


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
深度卷积网络的多品种多厂商药品近红外光谱分类
[李灵巧1, 2  , 潘细朋
, 潘细朋1 , 冯艳春3, * , 尹利辉3 , 胡昌勤3 , 杨辉华1, 2, * ]
, 潘细朋, 冯艳春, 尹利辉]
|
|


作者简介: 李灵巧, 1986年生, 北京邮电大学自动化学院博士研究生 e-mail: 54pe@163.com;潘细朋, 1985年生, 北京邮电大学自动化学院博士研究生 e-mail: pxp201@bupt.edu.cn;
李灵巧, 潘细朋: 并列第一作者
近红外光谱(NIR)分析具有分析高效、 样品无损、 环境无污染以及可现场检测等优点, 特别适合药品的快速建模分析。 但NIR存在吸收强度弱以及谱带重叠等缺点, 需要建立稳健可靠的化学计量学模型对其进行分析。 深度卷积神经网络是深度学习方法中一个重要分支, 它通过逐层抽取数据特征并进行组合、 转换, 形成更高层的语义特征, 具有极强的建模能力, 广泛应用于计算机视觉、 语音识别等领域, 而在药品NIR分析方面尚未见报道。 基于深度卷积网络模型, 对药品NIR多分类建模进行研究。针对药品NIR数据的特点,设计若干个面向多品种、多厂商药品NIR分类的一维深度卷积网络模型。模型中卷积层和池化层交叠排列用于逐层抽取NIR数据特征,输出层连接softmax分类器,对药品NIR数据进行分类概率预测。在输出层之前采用全局最大池化层, 将特征图进行整体池化, 形成一个特征点, 用于解决全连接层存在的限制输入维度大小, 参数过多的问题。 同时, 在网络模型中引入批处理操作和dropout机制, 以防止梯度消失和减小网络过拟合的风险。 在网络模型的设计过程中, 通过设计不同的卷积网络层数以及不同的卷积核尺寸大小, 分析其对建模效果的影响, 同时分析五种经典数据预处理方法对NIR分析的影响。 以我国7个厂商生产的头孢克肟片和11个厂商生产的苯妥英钠片样本NIR为实验对象, 建立药品的多品种、 多厂商分类模型, 该模型在二分类、 多分类实验中取得了良好的分类效果。 在十八分类实验中, 当训练集与测试集比例为7:3时, 分类准确率为99.37±0.45, 比SVM, BP, AE和ELM算法取得更优的分类性能。 同时, 深度卷积神经网络模型推理速度较快, 优于SVM和ELM算法, 但训练速度慢于二者。 大量实验结果表明, 深度卷积神经网络可对多品种、 多厂商药品NIR数据准确、 可靠地判别分类, 且模型具有良好的鲁棒性和可扩展性。 该方法也可推广到烟草、 石化等其他领域的NIR数据分类应用中。
As near infrared spectroscopy (NIR) has many advantages, such as high efficiency, being non-destructive and environment-friendly and on-site detection, it is especially suitable for rapid modeling and analysis of drugs. However, there are some shortcomings such as weak absorption intensity and overlapping bands. It is necessary to establish a robust and reliable chemometrics model to analyze NIR. Deep convolution neural network (DCNN) is an important branch of deep learning method, which extracts data features layer by layer, combines and transforms them to form higher-level semantic features. It is widely used in computer vision, speech recognition and other fields, and has achieved great success, but has not been reported in drug NIR analysis yet. Based on the deep convolution network model, this paper studies the multi-class modeling of drug NIR. According to the characteristics of drug NIR data, several one-dimensional deep convolution network models for multi-class and multi-manufacturer drug NIR classification are designed. The overlapping arrangement of convolution layer and pool layer in the model is employed to extract NIR data features layer by layer, and the output layer is connected with the softmax classifier to predict the classification probability of NIR data. Before the output layer, the global maximum pooling layer is used to solve the problem of restricting the size of input dimension and too many parameters in the full connection layer. At the same time, batch normalization and dropout are introduced in the network model to prevent the gradient vanishing and reduce the risk of network overfitting. The impact on the modeling effect with different convolutional network layers and different convolution kernel sizes is analyzed. At the same time, the influence of five classical data preprocessing methods is explored. Taking NIR samples of cefixime and phenytoin tablets as experimental datasets, a multi-class and multi-manufacturer classification model of drugs is established. The model achieved good classification results in the experiments of binary-classification and multi-classification. In eighteen classification experiments, when the ratio between training set and test set was 7:3, the classification accuracy was 99.37±0.45, which achieved better classification performance than SVM, BP, AE and ELM. At the same time, inference speed of deep convolution neural network was faster than SVM and ELM, but training speed was slower than both. A large number of experimental results showed that the deep convolutional neural network can accurately and reliably distinguish the NIR data of multi-class and multi-manufacturer drugs, with good robustness and scalability. The proposed method can also be extended to the application of NIR data classification in tobacco, petrochemical and other fields.
由于原材料, 生产工艺以及包装形式等的差别, 不同厂商生产的同一种药品的品质也有一定的差异。 对这些差异性的鉴别在药品的监管过程中具有重要意义。 近红外光谱(near infrared spectroscopy, NIR)分析具有高效、 稳定、 无损、 无污染等优点, 已广泛应用于食品、 制药以及医疗等领域[1, 2, 3, 4]。 近红外光谱分析结合化学计量学方法已广泛应用于药品的快速、 无损建模分析。 Deconinck等[5]使用决策树对Viagra和Cialis两种药品的近红外光谱进行了鉴别, 但该方法尚未对多分类问题进行研究。 张卫东等[6]融合堆栈稀疏自编码和核极限学习机各自的优势, 提出SSAE-KELM模型, 对四个厂商生产的铝塑和非铝塑包装形式的头孢克肟片近红外光谱进行分类研究, 取得良好的效果, 但仅报道了单个药品分类研究结果。 Yang等[7]结合Dropout和深度信念网络构建Dropout-DBN分类器, 对琥乙红霉素药品近红外光谱进行鉴别, 有效缓解了由于训练数据少导致模型过拟合现象, 实验结果表明深度学习方法适合相对较小样本规模的近红外光谱数据分析。 然而, 随着制药厂商以及药品品种的增加, 药品光谱数据进一步积累, 设计面向多品种、 多厂商并且可扩展性良好的分类模型显得尤为重要。
深度卷积神经网络(convolutional neural network, CNN)具有极强的建模能力, 广泛应用于多分类和大规模数据的计算机视觉和语音识别等领域并取得了巨大成功[8, 9, 10]。 同时, 由于其深层的网络结构和非线性激活能力, 深度卷积网络应用到近红外光谱的建模分析已有些报道[11, 12]。 鲁梦瑶等[11]提出一种改进的LeNet-5卷积神经网络模型, 对烟叶样本的近红外光谱进行分类实验研究, 获得良好的分类性能。 该方法本质上是将一维光谱数据转换成二维的矩阵, 以适应现有的CNN模型。 Acquarelli等[12]设计一个含一层卷积的CNN模型, 并用于振动光谱数据分析的分类、 分析, 但由于采用浅层CNN模型, 面向大规模的光谱数据分类准确率有待提高。
尽管CNN网络在图像分类、 语音识别等领域取得了突破性的进展, 但在NIR分析方面的应用却比较少。 其主要原因有以下两点: (1)近红外光谱数据本质上是一维向量(矩阵), 不大适合套用现有的二维CNN模型; (2)相比图像数据, 光谱数据的获取困难的多, 光谱样本量通常较小, 经典的化学计量学方法可满足应用要求。 但随着数据的积累, 光谱类别数大幅增加, 经典的分类方法无法满足高精度光谱数据鉴别的要求。 基于上述分析, 本文采用一维CNN模型用于多品种、 多厂商的药品近红外光谱分类研究。 核心贡献为: (1)将CNN模型引入药品NIR光谱鉴别领域; (2)基于一维CNN, 设计若干个端到端的NIR光谱分类模型, 适用于大规模、 多品种、 多厂商的药品鉴别场景; (3)本方法性能良好, 分类准确率超过或比肩多个现有的最佳方法, 同时具有良好的鲁棒性和可扩展性, 适合其他领域的NIR光谱数据分析。
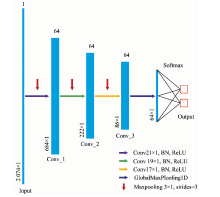
针对NIR光谱数据的特性, 设计了多个一维的CNN网络模型, 并进行比较研究, 具体在第1.2节将详细介绍和讨论, 本节以其中的一个CNN网络为例进行介绍。 网络主要分为输入层、 卷积层、 池化层、 全局最大池化层、 输出层, 示意图如图1所示。 图1中含三个卷积层, 卷积核大小分别为21, 19和17。 卷积核的权值采用Xavier正态分布初始化。 卷积后进行批处理化(batch normalization, BN)操作, BN操作将每个batch上前一层的激活值重新标准化, 将原本减小的激活值放大, 防止梯度消失。 池化层紧接在每个卷积层的后边, 它起到减小输出大小, 降低过拟合的作用。 该网络采用pool_size=3, strides=3的池化操作。 全局最大池化层的思想是将最后一层的特征图进行整体池化, 形成一个特征点, 主要是用来解决全连接层存在的限制输入维度大小, 参数过多的问题。 输出层的神经元个数为药品的类别数, 通过连接softmax分类器, 对药品NIR数据进行分类概率预测。 softmax公式为
其中1{yi=j}为示性函数, 当yi=j时, 1{yi=j}=1, 否则1{yi=j}=0。 N是光谱样本数, k是光谱样本类别数。 θ 表示softmax分类器参数。
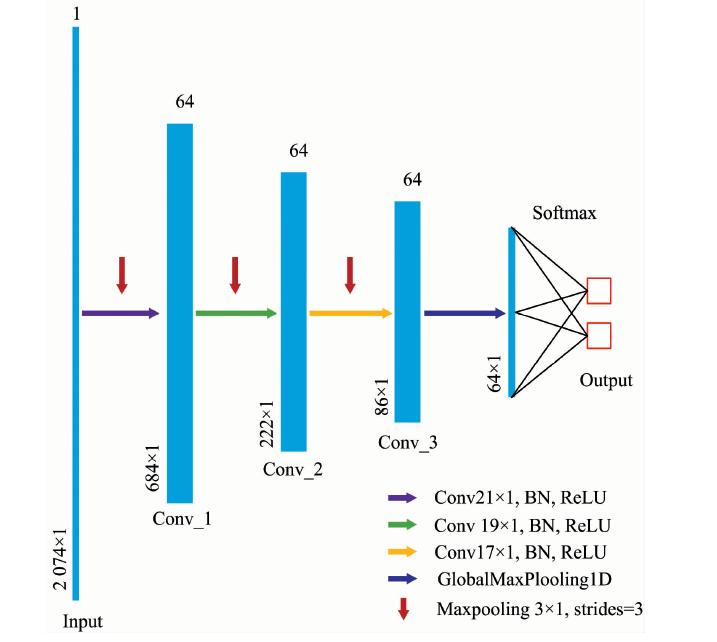 | 图1 一维CNN模型示意图Fig.1 The structure of one-dimensional CNN |
为减小网络过拟合的风险, 在网络的每个卷积层后引入dropout机制[13]。 为了公平对比, BP模型和AE算法与本文设计的CNN网络模型采用同样的dropout值。
为了探究卷积核大小以及网络层数对药品NIR分类性能的影响, 设计了7种具有不同深度和不同卷积核大小的卷积神经网络模型, 分别为3种大卷积核的网络, 以及4种小卷积核的网络, 取名CNN-1— CNN-7。 为节约篇幅, 从大卷积核和小卷积核神经网络中选取CNN-1和CNN-4为代表进行说明, 详见表1和表2。 其中, 药品NIR光谱数据维度为2074; 以七分类为例, 其输出层神经元个数为7。
| 表2 CNN-4网络的各项参数 Table 2 The parameters of CNN-4 |
CNN-1模型含有两个卷积层, 卷积核大小分别为21和19。 卷积层后紧接着BN层以及最大池化层。 第二个最大池化层后连接全局最大池化层, 最后是输出层。 第一个卷积层采用64个尺寸为21的卷积核, 在一维光谱上移动的步长为1, 生成64层特征映射图, 需要训练的参数为1 408个。 第二个卷积层采用64个尺寸为19的卷积核, 生成64层特征映射图, 需要训练的参数为77 888个。 经全局最大池化层后神经元个数为64, 经全连接输出, 输出为7分类, 该层的参数为455个。 加上2个BN层的参数, CNN-1模型总共含有80 263个参数。 CNN-2与CNN-1网络类似, 比CNN-1多一个卷积层、 BN层以及最大池化层组合。 CNN-3比CNN-2同样多一个卷积层、 BN层以及最大池化层组合。
CNN-4— CNN-7模型是小卷积核网络, 卷积核大小都为3, 但所含卷积层数不同。 CNN-4模型与CNN-1模型结构类似, 只是卷积核大小不同。 CNN-5与CNN-2模型结构类似, 唯一区别是将卷积核的大小都变成3。 CNN-6与CNN-7在CNN-5的基础上逐一增加一个卷积核、 BN层以及最大池化层组合。
整个CNN网络模型使用Adam优化器进行训练, Adam优化器由Kingma和Ba两位学者于2014年底提出, 结合AdaGrad和RMSProp两种优化算法的优点, 计算高效, 收敛速度较快。 模型训练过程中, 使用回调函数来观察网络内部的状态和统计信息。 在验证集损失在一定的周期n(e.g., n=10)内不下降的情况下, 对学习率乘以系数lambda(e.g., lambda=0.2)达到减小学习率的目的。 如验证集损失相比上一个训练周期没有下降, 则经过patience(e.g., patience=50)个周期后停止训练, 以防止过拟合。
对比实验方法有支持向量机(support vector machines, SVM), 反向传播算法(back propagation, BP), 自编码器(autoencoder, AE)以及极限学习机(extreme learning machines, ELM), 几种方法简要介绍如下。
(1)SVM的参数C设置为1.0, gamma设置为0.001, 其他参数使用python机器学习库sklearn的默认值。 多分类实验时, 采用one-against-all策略来构造多类SVM分类器。
(2)BP算法与CNN模型一致, 也采用三层网络结构。 BP网络结构为: 2074-500-100-20-num_class(num_class为分类类别数)。
(3)AE模型也采用三层网络结构, AE编码网络结构为: 2074-500-100-20-num_class, 解码网络结构为: num_class-20-100-500-2074。 训练自编码模型时, 损失函数采用均方误差损失, 使用Adam作为优化器; 当无监督预训练结束后, 进行有监督分类训练。
(4)ELM的网络结构为2074-800-num_class。 实验表明, ELM网络隐藏层神经元个数设置为800, 模型取得较好的性能。
实验数据为中国食品药品检定研究院采集的非铝塑包装头孢克肟片和苯妥英钠片两种药品的NIR数据。 数据通过Bruker Matrix光谱仪测得, 每条NIR数据的波长范围是4 000~11 995 cm-1, 间隔4 cm-1, 有2 074个吸光度值。 NIR样品信息如表3和表4所示。 7个厂商生产的头孢克肟片样本NIR光谱如图2所示。 图3为11个不同的制药厂商生产的苯妥英钠片光谱。 从图2和图3中可以看出, 不同厂商的同种药品光谱图非常相似, 部分谱段甚至重叠, 这对分类算法带来较大挑战。
| 表3 头孢克肟片NIR数据 Table 3 NIR data of cefixime tablets |
| 表4 苯妥英钠片NIR数据 Table 4 NIR data of phenytoin tablets |
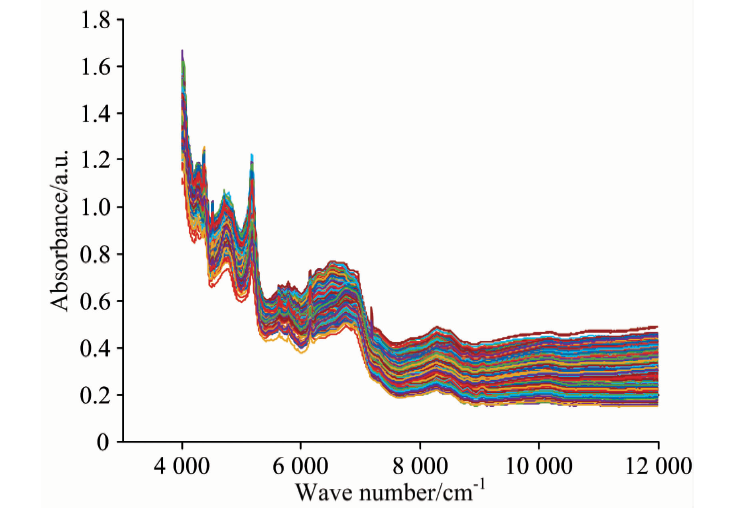 | 图2 7个制药厂商头孢克肟片光谱曲线图Fig.2 NIR of cefixime tablets from seven pharmaceutical manufacturers |
 | 图3 11个制药厂商苯妥英钠片光谱曲线图Fig.3 NIR of phenytoin tablets from eleven pharmaceutical manufacturers |
采用均值中心化、 标准化、 标准正态变量变换、 Savitzky-Golay(SG)平滑求导以及多元散射校正5种经典方法对NIR光谱进行预处理。 以7个制药厂商生产的头孢克肟片光谱为例, 分析5种光谱数据预处理方法的效果。 从图4可以看出, 均值中心化方法可以使光谱之间的差异性增大, 标准化方法能有效克服光谱数据中存在的噪声点和异常值, SG算法对NIR光谱曲线进行平滑, 可有效消除光谱中噪声。
 | 图4 光谱原图与5种方法预处理后光谱曲线图Fig.4 The original NIR and the NIR preprocessed by five methods |
对每一个光谱预处理方法处理后的数据进行分类实验, 选取性能最佳的预处理方法, 实验结果详见表5。 表5中, ratio表示训练集占总数据的比率, acc_raw, acc_cen, acc_auto, acc_snv, acc_savg和acc_msc分别代表NIR数据未经预处理以及经过上述5种预处理测试集的分类准确率。 随机重复5次实验取均值和标准差作为实验结果, 实验中迭代周期设为100。 从表5的实验结果可以看出, 相比原始光谱实验结果, 均值中心化、 标准化、 标准正态变量变换后的分类准确率有较大的提高, 经过标准化后的光谱数据在大多数情况下取得最佳分类结果。 因此, 后续的分类实验中选取标准化为预处理方法。
| 表5 不同预处理NIR数据在CNN-2模型的分类性能 Table 5 Classification performance of NIR data with different preprocessing methods in CNN-2 model |
以7个厂商头孢克肟片未经预处理的NIR数据为例, 通过对每一个CNN模型重复多次(5次)实验, 计算光谱数据分类准确率, 选取性能最优的模型, 用于光谱数据分类实验, 实验结果如表6所示。
| 表6 七种CNN模型的分类性能对比 Table 6 Comparison of classification performance of seven CNN models |
表6中, ratio的含义与表5一致。 acc_cnn1— acc_cnn7分别代表上述七种CNN网络模型在测试集上的分类准确率。 从表6中可以看出, CNN-1— CNN-3这3个模型获得较优的分类性能, 而CNN-4— CNN-7这4个模型性能较差。 主要原因是CNN-4— CNN-7模型采用小的卷积核, 难以捕获光谱曲线有区分度的模式特征, 而CNN-1— CNN-3中的卷积核尺寸较大, 在光谱曲线上滑动时跨度较大, 能有效提取连续变化分辨率高的光谱曲线的模式特征。 同时, 我们观察到CNN-2比CNN-1和CNN-3整体性能更优。 CNN-1— CNN-3分别包含2~4个卷积层。 对于样本量较小的光谱数据, 采用层数过多的模型, 容易出现过拟合, 但浅层网络建模能力较弱, 综合考虑, 采用CNN-2模型进行后续实验研究。
实验代码采用python2.7编写, 硬件环境GPU型号为NVIDIA Tesla P100。 在二分类和多分类光谱数据上进行实验, 并与当前最佳NIR光谱分类算法, 如SVM, BP, AE以及ELM进行比较。
本工作的实验设置思路为: 首先在头孢克肟片NIR数据上分别进行二分类和七分类实验, 然后结合苯妥英钠片NIR数据进行多药品多厂商的十八分类实验。
参照文献[6]的实验数据设置进行二分类实验。 实验样本设置为: 取表3中江苏正大生产的头孢克肟片NIR样本共63个, 作为负类样本集; 取湖南方盛、 山东鲁抗和山东罗欣三个厂商生产的头孢克肟片NIR样本共153个, 作为正类样本集。 两组数据的实验结果如表7所示。 二分类实验由于分类性能都较好, 不能体现本文设计的CNN模型的优越性。
| 表7 二分类实验不同方法分类准确率 Table 7 Classification accuracy of different methods in binary classification experiment |
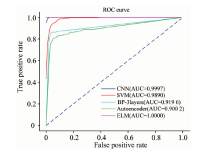
(1)七分类实验。 表3中7个厂商生产的头孢克肟片NIR样本分别作为不同的类, 计7类。 实验结果如表8所示, CNN在ratio=0.7, 0.6时, 相比其他方法, 获得最高分类准确率; ELM算法在ratio较小时, 获得最佳性能, 但在这些情况下, CNN与ELM性能相近。 相同条件下, CNN比SVM高1~3个点, 比BP高1~2.8个点, 比AE高4~21个点。 图5为七分类ratio=0.7时, 迭代周期为100的ROC曲线, 从图中可以看出, ELM方法的AUC值为1, CNN的AUC值为0.9997, 接近1, 说明两个方法取得非常好的分类性能。 SVM, BP和AE方法的AUC值也大于0.9, 表明分类性能也不错。 该结论从表8中也可以得到佐证。
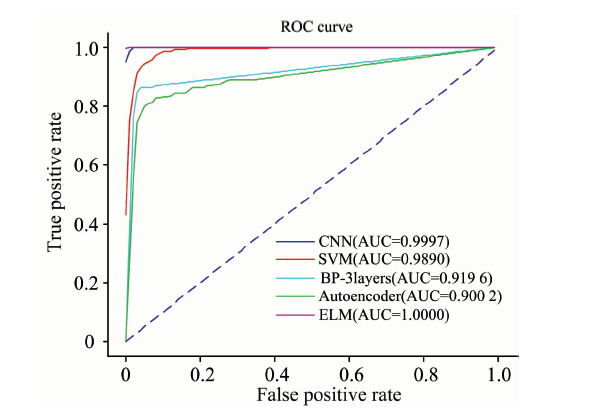 | 图5 ratio=0.7时七分类实验ROC曲线Fig.5 ROC curve of seven classification experiment when ratio is 0.7 |
| 表8 七分类实验不同方法分类准确率 Table 8 Classification accuracy of different methods in seven classification experiments |
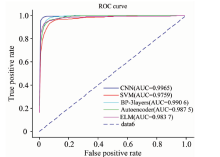
(2)十八分类实验。 取表3中7个厂商生产的头孢克肟片光谱样本以及表4中11个不同厂商生产的苯妥英钠片NIR数据分别作为不同的类, 共18类。 实验结果如表9、 表10所示。 表9是十八分类实验不同方法分类准确率, 环比二分类和七分类实验结果, CNN方法在十八分类实验中仍然获得了非常好的性能, 但其他方法性能下降幅度较大, 尤其是SVM和ELM, 体现了CNN方法对于多药品、 多厂商分类的优越性。 实验中采用one-against-all策略构造多类SVM分类器, 由于算法策略带来的样本不平衡问题, 导致分类准确率一定程度的降低。 ELM模型在隐藏层的权重和偏置被随机确定后, 隐藏层的输出矩阵H就被唯一确定。 训练单隐层神经网络可以转化为求解一个线性方程Hβ =T, 并且输出权重β 可以被确定为
| 表9 十八分类实验不同方法分类准确率 Table 9 Classification accuracy of different methods in eighteen classification experiment |
| 表1 0 十八分类实验不同方法训练时间和推理时间(单位: 秒) Table 1 0 Training and inference time of different methods in eighteen classification experiments (unit: s) |
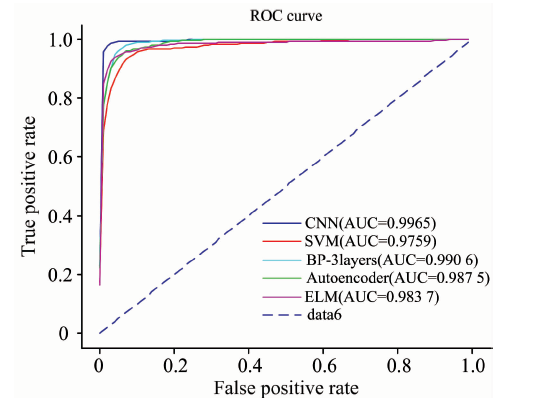 | 图6 ratio=0.2时十八分类ROC曲线Fig.6 ROC curve of eighteen classification experiment when ratiois 0.2 |
设计了几种简单但非常有效的一维深度卷积网络模型, 用于药品的NIR鉴别分析, 并对卷积网络层数以及卷积核尺寸对建模结果的影响进行详细实验研究, 同时分析五种经典预处理方法对药品NIR数据分析的影响。 与当前最佳方法, 比如: SVM, BP, AE, ELM算法进行对比, 在大规模, 多药品、 多厂商NIR鉴别实验中取得了更高的分类准确率和良好的可扩展性。 一维深度卷积网络模型推理阶段速度较快, 优于SVM和ELM算法, 但训练速度慢于二者。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|