

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
茶叶傅里叶近红外光谱的混合模糊极大熵聚类分析
[傅海军1, 2  , 周树斌
, 周树斌1, 3 , 武小红1, 2, * , 武斌4 , 孙俊1, 2 , 戴春霞1, 5 ]
, 周树斌, 武斌|
|


作者简介: 傅海军, 1976年生, 江苏大学电气信息工程学院副教授 e-mail: fuhaijun21@ujs.edu.cn
茶作为世界最受欢迎的三大饮料之一, 不仅能够提神醒脑, 而且还有帮助消化和降低血压等作用。 随着人们对茶叶品质要求的日益提高, 需要对不同品种的茶叶实现准确的鉴别分析以防止茶叶市场里茶叶品牌名不副实和以次充好等现象的发生。 为实现对茶叶快速精准的鉴别分析, 设计了一种综合采用傅里叶近红外光谱和新的模糊极大熵聚类(FEC)分析算法的茶叶品种鉴别系统。 传统模糊极大熵聚类分析在聚类含噪声数据时, 聚类结果往往容易出现错误, 即FEC对噪声数据敏感。 为解决这个问题, 在FEC分析算法的基础上引入可能C均值聚类分析(PCM), 提出了一种混合模糊极大熵聚类(MFEC)分析算法。 MFEC可通过迭代计算得到模糊隶属度值, 能实现对含噪声的茶叶傅里叶近红外光谱数据的准确聚类分析。 首先, 使用傅里叶近红外光谱仪(Antaris Ⅱ型)采集岳西翠兰、 六安瓜片、 施集毛峰三种安徽茶叶的傅里叶近红外光谱数据, 光谱波数范围为10 000~4 000 cm-1。 其次, 对采集到的光谱数据使用多元散射校正(MSC)进行预处理, 预处理后先用主成分分析(PCA)将光谱数据维数降至10维, 然后再用线性判别分析(LDA)对降维后的近红外光谱数据进行特征提取。 最后, 通过混合模糊极大熵聚类分析和传统的模糊极大熵聚类分析对三种茶叶的光谱数据进行聚类分析, 并对两种聚类分析算法得到的聚类准确率、 收敛速度等进行对比分析。 实验结果表明: 混合模糊极大熵聚类(MFEC)分析算法与传统的模糊极大熵聚类(FEC)分析算法相比较, 在相同的权重指数 m下MFEC具有更高的聚类准确率。 在 m=2条件下, MFEC的聚类准确率达到了100%, 而传统的模糊极大熵聚类在相同条件下聚类准确率仅为37.98%。 MFEC收敛过程中仅需迭代10次即可达到收敛, 而FEC需要迭代100次, 因此MFEC可以更高效的进行模糊聚类分析, MFEC相比于FEC聚类性能具有明显的优越性。 通过傅里叶近红外光谱技术, 混合模糊极大熵聚类分析结合PCA与LDA算法构建的茶叶品种鉴别系统能够高效快速的完成对岳西翠兰、 六安瓜片、 施集毛峰三种茶叶的准确分类, 为茶叶检测领域提供了一种创新的方法与设计思路, 具有一定的理论价值和良好的市场应用前景。
Tea is one of the three most popular drinks in the world. It can not only refresh the mind, but also help digestion and lower blood pressure. With the increasing advance of requirements of tea quality by people, it is necessary to achieve accurate identification of different varieties of tea to prevent the false tea brands and adulteration in the tea market from happening. In order to identify tea varieties quickly and accurately, a tea variety identification system was designed with a combination of Fourier transform near-infrared spectroscopy (FT-NIR) and a novel fuzzy maximum entropy clustering. When traditional fuzzy maximum entropy clustering (FEC) clusters the data with noise, clustering results are often prone to errors, that is to say, FEC is sensitive to noise. To solve this problem, a mixed fuzzy maximum entropy clustering (MFEC) was proposed by introducing possibilistic c-means (PCM)clustering into traditional FEC. MFEC has fuzzy membership and typicality values by iterative computing, and it can cluster FT-NIR data mixed with noise accurately. Firstly, three kinds of Anhui tea samples (i. e. Yuexi Cuilan, Lu’an Guapian and Shiji Maofeng) were prepared for FT-NIR data collection with Antaris Ⅱ spectrometer in the wave number range of 10 000~4 000 cm-1. Secondly, spectral data were preprocessed by multiple scattering correction (MSC), and then the dimensionality of the data was reduced to 10 by principal component analysis (PCA), and then the discriminant information of the data was extracted by linear discriminant analysis (LDA). Finally, MFEC and FEC were applied to perform clustering analysis on the data, respectively, and they were compared in the clustering accuracy and convergence speed. The results of this study indicated that in the condition of m=2, the clustering accuracy rate of MFEC was 100%, while that of FEC was 37.98%. MFEC achieved convergence after four iterations while FEC converged after 100 iterations. Therefore, MFEC could cluster spectral data more efficiently than FEC, and MFEC had the obvious superiority. Three types of Anhui tea samples could be classified correctly and efficiently by combining FT-NIR technology with PCA, LDA and MFEC. This method provided an innovative method and design idea for the identification analysis in the tea testing field, and it has certain theoretical value and good market application prospect.
中国人自古以来便喜欢品茶鉴茶, 饮茶之风从古代风靡至今, 茶成为了最受欢迎的饮用佳品之一。 喜好饮茶的人都希望可以品尝到质量可以得到保障的茶叶, 而市场上的茶叶却往往鱼龙混杂, 良莠不齐, 品质不能得到很好地保证, 这在很大程度上影响了消费者的利益和优良茶叶品牌的建设和推广。 所以, 研究出一种高效快速又准确的茶叶品种鉴别方法符合社会和广大消费者的需求[1, 2]。
茶叶的鉴别方法从传统的人工鉴别到化学鉴别方法一直在不断发展[3], 但在一定程度上都不能真正满足现代化社会的需求。 前者主观因素较强且需要投入较大的人力和时间, 不能满足日益扩大的茶叶市场需求; 后者则工艺复杂且价格昂贵, 不适合进行大规模的实际应用。 近年来, 傅里叶近红外光谱技术以其绿色高效准确的性能在茶叶鉴别研究中初步崭露头角, 从定性到定量, 诸多的研究成果论证了这一技术运用于茶叶领域的可行性[4]。 例如: Zhuang等应用近红外光谱可以有效无损地检测山东绿茶的起源地, 采用BP神经网络, 偏最小二乘法(PLS)和支持向量机(SVM)进行回归计算, 结果表明运用PLS对训练样本和测试样本均可达到100%的鉴定准确率[5]。 Cai等利用傅里叶红外光谱(FTIR)和模式识别对茶叶品种进行鉴别, 采用偏最小二乘法(PLS)与自组织特征映射(SOM)神经网络方法相结合形成了一种相比于PLS线性方法更为准确的非线性分类算法, 识别率达到100%[6]。 武小红等利用FTIR光谱结合Gustafson-Kessel聚类方法对茶叶品种进行鉴别分析, 为茶叶品种分类提供了一种有效的判别模型[7]。 Deng等利用近红外高光谱成像完成了对浙江龙井茶叶含水量快速准确的无损检测[8]。 Li等提出间隔偏最小二乘法(IPLS)提取和优化全光谱数据的特征, 研究了来自14种茶树的160个茶叶样本的茶多酚(TP)红外光谱快速测定, 分别建立基于PLS, IPLS和后向间隔偏最小二乘法(BIPLS)的回归预测模型, 证明了红外光谱法测定茶叶中TP含量的可行性[9]。 Xiong等利用近红外反射光谱和多光谱成像(MSI)系统对铁观音的总多酚含量(TPC)和贮藏期进行无损测定, 实验结果表明采用偏最小二乘法的MSI系统是无损和快速检测茶叶TPC含量的最佳方法[10], 分别采用最小二乘支持向量机(LS-SVM)和BP神经网络分类茶叶贮藏期的准确率分别为95.0%和97.5%。 Xu等应用傅里叶变换近红外光谱, PLS和单类偏最小二乘(OCPLS)对中国功能性茶(板蓝根)掺假进行快速鉴别, 为板蓝根茶的快速质量控制提供一个有用的新方法[11]。
通过光谱仪采集到的茶叶近红外光谱是一种高维的数据[12], 其中包含了很多复杂的冗余信息, 影响了计算结果的准确性, 通过对光谱数据的降维处理可减少冗余信息。 本工作采用主成分分析(PCA)进行降维处理[13], 然后通过线性判别分析(LDA)进行特征提取[14]。 最后在传统模糊极大熵聚类(FEC)[15]算法的基础上引入了可能C均值聚类分析(PCM)[16], 在此基础上提出了一种混合模糊极大熵聚类(MFEC)算法, 同时用MFEC进行聚类分析以实现对茶叶品种的最终鉴别分类。
首先用近红外光谱仪完成对岳西翠兰、 六安瓜片、 施集毛峰三种茶叶样本的傅里叶近红外光谱(FT-NIR)数据采集, 然后经过多元散射校正(MSC)预处理, 主成分分析和线性判别分析的数据压缩和特征提取, 最后分别通过模糊极大熵聚类分析和混合模糊极大熵聚类分析完成对三种茶叶的分类。 结果表明, 本工作提出的FT-NIR结合MFEC算法可以很好的完成对三种安徽品牌茶叶的鉴别分析。
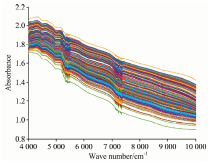
实验用茶叶为岳西翠兰、 六安瓜片、 施集毛峰等三种安徽品牌茶叶, 每种茶叶有65个样本, 总的茶叶样本数为195。 样本经过研磨粉粹后过40目筛。 实验室的温度和相对湿度保持相对不变, Antaris Ⅱ 型FT-NIR光谱仪开机预热1 h。 采用反射积分球模式采集茶叶近红外光谱, 每个茶叶样品扫描32次。 光谱波数范围是4 000~10 000 cm-1, 扫描的光谱波数间隔是3.857 cm-1, 采集的茶叶光谱数据维数为1 557维。 每个样本采样3次, 3次的平均值作为后续实验中样本的光谱数据。 采集的3种安徽茶叶样本的FT-NIR图如图1所示。 用Matlab R2014b编写程序, 运行在Windows 10系统里, RAM 8GB。
 | 图1 3种茶叶样本的近红外光谱图Fig.1 FT-NIR spectra of three kinds of tea samples |
混合模糊极大熵聚类(MFEC)算法具体描述如下:
(1) 初始化过程: 设置权重指数m(m> 1), 类别数c; 设置循环计数r的初始值和最大迭代次数为rmax; 设置迭代最大误差参数ε ; 参数λ 和β , 以每类训练样本的均值作为初始的类中心值
式(1)中, n为测试样本数, m(m> 1)为权重指数, xk为第k个茶叶测试样本。
(2) 计算第r(r=1, 2, …, rmax)次迭代时的模糊隶属度值
式(2)中, uik是样本xk隶属于类别i的模糊隶属度值,
(3) 计算第r次迭代时的第i类的类中心值
式(3)中,
(4) 循环计数增加, 即r=r+1;
若满足条件: (‖ V(r)-V(r-1)‖ < ε )或(r> rmax)则计算终止, 否则继续步骤(2)。
用近红外光谱仪采集到的光谱数据中, 除了包含对数据分析有价值的茶叶化学成分的光谱吸收数据信息外, 还掺杂着影响数据分析准确率的光散射信息。 光散射受多种物理因素(如粒径, 形状和分布)的影响, 并且在不同样品的光散射信息中可能存在差异。 鉴于光散射信息带来的种种不利影响, 需要对采集到的原始近红外光谱数据进行预处理。 多元散射校正(MSC)是有效的近红外光谱预处理方法, 所以本文采用MSC方法预处理茶叶近红外光谱的原始数据。 该方法需要重新构建待测样品原始数据的理想光谱。 这需要近红外光谱变化和样本组成含量符合直接线性的关系。 而实际操作中往往难以获得真正的理想光谱, 因此根据具体情况, 取全部光谱的平均光谱来作为理想光谱是比较合理的。 作为多变量散射校正的方法, MSC方法可使光谱数据去除或减弱光散射所带来的影响, 从而使有用光谱信息得到增强。 对图1的茶叶近红外光谱进行MSC处理后的光谱如图2所示。
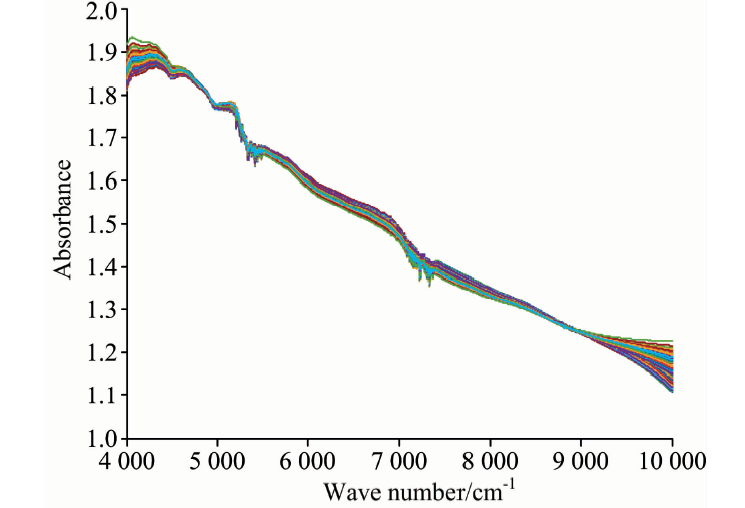 | 图2 MSC预处理后的茶叶近红外光谱图Fig.2 FT-NIR spectra pretreated with MSC |
经过MSC预处理后的茶叶光谱数据仍然是1 557维的高维数据, 其中包含了大量的冗余信息, 因此需要对光谱数据进行降维处理。 这里选取经典降维算法— 主成分分析(PCA)算法来实现降维处理。 经PCA降维处理后前2个特征向量的PCA得分图如图3所示。 其中符号“ · ” , “ * ” 和“ ” 分别代表了岳西翠兰、 六安瓜片和施集毛峰三种茶叶。 观察PCA得分图可知, 岳西翠兰和六安瓜片茶叶样本数据有少部分存在重叠, 重叠部分数据在分类时容易出错, 而施集毛峰和其余两种茶叶样本数据没有重叠, 分类效果好。 经PCA将光谱数据降至10维后, 再用线性判别分析(LDA)方法对降维后的数据进行特征提取以提取出有价值的鉴别信息。 从每类茶叶样本中选取22个样本作为训练样本, 即训练集样本数为66个, 剩下每类43个茶叶样本作为测试样本, 即测试集样本数为129个。
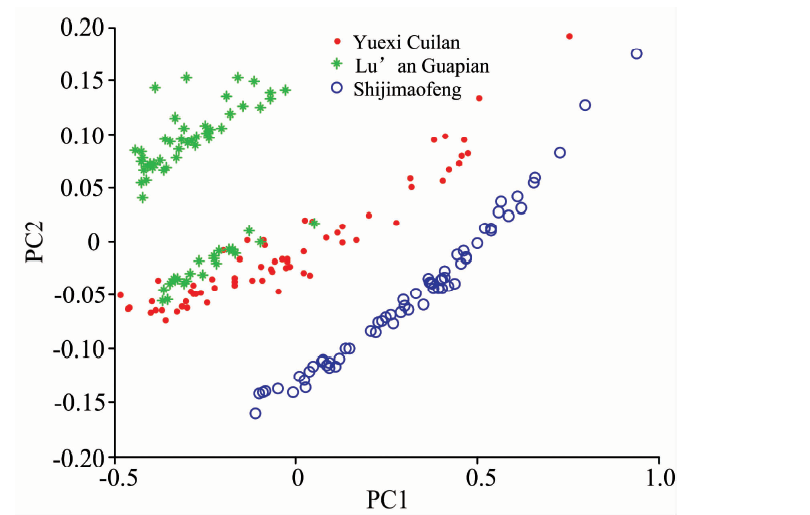 | 图3 PCA得分图Fig.3 Scores plot of PCA |
2.3.1 模糊聚类分析初始参数的设置
FEC与MFEC的初始参数设置为: 权重指数m=2, 品种数c=3, 参数λ =10, β =10, 初始迭代次数r=1, 最大迭代次数rmax=100, 迭代最大误差参数为ε =0.000 01, 测试样本数n=129, 经过LDA后得到的训练样本的均值即为初始聚类中心, 则得到的初始聚类中心如式(4)所示
2.3.2 模糊聚类准确率
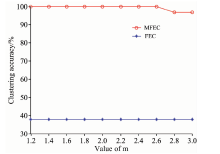
通过运行FEC和MFEC两种聚类算法, 改变MFEC算法权重指数m的值后观察两种聚类分析算法的聚类准确率。 在m分别取值1.2, 1.4, …, 3.0下观察聚类准确率的变化如图4所示。 从图4中不难看出, MFEC的准确率明显高于传统的FEC的准确率。 在m分别取值1.2, 1.4, …, 2.6的情况下, MFEC的聚类准确率达到100%, 并且在m=2.8, 3.0的情况下聚类准确率达到96.9%。 传统的FEC没有参数m, 其聚类准确率仅为37.98%。 当m=2时, MFEC分析算法在经过10次迭代计算后收敛, 而传统的FEC需经过100次迭代计算才可达到收敛, 所以, MFEC在聚类收敛上要优于传统的FEC。
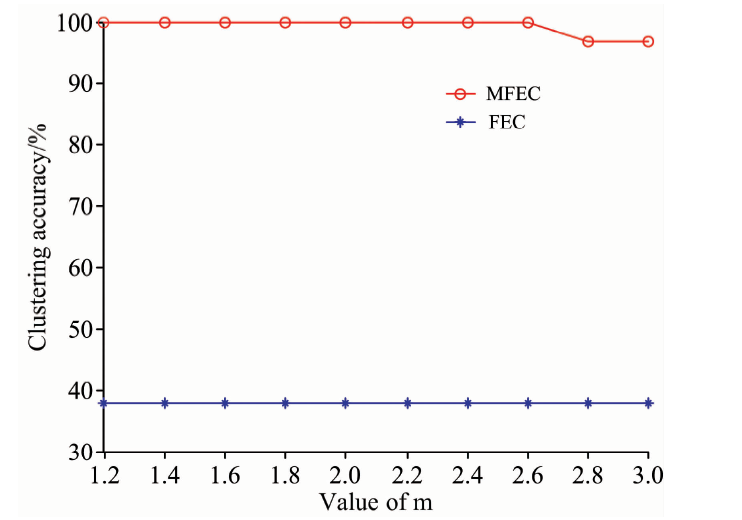 | 图4 FEC和MFEC的聚类准确率Fig.4 The clustering accuracies of FEC and MFEC |
2.3.3 茶叶种类判别
以经过LDA处理后的数据样本作为本节所使用的训练样本和测试样本。 计算岳西翠兰、 六安瓜片以及施集毛峰三种茶叶训练样本的平均值: 岳西翠兰平均值
测试样本经过MFEC计算后得到三个聚类中心
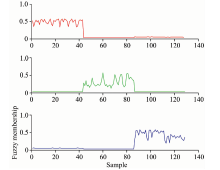
在聚类分析算法达到收敛后, 对于得到的样本的模糊隶属度值进行分析。 对于MFEC的模糊隶属度值而言, 通过分析判断某样本模糊隶属度值在三种类别下的情况可判断该样本隶属于哪个品种茶叶。 当某样本在某一类模糊隶属度值高于另外两类的模糊隶属度值时则判定该样本属于这一类品种茶叶。 对于测试样本xk的模糊隶属度值uik, 若判定其类别属于第i类, 则uik的值要大于其他类别的模糊隶属度值。 MFEC迭代收敛后的模糊隶属度图如图5所示。
 | 图5 模糊隶属度值Fig.5 Fuzzy membership of MFEC |
为解决FEC对噪声数据敏感问题, 在FEC基础上, 结合可能C均值聚类分析(PCM), 提出了一种混合模糊极大熵聚类(MFEC)分析。 将MFEC和FEC运用于茶叶傅里叶近红外光谱的模糊聚类分析, 聚类结果表明, MFEC算法相比于传统的FEC算法, 具有更快的收敛速度, 更高的聚类准确率。 通过使用茶叶的傅里叶近红外光谱数据, 结合主成分分析, 线性判别分析和MFEC算法可对三种安徽品牌茶叶实现快速、 准确的分类, MFEC具有明显更高的聚类准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|