
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于互信息熵-近红外光谱的过程模式故障检测
[高爽, 栾小丽*  , 刘飞]
, 刘飞]
, 刘飞]
|
|


作者简介: 高爽, 女, 1995年生, 江南大学自动化研究所轻工过程先进控制教育部重点实验室硕士研究生e-mail: gao_shuang1995@126.com
近红外光谱分析在工业过程故障检测方面具有独特的优势, 是一种准确且高效的方法。 结合互信息熵和传统的主成分分析, 对近红外光谱特征信息进行提取, 通过构建过程的模式来刻画工业过程的运行状态。 利用近红外光谱数据, 从有机分子含氢基团振动信息中获取工业系统的过程模式, 从微观分子层面探索提高工业过程故障检测准确率的有效方法, 结合贝叶斯统计学习技术, 提出了基于近红外光谱数据的工业过程故障检测技术。 针对近红外光谱信息量丰富, 谱带较宽, 特征性不强的特点, 首先对工业过程不同运行状态下的近红外光谱吸光度数据进行一阶导数预处理, 采用主成分分析法(principal component analysis, PCA)压缩光谱数据量, 扩大不同运行状态下光谱特征信息的差异性, 提取光谱的内部特征信息。 然后采用互信息熵(mutual information entropy, MIE)作为光谱特征信息相关性度量函数, 基于最小冗余最大相关算法进一步减少光谱特征信息间的冗余并最大化光谱特征信息与类别的相关性, 弥补了PCA无监督特征波长选择的不足, 提出一种基于PCA-MIE的过程模式构建方法, 获得的过程模式子集更紧凑更具类别表现力。 再利用贝叶斯统计学习算法, 根据后验概率对构建的模式子集进行决策, 判别生产过程的正常状态和故障状态。 由于过程模式子集结合了PCA浓聚方差的优势和互信息熵相关性测度的特征信息选择方法, 蕴含了更多的近红外光谱的本质信息与内在规律, 从而更能刻画工业过程的运行状态。 接着, 设置测试准确率TA作为评估标准, 用以评价故障检测方法的性能效果。 最后利用某化工厂提供的原油脱盐脱水过程近红外光谱数据对所提方法进行验证, 并与传统近红外光谱特征信息提取方法PCA和MIE方法性能进行对比分析, 结果表明基于PCA-MIE的过程模式故障检测方法几乎在所有维数子集上性能都优于其他两种方法, 在特征维数为18维时获得最高的准确率94. 6%, 证明了方法的优越性。
The technology of near infrared spectroscopy that has unique advantage in fault detection in industrial processes is an accurateand effective method. Combining the mutual information entropy and the traditional principal component analysis, a new method for extracting the near infrared spectral feature information was first developed. The operating states of the industrial process was described by the constructed process pattern.Near infrared spectroscopy data were used to obtain the process pattern of industrial systems from the vibration information of hydrogen groups in organic molecules in this paper. An effective method to improve accuracy of fault detection in industrial processes was explored from the microscopic molecular level. Combined with Bayesian statistical learning method, an industrial processes fault detection technique based on near infrared spectroscopy data was proposed. Firstly, for the characteristics of rich information, wide spectrum band and weak characteristic, first-order derivative preprocessing of near infrared spectroscopic absorbance data under different operating states of industrial process was applied. Principal component analysis(PCA) was used to compress the amount of spectral data, expand the differences in spectral feature information under different operating states, and extract the internal feature information of the spectrum. Then, mutual information entropy(MIE) was used as correlation measure function of spectral feature information, and the minimum redundancy maximum relevance algorithm was used to further reduce the redundancy between the spectral feature information and maximize the relevance between the spectral and class.It made up for the deficiency of unsupervised feature wavelength selection of PCA. Therefore, a process pattern construction method based on PCA-MIE was proposed. The obtained process pattern subset was more compact and more expressive. Furthermore, Bayesian statistical learning method was applied to make decisions based on posterior probability of the constructed process pattern subset to identify the normal and accident state of the production process. Because the process pattern subset combines the advantages of PCA in density variance reduction and the feature information selection method of mutual information entropy correlation measure, it contains more essential information and inherent laws of near infrared spectroscopy, which can better describe the operating states of the industrial process. Next, The test accuracy (TA) was set as the evaluation criteria to evaluate the performance of the fault detection method. Finally, the data of crude oil desalination and dehydration process provided by the chemical plant was used to verify the effectiveness of the proposed method. Compared with the performance of traditional near infrared spectral feature information selection methods PCA and MIE, the results showed that the process pattern fault detection based on PCA-MIE outperforms the other two methods on almost all dimensions subsets. The highest accuracy rate is 94.6% when the feature dimensions is 18, which proves the superiority of the proposed method.
故障检测技术在过程控制系统中发挥越来越重要的作用, 对过程工业的节能减排、 安全稳定运行以及提高产品质量具有重要的意义[1, 2, 3]。 传统故障检测有三大类方法: 基于机理模型、 基于知识以及基于数据驱动的故障检测方法[4], 其中基于机理模型的方法是最直接有效的, 但由于数学模型的建立及求解十分困难, 使其应用受到限制, 基于知识的方法便应运而生, 它不需要对象的精确数学模型, 其局限表现在对专家知识的依赖、 自适应能力和学习能力差等方面。 而基于数据驱动的故障检测方法既不需要系统精确的数学模型, 也不依赖工业知识和生产经验, 在石油化工、 农业、 医药、 食品等诸多领域得到了广泛应用[5]。 但上述研究大多集中在基于过程宏观变量的故障检测。
随着先进测量仪器的使用, 基于分子振动的近红外光谱分析, 具有无损、 快速、 高通量、 低成本等优点, 为工业过程的故障检测提供了技术手段[6]。 由于近红外光谱是从分子层面获取过程信息, 相比较于基于过程宏观变量的故障检测方法, 对早期故障的判断更为灵敏, 因此近红外作为一种新兴的测量仪器, 在故障检测领域展现了其极大的优势与应用前景。 由于光谱信息量(待选自变量数目)远远大于样本量(采样次数), 光谱数据之间存在大量的冗余和共线性信息。 为了降低模型复杂度, 对光谱信息进行变量选择(剔除无效信息、 保留对样品品质指标有显著影响的变量)格外重要。
利用信息论中的互信息熵[7](MIE), 在光谱信息量大于样本量且存在大量冗余和共线性的背景下, 提出基于PCA-MIE的光谱特征波长选择方法, 从所选择的特征波长子集中获取工业系统的过程模式。 另外区别于传统利用投影空间中的T2统计量和残差空间中的Q统计量为监控指标的故障检测技术[8], 利用贝叶斯统计学习判别法, 对所构建的过程模式进行决策和划分, 判断系统是否处于故障状态。 由于所构建的过程模式不仅度量了特征与目标类别之间的相关程度, 而且也度量了待选特征项和已选特征项子集的相关程度, 并通过一个前向顺序搜索算法将两个标准结合起来, 同步优化两个指标, 因此基于过程模式的故障检测方法具有更高的准确率。
设矩阵X∈ RN× M为所测样本的光谱数据矩阵, N为样本数, M为变量数, 对光谱数据矩阵进行PCA分解[9], 可得
式中: ti为得分向量; pi为负荷向量, i=1, …, M。 得分向量和负荷向量均是两两正交, 且负荷向量的模是1。 每一个得分向量ti是矩阵X与在此得分向量相应的负荷向量pi方向上的投影, 即主元
对光谱数据矩阵进行主成分分析实质上是对矩阵的协方差矩阵进行特征向量分析, 矩阵X的协方差矩阵可以表示为
对E做特征向量分析, 即求解式(4)
取前k个负荷向量[p1, p2, …, pk]构成新的主元空间
主成分分析虽然在不丢失主要光谱信息的前提下选择为数较少的新变量来代替原来较多的变量, 解决了由于谱带的重叠而无法分析的困难, 识别出最重要的多个特征。 然而作为无监督特征提取算法, PCA舍弃已有类别标记信息, 将所有数据当成无类别标记数据, 识别出的不一定是所需要的特征, 会损失有用信息。 为弥补此不足, 创新性地提出了一种混合算法PCA-MIE来构成过程模式, 获得更优的特征波长子集。
信息熵(IE)是信息论中一个表示变量取值不确定性程度的指标。 设两个离散变量A, B均取有限值, 如果信源a与随机变量b不是相互独立的, 它们的联合分布为p(a, b)=P{A=a, B=b}, 边缘分布为p(a)=P{A=a}, p(b)=P{B=b}。 则信源a的初始不确定度可以用熵H(A)表示[10]
已知B下, a的条件熵定义为
式中p(a|b)为条件概率, p(a|b)=
即
最小冗余最大相关(mRMR)算法[11]中最大相关性是PCA降维后的特征fi(i=1, …, k)与类别C之间的相关性, 采用互信息熵I(fi; C)来衡量, 需要最大的优化函数如式(9)
其中S是候选特征子集, |S|=r表示选择特征的个数。 在这样选择的子集中特征之间可能具有很多冗余的特征, 也就是特征之间的依赖性很强。 对于两个具有强依赖性的特征, 如果去掉一个, 不会对分类造成很大影响。 因此, 引进最小冗余度
将式(9)和式(10)进行组合, 构成定义目标函数Φ (· ), 使其最大化
采用前向搜索法搜索最优特征子集, 假设在当前步骤下已选出r-1个特征, 记为特征子集Sr-1, 任务是从剩下的{F-Sr-1}, 中找到第r个特征xj, 使Φ (· )最大, 相应的前向搜索算法的实质是优化下面条件
即可得到过程模式Z=[z1, z2, …, zr], r≤ k< M。
贝叶斯分类模型是一种典型的基于统计方法的分类模型[12]。 贝叶斯定理是贝叶斯理论中最重要的一个公式, 是贝叶斯学习方法的理论基础, 它将事件的先验概率与后验概率巧妙地联系起来, 利用先验信息和样本数据信息确定事件的后验概率[13]。
在近红外故障检测问题中, 原始光谱数据X经过主成分分析所得到数据矩阵F=[f1, f2, …, fk], 再经过互信息熵变量选择后获得过程模式Z=[z1, z2, …, zr], r≤ k< M作为贝叶斯统计学习算法的输入。 假定有m个类C1, C2, …, Cm, 针对过程模式Z, 分类法将预测过程模式Z属于最高后验概率的类。 贝叶斯决策将未知的过程模式分配给类Ci, 当且仅当
其中P(Ci|Z)为后验概率, 可由如下贝叶斯定理计算获得
对过程模式Z进行判别, 对于每个类Ci, 可转化为计算P(Z|Ci)P(Ci)。 过程模式Z被指派到类Ci, 当且仅当
令
其中l12为似然比, θ 12为阈值。 对于原油脱盐脱水工业过程, 结合贝叶斯判别准则, 其故障检测原理可以表述为
其中C1为正常模式, C2为故障模式。 采用贝叶斯统计学习方法进行检测, 其判别规则能对过程模式的变化做出迅速灵敏的判断, 且具有无需确定故障监测的门限的优点。
所用试验样品为某化工厂提供的原油脱盐脱水工业过程的光谱数据。 采用德国Bruker公司生产的MATRIX-F型傅里叶红外光谱仪(含OPUS定量分析软件包)进行数据采集, 该仪器的光谱测量范围是12 800~4 000 cm-1, 最小光谱扫描分辨率为2 cm-1。 实验设置光谱测量波长范围为10 000~4 500 cm-1, 分辨率为8 cm-1。
利用1 000组光谱样本数据进行实验。 为消除基线漂移和背景干扰, 分辨重叠峰, 提高分辨率。 对原始光谱进行一阶导数预处理, 处理后的光谱如图1(b)所示, 横坐标为波长, 范围为1 000~2 222 nm, 纵坐标为吸光度值。 然后将测得的1 000组样本, 按照3∶ 2的比例分成训练集和测试集, 分配情况如表1。
| 表1 样品的训练集和测试集 Table 1 Samples of training and test sets |
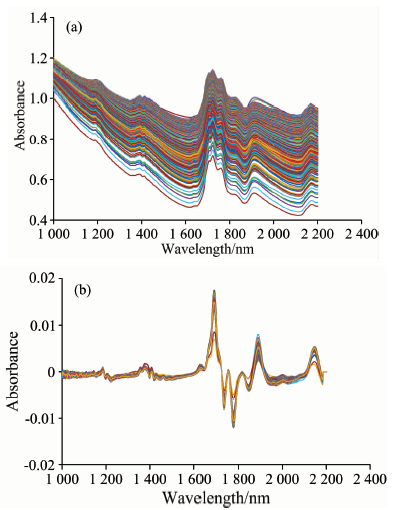 | 图1 预处理前后光谱图 (a): 原始光谱; (b): 一阶导数光谱Fig.1 Spectra before and after pretreatment (a): Raw spectra; (b): First derivative spectra |
3.3.1 PCA特征波长选择
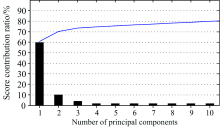
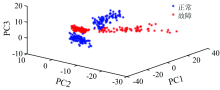
将光谱仪提取的光谱特征曲线一阶导数处理后, 得到光谱数据矩阵X∈ RN× M, 对其进行PCA分析。 图2为主成分得分贡献率。 分别以前3个主成分为坐标, 建立样本的三维得分图, 如图3所示。 红色为故障样品, 蓝色为正常样品, 可以看出大部分故障与正常的样本各自聚为一类。 由于三维视图信息维度较小, 且正常样品与早期故障样品内部基团组成差异不明显, 所以其光谱特征信息相似导致部分样品出现重叠现象。 因主成分分析仅能呈现样品的聚类趋势, 未考虑类别信息, 识别出的不一定是所需要的特征, 会损失有用信息, 故降维后的主成分不能充分代表光谱的主要信息。
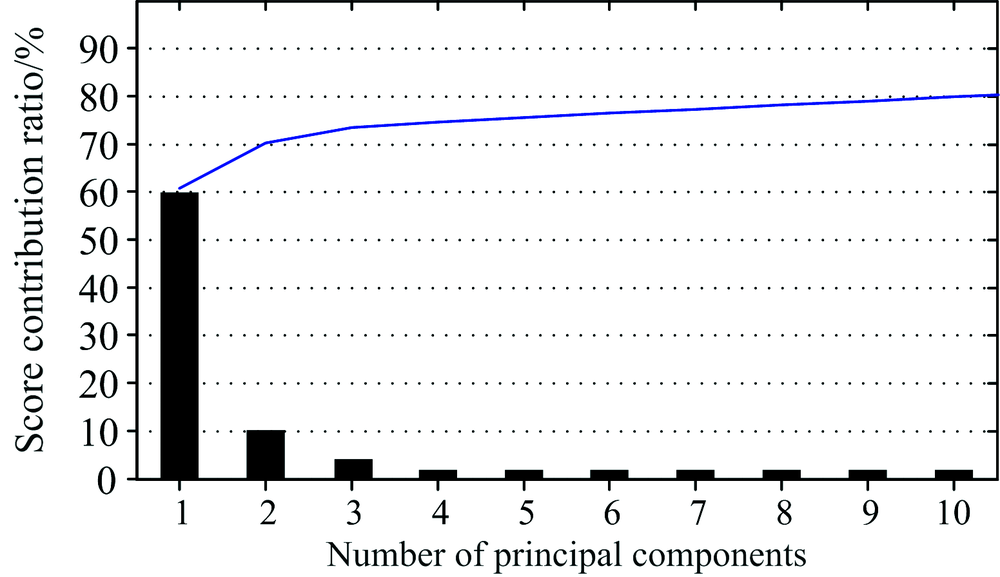 | 图2 主成分得分贡献率Fig.2 Score contribution ratio of principal components |
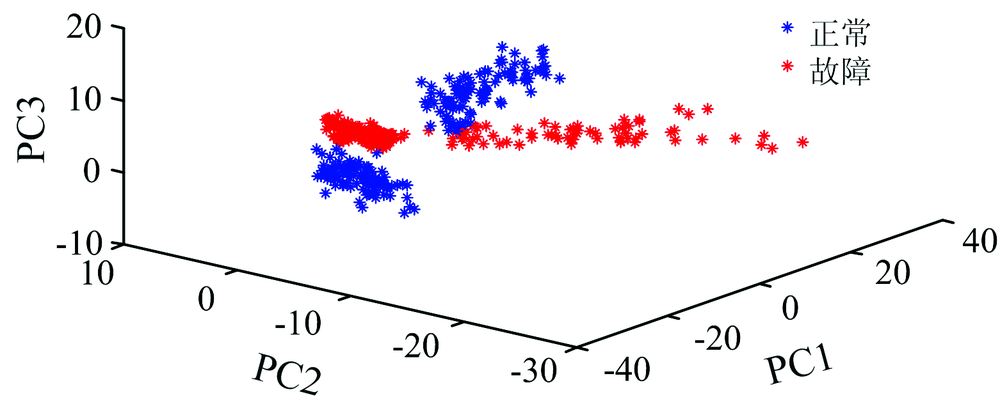 | 图3 样品光谱前3主成分得分图Fig.3 Score of the first three PCs for sample spectral data |
3.3.2 MIE特征波长选择
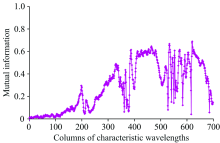
MIE方法将预处理过的光谱699个特征波长作为原始特征集X699={x1, x2, …, x699}, 初始最优特征子集为空集S0, 设定选取的特征数量为m, 根据光谱的特征波长和类别的数据, 计算X中各个特征波长xi与类别C的互信息熵I(xi; C), 结果如图4所示。
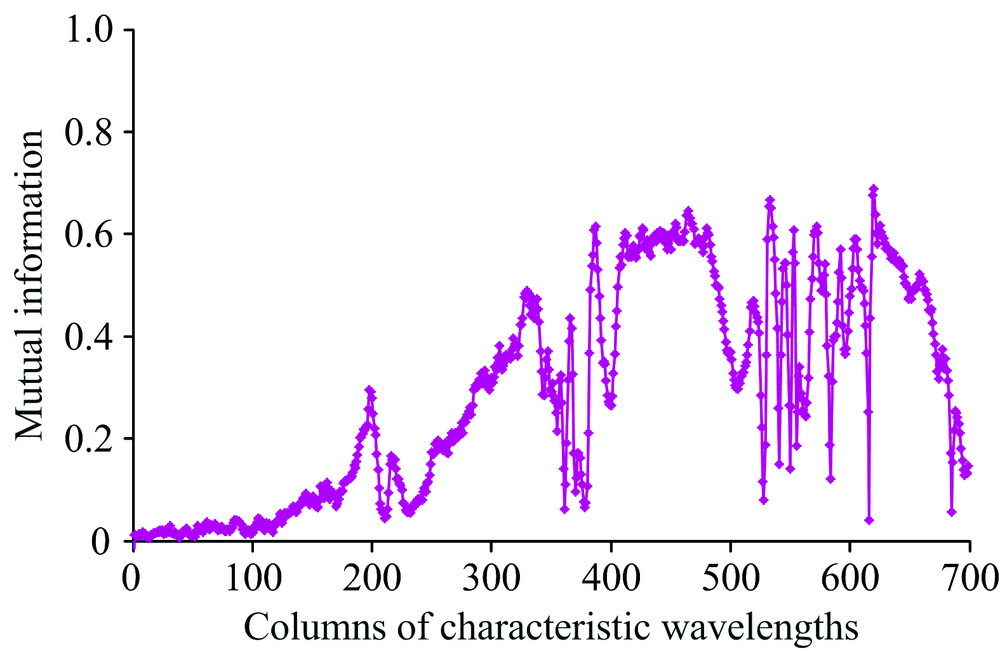 | 图4 特征波长所在的列与类别互信息分布Fig.4 Distribution of mutual information between the columns for characteristic wavelengths and class |
表2是按最小冗余最大相关算法降维之后的前30个特征排名(即m=30)。 该算法步骤如下: 首先, 选取互信息熵值最大的620列所在的特征波长1 927 nm作为加入最优特征子集S的第一个特征波长, 即S1={x620}X698=X699-{x620}={x1, …, x619, x621, …, x699}。 然后遍历X698中每个特征波长, 找到满足式(12)的特征x, 使得该特征波长既保证与类别之间的相关性充分大, 又能保证与S中已有特征波长的冗余度总和充分小, 将得到的特征波长加入S1并从X698中去除。 以此类推, 直到S中特征波长的个数达到设定的m值。 本文按照特征的排名, 选取特征数量分别为1, 2, 4, 6, 8, 10, 12, 14, 16, 18和20。
| 表2 最小冗余最大相关特征波长选择 Table 2 TOP30 characteristic wavelengths selected by min-redundancy and max-relevance |
3.3.3 PCA-MIE特征波长选择
PCA-MIE算法是特征提取的两阶段方法, 第一步先将PCA应用于原始特征波长获得简化特征子集F=[f1, f2, …, fk], 当主成分累计贡献率> 95%时, k=48, 故先提取48个特征波长主成分。 第二步将MIE应用于简化特征子集F, 最大限度的减小冗余并最大化特征与类别之间的相关性, 进一步降低特征维数, 得到最优的过程模式子集Z。 针对构建好的过程模式, 进一步利用贝叶斯统计学习算法进行故障检测, 用测试准确率(test accuracy, TA)作为评估标准, 其定义如下
其中, Num表示测试样本总数, CD表示正确决策的样本数量。
利用光谱699个特征波长, 通过PCA-MIE算法构造过程的模式子集, 再利用贝叶斯分类器进行故障检测, 表3是利用PCA, MIE和PCA-MIE三种方法获得的不同维数的特征子集和原始特征子集在贝叶斯统计学习算法下的准确率, 其中NB表示贝叶斯判别方法。 从表3可以看出, 全光谱判别的正确率最低, 仅有50.15%。 因为全光谱数据中含有大量的噪声、 冗余信息、 干扰信息, 大大降低了正确率。 利用PCA提取特征波长, 可以看出当主成分维数在14维时准确度达到最高值93.11%之后呈现稳定和下降趋势。 这说明了, 选取的特征子集对原油脱盐脱水工业过程故障检测的影响之大以及进行特征波长选择的重要性和必要性。 当维数大于14维时由于冗余的作用, 不仅不能获得更多的运行信息, 反而会因为特征波长子集中的冗余特征项使判别准确率下降。 利用MIE选择特征波长, 在特征波长数为12维时的准确度最高为93.56%, 即最优特征子集数为12。
| 表3 贝叶斯算法判别准确率% Table 3 Discriminant accuracy of Bayesian algorithm% |
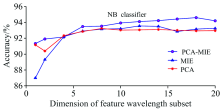
图5是PCA, MIE和PCA-MIE三种方法获得的不同维数子集的贝叶斯判别准确率。 从图5可以看出在特征波长子集维数较低(低于5维)时, PCA方法分类准确率高于MIE算法, 而大于5维之后, 随着特征项维数的增加, MIE方法准确率慢慢赶上并超过PCA。 本算法PCA-MIE几乎在所有维数子集上性能都优于其他两种方法, 说明该算法提取的特征子集更有类别代表能力且冗余最小。 在特征维数为18维时获得最高准确度94.6%。
 | 图5 贝叶斯判别准确率Fig.5 Bayesian discriminant accuracy |
针对近红外光谱, 提出了一种基于互信息熵的PCA-MIE算法, 该方法结合了传统主成分分析的优势, 并从信息论的角度对特征波长的相关度和冗余度进行了综合考量, 弥补了无监督特征波长选择的不足。 通过PCA-MIE获得的模式子集由于包含了更多的过程信息, 使得过程模式框架下的贝叶斯分类具有更高的准确率, 因此该方法在工业过程的故障检测领域具有良好的应用前景。 未来研究将从结构扩展和属性加权两个方面改进贝叶斯统计学习算法, 构造组合分类器, 以进一步提高故障检测的正确率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|