
{kind=link}
{kind=link}
近红外光谱结合化学计量学的常见中国蜂蜜掺杂糖浆鉴别
[黄富荣1  , 宋晗
, 宋晗1 , 郭鎏1 , 杨心浩1 , 李立群2 , 赵红霞2, * , 杨懋勋3, * ]
, 宋晗, 杨懋勋]
|
|


作者简介: 黄富荣, 1979年生, 暨南大学理工学院光电工程系副研究员 e-mail: furong_huang@163.com
目前我国蜂蜜市场掺假现象严重, 研究一种快速、 准确的方法用于市场流通领域掺假蜂蜜的鉴别具有重要的现实意义。 采用近红外光谱(NIR)结合化学计量学方法对常见的天然蜂蜜以及掺假(掺杂常见糖浆)蜂蜜进行建模识别, 并比较偏最小二乘-判别分析(PLS-DA)及支持向量机(SVM)对糖浆掺假蜂蜜鉴别模型的影响。 首先, 采集来自中国10个省份、 20种常见蜂蜜的112个天然纯蜂蜜样品, 以及6种常见糖浆样品按不同糖浆含量(10%, 20%, 30%, 40%, 50%, 60%)配制的112个掺假蜂蜜样品, 共计224个样品; 通过近红外光仪器扫描获得所有样品的近红外光谱数据(波长范围400~2 500 nm); 然后, 分别采用一阶导数(FD)、 二阶导数(SD)、 多元散射校正(MSC)、 标准正态变化(SNVT)四种方式对原始光谱进行预处理; 再结合PLS-DA和SVM建立天然蜂蜜和糖浆掺假蜂蜜的鉴别模型, 比较不同预处理方法对两种不同建模算法建立的蜂蜜掺假鉴别模型效果。 其中SVM算法的惩罚参数 c和核函数参数 g通过网格搜索法(GS)、 遗传算法(GA)、 粒子群算法(PSO)三种寻优算法进行优化。 分析结果表明: 光谱数据进行预处理后所建立的模型准确率均有明显提升, 而对于SVM模型, 惩罚参数 c和核函数参数 g对模型准确率的提升效果要比光谱预处理带来的提升效果更明显。 在PLS-DA算法中, 经FD光谱预处理后建立的模型效果最好, 最佳PLS-DA模型准确率为87.50%; 在SVM算法中, 经MSC预处理后, 再通过GS寻优, 获得惩罚参数 c为3.0314, 核函数参数 g为0.3298的条件下所建立的模型效果最好, 最佳SVM模型准确率为94.64%。 由此可见, 非线性的SVM算法结合NIR光谱数据所建立的天然蜂蜜与糖浆掺假蜂蜜鉴别模型要优于线性的PLS-DA模型, 同时表明NIR光谱结合化学计量学方法对常见糖浆掺杂的中国蜂蜜鉴别是可行的。
To find a fast, accurate, and effective method for the identification of honey adulteration, near-infrared spectroscopy combined with chemometrics was used to analyze natural honey and adulterated honey in this paper. First, 224 samples were collected for the study, including 112 natural pure honey samples from 20 common honeys in China, and 112 adulterated honey sample were prepared with 6 different syrup samples according to different syrup contents(10%, 20%, 30%, 40%, 50%, or 60%). Near infrared spectral data (wavelength range of 400~2 500 nm) of all samples were obtained by near infrared light instrument scanning. Then, first derivative (FD), second derivative (SD), multiple scattering correction (MSC), and standard normal variation (SNVT) pre-processing of the original spectra combined with PLS-DA (linear algorithm) and SVM (non-linear algorithm) modeling, respectively, were adopted to establish a differential model of natural honey and syrup-adulterated honey and compare the effects of different pretreatment methods on the honey adulteration identification model established by the two different modeling algorithms. The penalty parameter c and the kernel function parameter g of the SVM algorithm were optimized by three optimization algorithms: grid search, genetic algorithm, and particle swarm optimization. The analysis results showed that the PLS-DA model established by the FD preprocessing had the best effect, and the accuracy of the best PLS-DA model was 87.50%. After MSC pre-processing, the SVM model with the penalty parameter c of 3.031 4 and the kernel function parameter g of 0.329 8 was the best. The accuracy of the best SVM model was 94.64%. It can be seen that the non-linear SVM algorithm combined with the NIR spectral data natural honey and syrup-adulterated honey identification model is better than the PLS-DA model.
蜂蜜是一种富有营养的天然食品, 深受广大消费者的青睐。 我国自20世纪90年代以来一直是世界第一养蜂大国、 蜂蜜第一出口大国。 然而, 近年由于我国蜂蜜掺假的现象日益猖獗, 严重影响我国蜂蜜声誉及市场竞争力, 出口量大幅减少。 为确保蜂蜜的质量, 加强蜂蜜产品的检测显得尤为重要。 目前市场上最常见的蜂蜜掺假方式是糖浆掺假, 在蜂蜜中掺入果葡糖浆、 玉米糖浆等食用糖浆。 现有的糖浆掺假蜂蜜鉴别方法包括: 酶活性法、 色谱法、 差热分析法、 稳定性碳同位素比值分析法[1, 2, 3, 4]等。 其中稳定性碳同位素比值分析法是多年来检测蜂蜜糖浆掺假的标准分析技术, 但该方法只能检测掺入C4糖浆(玉米糖浆、 蔗糖糖浆、 果葡糖浆、 麦芽糖浆等)的掺假蜂蜜, 对于掺入C3糖浆(大米糖浆、 甜菜糖浆等)的掺假蜂蜜无法有效鉴别[5]。 同时上述这些检测方法均存在耗时长、 有破坏性、 仪器昂贵、 操作复杂、 需要专业技术人员等缺点, 无法实现现场快速检测。 因而, 寻找一种快速、 准确的掺假蜂蜜鉴别方法具有重要应用价值。
基于近红外光谱(NIR)检测方法具有快速、 无损、 绿色环保以及操作简单等优点, 近年国内外已开展大量的基于近红外光谱结合化学计量方法鉴别蜂蜜的研究[6, 7, 8]。 2011年, Chen等[9]利用NIR光谱对高果糖玉米糖浆掺杂的中国蜂蜜进行鉴别分析。 2015年, 张妍楠等[10]将NIR光谱与化学计量学结合, 快速、 高效的识别出掺入大米糖浆的洋槐蜂蜜。 2016年, Bazar等[11]利用光纤浸没探针记录了4种不同地区刺槐蜂蜜和高果糖玉米糖浆掺假蜂蜜的NIR光谱, 结合水光谱组学发现天然蜂蜜比工业糖浆含有更多高组织度的水分子结构。
以上研究均表明了利用NIR分析鉴别掺杂糖浆蜂蜜是可行的, 然而, 目前NIR光谱对蜂蜜掺假研究仍然处于方法学研究阶段, 采用的样品过于单一, 多是单一蜜种的蜂蜜掺入单一糖浆, 或者单一蜜种蜂蜜掺入多种糖浆和多蜜种蜂蜜掺入单一糖浆, 然而蜂蜜市场的掺假蜂蜜多种多样, 存在着多种糖浆与多蜜种混掺的情况, 目前建立的蜂蜜鉴别模型的泛化能力较差, 尚未能在蜂蜜市场中得到推广应用。
为此, 收集了来自中国的常见天然蜂蜜样品, 以及常见蜂蜜掺假的糖浆样品, 配制成较为齐全的天然蜂蜜和糖浆掺假蜂蜜样品, 采集样品的近红外光谱, 结合化学计量学方法, 以期建立一个具有较强的普适性蜂蜜掺假鉴别模型, 用于市场流通环节的蜂蜜鉴别。
1.1.1 蜂蜜及糖浆样品
112个天然蜂蜜样品由广东省生物资源应用研究所提供, 均取自各地的养蜂场以确保未加入任何物质。 为了使掺假蜂蜜鉴别具有普适性, 在蜂蜜选取方面, 选择20种不同蜜种的蜂蜜, 包括有乌桕蜜、 冬蜜、 半枫荷蜜、 山杏蜜、 枸杞蜜、 桔梗蜜、 枇杷蜜、 夏枯草蜜、 北芪蜜、 五味子蜜、 火炭母蜜、 益母草蜜、 银条蜜、 洋槐蜜、 椴树蜜、 桂花蜜、 龙眼蜜、 荔枝蜜、 荆条蜜、 红花蜜。 产地源自全国10个省份, 包括有广东、 广西、 湖南、 湖北、 云南、 甘肃、 黑龙江、 福建、 安徽、 江苏, 蜂蜜样品的具体信息见表1。 糖浆样品购自当地超市, 包括2种C3植物糖浆(甜菜糖浆和大米糖浆)以及4种C4植物糖浆(果葡糖浆、 玉米糖浆、 麦芽糖浆和蔗糖糖浆), 共6种常见的蜂蜜掺假糖浆种类。
| 表1 蜂蜜样品种类、 产地及数量 Table 1 Types, origin and numbers of honey samples |
1.1.2 糖浆掺假蜂蜜样品
配制不同掺假度[糖浆和纯蜂蜜的质量比(W/W%)]掺假蜂蜜样品。 其中: 单种糖浆掺假样品60个: 设定6个浓度梯度, 分别为10%, 20%, 30%, 40%, 50%, 60%。 每种糖浆配一个浓度梯度, 每个浓度配制10个不同的糖浆掺假样品, 共配制6× 10共60个单种糖浆掺假样品。 混掺蜂蜜样品52个: 52个掺假度均为60%的糖浆混掺蜂蜜样品。 其中包括2种不同糖浆混掺样品15个, 3种不同糖浆混掺样品20个, 4种不同糖浆混掺样品10个, 5种不同糖浆混掺样品6个及所有6种糖浆的混掺样品1个。
考虑到部分蜂蜜在低于25 ℃时所含的葡萄糖容易结晶而使得内部成分分布不均匀, 从而导致采集的光谱信噪比变低。 因此所有的蜂蜜样品及糖浆掺假样品均先在50 ℃下水浴1 h, 以充分去除结晶物或结晶核, 再在30 ℃下水浴48 h以确保完全去除气泡, 处理完毕后所有样品在试管上填好标签后, 放入试管架中在室温下静置待用。
采用丹麦福斯公司XDS Rapid Content光栅型近红外光谱分析仪及其透射附件, 光谱采集范围为400~2 500 nm, 探测器为Si(400~1 100 nm)、 PbS(1 100~2 500 nm)。
采集掺杂天然蜂蜜样品和糖浆掺杂的蜂蜜样品的光谱, 每隔2 nm采样一次, 获得400~2 500 nm范围的光谱。 所有样品的光谱数据均采集3次取平均, 得到纯天然蜂蜜光谱112条, 糖浆掺杂的蜂蜜样品112条, 共224条光谱。
PLS-DA是最常用的一种线性判别算法。 PLS-DA的基本思想是通过PLS分类技术在特征提取过程中获取样本的分类信息, 然后建立自变量和分类变量之间的回归模型, 进而有效地提取出与分类有关的特征变量, 实现数据的分类识别。 主要步骤如下: 首先对光谱矩阵X和类别向量Y进行正交分解, 得到光谱矩阵和类别向量Y的得分矩阵T和U, 见式(1)和式(2)。 然后对得分矩阵T和U进行线性回归, 求得回归系数B, 如式(3)和式(4)所示。 最后通过式(5)求得未知样品光谱矩阵Xtest的预测类别Ytest。 其中, P和Q分别为光谱矩阵X和类别向量Y的载荷矩阵; E和F分别为光谱矩阵X和类别向量Y的PLS拟合残差矩阵。
SVM算法原理如下: 训练数据集由{(xi, yi), i=1, 2, …, N}表示, 其中xi∈ RD是输入向量, yi∈ {-1, 1}是其对应的期望输出。 SVM可以找到在两类数据之间的最佳超平面(ω * x)+b=0 (ω 表示平面的法向矢量, 而b是从平面到原点的距离)。 对于线性可分的情况, 在分类后的平面将数据分成两类后, 两类数据之间的差值为2/‖ ω ‖ 。 分类器是
对于非线性情况, SVM将低维空间中的数据映射到高维空间。 分类器是
其中sgn{}是符号函数, ai是拉格朗日乘子, xi是训练样本, x是要分类的样本, K(xi× x)是核函数。 选择合适的核函数是建立性能良好的SVM模型最重要的一步, 通常包括两部分工作: 一是选择合适的核函数类型; 二是确定核函数类型后优化重要的参数。 研究表明核函数参数选择高斯核函数(RBF)所建立的模型具有良好的学习能力[12]。 因此本实验使用RBF核函数实现SVM的建模, 其中RBF核函数的两个重要参数为惩罚参数c和核函数参数g, 该两参数对于控制模型的复杂度、 逼近误差及模型的测量精度有重要影响, 因此对该两参数进行优化很有必要。 常用的参数优化算法有网格搜索法(grid search, GS)、 遗传算法(genetic algorithm, GA)和粒子群优化算法(particle swarm optimization, PSO)[13]。
采用Sample Set Partitioning Based on Joint X-Y Distance(SPXY)法[14]将224个蜂蜜及糖浆掺假蜂蜜样品按照3:1划分训练集和预测集。 训练集有168个蜂蜜及糖浆掺假蜂蜜样品, 纯蜂蜜和掺假蜂蜜样品各84个; 预测集有56个蜂蜜及糖浆掺假蜂蜜样品, 纯蜂蜜和掺假蜂蜜样品各28个, 样品集具体划分如表2所示。
| 表2 样品集划分 Table 2 Division of sample sets |
分类模型性能一般由预测集的准确率(accuracy)、 灵敏度(sensitivity)及特异性(specificity)进行评价。 准确率、 特异性和灵敏度越接近于1, 表明模型的分类效果越好。 分类准确率是指在分类模型中, 通过预测集来对已建立的模型进行测试, 统计样品被正确判别的数目占样品总数的比值。 灵敏度和特异性是临床诊断中很重要的两个指标, 灵敏度是指被正样本被正确分类的百分率, 特异性是指负样本被正确分类的百分率。
式中, ncorrect表示预测集数据被模型正确分类的所有样本个数, ntotal表示预测集数据的所有样本个数。 TP表示预测集数据被正确分类的正样本个数, FN表示预测集数据被错误分类的正样本个数, FP表示预测集数据被错分的负样本个数, TN表示预测集数据被模型正确分类的负样本个数。
天然蜂蜜和糖浆掺假蜂蜜样品的NIR原始光谱及平均光谱如图1所示。 图1(a)中可以看出天然蜂蜜和糖浆掺假蜂蜜的NIR光谱峰形基本一致, 但光谱重叠严重, 无法仅凭肉眼将两者区分开。 可以观察到在1 452, 1 771, 1 939, 2 100, 2 276, 2 326和2 437 nm处有明显的特征吸收峰。 其中1 452和1 939 nm是近红外区域水的两大吸收峰, 1 452 nm处归属于O— H伸缩振动的一级倍频, 1 939 nm处归属于O— H伸缩和弯曲振动的组合频; 1 771 nm处归属于C=O的二倍频吸收, 与蜂蜜糖分有关; 2 100 nm处归属于O— H变形振动和C— O伸缩振动; 2 276 nm处归属于C— H伸缩和变形振动的组合频; 2 326 nm处归属于CH2的伸缩和变形带[12]。 从图1(b)的平均光谱图中可以看出在1 939, 2 100和2 276 nm特征峰处两者的平均光谱强度有所差异, 这些差异说明NIR光谱可用于天然蜂蜜和糖浆掺假蜂蜜的鉴别。 下面利用NIR光谱结合化学计量学算法来建立天然蜂蜜和糖浆掺假蜂蜜的高效判别模型。
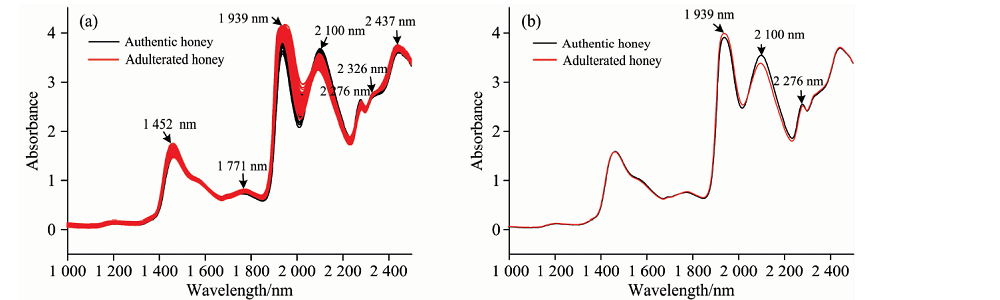 | 图1 天然蜂蜜及糖浆掺假蜂蜜样品的近红外光谱 (a): 原始光谱; (b): 平均光谱Fig.1 NIR spectra of natural honey and syrup adulterated honey samples (a): Original spectrum; (b): Average spectrum |
PLS-DA算法属于有监督学习, 在建立天然蜂蜜和糖浆掺假蜂蜜的PLS-DA判别模型之前, 要给划分好的训练集和预测集人工设定标签。 将天然蜂蜜样品赋值为1, 糖浆掺假蜂蜜样品赋值为-1。 样品赋好类别值后, 再采用FD, SD, MSC以及SNVT四种方法进行光谱预处理。 之后对训练集数据进行K折交互验证(K取5)选出最佳的PLS因子数, 再根据最佳因子数将光谱数据和类别值相关联, 建立糖浆掺假蜂蜜的判别模型。 最后利用预测集数据对建立的模型进行评估, PLS-DA模型预测集的分类结果如表3所示。 原始NIR光谱数据经FD预处理后鉴别天然蜂蜜和糖浆掺假蜂蜜的结果最好, 因此经FD预处理后建立的模型是最佳PLS-DA模型, 最佳PLS因子数为10, 准确率为87.50%, 灵敏度和特异性分别为96.43%和78.57%。
| 表3 PLS-DA模型对糖浆掺假蜂蜜的分类结果 Table 3 Model classification results of syrup adulterated honey by PLS-DA |
分两步建立糖浆掺假蜂蜜的最佳SVM判别模型: (1) 在惩罚参数c和核函数参数g均取默认值的条件下(惩罚参数c的默认值为1, 核函数参数g的默认值为1/k, k是类别数), 选出最佳的预处理方式。 (2) 利用寻优算法(GS, GA和PSO)进行c、 g参数寻优, 将寻得的最佳c、 g参数值建立SVM模型并对预测集进行预测, 选出天然蜂蜜和糖浆掺假蜂蜜的最佳SVM判别模型。
首先利用原始NIR光谱数据及4种不同预处理(FD, SD, MSC, SNVT)后的数据建立SVM判别模型, 比较不同预处理方法建立的SVM模型对预测数据集的预测准确率的高低来选取最佳的预处理方式。 此次建模的惩罚参数c和核函数参数g均取默认值, 不同预处理下的SVM模型分类结果如表4所示。 四种预处理建立的SVM模型准确率相对于原始光谱均有所提高, 但准确率提高的都不显著, 准确率提升最多的预处理方式是MSC, 相比于原始光谱的预测集准确率提高了3.57%。
| 表4 不同预处理下的SVM模型分类结果 Table 4 The classification results of SVM under different pretreatment |
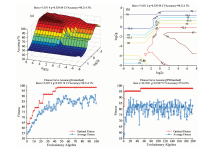
确定最佳预处理方式后, 分别利用GS, GA和PSO对惩罚参数c和核函数参数g进行优化, 参数寻优过程及交互验证结果如图2所示: 图2(a)是GS寻优结果的三维显示, 随着交互验证准确率的提高, 由不同c、 g值交织而成的方格颜色由冷色调(深蓝)向暖色调(明黄)变化, 同时方格各顶点所在水平面相应升高, 当惩罚参数c是3.031 4和核函数参数g是0.3298时, 交互验证准确率达到最高为98.21%; 图2(b)是GS参数寻优结果的等高线图, 由图2(a)投影到二维平面所得。 图2(c)是GA寻优结果图, 由最佳适应度曲线可知, 在迭代次数为0~50时, 交互验证准确率不断提高, 当迭代次数为50时准确率达到饱和为98.21%, 寻得的最佳惩罚参数c是8.057 4、 核函数参数g是0.292 7。 图2(d)是PSO的寻优结果图, 相比于GS和GA, 其交互验证的初始准确率相对较高(82.74%), 在经过55次迭代后交互验证准确率稳定遮97.62%, 寻得的最佳惩罚参数c是38.703 1、 核函数参数g是0.189 7。
 | 图2 SVM模型c、 g参数寻优结果图 (a): GS寻优结果三维显示; (b): GS寻优结果等高线图; (c): GA寻优结果; (d): PSO寻优结果Fig.2 The results of c, g parameter optimization (a): 3D display of GS optimization results; (b): Contour diagram of GS optimization results; (c): GA optimization results; (d): PSO optimization results |
经GS, GA, PSO三种寻优算法优化c、 g参数后的交互验证准确率最低达到了97.62%, 下一步利用寻得的最佳c、 g参数值分别建立SVM模型并用预测集检测模型的好坏以选出最佳SVM模型, 预测集结果如表5所示: 经过c、 g参数寻优后模型准确率均显著提升, 准确率最高达到了94.64%, 灵敏度即对天然蜂蜜的识别准确率均达到了100%, 特异性即对糖浆掺假蜂蜜的识别准确率最佳为89.29%。 相比于默认c、 g值建立的最优SVM模型, 经GS寻优后的准确率提升了12.5%; 经GA寻优后的准确率提升了10.72%; 经PSO寻优后的准确率提升了7.15%。 经GS寻得惩罚参数c=3.031 4, 核函数参数g=0.329 8的条件下, 所建的SVM模型效果最好, 预测集准确率为94.64%、 灵敏度为100%、 特异性为89.29%。
| 表5 参数寻优后SVM模型分类结果 Table 5 Model classification results of SVM by parameter optimization |
开展了近红外光谱结合化学计量学方法分析鉴别天然蜂蜜和糖浆掺假蜂蜜。 实验结果表明: 基于天然蜂蜜和糖浆掺假蜂蜜的NIR光谱数据结合PLS-DA和SVM算法所建立的蜂蜜鉴别模型均可实现对掺假蜂蜜的鉴别, 但由于蜂蜜样品成分复杂, 以及光谱预处理无法完全消除各种噪声所造成的影响, 从而使得光谱数据与蜂蜜中是否掺入糖浆的线性关系受到严重干扰, 因此非线性的SVM算法用于蜂蜜掺假效果更好。 综上所述, 基于NIR光谱数据结合PLS-DA和SVM算法可以实现常见中国蜂蜜糖浆掺假鉴别, 有望为中国蜂蜜市场流通环节提供一种快速、 可靠现场蜂蜜鉴别方法。 但本实验中部分蜂蜜样本数少, 实验结果鲁棒性以及泛化能力将有一定影响, 仍需进一步提高模型的性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|