



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LIBS与反向传播算法结合的橄榄石成分分析
[袁汝俊1, 2, 3  , 万雄
, 万雄1, 2, * , 何强1, 2, 3 , 王泓鹏1, 2 ]
, 万雄, 何强|
|


作者简介: 袁汝俊, 1993年生, 中国科学院上海技术物理研究所博士研究生 e-mail: yrujun@163.com
LIBS是一项用于分析物质成分的有力手段, 但是定量分析时存在结果不准确、 重复性低等缺点。 为了准确预测自然界中橄榄石的成分信息, 通过按照自然界中的橄榄石的成分信息制作15组橄榄石样品, 将其中的11组作为标准样品, 另外4组作为测试样品进行LIBS定量分析。 每个样本采50条LIBS光谱建立橄榄石的LIBS数据库。 然后采用多元线性回归算法和反向传播算法对样本的50组数据进行分析, 有效的降低了由于随机误差造成的测试结果的不准确。 最终结果表明, 使用激光诱导击穿光谱和反向传播算法对橄榄石中镁橄榄石与铁橄榄石含量进行检测, 预测结果的决定系数为0.901, 接近常规的多元线性回归算法得到的0.911, 这说明反向传播算法对橄榄石含量的预测精度接近多元线性回归算法。 同时使用反向传播算法得到的结果的均方根误差为28.64, 优于后者的29.23, 说明使用反向传播算法得到的结果分布更加集中。 此外, 通过分析关联矩阵中各数值的大小与各元素谱线的位置的对应关系, 表明使用反向传播算法反演出来的关联矩阵 F与之所代表的物理含义的相关性更高。 说明反向传播运算不仅与传统的多元线性回归算法性能相当, 而且在预测数据的一致性上表现得更好。 此外使用反向传播算法可以直接对激光诱导击穿光谱得到的橄榄石全谱数据进行数据反演, 而不需要经过光谱寻峰这一步骤, 简化了数据分析流程, 弥补了多元线性回归算法难以分析全谱数据的不足。
Laser-induced breakdown spectroscopy analysis technology is a powerful method for analyzing material composition, but the use of it for quantitative analysis has the disadvantages of inaccurate analysis results and low reproducibility. In order to predict the composition information of olivine in nature accurately, this paper made 15 samples according to the composition information of olivine in nature, and 11 of them were used as standard samples, and the other 4 samples were used as test samples for LIBS quantitative analysis. Lastly, the laser-induced breakdown spectroscopy database of olivine was established with 50 spectra per sample. Then, the multiple linear regression algorithm and the back-propagation algorithm were used to analyze the 50 sets of data of this series of samples, which effectively reduced the inaccuracy of the test results caused by random errors. In the study of the content of forsterite and fayalite in olivine using back-propagation algorithm with data of laser-induced breakdown spectroscopy, the final results showed that the coefficient of determination of the prediction result was 0.901, close to the 0.911 which was yielded with conventional multiple linear regression algorithm. This indicated that the backward propagation algorithm’s prediction accuracy for olivine content was close to the multiple linear regression algorithm. Furthermore, the root mean square error of the result obtained with back-propagation algorithm was 28.64, which was better than the latter’s 29.23, which indicated that the result distribution obtained by the back-propagation algorithm was more concentrated. In addition, by analyzing the correspondence between the size of each numerical value in the correlation matrix and the position of each element’s spectral line, the results showed that the correlation matrix F inverted with back-propagation algorithm had a higher correlation with the physical meaning represented by it. This showed that the performance of the back-propagation operation was comparable to that of the traditional multiple linear regression algorithm, and it performed better in predicting the consistency of the data. In addition, the back-propagation algorithm could directly analyze the data of the olivine full spectrum data obtained by laser induced breakdown spectroscopy without the step of spectral peak finding, simplifying the process of data analysis and making up the shortcomings of the multiple linear regression algorithm in analyzing full-spectrum data.
激光诱导击穿光谱(laser-induced breakdown spectroscopy, LIBS)技术是一种利用高能脉冲激光激发的等离子体光谱来检测材料所含物质信息的技术[1]。 产生等离子体光谱的原理是高能脉冲激光轰击靶材表面, 靶材表面产生的高达10 000 K的局部高温使物质样本被解离成等离子体状态, 随着处于高能状态的等离子体逐渐冷却, 离子中的电子会向低能级跃迁, 在这一过程中会发射出与元素种类相关的特定波长的光子。 通过观察等离子体光谱中谱峰的波长位置和强度就可以分析靶材中所含物质的成分及含量信息[1, 2]。
由于LIBS具有高效、 无损、 低检测限和可远距离探测等优势, 在成分分析方面具备很好的实用性与应用前景[3, 4, 5]。 具体应用场所包括冶金、 矿产资源勘测、 水体检测和地质分析等领域。 目前LIBS技术在利用传统的多元线性回归(multiple linear regression, MLR)算法[6, 7]对物质成分进行定量分析时需要人工参与手动查找谱峰位置等准备过程。 另外当样品条件、 激光能量变化时, 与实际物理含义无关的MLR方法对目标的成分预测值会比实际值有较大的误差。 本工作利用反向传播(back-propagation, BP)算法[8]预测待检样品中的橄榄石成分比传统的多元线性回归算法的精度稍有改善, 改善了物理含义匹配度不足的缺点。 此外还可以对全谱数据进行直接分析, 免除人工寻找谱峰位置的过程。 因此结合反向传播算法的方式是一种可以改善激光诱导击穿光谱对物质成分进行准确分析的有效方法。
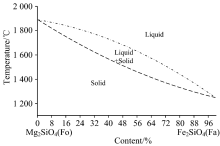
橄榄石是一种镁与铁的硅酸盐, 化学式为(Mg, Fe)2SiO4。 在地质成分分类中, 橄榄石属于火成岩中的一个重要的组成部分。 橄榄石的化学组成通常由两部分组成, 一部分是镁橄榄石(Mg2SiO4, 简称Fo), 另一部分是铁橄榄石(Fe2SiO4, 简称Fa)。 地质中形成的橄榄石就是这两种端元组分形成的固溶体。 橄榄石的成分可由Fo和Fa这两种端元组分的摩尔百分比表示, 例如Fo70 Fa30表示镁橄榄石端元组分占70%的橄榄石。 不同的橄榄石成分反映了地质形成过程中不同的物理条件, 例如: 不同的结晶温度下形成的橄榄石中Fo和Fa分子数的比例关系如图1所示。 通过分析岩石中橄榄石的成分信息, 结合岩石采集地点的地理位置和地质状况, 可以大致分析出地质运动时的成矿条件以及成矿之后的岩石演化和侵蚀作用。 因此使用LIBS定量分析橄榄石成分可以实现研究地质变化及地球演变的目的。 由于LIBS可在极端条件下进行远程探测, 因此在航天领域中对行星表面矿物的物质成分分析有十分积极的作用。 本工作就包含对火成岩中橄榄石成分的定量分析就是一个实例。
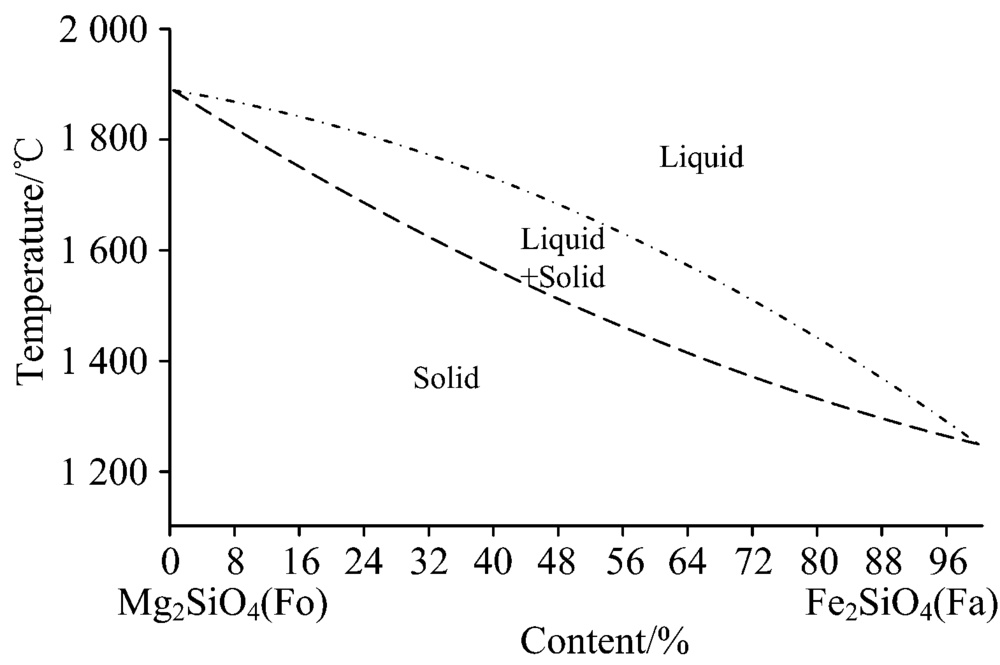 | 图1 橄榄石成分与结晶温度的关系Fig.1 Relationship between olivine compositions and crystallization temperature |
为分析出自然界中的各种橄榄石, 以组分比Fo∶ Fa从0∶ 10至10∶ 0制作标准橄榄石样品。 测试样品选用另一组自制样品及自然界中存在的橄榄石样品。
由于自然界中的火成岩成分都是由物质的氧化物反应形成的, 因此可以按照氧化物混合的配料方式来模拟镁橄榄石和铁橄榄石的化学组成。 方案中采用MgO和SiO2的2∶ 1混合的方式模拟橄榄石中的镁橄榄石端元矿物(Mg2SiO4, Fo)的化学组成, 采用Fe2O3和SiO2的1∶ 1混合的方式模拟橄榄石中的铁橄榄石端元矿物(Fe2SiO4, Fa)的化学组成。 最终的镁橄榄石端元矿物的化学式和配比方案中的组成成分(2(MgO)+SiO2)的氧分子数完全相同。 最终的铁橄榄石端元矿物的化学式和配比方案中的组成成分(Fe2O3+SiO2)的氧分子数稍有不同, 但由于空气中有氧元素, 因此氧元素不用作成分分析, 不会影响实验的结果, 这种配比方法是可行的。 最终制定的物质配比方案如表1、 表2所示。 实验中所用的氧化物粉末均购自阿拉丁化学试剂公司, 所有物质的纯净度等于或优于色谱级(SP)。
| 表1 第一组训练样品 Table 1 First group of samples for training |
| 表2 第二组测试样品 Table 2 Second group of samples for testing |
以上配制好的样品粉末经充分混合均匀后, 再经20 MPa压力压制成约10g的靶材。 用第一组样品的测试数据作为标准数据, 第二组样品的数据则用作最终的测试数据。 图2为混合完成的粉末以及最终压制成的实验样品。
 | 图2 混合完成的粉末以及最终制成的实验样品Fig.2 Mixed powder and final experimental sample |
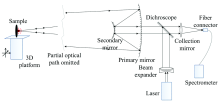
激光诱导击穿光谱实验系统如图3所示。
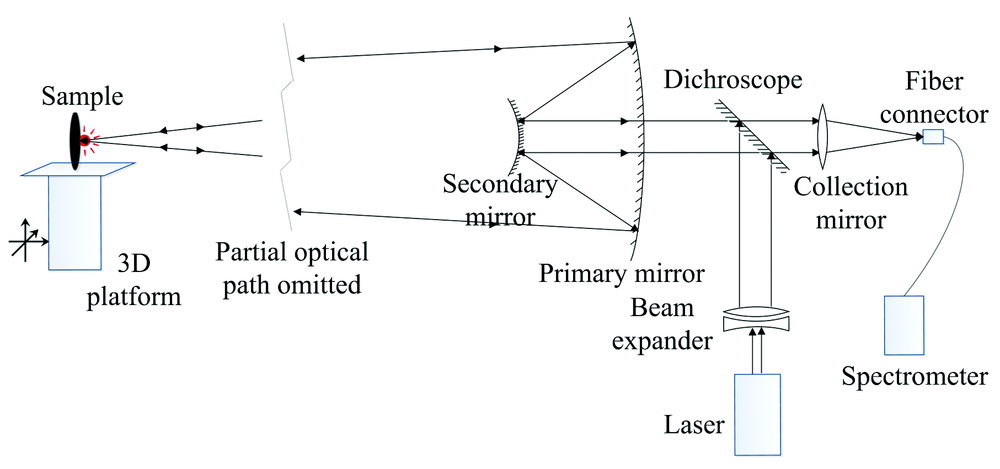 | 图3 激光诱导击穿光谱实验系统结构Fig.3 Structure of LIBS experimental system |
1 064 nm波长的输出激光, 到达样品表面的激光脉冲能量为18.2 mJ· pulse-1, 脉冲频率使用DG-645脉冲延时发生器调节为5 Hz。 激光从激光器中输出后, 首先经过4倍的扩束镜进行扩束以减小激光的能量密度, 然后经由一面镀有1 064 nm反射膜的45° 放置的二向色镜将激光引入一组由主次镜组成的施密特镜。 激光经由施密特镜反射后聚焦至1.2 m处靶材的位置。 在靶材表面产生等离子体LIBS的光谱经过同光路返回至二向色镜, 300~1 000 nm的有效信号透过二向色镜进入光纤输出的收集镜中。 最终的光谱信号由光纤引入Avantes 2048USB型光纤光谱仪中。 该型光谱仪的信噪比为200∶ 1 , 波长范围为200~1 100 nm, 分辨率为0.04~20 nm。
由DG546控制曝光的曝光时间为1.05 ms使整个等离子体发光的过程中产生的光子都能有效的收集。 最终的数据由PC机读出。
试验参数如表3所示。
| 表3 激光诱导击穿光谱试验参数 Table 3 Parameters of LIBS experiment |
在上述条件下一共测试了15个样品, 每个样品包含50条光谱信息, 共750条原始光谱数据。 将1_1组至1_11组的550条光谱作为训练数据, 2_1组至2_4组的200条光谱作为测试数据。
使用LIBS数据分析橄榄石中的Fo与Fa的含量的方法可分为数据准备、 回归分析两个过程, 详细流程见图4。 为保证回归分析中数据的统一性和有效性, 首先需要进行数据预处理[9]。 预处理之后, 以往需要利用寻峰算法找出原始数据中的谱峰的数据。 对谱峰数据可以采用多元线性回归算法和反向传播算法, 分别预测测试样品中的橄榄石成分信息, 具体的分析方法包括单变量分析[10]和多变量[10, 11, 12]。 本工作不利用寻峰算法, 创新性地提出采用反向传播算法直接对全谱段数据进行迭代运算以得到最终橄榄石中Fo含量的预测结果。
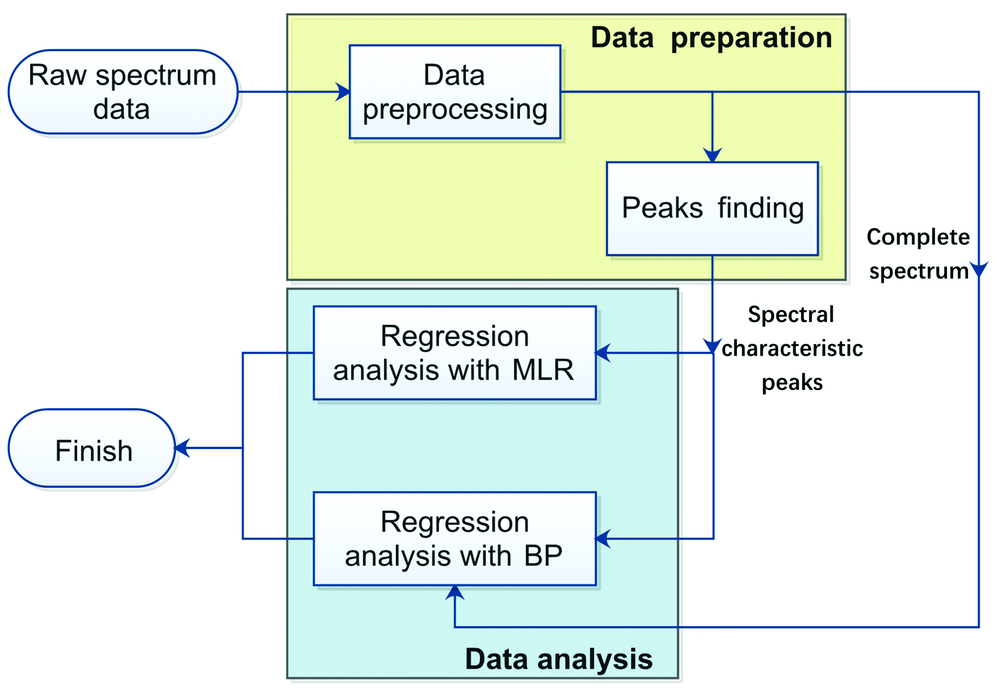 | 图4 数据分析流程图Fig.4 Flow chart of data analysis |
同时也对比分析了多元线性回归算法和反向传播算法的优缺点; 对比分析了使用两种不同数据即基于特征峰的数据和使用全谱段的数据进行反演分析的结果差异。
实验直接获取的LIBS信号会受到CCD暗电流、 连续光谱背景和激光脉冲能量变化等因素的干扰。 为了提高定量分析算法的准确性, 原始的光谱数据需要经过预处理才可进行下一步的数据分析过程。 预处理的流程示意图如图5所示。
 | 图5 数据预处理流程图Fig.5 Flow chart of data preprocessing |
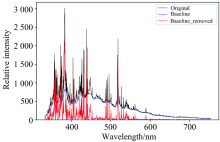
根据等离子体光谱的光谱发射特性可知: 在等离子体发射光谱的过程中, 存在两个主要过程[12]。 因为实验中采用的1.05 ms曝光时间远大于连续光谱背景和LIBS光谱的持续时间。 因此可以使用非对称最小二乘算法去除光谱信号中的连续光谱背景基线(Baseline), 保留有效的LIBS光谱信号。 经去除连续光谱背景基线后的LIBS光谱见图6。 此外对去除连续光谱背景基线后的数据进行规范化(normalization)处理, 以确保信号的一致性、 有效性, 有利于提高最终分析精度。
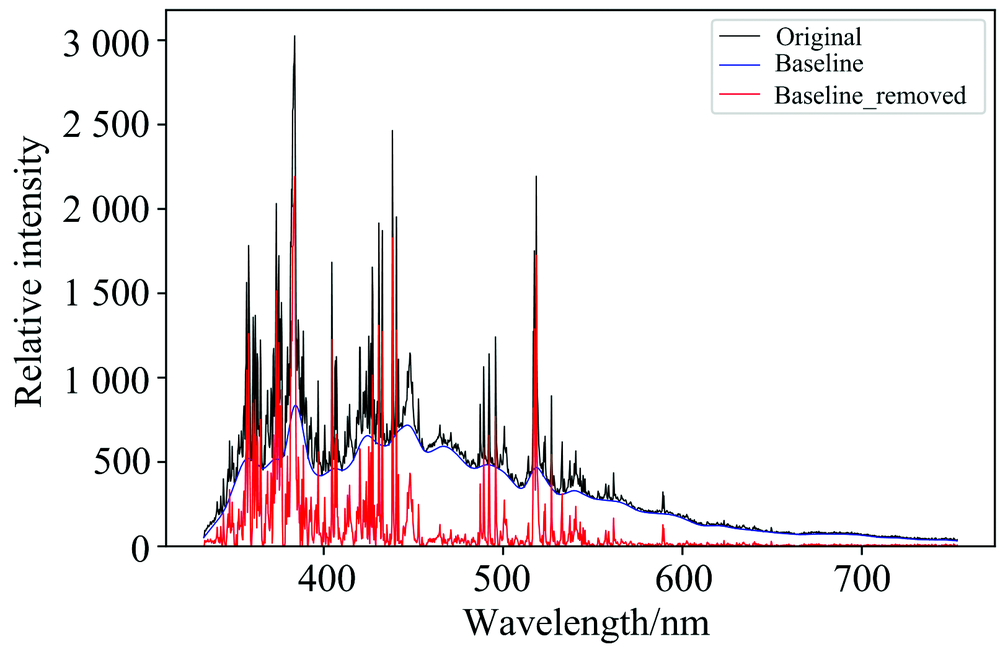 | 图6 去基线前后光谱对比图(第1_6组)Fig.6 Comparison between baseline removed and original specura |
1.3.1 寻找特征峰
经过预处理之后的光谱为了方便数据反演, 通常会通过与标准数据库对比选取各元素对应特征峰进行手动的特征峰提取, 然后再利用回归算法进行分析。
在此采用计算机自动选取光谱中的公共谱峰来做回归分析。 寻峰条件是: 谱峰间距大于1 nm, 光谱强度大于光谱最高强度值的1/10。 最终每条光谱信息选取出28条公共谱峰, 利用这组特征峰数据就可以进行下一步的分析工作。 寻找到的谱峰的所述元素的信息见表4。
| 表4 峰位及元素信息对照表 Table 4 Contrast table between spectral peaks and elements |
1.3.2 裁剪全谱数据
由于反射、 透射镜片的衰减作用, 仪器最终响应的波长范围在333~600 nm之间, 因此全谱段的信息由最原始的每条光谱2 048点剪切至964点。 最终全谱信息的数据格式统一为每条光谱964点。
X矩阵为由测试集中各组物质的光谱经数据预处理得到的光谱信息矩阵, Y为对应的物质含量信息矩阵, F为它们X与Y之间的关系矩阵。 关联矩阵F的物理含义: 光谱图中波长位置的强度与物质含量之间的相关关系。 利用式(1)就可以描述它们之间的基本关系
(1)只是分析光谱的特征峰时, 由于选用光谱中的28个特征峰作为X矩阵(形状为550× 28), 对应的物质信息只有c(Fo)%这一个未知量, 所以Y矩阵的形状为550× 1。 因为需要求解的矩阵是关联矩阵, 因此需要包含28个系数项和1个常数项, 所以最终需要求解的关联矩阵就是一个形状为(28+1)× 1的向量。
(2)只是分析全谱数据时, 将完整光谱作为X矩阵(形状为550× 964), 对应的物质信息只有c(Mg)%∶ c(Fe)%这一个未知量, 所以Y矩阵的形状依旧是550× 1。 所以我们需要求解的关联矩阵就是一个形状为(964+1)× 1的向量。
利用上述矩阵关系以及用于训练的550条光谱数据, 结合适当的优化算法就可以求解出关系矩阵F。 最后就可以利用上述公式及关系矩阵对测试集的200条光谱数据进行定量反演。
1.4.1 多元线性回归算法
多元线性回归是利用矩阵运算求解最小二乘解的一种方法[6]。 使用多元线性回归算法是利用最小二乘算法最小化误差寻找最优解的方法, 可以用来求解两个矩阵(X和Y)的关系矩阵F的近似解。 在使用MLR进行光谱分析时, 就是在求解光谱强度矩阵X与物质含量矩阵Y之间的关联矩阵F, 即
式(2)中, XT为X的转置矩阵, (XTX)-1为XTX的逆矩阵。
利用求解到的关联矩阵F对测试集进行数据分析: 结合已知测试样品的光谱信息矩阵X, 根据式(1)就可以计算出该光谱对应的物质含量信息矩阵Y。
只是分析光谱的特征峰时, 求解的关联矩阵Fmlr是一个形状为(28+1)× 1的向量。 但是在分析全谱数据时, 因为此时的未知数(965个)大于建立方程的个数(550), 因此利用多元线性回归的方法是无法求解出全谱数据的关系矩阵Fmlr。
1.4.2 反向传播算法
反向传播算法是一种利用迭代方式逐渐优化参数, 以获得近似最优解的优化算法。 在上式中求解关系矩阵FBP的过程中就可以使用反向传播算法来优化最终的测试结果。
使用反向传播算法计算关联矩阵F的方法包含以下三个基本过程:
(1)随机选取所有数据中的一部分, 计算出在当前参数Ftmp下使用前向传播的方式得出的预测值Ypre。
(2)利用L2损失函数, 计算预测值Ypre与实际值Yrel的误差值ltmp。
(3)使用反向传播算法在所得的损失值ltmp的条件下重新调整参数矩阵Ftmp中各元素的值, 并回到步骤(1)。
不断地重复以上过程就可以实现优化矩阵Ftmp的目的。 在此条件下得到的预测值Ypre趋近于实际值Yrel, 此时得到的关联矩阵Ftmp即为关联矩阵的最优解Fbp矩阵。
通过以上两种方法分别求解出的关联矩阵Fmlr和Fbp, 再结合方程就可以计算出测试集数据对应的橄榄石成分。 此时测试集是4种不同的含量的橄榄石样品, 每个样品测试出50条LIBS光谱, 通过使用矩阵运算的方法就可以得出最终的含量信息。 由于每条光谱都会有一定的差异, 因此将最终的50个预测值进行平均作为预测值。
按照上述方式获得的相应橄榄石含量的预测结果见表5。
表5中R2为决定系数(coefficient of determination), 表明预测结果与真实值之间的相关关系, 以此来判断模型的解释力。 RMSE为均方根误差(root-mean-square error), 表明数据的偏差程度, 以此来判断数据的集中程度。
2.1.1 使用单一谱峰数据进行分析
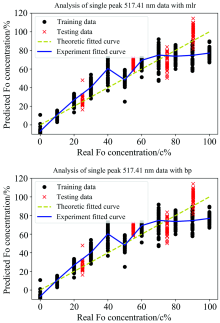
最终的预测结果可以说明在使用单一Mg元素的谱峰作为橄榄石成分分析的条件下, 采用MLR和BP算法反演求得的橄榄石成分分析结果是十分接近, R2值分别为0.821和0.820, RMSE分别为28.76和28.73。 说明二者在性能上没有表现出明显差别。 具体预测结果见图7和表5。
 | 图7 使用517.41 nm谱峰对Fo含量进行数据反演的结果Fig.7 Calibration and concentration prediction of Fo with the peak at 517.41 nm |
| 表5 橄榄石成分信息的预测结果 Table 5 Prediction results of olivine composition information |
2.1.2 使用多条谱峰数据进行分析
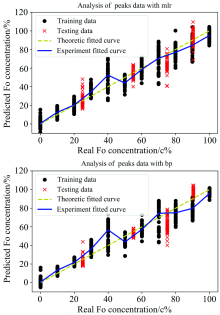
图8和表5可知使用橄榄石中能查找到的28条谱峰分析橄榄石成分, 采用MLR和BP算法反演求得的橄榄石成分分析结果为: R2值分别为0.911和0.888, RMSE分别为29.23和29.53。 说明MLR算法的精度稍好, 但是数据的集中性与BP算法相当。
 | 图8 使用所有28条谱峰对Fo含量进行数据反演的结果Fig.8 Calibration and concentration prediction of Fo with all 28 peaks |
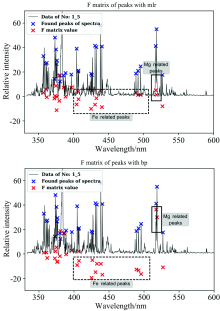
此外观察使用BP算法得到的谱峰的关联矩阵(决定系数)(图9)与使用MLR方法得到的结果相比, 可以明显发现关联矩阵F在实线框内谱峰的绝对值后者大于前者。 且该谱峰与Mg元素(Fo含量)呈正相关趋势; 同理, 在虚线框中呈现相同的特性。 这说明使用BP算法相比于MLR方法得到的结果更加符合关联矩阵的物理含义(光谱中Mg和Fe元素谱峰的强度与橄榄石中Fo含量之间的正、 负相关关系)。
 | 图9 使用所有28条谱峰对Fo含量进行数据反演得到的关联矩阵FFig.9 Correlation matrix F obtained by data inversion of Fo with all 28 peaks |
因为全谱数据中的的未知量太多, 使用MLR方法无法求解出全谱信息对应的橄榄石中Fo含量的信息。 但是采用反向传播算法则可以得出较为理想的反演结果。 故对于全谱数据只采用BP方法进行对关联矩阵F的求解。
由图10和表5可知使用全谱数据分析橄榄石成分, 采用BP算法反演求得的橄榄石成分分析结果与图8中采用MLR算法对28个谱峰数据进行分析得到的结果是十分接近, R2值分别为0.911和0.901, RMSE分别为29.23和28.64。 这说明二者预测精度相当, 但是对全谱数据分析的得到的结果更加集中, 可信度更高。
 | 图10 使用全谱数据对Fo含量进行数据反演 得到的预测结果和关联矩阵F此外观察使用BP算法得到谱峰的关联矩阵(决定系数)(图9、 图10)与使用MLR方法得到的结果相比, 可以明显发现关联矩阵F在实线框内谱峰的绝对值后者大于前者。 且该谱峰与Mg元素(Fo含量)呈正相关趋势; 同理, 在虚线框中呈现相同的特性。Fig.10 Prediction results and correlation matrix F obtained by data inversion of Fo with full-spectrum data |
这说明使用BP算法得到的结果更加符合关联矩阵的物理含义(即光谱中Mg和Fe元素谱峰的强度与橄榄石中Fo含量之间的正、 负相关关系)。 相比之下, 使用MLR方法得到的关联矩阵F并没有与物理含义相对应的表现。从这方面讨论, 使用BP算法得到的Fo含量的预测结果更具可信度。
在使用MLR和BP算法对橄榄石中Fo的含量进行数据反演分析时, BP算法通过全谱数据对物质成分预测出的结果更加集中。 此外使用BP算法对谱峰数据进行数据反演结果比MLR算法更符合实际的各元素谱峰的强度与橄榄石中Fo含量之间的相关关系, 因此预测结果在理论上分析更加完备。 这说明使用BP算法可以免除在特定条件下对LIBS寻峰的要求, 简化了数据分析的过程, 分析结果精度与与传统MLR方法相当。 因此在特定条件下, 可以采用BP算法替代传统的MLR方法进行数据反演。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|