{kind=link}
{kind=link}
{kind=link}
[朱梦远1, 2  , 杨红兵
, 杨红兵1, 2, * , 李志伟1, 2 ]
, 杨红兵, 李志伟|
|


作者简介: 朱梦远, 1994年生, 南京农业大学工学院硕士研究生 e-mail: 2016812086@njau.edu.cn
基于高光谱成像技术和化学计量方法, 实现了对水稻纹枯病病害的早期检测识别。 以幼苗时期的水稻植株为研究对象, 对其进行纹枯病病菌侵染, 获得染病植株, 采集358~1 021 nm波段范围的高光谱图像, 三次实验共240个样本, 包括染病植株120个样本和健康植株120个样本。 根据高光谱图像的光谱维, 对染病水稻叶片和健康水稻叶片提取感兴趣区域(ROI), 利用感兴趣区域的光谱数据, 对其进行Savitzky-Golay(SG)平滑、 Savitzky-Golay(SG)一阶求导、 Savitzky-Golay(SG)二阶求导、 变量标准化(SNV)和多元散射校正(MSC)预处理, 建立线性判别分析(LDA)和支持向量机(SVM)分类模型, 结果表明: 采用SG二阶求导预处理后的线性判别分析(LDA)模型取得了较好的性能, 正确识别率在建模集达98.3%, 在预测集达95%; 利用载荷系数法(x-loading weights, x-LW)对原始光谱和5种预处理的光谱数据进行特征波长提取, 然后根据选取的特征波长建立线性判别分析(LDA)和支持向量机(SVM)分类模型, 其中采用SG二阶求导预处理后提取的12个特征波长的线性判别分析(LDA)模型取得了较好的性能, 其正确识别率在建模集达97.8%, 在预测集达95%, 而且基于载荷系数法建立的模型性能与全波段相当, 可以通过载荷系数法减少数据量对水稻纹枯病病害进行识别; 根据高光谱图像的图像维, 研究了基于图像主成分分析、 基于概率滤波和基于二阶概率滤波的图像特征提取方法, 利用提取的特征变量建立反向传播神经网络(BPNN)和支持向量机(SVM)分类模型, 其中基于图像主成分分析的反向传播神经网络(BPNN)模型取得了较好的性能, 建模集准确识别率达90.6%, 预测集的准确识别率达83.3%; 根据高光谱图像光谱维和图像维的最优模型, 特将叶绿素含量作为建模的另一个特征, 分别与光谱特征、 图像特征组合, 建立反向传播神经网络(BPNN)和线性判别分析(LDA)模型, 提出基于光谱特征加叶绿素含量、 图像特征加叶绿素含量和光谱、 图像特征加叶绿素含量三种组合方式, 其中, 光谱特征和图像特征分别与叶绿素组合的方式比之前单独的光谱和图像特征建模性能都有所提升, 而且三种组合方式中光谱特征加叶绿素含量的反向传播神经网络(BPNN)建模方式取得本研究所有建模方式中较优的性能, 其准确识别率在建模集达100%, 在预测集达96.7%。 以上研究表明, 基于高光谱图像和叶绿素含量对水稻纹枯病病害进行早期识别是可行的, 为水稻病害的早期识别提供了一种新方法。
Hyperspectral imaging combined with chemometrics was successfully proposed to identify the rice sheath blight disease. First, infected rice plants with rice sheath blight in the seedling period to get the infected rice plants, then used the hyperspectral imaging system to acquire the hyperspectral imagines in the spectral range of 358~1 021 nm, finally selected 240 samples of all hyperspectral imagines to analyze, including 120 healthy samples and 120 infected samples. According to the spectral dimension of hyperspectral image, extracted the region of interest(ROI) of healthy and infected rice leaves, pretreated the spectral data of the region of interest with pretreatments including SG smoothing, SG-1D, SG-2D, SNV and MSC, then established the linear discriminant analysis (LDA) and support vector machine (SVM) classification models. The result showed that the linear discriminant analysis (LDA) model with SG-2D pretreatment achieved the better performance, with the correct recognition rate of the modeling set being 98.3% and the correct recognition rate of the prediction set being 95%. After five kinds of pretreatments, extracted the feature wavelengths with the method of x-loading weights, then established the linear discriminant analysis (LDA) and support vector machine (SVM) classification models based on feature wavelengths. The result showed that the linear discriminant analysis (LDA) model with SG-2D pretreatment achieved the better performance, with the correct recognition rate being 97.8% in the modeling set and 95% in the prediction set. Moreover, the model performance based on x-loading weights was equivalent to that of the whole band. So, it can be used to identify the rice sheath blight disease with x-loading weights. According to the image dimension of hyperspectral image, the principal component analysis, probabilistic filtering and second-order probabilistic filtering were proposed in this paper, then established the back propagation neural network (BPNN) and support vector machine (SVM) classification models. The result showed that the BPNN based on image principal component analysis achieved the better performance, with the correct recognition rate being 90.6% in the modeling set and 93.3% in the prediction set. According to the spectral and image dimension of hyperspectral image, the chlorophyll content was proposed to be another feature of disease recognition, which was combined with spectral characteristics and image features to build models to compare the performance of each model. Then established the back propagation neural network (BPNN) and linear discriminant analysis (LDA) classification models. The spectral features combining with chlorophyll content, image features combining with chlorophyll content and spectral, image features combining with chlorophyll content were proposed. The performance of spectral, image features combining with chlorophyll respectively were both better than that using the spectral and image features alone. BPNN based on spectral features combining with chlorophyll content achieved the better performance, with the correct recognition rate being 100% in the modeling set and 96.7% in the prediction set, also, this model achieved the best performance compared with all models in this paper. The overall results indicated that hyperspectral imaging technology with chlorophyll content can accurately identify the early rice sheath blight disease and provide a new method for early detection of rice disease.
水稻是中国的主要粮食作物, 实现水稻稳产、 高产一直是我国农业生产的目标。 但是由于受到病虫害的侵蚀, 水稻稳产、 高产的目标受到了严重阻碍。 为了减少病虫害对水稻产生的不利影响, 通常会采取大量使用农药的措施来应对。 这不仅加大了农药费用的支出, 而且农药的滥用还会对环境造成污染。 如能在第一时间快速准确获取了农作物的生长状况, 及时发现病害作物的发病情况, 采取变量施药手段按需按量施用农药, 就能够解决以上问题。 因此, 农作物病害的快速、 精确、 及时检测对于我国乃至全世界农业的发展具有十分重要的意义。 高光谱技术已经发展成为了携带波谱信息丰富的, 覆盖上百条光谱通道、 像素点的高分辨检测技术[1]。 与可见光和多光谱成像技术相比, 高光谱成像技术获得的图像有更高的光谱分辨率, 能获取更为精确和详实的光谱和空间信息, 并已应用到农业研究的许多方面。 而且, 已有较多相关研究取得了成果, 其中包括粮食作物[2, 3, 4, 5, 6]、 果树[7, 8]等多方面。 本工作应用高光谱成像技术, 结合判别分析方法实现对水稻纹枯病病害的早期检测。
分3批实验进行, 分别在2016年9月, 2017年7月和2017年9月, 以苗期的水稻植株为研究对象, 选用武运粳21号品种对其进行纹枯病病菌侵染, 在接种后一周左右, 采集水稻幼苗植株叶片的高光谱图像, 并且用SPAD-502叶绿素测量仪对健康叶片和染病叶片的上部、 中部和尾部三个部位测量其叶绿素含量, 每个部位取4点进行测量, 计算出每片叶子12个点的叶绿素含量的平均值代表这片叶子的叶绿素含量值。 通过观察比较分析3次实验采集的所有染病和健康水稻植株叶片的高光谱图像, 最终选取了240幅高光谱图像, 包括120个染病样本和120个健康样本。
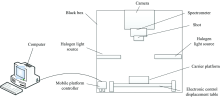
高光谱成像系统主要由CCD摄像机(GEV-B162M)、 2个150 W的光纤卤素灯、 电位控制台、 成像光谱仪(ImSpector V10E)、 暗箱(1 200 mm× 500 mm× 1 400 mm)、 高光谱采集软件(HIS Analyzer)和一台高性能计算机组成, 高光谱成像硬件系统简易图如图1所示。 高光谱图像采集光谱范围为358~1 021 nm共616个波段, 光谱分辨率为2.8 nm, 图像分辨率为1 632× 172。
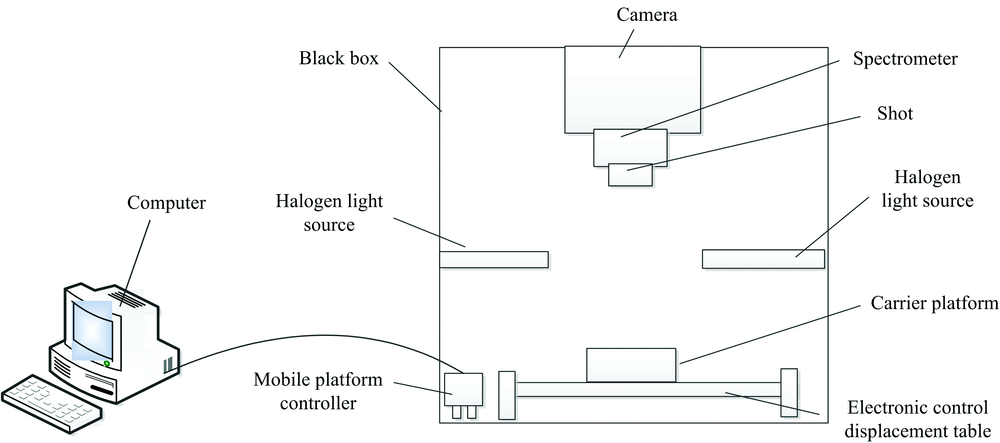 | 图1 高光谱成像系统Fig.1 Hyper-spectral imaging system |
高光谱图像处理采用ENVI 4.8(ITT, Visual Information Solution)软件, 数据分析以及制表采用The Unscrambler × 10.1(CAMOAS, Oslo, Norway)、 Excel 2016和Matlab R2014a(The MathWorks, Natick, USA)软件。
高光谱仪器在采集叶片之前先要进行仪器的校正, 在校正过程中, 多次重复调节镜头与待测物的距离(物距), 确定物镜高度设置为75 cm, 曝光时间设置为50 ms, 平台移动速度为1.1 mm· s-1。 设置参数的同时对高光谱图像进行黑白板校正。
为了提高高光谱数据的准确率并且减少光照强度改变对高光谱数据的影响, 对采集到的原始高光谱图像进行校正, 从而得到光谱相对反射信息, 计算公式如式(1)[9]
其中RT为校正后的图像, IRaw为原始高光谱图像, IDark为黑板标定图像, IWhite为白板标定图像。
采用正确的光谱数据预处理能够大大减少噪声和背景的干扰, 强化光谱中的有效信息, 从而提高模型的准确率。 本应用的光谱数据预处理方法有平滑算法, Savitzky-Golay卷积求导算法, 多元散射校正(multiplicative scatter correction, MSC)和变量标准化(standard normalized variate, SNV), 光谱数据预处理在The Unscrambler X 10.1软件中进行。
1.4.1 判别分析方法
线性判别式分析(linear discriminant analysis, LDA)是将高维的向量空间投影到最优分离的向量空间, 在类内方差最小, 类间方差最大, 表示这种模式在该空间具有最好的分离性, 它是一种有监督的判别分析方式。
误差反向传播神经网络(back propagation neural networks, BPNN)由输入层、 输出层、 隐含层三个部分组成, 首先从输入层输入数据, 经过标准化处理, 并且给数据设置权重以后传到隐含层, 在隐含层内对输入权重进行求和、 转换等操作传输到第三层, 从而给出神经网络的预测值; 在实际建模时可以通过调节隐含层的节点个数来优化模型。
支持向量机(support vector machine, SVM)是一种有监督识别方法, 能够很好地对非线性、 样本数据量小、 变量特征多和局部极值点等的具体情况进行处理, 目前受到很多领域研究人员的青睐[10]。
LDA和SVM建模在The Unscrambler X 10.1软件中进行, BPNN建模在Matlab R2014a 中进行。
1.4.2 特征波长选择方法
对光谱数据进行主成分分析(principal component analysis, PCA)后, 会给出贡献率最大的前几个主成分变量, 在每个主成分变量下, 可以计算得到每一个波长对应的x-loading weight, x-loading weight的绝对值越大表示该波长的影响能力越大, 因此, 将x-loading weight绝对值大的波长选择为特征波长。
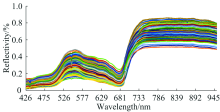
取高光谱图像中大小为50× 50的感兴趣区域(region of interest, ROI)的所有像素点的光谱平均值作为反射值, 去除其明显噪声波段, 选取425~950 nm(波段66~551)共486个波段光谱范围作为水稻样本光谱数据, 剔除噪声的样本光谱曲线如图2所示。
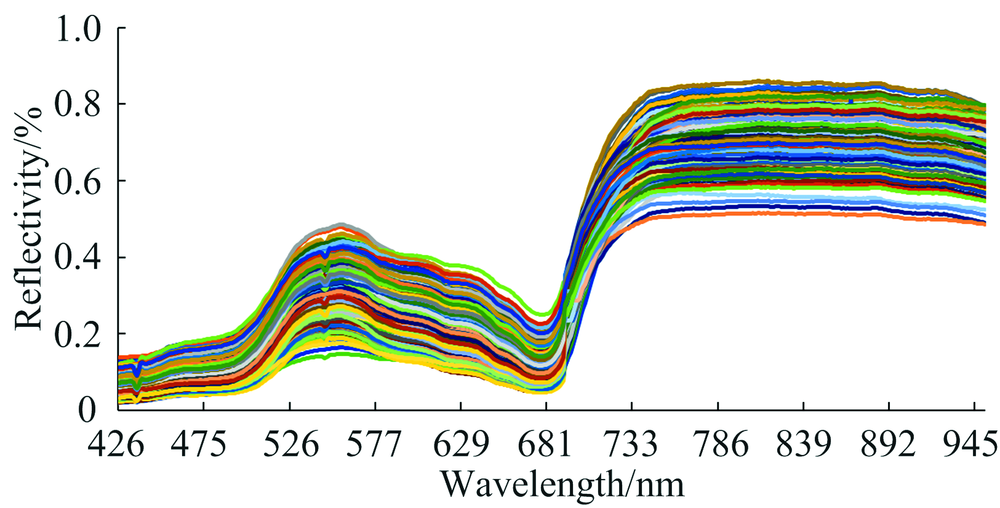 | 图2 全部样本光谱曲线图Fig.2 Spectral curves of all rice samples |
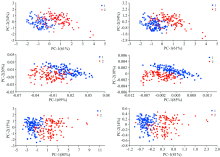
对预处理后的光谱数据进行主成分定性分析, 图3显示了原始光谱和经过预处理后的光谱数据的聚类效果。 原始光谱和不同预处理之后的光谱数据除了SG一阶求导之外, 第一主成分(PC1)和第二主成分(PC2)的累计贡献率均等于95%, SG一阶求导后PC1和PC2累计贡献率为89%, 说明PC1和PC2方向上能代表绝大部分的原始数据信息, PC1和PC2能够很好的表示健康水稻样本和染病水稻样本的数据信息。 在原始光谱(Raw)和SG平滑处理后样本光谱数据经PCA转变后, 健康水稻样本跟染病水稻样本大部分能够进行区分, 但是还有不少染病水稻样本混在健康水稻样本中很难区分出来。 经SG一阶求导、 SG二阶求导、 SNV和MSC预处理之后的样本数据PCA的聚类效果相比原始光谱(Raw)和SG平滑, 分类的界限更清楚, 效果更好, 而且发现SG二阶求导后分类的界限最清楚。
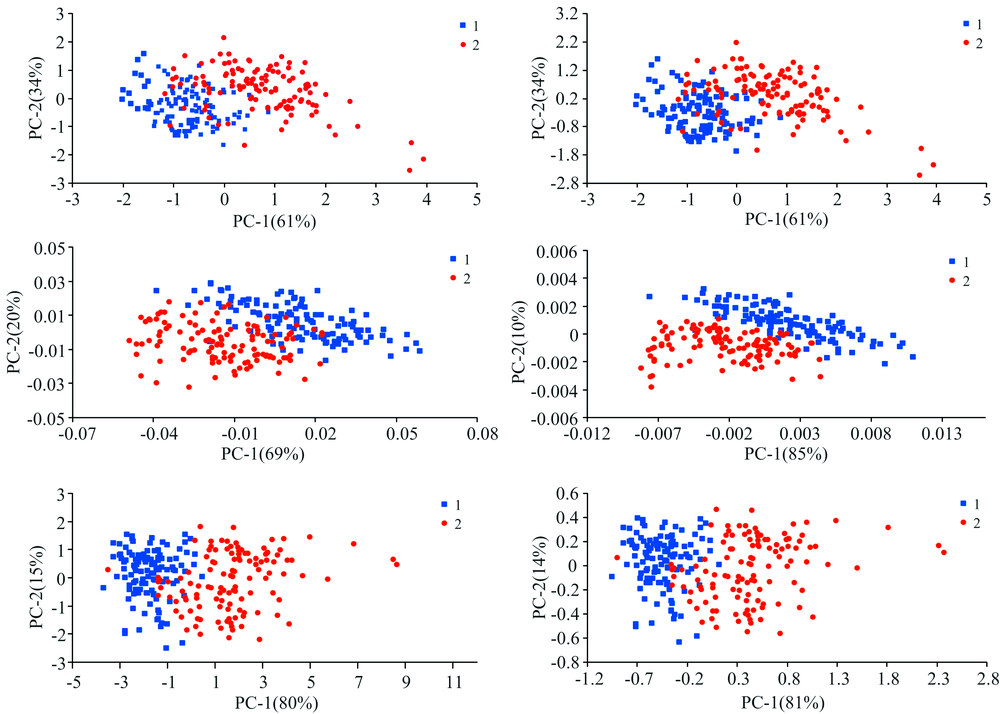 | 图3 不同预处理后的所有水稻样本PCA聚类图 注: 标1的蓝色的正方形点表示健康水稻样本; 标2的红色的圆形点表示染病水稻样本; a, b, c, d, e和f图分别表示原始光谱、 经SG一阶求导、 SG二阶求导、 SNV和MSC预处理之后的样本PCA聚类图Fig.3 The PCA cluster diagram of all rice samples after different pretreatments Note: The blue square points of mark 1 represent the healthy rice samples; the red dot of mark 2 represent the infected rice samples; The figures of a, b, c, d, e and f represent the PCA cluster diagram of raw, SG1D, SG2D, SNV and MSC samples, respectively |
对不同预处理后的光谱数据进行线性判别分析(LDA)和支持向量机(SVM)建模分类。 LDA建模的主成分变量数选为7, SVM建模选择种类为nu-SVC, 核函数为RBF核函数, Nu值跟Gamma选择默认数值。 模型的判别性能如表1所示。
| 表1 不同预处理后的LDA和SVM分类模型性能比较 Table 1 The performance of LDA and SVM models based on different pretreatments |
从表1可以看出, 线性判别分析(LDA)在建模集和预测集的分类正确识别率均在91%以上, 其中SG二阶求导后的样本光谱数据在建模集和预测集的正确识别率最高, 分别为98.3%和95%; 支持向量机(SVM)在建模集和预测集的分类正确识别率均在83%以上, 其中MSC处理后的样本光谱数据在建模集合和预测集的正确识别率达到最高, 分别为95%和95%。 综合看线性判别分析(LDA)比支持向量机(SVM)建模的效果更好, 而且在经SG二阶求导, SNV和MSC预处理之后的光谱数据在两个模型的正确识别率均大于90%, 效果较好。 回顾图2的PCA聚类图, 发现分类正确识别率高低与PCA聚类效果好坏基本符合。 用线性判别分析(LDA)建模对经SG二阶求导处理后的光谱数据的分类识别效果最好, 建模集和预测集正确识别率均达到了最高的98.3%和95%。
由于全波段的光谱数据量大, 为了简化光谱数据, 根据主成分分析(PCA)后的7个主成分变量的载荷系数来提取不同预处理之后样本光谱数据的特征波长。 挑选全局和局部区域载荷系数绝对值最大处的波长, 将此波长作为特征波长, LDA建模的主成分变量数选为7, SVM建模选择种类为nu-SVC, 核函数为RBF核函数, Nu值跟Gamma选择默认数值, 分别建立的线性判别分析(LDA)和支持向量机(SVM)分类识别模型性能见表2。
| 表2 不同预处理后的LDA和SVM分类模型性能比较 Table 2 The performance of LDA and SVM models based on different pretreatments |
从表2中可以看出, 线性判别分析(LDA)比支持向量机(SVM)建模的效果更好, 而且在经SNV和MSC预处理之后的光谱数据在两个模型的正确识别率均大于90%, 效果较好。 总体上, 经SG二阶求导的线性判别分析(LDA)模型在建模集和预测集上正确识别率相对较高。 与全波段数据建模相比较, 基于载荷系数法提取特征波长的两个模型性能几乎没有多大改变。 综合上述结果, 可以用线性判别分析(LDA)和支持向量机(SVM)对经不同预处理的样本光谱数据进行载荷系数法提取特征波长进行分类, 而且正确识别率与基于全波段光谱数据建模的正确识别率相当。
分别对高光谱图像进行主成分分析、 概率统计和二阶概率统计三种方式对水稻纹枯病进行建模分类识别。 染病植株120个样本和健康植株120个样本中各选取90个作为建模集, 30个作为预测集。 图像主成分分析选取前3个主成分图像均值和标准差作为特征变量, 概率统计滤波选取前5个主成分图像概率滤波后的数据范围、 均值和方差对应的3个纹理图像的均值作为特征变量, 二阶概率统计选取前5个主成分图像滤波后的均值、 方差、 同质性、 对比度、 差异性、 信息熵、 二阶矩和相关性对应的8个滤波图像的均值作为特征变量, 利用这些特征变量建立BPNN和SVM判别模型。 图像主成分分析、 概率统计和二阶概率统计均在ENVI 4.8 软件中进行, SVM建模选择种类为nu-SVC, 核函数为RBF核函数, Nu值跟Gamma选择默认数值, BPNN输入层的节点个数与样本的输入参数个数一致, 输出层节点个数与分类种类个数一致, 输入层和隐含层的传递函数采用S型正切函数tansig, 训练函数采用量化共轭梯度法scg, 设置网络的最大迭代次数为1 000, 学习速率为0.1, 训练精度为0.01, 隐含层神经网络节点个数Y与输入层节点个数I之间通过如下式子来计算[11]:
模型的性能如表3所示。 从表3可以看出, 综合看三种图像特征提取方法在校正集上的准确率均大于83%, 在预测集上的准确率均大于71%, 其中基于主成分图像特征提取的BP神经网络分类模型在预测集中取得了最佳识别效果, 正确识别率达83.3%。
| 表3 基于图像特征提取的水稻病害判别分析模型性能 Table 3 Analysis model performance of rice diseases based on image feature extraction |
由前面的结果可知: 光谱数据预处理中, SG二阶求导预处理方式相对较好, 而且基于载荷系数法提取特征波长的模型性能与全波段相当; 在图像特征选取方式中, 经图像主成分分析特征提取的方法相对较好; 在判别分析方法上, LDA方式优于SVM, BPNN方式优于SVM, 所以选取的光谱特征选取方式为SG+x-loading weights, 图像特征选取方式为PCA, 判别分析方法选择BPNN和LDA, 建立光谱特征+叶绿素含量、 图像特征+叶绿素含量和光谱特征+图像特征+叶绿素含量的LDA和BPNN判别模型, 模型的性能如表4所示。
| 表4 基于高光谱图像和叶绿素含量的判别模型性能比较 Table 4 The performance of discrimination Model models based on hyperspectral images and chlorophyll content |
从表4可以看出: 三种组合方式中光谱+叶绿素组合方式的BPNN模型取得了最好的性能, 建模集准确率达100%, 预测集达96.7%, 而且光谱特征和图像特征分别与叶绿素组合建模的模型性能均优于单一使用光谱或者图像特征, 基于SG-2D预处理后用载荷系数法提取的特征波长+叶绿素的LDA模型比基于光谱的LDA模型在建模集上的准确率从97.8%上升到了98.9%, 预测集则没有变化; 基于图像主成分分析+叶绿素含量的BPNN模型的建模集准确率从90.6%上升到了92.8%, 预测集的准确率从83.8%上升到了86.7%。 表明, 将高光谱图像结合叶绿素含量来对水稻纹枯病进行早期检测识别是可行的。
应用高光谱成像技术和叶绿素含量结合化学计量方法实现了对水稻纹理病的早期检测识别。 分别对提取的ROI的光谱数据进行不同的预处理, 建立基于全波段和载荷系数法提取特特征波长的LDA和SVM判别模型, 其中利用全波段和利用载荷系数法提取的特征波长建模的模型性能相当, 其中SG-2D+x-loading weights的LDA在建模集上准确率为97.8%, 在预测集上的准确率为95.0%; 分别对高光谱图像进行图像主成分分析、 概率滤波和二阶概率滤波, 建立BPNN和SVM判别模型, 其中图像主成分分析+BPNN取得了较好的性能, 建模集的准确率为90.6%, 预测集的准确率为83.9%。 为优化模型, 利用光谱维和图像维的较优模型, 将叶绿素含量分别与光谱特征和图像特征组合, 结果表明, 组合方式的模型性能均优于其单独使用光谱特征或图像特征, 其中SG-2D+x-loading weights+叶绿素含量的BPNN模型取得了最好的性能, 建模集准确率为100%, 预测集的准确率为96.7%。 通过高光谱图像和叶绿素含量结合的方式可以实现对水稻纹枯病病害的早期识别, 具有一定的应用价值。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|