


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
不同含水量的岩石近红外光谱的特征选择
[张芳1, 2  , 户佐乐
, 户佐乐1, 2 , 侯欣莉3 , 张秀莲1, 2 , 付成功1, 2 , 李英骏1, 4 , 何满潮1 ]
, 户佐乐|
|


作者简介: 张 芳, 1976年生, 中国矿业大学(北京)高级工程师 e-mail: zhangf76@163.com
岩石含水量是影响岩石物理、 化学和力学特性的一个重要指标。 在岩土工程、 隧道工程等领域, 岩石含水量的大小是诱发灾变和病害的关键原因。 与传统方法相比, 利用近红外光谱(NIRS)特征检测岩石含水量, 具有无损、 定量的明显优势, 其难点和关键是近红外光谱的特征选择。 针对该问题, 进行了室内实验, 研究不同含水量下的岩石近红外光谱的特征选择。 特征选择方法中的Filter法, 利用样本数据内在的特点, 评价特征的重要程度, 增强了特征与类的相关性, 同时削减了特征之间的相关性, 具有复杂度低、 直观、 效率高、 普适性强的优点, 符合该研究的数据特点。 因此, 选用Filter型的依赖性度量法进行特征选择。 室内实验中, 首先制备11种不同含水量的砂岩试样, 并分别采集了前后左右4个测试点处的共计44条近红外光谱曲线; 然后, 利用一阶导数法对光谱进行预处理, 基于此, 选择1 400和1 930 nm谱段进行光谱特征分析, 并分别提取2个谱段处的峰面积、 峰高、 半高宽、 左肩宽度、 右肩宽度、 左右肩宽比共计6个初始特征变量; 考虑到6个初始特征变量的量纲不同, 且变量之间的变化幅度不同, 对原始数据进行正规化变换, 消除量纲和变化幅度不同带来的影响; 接着, 根据自变量的筛选原则, 去掉自变量之间具有强线性相关的冗余变量; 然后, 利用依赖性度量法中的统计相关系数作为相关程度的度量标准, 分析了初始特征变量之间以及初始特征变量与含水量之间的相关程度, 并得到了2个强相关谱段处的最优特征变量; 最后, 在强相关谱段处分别构建了多元回归模型, 并对模型进行了检验分析。 研究结果表明: (1)波长1 400和1 930 nm附近的近红外光谱吸收峰特征与岩石含水量有明显相关性; (2)波长1 400 nm处的峰高、 右肩宽度、 左肩宽度与含水量线性相关性明显; 波长1 930 nm处的峰高、 右肩宽度与含水量线性相关性明显; (3)多元线性回归模型能够较精确表达含水量与近红外光谱之间的相关性, 利用该模型可实现基于近红外光谱特征的含水岩石含水量预测, 为利用近红外光谱实现动态监测与评估岩石含水量提供基础建模数据。
, HU Zuo-leWater content of rock is an important index to affect the physical, chemical and mechanical properties of rock. In geotechnical engineering, tunnel engineering and other fields, water content is the key factor to induce disaster and disease. Compared with the traditional method, the determination of rock water content by using the feature of NIR spectrum (NIRS) has obvious advantages of nondestructive and quantitative analysis, and the difficulty and key is the feature selection of NIR spectrum. In order to solve this problem, laboratory experiments were carried out to study the feature selection of near infrared spectra of rock under different water content. The Filter method of feature selection, using the inherent characteristics of the sample data, evaluates the importance of the feature, enhances the correlation between the feature and the class, and reduces the correlation between the features, so it has the advantages of low complexity, being intuitionistic, high efficiency and strong universality and accords with the characteristics of the data studied in this paper. Therefore, this paper selects the Filter type dependency metric for feature selection. In the laboratory experiment, 11 kinds of sandstone samples with different moisture content were prepared, and 44 NIR spectra were collected respectively at 4 test points on the front, behind, left and right sides. Then, the first derivative method was used to preprocess the spectrum. Based on this, the spectral characteristics were analyzed at 1 400 and 1 930 nm, and six initial characteristic variables (the peak area, peak height, width of half height, width of left shoulder, width of right shoulder, the ratio of the width of the left shoulder to the width of the right shoulder )were extracted respectively. Considering the different dimensions and variation range of the six initial characteristic variables, the original data were normalized to eliminate the influence of different dimensions and variation ranges. And then, according to the principle of independent variable selection, redundant variables with strong linear correlation between independent variables were removed. Then, used the statistical correlation coefficient in the dependency metric as the measure of correlation degree, and the correlation among the initial characteristic variables and the correlation between the initial characteristic variables and water content were analyzed. The optimal characteristic variables at two strongly correlated spectral segments were obtained. Finally, multiple regression models were constructed at the strong correlation spectral segments, and the models were tested and analyzed. The results showed that: (1) the characteristics of the near-infrared spectral absorption peaks around the wavelengths of 1 400 and 1 930 nm are significantly correlated with the rock water content; (2) the peak height, right half width and left half width at the wavelength of 1 400 nm have linear correlation with the water content obviously, and the peak height and right half width at the wavelength of 1 930 nm also have linear correlation with the water content obviously; (3) the multiple linear regression model can accurately express the correlation between the water content and the near-infrared spectrum, and the model can be used to predict the water content of water-bearing rock based on the characteristics of near-infrared spectrum. It provides basic modeling data for dynamic monitoring and evaluation of rock water content by using near infrared spectrum analysis technology.
岩石含水量是影响岩石物理、 化学和力学特性的一个重要指标。 在岩土工程、 隧道工程等领域, 岩石含水量的大小是诱发灾变和病害的关键原因。 与传统方法相比, 利用近红外光谱(NIRS)特征检测岩石含水量, 具有无损、 定量的明显优势, 近年来该方法逐渐引起人们的关注。
光谱特征选择是建立岩石含水量与近红外光谱特征之间的定量关系的难点和关键。 如何从高维数据中剔除冗余或无关的特征变量是目前面临的难题。 一个合适的特征选择方法, 不仅可以有效简化推理规则, 还可在不降低模型准确性和稳定性的前提下提高运行效率。 目前国内外诸多学者已开展了大量的研究工作[1, 2, 3, 4, 5, 6, 7], 根据评估方法可将特征选择大致分为过滤型(Filter)、 封装型(Wrapper)和嵌入型(Embedded)三类方法, 其中Filter利用样本数据内在的特点, 评价特征的重要程度, 增强了特征与类的相关性, 同时削减了特征之间的相关性, 具有复杂度低、 直观、 效率高、 普适性强的优点, 符合本研究的数据特点, 故采用此方法。
Filter法的度量标准有四类, 分别是距离度量、 信息度量、 依赖性度量和一致性度量, 其中距离度量常用欧氏距离、 平方距离等参数度量; 信息度量常用信息增益、 互信息等参数度量; 依赖性度量常用Pearson相关系数、 Fisher分数、 平方关联系数等参数度量; 一致性度量采用不一致率进行度量。 这四类度量标准适用范围不同, 也有局限性: 距离度量函数要求满足单调性, 信息度量(如BIF法)未考虑到所选特征间的相关性, 会带来较大冗余, 一致性度量对噪声数据比较敏感, 不适用于近红外光谱。
综上所述, 根据数据特点。 选用Filter型的依赖性度量法进行特征选择, 分析岩石在不同含水量下的近红外光谱的特征变量之间以及特征变量与含水量之间的相关关系, 选择最优特征变量, 为利用近红外光谱分析技术实现动态监测与评估岩石含水量提供基础建模数据。
利用深部软岩气态水吸附智能测试系统[图1(a)]、 电子恒温水箱[图1(b)]和真空干燥箱[图1(c)]制备不同含水量的砂岩, 数据采集系统为瑞士万通的XDS SmartProbe近红外光谱分析仪, 如图2所示, 其技术性能参数如表1。
 | 图1 制备不同含水量岩石的试验系统 (a): 深部软岩气态水吸附智能测试系统; (b): 电子恒温水箱; (c): 真空干燥箱Fig.1 Test system for preparing rock with different water contents (a): Intelligent testing system for vapour water adsorption of deep soft rock; (b): Electronic constant temperature water tank; (c): Vacuum drying oven |
 | 图2 近红外光谱测试系统Fig.2 Test system of near infrared spectroscopy |
砂岩样品(图3)取自陕西省榆林市神木县中部孙家岔乡的柠条塔井煤矿, 其基本的物理力学参数如表2。 分别制备含水量为0% , 10%, 20%, …, 90%, 100%共11个不同含水量的砂岩试样, 其制备步骤为: ①将砂岩试样放在真空干燥箱[图1(c)]干燥12 h后, 测量含水量为0%的近红外光谱曲线; ②将砂岩试样放入电子恒温水箱[图1(b)]煮沸8 h, 使其达到饱和状态; ③取出砂岩试样在室温下晾干, 待表面自由水消失后, 测量近红外光谱, 得到含水量100%的近红外光谱曲线; ④将饱和砂岩试样放到深部软岩气态水吸附智能测试系统[图1(a)]中, 进行蒸发实验, 观察含水量曲线, 分别在理论计算含水量达到36, 32, …, 4 g时, 中止含水量制备实验, 分别测量含水量为90%, 80%, …, 10%的近红外光谱曲线。
 | 图3 砂岩测试点位置 (a): 测点1; (b): 测点2; (c): 测点3; (d): 测点4Fig.3 Test point locations of sandstone (a): Point 1; (b): Point 2; (c): Point 3; (d): Point 4 |
| 表2 基本物理力学参数 Table 2 Basic physical and mechanical parameters |
实验过程中将光纤探头分别垂直接触试样的前后左右共4个测试点进行测量, 整个实验共采集11个不同含水量的共44条近红外光谱曲线。
数据分析所用到的软件有Origin8.0和Matlab7.0, 其中利用Origin分别提取光谱吸收峰的6个初始特征变量值; 利用Matlab计算吸收峰回归模型的各个参数和检验临界值, 设置在显著性水平为0.05的水平下有意义, 即认为该回归方程具有0.95的置信度。
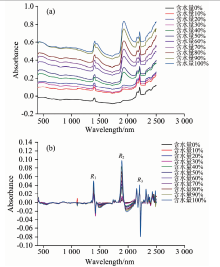
首先利用XDS SmartProbe近红外光谱分析仪配套软件将每个含水量的4条近红外光谱取平均值, 然后再利用一阶导数法对该光谱进行预处理, 消除背景的常数平移对近红外光谱的影响, 使数据具有更好的连续性, 处理前后光谱如图4。
 | 图4 近红外光谱 (a): 原始光谱; (b): 一阶导数预处理后光谱Fig.4 Near-infrared spectrum (a): Original spectra; (b): First-order derivative spectra |
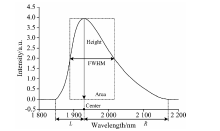
分析预处理后的近红外光谱[图4(b)]可知, 在400~2 500 nm波长范围内有3个明显的吸收峰, 分别位于波长1 400, 1 930和2 300 nm附近, 三处波长光谱的反射率随岩石含水量变化而变化, 依次将其记作峰R1、 峰R2、 峰R3。 随着含水量的不断增大, R1和R2两个吸收峰的波峰越来越高, 峰顶中心位置逐渐右移, 最终R1峰中心点位置停留在1 400 nm左右, R2峰中心点位置停留在1 930 nm左右, 而R3吸收峰的波峰随着含水量增加逐渐减小, 信号特征逐渐减弱, 且受2 400 nm之后的噪音波段干扰强烈, 故峰R3不适合作为含水量信息的特征谱段。 因此, 选择峰R1、 峰R2所在的1 400和1 930 nm谱段进行含水岩石光谱特征分析, 其具体提取的特征变量如图5所示, 分别为峰面积(area)、 峰高(height)、 半高宽(FWHM)、 左肩宽度(left half width, LHW)、 右肩宽度(right half width, RHW)、 左右肩宽比(LHW/RHW)共计6个初始特征变量, 记作X={x1, x2, x3, x4, x5, x6}。
 | 图5 吸收峰的初始特征变量示意图Fig.5 Schematic diagram of the initial characteristic variables of the absorption peak |
利用origin8.0分别计算峰R1、 峰R2的6个初始特征变量值, 如表2和表3所示。
| 表3 峰R1处的初始特征变量值 Table 3 Initial characteristic variable values at the peak R1 |
分析表3和表4可知, 6个初始特征变量的量纲不同, 且变量之间的变化幅度不同, 可能导致在分析计算过程中, 一些数量级较小的变量作用无法体现, 因此对原始数据进行正规化变换, 即将所有特征变量转换成0-1内的数值, 消除量纲和变化幅度不同带来的影响。
| 表4 峰R2处的初始特征变量值 Table 4 Initial characteristic variable values at the peak R2 |
归一化方法是将原始数据矩阵的各元素减去该元素所在列的最小值后再除以该列元素的极差, 公式如下
| 表5 峰R1处归一化后的初始特征变量值 Table 5 Iniuial characteristic variable values after normalization at the peak R1 |
| 表6 峰R2处归一化后的初始特征变量值 Table 6 Initial characteristic variable values after normalization at the peak R2 |
2.4.1 筛选原则
对特征变量进行筛选和简化, 即去掉自变量X之间具有强线性相关的冗余变量, 以及自变量中与因变量相关性较小的变量。
自变量的筛选原则[8]: (1)变量的零值测试, 即变量不应过于接近零值, 否则将使变量的作用偏小; (2)变量的方差测试, 标准方差越大的变量, 其作用也越大, 反之则越小, 因此应删除标准方差接近零的变量; (3)自变量的相关性测试, 即根据自变量间的相关系数可以判断自变量间的相关程度, 取门槛值0.95作为特征变量取舍的界限, 当两自变量相关系数大于此值时, 应剔除其一; (4)自变量与因变量的相关性测试, 即根据自变量与因变量间的相关系数可以判断相关程度, 本文取门槛值0.85作为特征变量取舍的界限, 当自变量与因变量相关系数小于此值时, 应剔除此特征变量。
2.4.2 特征选择与分析
(1)自变量零值和标准方差分析
由表5和表6可知, 特征变量经归一化处理后没有出现零值; 分析特征变量的标准方差, 可知峰R1各特征变量的标准方差比较接近, 故全部保留, 则峰R1处筛选后的特征变量为X={x1, x2, x3, x4, x5, x6}; 峰R2中左肩宽度x4的标准方差明显小于其他特征变量, 根据筛选原则, 剔除左肩宽度x4, 峰R2处筛选后的特征变量为X={x1, x2, x3, x5, x6}。
(2)自变量间的相关性分析
将初筛后的特征变量输入matlab组成矩阵X, 然后输入命令R=corrcoef(X), 计算矩阵X的相关系数矩阵R, 计算结果如表7和表8所示。
| 表7 峰R1特征变量间的相关系数 Table 7 Correlation coefficients between characteristic variables at the peak R1 |
| 表8 峰R2特征变量间的相关系数 Table 8 Correlation coefficients between characteristic variables at the peak R2 |
根据筛选原则, 分析表7和表8可知, 峰R1自变量间的相关系数大于门槛值0.95的有r1(x1, x2), r1(x1, x3), r1(x3, x4), r1(x3, x5), 综合考虑其重要性, 剔除峰面积x1、 半高宽x3和左右肩宽比x6, 则筛选后的特征变量为X={x2, x4, x5}; 同理, 峰R2自变量间的相关系数大于门槛值0.95的只有r2(x1, x2), 综合考虑其重要性, 剔除峰面积x1和左右肩宽比x6, 则筛选后的特征变量为X={x2, x3, x5}。
(3)自变量与因变量间的相关性分析
将上述筛选后的特征变量及因变量(含水量)输入matlab, 计算各自变量与因变量相关系数, 计算结果如表9和表10所示。
| 表9 峰R1的因变量与自变量间的相关系数 Table 9 Correlation coefficients between dependent and independent variables at the peak R1 |
| 表1 0 峰R2处的因变量与自变量间的相关系数 Table 1 0 Correlation coefficients between dependent and independent variables at the peak R2 |
根据筛选原则, 分析表9和表10可知, 峰R1自变量与因变量间的相关系数均大于门槛值0.85, 则筛选后的特征变量为X={x2, x4, x5}; 同理, 峰R2自变量与因变量间的相关系数小于门槛值0.85的有r2(y, x3), 故剔除半高宽x3, 则筛选后的特征变量为X={x2, x5}。
综上所述, 峰R1筛选后的特征变量为X={x2, x4, x5}, 按相关程度由大到小为峰高、 右肩宽度、 左肩宽度三个特征变量; 峰R2筛选后的特征变量为X={x2, x5}, 按相关程度由大到小为峰高、 右肩宽度两个特征变量。
采用多元线性回归方法建立因变量Y与筛选后自变量X的数学模型并进行统计检验, 对回归方程可信度进行判断。
应用matlab中的regress命令, 计算峰R1回归模型的各个参数, 以及应用finv命令计算峰R1回归模型的检验临界值。
经计算, 得出峰R1因变量Y与自变量X的数学回归模型为
F=55.417 5> F3, 7(0.05)=4.346 8, 因此, 线性回归效果显著, 即Y与X之间存在线性相关关系, 且p=0.000 0< 0.05, 说明岩石含水量与峰R1处的峰高、 左肩宽度、 右肩宽度之间的多元线性回归方程的模型参数为0的原假设是小概率事件, 即式(2)的回归方程可以通过检验。
同理, 可得出峰R2因变量Y与自变量X的数学回归模型为
F=139.811 1> F2, 8(0.05)=4.459 0, 因此, 线性回归效果显著, 即Y与X之间存在线性相关关系, 且p=0.000 0< 0.05, 说明岩石含水量与峰R2处的峰高、 右肩宽度之间的多元线性回归方程的模型参数为0的原假设是小概率事件, 即式(3)的回归方程可以通过检验。
综上所述, 岩石含水量与光谱特征之间呈线性相关关系, 其中峰R1的峰高、 右肩宽度、 左肩宽度与含水量线性回归效果较显著, 峰R2的峰高、 右肩宽度与含水量线性回归效果较显著。 采用多元线性回归模型可建立含水岩石近红外光谱特征与含水量之间的因果关系, 利用该回归模型可进行基于近红外光谱特征的含水岩石中的含水量预测。
在室内制备了11种不同含水量岩石, 并分别测量了近红外光谱曲线, 对其进行一阶求导之后, 分析谱段特征进行初始特征提取, 然后进行了光谱特征选择, 最后利用最优特征变量构建多元回归模型, 并对此模型进行了检验分析, 得出如下结论:
(1)波长1 400和1 930 nm附近的近红外光谱吸收峰特征与岩石含水量有明显相关性;
(2)波长1 400 nm处的峰高、 右肩宽度、 左肩宽度与含水量线性相关性明显; 波长1 930 nm处的峰高、 右肩宽度与含水量线性相关性明显;
(3)采用含水岩石近红外光谱吸收峰特征建立多元线性回归模型, 通过线性模型能够较精确表达含水量与近红外光谱之间的相关性, 利用该回归模型可进行基于近红外光谱特征的含水岩石中的含水量预测。
致谢: 非常感谢为本工作做出贡献的同事们, 特别要感谢王东升、 李鹏飞、 胡臣、 谢运鑫等学生参与实验模拟工作。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|