
DBSCAN算法聚类时, 需要合理的设置邻域距离Eps和核心对象的样本最小数目MinPts。 当邻域距离相同时, 核心对象样本数越大, DBSCAN聚类出的簇相对越少, 当某一簇所包含的样本数小于参数MinPts时, 该簇所有样本会被视为噪声, 将DBSCAN的参数MinPts设置为3。 参数Eps与样本集的密度相关, 最高聚类准确率对应的Eps往往是一个区间, 将MVO用于DBSCAN算法的参数寻优, 获取最高识别率下Eps所对应的取值区间。 MVO算法WEP的最大值设置为1, 最小值设置为0.2, 宇宙数设置为15, 优化时最大迭代次数设置为300。 MinPts取值为3时的寻优结果如图5所示。
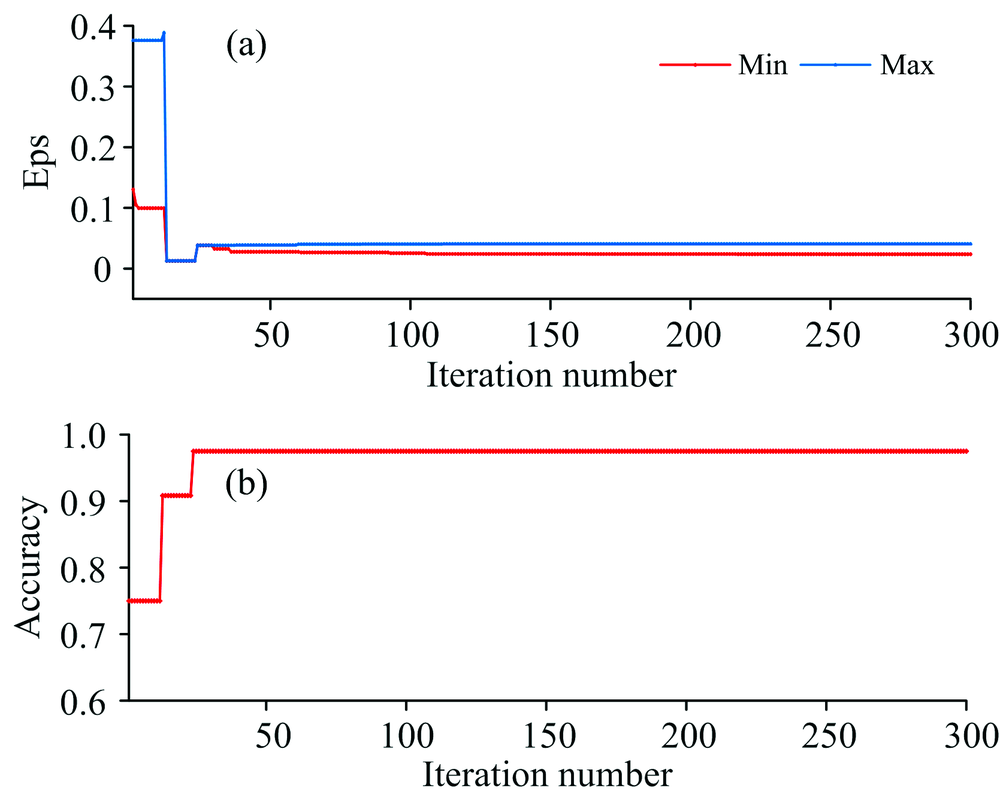 | 图5 AE-MVO-DBSCAN优化结果 (a): 参数Eps曲线; (b): 聚类准确率曲线Fig.5 Optimization results of AE-MVO-DBSCAN (a): The curve of parameter Eps; (b): The curve of clustering accuracy |
图5中, (a)为被寻优参数Eps的变化曲线, (b)为寻优过程中DBSCAN算法对降维后的水样光谱的识别率曲线。 图5(a)中的“ Max” 为前n次迭代中, 最优识别率所对应的Eps 最大值, “ Min” 为其所对应的最小值。 由图5可知, MVO算法参数自寻优速度较快, 经历24次迭代对降维后的水样光谱的识别率就已达到最大, 为97.5%; 大约经历120次迭代, 最高识别率所对应的的最大值和最小值已不再改变, 其对应区间为[0.023 66 0.040 65], 即当取值在区间[0.023 66 0.040 65]之内时, DBSCAN对降维后的水样光谱识别率为97.5%。 当Eps=(0.023 66+0.040 65)÷ 2、 MinPts取值为3时, DBSCAN对降维后的水样识别结果如图6所示。
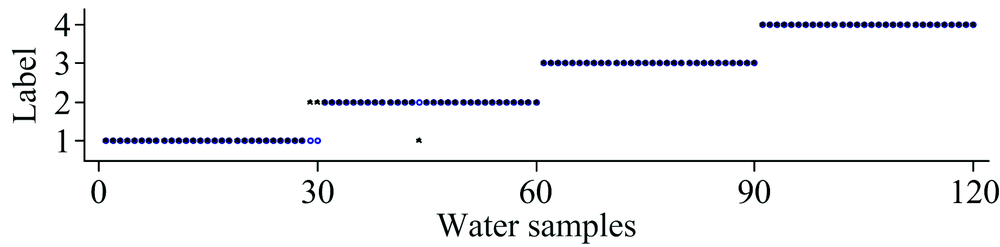 | 图6 MinPts=3, Eps=0.0322时DBSCAN识别结果Fig.6 DBSCAN recognition result when MinPts=3, Eps=0.032 2 |
图6为Eps取值为0.032 2和MinPts取值为3时, DBSCAN对降维后的水样光谱的识别结果, 蓝色“ ○” 为样本实际标签, 红色“ ☆” 为预测标签, 红色“ ☆” 和蓝色“ ○” 重合, 表示该样本被正确识别。 从图6中可看出, 水样三和水样四全部被识别出, 水样一中有2个样本被识别成水样二, 水样二中有1个样本被识别成水样一, 综上可知, DBSCAN对降维后的水样光谱的识别率为97.5%。
为验证AE降维算法对水样光谱数据降维的有效性, 将MVO寻优DBSCAN, 并将结果用于识别未降维的水样光谱, 在参数寻优前将原始光谱数据进行归一化处理。 DBSCAN算法的寻优结果如图7所示。
 | 图7 MVO-DBSCAN优化结果 (a): 参数Eps曲线; (b): 聚类准确率曲线Fig.7 Optimization results of MVO-DBSCAN (a): The curve of parameter Eps; (b): The curve of clustering accuracy |
图7(a)为当前迭代次数最高硕别率所对应的Eps的最大值和最小值曲线, 图7(b)为识别率曲线。 从图7中可知, 改进DBSCAN对未经自动编码器降维的水样光谱的识别, 经历288次迭代才能达到最高识别率, 其最高识别率为95%; 而改进算法对降维后的水样光谱的识别, 只需24次迭代就达到最大识别率, 且最大识别率为97.5%。 综上可知, 将AE用于降维水样光谱数据, 可加快改进算法的寻优, 提高其对水样光谱的识别率。
监督学习是在识别时让模型在监督条件下将训练样本映射到其所对应的标签上, 在已知标签的数据集上, 监督学习所表现出的性能优于无监督学习, 但是新样本的标签在已有的数据中没有出现过, 监督学习算法依然会将其映射到训练集已有的标签上, 便发生误判。 把监督学习算法用于LIF光谱数据的识别, 将结果与DBSCAN的聚类结果对比, 文中监督学习算法选用K最近邻算法。 K最近邻(K-nearest neighbors, KNN) 算法是Cover等提出的一种监督学习算法, 主要应用场景有字符识别、 文本分类、 图像识别等领域。
在模型训练中, 从水样一、 水样二和水样三中各随机选取20组光谱数据作为训练集, 其余的光谱数据(包含水样四的30组水样光谱)用于训练好的模型测试。 在训练集上, DBSCAN算法聚类准确率最高时, 参数MinPts的取值为3, Eps的取值为0. 0382。 将训练好的模型参数用于测试集测试, 预测结果如图7所示。
图8中, 黑色圆圈为测试集水样的实际标签, 红色方块为KNN的识别结果, 蓝色五角星为DBSCAN的识别结果。 由图8可知, KNN将水样一、 二和三全部正确识别, 把训练集中没有的水样四全部识别成水样一, DBSCAN算法把水样一的两个样本视为噪声, 其余全部正确的识别。 由对比可得, 监督学习算法在识别训练集已有的光谱时, 具有较高的识别率, 但是无法识别训练集没有的光谱, 而无监督学习算法DBSCAN能识别出训练集中没有的水样光谱。 在煤矿开采中, 由于地下环境较为复杂, 难以预先建立所有水样的光谱数据库, 将DBSCAN用于矿井突水的识别, 可有效降低对未知水源的误识别。
 | 图8 KNN和DBSCAN的识别结果Fig.8 Recognition results of KNN and DBSCAN |
(1) 快速准确地判别矿井突水来源, 对煤矿的安全生产具有重要意义, 把激光诱导荧光技术用于矿井突出检测, 再结合无监督学习聚类算法DBSCAN, 快速识别突水来源的同时有效的降低了对未知水源的误识别。 此外, 将MVO用于DBSCAN算法的参数寻优, 获取DBSCAN对水样光谱最高识别率所对应的参数取值范围, 省去了光谱识别中繁琐的人工参数寻优过程;
(2) 把AE用于降维水样LIF光谱数据, 所设计的多层网络降维模型将原始光谱数据从2 048维降到2维, 大幅度减少了原始光谱数据中的冗余信息, 加快了MVO对DBSCAN参数寻优的速度, 同时也提高DBSCAN对水样光谱的识别率。 在AE算法中引入一个Dropout层, 使降维模型具有一定的稀疏性的同时, 加快了AE训练收敛速度; 一般原始光谱数据中都含有大量冗余信息, 本工作成功地将AE用于LIF光谱数据降维, 在复杂光谱数据处理中具有较重要的意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|