{kind=link}
{kind=link}
{kind=link}
食用植物油中反式脂肪酸含量的激光拉曼光谱检测
[蒋雪松1  , 莫欣欣
, 莫欣欣3 , 孙通2, 3, * , 胡栋2 ]
, 莫欣欣, 胡栋|
|


作者简介: 蒋雪松, 1979年生, 南京林业大学机械电子工程学院副教授 e-mail: xsjiang@126.com
油脂中的反式脂肪酸(TFA)有害人们的身体健康, 有必要对其含量进行监测。 共收集各类食用植物油样本79个, 涉及9个品种和27个品牌, 分配到校正集和预测集的样本数分别为53个和26个。 采用QE65000拉曼光谱仪采集79个样本的拉曼光谱, 利用自适应迭代惩罚最小二乘法去除样本拉曼光谱的荧光背景; 在此基础上, 采用多种归一化方法对样本拉曼光谱进行处理, 并对拉曼光谱的建模波数范围进行初选; 再利用竞争性自适应重加权采样(CARS)方法筛选与食用植物油TFA含量相关的光谱变量, 并应用偏最小二乘(PLS)回归将食用植物油TFA的特征变量光谱强度与气相色谱测定的TFA真实含量进行关联, 建立食用植物油中TFA含量的定量预测模型。 研究结果表明, 多种归一化方法中, 有4种归一化方法均能提高PLS定量预测模型的性能, 其中Area normalization方法的效果最优; 经建模波数范围初选, 波数范围由6862 301 cm-1缩减为7371 787 cm-1, 确定较优的建模波数范围为7371 787 cm-1; 经CARS方法筛选, 共有31个光谱变量被选择, 其选择的光谱变量主要分布在1 265, 1 303, 1 442及1 658 cm-1拉曼振动峰附近, 且974 cm-1拉曼振动峰两侧均有光谱变量被选择; 此外, CARS方法的PLS建模结果优于常用的无信息变量消除及连续投影算法。 由此可知, 激光拉曼光谱技术结合化学计量学方法检测食用植物油中的TFA含量是可行的。 归一化方法、 建模波数范围初选及竞争性自适应重加权采样(CARS)方法能有效提高TFA定量预测模型的预测精度和稳定性, 优化后的TFA定量预测模型的校正集及预测集的相关系数和均方根误差分别为0.949, 0.953和0.188%, 0.191%。 与未优化的预测模型相比, 预测均方根误差由0.361%下降为0.191%, 下降幅度为47.1%; 建模所用的变量数由683个下降为31个, 仅占原变量数的4.54%。
Trans fatty acids (TFA) in oils and fats are harmful to people’s health, so it is necessary to monitor their content. In this research, 79 samples of edible vegetable oils were collected, involving 9 varieties and 27 brands. The number of samples that were allocated to calibration and prediction sets was 53 and 26, respectively. Raman spectra of 79 edible vegetable oil samples were collected by a QE65000 Raman spectrometer, and adaptive iteratively reweighted penalized least squares was used to remove fluorescence background of Raman spectra. Then, various normalization methods were used to process Raman spectra, and preliminary selection of modeling wavenumber range of Raman spectra was carried out. After that, competitive adaptive reweighted sampling (CARS) method was used to select TFA-related variables, and partial least squares regression was used to correlate the spectral intensity of TFA characteristic variables with the real content determined by gas chromatography to establish quantitative prediction model of TFA content in edible vegetable oils. The results indicate that among various normalization methods, four normalization methods can improve the performance of PLS quantitative prediction model, and area normalization method has the best effect. After primary selection of wavenumber range, the range of wavenumber is reduced from 686 to 2 301 cm-1 to 737 to 1 787 cm-1, and the optimum range of wavenumber is determined to be 737 to 1 787 cm-1. Thirty-one spectral variables are selected by CARS method. The selected spectral variables are mainly distributed near the Raman vibration peaks of 1 265, 1 303, 1 442 and 1 658 cm-1, and the variables in the both sides of the Raman vibration peaks of 974 cm-1 are also selected. In addition, the PLS modeling results of CARS method were better than those of the commonly used methods such as uninformative variable elimination and successive projections algorithm. Therefore, it is feasible to detect TFA content in edible vegetable oil by laser Raman spectroscopy combined with chemometrics. Normalization method, wavenumber range selection and CARS method can effectively improve the prediction accuracy and stability of TFA quantitative prediction model. The correlation coefficients and root mean square errors of optimized TFA quantitative prediction model in calibration and prediction sets are 0.949, 0.953 and 0.188%, 0.191%, respectively. Compared with the unoptimized prediction model, the root mean square error of prediction decreases from 0.361% to 0.191%, with a decrease of 47.1%. The number of variables used in modeling decreases from 683 to 31, accounting for only 4.54% of the original variables.
反式脂肪酸(trans fatty acid, TFA)是一类不饱和脂肪酸, 食用油脂的氢化加工、 食用植物油的精炼、 脱臭工艺以及高温烹调均会产生反式脂肪酸。 食用植物油中的反式脂肪酸是一种不好的脂肪酸, 食用过量会对人体健康产生诸多危害, 如影响儿童生长发育, 引起动脉硬化, 诱发糖尿病、 心血管疾病及神经系统疾病, 增加前列腺癌、 乳腺癌、 结肠癌等癌症风险[1]。 而食用植物油是人们生活的必需品, 因此非常有必要对食用植物油中的反式脂肪酸含量进行监测。
激光拉曼光谱技术是近年来发展起来的现代光谱分析技术, 具有分析速度快、 非破坏性检测、 无需样品预处理、 不污染环境以及成本低等优点。 目前, 在农产品/食品安全检测领域, 激光拉曼光谱分析技术已应用于辣椒苏丹红[2, 3]、 鸡尾酒防腐剂[4]、 玉米真菌毒素[5]、 奶粉三聚氰胺[6]、 果蔬农药残留[7, 8]、 牛奶抗生素[9]及猪肉瘦肉精[10]等的定量检测。 对于反式脂肪酸的拉曼光谱检测, Stefanov等[11]对牛奶中反式脂肪酸进行拉曼分析, 确定了单不饱和脂肪酸和共轭亚油酸的C=C双键特征拉曼峰分别为1 674和1 653 cm-1。 Zhao等[12]采用拉曼光谱技术对乳制品中总反式脂肪酸含量进行检测。 对于黄油, 其总反式脂肪酸验证集模型的决定系数为0.560.78。 Numata等[13]利用拉曼光谱技术对混合溶液中的油酸和反油酸含量进行检测。 总结上述文献发现, 反式脂肪酸的拉曼光谱检测研究非常稀少, 仅为初步的特征峰判别和定量分析, 需要进一步深入研究。 此外, 尚未有食用植物油中反式脂肪酸的拉曼光谱检测研究报道。
研究利用激光拉曼光谱技术对食用植物油中的反式脂肪酸含量进行快速定量检测研究, 采用归一化方法对样本光谱进行预处理, 并对光谱建模波数范围进行初选及(competitive adaptive reweighted sampling, CARS)变量筛选, 最后应用偏最小二乘 (partial least squares, PLS)回归方法建立食用植物油中反式脂肪酸含量的定量预测模型。
试验所用的食用植物油样本共有79个, 均从各正规大超市购买。 品种包括大豆油、 菜籽油、 玉米油、 花生油及调和油等, 含有福临门、 胡姬花、 香满园、 金龙鱼、 鲁花、 游天下及道道全等27个品牌。 为保证校正集和预测集样本分配具有代表性及合理性, 首先将79个样本按照TFA含量高低进行排序, 再按相应比例随机分配到校正集和预测集。 校正集及预测集各分配到53个和26个样本。
试验所用的主要试剂: 顺式-9-十八烯酸甲酯(46902-U)、 反式-9-十八烯酸甲酯(46903)、 4种亚油酸甲酯顺反异构体(47791)及8种亚麻酸甲酯顺反异构体(47792)标准品, 均购买于美国Sigma公司; 异辛烷(色谱纯), 氢氧化钾-甲醇溶液(2 mol· L-1), 硫酸氢钠(分析纯)。
试验所用的便携式拉曼光谱检测系统主要包括QE65000拉曼光谱仪(Ocean Optics Co., USA)、 激光器、 光纤及样品池等。 激光器波长为785 nm, 功率为460 mW。 GC-2010气相色谱仪(Shimadzu Co., Japan)配有FID检测器和GC SOLUTION数据处理工作站。 色谱柱为HP88毛细管色谱柱(100 m× 0.25 mm× 0.25 μ m)。
采用移液枪将79个食用植物油样本依次加入2 mL石英进样瓶中, 再将进样瓶置于样品池中进行拉曼光谱采集。 光谱采集软件为Ocean Optics Spectrasuite (Ocean Optics Co., USA)。 光谱积分时间为10 s, 平均次数为2次。
对于79个食用植物油样本, 参照国家标准方法GB 5009.257— 2016测定其TFA含量。 每个食用植物油样本均测定两次, 取测定结果的平均值作为样本TFA含量。 气相色谱的检测条件如下: 进样口及检测器温度分别设定为240和300 ℃; 色谱柱采用程序升温, 初始温度为120 ℃, 先以5 ℃· min-1升温至170 ℃, 保持10 min, 再以2 ℃· min-1升温至185 ℃, 保持8 min, 然后以3 ℃· min-1升温至240 ℃, 保持10 min; 载气为氮气, 其流速及压力分别为1.99 mL· min-1和360.4 KPa; 氢气及空气流速分别为50和500 mL· min-1; 分流比为20∶ 1。
首先, 采用自适应迭代惩罚最小二乘法对样本拉曼光谱进行预处理, 以扣除光谱的荧光背景。 在此基础上, 利用多种归一化方法(area normalization, mean normalization, maximum normalization, unit vector normalization, range normalization)对拉曼光谱进行处理, 以消除外界因素及激光能量波动等的影响。
然后, 利用竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)方法筛选变量, 并与连续投影算法(successive projections algorithm, SPA)及无信息变量消除(uninformative variable elimination, UVE)进行比较。 本研究中, 由蒙特卡罗交叉验证决定CARS方法的最大因子数, 采样次数为50次, 并根据交互验证均方根误差(root mean square error of cross validation, RMSECV)最小确定最优变量子集。 CARS方法的原理参见文献[14]。
最后, 应用PLS方法建立食用植物油中TFA含量的定量预测模型, 并利用预测集样本对模型进行验证。
表1为校正集、 预测集及所有样本的TFA含量平均值、 范围及标准偏差。 样本最高及最低的反式脂肪酸含量分别为2.662%和0.014%。 此外, TFA含量在00.5%, 0.51%, 11.5%, 1.52%之间的样本数分别为30个、 29个、 11个和6个, TFA含量在2%以上的样本数为3个。
| 表1 校正集、 预测集及所有样本的反式脂肪酸含量平均值、 范围及标准偏差 Table 1 Means, ranges, and SDs of TFA contents for calibration, prediction and all samples |
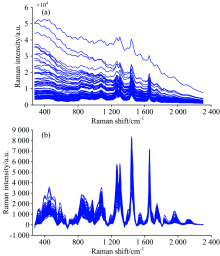
图1(a)为所有样本的原始拉曼光谱。 由图1(a)可知, 原始光谱在1 2001 800 cm-1波数范围存在较为明显的谱峰; 在4001 200 cm-1波数范围, 由于不同品种的样本颜色深度有差异, 其光谱存在较强的荧光背景及基线漂移, 导致谱峰被掩盖, 需要对光谱进行预处理。 图1(b)为扣除荧光背景后的样本拉曼光谱。 由图1(b)可知, 样本光谱的荧光背景及基线漂移得到有效消除, 各拉曼谱峰更加清晰。 其中, 974 cm-1为反式双键的拉曼振动峰, 1 265及1 658 cm-1为顺式双键的拉曼振动峰, 1 303及1 442 cm-1分别为亚甲基和甲基的拉曼振动峰[15]。 上述拉曼振动峰对TFA定量检测可能均为有用的光谱信息, 需要包含在建模波数范围内。 此外, 在279685 cm-1波数范围, 由于受荧光背景及基线漂移影响最大, 其光谱信噪比较低, 不纳入建模波数范围。 因此, 后续的光谱数据分析在6862 301 cm-1波数范围内进行, 该范围共有683个变量。
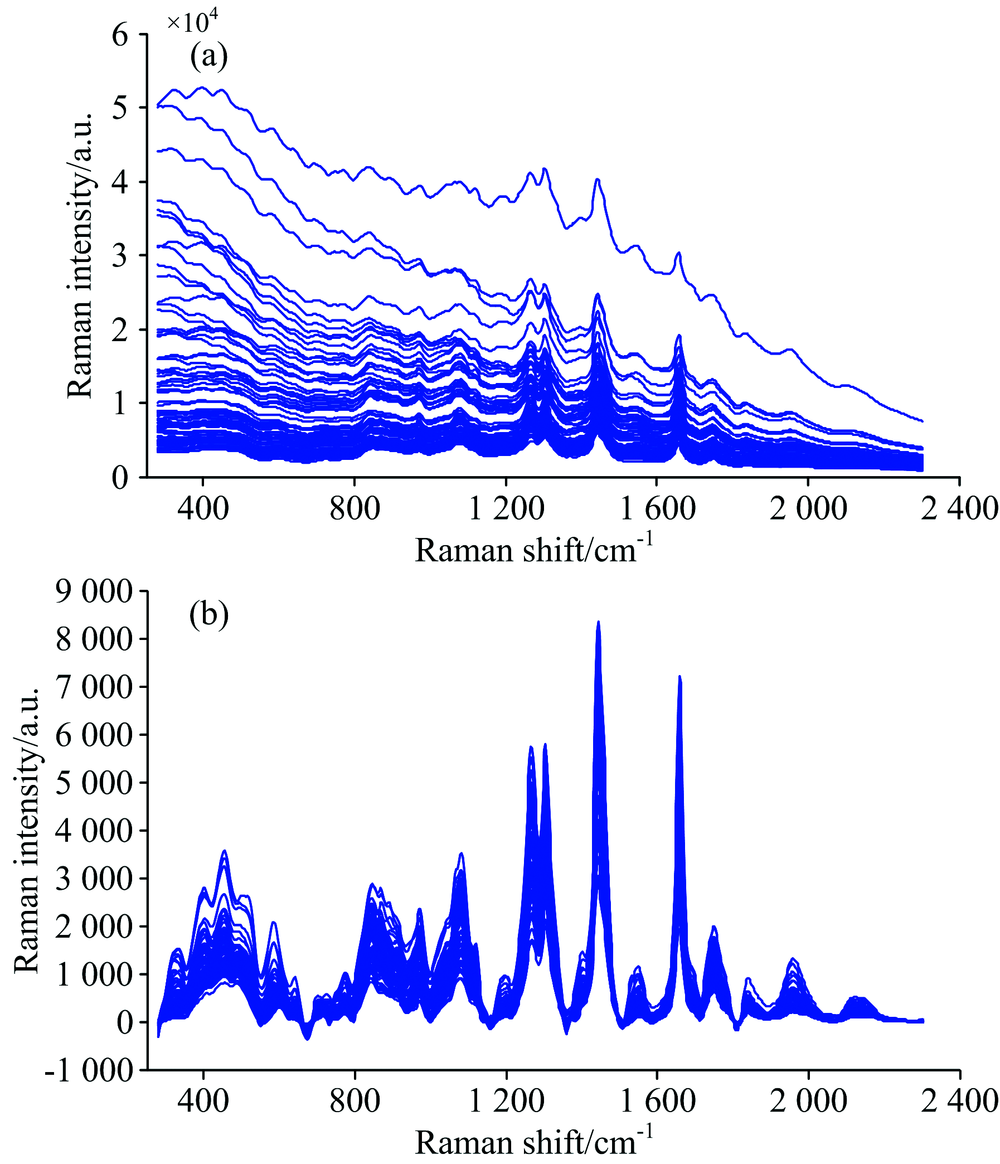 | 图1 食用植物油样本的拉曼光谱 (a): 原始光谱; (b): 荧光背景扣除后的光谱Fig.1 Raman spectra of edible vegetable oil samples (a): Original spectra; (b): Spectra after fluorescence background subtraction |
在扣除荧光背景的基础上, 采用多种归一化方法对样本拉曼光谱进行处理, 以确定较优的归一化处理方法。 表2为不同归一化预处理方法下样本TFA含量的PLS建模结果。 由表2可知, 除Range normalization方法外, 其他4种归一化方法均能在一定程度上提高TFA定量预测模型的性能。 5种归一化方法中, 经Area normalization预处理后所建立的TFA定量预测模型性能最优, 其校正集和预测集的相关系数及均方根误差分别为0.956, 0.905和0.176%, 0.276%。
| 表2 不同归一化预处理方法下反式脂肪酸的PLS建模结果 Table 2 PLS results of TFA at different normalization pretreatment methods |
在Area normalization预处理的基础上, 进一步对样本拉曼光谱的建模波数范围进行初步选择。 表3为不同波数范围下样本TFA含量的PLS建模结果。 由表3可知, 当波数范围由6862 301 cm-1缩减为6861 882 cm-1时, TFA含量的校正集和预测集相关系数均有上升, 而校正均方根误差(root mean square error of calibration, RMSEC)及预测均方根误差(root mean square error of predictioo, RMSEP)均下降, TFA定量预测模型性能提高, 表明缩减的波数范围为无用光谱信号, 对TFA定量预测模型有干扰作用。 波数范围由6862 301 cm-1一直缩减为7371 787 cm-1时, TFA定量预测模型的性能均有不同程度地提高, 而波数范围由7371 787 cm-1缩减为8011 787 cm-1时, TFA定量预测模型的性能下降, 表明缩减的波数范围含有对TFA有用的光谱信号。 因此, 确定7371 787 cm-1波数范围为较优的建模波数范围, 该波数范围共有349个变量。
| 表3 不同波数范围下反式脂肪酸的PLS建模结果 Table 3 PLS results of TFA at different wavenumber ranges |
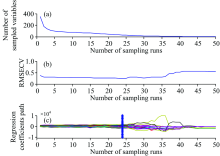
在7371 787 cm-1波数范围内, 利用CARS变量选择方法进一步筛选与TFA相关的重要变量。 图2为TFA的CARS变量选择结果。 由图2(a)可知, 采样次数由1增加到5时, 被选择的变量数迅速下降, 而后随着采样次数的增加,
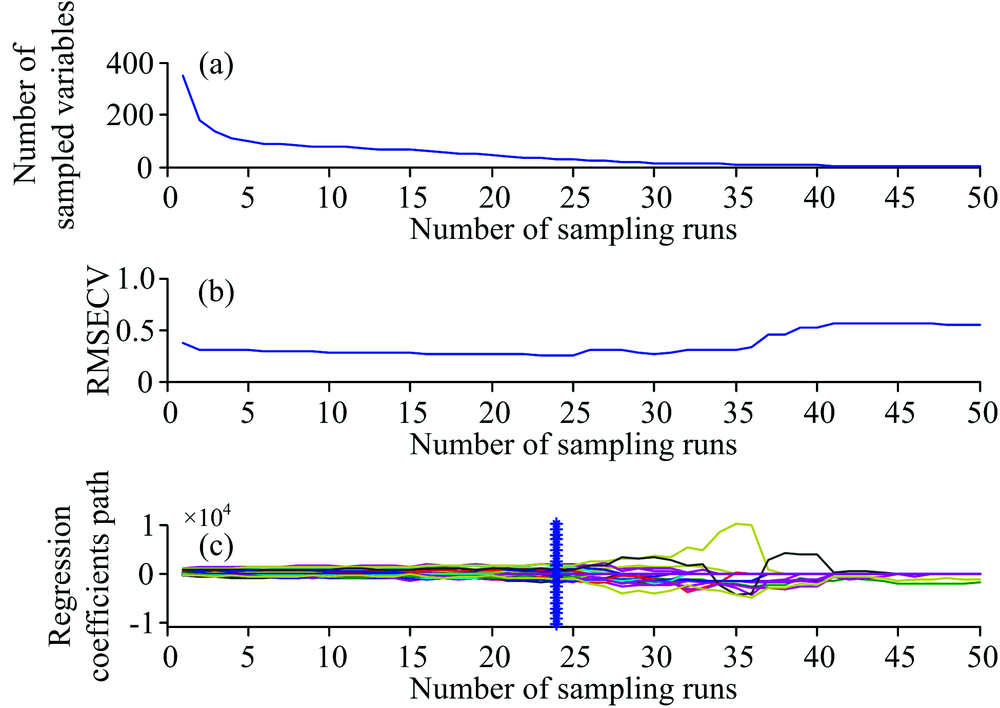 | 图2 反式脂肪酸的CRAS变量选择结果 (a): 被选择的变量数; (b): RMSECV; (c): 回归系数变化趋势Fig.2 Results of CRAS variable selection of TFA (a): Number of selected variables; (b): RMSECV; (c): Trends of regression coefficients |
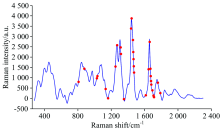
被选择的变量数缓慢下降, 存在变量粗选和精选两个过程。 由图2(b)可知, 采样次数由1增加到2时, RMSECV有较大下降, 而采样次数由2增加到24时, RMSECV逐渐缓慢下降, 并达到最小值, 表明CARS方法正在逐步剔除与TFA含量无关的变量; 而后, 随着采样次数的再增加, RMSECV上下波动, 但总体呈上升趋势, 表明有与TFA含量相关的有用变量被剔除。 图2(c)为被选择变量的回归系数变化趋势, “ * ” 对应的位置为24次采样, 此时RMSECV达到最小值。 根据RMSECV最小原则, 最终共选中31个变量。 图3为由CARS方法选择的变量的分布情况。 由图3可知, 被选择的变量主要分布在1 265, 1 303, 1 442及1 658 cm-1拉曼振动峰附近, 974 cm-1拉曼振动峰虽未被选中, 但其谱峰两侧均有变量被选中。
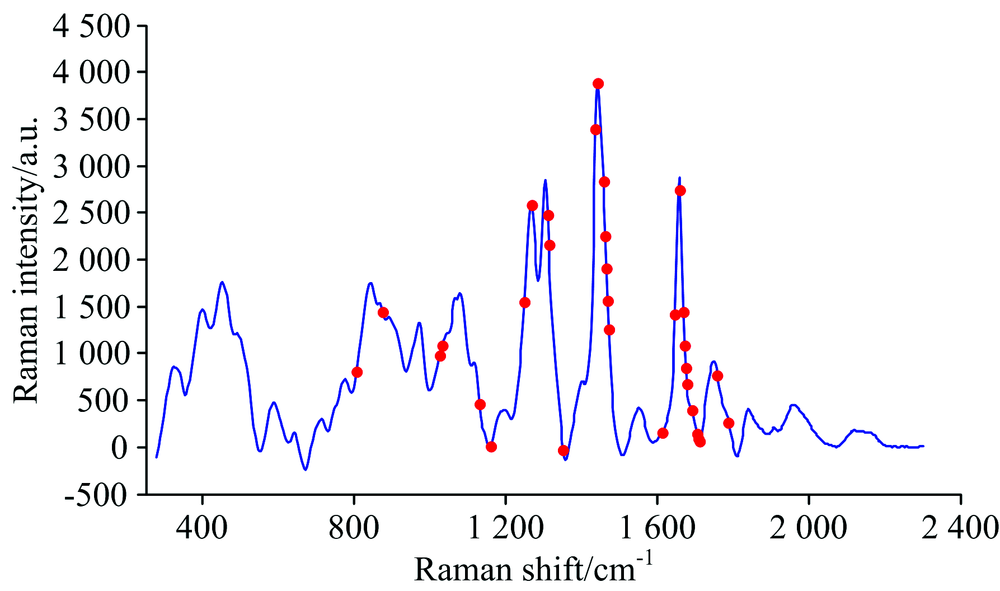 | 图3 CARS方法选择的变量的分布情况Fig.3 Distribution of variables selected by CARS method |
对CARS方法选择的31个变量, 应用PLS方法建立食用植物油中TFA含量的定量预测模型, 并与常用的UVE及SPA方法的结果进行比较。 表4为不同变量选择方法下TFA的PLS建模结果。 由表4可知, 3种变量选择方法中, CARS方法的结果最优, SPA方法次之, 而UVE方法则最差。 由表3和表4可知, 经CRAS变量选择后, TFA的定量预测模型性能有较大提高, 校正集和预测集的相关系数分别由0.932, 0.934上升为0.949, 0.953, RMSEC及RMSEP则分别由0.216%, 0.232%下降为0.188%, 0.191%, 且建模所用的变量数由349个下降为31个, 表明CARS方法能有效筛选TFA的拉曼特征变量。
此外, 由表2、 表3及表4可知, 经归一化处理、 波段初选及CARS变量选择后, 对于TFA定量预测模型, 其校正集和预测集的相关系数分别由0.868, 0.816上升为0.949, 0.953, RMSEC及RMSEP则分别由0.296%, 0.361%下降为0.188%, 0.191%, 且建模所用的变量数由683个下降为31个, 仅占原变量数的4.54%, 有效提高了定量预测模型的预测精度和稳定性。
| 表4 不同变量选择方法下反式脂肪酸的PLS建模结果 Table 4 PLS results of TFA at different variable selection methods |
利用激光拉曼光谱技术对食用植物油中的TFA含量进行定量检测, 采用CARS方法筛选有用变量, 并应用PLS方法建立TFA含量的定量预测模型。 研究结果表明, 激光拉曼光谱技术检测食用植物油中的TFA含量是可行的, 归一化处理、 波段初选及CARS方法均有效提高了TFA预测模型的预测精度和稳定性; 与未优化的模型相比, 其校正集和预测集的相关系数分别由0.868, 0.816上升为0.949, 0.953, RMSEC及RMSEP则分别由0.296%, 0.361%下降为0.188%, 0.191%, 且建模所用的变量数由683个下降为31个, 仅占原变量数的4.54%。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|